 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
EyeDAS: Securing Perception of Autonomous Cars Against the Stereoblindness Syndrome
May 13, 2022
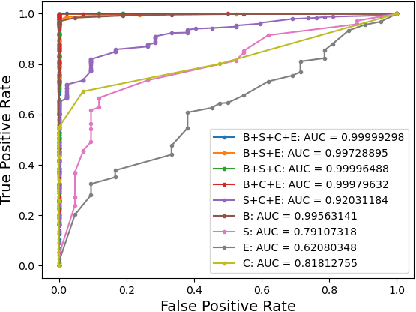
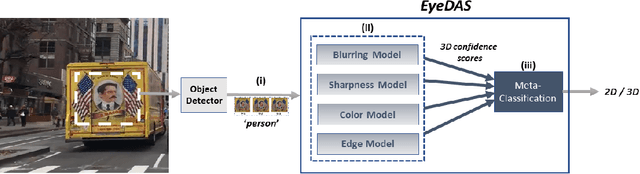

The ability to detect whether an object is a 2D or 3D object is extremely important in autonomous driving, since a detection error can have life-threatening consequences, endangering the safety of the driver, passengers, pedestrians, and others on the road. Methods proposed to distinguish between 2 and 3D objects (e.g., liveness detection methods) are not suitable for autonomous driving, because they are object dependent or do not consider the constraints associated with autonomous driving (e.g., the need for real-time decision-making while the vehicle is moving). In this paper, we present EyeDAS, a novel few-shot learning-based method aimed at securing an object detector (OD) against the threat posed by the stereoblindness syndrome (i.e., the inability to distinguish between 2D and 3D objects). We evaluate EyeDAS's real-time performance using 2,000 objects extracted from seven YouTube video recordings of street views taken by a dash cam from the driver's seat perspective. When applying EyeDAS to seven state-of-the-art ODs as a countermeasure, EyeDAS was able to reduce the 2D misclassification rate from 71.42-100% to 2.4% with a 3D misclassification rate of 0% (TPR of 1.0). We also show that EyeDAS outperforms the baseline method and achieves an AUC of over 0.999 and a TPR of 1.0 with an FPR of 0.024.
Time Series Forecasting via Learning Convolutionally Low-Rank Models
Apr 23, 2021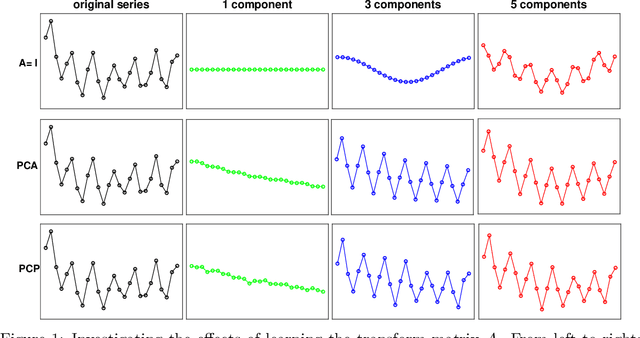
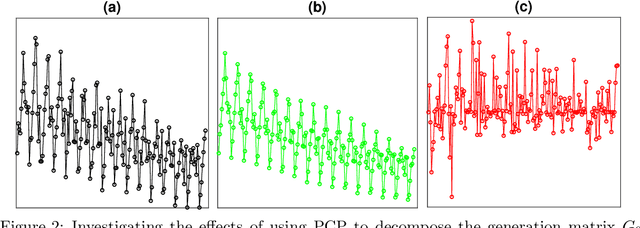
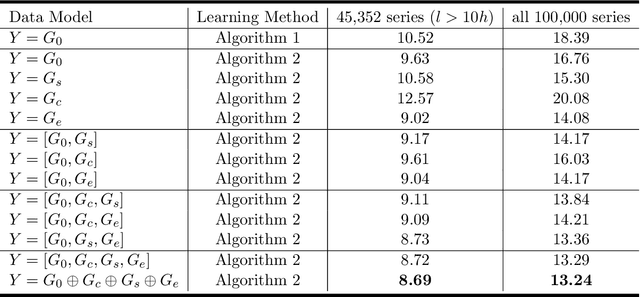
Recently,~\citet{liu:arxiv:2019} studied the rather challenging problem of time series forecasting from the perspective of compressed sensing. They proposed a no-learning method, named Convolution Nuclear Norm Minimization (CNNM), and proved that CNNM can exactly recover the future part of a series from its observed part, provided that the series is convolutionally low-rank. While impressive, the convolutional low-rankness condition may not be satisfied whenever the series is far from being seasonal, and is in fact brittle to the presence of trends and dynamics. This paper tries to approach the issues by integrating a learnable, orthonormal transformation into CNNM, with the purpose for converting the series of involute structures into regular signals of convolutionally low-rank. We prove that the resulted model, termed Learning-Based CNNM (LbCNNM), strictly succeeds in identifying the future part of a series, as long as the transform of the series is convolutionally low-rank. To learn proper transformations that may meet the required success conditions, we devise an interpretable method based on Principal Component Purist (PCP). Equipped with this learning method and some elaborate data argumentation skills, LbCNNM not only can handle well the major components of time series (including trends, seasonality and dynamics), but also can make use of the forecasts provided by some other forecasting methods; this means LbCNNM can be used as a general tool for model combination. Extensive experiments on 100,452 real-world time series from TSDL and M4 demonstrate the superior performance of LbCNNM.
Automatic extraction of similar traffic scenes from large naturalistic datasets using the Hausdorff distance
Jun 17, 2022

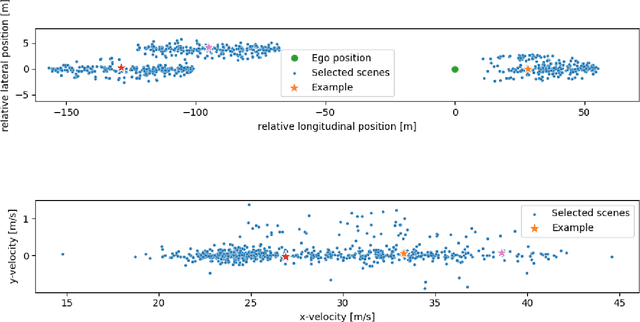
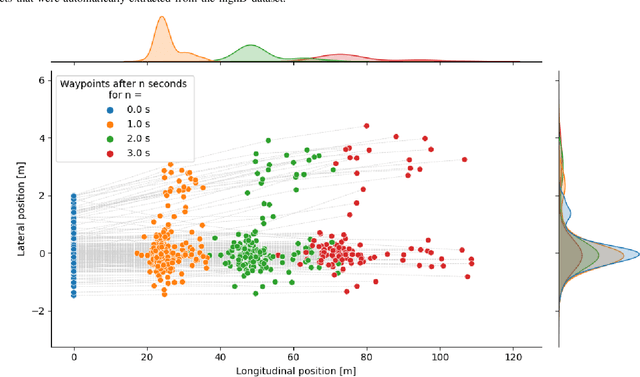
Recently, multiple naturalistic traffic datasets of human-driven trajectories have been published (e.g., highD, NGSim, and pNEUMA). These datasets have been used in studies that investigate variability in human driving behavior, for example for scenario-based validation of autonomous vehicle (AV) behavior, modeling driver behavior, or validating driver models. Thus far, these studies focused on the variability on an operational level (e.g., velocity profiles during a lane change), not on a tactical level (i.e., to change lanes or not). Investigating the variability on both levels is necessary to develop driver models and AVs that include multiple tactical behaviors. To expose multi-level variability, the human responses to the same traffic scene could be investigated. However, no method exists to automatically extract similar scenes from datasets. Here, we present a four-step extraction method that uses the Hausdorff distance, a mathematical distance metric for sets. We performed a case study on the highD dataset that showed that the method is practically applicable. The human responses to the selected scenes exposed the variability on both the tactical and operational levels. With this new method, the variability in operational and tactical human behavior can be investigated, without the need for costly and time-consuming driving-simulator experiments.
One Step at a Time: Long-Horizon Vision-and-Language Navigation with Milestones
Feb 14, 2022

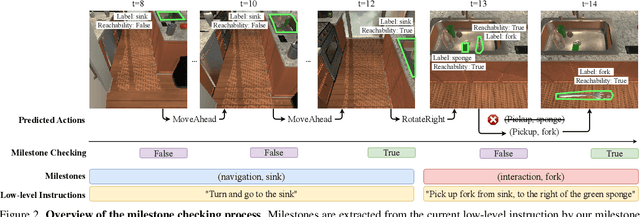
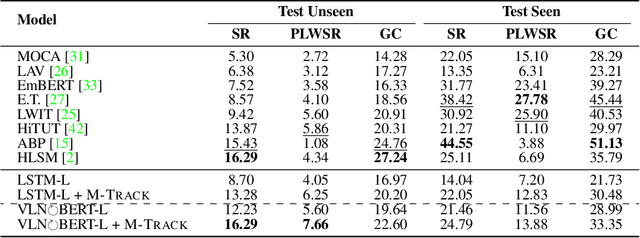
We study the problem of developing autonomous agents that can follow human instructions to infer and perform a sequence of actions to complete the underlying task. Significant progress has been made in recent years, especially for tasks with short horizons. However, when it comes to long-horizon tasks with extended sequences of actions, an agent can easily ignore some instructions or get stuck in the middle of the long instructions and eventually fail the task. To address this challenge, we propose a model-agnostic milestone-based task tracker (M-TRACK) to guide the agent and monitor its progress. Specifically, we propose a milestone builder that tags the instructions with navigation and interaction milestones which the agent needs to complete step by step, and a milestone checker that systemically checks the agent's progress in its current milestone and determines when to proceed to the next. On the challenging ALFRED dataset, our M-TRACK leads to a notable 45% and 70% relative improvement in unseen success rate over two competitive base models.
NeRF-In: Free-Form NeRF Inpainting with RGB-D Priors
Jun 10, 2022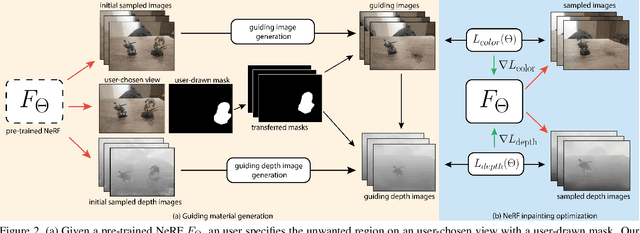
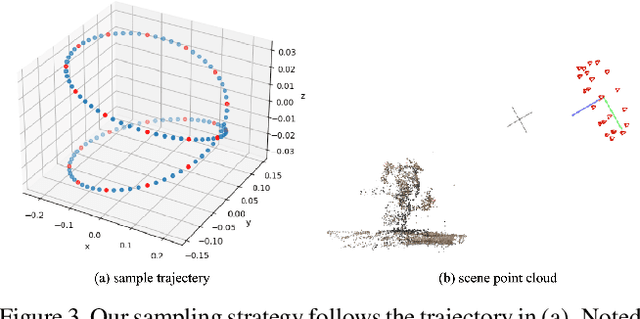


Though Neural Radiance Field (NeRF) demonstrates compelling novel view synthesis results, it is still unintuitive to edit a pre-trained NeRF because the neural network's parameters and the scene geometry/appearance are often not explicitly associated. In this paper, we introduce the first framework that enables users to remove unwanted objects or retouch undesired regions in a 3D scene represented by a pre-trained NeRF without any category-specific data and training. The user first draws a free-form mask to specify a region containing unwanted objects over a rendered view from the pre-trained NeRF. Our framework first transfers the user-provided mask to other rendered views and estimates guiding color and depth images within these transferred masked regions. Next, we formulate an optimization problem that jointly inpaints the image content in all masked regions across multiple views by updating the NeRF model's parameters. We demonstrate our framework on diverse scenes and show it obtained visual plausible and structurally consistent results across multiple views using shorter time and less user manual efforts.
STAR-RIS-Assisted Hybrid NOMA mmWave Communication: Optimization and Performance Analysis
May 13, 2022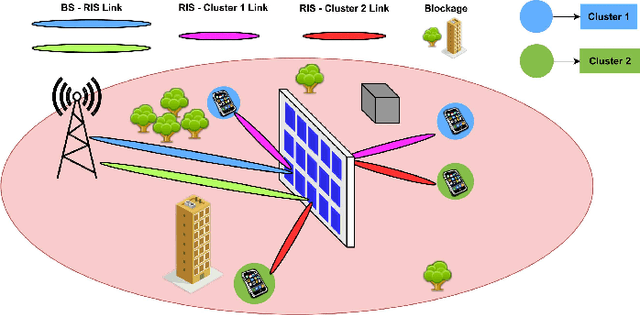
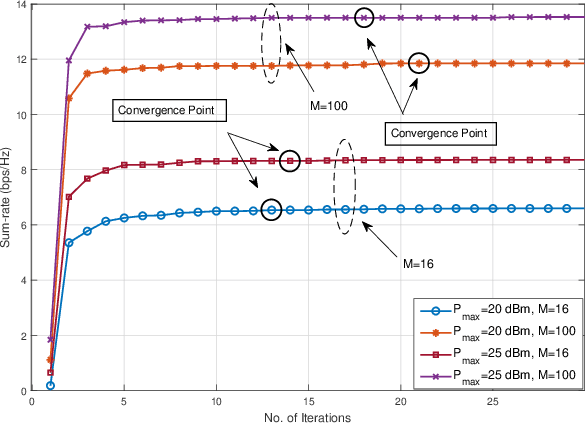
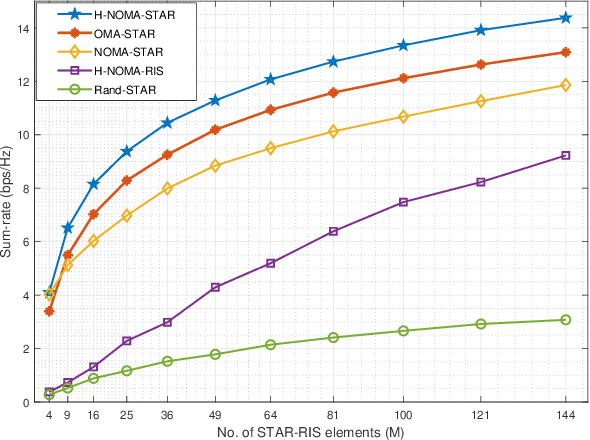
Simultaneously reflecting and transmitting reconfigurable intelligent surfaces (STAR-RIS) has recently emerged as prominent technology that exploits the transmissive property of RIS to mitigate the half-space coverage limitation of conventional RIS operating on millimeter-wave (mmWave). In this paper, we study a downlink STAR-RIS-based multi-user multiple-input single-output (MU-MISO) mmWave hybrid non-orthogonal multiple access (H-NOMA) wireless network, where a sum-rate maximization problem has been formulated. The design of active and passive beamforming vectors, time and power allocation for H-NOMA is a highly coupled non-convex problem. To handle the problem, we propose an optimization framework based on alternating optimization (AO) that iteratively solves active and passive beamforming sub-problems. Channel correlations and channel strength-based techniques have been proposed for a specific case of two-user optimal clustering and decoding order assignment, respectively, for which analytical solutions to joint power and time allocation for H-NOMA have also been derived. Simulation results show that: 1) the proposed framework leveraging H-NOMA outperforms conventional OMA and NOMA to maximize the achievable sum-rate; 2) using the proposed framework, the supported number of clusters for the given design constraints can be increased considerably; 3) through STAR-RIS, the number of elements can be significantly reduced as compared to conventional RIS to ensure a similar quality-of-service (QoS).
Efficient and Flexible Sublabel-Accurate Energy Minimization
Jun 20, 2022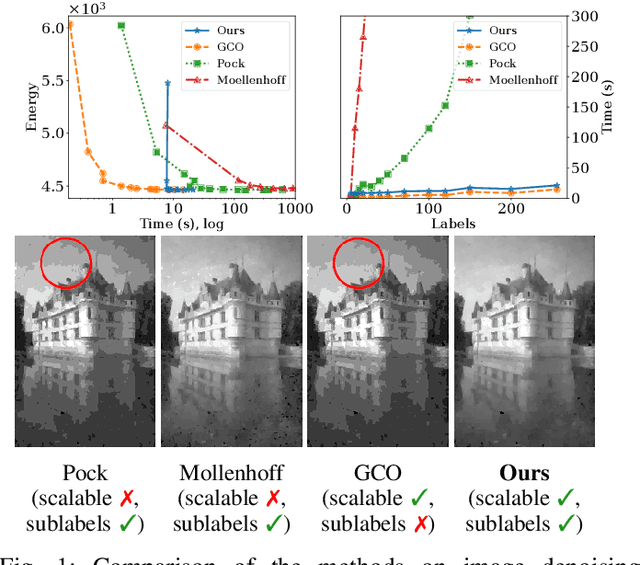

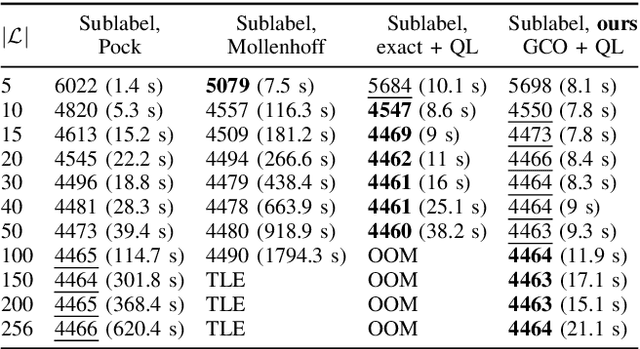
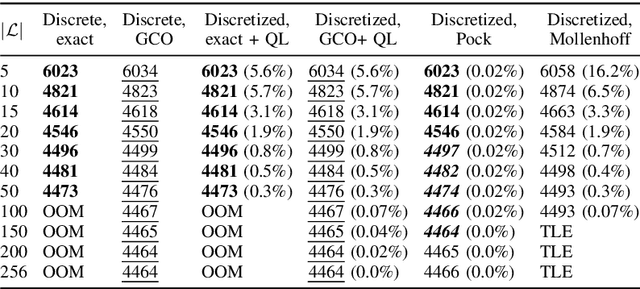
We address the problem of minimizing a class of energy functions consisting of data and smoothness terms that commonly occur in machine learning, computer vision, and pattern recognition. While discrete optimization methods are able to give theoretical optimality guarantees, they can only handle a finite number of labels and therefore suffer from label discretization bias. Existing continuous optimization methods can find sublabel-accurate solutions, but they are not efficient for large label spaces. In this work, we propose an efficient sublabel-accurate method that utilizes the best properties of both continuous and discrete models. We separate the problem into two sequential steps: (i) global discrete optimization for selecting the label range, and (ii) efficient continuous sublabel-accurate local refinement of a convex approximation of the energy function in the chosen range. Doing so allows us to achieve a boost in time and memory efficiency while practically keeping the accuracy at the same level as continuous convex relaxation methods, and in addition, providing theoretical optimality guarantees at the level of discrete methods. Finally, we show the flexibility of the proposed approach to general pairwise smoothness terms, so that it is applicable to a wide range of regularizations. Experiments on the illustrating example of the image denoising problem demonstrate the properties of the proposed method. The code reproducing experiments is available at \url{https://github.com/nurlanov-zh/sublabel-accurate-alpha-expansion}.
Image-based Treatment Effect Heterogeneity
Jun 13, 2022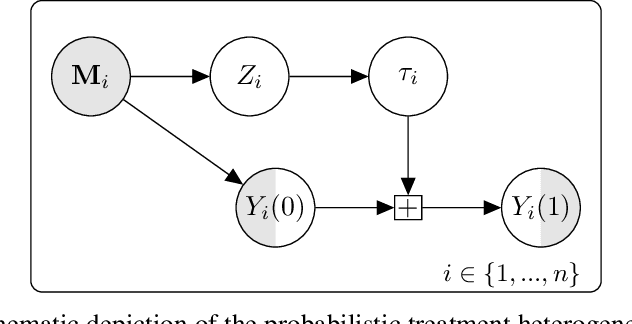
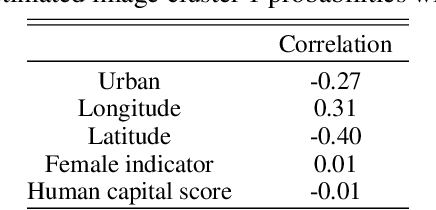
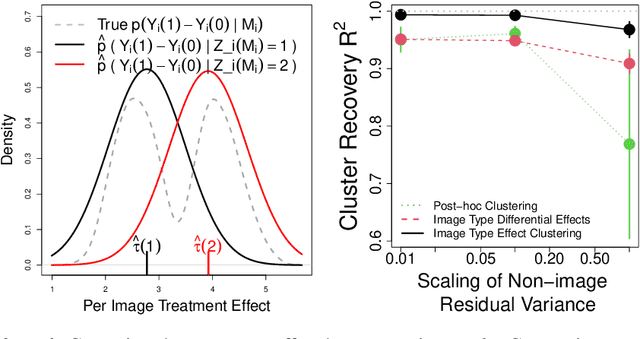
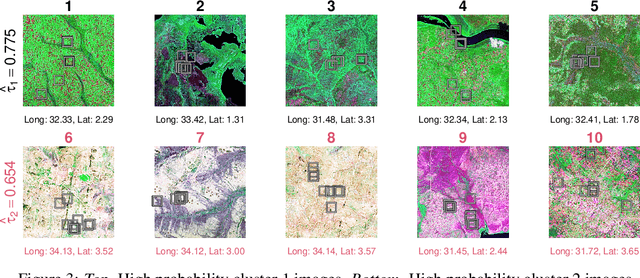
Randomized controlled trials (RCTs) are considered the gold standard for estimating the effects of interventions. Recent work has studied effect heterogeneity in RCTs by conditioning estimates on tabular variables such as age and ethnicity. However, such variables are often only observed near the time of the experiment and may fail to capture historical or geographical reasons for effect variation. When experiment units are associated with a particular location, satellite imagery can provide such historical and geographical information, yet there is no method which incorporates it for describing effect heterogeneity. In this paper, we develop such a method which estimates, using a deep probabilistic modeling framework, the clusters of images having the same distribution over treatment effects. We compare the proposed methods against alternatives in simulation and in an application to estimating the effects of an anti-poverty intervention in Uganda. A causal regularization penalty is introduced to ensure reliability of the cluster model in recovering Average Treatment Effects (ATEs). Finally, we discuss feasibility, limitations, and the applicability of these methods to other domains, such as medicine and climate science, where image information is prevalent. We make code for all modeling strategies publicly available in an open-source software package.
pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models
Jun 23, 2022



Knowledge tracing (KT) is the task of using students' historical learning interaction data to model their knowledge mastery over time so as to make predictions on their future interaction performance. Recently, remarkable progress has been made of using various deep learning techniques to solve the KT problem. However, the success behind deep learning based knowledge tracing (DLKT) approaches is still left somewhat mysterious and proper measurement and analysis of these DLKT approaches remain a challenge. First, data preprocessing procedures in existing works are often private and/or custom, which limits experimental standardization. Furthermore, existing DLKT studies often differ in terms of the evaluation protocol and are far away real-world educational contexts. To address these problems, we introduce a comprehensive python based benchmark platform, \textsc{pyKT}, to guarantee valid comparisons across DLKT methods via thorough evaluations. The \textsc{pyKT} library consists of a standardized set of integrated data preprocessing procedures on 7 popular datasets across different domains, and 10 frequently compared DLKT model implementations for transparent experiments. Results from our fine-grained and rigorous empirical KT studies yield a set of observations and suggestions for effective DLKT, e.g., wrong evaluation setting may cause label leakage that generally leads to performance inflation; and the improvement of many DLKT approaches is minimal compared to the very first DLKT model proposed by Piech et al. \cite{piech2015deep}. We have open sourced \textsc{pyKT} and our experimental results at \url{https://pykt.org/}. We welcome contributions from other research groups and practitioners.
LIDER: An Efficient High-dimensional Learned Index for Large-scale Dense Passage Retrieval
May 02, 2022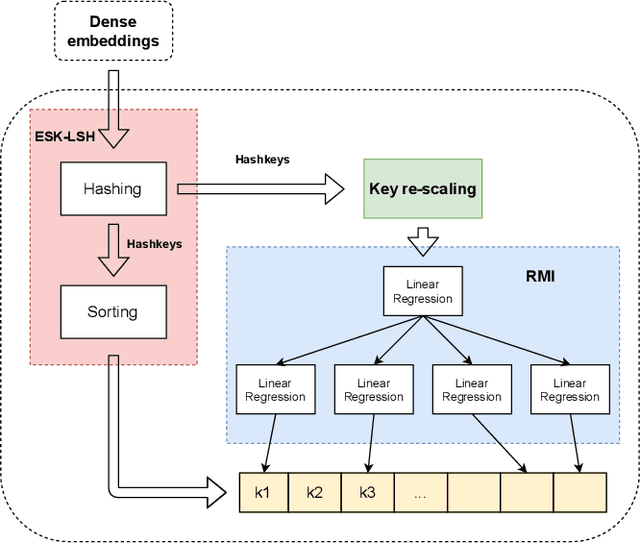
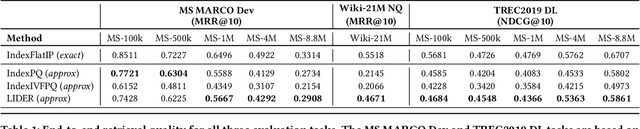
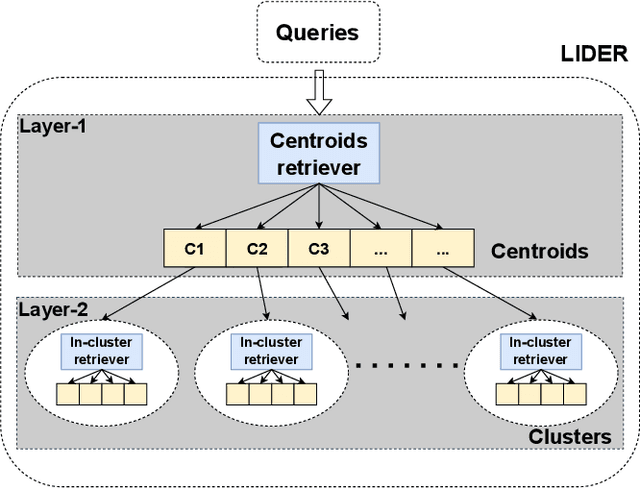
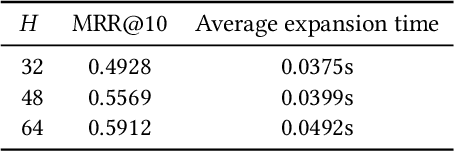
Text retrieval using dense embeddings generated from deep neural models is called "dense passage retrieval". Dense passage retrieval systems normally deploy a deep neural model followed by an approximate nearest neighbor (ANN) search module. The model generates text embeddings, which are then indexed by the ANN module. With the increasing data scale, the ANN module unavoidably becomes the bottleneck on efficiency, because of its linear or sublinear time complexity with data scale. An alternative is the learned index which has a theoretically constant time complexity. But most of the existing learned indexes are designed for low dimensional data. Thus they are not suitable for dense passage retrieval tasks with high-dimensional dense embeddings. We propose LIDER, an efficient high-dimensional Learned Index for large-scale DEnse passage Retrieval. LIDER has a clustering-based hierarchical architecture formed by two layers of core models. As the basic unit of LIDER to index and search data, each core model includes an adapted recursive model index (RMI) and a dimension reduction component which consists of an extended SortingKeys-LSH (SK-LSH) and a key re-scaling module. The dimension reduction component reduces the high-dimensional dense embeddings into one-dimensional keys and sorts them in a specific order, which are then used by the RMI. And the RMI consists of multiple simple linear regression models that make fast prediction in only O(1) time. We successfully optimize and combine SK-LSH and RMI together into the core model, and organize multiple core models into a two-layer structure based on a clustering-based partitioning of the whole data space. Experiments show that LIDER has a higher search speed with high retrieval quality comparing to the state-of-the-art ANN indexes commonly used in dense passage retrieval. Furthermore, LIDER has a better capability of speed-quality trade-off.