 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scaling ResNets in the Large-depth Regime
Jun 14, 2022
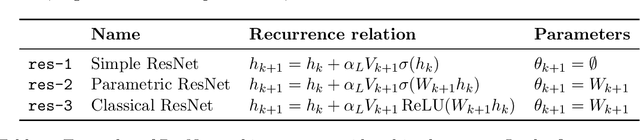
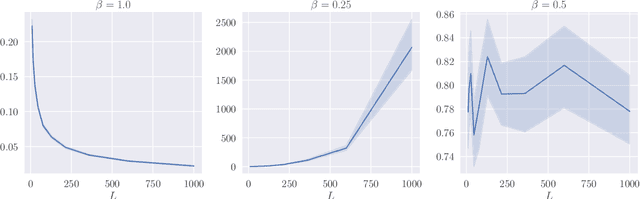
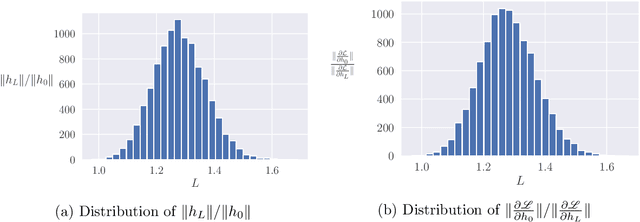
Deep ResNets are recognized for achieving state-of-the-art results in complex machine learning tasks. However, the remarkable performance of these architectures relies on a training procedure that needs to be carefully crafted to avoid vanishing or exploding gradients, particularly as the depth $L$ increases. No consensus has been reached on how to mitigate this issue, although a widely discussed strategy consists in scaling the output of each layer by a factor $\alpha_L$. We show in a probabilistic setting that with standard i.i.d. initializations, the only non-trivial dynamics is for $\alpha_L = 1/\sqrt{L}$ (other choices lead either to explosion or to identity mapping). This scaling factor corresponds in the continuous-time limit to a neural stochastic differential equation, contrarily to a widespread interpretation that deep ResNets are discretizations of neural ordinary differential equations. By contrast, in the latter regime, stability is obtained with specific correlated initializations and $\alpha_L = 1/L$. Our analysis suggests a strong interplay between scaling and regularity of the weights as a function of the layer index. Finally, in a series of experiments, we exhibit a continuous range of regimes driven by these two parameters, which jointly impact performance before and after training.
Privacy-Preserving Wavelet Neural Network with Fully Homomorphic Encryption
May 31, 2022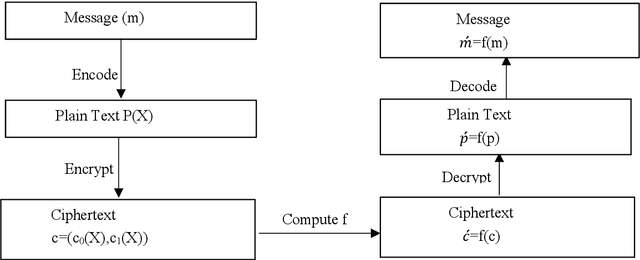
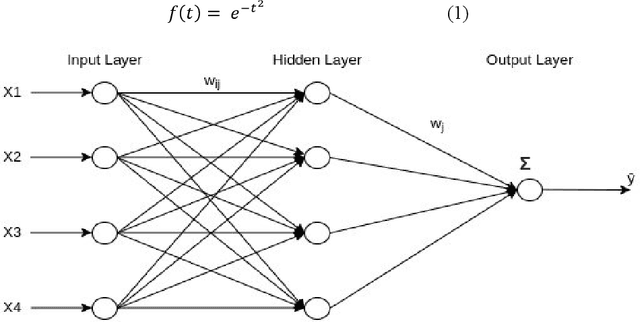
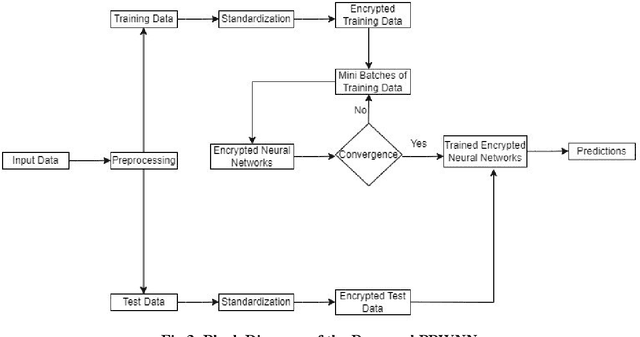

The main aim of Privacy-Preserving Machine Learning (PPML) is to protect the privacy and provide security to the data used in building Machine Learning models. There are various techniques in PPML such as Secure Multi-Party Computation, Differential Privacy, and Homomorphic Encryption (HE). The techniques are combined with various Machine Learning models and even Deep Learning Networks to protect the data privacy as well as the identity of the user. In this paper, we propose a fully homomorphic encrypted wavelet neural network to protect privacy and at the same time not compromise on the efficiency of the model. We tested the effectiveness of the proposed method on seven datasets taken from the finance and healthcare domains. The results show that our proposed model performs similarly to the unencrypted model.
Your Neighbors Are Communicating: Towards Powerful and Scalable Graph Neural Networks
Jun 04, 2022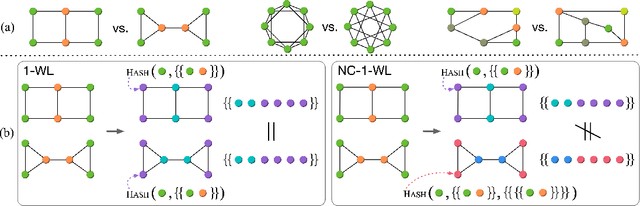
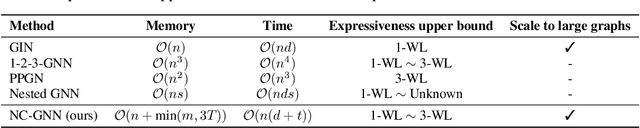


Message passing graph neural networks (GNNs) are known to have their expressiveness upper-bounded by 1-dimensional Weisfeiler-Lehman (1-WL) algorithm. To achieve more powerful GNNs, existing attempts either require ad hoc features, or involve operations that incur high time and space complexities. In this work, we propose a general and provably powerful GNN framework that preserves the scalability of message passing scheme. In particular, we first propose to empower 1-WL for graph isomorphism test by considering edges among neighbors, giving rise to NC-1-WL. The expressiveness of NC-1-WL is shown to be strictly above 1-WL but below 3-WL theoretically. Further, we propose the NC-GNN framework as a differentiable neural version of NC-1-WL. Our simple implementation of NC-GNN is provably as powerful as NC-1-WL. Experiments demonstrate that our NC-GNN achieves remarkable performance on various benchmarks.
Tight lower bounds for Dynamic Time Warping
Feb 14, 2021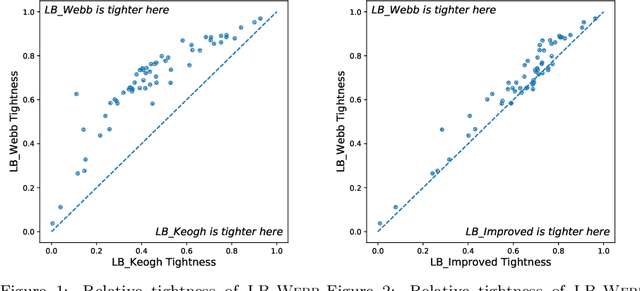
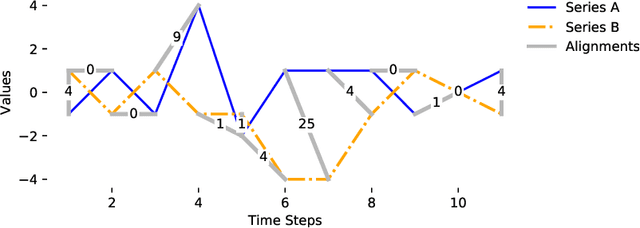
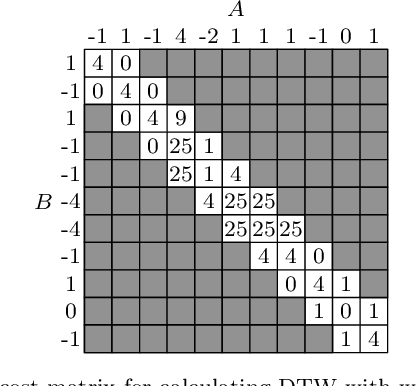
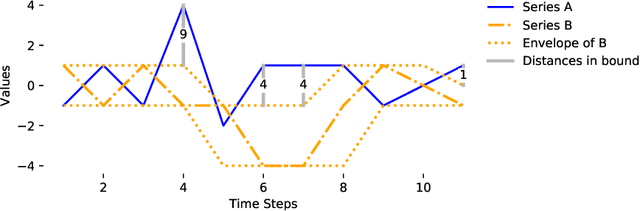
Dynamic Time Warping (DTW) is a popular similarity measure for aligning and comparing time series. Due to DTW's high computation time, lower bounds are often employed to screen poor matches. Many alternative lower bounds have been proposed, providing a range of different trade-offs between tightness and computational efficiency. LB Keogh provides a useful trade-off in many applications. Two recent lower bounds, LB Improved and LB Enhanced, are substantially tighter than LB Keogh. All three have the same worst case computational complexity - linear with respect to series length and constant with respect to window size. We present four new DTW lower bounds in the same complexity class. LB Petitjean is substantially tighter than LB Improved, with only modest additional computational overhead. LB Webb is more efficient than LB Improved, while often providing a tighter bound. LB Webb is always tighter than LB Keogh. The parameter free LB Webb is usually tighter than LB Enhanced. A parameterized variant, LB Webb Enhanced, is always tighter than LB Enhanced. A further variant, LB Webb*, is useful for some constrained distance functions. In extensive experiments, LB Webb proves to be very effective for nearest neighbor search.
Real-Time Face Recognition System for Remote Employee Tracking
Jul 15, 2021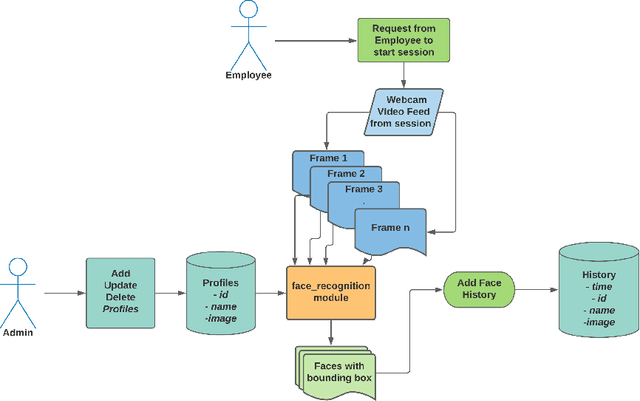
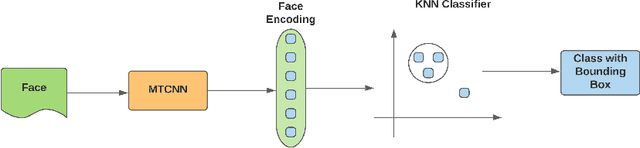
During the COVID-19 pandemic, most of the human-to-human interactions have been stopped. To mitigate the spread of deadly coronavirus, many offices took the initiative so that the employees can work from home. But, tracking the employees and finding out if they are really performing what they were supposed to turn out to be a serious challenge for all the companies and organizations who are facilitating "Work From Home". To deal with the challenge effectively, we came up with a solution to track the employees with face recognition. We have been testing this system experimentally for our office. To train the face recognition module, we used FaceNet with KNN using the Labeled Faces in the Wild (LFW) dataset and achieved 97.8% accuracy. We integrated the trained model into our central system, where the employees log their time. In this paper, we discuss in brief the system we have been experimenting with and the pros and cons of the system.
CNN Classifier for Just-in-Time Woodpeckers Detection and Deterrent
Jul 21, 2021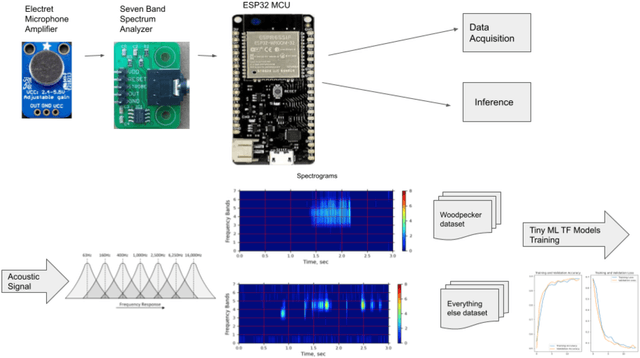
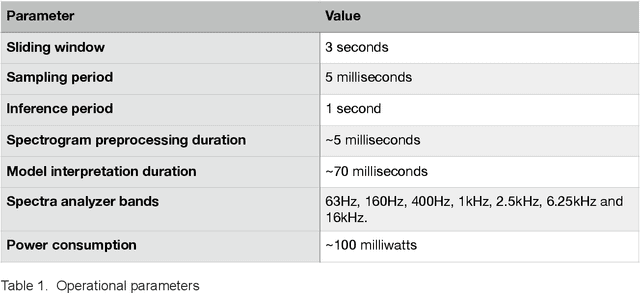
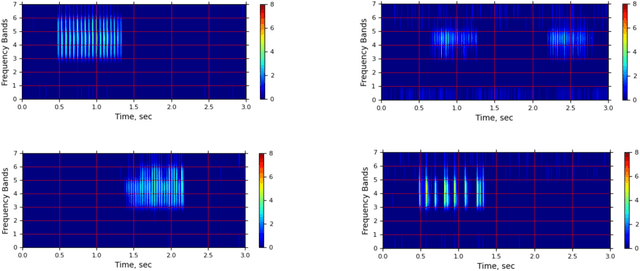
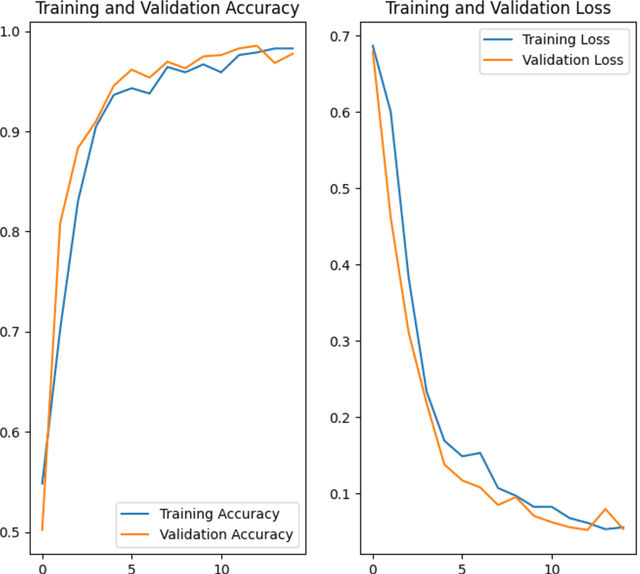
Woodpeckers can cause significant damage to homes, especially in suburban areas. There are a number of preventing and repelling methods including passive decoys, though these may only provide temporary relief. Subsequently, it may be more efficient to implement a woodpecker deterrent, such as motion, light, sound, or ultrasound that would be triggered by detection of woodpecker signature drumming. To detect the typical 25 Hz drumming frequency, sampling periods under 10 milliseconds with frequent FFTs are required with considerable computational costs. An in-hardware spectrum analyzer may avoid these costs by trading off frequency for time resolutions. The trained model converted to TF Lite Micro, ported to an MCU, and identifies a variety of the prerecorded woodpecker drumming. The plan is to integrate the prototype with a deterrent device making it a completely autonomous solution.
Learning who is in the market from time series: market participant discovery through adversarial calibration of multi-agent simulators
Aug 02, 2021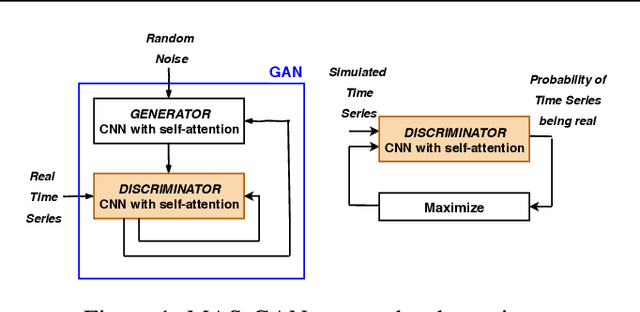
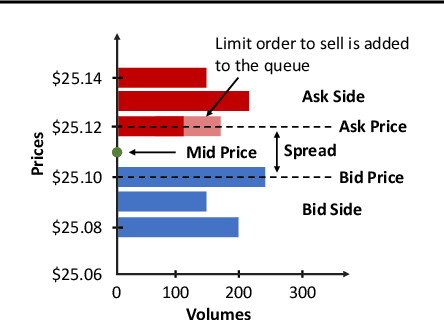
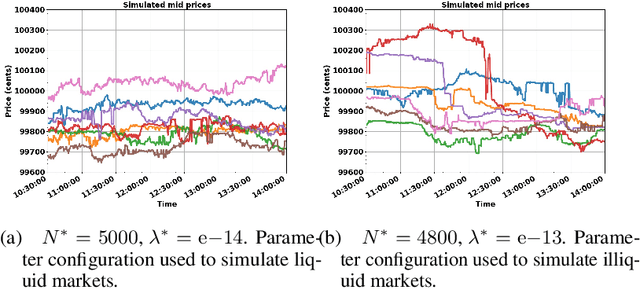
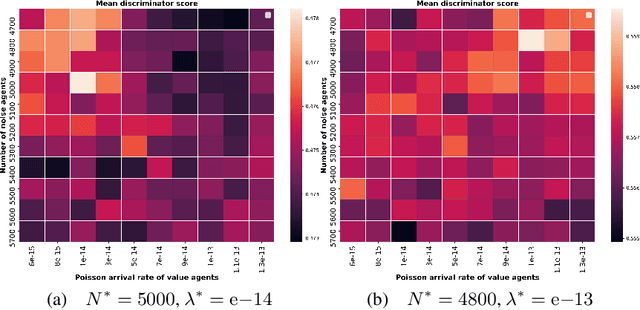
In electronic trading markets often only the price or volume time series, that result from interaction of multiple market participants, are directly observable. In order to test trading strategies before deploying them to real-time trading, multi-agent market environments calibrated so that the time series that result from interaction of simulated agents resemble historical are often used. To ensure adequate testing, one must test trading strategies in a variety of market scenarios -- which includes both scenarios that represent ordinary market days as well as stressed markets (most recently observed due to the beginning of COVID pandemic). In this paper, we address the problem of multi-agent simulator parameter calibration to allow simulator capture characteristics of different market regimes. We propose a novel two-step method to train a discriminator that is able to distinguish between "real" and "fake" price and volume time series as a part of GAN with self-attention, and then utilize it within an optimization framework to tune parameters of a simulator model with known agent archetypes to represent a market scenario. We conclude with experimental results that demonstrate effectiveness of our method.
Accelerating GMRES with Deep Learning in Real-Time
Mar 19, 2021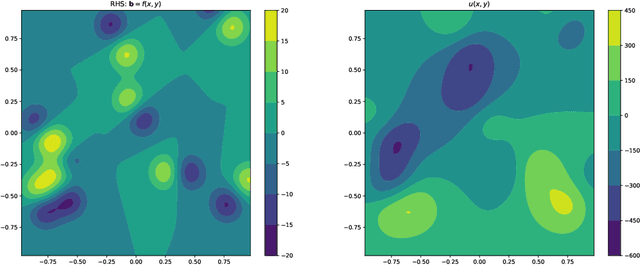
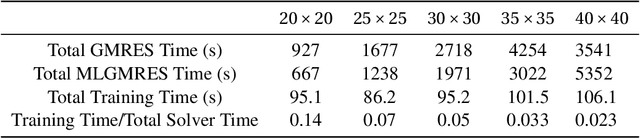
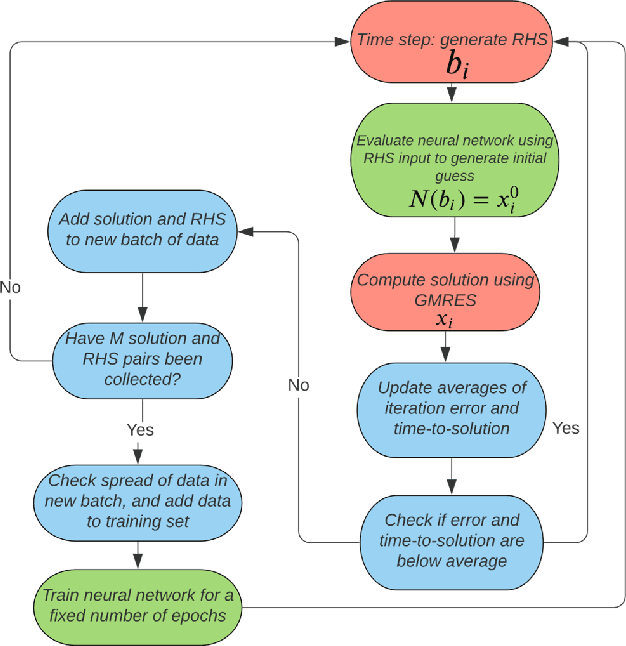
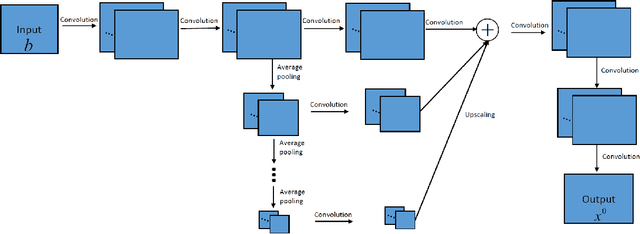
GMRES is a powerful numerical solver used to find solutions to extremely large systems of linear equations. These systems of equations appear in many applications in science and engineering. Here we demonstrate a real-time machine learning algorithm that can be used to accelerate the time-to-solution for GMRES. Our framework is novel in that is integrates the deep learning algorithm in an in situ fashion: the AI-accelerator gradually learns how to optimizes the time to solution without requiring user input (such as a pre-trained data set). We describe how our algorithm collects data and optimizes GMRES. We demonstrate our algorithm by implementing an accelerated (MLGMRES) solver in Python. We then use MLGMRES to accelerate a solver for the Poisson equation -- a class of linear problems that appears in may applications. Informed by the properties of formal solutions to the Poisson equation, we test the performance of different neural networks. Our key takeaway is that networks which are capable of learning non-local relationships perform well, without needing to be scaled with the input problem size, making them good candidates for the extremely large problems encountered in high-performance computing. For the inputs studied, our method provides a roughly 2$\times$ acceleration.
Bayesian Information Criterion for Event-based Multi-trial Ensemble data
Apr 29, 2022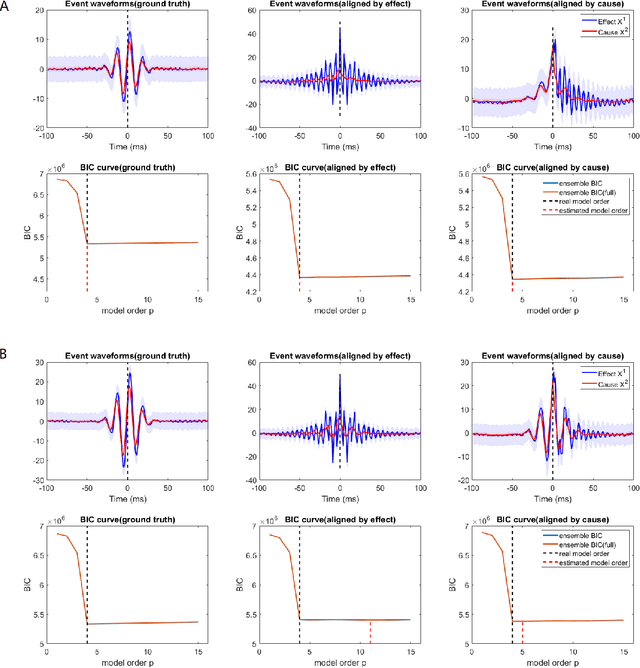
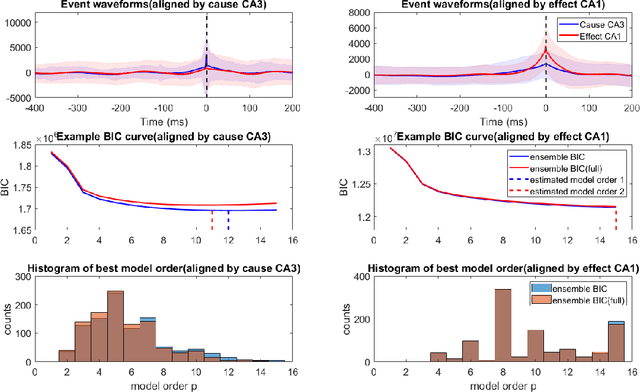
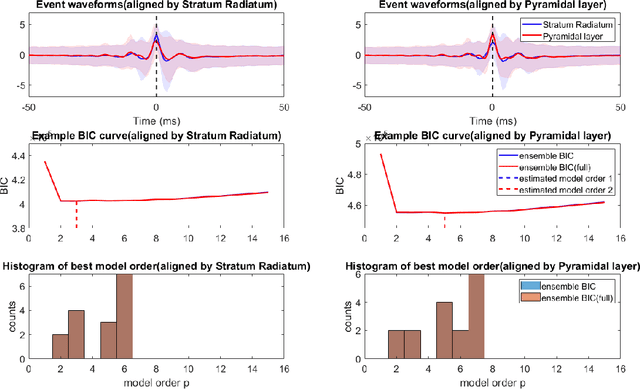
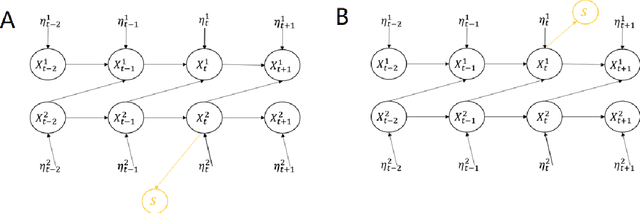
Transient recurring phenomena are ubiquitous in many scientific fields like neuroscience and meteorology. Time inhomogenous Vector Autoregressive Models (VAR) may be used to characterize peri-event system dynamics associated with such phenomena, and can be learned by exploiting multi-dimensional data gathering samples of the evolution of the system in multiple time windows comprising, each associated with one occurrence of the transient phenomenon, that we will call "trial". However, optimal VAR model order selection methods, commonly relying on the Akaike or Bayesian Information Criteria (AIC/BIC), are typically not designed for multi-trial data. Here we derive the BIC methods for multi-trial ensemble data which are gathered after the detection of the events. We show using simulated bivariate AR models that the multi-trial BIC is able to recover the real model order. We also demonstrate with simulated transient events and real data that the multi-trial BIC is able to estimate a sufficiently small model order for dynamic system modeling.
A real-time global re-localization framework for 3D LiDAR SLAM
Sep 01, 2021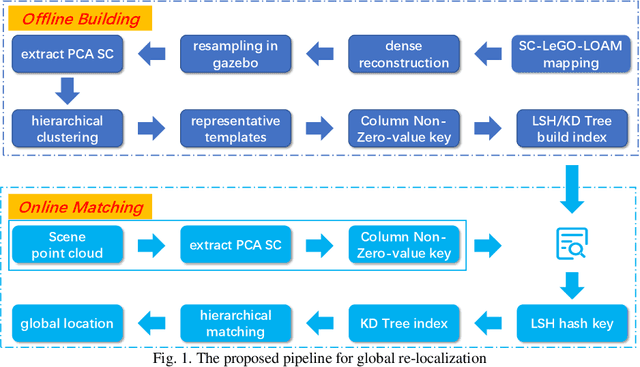


Simultaneous localization and mapping (SLAM) has been a hot research field in the past years. Against the backdrop of more affordable 3D LiDAR sensors, research on 3D LiDAR SLAM is becoming increasingly popular. Furthermore, the re-localization problem with a point cloud map is the foundation for other SLAM applications. In this paper, a template matching framework is proposed to re-localize a robot globally in a 3D LiDAR map. This presents two main challenges. First, most global descriptors for point cloud can only be used for place detection under a small local area. Therefore, in order to re-localize globally in the map, point clouds and descriptors(templates) are densely collected using a reconstructed mesh model at an offline stage by a physical simulation engine to expand the functional distance of point cloud descriptors. Second, the increased number of collected templates makes the matching stage too slow to meet the real-time requirement, for which a cascade matching method is presented for better efficiency. In the experiments, the proposed framework achieves 0.2-meter accuracy at about 10Hz matching speed using pure python implementation with 100k templates, which is effective and efficient for SLAM applications.