 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Best Arm Identification in Restless Markov Multi-Armed Bandits
Mar 29, 2022
We study the problem of identifying the best arm in a multi-armed bandit environment when each arm is a time-homogeneous and ergodic discrete-time Markov process on a common, finite state space. The state evolution on each arm is governed by the arm's transition probability matrix (TPM). A decision entity that knows the set of arm TPMs but not the exact mapping of the TPMs to the arms, wishes to find the index of the best arm as quickly as possible, subject to an upper bound on the error probability. The decision entity selects one arm at a time sequentially, and all the unselected arms continue to undergo state evolution ({\em restless} arms). For this problem, we derive the first-known problem instance-dependent asymptotic lower bound on the growth rate of the expected time required to find the index of the best arm, where the asymptotics is as the error probability vanishes. Further, we propose a sequential policy that, for an input parameter $R$, forcibly selects an arm that has not been selected for $R$ consecutive time instants. We show that this policy achieves an upper bound that depends on $R$ and is monotonically non-increasing as $R\to\infty$. The question of whether, in general, the limiting value of the upper bound as $R\to\infty$ matches with the lower bound, remains open. We identify a special case in which the upper and the lower bounds match. Prior works on best arm identification have dealt with (a) independent and identically distributed observations from the arms, and (b) rested Markov arms, whereas our work deals with the more difficult setting of restless Markov arms.
Automatic Autism Spectrum Disorder Detection Using Artificial Intelligence Methods with MRI Neuroimaging: A Review
Jun 20, 2022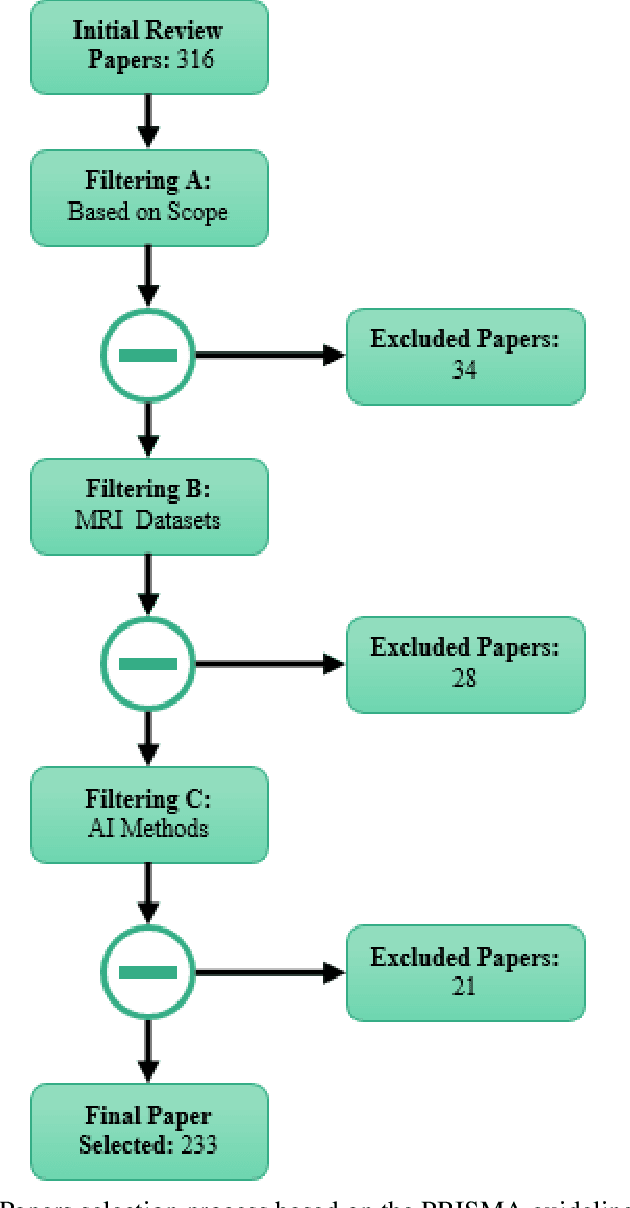

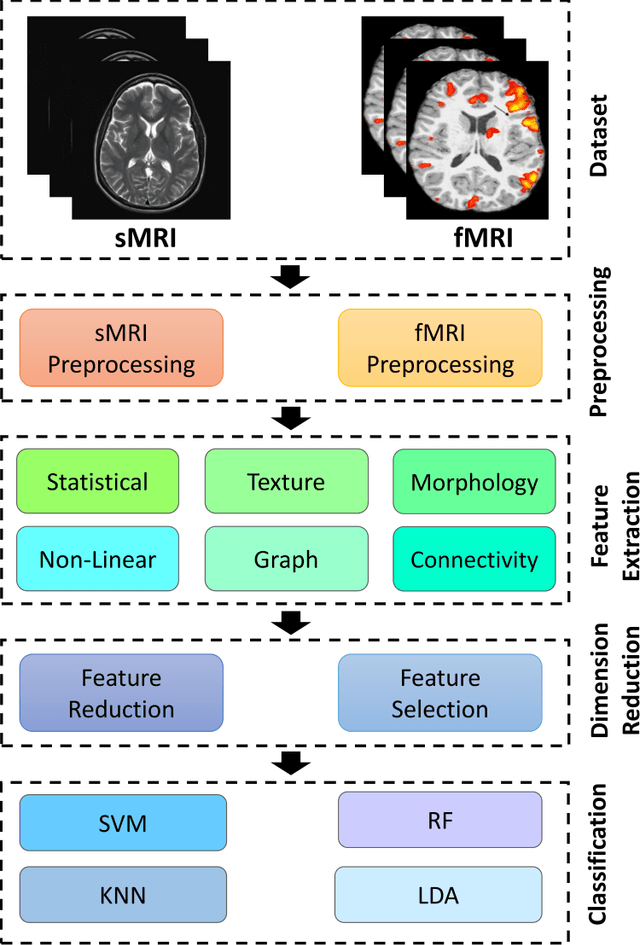
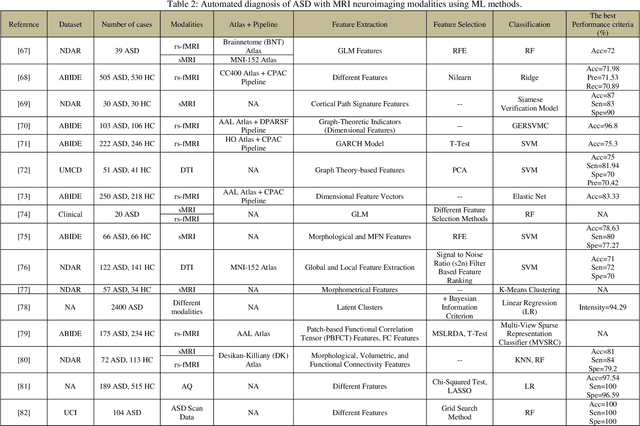
Autism spectrum disorder (ASD) is a brain condition characterized by diverse signs and symptoms that appear in early childhood. ASD is also associated with communication deficits and repetitive behavior in affected individuals. Various ASD detection methods have been developed, including neuroimaging modalities and psychological tests. Among these methods, magnetic resonance imaging (MRI) imaging modalities are of paramount importance to physicians. Clinicians rely on MRI modalities to diagnose ASD accurately. The MRI modalities are non-invasive methods that include functional (fMRI) and structural (sMRI) neuroimaging methods. However, the process of diagnosing ASD with fMRI and sMRI for specialists is often laborious and time-consuming; therefore, several computer-aided design systems (CADS) based on artificial intelligence (AI) have been developed to assist the specialist physicians. Conventional machine learning (ML) and deep learning (DL) are the most popular schemes of AI used for diagnosing ASD. This study aims to review the automated detection of ASD using AI. We review several CADS that have been developed using ML techniques for the automated diagnosis of ASD using MRI modalities. There has been very limited work on the use of DL techniques to develop automated diagnostic models for ASD. A summary of the studies developed using DL is provided in the appendix. Then, the challenges encountered during the automated diagnosis of ASD using MRI and AI techniques are described in detail. Additionally, a graphical comparison of studies using ML and DL to diagnose ASD automatically is discussed. We conclude by suggesting future approaches to detecting ASDs using AI techniques and MRI neuroimaging.
Deep Reinforcement Learning Based Semi-Autonomous Control for Robotic Surgery
Apr 11, 2022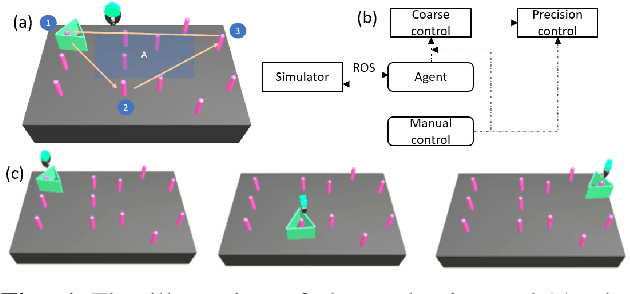
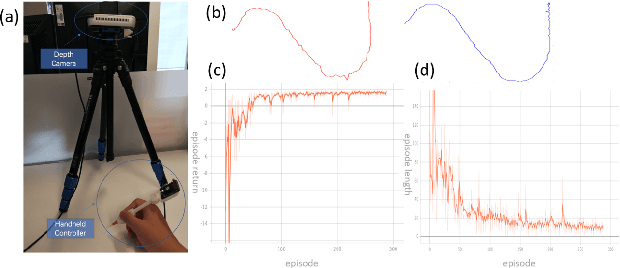

In recent decades, the tremendous benefits surgical robots have brought to surgeons and patients have been witnessed. With the dexterous operation and the great precision, surgical robots can offer patients less recovery time and less hospital stay. However, the controls for current surgical robots in practical usage are fully carried out by surgeons via teleoperation. During the surgery process, there exists a lot of repetitive but simple manipulation, which can cause unnecessary fatigue to the surgeons. In this paper, we proposed a deep reinforcement learning-based semi-autonomous control framework for robotic surgery. The user study showed that the framework can reduce the completion time by 19.1% and the travel length by 58.7%.
Dynamic Query Selection for Fast Visual Perceiver
May 22, 2022
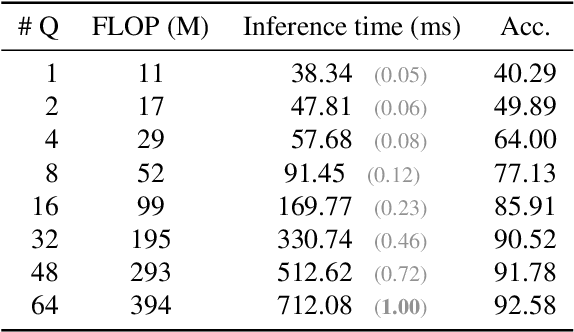
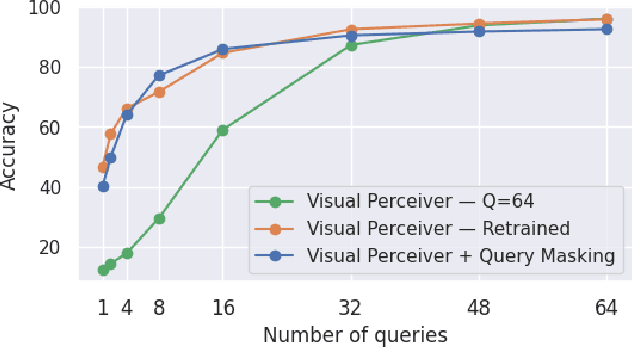
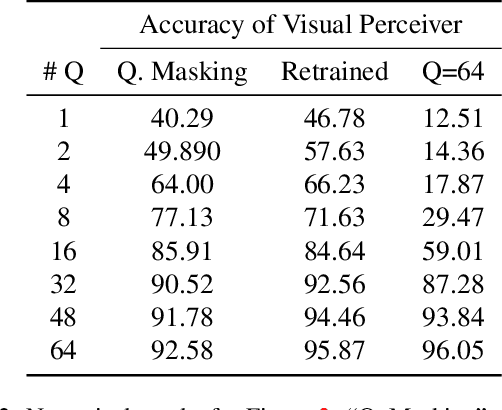
Transformers have been matching deep convolutional networks for vision architectures in recent works. Most work is focused on getting the best results on large-scale benchmarks, and scaling laws seem to be the most successful strategy: bigger models, more data, and longer training result in higher performance. However, the reduction of network complexity and inference time remains under-explored. The Perceiver model offers a solution to this problem: by first performing a Cross-attention with a fixed number Q of latent query tokens, the complexity of the L-layers Transformer network that follows is bounded by O(LQ^2). In this work, we explore how to make Perceivers even more efficient, by reducing the number of queries Q during inference while limiting the accuracy drop.
Extrinsic Calibration of Multiple Inertial Sensors from Arbitrary Trajectories
May 29, 2022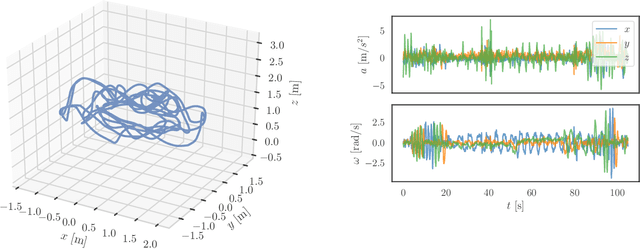
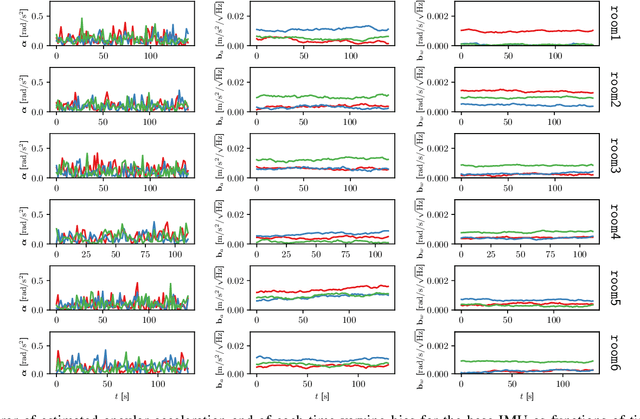


We present a method of extrinsic calibration for a system of multiple inertial measurement units (IMUs) that estimates the relative pose of each IMU on a rigid body using only measurements from the IMUs themselves, without the need to prescribe the trajectory. Our method is based on solving a nonlinear least-squares problem that penalizes inconsistency between measurements from pairs of IMUs. We validate our method with experiments both in simulation and in hardware. In particular, we show that it meets or exceeds the performance -- in terms of error, success rate, and computation time -- of an existing, state-of-the-art method that does not rely only on IMU measurements and instead requires the use of a camera and a fiducial marker. We also show that the performance of our method is largely insensitive to the choice of trajectory along which IMU measurements are collected.
* RA-L with ICRA 2022
GIT: A Generative Image-to-text Transformer for Vision and Language
May 31, 2022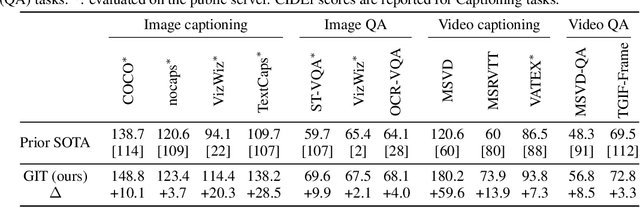

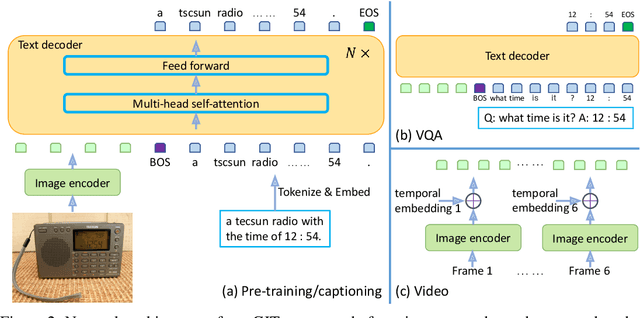
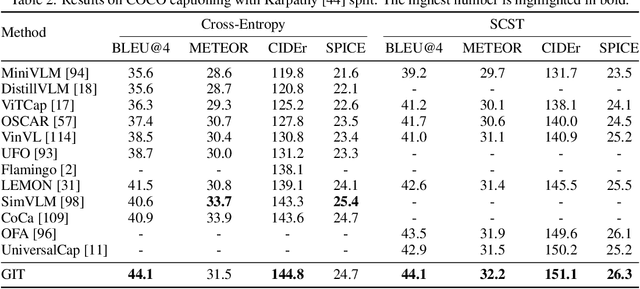
In this paper, we design and train a Generative Image-to-text Transformer, GIT, to unify vision-language tasks such as image/video captioning and question answering. While generative models provide a consistent network architecture between pre-training and fine-tuning, existing work typically contains complex structures (uni/multi-modal encoder/decoder) and depends on external modules such as object detectors/taggers and optical character recognition (OCR). In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. We also scale up the pre-training data and the model size to boost the model performance. Without bells and whistles, our GIT establishes new state of the arts on 12 challenging benchmarks with a large margin. For instance, our model surpasses the human performance for the first time on TextCaps (138.2 vs. 125.5 in CIDEr). Furthermore, we present a new scheme of generation-based image classification and scene text recognition, achieving decent performance on standard benchmarks.
Boosting the Confidence of Generalization for $L_2$-Stable Randomized Learning Algorithms
Jun 08, 2022Exponential generalization bounds with near-tight rates have recently been established for uniformly stable learning algorithms. The notion of uniform stability, however, is stringent in the sense that it is invariant to the data-generating distribution. Under the weaker and distribution dependent notions of stability such as hypothesis stability and $L_2$-stability, the literature suggests that only polynomial generalization bounds are possible in general cases. The present paper addresses this long standing tension between these two regimes of results and makes progress towards relaxing it inside a classic framework of confidence-boosting. To this end, we first establish an in-expectation first moment generalization error bound for potentially randomized learning algorithms with $L_2$-stability, based on which we then show that a properly designed subbagging process leads to near-tight exponential generalization bounds over the randomness of both data and algorithm. We further substantialize these generic results to stochastic gradient descent (SGD) to derive improved high-probability generalization bounds for convex or non-convex optimization problems with natural time decaying learning rates, which have not been possible to prove with the existing hypothesis stability or uniform stability based results.
Developing a Free and Open-source Automated Building Exterior Crack Inspection Software for Construction and Facility Managers
Jun 20, 2022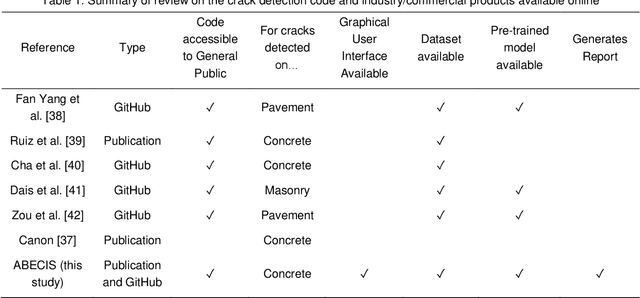
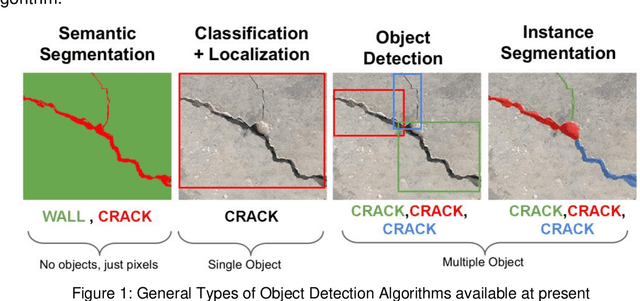

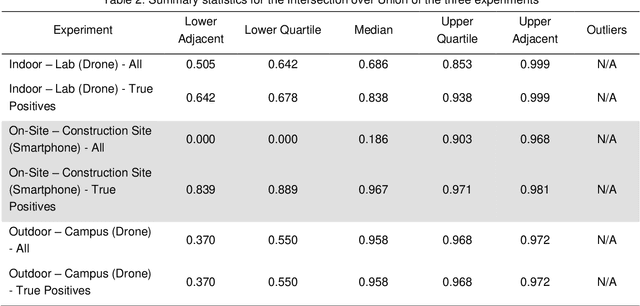
Inspection of cracks is an important process for properly monitoring and maintaining a building. However, manual crack inspection is time-consuming, inconsistent, and dangerous (e.g., in tall buildings). Due to the development of open-source AI technologies, the increase in available Unmanned Aerial Vehicles (UAVs) and the availability of smartphone cameras, it has become possible to automate the building crack inspection process. This study presents the development of an easy-to-use, free and open-source Automated Building Exterior Crack Inspection Software (ABECIS) for construction and facility managers, using state-of-the-art segmentation algorithms to identify concrete cracks and generate a quantitative and qualitative report. ABECIS was tested using images collected from a UAV and smartphone cameras in real-world conditions and a controlled laboratory environment. From the raw output of the algorithm, the median Intersection over Unions for the test experiments is (1) 0.686 for indoor crack detection experiment in a controlled lab environment using a commercial drone, (2) 0.186 for indoor crack detection at a construction site using a smartphone and (3) 0.958 for outdoor crack detection on university campus using a commercial drone. These IoU results can be improved significantly to over 0.8 when a human operator selectively removes the false positives. In general, ABECIS performs best for outdoor drone images, and combining the algorithm predictions with human verification/intervention offers very accurate crack detection results. The software is available publicly and can be downloaded for out-of-the-box use at: https://github.com/SMART-NYUAD/ABECIS
Deep learning based closed-loop optimization of geothermal reservoir production
Apr 15, 2022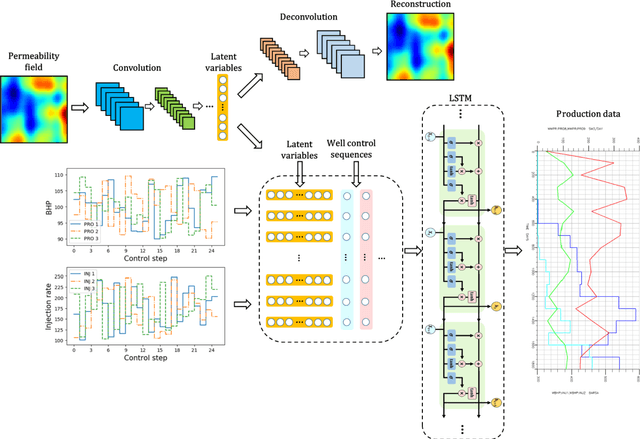
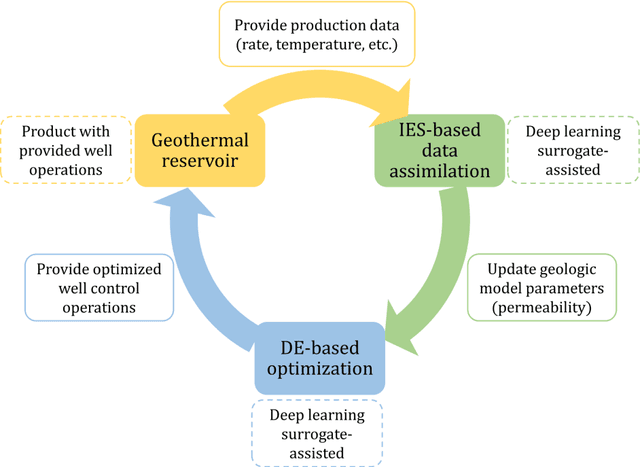
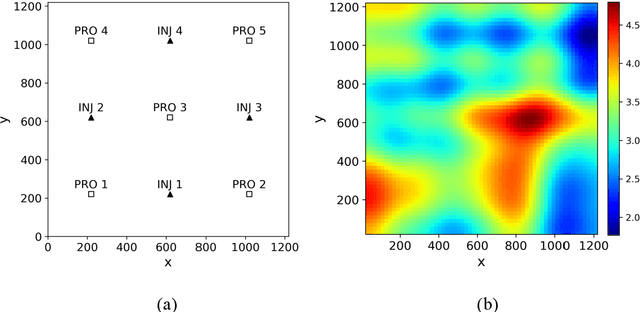
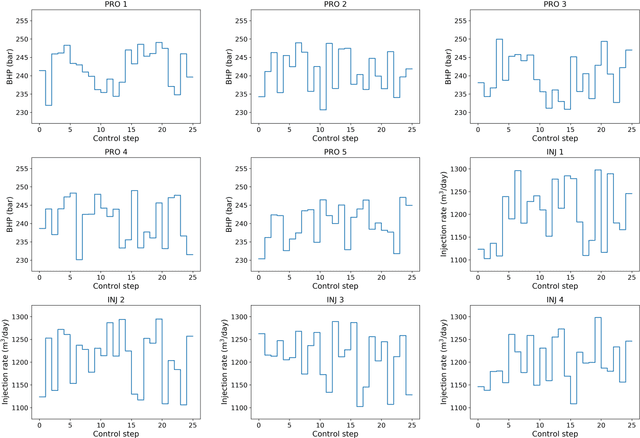
To maximize the economic benefits of geothermal energy production, it is essential to optimize geothermal reservoir management strategies, in which geologic uncertainty should be considered. In this work, we propose a closed-loop optimization framework, based on deep learning surrogates, for the well control optimization of geothermal reservoirs. In this framework, we construct a hybrid convolution-recurrent neural network surrogate, which combines the convolution neural network (CNN) and long short-term memory (LSTM) recurrent network. The convolution structure can extract spatial information of geologic parameter fields and the recurrent structure can approximate sequence-to-sequence mapping. The trained model can predict time-varying production responses (rate, temperature, etc.) for cases with different permeability fields and well control sequences. In the closed-loop optimization framework, production optimization based on the differential evolution (DE) algorithm, and data assimilation based on the iterative ensemble smoother (IES), are performed alternately to achieve real-time well control optimization and geologic parameter estimation as the production proceeds. In addition, the averaged objective function over the ensemble of geologic parameter estimations is adopted to consider geologic uncertainty in the optimization process. Several geothermal reservoir development cases are designed to test the performance of the proposed production optimization framework. The results show that the proposed framework can achieve efficient and effective real-time optimization and data assimilation in the geothermal reservoir production process.
Who Goes First? Influences of Human-AI Workflow on Decision Making in Clinical Imaging
May 19, 2022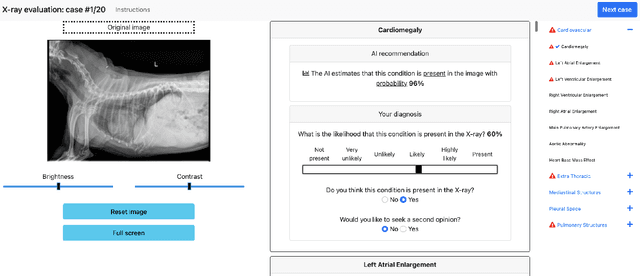
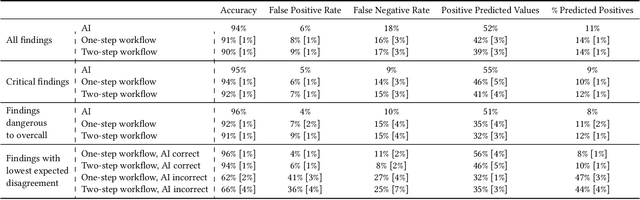
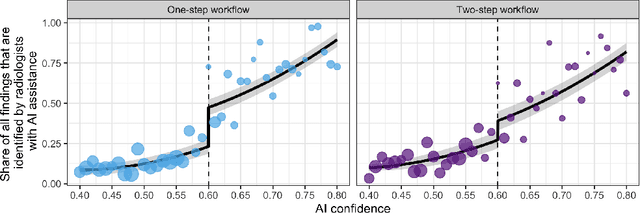

Details of the designs and mechanisms in support of human-AI collaboration must be considered in the real-world fielding of AI technologies. A critical aspect of interaction design for AI-assisted human decision making are policies about the display and sequencing of AI inferences within larger decision-making workflows. We have a poor understanding of the influences of making AI inferences available before versus after human review of a diagnostic task at hand. We explore the effects of providing AI assistance at the start of a diagnostic session in radiology versus after the radiologist has made a provisional decision. We conducted a user study where 19 veterinary radiologists identified radiographic findings present in patients' X-ray images, with the aid of an AI tool. We employed two workflow configurations to analyze (i) anchoring effects, (ii) human-AI team diagnostic performance and agreement, (iii) time spent and confidence in decision making, and (iv) perceived usefulness of the AI. We found that participants who are asked to register provisional responses in advance of reviewing AI inferences are less likely to agree with the AI regardless of whether the advice is accurate and, in instances of disagreement with the AI, are less likely to seek the second opinion of a colleague. These participants also reported the AI advice to be less useful. Surprisingly, requiring provisional decisions on cases in advance of the display of AI inferences did not lengthen the time participants spent on the task. The study provides generalizable and actionable insights for the deployment of clinical AI tools in human-in-the-loop systems and introduces a methodology for studying alternative designs for human-AI collaboration. We make our experimental platform available as open source to facilitate future research on the influence of alternate designs on human-AI workflows.