 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Streamable Neural Audio Synthesis With Non-Causal Convolutions
Apr 14, 2022
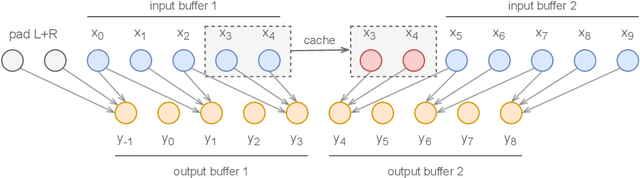
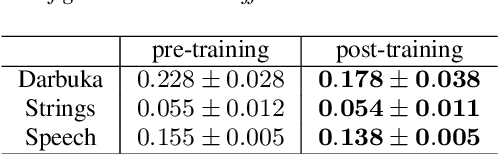
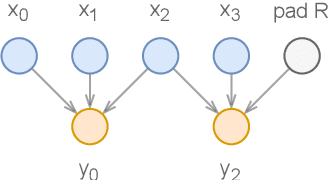
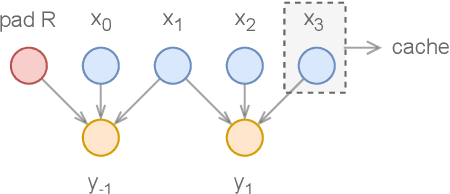
Deep learning models are mostly used in an offline inference fashion. However, this strongly limits the use of these models inside audio generation setups, as most creative workflows are based on real-time digital signal processing. Although approaches based on recurrent networks can be naturally adapted to this buffer-based computation, the use of convolutions still poses some serious challenges. To tackle this issue, the use of causal streaming convolutions have been proposed. However, this requires specific complexified training and can impact the resulting audio quality. In this paper, we introduce a new method allowing to produce non-causal streaming models. This allows to make any convolutional model compatible with real-time buffer-based processing. As our method is based on a post-training reconfiguration of the model, we show that it is able to transform models trained without causal constraints into a streaming model. We show how our method can be adapted to fit complex architectures with parallel branches. To evaluate our method, we apply it on the recent RAVE model, which provides high-quality real-time audio synthesis. We test our approach on multiple music and speech datasets and show that it is faster than overlap-add methods, while having no impact on the generation quality. Finally, we introduce two open-source implementation of our work as Max/MSP and PureData externals, and as a VST audio plugin. This allows to endow traditional digital audio workstation with real-time neural audio synthesis on a laptop CPU.
Feature Re-calibration based MIL for Whole Slide Image Classification
Jun 22, 2022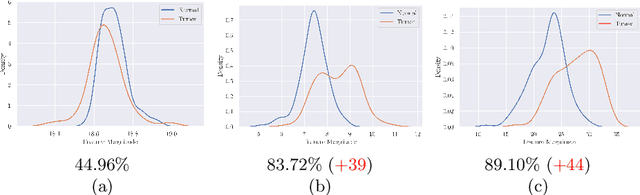
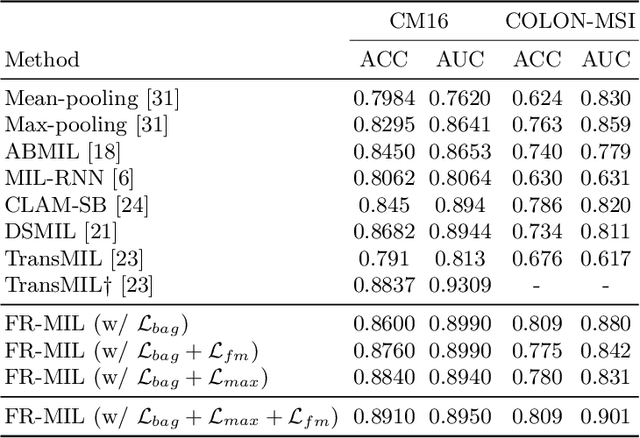
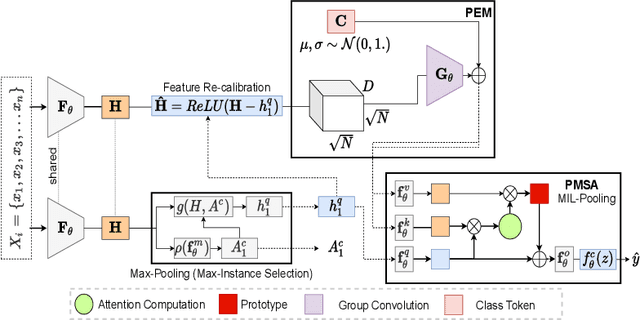
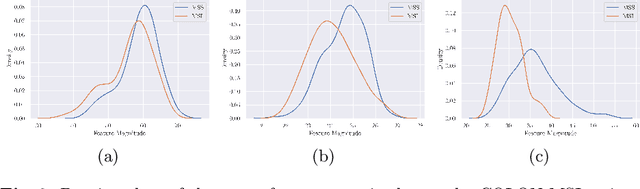
Whole slide image (WSI) classification is a fundamental task for the diagnosis and treatment of diseases; but, curation of accurate labels is time-consuming and limits the application of fully-supervised methods. To address this, multiple instance learning (MIL) is a popular method that poses classification as a weakly supervised learning task with slide-level labels only. While current MIL methods apply variants of the attention mechanism to re-weight instance features with stronger models, scant attention is paid to the properties of the data distribution. In this work, we propose to re-calibrate the distribution of a WSI bag (instances) by using the statistics of the max-instance (critical) feature. We assume that in binary MIL, positive bags have larger feature magnitudes than negatives, thus we can enforce the model to maximize the discrepancy between bags with a metric feature loss that models positive bags as out-of-distribution. To achieve this, unlike existing MIL methods that use single-batch training modes, we propose balanced-batch sampling to effectively use the feature loss i.e., (+/-) bags simultaneously. Further, we employ a position encoding module (PEM) to model spatial/morphological information, and perform pooling by multi-head self-attention (PSMA) with a Transformer encoder. Experimental results on existing benchmark datasets show our approach is effective and improves over state-of-the-art MIL methods.
Tight lower bounds for Dynamic Time Warping
Feb 16, 2021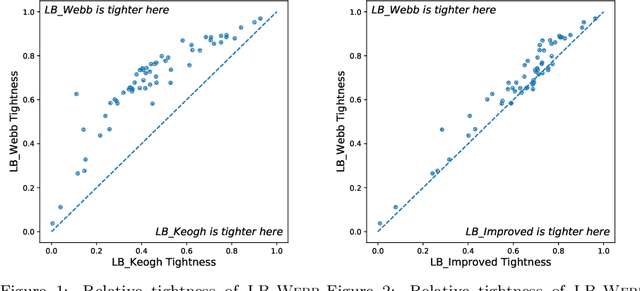
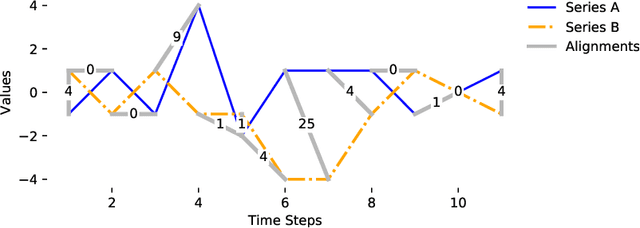
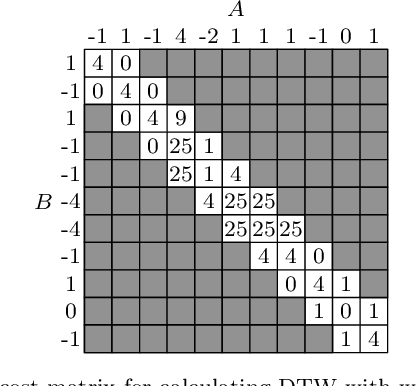
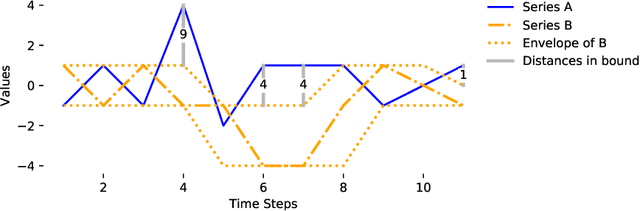
Dynamic Time Warping (DTW) is a popular similarity measure for aligning and comparing time series. Due to DTW's high computation time, lower bounds are often employed to screen poor matches. Many alternative lower bounds have been proposed, providing a range of different trade-offs between tightness and computational efficiency. LB Keogh provides a useful trade-off in many applications. Two recent lower bounds, LB Improved and LB Enhanced, are substantially tighter than LB Keogh. All three have the same worst case computational complexity - linear with respect to series length and constant with respect to window size. We present four new DTW lower bounds in the same complexity class. LB Petitjean is substantially tighter than LB Improved, with only modest additional computational overhead. LB Webb is more efficient than LB Improved, while often providing a tighter bound. LB Webb is always tighter than LB Keogh. The parameter free LB Webb is usually tighter than LB Enhanced. A parameterized variant, LB Webb Enhanced, is always tighter than LB Enhanced. A further variant, LB Webb*, is useful for some constrained distance functions. In extensive experiments, LB Webb proves to be very effective for nearest neighbor search.
Materials Transformers Language Models for Generative Materials Design: a benchmark study
Jun 27, 2022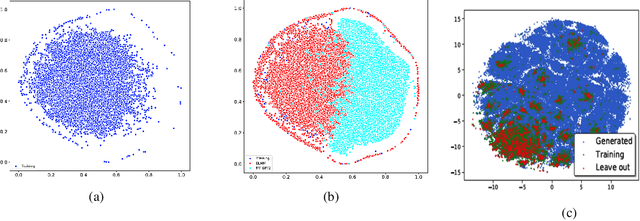
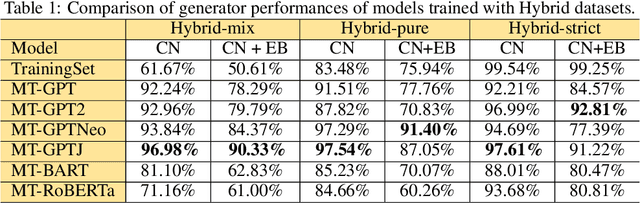
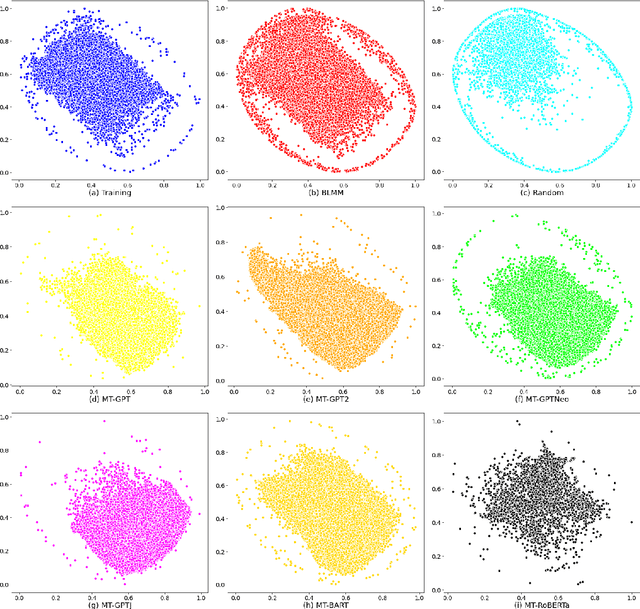
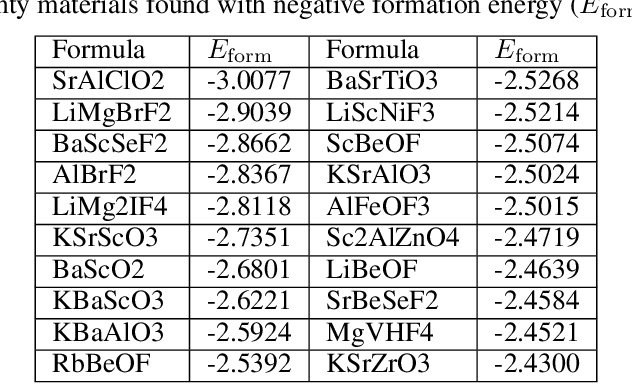
Pre-trained transformer language models on large unlabeled corpus have produced state-of-the-art results in natural language processing, organic molecule design, and protein sequence generation. However, no such models have been applied to learn the composition patterns of inorganic materials. Here we train a series of seven modern transformer language models (GPT, GPT-2, GPT-Neo, GPT-J, BLMM, BART, and RoBERTa) using the expanded formulas from material deposited in the ICSD, OQMD, and Materials Projects databases. Six different datasets with/out non-charge-neutral or balanced electronegativity samples are used to benchmark the performances and uncover the generation biases of modern transformer models for the generative design of materials compositions. Our extensive experiments showed that the causal language models based materials transformers can generate chemically valid materials compositions with as high as 97.54\% to be charge neutral and 91.40\% to be electronegativity balanced, which has more than 6 times higher enrichment compared to a baseline pseudo-random sampling algorithm. These models also demonstrate high novelty and their potential in new materials discovery has been proved by their capability to recover the leave-out materials. We also find that the properties of the generated samples can be tailored by training the models with selected training sets such as high-bandgap materials. Our experiments also showed that different models each have their own preference in terms of the properties of the generated samples and their running time complexity varies a lot. We have applied our materials transformer models to discover a set of new materials as validated using DFT calculations.
Learning to Drive Using Sparse Imitation Reinforcement Learning
May 24, 2022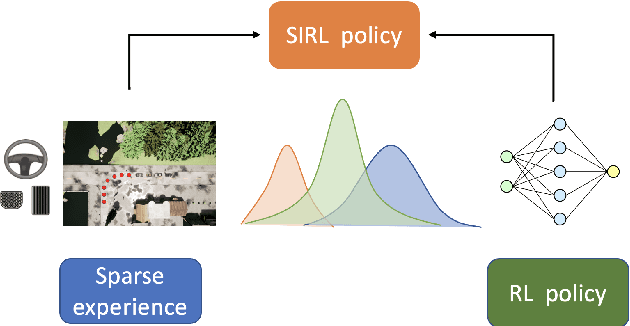

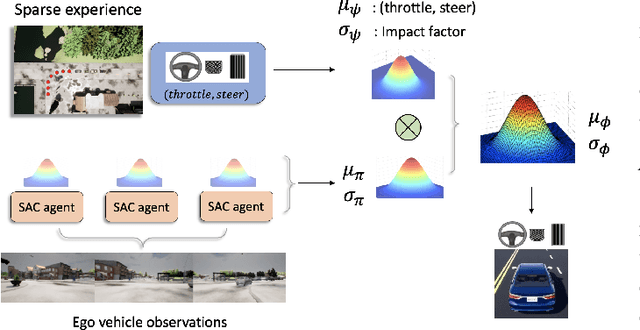
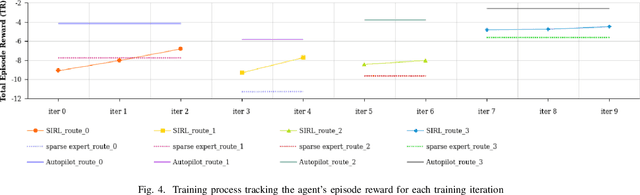
In this paper, we propose Sparse Imitation Reinforcement Learning (SIRL), a hybrid end-to-end control policy that combines the sparse expert driving knowledge with reinforcement learning (RL) policy for autonomous driving (AD) task in CARLA simulation environment. The sparse expert is designed based on hand-crafted rules which is suboptimal but provides a risk-averse strategy by enforcing experience for critical scenarios such as pedestrian and vehicle avoidance, and traffic light detection. As it has been demonstrated, training a RL agent from scratch is data-inefficient and time consuming particularly for the urban driving task, due to the complexity of situations stemming from the vast size of state space. Our SIRL strategy provides a solution to solve these problems by fusing the output distribution of the sparse expert policy and the RL policy to generate a composite driving policy. With the guidance of the sparse expert during the early training stage, SIRL strategy accelerates the training process and keeps the RL exploration from causing a catastrophe outcome, and ensures safe exploration. To some extent, the SIRL agent is imitating the driving expert's behavior. At the same time, it continuously gains knowledge during training therefore it keeps making improvement beyond the sparse expert, and can surpass both the sparse expert and a traditional RL agent. We experimentally validate the efficacy of proposed SIRL approach in a complex urban scenario within the CARLA simulator. Besides, we compare the SIRL agent's performance for risk-averse exploration and high learning efficiency with the traditional RL approach. We additionally demonstrate the SIRL agent's generalization ability to transfer the driving skill to unseen environment.
Wave-based extreme deep learning based on non-linear time-Floquet entanglement
Jul 19, 2021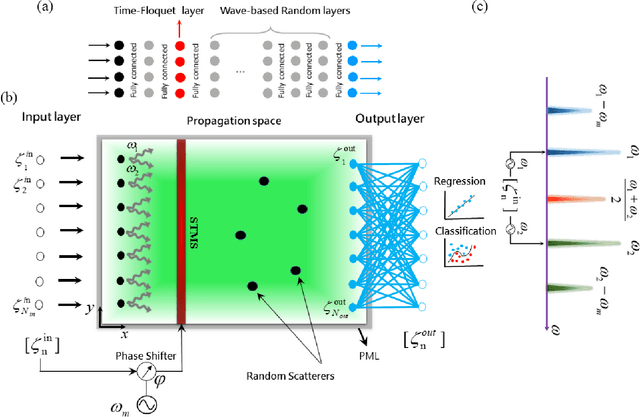
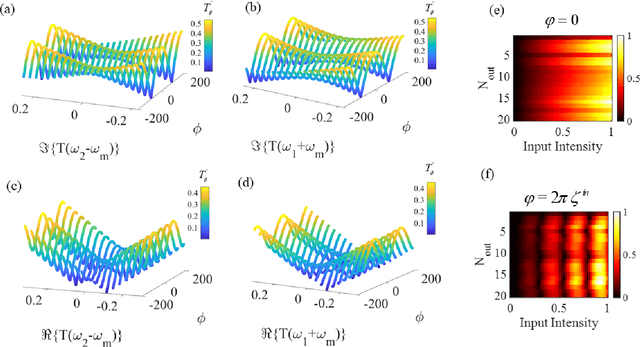
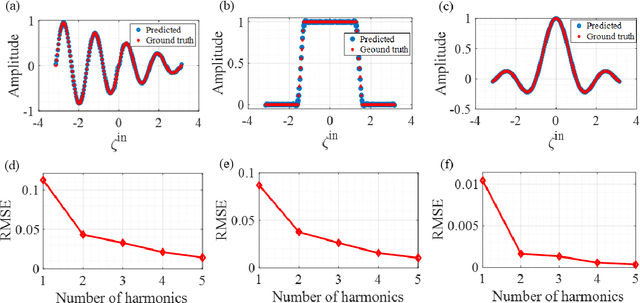
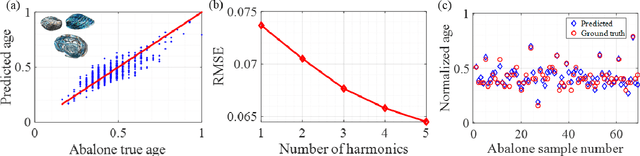
Wave-based analog signal processing holds the promise of extremely fast, on-the-fly, power-efficient data processing, occurring as a wave propagates through an artificially engineered medium. Yet, due to the fundamentally weak non-linearities of traditional wave materials, such analog processors have been so far largely confined to simple linear projections such as image edge detection or matrix multiplications. Complex neuromorphic computing tasks, which inherently require strong non-linearities, have so far remained out-of-reach of wave-based solutions, with a few attempts that implemented non-linearities on the digital front, or used weak and inflexible non-linear sensors, restraining the learning performance. Here, we tackle this issue by demonstrating the relevance of Time-Floquet physics to induce a strong non-linear entanglement between signal inputs at different frequencies, enabling a power-efficient and versatile wave platform for analog extreme deep learning involving a single, uniformly modulated dielectric layer and a scattering medium. We prove the efficiency of the method for extreme learning machines and reservoir computing to solve a range of challenging learning tasks, from forecasting chaotic time series to the simultaneous classification of distinct datasets. Our results open the way for wave-based machine learning with high energy efficiency, speed, and scalability.
End-to-End Topology-Aware Machine Learning for Power System Reliability Assessment
May 30, 2022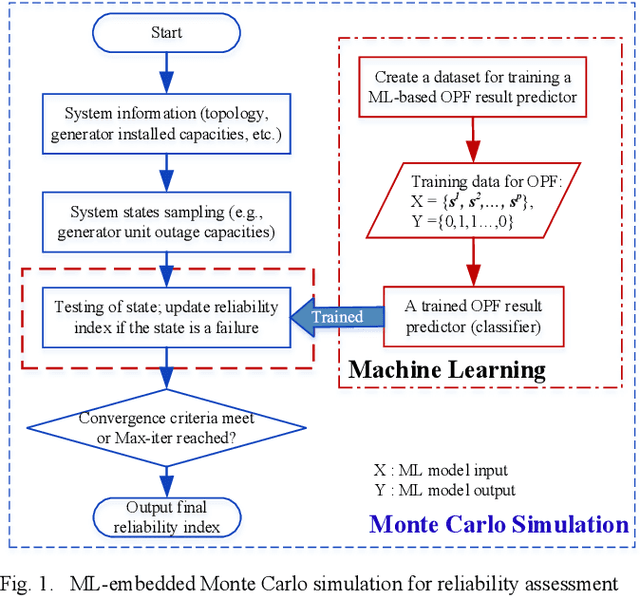
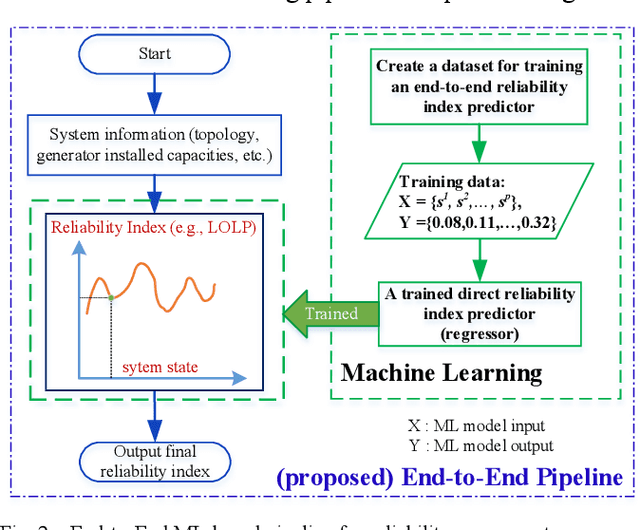
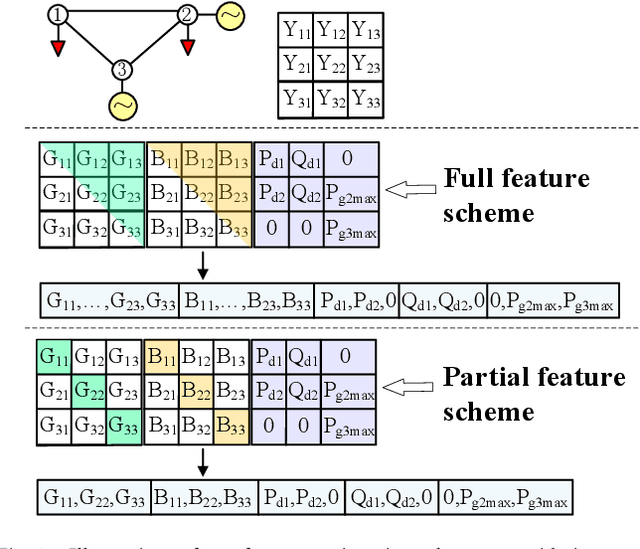
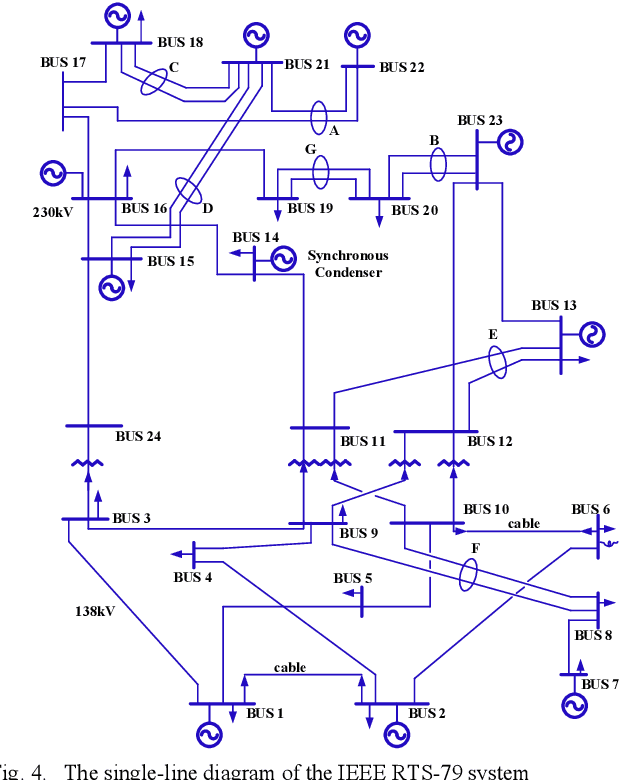
Conventional power system reliability suffers from the long run time of Monte Carlo simulation and the dimension-curse of analytic enumeration methods. This paper proposes a preliminary investigation on end-to-end machine learning for directly predicting the reliability index, e.g., the Loss of Load Probability (LOLP). By encoding the system admittance matrix into the input feature, the proposed machine learning pipeline can consider the impact of specific topology changes due to regular maintenances of transmission lines. Two models (Support Vector Machine and Boosting Trees) are trained and compared. Details regarding the training data creation and preprocessing are also discussed. Finally, experiments are conducted on the IEEE RTS-79 system. Results demonstrate the applicability of the proposed end-to-end machine learning pipeline in reliability assessment.
Achieving Multi-beam Gain in Intelligent Reflecting Surface Assisted Wireless Energy Transfer
May 18, 2022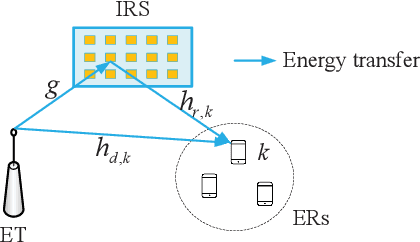


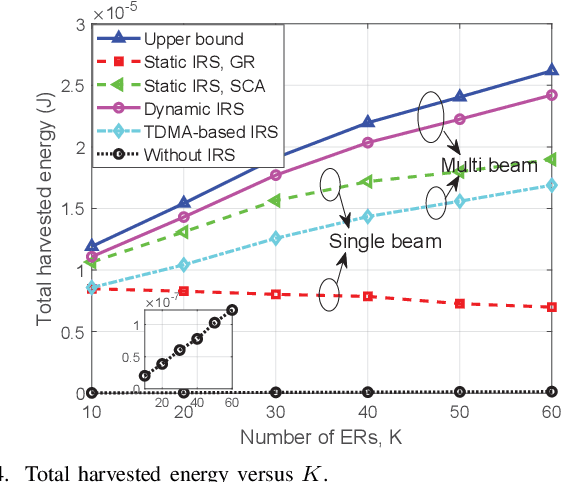
Intelligent reflecting surface (IRS) is a promising technology to boost the efficiency of wireless energy transfer (WET) systems. However, for a multiuser WET system, simultaneous multi-beam energy transmission is generally required to achieve the maximum performance, which may not be implemented by using the IRS having only a single set of coefficients. As a result, it remains unknowns how to exploit the IRS to approach such a performance upper bound. To answer this question, we aim to maximize the total harvested energy of a multiuser WET system subject to the user fairness constraints and the non-linear energy harvesting model. We first consider the static IRS beamforming scheme, which shows that the optimal IRS reflection matrix obtained by applying semidefinite relaxation is indeed of high rank in general as the number of energy receivers (ERs) increases, due to which the resulting rank-one solution by applying Gaussian Randomization may lead to significant loss. To achieve the multi-beam gain, we then propose a general time-division based novel framework by exploiting the IRS's dynamic passive beamforming. Moreover, it is able to achieve a good balance between the system performance and complexity by controlling the number of IRS shift patterns. Finally, we also propose a time-division multiple access (TDMA) based passive beamforming design for performance comparison. Simulation results demonstrate the necessity of multi-beam transmission and the superiority of the proposed dynamic IRS beamforming scheme over existing schemes.
SpecGrad: Diffusion Probabilistic Model based Neural Vocoder with Adaptive Noise Spectral Shaping
Mar 31, 2022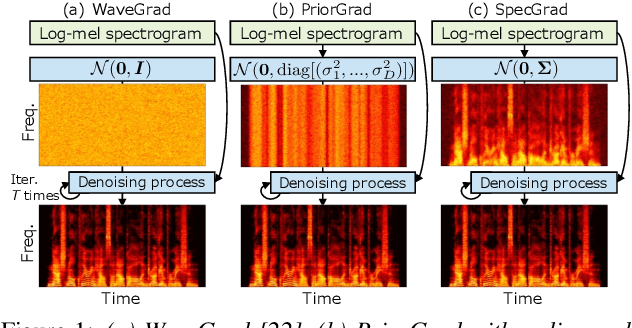
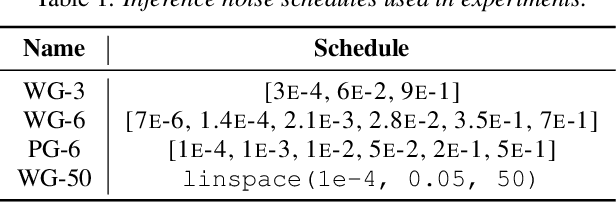
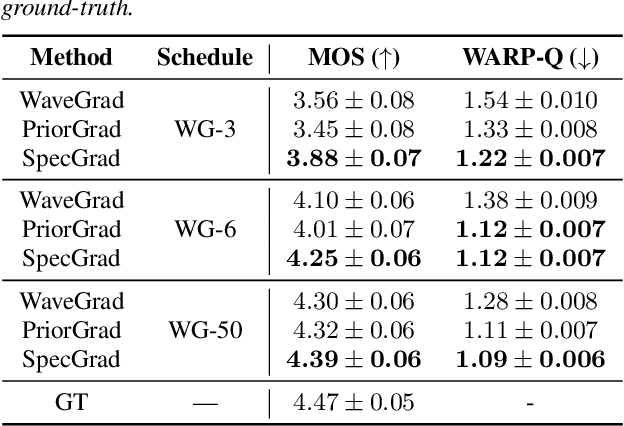
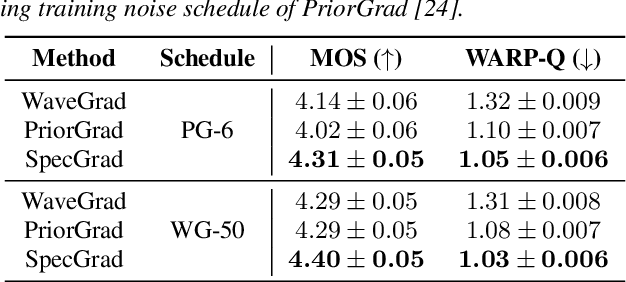
Neural vocoder using denoising diffusion probabilistic model (DDPM) has been improved by adaptation of the diffusion noise distribution to given acoustic features. In this study, we propose SpecGrad that adapts the diffusion noise so that its time-varying spectral envelope becomes close to the conditioning log-mel spectrogram. This adaptation by time-varying filtering improves the sound quality especially in the high-frequency bands. It is processed in the time-frequency domain to keep the computational cost almost the same as the conventional DDPM-based neural vocoders. Experimental results showed that SpecGrad generates higher-fidelity speech waveform than conventional DDPM-based neural vocoders in both analysis-synthesis and speech enhancement scenarios. Audio demos are available at wavegrad.github.io/specgrad/.
Towards Safe, Real-Time Systems: Stereo vs Images and LiDAR for 3D Object Detection
Feb 25, 2022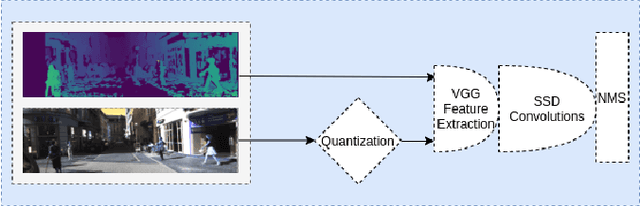

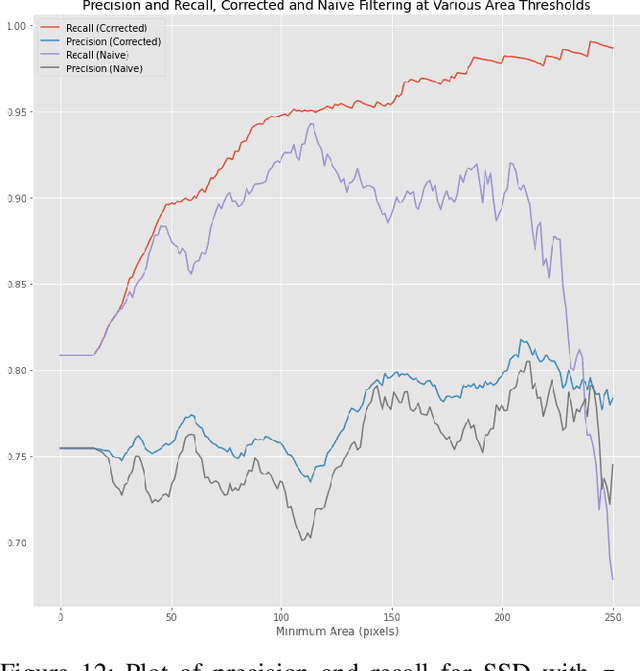
As object detectors rapidly improve, attention has expanded past image-only networks to include a range of 3D and multimodal frameworks, especially ones that incorporate LiDAR. However, due to cost, logistics, and even some safety considerations, stereo can be an appealing alternative. Towards understanding the efficacy of stereo as a replacement for monocular input or LiDAR in object detectors, we show that multimodal learning with traditional disparity algorithms can improve image-based results without increasing the number of parameters, and that learning over stereo error can impart similar 3D localization power to LiDAR in certain contexts. Furthermore, doing so also has calibration benefits with respect to image-only methods. We benchmark on the public dataset KITTI, and in doing so, reveal a few small but common algorithmic mistakes currently used in computing metrics on that set, and offer efficient, provably correct alternatives.