 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Amortized backward variational inference in nonlinear state-space models
Jun 01, 2022
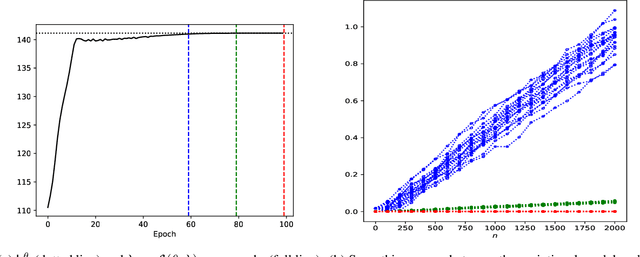

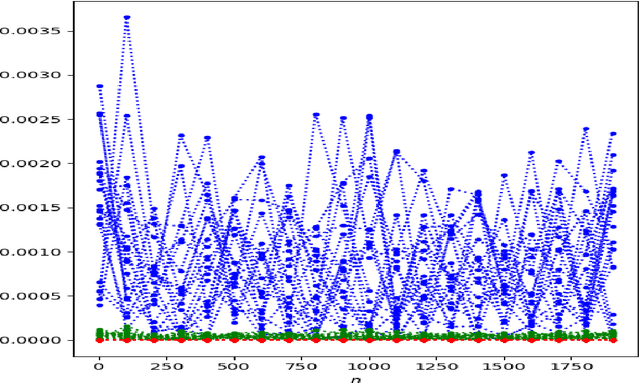
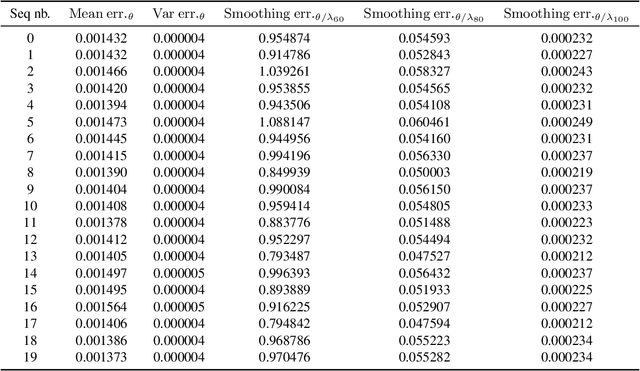
We consider the problem of state estimation in general state-space models using variational inference. For a generic variational family defined using the same backward decomposition as the actual joint smoothing distribution, we establish for the first time that, under mixing assumptions, the variational approximation of expectations of additive state functionals induces an error which grows at most linearly in the number of observations. This guarantee is consistent with the known upper bounds for the approximation of smoothing distributions using standard Monte Carlo methods. Moreover, we propose an amortized inference framework where a neural network shared over all times steps outputs the parameters of the variational kernels. We also study empirically parametrizations which allow analytical marginalization of the variational distributions, and therefore lead to efficient smoothing algorithms. Significant improvements are made over state-of-the art variational solutions, especially when the generative model depends on a strongly nonlinear and noninjective mixing function.
Robust SAR ATR on MSTAR with Deep Learning Models trained on Full Synthetic MOCEM data
Jun 15, 2022
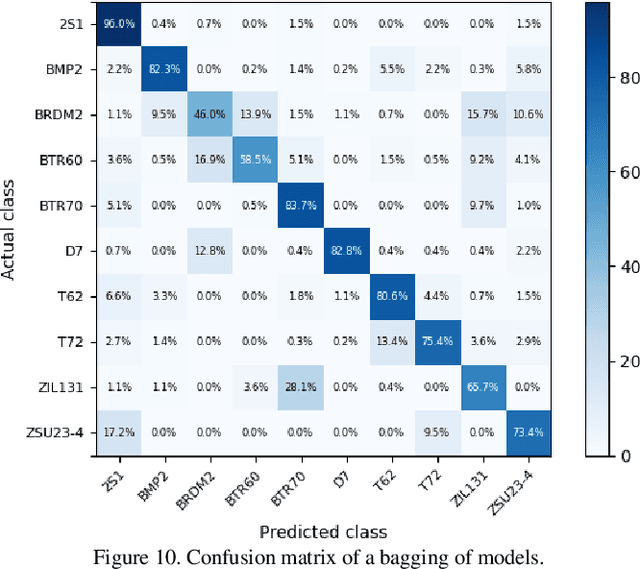

The promising potential of Deep Learning for Automatic Target Recognition (ATR) on Synthetic Aperture Radar (SAR) images vanishes when considering the complexity of collecting training datasets measurements. Simulation can overcome this issue by producing synthetic training datasets. However, because of the limited representativeness of simulation, models trained in a classical way with synthetic images have limited generalization abilities when dealing with real measurement at test time. Previous works identified a set of equally promising deep-learning algorithms to tackle this issue. However, these approaches have been evaluated in a very favorable scenario with a synthetic training dataset that overfits the ground truth of the measured test data. In this work, we study the ATR problem outside of this ideal condition, which is unlikely to occur in real operational contexts. Our contribution is threefold. (1) Using the MOCEM simulator (developed by SCALIAN DS for the French MoD/DGA), we produce a synthetic MSTAR training dataset that differs significantly from the real measurements. (2) We experimentally demonstrate the limits of the state-of-the-art. (3) We show that domain randomization techniques and adversarial training can be combined to overcome this issue. We demonstrate that this approach is more robust than the state-of-the-art, with an accuracy of 75 %, while having a limited impact on computing performance during training.
XMorpher: Full Transformer for Deformable Medical Image Registration via Cross Attention
Jun 15, 2022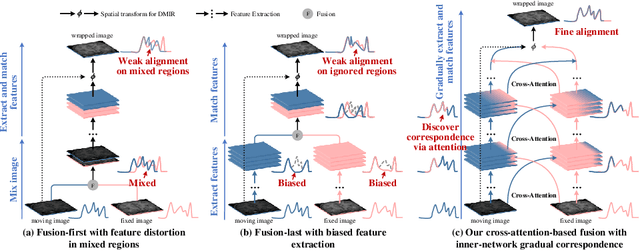
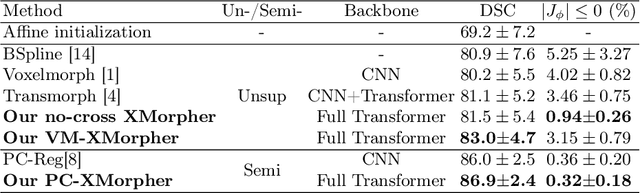
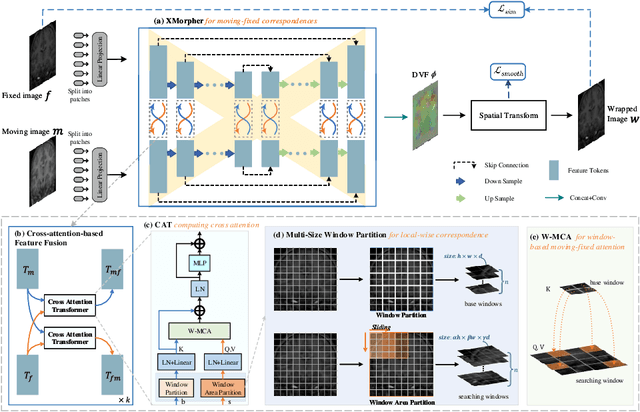
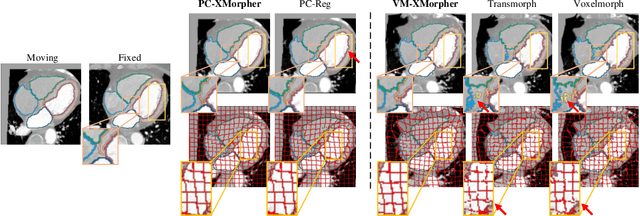
An effective backbone network is important to deep learning-based Deformable Medical Image Registration (DMIR), because it extracts and matches the features between two images to discover the mutual correspondence for fine registration. However, the existing deep networks focus on single image situation and are limited in registration task which is performed on paired images. Therefore, we advance a novel backbone network, XMorpher, for the effective corresponding feature representation in DMIR. 1) It proposes a novel full transformer architecture including dual parallel feature extraction networks which exchange information through cross attention, thus discovering multi-level semantic correspondence while extracting respective features gradually for final effective registration. 2) It advances the Cross Attention Transformer (CAT) blocks to establish the attention mechanism between images which is able to find the correspondence automatically and prompts the features to fuse efficiently in the network. 3) It constrains the attention computation between base windows and searching windows with different sizes, and thus focuses on the local transformation of deformable registration and enhances the computing efficiency at the same time. Without any bells and whistles, our XMorpher gives Voxelmorph 2.8% improvement on DSC , demonstrating its effective representation of the features from the paired images in DMIR. We believe that our XMorpher has great application potential in more paired medical images. Our XMorpher is open on https://github.com/Solemoon/XMorpher
HIVE-COTE 2.0: a new meta ensemble for time series classification
Apr 15, 2021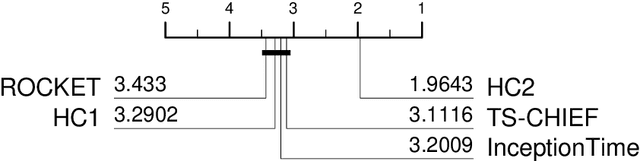
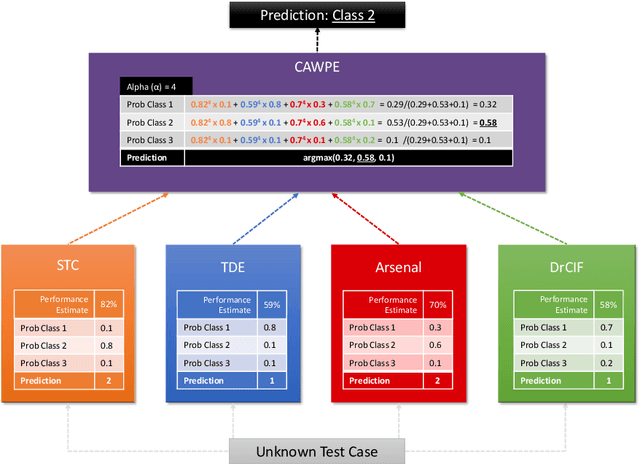

The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. HIVE-COTE forms its ensemble from classifiers of multiple domains, including phase-independent shapelets, bag-of-words based dictionaries and phase-dependent intervals. Since it was first proposed in 2016, the algorithm has remained state of the art for accuracy on the UCR time series classification archive. Over time it has been incrementally updated, culminating in its current state, HIVE-COTE 1.0. During this time a number of algorithms have been proposed which match the accuracy of HIVE-COTE. We propose comprehensive changes to the HIVE-COTE algorithm which significantly improve its accuracy and usability, presenting this upgrade as HIVE-COTE 2.0. We introduce two novel classifiers, the Temporal Dictionary Ensemble (TDE) and Diverse Representation Canonical Interval Forest (DrCIF), which replace existing ensemble members. Additionally, we introduce the Arsenal, an ensemble of ROCKET classifiers as a new HIVE-COTE 2.0 constituent. We demonstrate that HIVE-COTE 2.0 is significantly more accurate than the current state of the art on 112 univariate UCR archive datasets and 26 multivariate UEA archive datasets.
Short-term bus travel time prediction for transfer synchronization with intelligent uncertainty handling
Apr 14, 2021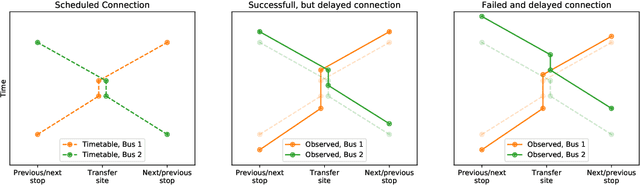
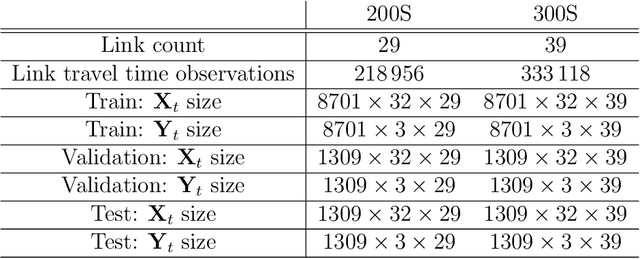
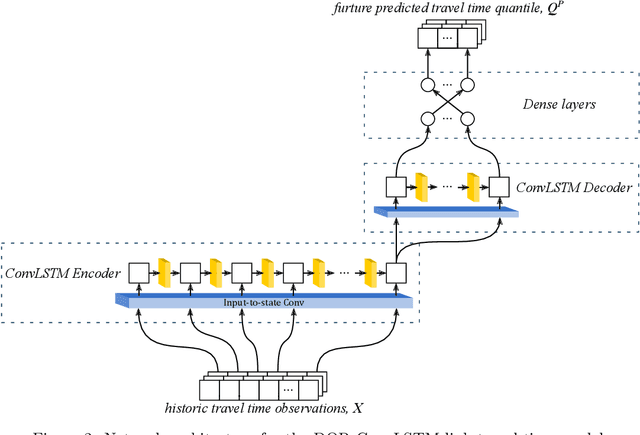
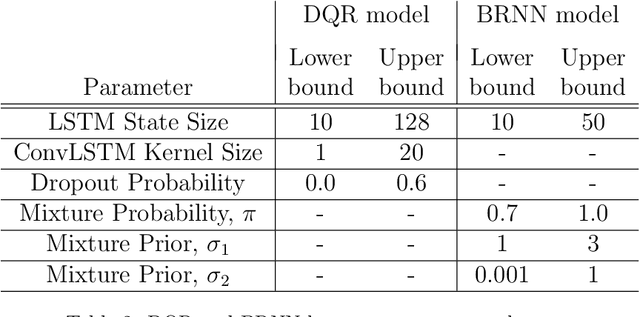
This paper presents two novel approaches for uncertainty estimation adapted and extended for the multi-link bus travel time problem. The uncertainty is modeled directly as part of recurrent artificial neural networks, but using two fundamentally different approaches: one based on Deep Quantile Regression (DQR) and the other on Bayesian Recurrent Neural Networks (BRNN). Both models predict multiple time steps into the future, but handle the time-dependent uncertainty estimation differently. We present a sampling technique in order to aggregate quantile estimates for link level travel time to yield the multi-link travel time distribution needed for a vehicle to travel from its current position to a specific downstream stop point or transfer site. To motivate the relevance of uncertainty-aware models in the domain, we focus on the connection assurance application as a case study: An expert system to determine whether a bus driver should hold and wait for a connecting service, or break the connection and reduce its own delay. Our results show that the DQR-model performs overall best for the 80%, 90% and 95% prediction intervals, both for a 15 minute time horizon into the future (t + 1), but also for the 30 and 45 minutes time horizon (t + 2 and t + 3), with a constant, but very small underestimation of the uncertainty interval (1-4 pp.). However, we also show, that the BRNN model still can outperform the DQR for specific cases. Lastly, we demonstrate how a simple decision support system can take advantage of our uncertainty-aware travel time models to prioritize the difference in travel time uncertainty for bus holding at strategic points, thus reducing the introduced delay for the connection assurance application.
Conditional Generation of Medical Time Series for Extrapolation to Underrepresented Populations
Jan 20, 2022
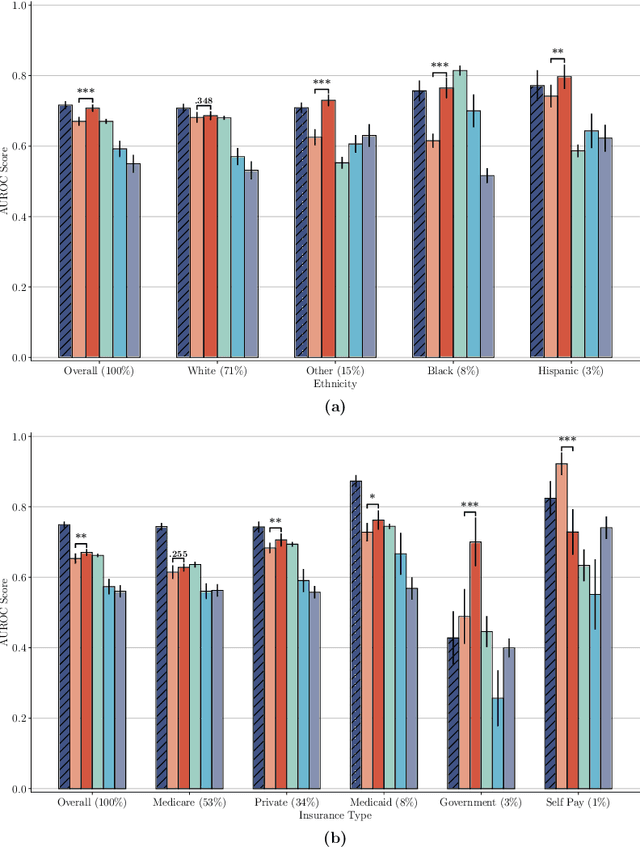
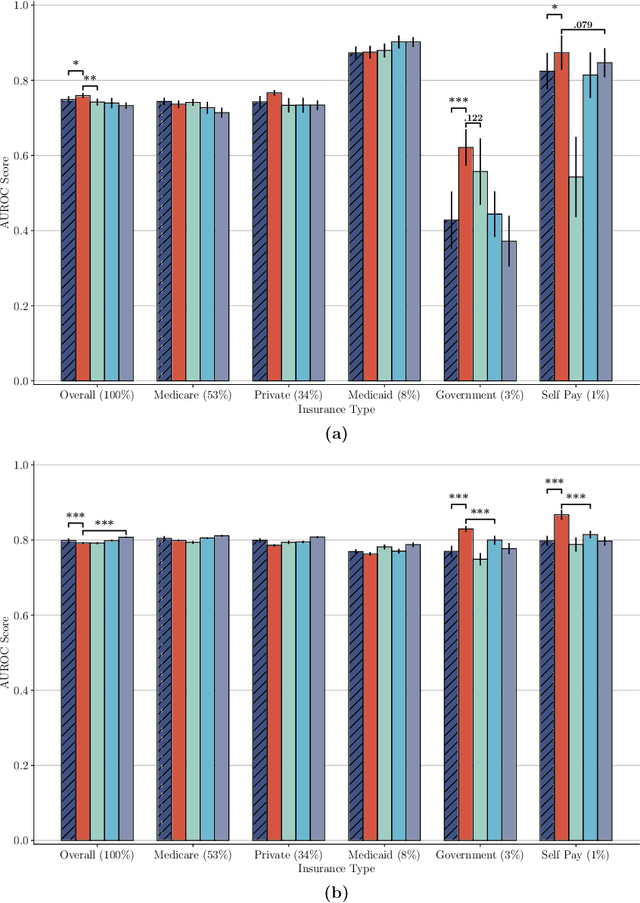
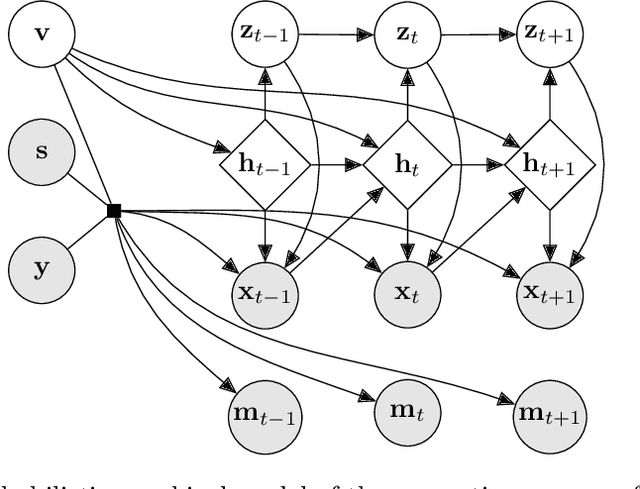
The widespread adoption of electronic health records (EHRs) and subsequent increased availability of longitudinal healthcare data has led to significant advances in our understanding of health and disease with direct and immediate impact on the development of new diagnostics and therapeutic treatment options. However, access to EHRs is often restricted due to their perceived sensitive nature and associated legal concerns, and the cohorts therein typically are those seen at a specific hospital or network of hospitals and therefore not representative of the wider population of patients. Here, we present HealthGen, a new approach for the conditional generation of synthetic EHRs that maintains an accurate representation of real patient characteristics, temporal information and missingness patterns. We demonstrate experimentally that HealthGen generates synthetic cohorts that are significantly more faithful to real patient EHRs than the current state-of-the-art, and that augmenting real data sets with conditionally generated cohorts of underrepresented subpopulations of patients can significantly enhance the generalisability of models derived from these data sets to different patient populations. Synthetic conditionally generated EHRs could help increase the accessibility of longitudinal healthcare data sets and improve the generalisability of inferences made from these data sets to underrepresented populations.
Time Series Imaging for Link Layer Anomaly Classification in Wireless Networks
Apr 02, 2021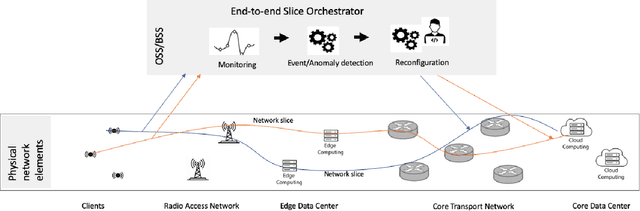


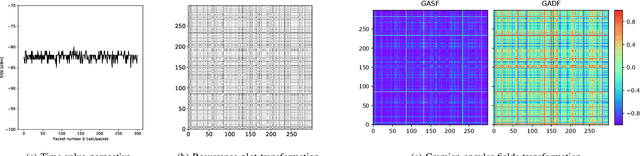
The number of end devices that use the last mile wireless connectivity is dramatically increasing with the rise of smart infrastructures and require reliable functioning to support smooth and efficient business processes. To efficiently manage such massive wireless networks, more advanced and accurate network monitoring and malfunction detection solutions are required. In this paper, we perform a first time analysis of image-based representation techniques for wireless anomaly detection using recurrence plots and Gramian angular fields and propose a new deep learning architecture enabling accurate anomaly detection. We examine the relative performance of the proposed model and show that the image transformation of time series improves the performance of anomaly detection by up to 29% for binary classification and by up to 27% for multiclass classification. At the same time, the best performing model based on recurrence plot transformation leads to up to 55% increase compared to the state of the art where classical machine learning techniques are used. We also provide insights for the decisions of the classifier using an instance based approach enabled by insights into guided back-propagation. Our results demonstrate the potential of transformation of time series signals to images to improve classification performance compared to classification on raw time series data.
Online Contextual Decision-Making with a Smart Predict-then-Optimize Method
Jun 15, 2022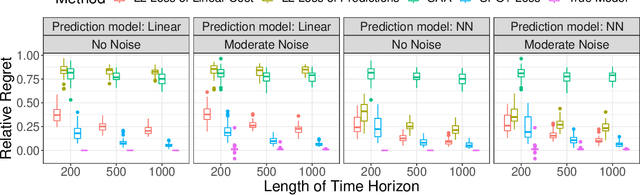
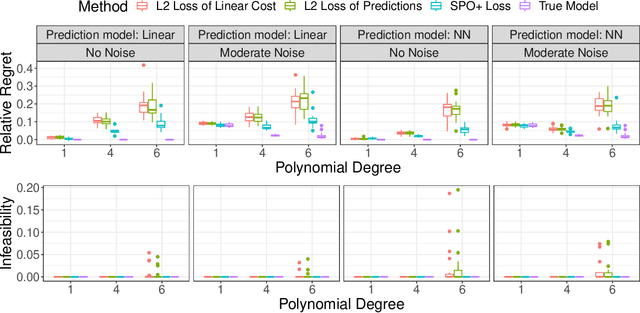
We study an online contextual decision-making problem with resource constraints. At each time period, the decision-maker first predicts a reward vector and resource consumption matrix based on a given context vector and then solves a downstream optimization problem to make a decision. The final goal of the decision-maker is to maximize the summation of the reward and the utility from resource consumption, while satisfying the resource constraints. We propose an algorithm that mixes a prediction step based on the "Smart Predict-then-Optimize (SPO)" method with a dual update step based on mirror descent. We prove regret bounds and demonstrate that the overall convergence rate of our method depends on the $\mathcal{O}(T^{-1/2})$ convergence of online mirror descent as well as risk bounds of the surrogate loss function used to learn the prediction model. Our algorithm and regret bounds apply to a general convex feasible region for the resource constraints, including both hard and soft resource constraint cases, and they apply to a wide class of prediction models in contrast to the traditional settings of linear contextual models or finite policy spaces. We also conduct numerical experiments to empirically demonstrate the strength of our proposed SPO-type methods, as compared to traditional prediction-error-only methods, on multi-dimensional knapsack and longest path instances.
Interpretable Deep Learning Classifier by Detection of Prototypical Parts on Kidney Stones Images
Jun 01, 2022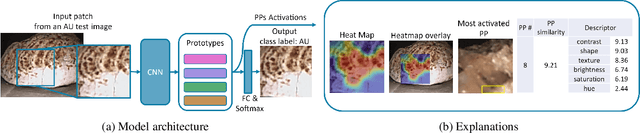


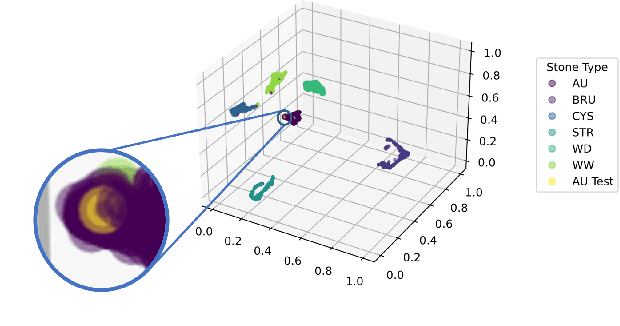
Identifying the type of kidney stones can allow urologists to determine their formation cause, improving the early prescription of appropriate treatments to diminish future relapses. However, currently, the associated ex-vivo diagnosis (known as morpho-constitutional analysis, MCA) is time-consuming, expensive, and requires a great deal of experience, as it requires a visual analysis component that is highly operator dependant. Recently, machine learning methods have been developed for in-vivo endoscopic stone recognition. Shallow methods have been demonstrated to be reliable and interpretable but exhibit low accuracy, while deep learning-based methods yield high accuracy but are not explainable. However, high stake decisions require understandable computer-aided diagnosis (CAD) to suggest a course of action based on reasonable evidence, rather than merely prescribe one. Herein, we investigate means for learning part-prototypes (PPs) that enable interpretable models. Our proposal suggests a classification for a kidney stone patch image and provides explanations in a similar way as those used on the MCA method.
Real-Time Patient-Specific ECG Classification by 1D Self-Operational Neural Networks
Sep 30, 2021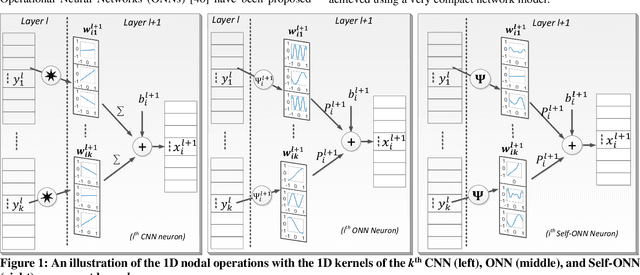
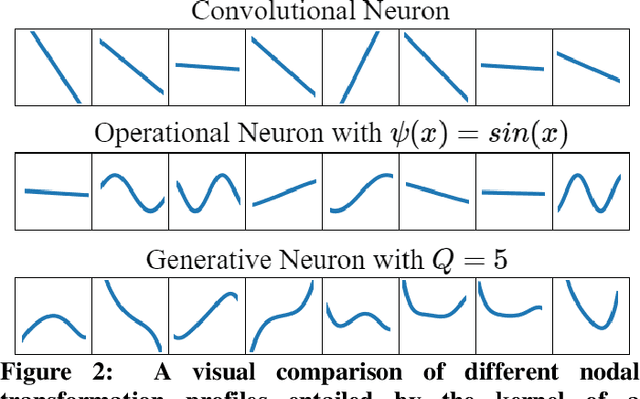
Despite the proliferation of numerous deep learning methods proposed for generic ECG classification and arrhythmia detection, compact systems with the real-time ability and high accuracy for classifying patient-specific ECG are still few. Particularly, the scarcity of patient-specific data poses an ultimate challenge to any classifier. Recently, compact 1D Convolutional Neural Networks (CNNs) have achieved the state-of-the-art performance level for the accurate classification of ventricular and supraventricular ectopic beats. However, several studies have demonstrated the fact that the learning performance of the conventional CNNs is limited because they are homogenous networks with a basic (linear) neuron model. In order to address this deficiency and further boost the patient-specific ECG classification performance, in this study, we propose 1D Self-organized Operational Neural Networks (1D Self-ONNs). Due to its self-organization capability, Self-ONNs have the utmost advantage and superiority over conventional ONNs where the prior operator search within the operator set library to find the best possible set of operators is entirely avoided. As the first study where 1D Self-ONNs are ever proposed for a classification task, our results over the MIT-BIH arrhythmia benchmark database demonstrate that 1D Self-ONNs can surpass 1D CNNs with a significant margin while having a similar computational complexity. Under AAMI recommendations and with minimal common training data used, over the entire MIT-BIH dataset 1D Self-ONNs have achieved 98% and 99.04% average accuracies, 76.6% and 93.7% average F1 scores on supra-ventricular and ventricular ectopic beat (VEB) classifications, respectively, which is the highest performance level ever reported.