 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Short-range forecasts of global precipitation using using deep learning-augmented numerical weather prediction
Jun 23, 2022
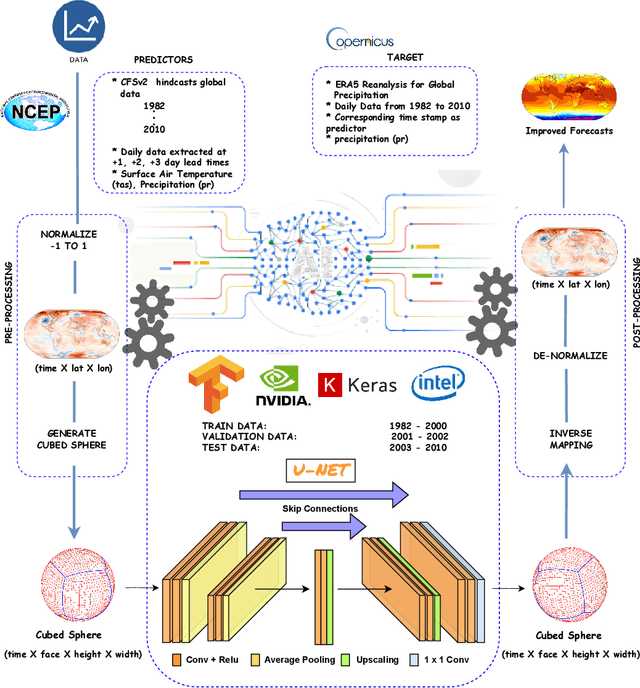

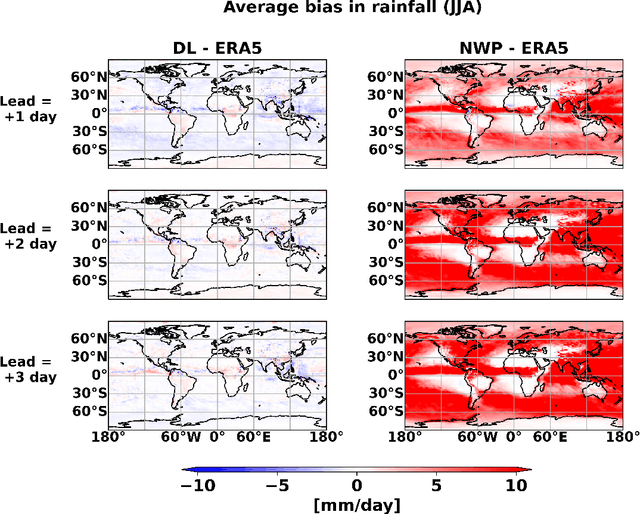
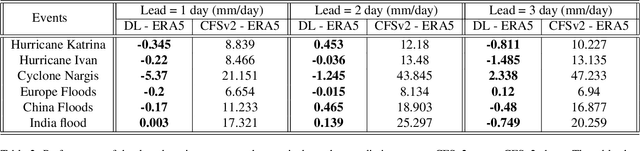
Precipitation governs Earth's hydroclimate, and its daily spatiotemporal fluctuations have major socioeconomic effects. Advances in Numerical weather prediction (NWP) have been measured by the improvement of forecasts for various physical fields such as temperature and pressure; however, large biases exist in precipitation prediction. We augment the output of the well-known NWP model CFSv2 with deep learning to create a hybrid model that improves short-range global precipitation at 1-, 2-, and 3-day lead times. To hybridise, we address the sphericity of the global data by using modified DLWP-CS architecture which transforms all the fields to cubed-sphere projection. Dynamical model precipitation and surface temperature outputs are fed into a modified DLWP-CS (UNET) to forecast ground truth precipitation. While CFSv2's average bias is +5 to +7 mm/day over land, the multivariate deep learning model decreases it to within -1 to +1 mm/day. Hurricane Katrina in 2005, Hurricane Ivan in 2004, China floods in 2010, India floods in 2005, and Myanmar storm Nargis in 2008 are used to confirm the substantial enhancement in the skill for the hybrid dynamical-deep learning model. CFSv2 typically shows a moderate to large bias in the spatial pattern and overestimates the precipitation at short-range time scales. The proposed deep learning augmented NWP model can address these biases and vastly improve the spatial pattern and magnitude of predicted precipitation. Deep learning enhanced CFSv2 reduces mean bias by 8x over important land regions for 1 day lead compared to CFSv2. The spatio-temporal deep learning system opens pathways to further the precision and accuracy in global short-range precipitation forecasts.
GeCo: Quality Counterfactual Explanations in Real Time
Jan 05, 2021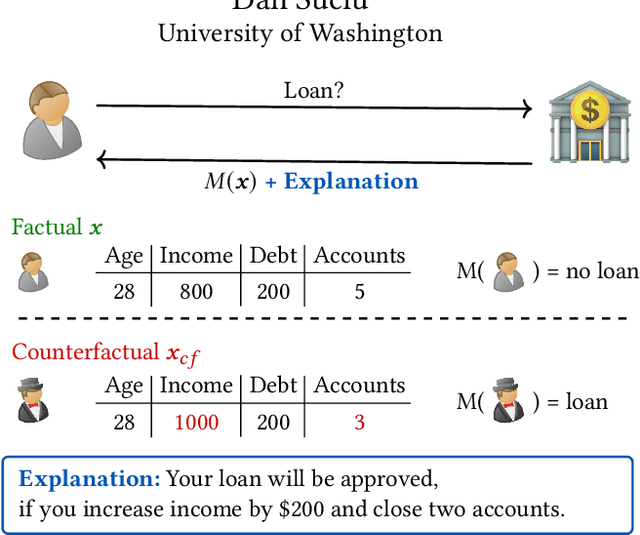
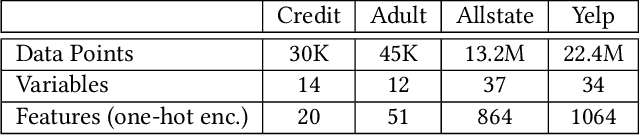

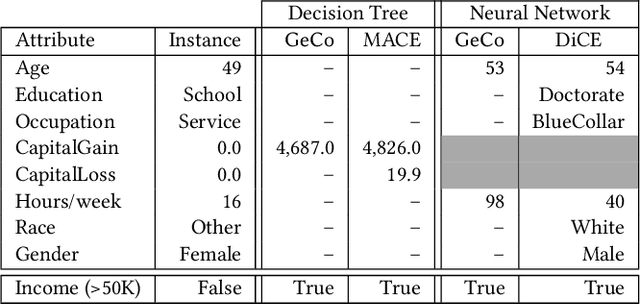
Machine learning is increasingly applied in high-stakes decision making that directly affect people's lives, and this leads to an increased demand for systems to explain their decisions. Explanations often take the form of counterfactuals, which consists of conveying to the end user what she/he needs to change in order to improve the outcome. Computing counterfactual explanations is challenging, because of the inherent tension between a rich semantics of the domain, and the need for real time response. In this paper we present GeCo, the first system that can compute plausible and feasible counterfactual explanations in real time. At its core, GeCo relies on a genetic algorithm, which is customized to favor searching counterfactual explanations with the smallest number of changes. To achieve real-time performance, we introduce two novel optimizations: $\Delta$-representation of candidate counterfactuals, and partial evaluation of the classifier. We compare empirically GeCo against four other systems described in the literature, and show that it is the only system that can achieve both high quality explanations and real time answers.
Narrowing the Gap: Improved Detector Training with Noisy Location Annotations
Jun 12, 2022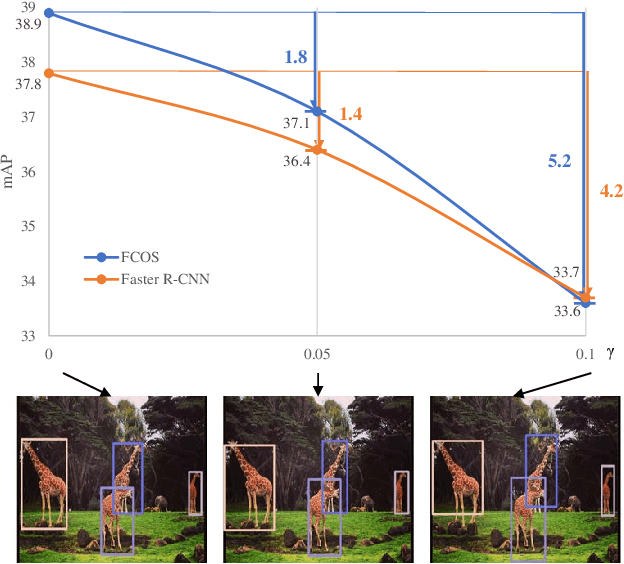
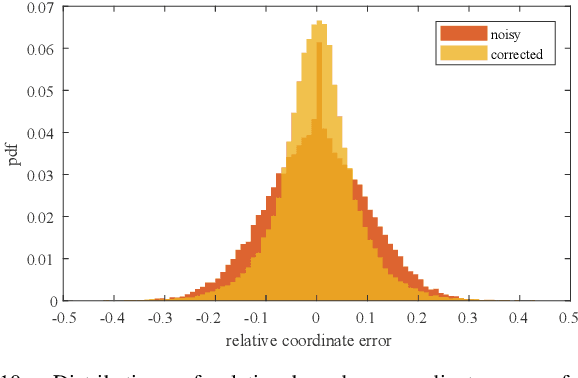

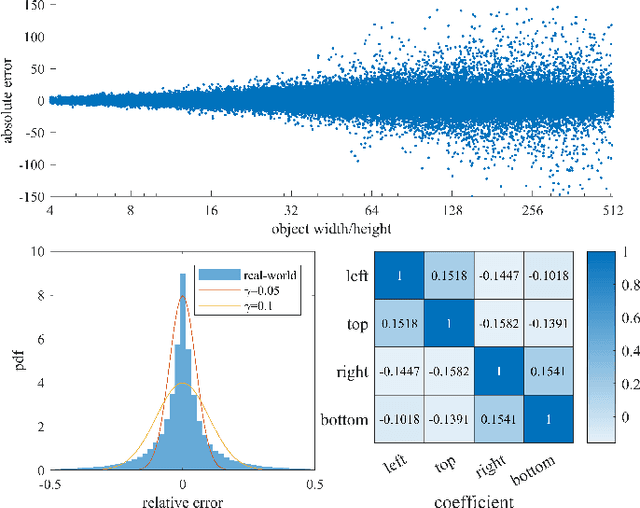
Deep learning methods require massive of annotated data for optimizing parameters. For example, datasets attached with accurate bounding box annotations are essential for modern object detection tasks. However, labeling with such pixel-wise accuracy is laborious and time-consuming, and elaborate labeling procedures are indispensable for reducing man-made noise, involving annotation review and acceptance testing. In this paper, we focus on the impact of noisy location annotations on the performance of object detection approaches and aim to, on the user side, reduce the adverse effect of the noise. First, noticeable performance degradation is experimentally observed for both one-stage and two-stage detectors when noise is introduced to the bounding box annotations. For instance, our synthesized noise results in performance decrease from 38.9% AP to 33.6% AP for FCOS detector on COCO test split, and 37.8%AP to 33.7%AP for Faster R-CNN. Second, a self-correction technique based on a Bayesian filter for prediction ensemble is proposed to better exploit the noisy location annotations following a Teacher-Student learning paradigm. Experiments for both synthesized and real-world scenarios consistently demonstrate the effectiveness of our approach, e.g., our method increases the degraded performance of the FCOS detector from 33.6% AP to 35.6% AP on COCO.
A Temporal Kernel Approach for Deep Learning with Continuous-time Information
Mar 28, 2021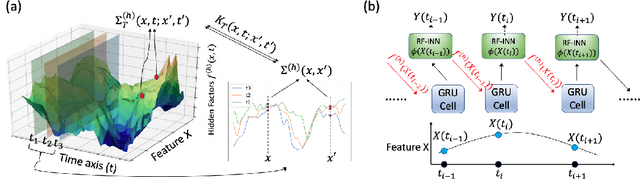
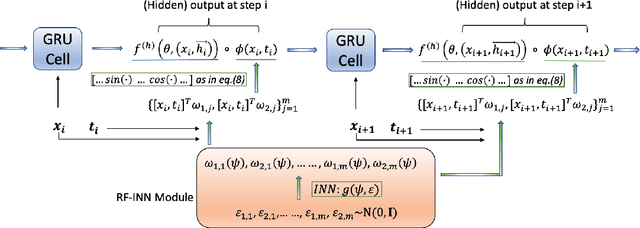
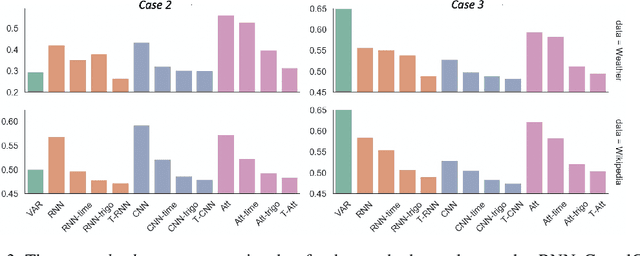
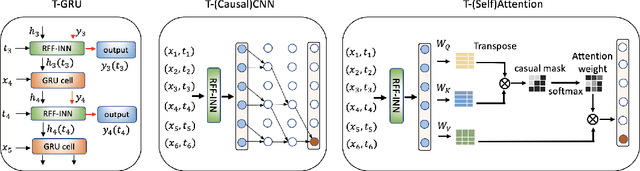
Sequential deep learning models such as RNN, causal CNN and attention mechanism do not readily consume continuous-time information. Discretizing the temporal data, as we show, causes inconsistency even for simple continuous-time processes. Current approaches often handle time in a heuristic manner to be consistent with the existing deep learning architectures and implementations. In this paper, we provide a principled way to characterize continuous-time systems using deep learning tools. Notably, the proposed approach applies to all the major deep learning architectures and requires little modifications to the implementation. The critical insight is to represent the continuous-time system by composing neural networks with a temporal kernel, where we gain our intuition from the recent advancements in understanding deep learning with Gaussian process and neural tangent kernel. To represent the temporal kernel, we introduce the random feature approach and convert the kernel learning problem to spectral density estimation under reparameterization. We further prove the convergence and consistency results even when the temporal kernel is non-stationary, and the spectral density is misspecified. The simulations and real-data experiments demonstrate the empirical effectiveness of our temporal kernel approach in a broad range of settings.
Mapping Research Trajectories
Apr 25, 2022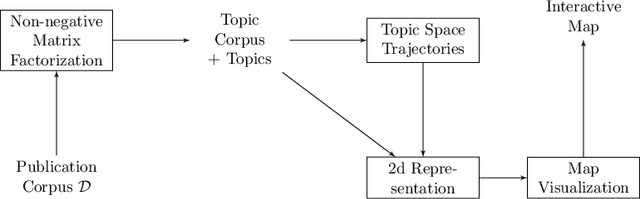
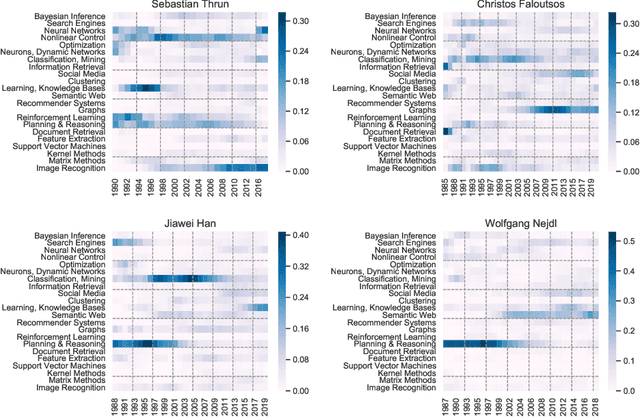
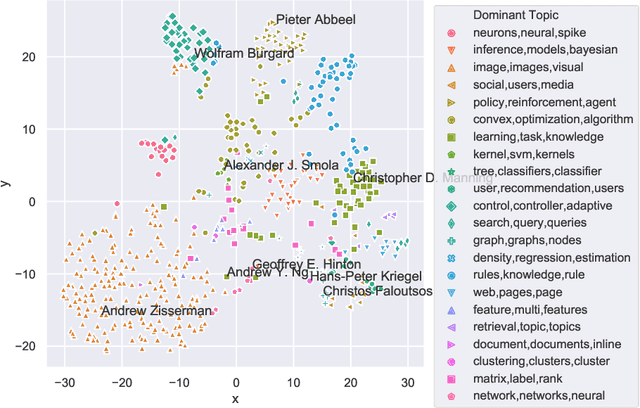
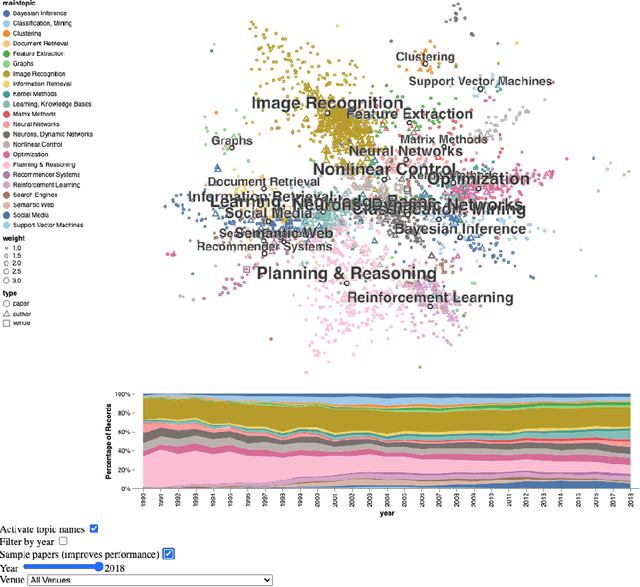
Steadily growing amounts of information, such as annually published scientific papers, have become so large that they elude an extensive manual analysis. Hence, to maintain an overview, automated methods for the mapping and visualization of knowledge domains are necessary and important, e.g., for scientific decision makers. Of particular interest in this field is the development of research topics of different entities (e.g., scientific authors and venues) over time. However, existing approaches for their analysis are only suitable for single entity types, such as venues, and they often do not capture the research topics or the time dimension in an easily interpretable manner. Hence, we propose a principled approach for \emph{mapping research trajectories}, which is applicable to all kinds of scientific entities that can be represented by sets of published papers. For this, we transfer ideas and principles from the geographic visualization domain, specifically trajectory maps and interactive geographic maps. Our visualizations depict the research topics of entities over time in a straightforward interpr. manner. They can be navigated by the user intuitively and restricted to specific elements of interest. The maps are derived from a corpus of research publications (i.e., titles and abstracts) through a combination of unsupervised machine learning methods. In a practical demonstrator application, we exemplify the proposed approach on a publication corpus from machine learning. We observe that our trajectory visualizations of 30 top machine learning venues and 1000 major authors in this field are well interpretable and are consistent with background knowledge drawn from the entities' publications. Next to producing interactive, interpr. visualizations supporting different kinds of analyses, our computed trajectories are suitable for trajectory mining applications in the future.
Accelerating Large Scale Real-Time GNN Inference using Channel Pruning
May 10, 2021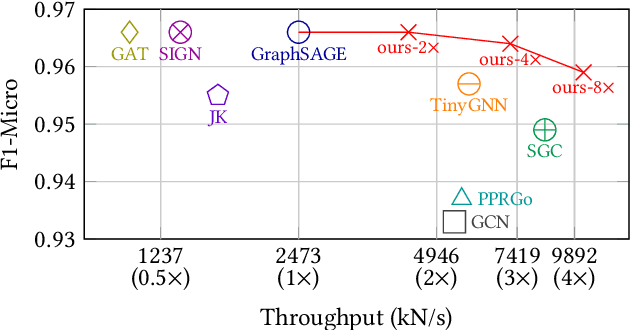
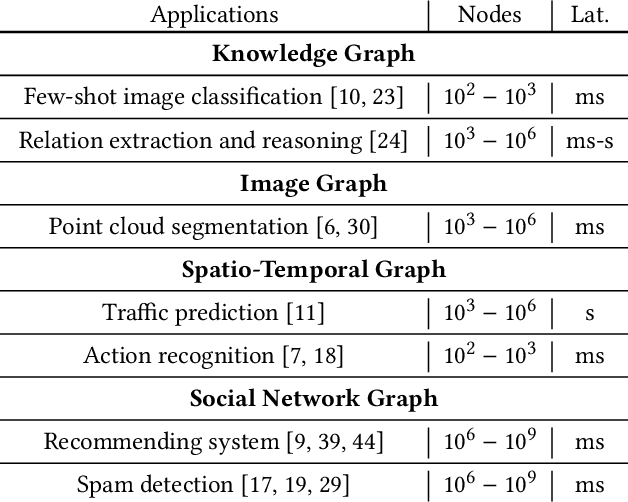
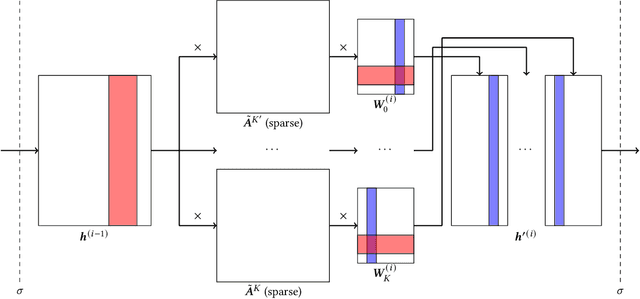
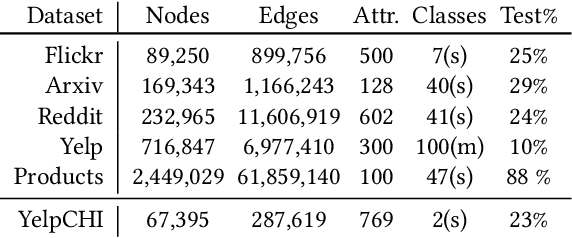
Graph Neural Networks (GNNs) are proven to be powerful models to generate node embedding for downstream applications. However, due to the high computation complexity of GNN inference, it is hard to deploy GNNs for large-scale or real-time applications. In this paper, we propose to accelerate GNN inference by pruning the dimensions in each layer with negligible accuracy loss. Our pruning framework uses a novel LASSO regression formulation for GNNs to identify feature dimensions (channels) that have high influence on the output activation. We identify two inference scenarios and design pruning schemes based on their computation and memory usage for each. To further reduce the inference complexity, we effectively store and reuse hidden features of visited nodes, which significantly reduces the number of supporting nodes needed to compute the target embedding. We evaluate the proposed method with the node classification problem on five popular datasets and a real-time spam detection application. We demonstrate that the pruned GNN models greatly reduce computation and memory usage with little accuracy loss. For full inference, the proposed method achieves an average of 3.27x speedup with only 0.002 drop in F1-Micro on GPU. For batched inference, the proposed method achieves an average of 6.67x speedup with only 0.003 drop in F1-Micro on CPU. To the best of our knowledge, we are the first to accelerate large scale real-time GNN inference through channel pruning.
Identifiability of deep generative models under mixture priors without auxiliary information
Jun 20, 2022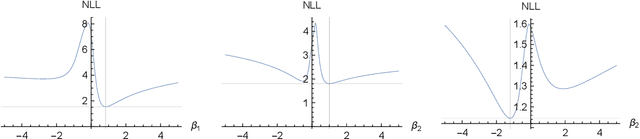


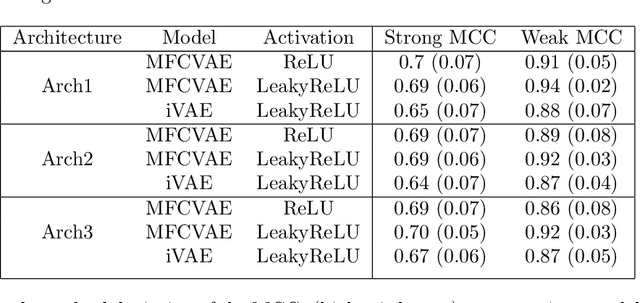
We prove identifiability of a broad class of deep latent variable models that (a) have universal approximation capabilities and (b) are the decoders of variational autoencoders that are commonly used in practice. Unlike existing work, our analysis does not require weak supervision, auxiliary information, or conditioning in the latent space. Recently, there has been a surge of works studying identifiability of such models. In these works, the main assumption is that along with the data, an auxiliary variable $u$ (also known as side information) is observed as well. At the same time, several works have empirically observed that this doesn't seem to be necessary in practice. In this work, we explain this behavior by showing that for a broad class of generative (i.e. unsupervised) models with universal approximation capabilities, the side information $u$ is not necessary: We prove identifiability of the entire generative model where we do not observe $u$ and only observe the data $x$. The models we consider are tightly connected with autoencoder architectures used in practice that leverage mixture priors in the latent space and ReLU/leaky-ReLU activations in the encoder. Our main result is an identifiability hierarchy that significantly generalizes previous work and exposes how different assumptions lead to different "strengths" of identifiability. For example, our weakest result establishes (unsupervised) identifiability up to an affine transformation, which already improves existing work. It's well known that these models have universal approximation capabilities and moreover, they have been extensively used in practice to learn representations of data.
Quantum Kerr Learning
May 20, 2022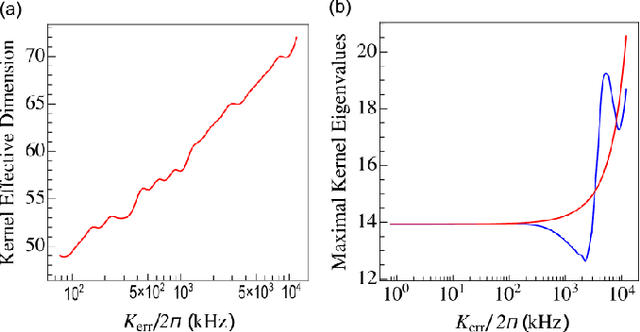
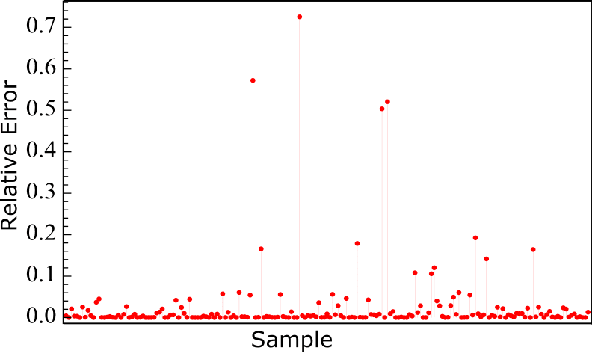
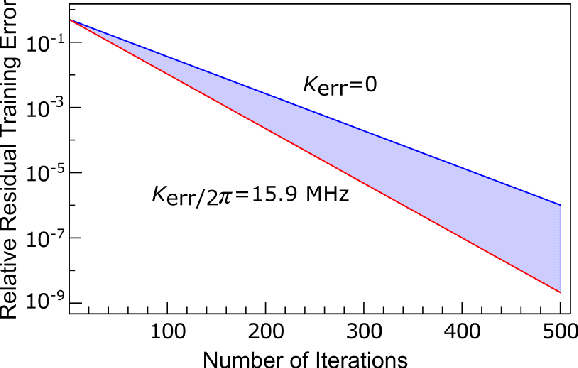
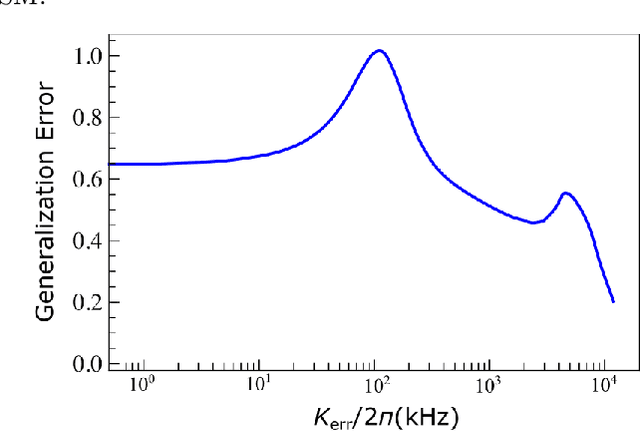
Quantum machine learning is a rapidly evolving area that could facilitate important applications for quantum computing and significantly impact data science. In our work, we argue that a single Kerr mode might provide some extra quantum enhancements when using quantum kernel methods based on various reasons from complexity theory and physics. Furthermore, we establish an experimental protocol, which we call \emph{quantum Kerr learning} based on circuit QED. A detailed study using the kernel method, neural tangent kernel theory, first-order perturbation theory of the Kerr non-linearity, and non-perturbative numerical simulations, shows quantum enhancements could happen in terms of the convergence time and the generalization error, while explicit protocols are also constructed for higher-dimensional input data.
Prefix-Free Coding for LQG Control
Apr 01, 2022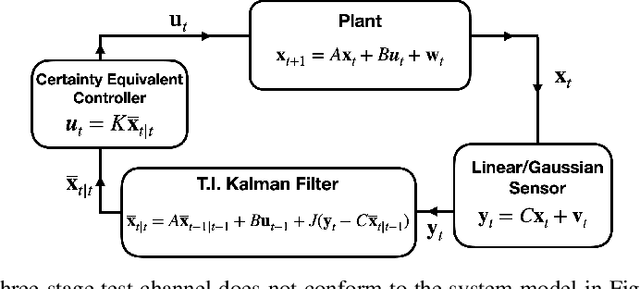
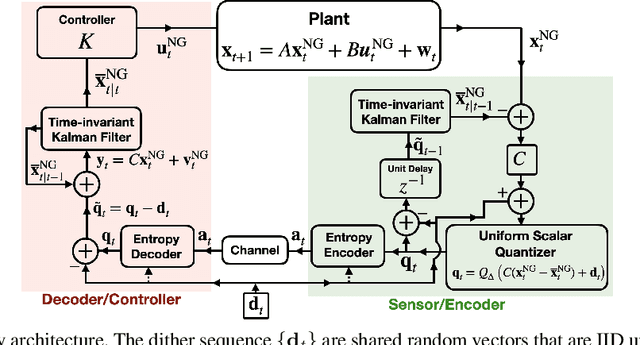
In this work, we develop quantization and variable-length source codecs for the feedback links in linear-quadratic-Gaussian (LQG) control systems. We prove that for any fixed control performance, the approaches we propose nearly achieve lower bounds on communication cost that have been established in prior work. In particular, we refine the analysis of a classical achievability approach with an eye towards more practical details. Notably, in the prior literature the source codecs used to demonstrate the (near) achievability of these lower bounds are often implicitly assumed to be time-varying. For single-input single-output (SISO) plants, we prove that it suffices to consider time-invariant quantization and source coding. This result follows from analyzing the long-term stochastic behavior of the system's quantized measurements and reconstruction errors. To our knowledge, this time-invariant achievability result is the first in the literature.
Self-Supervised Learning as a Means To Reduce the Need for Labeled Data in Medical Image Analysis
Jun 01, 2022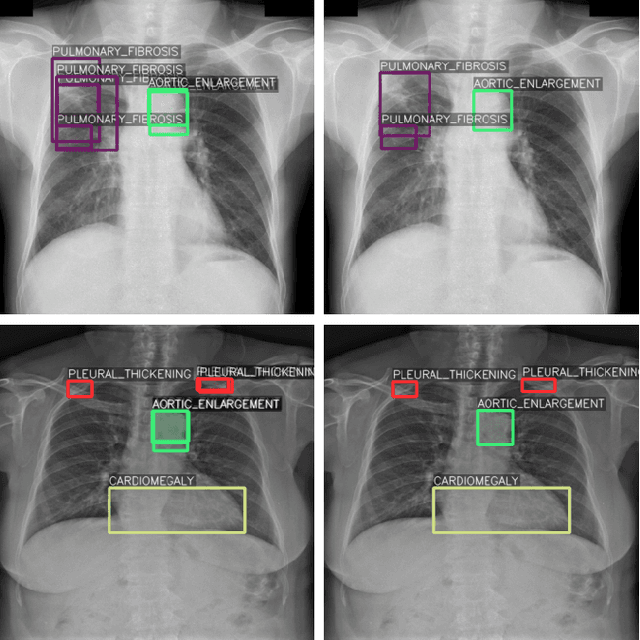
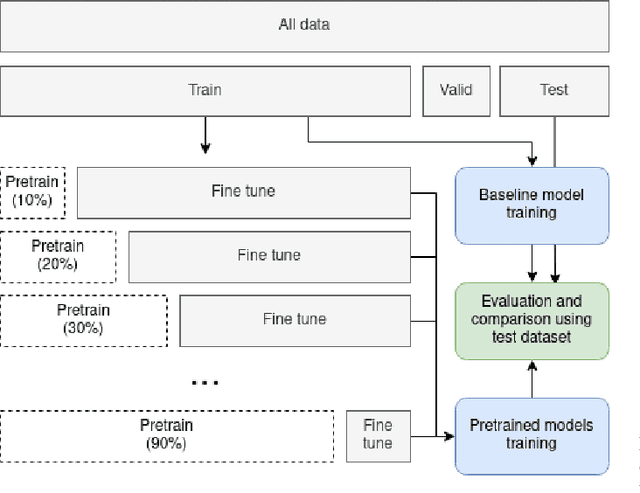
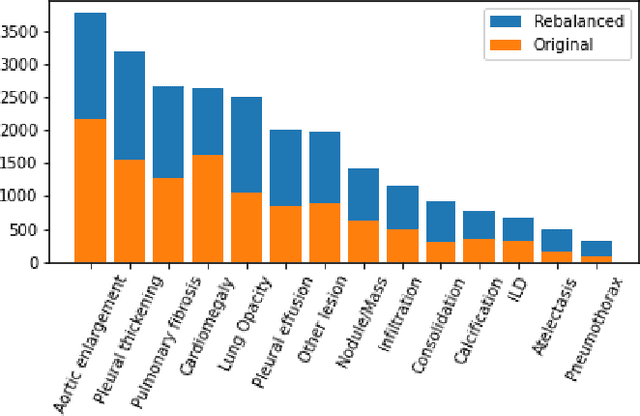
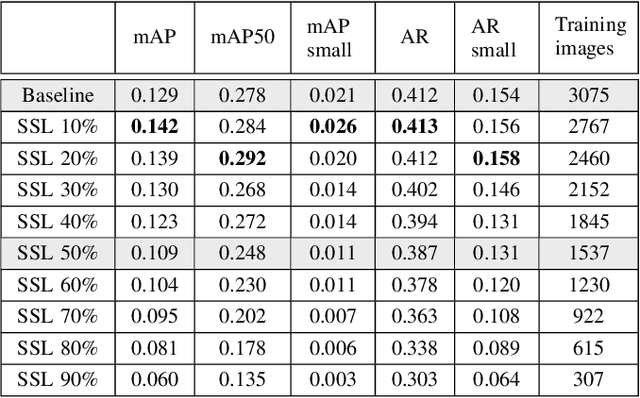
One of the largest problems in medical image processing is the lack of annotated data. Labeling medical images often requires highly trained experts and can be a time-consuming process. In this paper, we evaluate a method of reducing the need for labeled data in medical image object detection by using self-supervised neural network pretraining. We use a dataset of chest X-ray images with bounding box labels for 13 different classes of anomalies. The networks are pretrained on a percentage of the dataset without labels and then fine-tuned on the rest of the dataset. We show that it is possible to achieve similar performance to a fully supervised model in terms of mean average precision and accuracy with only 60\% of the labeled data. We also show that it is possible to increase the maximum performance of a fully-supervised model by adding a self-supervised pretraining step, and this effect can be observed with even a small amount of unlabeled data for pretraining.