 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Image Retrieval is not Robust to Label Noise
May 23, 2022
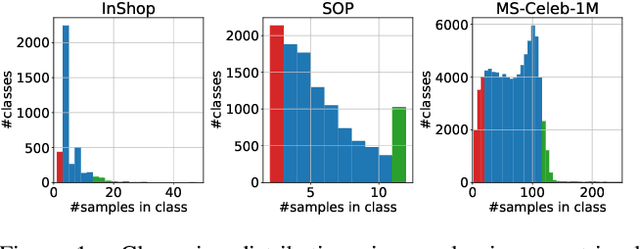
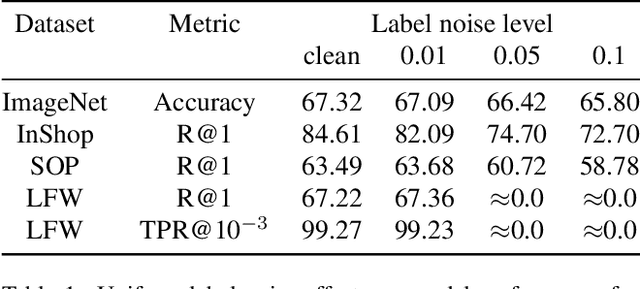
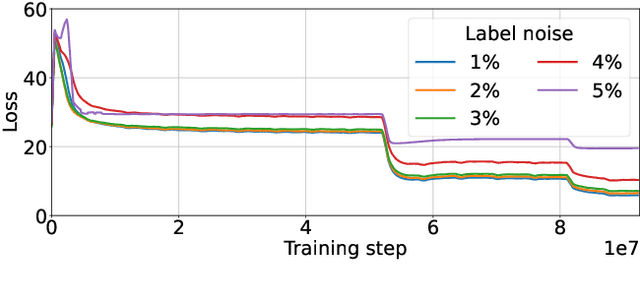
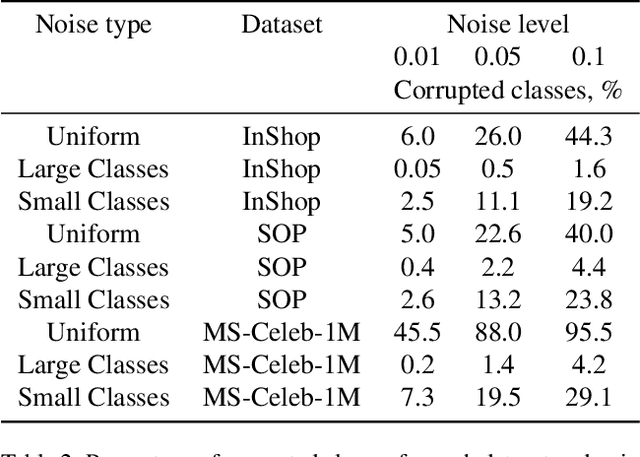
Large-scale datasets are essential for the success of deep learning in image retrieval. However, manual assessment errors and semi-supervised annotation techniques can lead to label noise even in popular datasets. As previous works primarily studied annotation quality in image classification tasks, it is still unclear how label noise affects deep learning approaches to image retrieval. In this work, we show that image retrieval methods are less robust to label noise than image classification ones. Furthermore, we, for the first time, investigate different types of label noise specific to image retrieval tasks and study their effect on model performance.
Semi-supervised Drifted Stream Learning with Short Lookback
May 25, 2022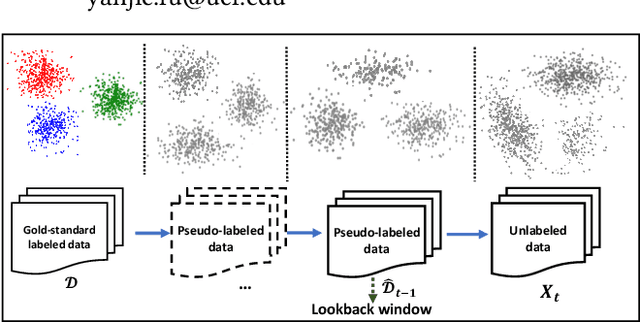
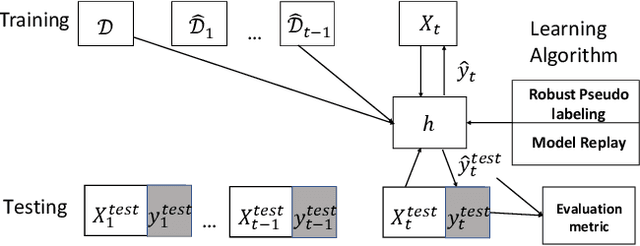
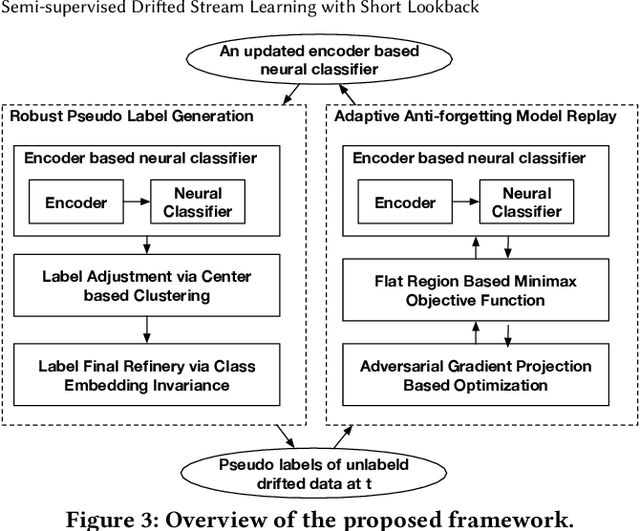
In many scenarios, 1) data streams are generated in real time; 2) labeled data are expensive and only limited labels are available in the beginning; 3) real-world data is not always i.i.d. and data drift over time gradually; 4) the storage of historical streams is limited and model updating can only be achieved based on a very short lookback window. This learning setting limits the applicability and availability of many Machine Learning (ML) algorithms. We generalize the learning task under such setting as a semi-supervised drifted stream learning with short lookback problem (SDSL). SDSL imposes two under-addressed challenges on existing methods in semi-supervised learning, continuous learning, and domain adaptation: 1) robust pseudo-labeling under gradual shifts and 2) anti-forgetting adaptation with short lookback. To tackle these challenges, we propose a principled and generic generation-replay framework to solve SDSL. The framework is able to accomplish: 1) robust pseudo-labeling in the generation step; 2) anti-forgetting adaption in the replay step. To achieve robust pseudo-labeling, we develop a novel pseudo-label classification model to leverage supervised knowledge of previously labeled data, unsupervised knowledge of new data, and, structure knowledge of invariant label semantics. To achieve adaptive anti-forgetting model replay, we propose to view the anti-forgetting adaptation task as a flat region search problem. We propose a novel minimax game-based replay objective function to solve the flat region search problem and develop an effective optimization solver. Finally, we present extensive experiments to demonstrate our framework can effectively address the task of anti-forgetting learning in drifted streams with short lookback.
Sparse Compressed Spiking Neural Network Accelerator for Object Detection
May 02, 2022
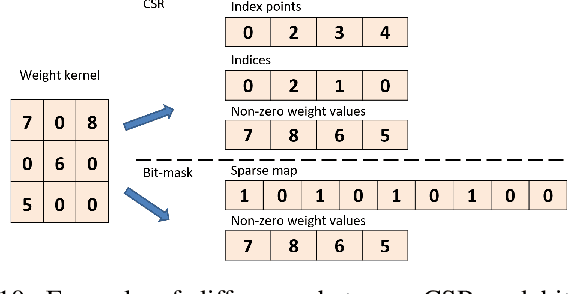
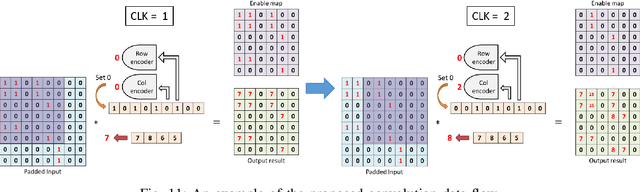
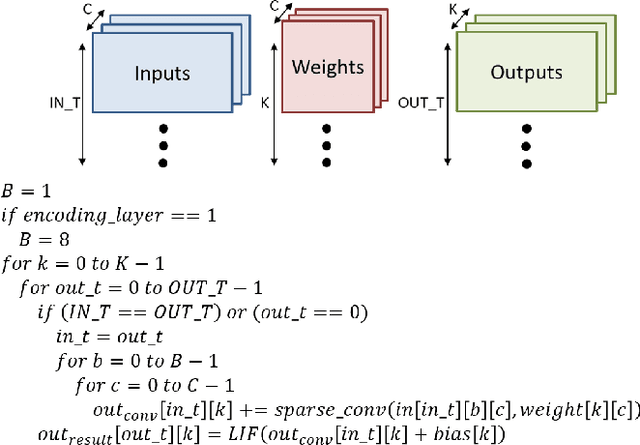
Spiking neural networks (SNNs), which are inspired by the human brain, have recently gained popularity due to their relatively simple and low-power hardware for transmitting binary spikes and highly sparse activation maps. However, because SNNs contain extra time dimension information, the SNN accelerator will require more buffers and take longer to infer, especially for the more difficult high-resolution object detection task. As a result, this paper proposes a sparse compressed spiking neural network accelerator that takes advantage of the high sparsity of activation maps and weights by utilizing the proposed gated one-to-all product for low power and highly parallel model execution. The experimental result of the neural network shows 71.5$\%$ mAP with mixed (1,3) time steps on the IVS 3cls dataset. The accelerator with the TSMC 28nm CMOS process can achieve 1024$\times$576@29 frames per second processing when running at 500MHz with 35.88TOPS/W energy efficiency and 1.05mJ energy consumption per frame.
Graph Attention Recurrent Neural Networks for Correlated Time Series Forecasting -- Full version
Mar 22, 2021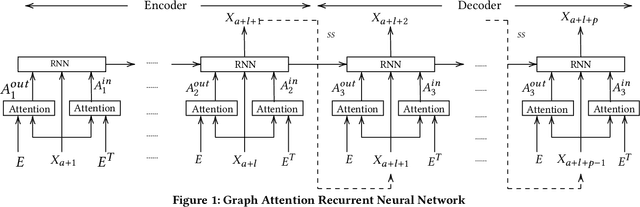
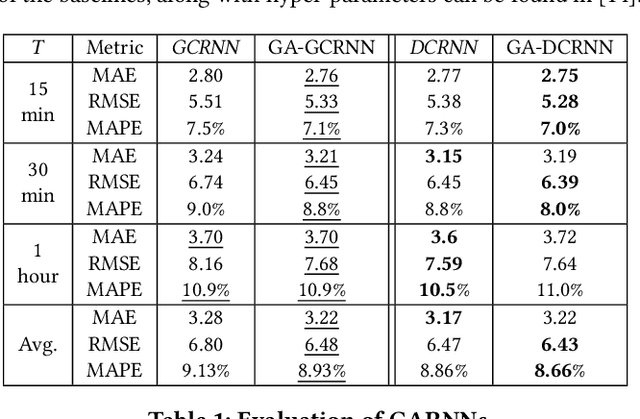
We consider a setting where multiple entities inter-act with each other over time and the time-varying statuses of the entities are represented as multiple correlated time series. For example, speed sensors are deployed in different locations in a road network, where the speed of a specific location across time is captured by the corresponding sensor as a time series, resulting in multiple speed time series from different locations, which are often correlated. To enable accurate forecasting on correlated time series, we proposes graph attention recurrent neural networks.First, we build a graph among different entities by taking into account spatial proximity and employ a multi-head attention mechanism to derive adaptive weight matrices for the graph to capture the correlations among vertices (e.g., speeds at different locations) at different timestamps. Second, we employ recurrent neural networks to take into account temporal dependency while taking into account the adaptive weight matrices learned from the first step to consider the correlations among time series.Experiments on a large real-world speed time series data set suggest that the proposed method is effective and outperforms the state-of-the-art in most settings. This manuscript provides a full version of a workshop paper [1].
S2RL: Do We Really Need to Perceive All States in Deep Multi-Agent Reinforcement Learning?
Jun 20, 2022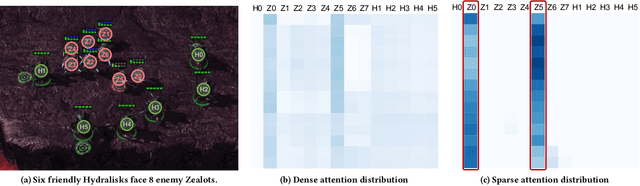
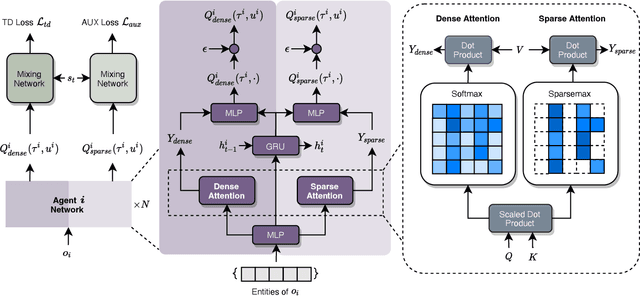
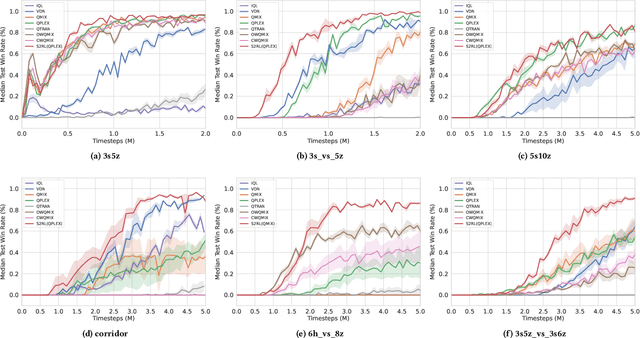
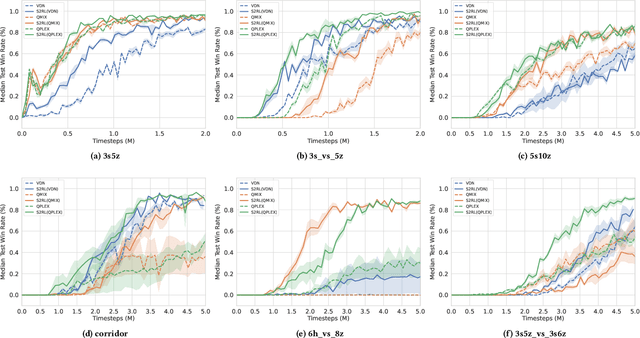
Collaborative multi-agent reinforcement learning (MARL) has been widely used in many practical applications, where each agent makes a decision based on its own observation. Most mainstream methods treat each local observation as an entirety when modeling the decentralized local utility functions. However, they ignore the fact that local observation information can be further divided into several entities, and only part of the entities is helpful to model inference. Moreover, the importance of different entities may change over time. To improve the performance of decentralized policies, the attention mechanism is used to capture features of local information. Nevertheless, existing attention models rely on dense fully connected graphs and cannot better perceive important states. To this end, we propose a sparse state based MARL (S2RL) framework, which utilizes a sparse attention mechanism to discard irrelevant information in local observations. The local utility functions are estimated through the self-attention and sparse attention mechanisms separately, then are combined into a standard joint value function and auxiliary joint value function in the central critic. We design the S2RL framework as a plug-and-play module, making it general enough to be applied to various methods. Extensive experiments on StarCraft II show that S2RL can significantly improve the performance of many state-of-the-art methods.
Pushing the Limits of Learning-based Traversability Analysis for Autonomous Driving on CPU
Jun 07, 2022
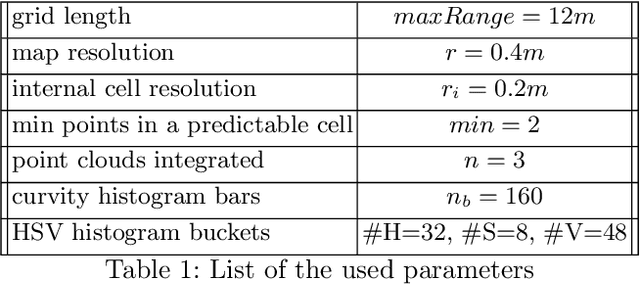

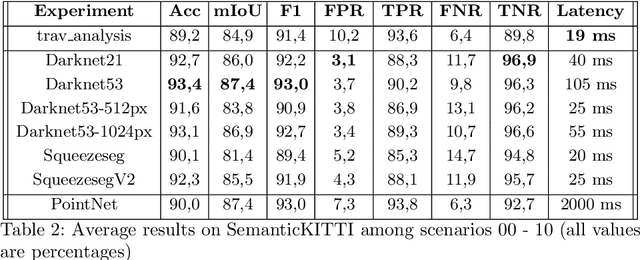
Self-driving vehicles and autonomous ground robots require a reliable and accurate method to analyze the traversability of the surrounding environment for safe navigation. This paper proposes and evaluates a real-time machine learning-based Traversability Analysis method that combines geometric features with appearance-based features in a hybrid approach based on a SVM classifier. In particular, we show that integrating a new set of geometric and visual features and focusing on important implementation details enables a noticeable boost in performance and reliability. The proposed approach has been compared with state-of-the-art Deep Learning approaches on a public dataset of outdoor driving scenarios. It reaches an accuracy of 89.2% in scenarios of varying complexity, demonstrating its effectiveness and robustness. The method runs fully on CPU and reaches comparable results with respect to the other methods, operates faster, and requires fewer hardware resources.
Only-Train-Once MR Fingerprinting for Magnetization Transfer Contrast Quantification
Jun 09, 2022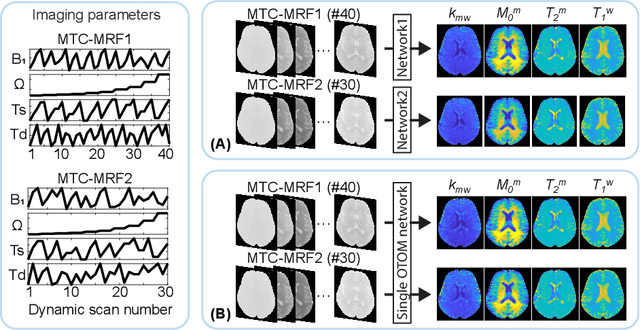
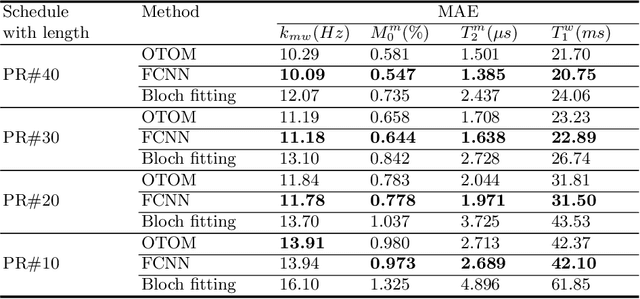
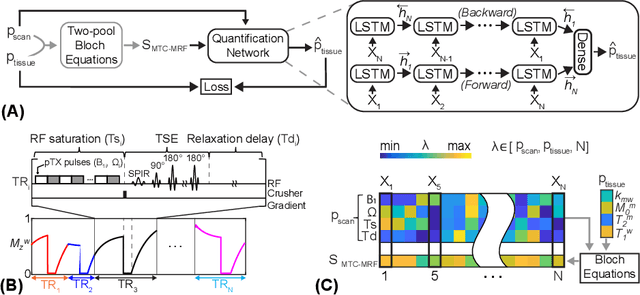

Magnetization transfer contrast magnetic resonance fingerprinting (MTC-MRF) is a novel quantitative imaging technique that simultaneously measures several tissue parameters of semisolid macromolecule and free bulk water. In this study, we propose an Only-Train-Once MR fingerprinting (OTOM) framework that estimates the free bulk water and MTC tissue parameters from MR fingerprints regardless of MRF schedule, thereby avoiding time-consuming process such as generation of training dataset and network training according to each MRF schedule. A recurrent neural network is designed to cope with two types of variants of MRF schedules: 1) various lengths and 2) various patterns. Experiments on digital phantoms and in vivo data demonstrate that our approach can achieve accurate quantification for the water and MTC parameters with multiple MRF schedules. Moreover, the proposed method is in excellent agreement with the conventional deep learning and fitting methods. The flexible OTOM framework could be an efficient tissue quantification tool for various MRF protocols.
A Survey on Learnable Evolutionary Algorithms for Scalable Multiobjective Optimization
Jun 23, 2022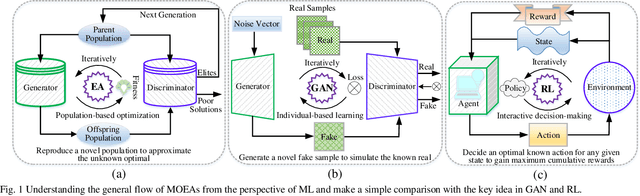
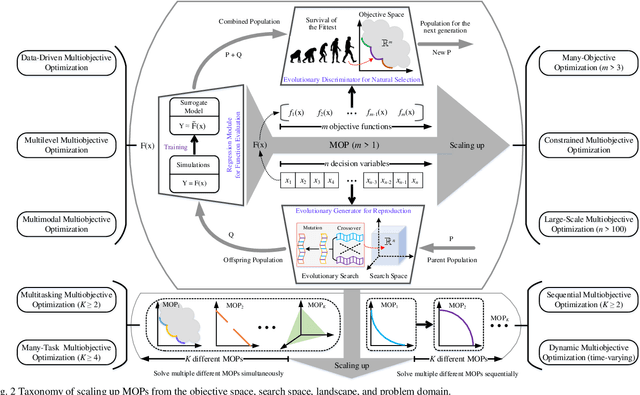
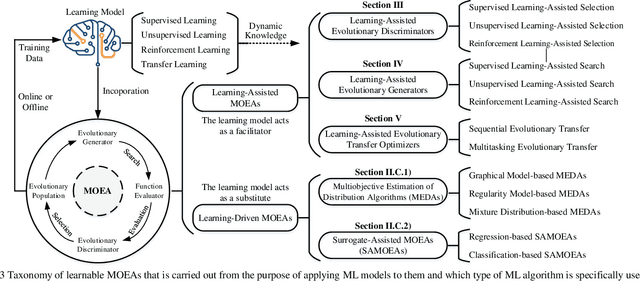
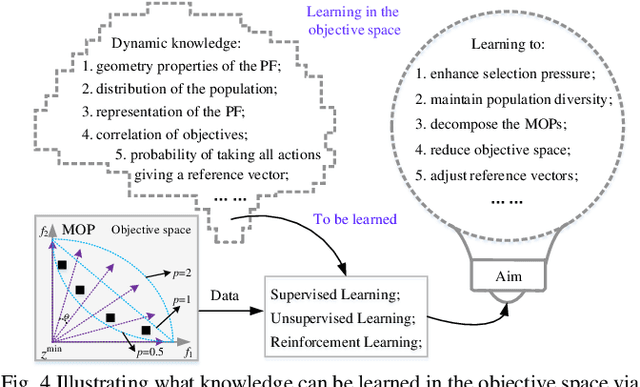
Recent decades have witnessed remarkable advancements in multiobjective evolutionary algorithms (MOEAs) that have been adopted to solve various multiobjective optimization problems (MOPs). However, these progressively improved MOEAs have not necessarily been equipped with sophisticatedly scalable and learnable problem-solving strategies that are able to cope with new and grand challenges brought by the scaling-up MOPs with continuously increasing complexity or scale from diverse aspects, mainly including expensive function evaluations, many objectives, large-scale search space, time-varying environments, and multitask. Under different scenarios, it requires divergent thinking to design new powerful MOEAs for solving them effectively. In this context, research into learnable MOEAs that arm themselves with machine learning techniques for scaling-up MOPs has received extensive attention in the field of evolutionary computation. In this paper, we begin with a taxonomy of scalable MOPs and learnable MOEAs, followed by an analysis of the challenges that scaling up MOPs pose to traditional MOEAs. Then, we synthetically overview recent advances of learnable MOEAs in solving various scaling up MOPs, focusing primarily on three attractive and promising directions (i.e., learnable evolutionary discriminators for environmental selection, learnable evolutionary generators for reproduction, and learnable evolutionary transfer for sharing or reusing optimization experience between different problem domains). The insight into learnable MOEAs held throughout this paper is offered to the readers as a reference to the general track of the efforts in this field.
Fundamentals of Wobbling and Hardware Impairments-Aware Air-to-Ground Channel Model
May 22, 2022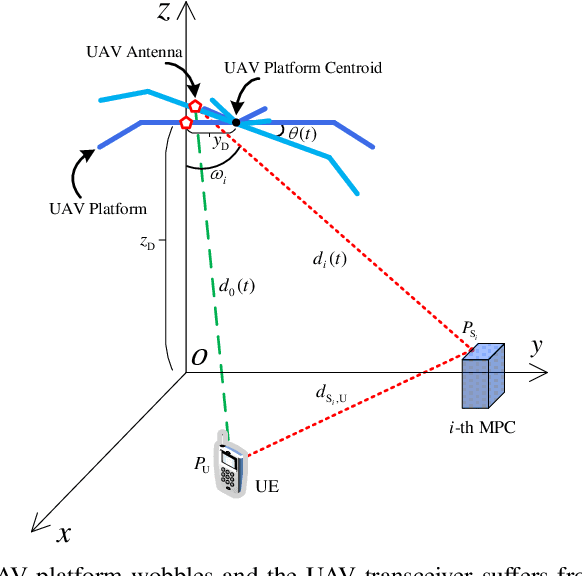
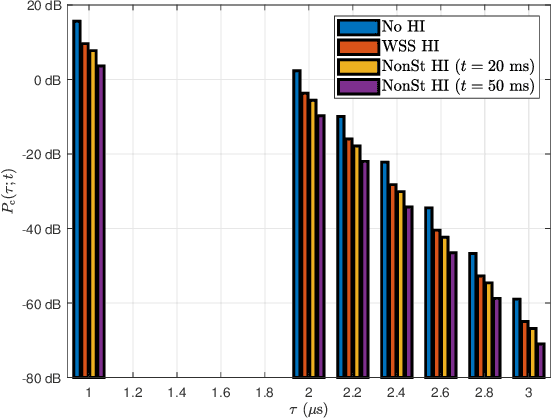
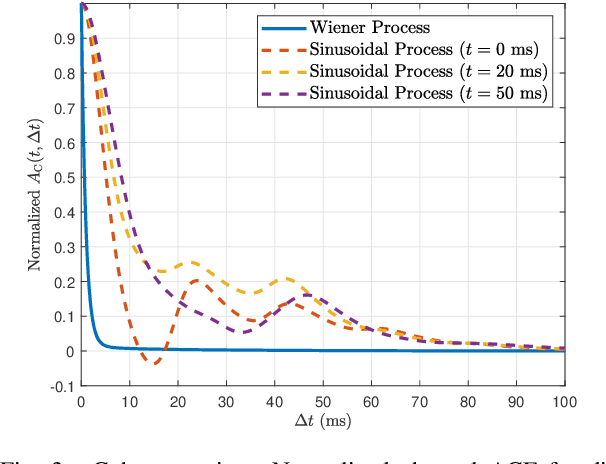
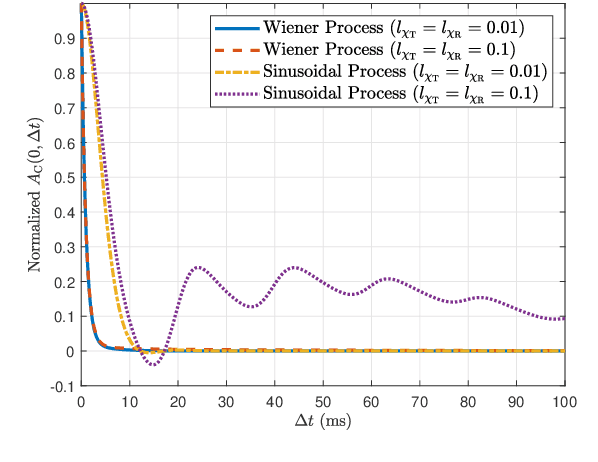
In this paper, we develop an impairments-aware air-to-ground unified channel model that incorporates the effect of both wobbling and hardware impairments, where the former is caused by random physical fluctuations of unmanned aerial vehicles (UAVs), and the latter by intrinsic radio frequency (RF) nonidealities at both the transmitter and receiver, such as phase noise, in-phase/quadrature (I/Q) imbalance, and power amplifier (PA) nonlinearity. The impact of UAV wobbling is modeled by two stochastic processes, i.e., the canonical Wiener process and the more realistic sinusoidal process. On the other hand, the aggregate impact of all hardware impairments is modeled as two multiplicative and additive distortion noise processes, which is a well-accepted model. For the sake of generality, we consider both wide-sense stationary (WSS) and nonstationary processes for the distortion noises. We then rigorously characterize the autocorrelation function (ACF) of the wireless channel, using which we provide a comprehensive analysis of four key channel-related metrics: (i) power delay profile (PDP), (ii) coherence time, (iii) coherence bandwidth, and (iv) power spectral density (PSD) of the distortion-plus-noise process. Furthermore, we evaluate these metrics with reasonable UAV wobbling and hardware impairment models to obtain useful insights. Quite noticeably, we demonstrate that even for small UAV wobbling, the coherence time severely degrades at high frequencies, which renders air-to-ground channel estimation very difficult at these frequencies. To the best of our understanding, this is the first work that characterizes the joint impact of UAV wobbling and hardware impairments on the air-to-ground wireless channel.
Faster Optimization-Based Meta-Learning Adaptation Phase
Jun 13, 2022

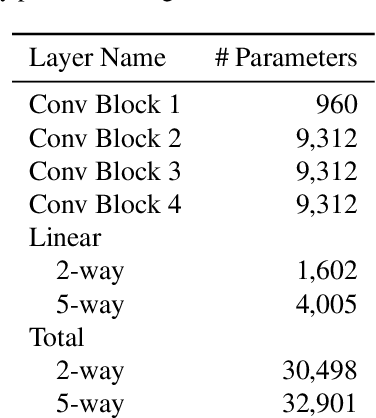
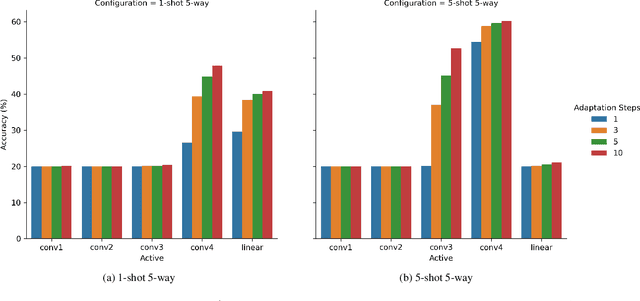
Neural networks require a large amount of annotated data to learn. Meta-learning algorithms propose a way to decrease the number of training samples to only a few. One of the most prominent optimization-based meta-learning algorithms is Model-Agnostic Meta-Learning (MAML). However, the key procedure of adaptation to new tasks in MAML is quite slow. In this work we propose an improvement to MAML meta-learning algorithm. We introduce Lambda patterns by which we restrict which weight are updated in the network during the adaptation phase. This makes it possible to skip certain gradient computations. The fastest pattern is selected given an allowed quality degradation threshold parameter. In certain cases, quality improvement is possible by a careful pattern selection. The experiments conducted have shown that via Lambda adaptation pattern selection, it is possible to significantly improve the MAML method in the following areas: adaptation time has been decreased by a factor of 3 with minimal accuracy loss; accuracy for one-step adaptation has been substantially improved.