 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Depression Diagnosis and Forecast based on Mobile Phone Sensor Data
May 10, 2022
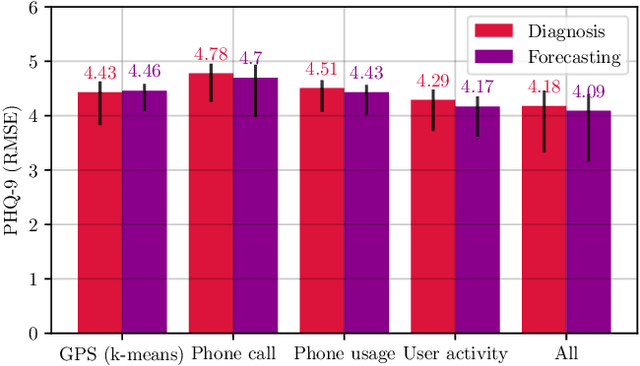
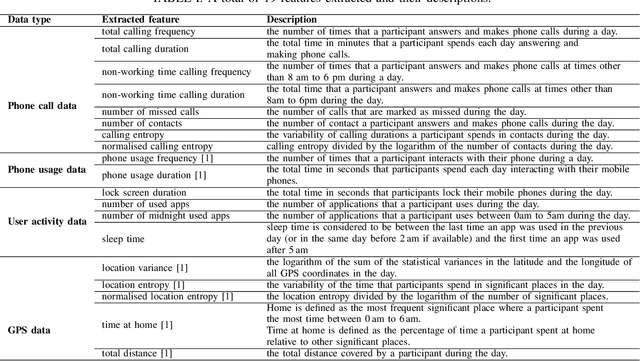

Previous studies have shown the correlation between sensor data collected from mobile phones and human depression states. Compared to the traditional self-assessment questionnaires, the passive data collected from mobile phones is easier to access and less time-consuming. In particular, passive mobile phone data can be collected on a flexible time interval, thus detecting moment-by-moment psychological changes and helping achieve earlier interventions. Moreover, while previous studies mainly focused on depression diagnosis using mobile phone data, depression forecasting has not received sufficient attention. In this work, we extract four types of passive features from mobile phone data, including phone call, phone usage, user activity, and GPS features. We implement a long short-term memory (LSTM) network in a subject-independent 10-fold cross-validation setup to model both a diagnostic and a forecasting tasks. Experimental results show that the forecasting task achieves comparable results with the diagnostic task, which indicates the possibility of forecasting depression from mobile phone sensor data. Our model achieves an accuracy of 77.0 % for major depression forecasting (binary), an accuracy of 53.7 % for depression severity forecasting (5 classes), and a best RMSE score of 4.094 (PHQ-9, range from 0 to 27).
Surgical-VQA: Visual Question Answering in Surgical Scenes using Transformer
Jun 26, 2022
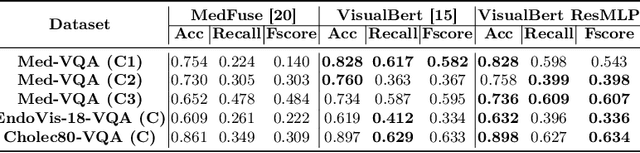
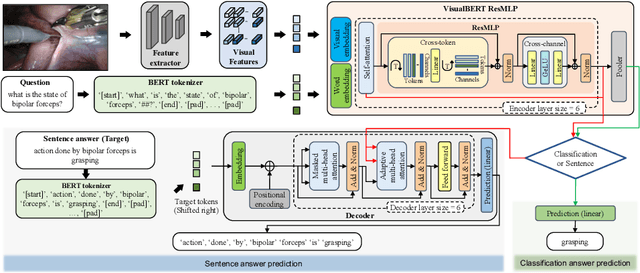
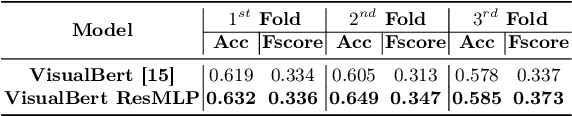
Visual question answering (VQA) in surgery is largely unexplored. Expert surgeons are scarce and are often overloaded with clinical and academic workloads. This overload often limits their time answering questionnaires from patients, medical students or junior residents related to surgical procedures. At times, students and junior residents also refrain from asking too many questions during classes to reduce disruption. While computer-aided simulators and recording of past surgical procedures have been made available for them to observe and improve their skills, they still hugely rely on medical experts to answer their questions. Having a Surgical-VQA system as a reliable 'second opinion' could act as a backup and ease the load on the medical experts in answering these questions. The lack of annotated medical data and the presence of domain-specific terms has limited the exploration of VQA for surgical procedures. In this work, we design a Surgical-VQA task that answers questionnaires on surgical procedures based on the surgical scene. Extending the MICCAI endoscopic vision challenge 2018 dataset and workflow recognition dataset further, we introduce two Surgical-VQA datasets with classification and sentence-based answers. To perform Surgical-VQA, we employ vision-text transformers models. We further introduce a residual MLP-based VisualBert encoder model that enforces interaction between visual and text tokens, improving performance in classification-based answering. Furthermore, we study the influence of the number of input image patches and temporal visual features on the model performance in both classification and sentence-based answering.
Automatic Polyp Segmentation with Multiple Kernel Dilated Convolution Network
Jun 23, 2022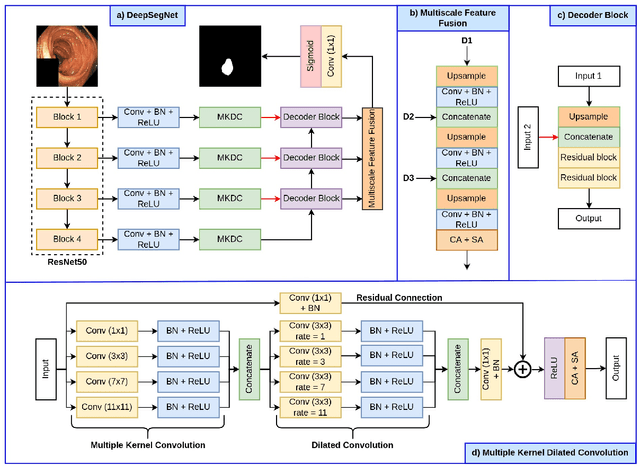
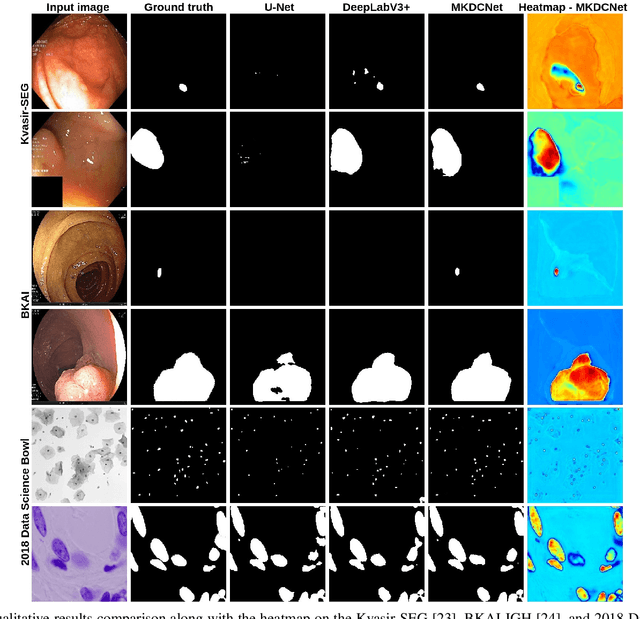
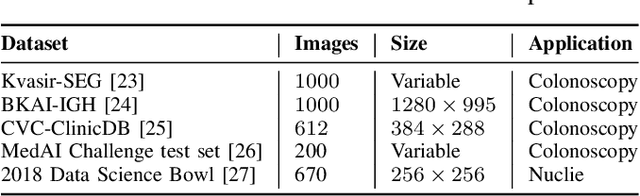
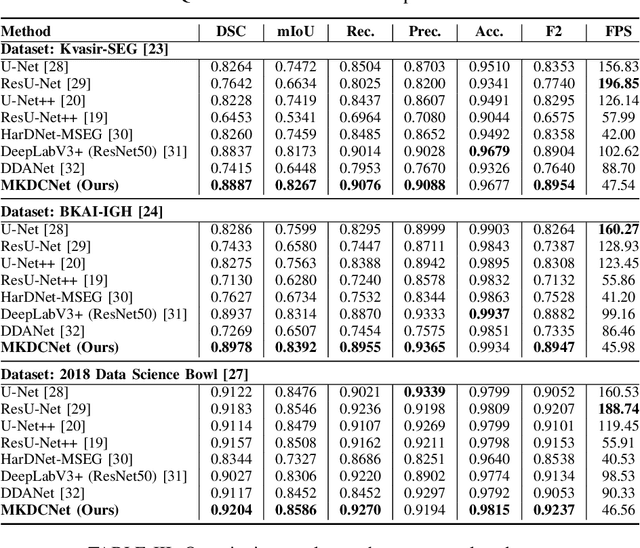
The detection and removal of precancerous polyps through colonoscopy is the primary technique for the prevention of colorectal cancer worldwide. However, the miss rate of colorectal polyp varies significantly among the endoscopists. It is well known that a computer-aided diagnosis (CAD) system can assist endoscopists in detecting colon polyps and minimize the variation among endoscopists. In this study, we introduce a novel deep learning architecture, named MKDCNet, for automatic polyp segmentation robust to significant changes in polyp data distribution. MKDCNet is simply an encoder-decoder neural network that uses the pre-trained ResNet50 as the encoder and novel multiple kernel dilated convolution (MKDC) block that expands the field of view to learn more robust and heterogeneous representation. Extensive experiments on four publicly available polyp datasets and cell nuclei dataset show that the proposed MKDCNet outperforms the state-of-the-art methods when trained and tested on the same dataset as well when tested on unseen polyp datasets from different distributions. With rich results, we demonstrated the robustness of the proposed architecture. From an efficiency perspective, our algorithm can process at (approx 45) frames per second on RTX 3090 GPU. MKDCNet can be a strong benchmark for building real-time systems for clinical colonoscopies. The code of the proposed MKDCNet is available at https://github.com/nikhilroxtomar/MKDCNet.
Indian Legal Text Summarization: A Text Normalisation-based Approach
Jun 13, 2022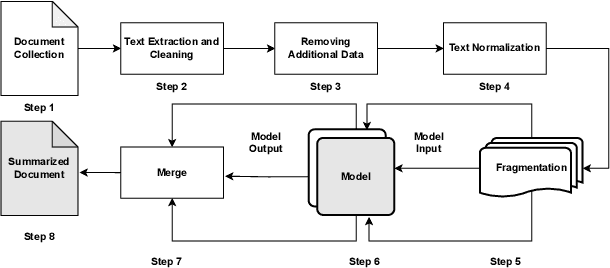
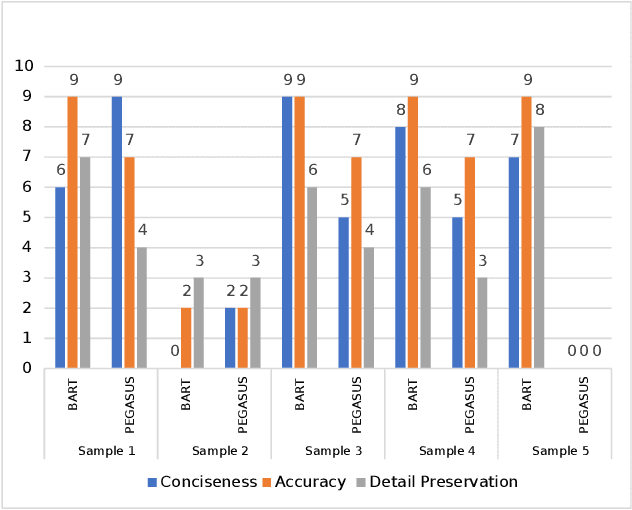
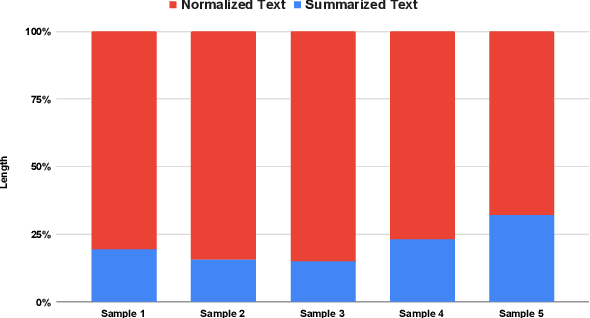

In the Indian court system, pending cases have long been a problem. There are more than 4 crore cases outstanding. Manually summarising hundreds of documents is a time-consuming and tedious task for legal stakeholders. Many state-of-the-art models for text summarization have emerged as machine learning has progressed. Domain-independent models don't do well with legal texts, and fine-tuning those models for the Indian Legal System is problematic due to a lack of publicly available datasets. To improve the performance of domain-independent models, the authors have proposed a methodology for normalising legal texts in the Indian context. The authors experimented with two state-of-the-art domain-independent models for legal text summarization, namely BART and PEGASUS. BART and PEGASUS are put through their paces in terms of extractive and abstractive summarization to understand the effectiveness of the text normalisation approach. Summarised texts are evaluated by domain experts on multiple parameters and using ROUGE metrics. It shows the proposed text normalisation approach is effective in legal texts with domain-independent models.
Convergence for score-based generative modeling with polynomial complexity
Jun 13, 2022Score-based generative modeling (SGM) is a highly successful approach for learning a probability distribution from data and generating further samples. We prove the first polynomial convergence guarantees for the core mechanic behind SGM: drawing samples from a probability density $p$ given a score estimate (an estimate of $\nabla \ln p$) that is accurate in $L^2(p)$. Compared to previous works, we do not incur error that grows exponentially in time or that suffers from a curse of dimensionality. Our guarantee works for any smooth distribution and depends polynomially on its log-Sobolev constant. Using our guarantee, we give a theoretical analysis of score-based generative modeling, which transforms white-noise input into samples from a learned data distribution given score estimates at different noise scales. Our analysis gives theoretical grounding to the observation that an annealed procedure is required in practice to generate good samples, as our proof depends essentially on using annealing to obtain a warm start at each step. Moreover, we show that a predictor-corrector algorithm gives better convergence than using either portion alone.
Square One Bias in NLP: Towards a Multi-Dimensional Exploration of the Research Manifold
Jun 20, 2022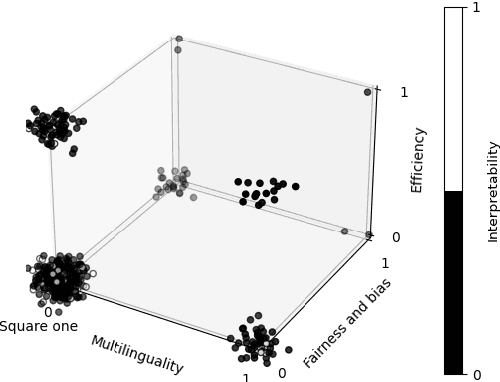
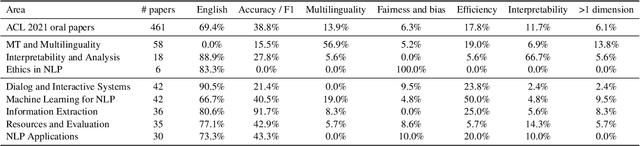
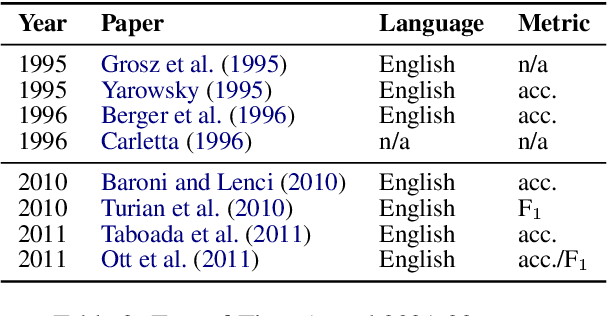

The prototypical NLP experiment trains a standard architecture on labeled English data and optimizes for accuracy, without accounting for other dimensions such as fairness, interpretability, or computational efficiency. We show through a manual classification of recent NLP research papers that this is indeed the case and refer to it as the square one experimental setup. We observe that NLP research often goes beyond the square one setup, e.g, focusing not only on accuracy, but also on fairness or interpretability, but typically only along a single dimension. Most work targeting multilinguality, for example, considers only accuracy; most work on fairness or interpretability considers only English; and so on. We show this through manual classification of recent NLP research papers and ACL Test-of-Time award recipients. Such one-dimensionality of most research means we are only exploring a fraction of the NLP research search space. We provide historical and recent examples of how the square one bias has led researchers to draw false conclusions or make unwise choices, point to promising yet unexplored directions on the research manifold, and make practical recommendations to enable more multi-dimensional research. We open-source the results of our annotations to enable further analysis at https://github.com/google-research/url-nlp
Personalized PercepNet: Real-time, Low-complexity Target Voice Separation and Enhancement
Jun 08, 2021



The presence of multiple talkers in the surrounding environment poses a difficult challenge for real-time speech communication systems considering the constraints on network size and complexity. In this paper, we present Personalized PercepNet, a real-time speech enhancement model that separates a target speaker from a noisy multi-talker mixture without compromising on complexity of the recently proposed PercepNet. To enable speaker-dependent speech enhancement, we first show how we can train a perceptually motivated speaker embedder network to produce a representative embedding vector for the given speaker. Personalized PercepNet uses the target speaker embedding as additional information to pick out and enhance only the target speaker while suppressing all other competing sounds. Our experiments show that the proposed model significantly outperforms PercepNet and other baselines, both in terms of objective speech enhancement metrics and human opinion scores.
Guided Safe Shooting: model based reinforcement learning with safety constraints
Jun 20, 2022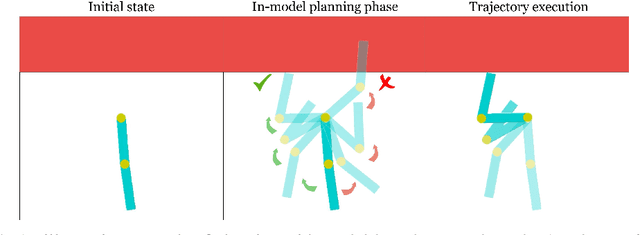
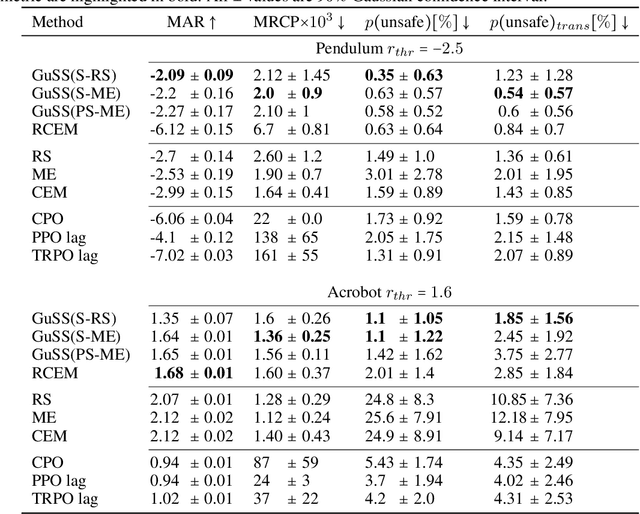
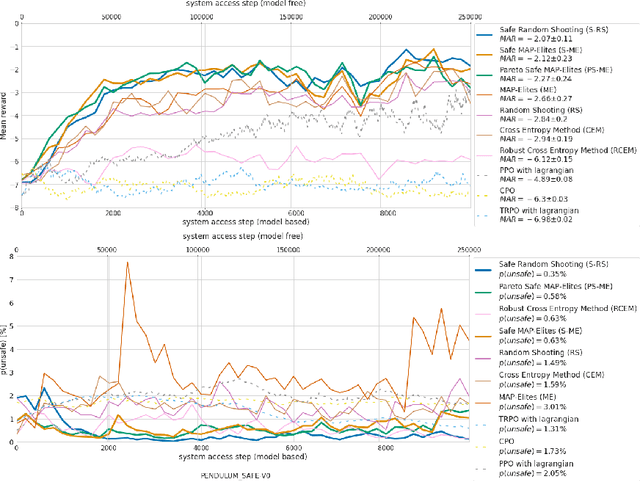
In the last decade, reinforcement learning successfully solved complex control tasks and decision-making problems, like the Go board game. Yet, there are few success stories when it comes to deploying those algorithms to real-world scenarios. One of the reasons is the lack of guarantees when dealing with and avoiding unsafe states, a fundamental requirement in critical control engineering systems. In this paper, we introduce Guided Safe Shooting (GuSS), a model-based RL approach that can learn to control systems with minimal violations of the safety constraints. The model is learned on the data collected during the operation of the system in an iterated batch fashion, and is then used to plan for the best action to perform at each time step. We propose three different safe planners, one based on a simple random shooting strategy and two based on MAP-Elites, a more advanced divergent-search algorithm. Experiments show that these planners help the learning agent avoid unsafe situations while maximally exploring the state space, a necessary aspect when learning an accurate model of the system. Furthermore, compared to model-free approaches, learning a model allows GuSS reducing the number of interactions with the real-system while still reaching high rewards, a fundamental requirement when handling engineering systems.
Graph Attention Recurrent Neural Networks for Correlated Time Series Forecasting -- Full version
Mar 22, 2021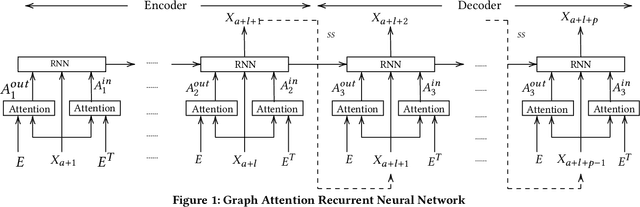
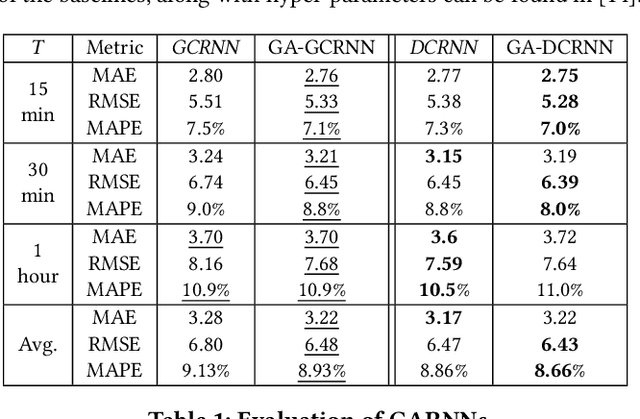
We consider a setting where multiple entities inter-act with each other over time and the time-varying statuses of the entities are represented as multiple correlated time series. For example, speed sensors are deployed in different locations in a road network, where the speed of a specific location across time is captured by the corresponding sensor as a time series, resulting in multiple speed time series from different locations, which are often correlated. To enable accurate forecasting on correlated time series, we proposes graph attention recurrent neural networks.First, we build a graph among different entities by taking into account spatial proximity and employ a multi-head attention mechanism to derive adaptive weight matrices for the graph to capture the correlations among vertices (e.g., speeds at different locations) at different timestamps. Second, we employ recurrent neural networks to take into account temporal dependency while taking into account the adaptive weight matrices learned from the first step to consider the correlations among time series.Experiments on a large real-world speed time series data set suggest that the proposed method is effective and outperforms the state-of-the-art in most settings. This manuscript provides a full version of a workshop paper [1].
ComENet: Towards Complete and Efficient Message Passing for 3D Molecular Graphs
Jun 17, 2022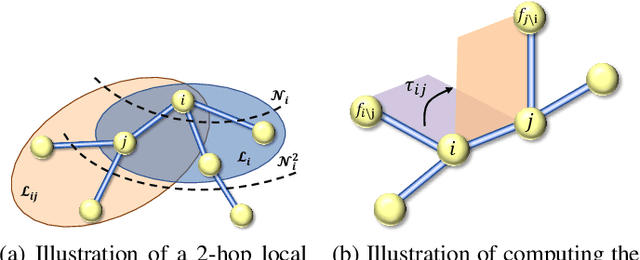

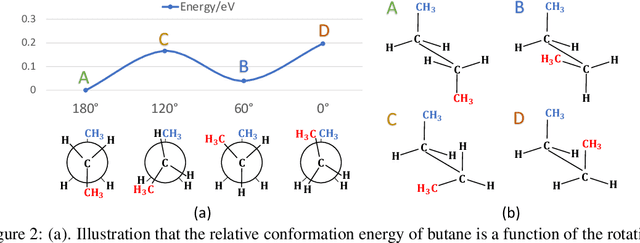

Many real-world data can be modeled as 3D graphs, but learning representations that incorporates 3D information completely and efficiently is challenging. Existing methods either use partial 3D information, or suffer from excessive computational cost. To incorporate 3D information completely and efficiently, we propose a novel message passing scheme that operates within 1-hop neighborhood. Our method guarantees full completeness of 3D information on 3D graphs by achieving global and local completeness. Notably, we propose the important rotation angles to fulfill global completeness. Additionally, we show that our method is orders of magnitude faster than prior methods. We provide rigorous proof of completeness and analysis of time complexity for our methods. As molecules are in essence quantum systems, we build the \underline{com}plete and \underline{e}fficient graph neural network (ComENet) by combing quantum inspired basis functions and the proposed message passing scheme. Experimental results demonstrate the capability and efficiency of ComENet, especially on real-world datasets that are large in both numbers and sizes of graphs. Our code is publicly available as part of the DIG library (\url{https://github.com/divelab/DIG}).