 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Convergence of FedProx: Local Dissimilarity Invariant Bounds, Non-smoothness and Beyond
Jun 10, 2022

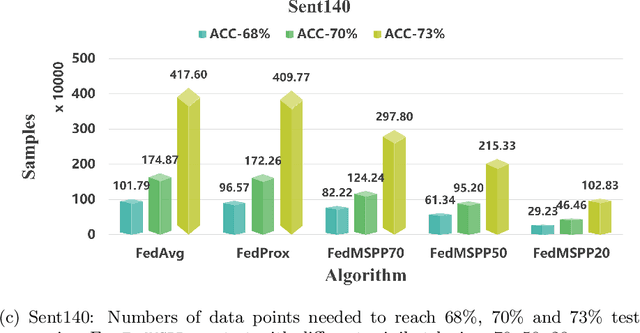
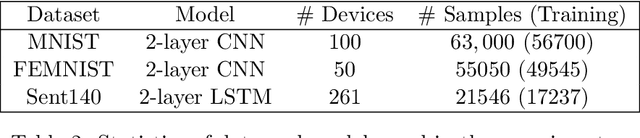
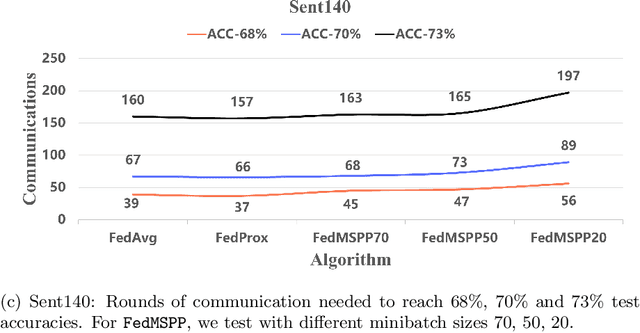
The FedProx algorithm is a simple yet powerful distributed proximal point optimization method widely used for federated learning (FL) over heterogeneous data. Despite its popularity and remarkable success witnessed in practice, the theoretical understanding of FedProx is largely underinvestigated: the appealing convergence behavior of FedProx is so far characterized under certain non-standard and unrealistic dissimilarity assumptions of local functions, and the results are limited to smooth optimization problems. In order to remedy these deficiencies, we develop a novel local dissimilarity invariant convergence theory for FedProx and its minibatch stochastic extension through the lens of algorithmic stability. As a result, we contribute to derive several new and deeper insights into FedProx for non-convex federated optimization including: 1) convergence guarantees independent on local dissimilarity type conditions; 2) convergence guarantees for non-smooth FL problems; and 3) linear speedup with respect to size of minibatch and number of sampled devices. Our theory for the first time reveals that local dissimilarity and smoothness are not must-have for FedProx to get favorable complexity bounds. Preliminary experimental results on a series of benchmark FL datasets are reported to demonstrate the benefit of minibatching for improving the sample efficiency of FedProx.
Lightweight Conditional Model Extrapolation for Streaming Data under Class-Prior Shift
Jun 10, 2022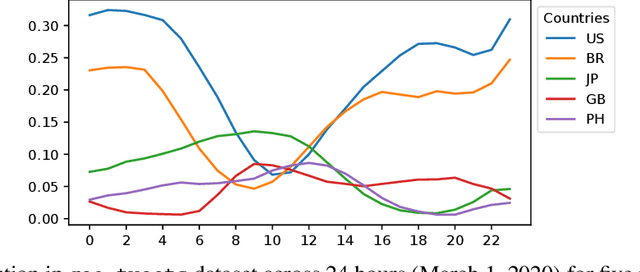
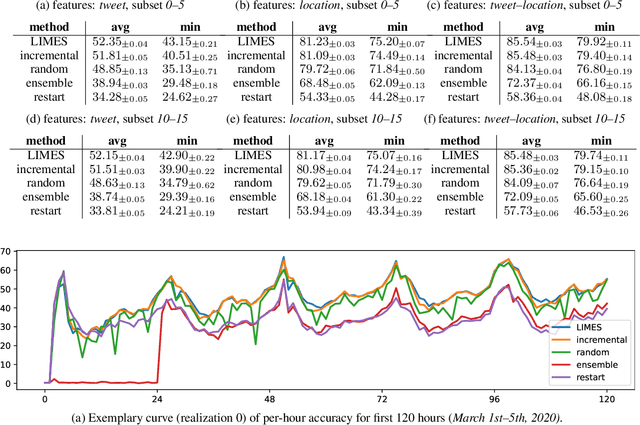
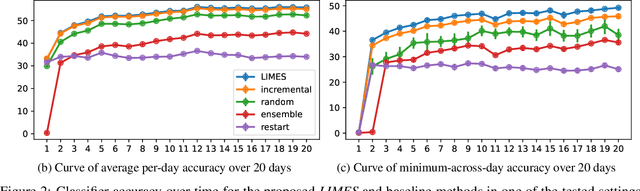
We introduce LIMES, a new method for learning with non-stationary streaming data, inspired by the recent success of meta-learning. The main idea is not to attempt to learn a single classifier that would have to work well across all occurring data distributions, nor many separate classifiers, but to exploit a hybrid strategy: we learn a single set of model parameters from which a specific classifier for any specific data distribution is derived via classifier adaptation. Assuming a multi-class classification setting with class-prior shift, the adaptation step can be performed analytically with only the classifier's bias terms being affected. Another contribution of our work is an extrapolation step that predicts suitable adaptation parameters for future time steps based on the previous data. In combination, we obtain a lightweight procedure for learning from streaming data with varying class distribution that adds no trainable parameters and almost no memory or computational overhead compared to training a single model. Experiments on a set of exemplary tasks using Twitter data show that LIMES achieves higher accuracy than alternative approaches, especially with respect to the relevant real-world metric of lowest within-day accuracy.
How Much is Enough? A Study on Diffusion Times in Score-based Generative Models
Jun 10, 2022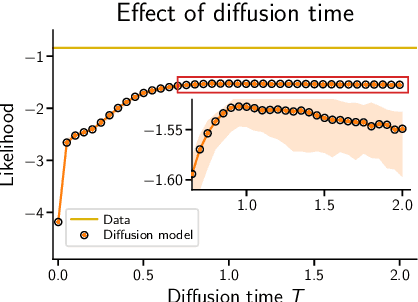
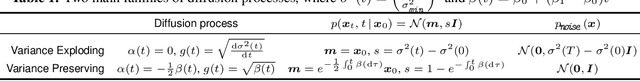

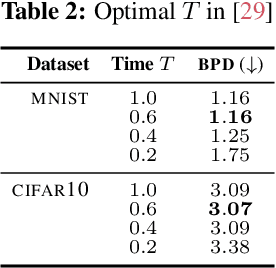
Score-based diffusion models are a class of generative models whose dynamics is described by stochastic differential equations that map noise into data. While recent works have started to lay down a theoretical foundation for these models, an analytical understanding of the role of the diffusion time T is still lacking. Current best practice advocates for a large T to ensure that the forward dynamics brings the diffusion sufficiently close to a known and simple noise distribution; however, a smaller value of T should be preferred for a better approximation of the score-matching objective and higher computational efficiency. Starting from a variational interpretation of diffusion models, in this work we quantify this trade-off, and suggest a new method to improve quality and efficiency of both training and sampling, by adopting smaller diffusion times. Indeed, we show how an auxiliary model can be used to bridge the gap between the ideal and the simulated forward dynamics, followed by a standard reverse diffusion process. Empirical results support our analysis; for image data, our method is competitive w.r.t. the state-of-the-art, according to standard sample quality metrics and log-likelihood.
Finding Patterns in Visualized Data by Adding Redundant Visual Information
May 27, 2022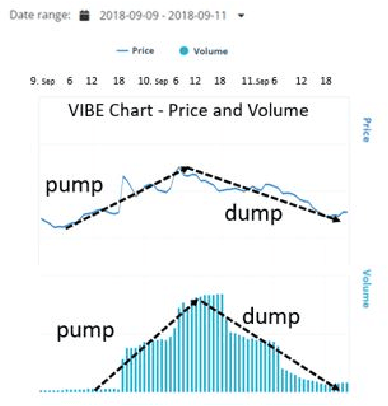


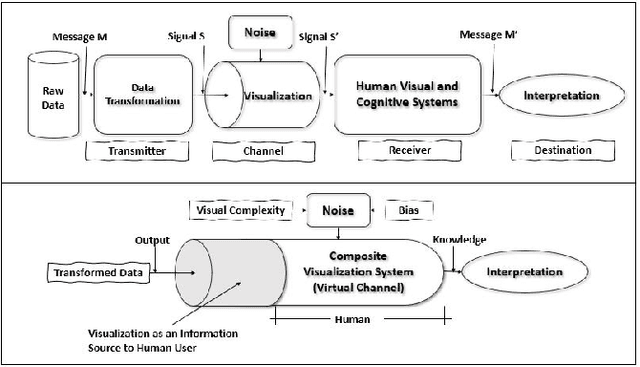
We present "PATRED", a technique that uses the addition of redundant information to facilitate the detection of specific, generally described patterns in line-charts during the visual exploration of the charts. We compared different versions of this technique, that differed in the way redundancy was added, using nine distance metrics (such as Euclidean, Pearson, Mutual Information and Jaccard) with judgments from data scientists which served as the "ground truth". Results were analyzed with correlations (R2), F1 scores and Mutual Information with the average ranking by the data scientists. Some distance metrics consistently benefit from the addition of redundant information, while others are only enhanced for specific types of data perturbations. The results demonstrate the value of adding redundancy to improve the identification of patterns in time-series data during visual exploration.
Time-Aware Tensor Decomposition for Missing Entry Prediction
Dec 16, 2020
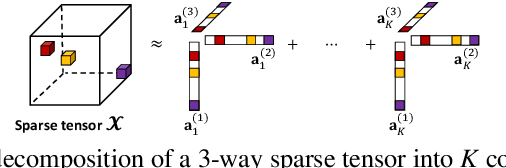
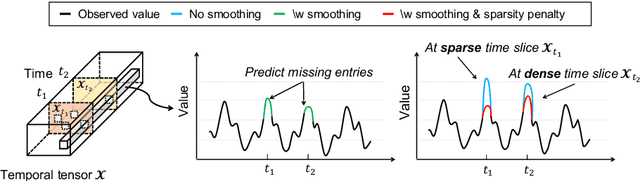

Given a time-evolving tensor with missing entries, how can we effectively factorize it for precisely predicting the missing entries? Tensor factorization has been extensively utilized for analyzing various multi-dimensional real-world data. However, existing models for tensor factorization have disregarded the temporal property for tensor factorization while most real-world data are closely related to time. Moreover, they do not address accuracy degradation due to the sparsity of time slices. The essential problems of how to exploit the temporal property for tensor decomposition and consider the sparsity of time slices remain unresolved. In this paper, we propose TATD (Time-Aware Tensor Decomposition), a novel tensor decomposition method for real-world temporal tensors. TATD is designed to exploit temporal dependency and time-varying sparsity of real-world temporal tensors. We propose a new smoothing regularization with Gaussian kernel for modeling time dependency. Moreover, we improve the performance of TATD by considering time-varying sparsity. We design an alternating optimization scheme suitable for temporal tensor factorization with our smoothing regularization. Extensive experiments show that TATD provides the state-of-the-art accuracy for decomposing temporal tensors.
Time-Aware Ancient Chinese Text Translation and Inference
Jul 07, 2021
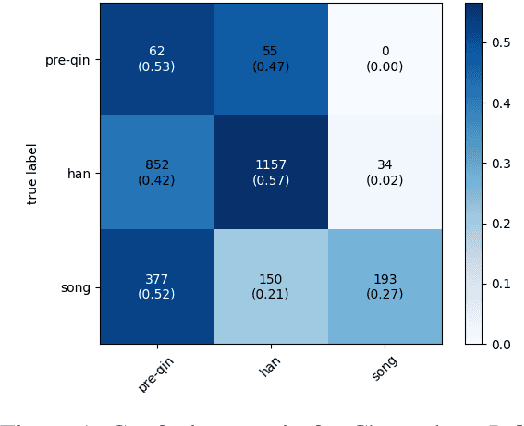
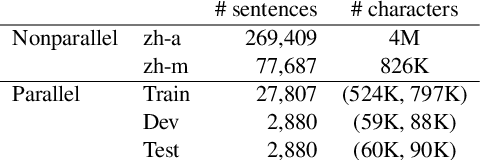
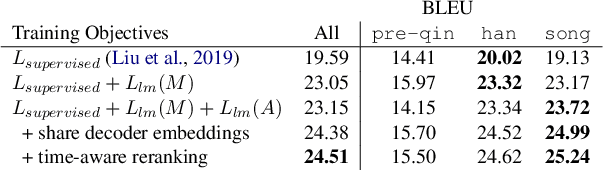
In this paper, we aim to address the challenges surrounding the translation of ancient Chinese text: (1) The linguistic gap due to the difference in eras results in translations that are poor in quality, and (2) most translations are missing the contextual information that is often very crucial to understanding the text. To this end, we improve upon past translation techniques by proposing the following: We reframe the task as a multi-label prediction task where the model predicts both the translation and its particular era. We observe that this helps to bridge the linguistic gap as chronological context is also used as auxiliary information. % As a natural step of generalization, we pivot on the modern Chinese translations to generate multilingual outputs. %We show experimentally the efficacy of our framework in producing quality translation outputs and also validate our framework on a collected task-specific parallel corpus. We validate our framework on a parallel corpus annotated with chronology information and show experimentally its efficacy in producing quality translation outputs. We release both the code and the data https://github.com/orina1123/time-aware-ancient-text-translation for future research.
Filtered Noise Shaping for Time Domain Room Impulse Response Estimation From Reverberant Speech
Jul 15, 2021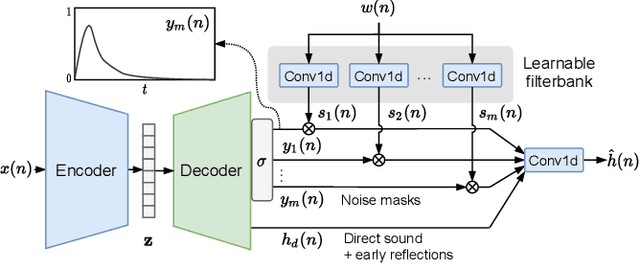
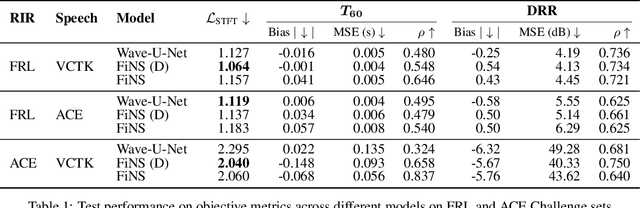
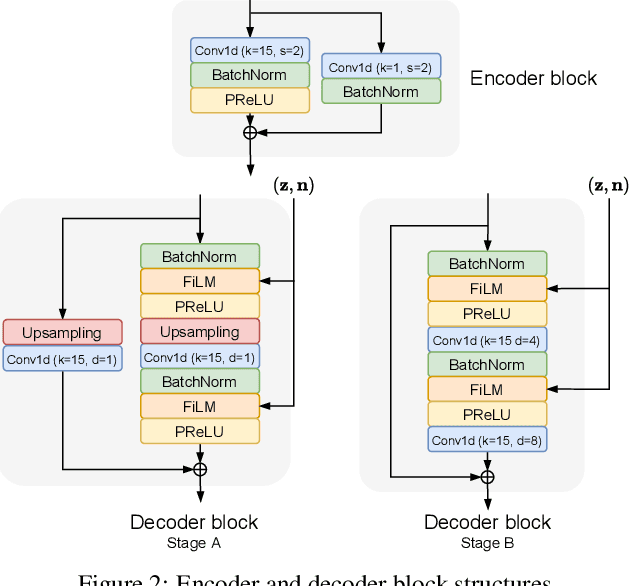
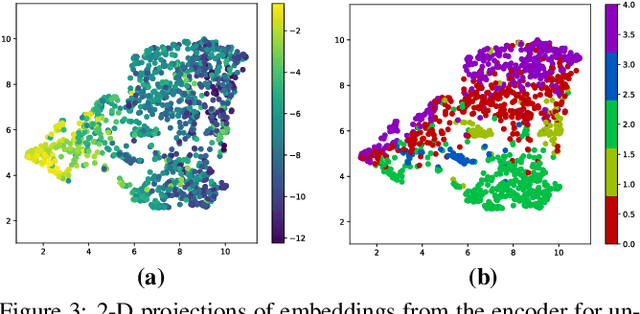
Deep learning approaches have emerged that aim to transform an audio signal so that it sounds as if it was recorded in the same room as a reference recording, with applications both in audio post-production and augmented reality. In this work, we propose FiNS, a Filtered Noise Shaping network that directly estimates the time domain room impulse response (RIR) from reverberant speech. Our domain-inspired architecture features a time domain encoder and a filtered noise shaping decoder that models the RIR as a summation of decaying filtered noise signals, along with direct sound and early reflection components. Previous methods for acoustic matching utilize either large models to transform audio to match the target room or predict parameters for algorithmic reverberators. Instead, blind estimation of the RIR enables efficient and realistic transformation with a single convolution. An evaluation demonstrates our model not only synthesizes RIRs that match parameters of the target room, such as the $T_{60}$ and DRR, but also more accurately reproduces perceptual characteristics of the target room, as shown in a listening test when compared to deep learning baselines.
Stochastic Conservative Contextual Linear Bandits
Mar 29, 2022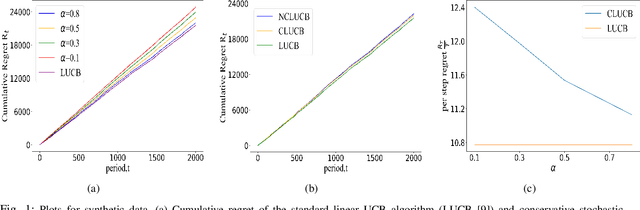
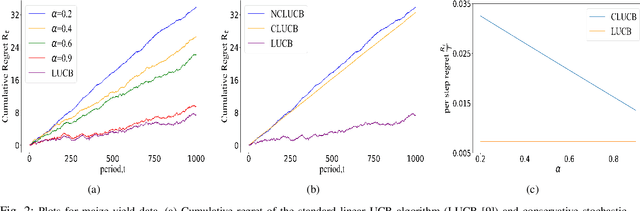
Many physical systems have underlying safety considerations that require that the strategy deployed ensures the satisfaction of a set of constraints. Further, often we have only partial information on the state of the system. We study the problem of safe real-time decision making under uncertainty. In this paper, we formulate a conservative stochastic contextual bandit formulation for real-time decision making when an adversary chooses a distribution on the set of possible contexts and the learner is subject to certain safety/performance constraints. The learner observes only the context distribution and the exact context is unknown, and the goal is to develop an algorithm that selects a sequence of optimal actions to maximize the cumulative reward without violating the safety constraints at any time step. By leveraging the UCB algorithm for this setting, we propose a conservative linear UCB algorithm for stochastic bandits with context distribution. We prove an upper bound on the regret of the algorithm and show that it can be decomposed into three terms: (i) an upper bound for the regret of the standard linear UCB algorithm, (ii) a constant term (independent of time horizon) that accounts for the loss of being conservative in order to satisfy the safety constraint, and (ii) a constant term (independent of time horizon) that accounts for the loss for the contexts being unknown and only the distribution being known. To validate the performance of our approach we perform extensive simulations on synthetic data and on real-world maize data collected through the Genomes to Fields (G2F) initiative.
Image Generation with Multimodal Priors using Denoising Diffusion Probabilistic Models
Jun 10, 2022



Image synthesis under multi-modal priors is a useful and challenging task that has received increasing attention in recent years. A major challenge in using generative models to accomplish this task is the lack of paired data containing all modalities (i.e. priors) and corresponding outputs. In recent work, a variational auto-encoder (VAE) model was trained in a weakly supervised manner to address this challenge. Since the generative power of VAEs is usually limited, it is difficult for this method to synthesize images belonging to complex distributions. To this end, we propose a solution based on a denoising diffusion probabilistic models to synthesise images under multi-model priors. Based on the fact that the distribution over each time step in the diffusion model is Gaussian, in this work we show that there exists a closed-form expression to the generate the image corresponds to the given modalities. The proposed solution does not require explicit retraining for all modalities and can leverage the outputs of individual modalities to generate realistic images according to different constraints. We conduct studies on two real-world datasets to demonstrate the effectiveness of our approach
Extensive Study of Multiple Deep Neural Networks for Complex Random Telegraph Signals
May 31, 2022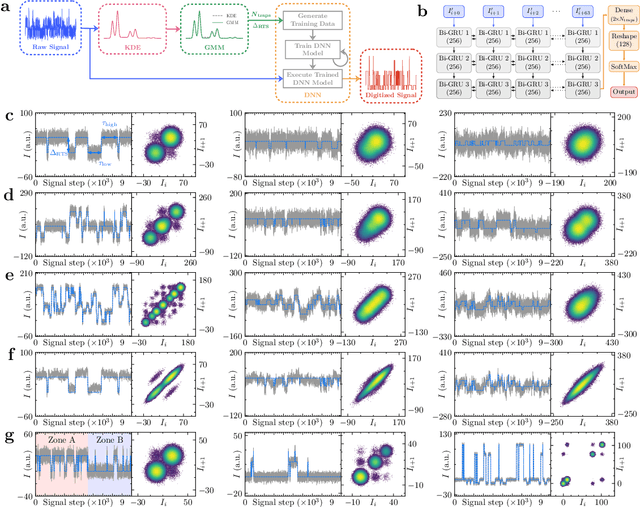
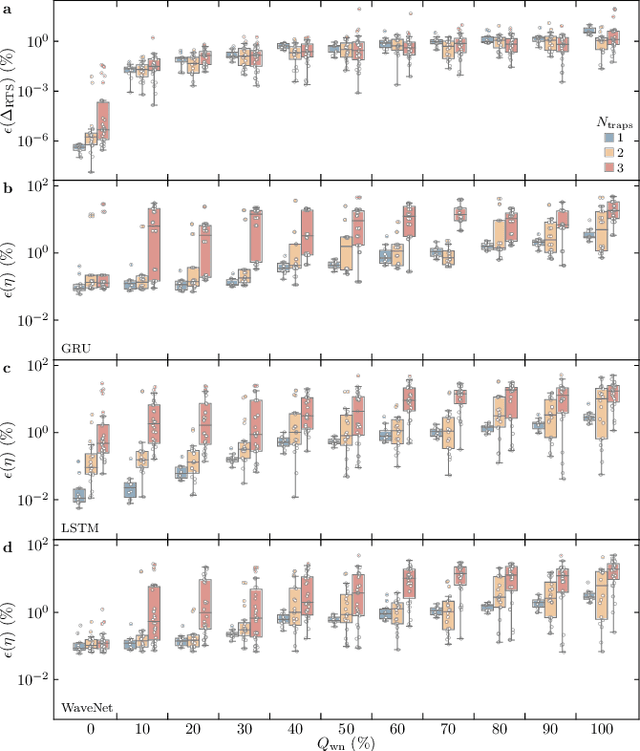
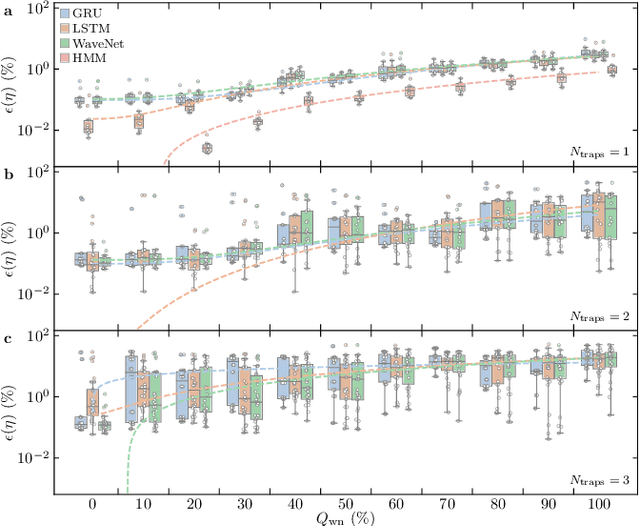
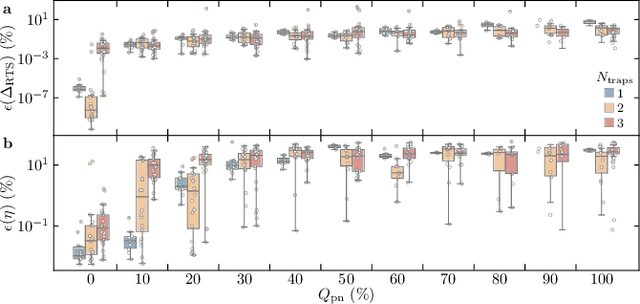
Time-fluctuating signals are ubiquitous and diverse in many physical, chemical, and biological systems, among which random telegraph signals (RTSs) refer to a series of instantaneous switching events between two discrete levels from single-particle movements. Reliable RTS analyses are crucial prerequisite to identify underlying mechanisms related to performance sensitivity. When numerous levels partake, complex patterns of multilevel RTSs occur, making their quantitative analysis exponentially difficult, hereby systematic approaches are found elusive. Here, we present a three-step analysis protocol via progressive knowledge-transfer, where the outputs of early step are passed onto a subsequent step. Especially, to quantify complex RTSs, we build three deep neural network architectures that can process temporal data well and demonstrate the model accuracy extensively with a large dataset of different RTS types affected by controlling background noise size. Our protocol offers structured schemes to quantify complex RTSs from which meaningful interpretation and inference can ensue.