 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Critical Regularizations for Neural Surface Reconstruction in the Wild
Jun 07, 2022
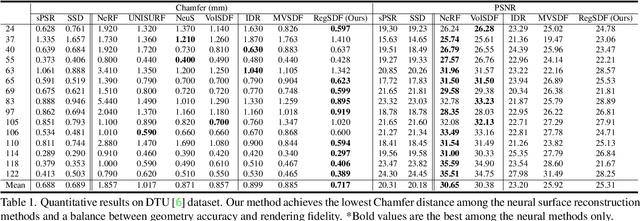

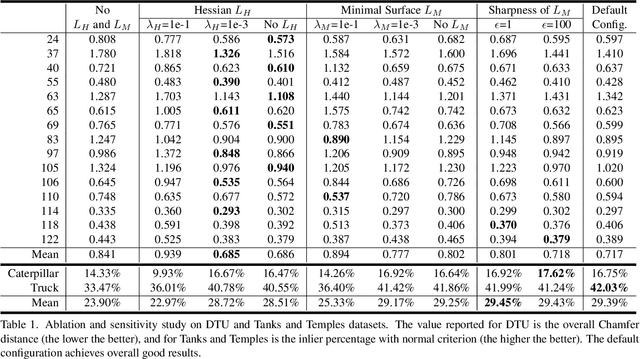
Neural implicit functions have recently shown promising results on surface reconstructions from multiple views. However, current methods still suffer from excessive time complexity and poor robustness when reconstructing unbounded or complex scenes. In this paper, we present RegSDF, which shows that proper point cloud supervisions and geometry regularizations are sufficient to produce high-quality and robust reconstruction results. Specifically, RegSDF takes an additional oriented point cloud as input, and optimizes a signed distance field and a surface light field within a differentiable rendering framework. We also introduce the two critical regularizations for this optimization. The first one is the Hessian regularization that smoothly diffuses the signed distance values to the entire distance field given noisy and incomplete input. And the second one is the minimal surface regularization that compactly interpolates and extrapolates the missing geometry. Extensive experiments are conducted on DTU, BlendedMVS, and Tanks and Temples datasets. Compared with recent neural surface reconstruction approaches, RegSDF is able to reconstruct surfaces with fine details even for open scenes with complex topologies and unstructured camera trajectories.
Online Deep Clustering with Video Track Consistency
Jun 07, 2022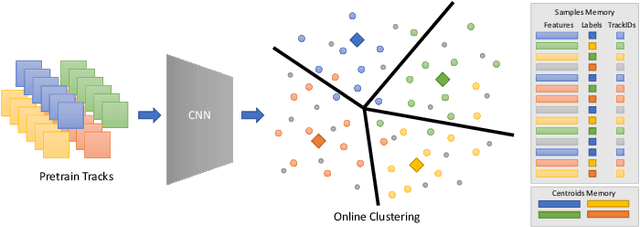
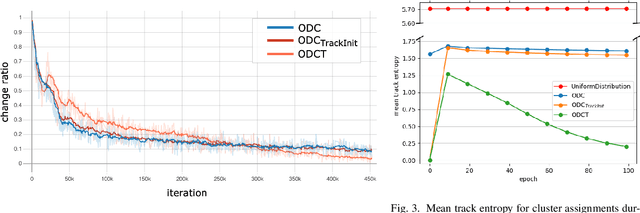


Several unsupervised and self-supervised approaches have been developed in recent years to learn visual features from large-scale unlabeled datasets. Their main drawback however is that these methods are hardly able to recognize visual features of the same object if it is simply rotated or the perspective of the camera changes. To overcome this limitation and at the same time exploit a useful source of supervision, we take into account video object tracks. Following the intuition that two patches in a track should have similar visual representations in a learned feature space, we adopt an unsupervised clustering-based approach and constrain such representations to be labeled as the same category since they likely belong to the same object or object part. Experimental results on two downstream tasks on different datasets demonstrate the effectiveness of our Online Deep Clustering with Video Track Consistency (ODCT) approach compared to prior work, which did not leverage temporal information. In addition we show that exploiting an unsupervised class-agnostic, yet noisy, track generator yields to better accuracy compared to relying on costly and precise track annotations.
Deep Reinforcement Learning-Based Adaptive IRS Control with Limited Feedback Codebooks
May 07, 2022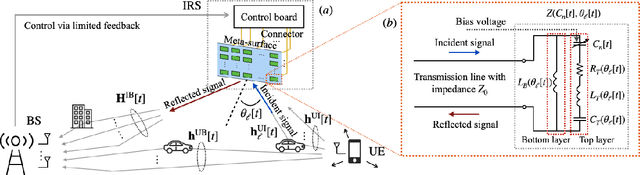

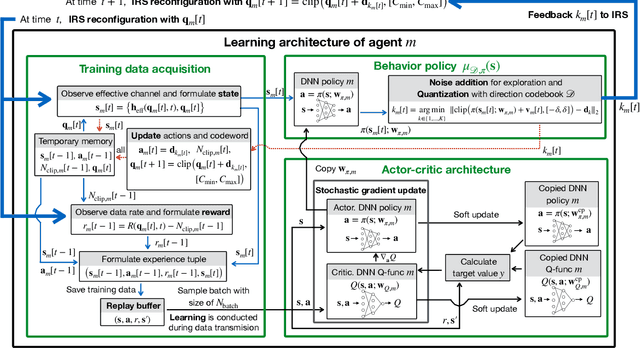
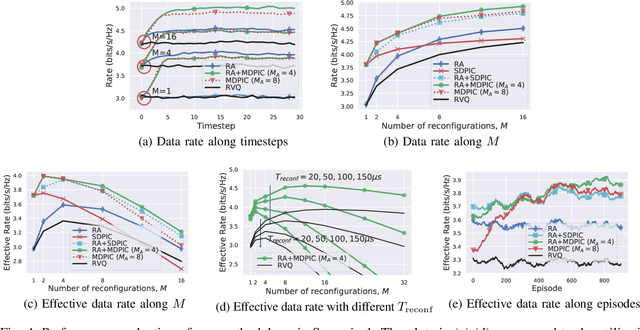
Intelligent reflecting surfaces (IRS) consist of configurable meta-atoms, which can alter the wireless propagation environment through design of their reflection coefficients. We consider adaptive IRS control in the practical setting where (i) the IRS reflection coefficients are attained by adjusting tunable elements embedded in the meta-atoms, (ii) the IRS reflection coefficients are affected by the incident angles of the incoming signals, (iii) the IRS is deployed in multi-path, time-varying channels, and (iv) the feedback link from the base station (BS) to the IRS has a low data rate. Conventional optimization-based IRS control protocols, which rely on channel estimation and conveying the optimized variables to the IRS, are not practical in this setting due to the difficulty of channel estimation and the low data rate of the feedback channel. To address these challenges, we develop a novel adaptive codebook-based limited feedback protocol to control the IRS. We propose two solutions for adaptive IRS codebook design: (i) random adjacency (RA), which utilizes correlations across the channel realizations, and (ii) deep neural network policy-based IRS control (DPIC), which is based on a deep reinforcement learning. Numerical evaluations show that the data rate and average data rate over one coherence time are improved substantially by the proposed schemes.
Regression Trees on Grassmann Manifold for Adapting Reduced-Order Models
Jun 22, 2022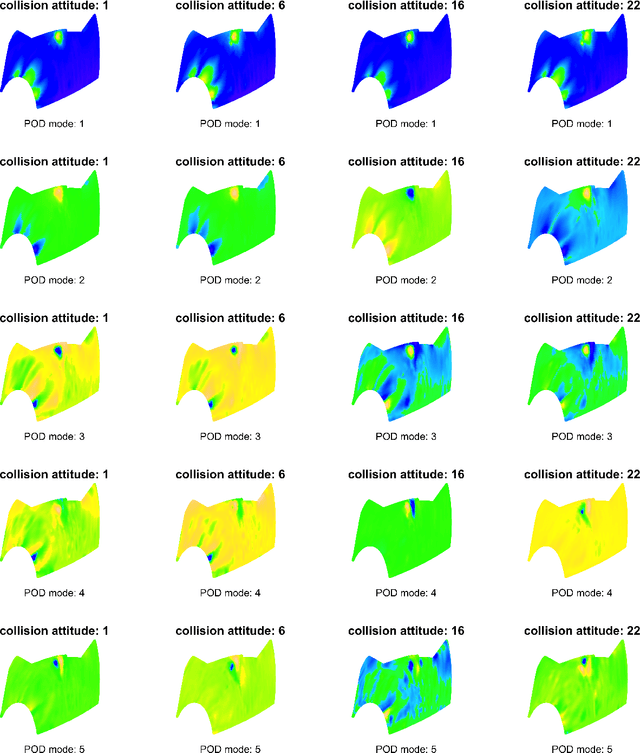
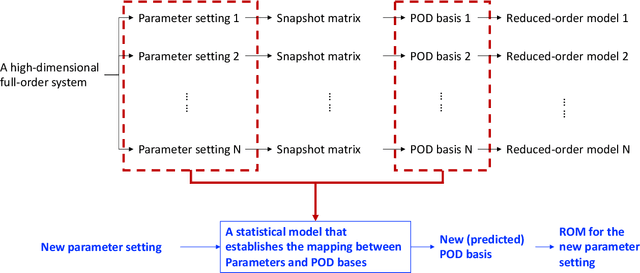
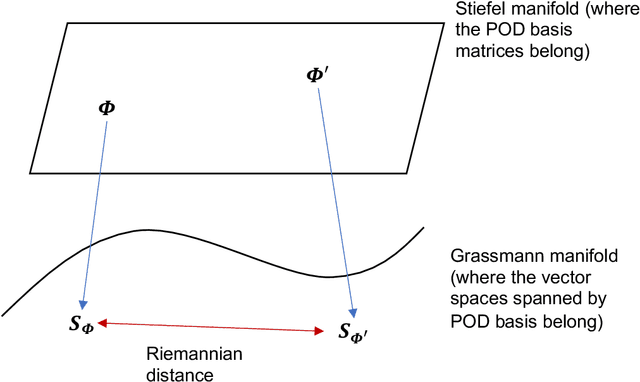
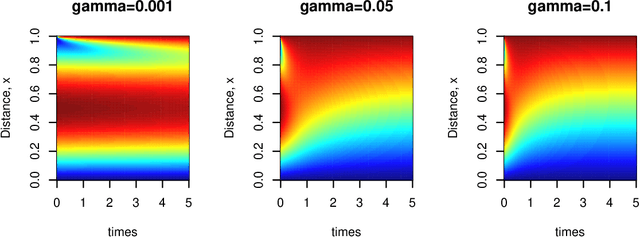
Low dimensional and computationally less expensive Reduced-Order Models (ROMs) have been widely used to capture the dominant behaviors of high-dimensional systems. A ROM can be obtained, using the well-known Proper Orthogonal Decomposition (POD), by projecting the full-order model to a subspace spanned by modal basis modes which are learned from experimental, simulated or observational data, i.e., training data. However, the optimal basis can change with the parameter settings. When a ROM, constructed using the POD basis obtained from training data, is applied to new parameter settings, the model often lacks robustness against the change of parameters in design, control, and other real-time operation problems. This paper proposes to use regression trees on Grassmann Manifold to learn the mapping between parameters and POD bases that span the low-dimensional subspaces onto which full-order models are projected. Motivated by the fact that a subspace spanned by a POD basis can be viewed as a point in the Grassmann manifold, we propose to grow a tree by repeatedly splitting the tree node to maximize the Riemannian distance between the two subspaces spanned by the predicted POD bases on the left and right daughter nodes. Five numerical examples are presented to comprehensively demonstrate the performance of the proposed method, and compare the proposed tree-based method to the existing interpolation method for POD basis and the use of global POD basis. The results show that the proposed tree-based method is capable of establishing the mapping between parameters and POD bases, and thus adapt ROMs for new parameters.
Rainbow-link: Beam-Alignment-Free and Grant-Free mmW Multiple Access using True-Time-Delay Array
Aug 21, 2021
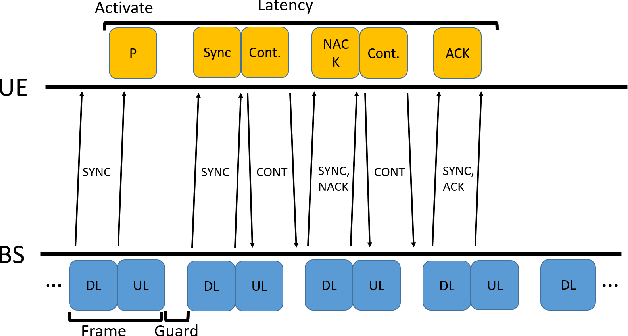
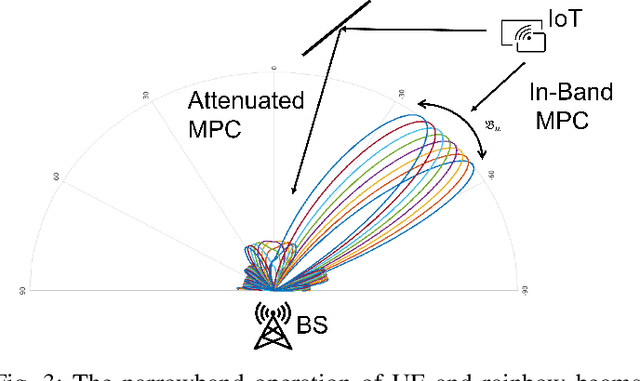
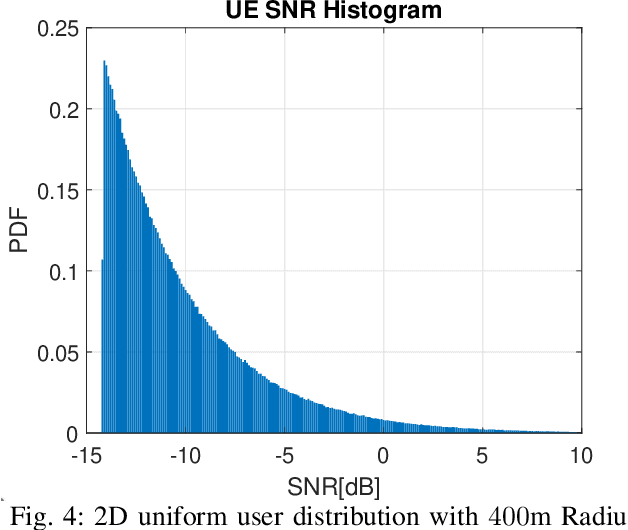
In this paper we propose a novel millimeter wave (mmW) multiple access method that exploits unique frequency dependent beamforming capabilities of True Time Delay (TTD) array architecture. The proposed protocol combines a contentionbased grant-free access and orthogonal frequency-division multiple access (OFDMA) scheme for uplink machine type communications. By exploiting abundant time-frequency resource blocks in mmW spectrum, we design a simple protocol that can achieve low collision rate and high network reliability for short packets and sporadic transmissions. We analyze the impact of various system parameters on system performance during synchronization and contention period. We exploit unique advantages of frequency dependent beamforming, referred as rainbow beam, to eliminate beam training overhead and analyze its impact on rates, latency, and coverage. The proposed system and protocol can flexibly accommodate different low latency applications with moderate rate requirements for a very large number of narrowband single antenna devices. By harnessing abundant resources in mmW spectrum and beamforming gain of TTD arrays rainbow link based system can simultaneously satisfy ultra-reliability and massive multiple access requirements.
Attack Techniques and Threat Identification for Vulnerabilities
Jun 22, 2022
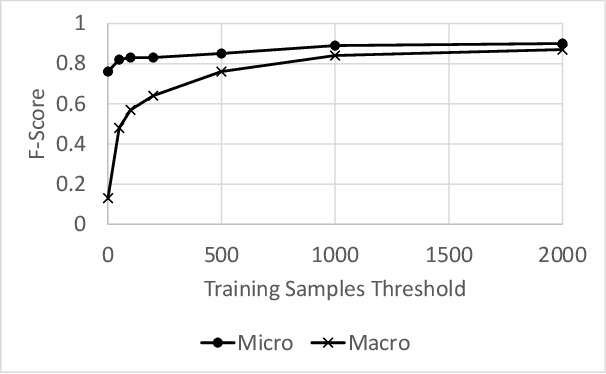
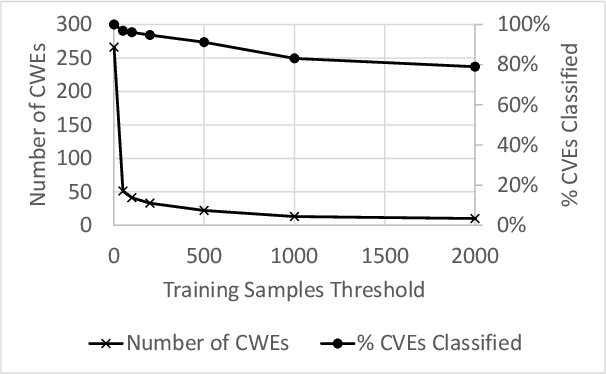
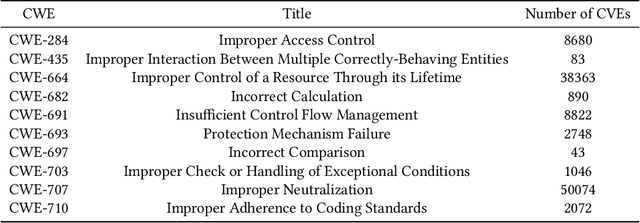
Modern organizations struggle with insurmountable number of vulnerabilities that are discovered and reported by their network and application vulnerability scanners. Therefore, prioritization and focus become critical, to spend their limited time on the highest risk vulnerabilities. In doing this, it is important for these organizations not only to understand the technical descriptions of the vulnerabilities, but also to gain insights into attackers' perspectives. In this work, we use machine learning and natural language processing techniques, as well as several publicly available data sets to provide an explainable mapping of vulnerabilities to attack techniques and threat actors. This work provides new security intelligence, by predicting which attack techniques are most likely to be used to exploit a given vulnerability and which threat actors are most likely to conduct the exploitation. Lack of labeled data and different vocabularies make mapping vulnerabilities to attack techniques at scale a challenging problem that cannot be addressed easily using supervised or unsupervised (similarity search) learning techniques. To solve this problem, we first map the vulnerabilities to a standard set of common weaknesses, and then common weaknesses to the attack techniques. This approach yields a Mean Reciprocal Rank (MRR) of 0.95, an accuracy comparable with those reported for state-of-the-art systems. Our solution has been deployed to IBM Security X-Force Red Vulnerability Management Services, and in production since 2021. The solution helps security practitioners to assist customers to manage and prioritize their vulnerabilities, providing them with an explainable mapping of vulnerabilities to attack techniques and threat actors
Tomography of time-dependent quantum spin networks with machine learning
Mar 15, 2021
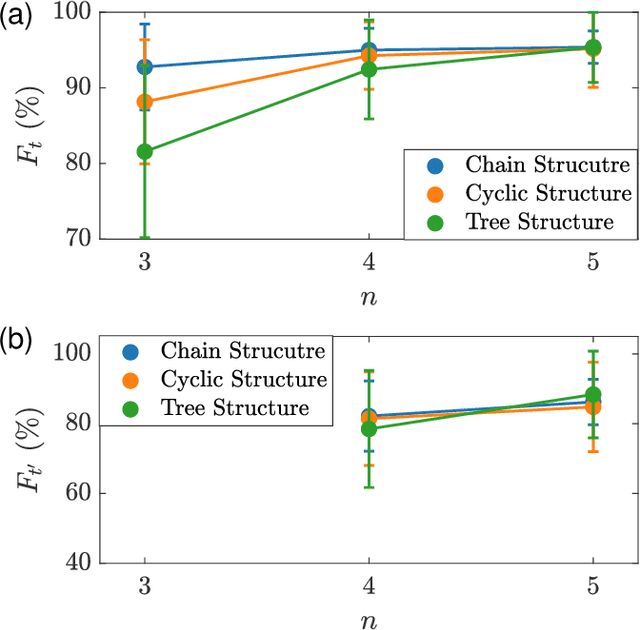
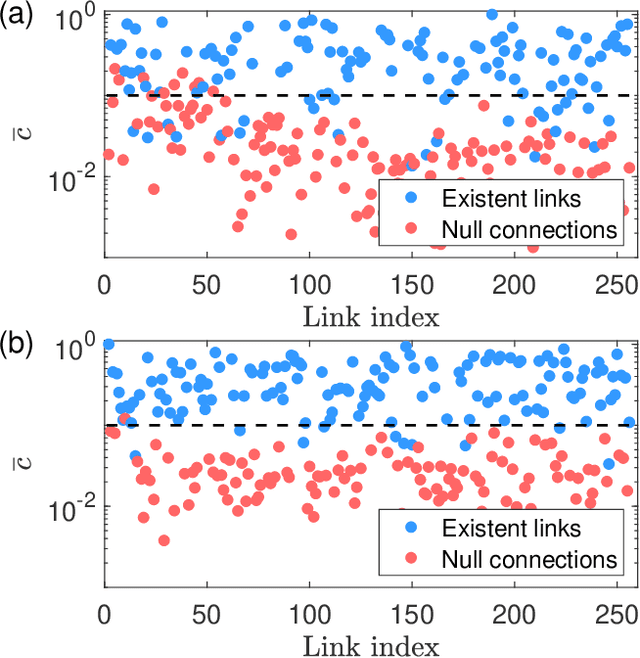
Interacting spin networks are fundamental to quantum computing. Data-based tomography of time-independent spin networks has been achieved, but an open challenge is to ascertain the structures of time-dependent spin networks using time series measurements taken locally from a small subset of the spins. Physically, the dynamical evolution of a spin network under time-dependent driving or perturbation is described by the Heisenberg equation of motion. Motivated by this basic fact, we articulate a physics-enhanced machine learning framework whose core is Heisenberg neural networks. In particular, we develop a deep learning algorithm according to some physics motivated loss function based on the Heisenberg equation, which "forces" the neural network to follow the quantum evolution of the spin variables. We demonstrate that, from local measurements, not only the local Hamiltonian can be recovered but the Hamiltonian reflecting the interacting structure of the whole system can also be faithfully reconstructed. We test our Heisenberg neural machine on spin networks of a variety of structures. In the extreme case where measurements are taken from only one spin, the achieved tomography fidelity values can reach about 90%. The developed machine learning framework is applicable to any time-dependent systems whose quantum dynamical evolution is governed by the Heisenberg equation of motion.
Shape registration in the time of transformers
Jun 28, 2021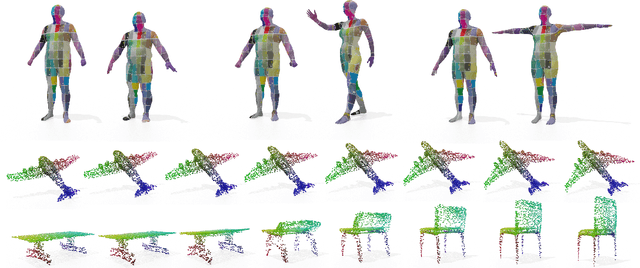

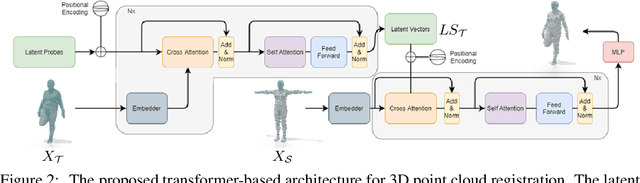
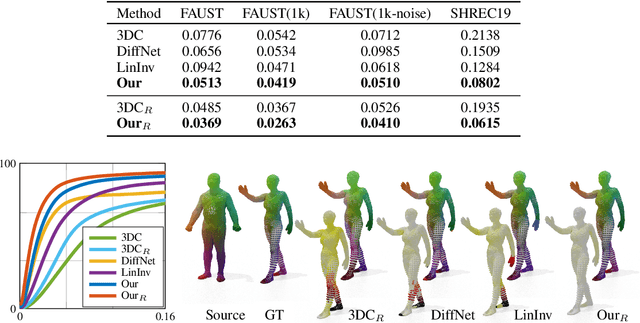
In this paper, we propose a transformer-based procedure for the efficient registration of non-rigid 3D point clouds. The proposed approach is data-driven and adopts for the first time the transformer architecture in the registration task. Our method is general and applies to different settings. Given a fixed template with some desired properties (e.g. skinning weights or other animation cues), we can register raw acquired data to it, thereby transferring all the template properties to the input geometry. Alternatively, given a pair of shapes, our method can register the first onto the second (or vice-versa), obtaining a high-quality dense correspondence between the two. In both contexts, the quality of our results enables us to target real applications such as texture transfer and shape interpolation. Furthermore, we also show that including an estimation of the underlying density of the surface eases the learning process. By exploiting the potential of this architecture, we can train our model requiring only a sparse set of ground truth correspondences ($10\sim20\%$ of the total points). The proposed model and the analysis that we perform pave the way for future exploration of transformer-based architectures for registration and matching applications. Qualitative and quantitative evaluations demonstrate that our pipeline outperforms state-of-the-art methods for deformable and unordered 3D data registration on different datasets and scenarios.
On Convergence of FedProx: Local Dissimilarity Invariant Bounds, Non-smoothness and Beyond
Jun 10, 2022
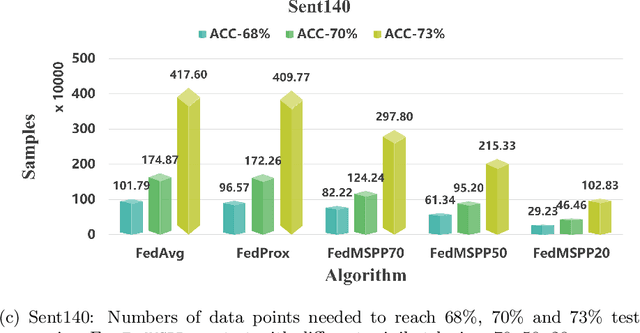
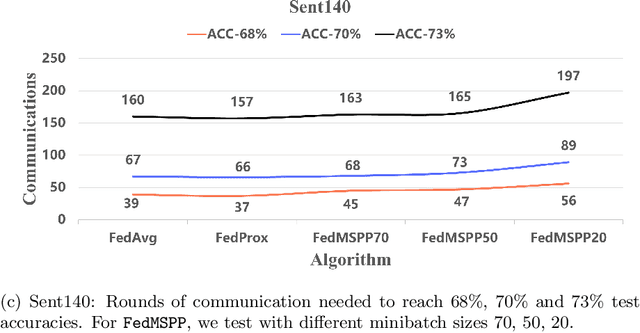
The FedProx algorithm is a simple yet powerful distributed proximal point optimization method widely used for federated learning (FL) over heterogeneous data. Despite its popularity and remarkable success witnessed in practice, the theoretical understanding of FedProx is largely underinvestigated: the appealing convergence behavior of FedProx is so far characterized under certain non-standard and unrealistic dissimilarity assumptions of local functions, and the results are limited to smooth optimization problems. In order to remedy these deficiencies, we develop a novel local dissimilarity invariant convergence theory for FedProx and its minibatch stochastic extension through the lens of algorithmic stability. As a result, we contribute to derive several new and deeper insights into FedProx for non-convex federated optimization including: 1) convergence guarantees independent on local dissimilarity type conditions; 2) convergence guarantees for non-smooth FL problems; and 3) linear speedup with respect to size of minibatch and number of sampled devices. Our theory for the first time reveals that local dissimilarity and smoothness are not must-have for FedProx to get favorable complexity bounds. Preliminary experimental results on a series of benchmark FL datasets are reported to demonstrate the benefit of minibatching for improving the sample efficiency of FedProx.
FREDA: Flexible Relation Extraction Data Annotation
Apr 14, 2022
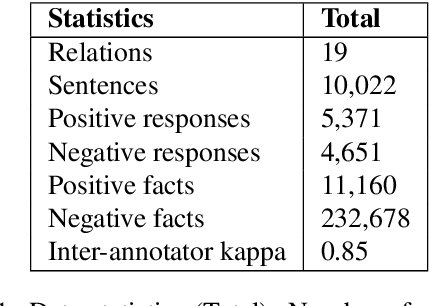
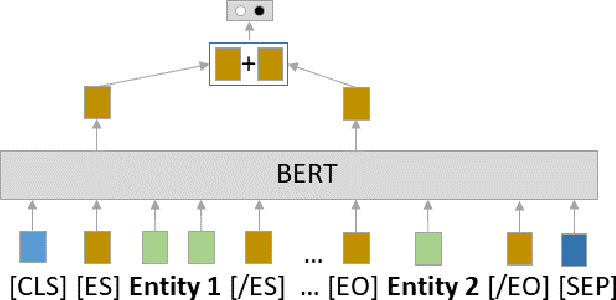
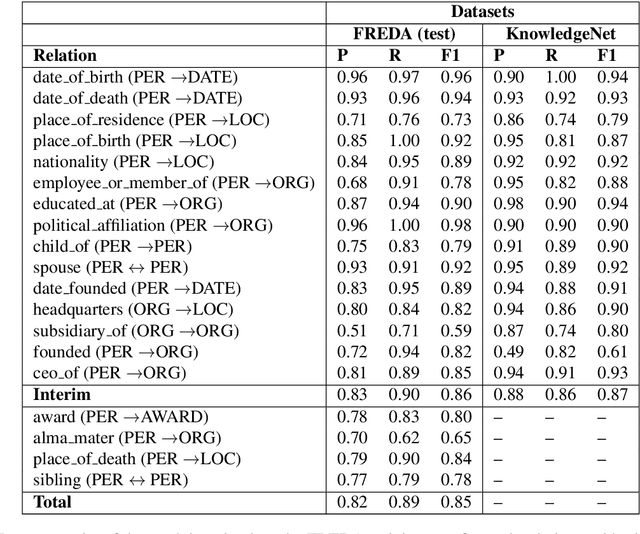
To effectively train accurate Relation Extraction models, sufficient and properly labeled data is required. Adequately labeled data is difficult to obtain and annotating such data is a tricky undertaking. Previous works have shown that either accuracy has to be sacrificed or the task is extremely time-consuming, if done accurately. We are proposing an approach in order to produce high-quality datasets for the task of Relation Extraction quickly. Neural models, trained to do Relation Extraction on the created datasets, achieve very good results and generalize well to other datasets. In our study, we were able to annotate 10,022 sentences for 19 relations in a reasonable amount of time, and trained a commonly used baseline model for each relation.