 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Local SGD Optimizes Overparameterized Neural Networks in Polynomial Time
Jul 22, 2021
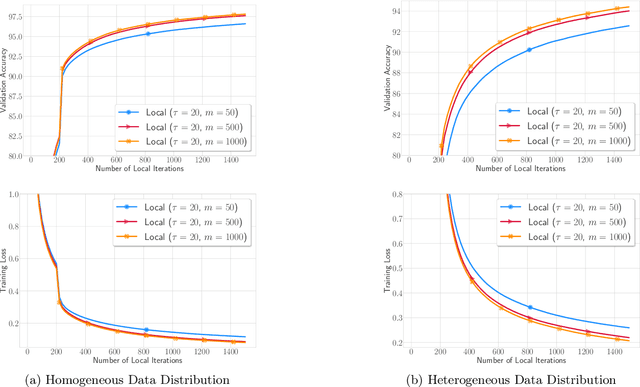
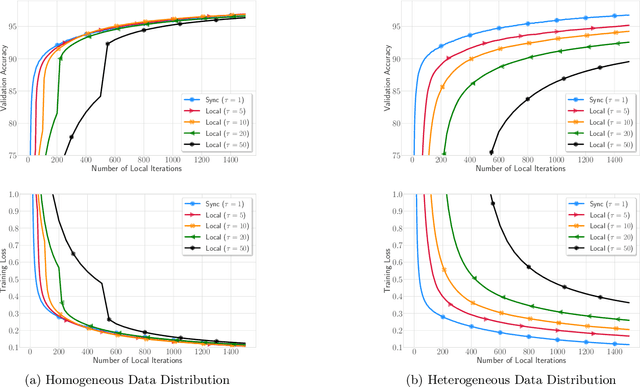
In this paper we prove that Local (S)GD (or FedAvg) can optimize two-layer neural networks with Rectified Linear Unit (ReLU) activation function in polynomial time. Despite the established convergence theory of Local SGD on optimizing general smooth functions in communication-efficient distributed optimization, its convergence on non-smooth ReLU networks still eludes full theoretical understanding. The key property used in many Local SGD analysis on smooth function is gradient Lipschitzness, so that the gradient on local models will not drift far away from that on averaged model. However, this decent property does not hold in networks with non-smooth ReLU activation function. We show that, even though ReLU network does not admit gradient Lipschitzness property, the difference between gradients on local models and average model will not change too much, under the dynamics of Local SGD. We validate our theoretical results via extensive experiments. This work is the first to show the convergence of Local SGD on non-smooth functions, and will shed lights on the optimization theory of federated training of deep neural networks.
Towards a Rigorous Evaluation of Explainability for Multivariate Time Series
Apr 06, 2021
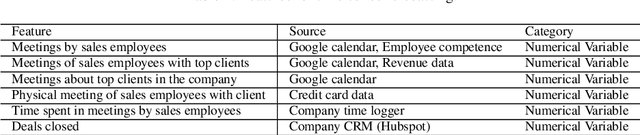
Machine learning-based systems are rapidly gaining popularity and in-line with that there has been a huge research surge in the field of explainability to ensure that machine learning models are reliable, fair, and can be held liable for their decision-making process. Explainable Artificial Intelligence (XAI) methods are typically deployed to debug black-box machine learning models but in comparison to tabular, text, and image data, explainability in time series is still relatively unexplored. The aim of this study was to achieve and evaluate model agnostic explainability in a time series forecasting problem. This work focused on proving a solution for a digital consultancy company aiming to find a data-driven approach in order to understand the effect of their sales related activities on the sales deals closed. The solution involved framing the problem as a time series forecasting problem to predict the sales deals and the explainability was achieved using two novel model agnostic explainability techniques, Local explainable model-agnostic explanations (LIME) and Shapley additive explanations (SHAP) which were evaluated using human evaluation of explainability. The results clearly indicate that the explanations produced by LIME and SHAP greatly helped lay humans in understanding the predictions made by the machine learning model. The presented work can easily be extended to any time
Towards Using Promises for Multi-Agent Cooperation in Goal Reasoning
Jun 20, 2022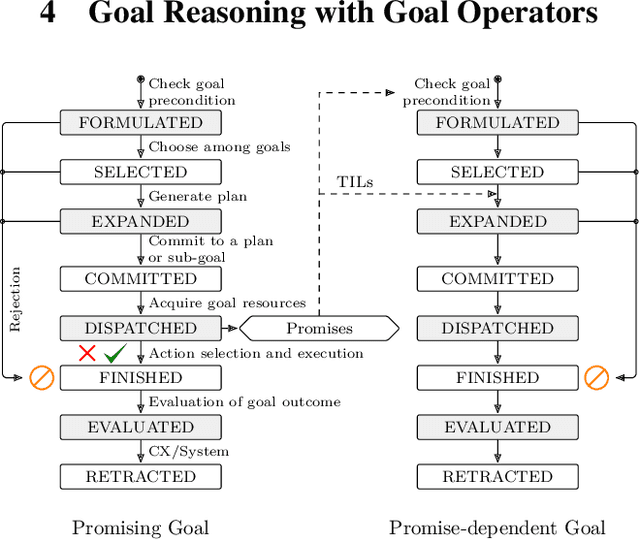

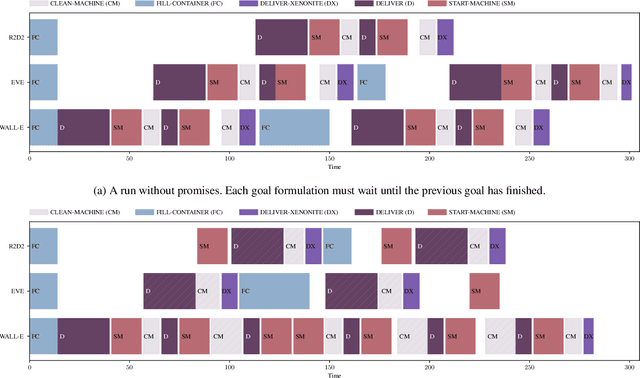
Reasoning and planning for mobile robots is a challenging problem, as the world evolves over time and thus the robot's goals may change. One technique to tackle this problem is goal reasoning, where the agent not only reasons about its actions, but also about which goals to pursue. While goal reasoning for single agents has been researched extensively, distributed, multi-agent goal reasoning comes with additional challenges, especially in a distributed setting. In such a context, some form of coordination is necessary to allow for cooperative behavior. Previous goal reasoning approaches share the agent's world model with the other agents, which already enables basic cooperation. However, the agent's goals, and thus its intentions, are typically not shared. In this paper, we present a method to tackle this limitation. Extending an existing goal reasoning framework, we propose enabling cooperative behavior between multiple agents through promises, where an agent may promise that certain facts will be true at some point in the future. Sharing these promises allows other agents to not only consider the current state of the world, but also the intentions of other agents when deciding on which goal to pursue next. We describe how promises can be incorporated into the goal life cycle, a commonly used goal refinement mechanism. We then show how promises can be used when planning for a particular goal by connecting them to timed initial literals (TILs) from PDDL planning. Finally, we evaluate our prototypical implementation in a simplified logistics scenario.
Analysis Social Sparsity Audio Declipper
May 20, 2022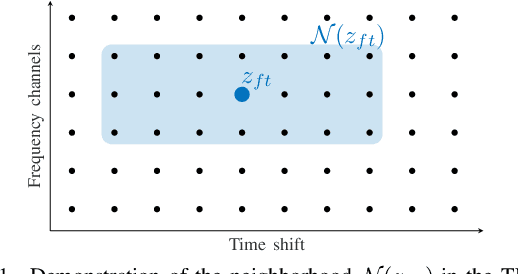
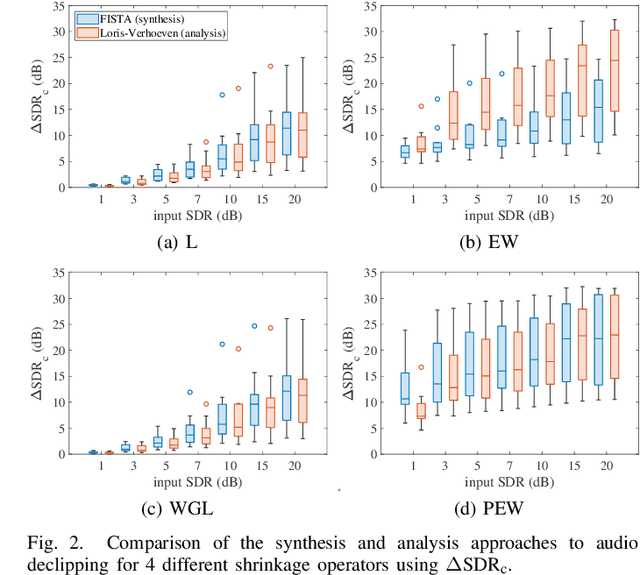
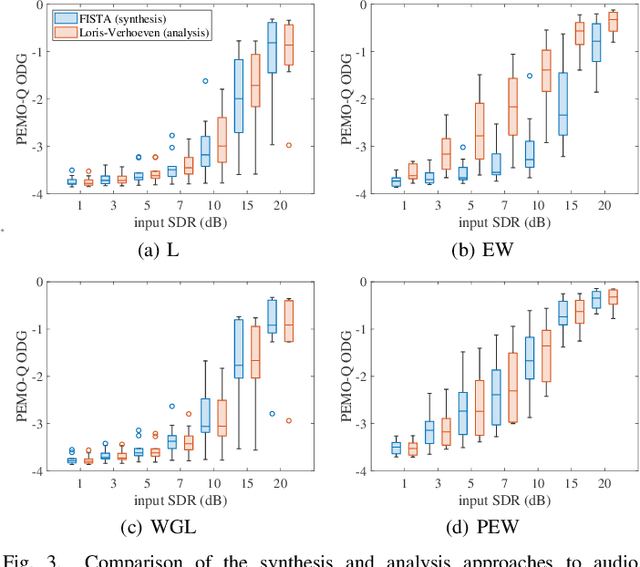
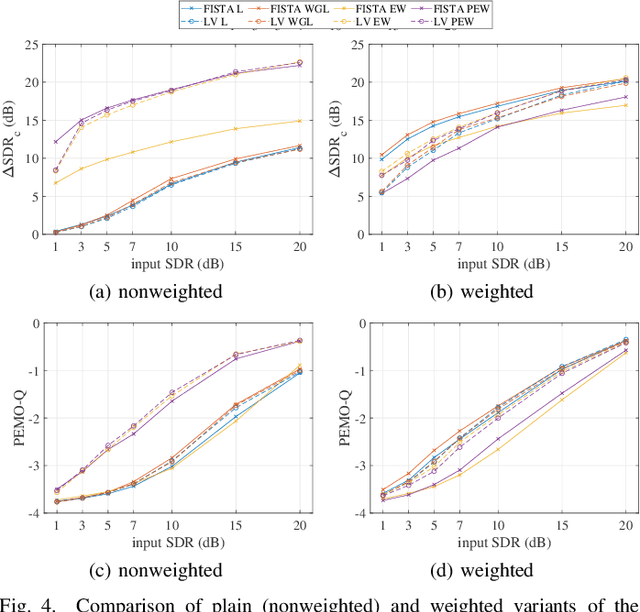
We develop the analysis (cosparse) variant of the popular audio declipping algorithm of Siedenburg et al. Furthermore, we extend it by the possibility of weighting the time-frequency coefficients. We examine the audio reconstruction performance of several combinations of weights and shrinkage operators. We show that weights improve the reconstruction quality in some cases; however, the overall scores achieved by the non-weighted are not surpassed. Yet, the analysis Empirical Wiener (EW) shrinkage was able to reach the quality of a computationally more expensive competitor, the Persistent Empirical Wiener (PEW). Moreover, the proposed analysis variant using PEW slightly outperforms the synthesis counterpart in terms of an auditory-motivated metric.
CS$^2$: A Controllable and Simultaneous Synthesizer of Images and Annotations with Minimal Human Intervention
Jun 20, 2022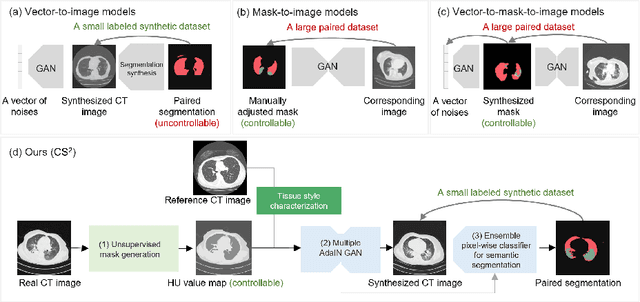
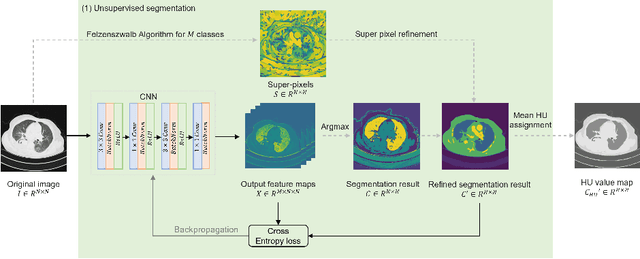

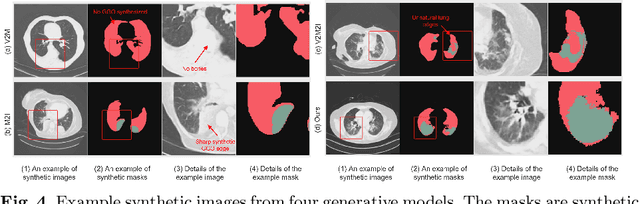
The destitution of image data and corresponding expert annotations limit the training capacities of AI diagnostic models and potentially inhibit their performance. To address such a problem of data and label scarcity, generative models have been developed to augment the training datasets. Previously proposed generative models usually require manually adjusted annotations (e.g., segmentation masks) or need pre-labeling. However, studies have found that these pre-labeling based methods can induce hallucinating artifacts, which might mislead the downstream clinical tasks, while manual adjustment could be onerous and subjective. To avoid manual adjustment and pre-labeling, we propose a novel controllable and simultaneous synthesizer (dubbed CS$^2$) in this study to generate both realistic images and corresponding annotations at the same time. Our CS$^2$ model is trained and validated using high resolution CT (HRCT) data collected from COVID-19 patients to realize an efficient infections segmentation with minimal human intervention. Our contributions include 1) a conditional image synthesis network that receives both style information from reference CT images and structural information from unsupervised segmentation masks, and 2) a corresponding segmentation mask synthesis network to automatically segment these synthesized images simultaneously. Our experimental studies on HRCT scans collected from COVID-19 patients demonstrate that our CS$^2$ model can lead to realistic synthesized datasets and promising segmentation results of COVID infections compared to the state-of-the-art nnUNet trained and fine-tuned in a fully supervised manner.
FDGNN: Fully Dynamic Graph Neural Network
Jun 07, 2022Dynamic Graph Neural Networks recently became more and more important as graphs from many scientific fields, ranging from mathematics, biology, social sciences, and physics to computer science, are dynamic by nature. While temporal changes (dynamics) play an essential role in many real-world applications, most of the models in the literature on Graph Neural Networks (GNN) process static graphs. The few GNN models on dynamic graphs only consider exceptional cases of dynamics, e.g., node attribute-dynamic graphs or structure-dynamic graphs limited to additions or changes to the graph's edges, etc. Therefore, we present a novel Fully Dynamic Graph Neural Network (FDGNN) that can handle fully-dynamic graphs in continuous time. The proposed method provides a node and an edge embedding that includes their activity to address added and deleted nodes or edges, and possible attributes. Furthermore, the embeddings specify Temporal Point Processes for each event to encode the distributions of the structure- and attribute-related incoming graph events. In addition, our model can be updated efficiently by considering single events for local retraining.
Inferring Black Hole Properties from Astronomical Multivariate Time Series with Bayesian Attentive Neural Processes
Jun 18, 2021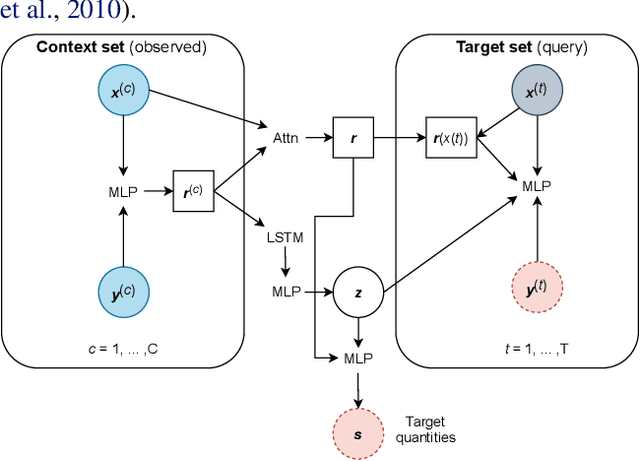
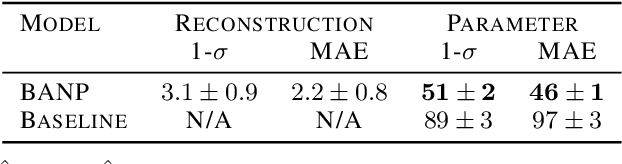
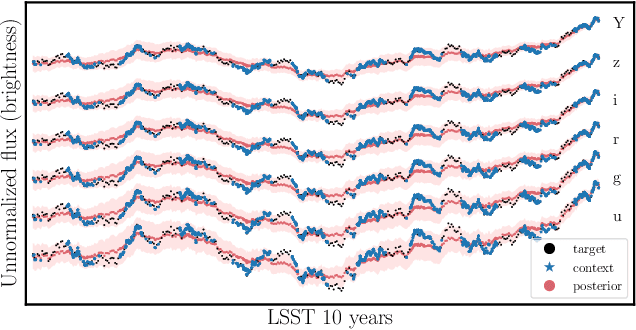
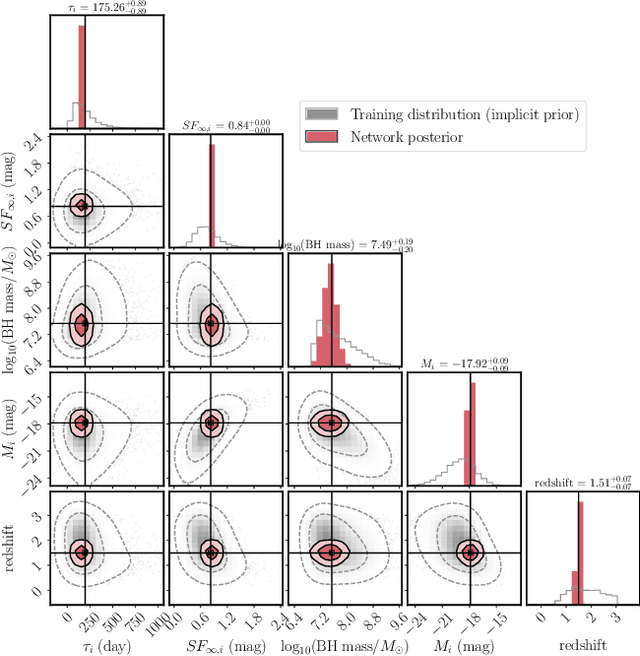
Among the most extreme objects in the Universe, active galactic nuclei (AGN) are luminous centers of galaxies where a black hole feeds on surrounding matter. The variability patterns of the light emitted by an AGN contain information about the physical properties of the underlying black hole. Upcoming telescopes will observe over 100 million AGN in multiple broadband wavelengths, yielding a large sample of multivariate time series with long gaps and irregular sampling. We present a method that reconstructs the AGN time series and simultaneously infers the posterior probability density distribution (PDF) over the physical quantities of the black hole, including its mass and luminosity. We apply this method to a simulated dataset of 11,000 AGN and report precision and accuracy of 0.4 dex and 0.3 dex in the inferred black hole mass. This work is the first to address probabilistic time series reconstruction and parameter inference for AGN in an end-to-end fashion.
Robust Sparse Mean Estimation via Sum of Squares
Jun 07, 2022We study the problem of high-dimensional sparse mean estimation in the presence of an $\epsilon$-fraction of adversarial outliers. Prior work obtained sample and computationally efficient algorithms for this task for identity-covariance subgaussian distributions. In this work, we develop the first efficient algorithms for robust sparse mean estimation without a priori knowledge of the covariance. For distributions on $\mathbb R^d$ with "certifiably bounded" $t$-th moments and sufficiently light tails, our algorithm achieves error of $O(\epsilon^{1-1/t})$ with sample complexity $m = (k\log(d))^{O(t)}/\epsilon^{2-2/t}$. For the special case of the Gaussian distribution, our algorithm achieves near-optimal error of $\tilde O(\epsilon)$ with sample complexity $m = O(k^4 \mathrm{polylog}(d))/\epsilon^2$. Our algorithms follow the Sum-of-Squares based, proofs to algorithms approach. We complement our upper bounds with Statistical Query and low-degree polynomial testing lower bounds, providing evidence that the sample-time-error tradeoffs achieved by our algorithms are qualitatively the best possible.
Revealing Single Frame Bias for Video-and-Language Learning
Jun 07, 2022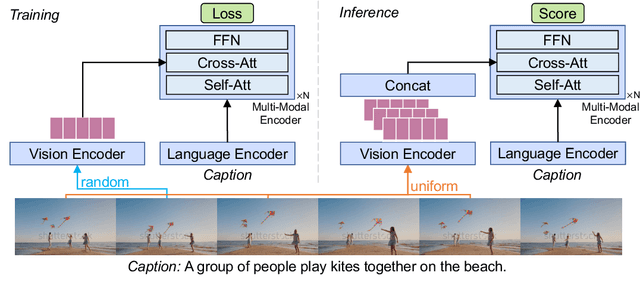
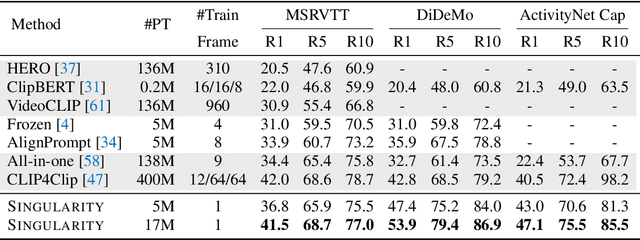
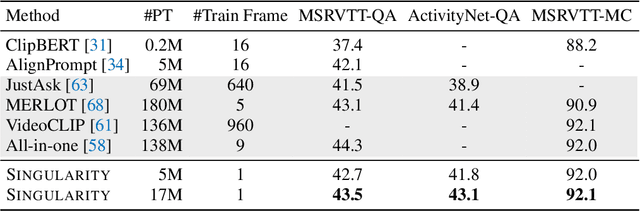

Training an effective video-and-language model intuitively requires multiple frames as model inputs. However, it is unclear whether using multiple frames is beneficial to downstream tasks, and if yes, whether the performance gain is worth the drastically-increased computation and memory costs resulting from using more frames. In this work, we explore single-frame models for video-and-language learning. On a diverse set of video-and-language tasks (including text-to-video retrieval and video question answering), we show the surprising result that, with large-scale pre-training and a proper frame ensemble strategy at inference time, a single-frame trained model that does not consider temporal information can achieve better performance than existing methods that use multiple frames for training. This result reveals the existence of a strong "static appearance bias" in popular video-and-language datasets. Therefore, to allow for a more comprehensive evaluation of video-and-language models, we propose two new retrieval tasks based on existing fine-grained action recognition datasets that encourage temporal modeling. Our code is available at https://github.com/jayleicn/singularity
Multi-Contact Motion Retargeting using Whole-body Optimization of Full Kinematics and Sequential Force Equilibrium
Jun 01, 2022
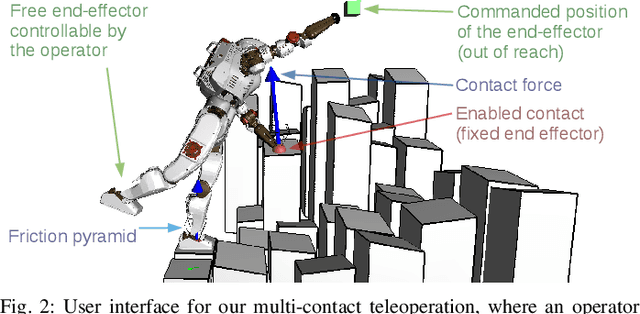
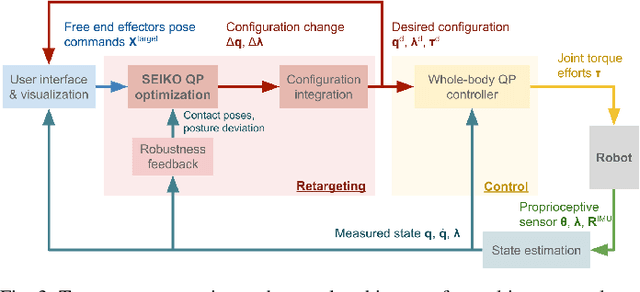
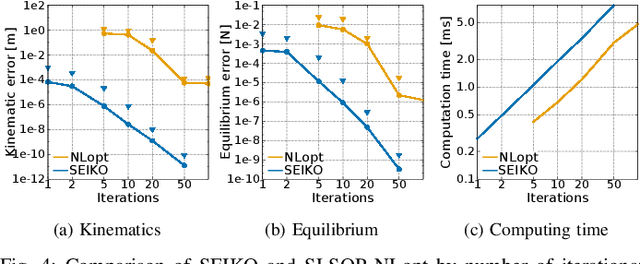
This paper presents a multi-contact motion adaptation framework that enables teleoperation of high degree-of-freedom (DoF) robots, such as quadrupeds and humanoids, for loco-manipulation tasks in multi-contact settings. Our proposed algorithms optimize whole-body configurations and formulate the retargeting of multi-contact motions as sequential quadratic programming, which is robust and stable near the edges of feasibility constraints. Our framework allows real-time operation of the robot and reduces cognitive load for the operator because infeasible commands are automatically adapted into physically stable and viable motions on the robot. The results in simulations with full dynamics demonstrated the effectiveness of teleoperating different legged robots interactively and generating rich multi-contact movements. We evaluated the computational efficiency of the proposed algorithms, and further validated and analyzed multi-contact loco-manipulation tasks on humanoid and quadruped robots by reaching, active pushing and various traversal on uneven terrains.