 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NeuralTree: A 256-Channel 0.227uJ/class Versatile Neural Activity Classification and Closed-Loop Neuromodulation SoC
May 21, 2022




Closed-loop neural interfaces with on-chip machine learning can detect and suppress disease symptoms in neurological disorders or restore lost functions in paralyzed patients. While high-density neural recording can provide rich neural activity information for accurate disease-state detection, existing systems have low channel count and poor scalability, which could limit their therapeutic efficacy. This work presents a highly scalable and versatile closed-loop neural interface SoC that can overcome these limitations. A 256-channel time-division multiplexed (TDM) front-end with a two-step fast-settling mixed-signal DC servo loop (DSL) is proposed to record high-spatial-resolution neural activity and perform channel-selective brain-state inference. A tree-structured neural network (NeuralTree) classification processor extracts a rich set of neural biomarkers in a patient- and disease-specific manner. Trained with an energy-aware learning algorithm, the NeuralTree classifier detects the symptoms of underlying disorders (e.g., epilepsy and movement disorders) at an optimal energy-accuracy trade-off. A 16-channel high-voltage (HV) compliant neurostimulator closes the therapeutic loop by delivering charge-balanced biphasic current pulses to the brain. The proposed SoC was fabricated in 65nm CMOS and achieved a 0.227uJ/class energy efficiency in a compact area of 0.014mm^2/channel. The SoC was extensively verified on human electroencephalography (EEG) and intracranial EEG (iEEG) epilepsy datasets, obtaining 95.6%/94% sensitivity and 96.8%/96.9% specificity, respectively. In-vivo neural recordings using soft uECoG arrays and multi-domain biomarker extraction were further performed on a rat model of epilepsy. In addition, for the first time in literature, on-chip classification of rest-state tremor in Parkinson's disease from human local field potentials (LFPs) was demonstrated.
Temporal Inductive Logic Reasoning
Jun 09, 2022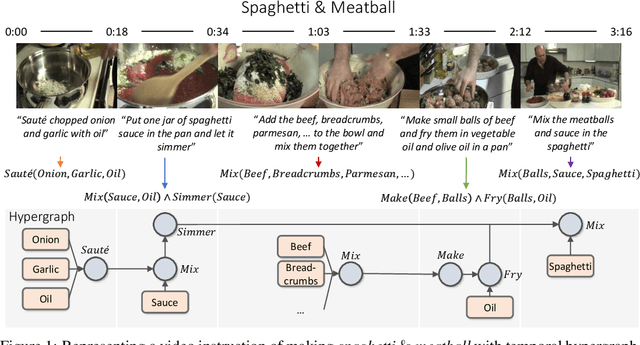
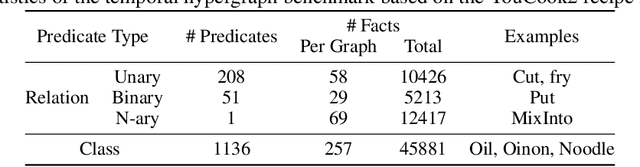
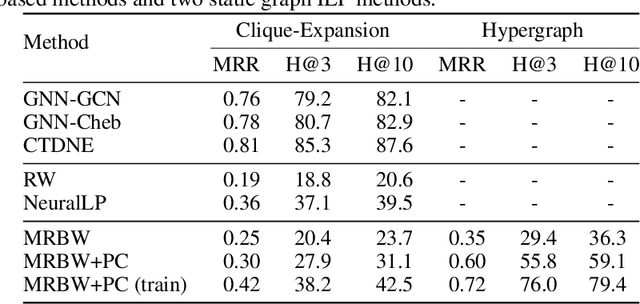
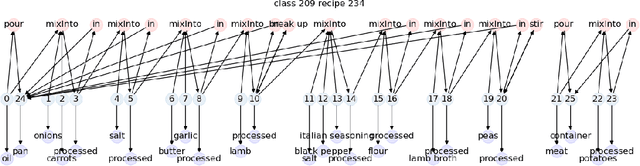
Inductive logic reasoning is one of the fundamental tasks on graphs, which seeks to generalize patterns from the data. This task has been studied extensively for traditional graph datasets such as knowledge graphs (KGs), with representative techniques such as inductive logic programming (ILP). Existing ILP methods typically assume learning from KGs with static facts and binary relations. Beyond KGs, graph structures are widely present in other applications such as video instructions, scene graphs and program executions. While inductive logic reasoning is also beneficial for these applications, applying ILP to the corresponding graphs is nontrivial: they are more complex than KGs, which usually involve timestamps and n-ary relations, effectively a type of hypergraph with temporal events. In this work, we study two of such applications and propose to represent them as hypergraphs with time intervals. To reason on this graph, we propose the multi-start random B-walk that traverses this hypergraph. Combining it with a path-consistency algorithm, we propose an efficient backward-chaining ILP method that learns logic rules by generalizing from both the temporal and the relational data.
Optimization of IoT-Enabled Physical Location Monitoring Using DT and VAR
Apr 10, 2022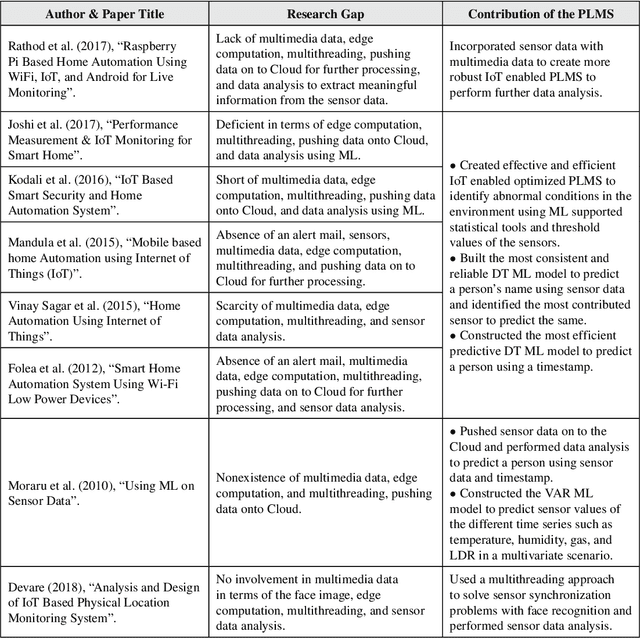
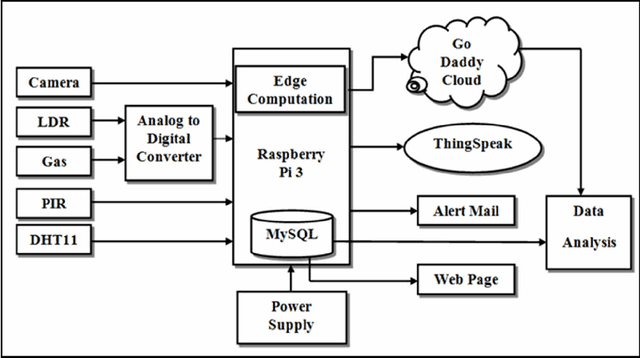
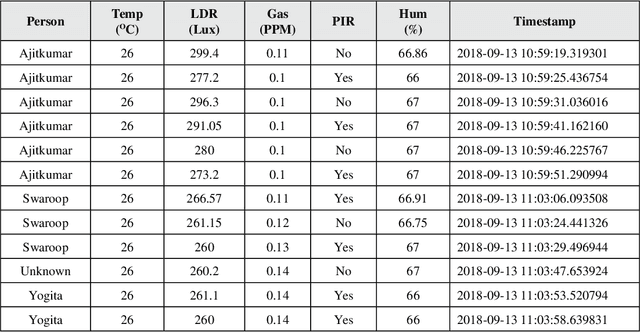
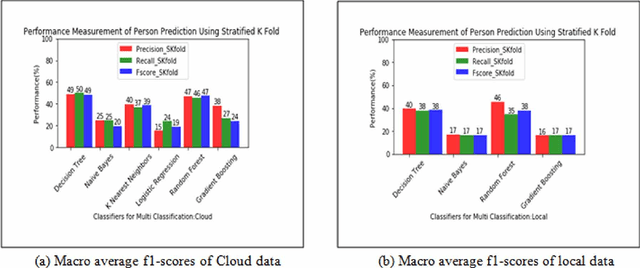
This study shows an enhancement of IoT that gets sensor data and performs real-time face recognition to screen physical areas to find strange situations and send an alarm mail to the client to make remedial moves to avoid any potential misfortune in the environment. Sensor data is pushed onto the local system and GoDaddy Cloud whenever the camera detects a person to optimize the physical location monitoring system by reducing the bandwidth requirement and storage cost onto the cloud using edge computation. The study reveals that decision tree (DT) and random forest give reasonably similar macro average f1-scores to predict a person using sensor data. Experimental results show that DT is the most reliable predictive model for the cloud datasets of three different physical locations to predict a person using timestamp with an accuracy of 83.99%, 88.92%, and 80.97%. This study also explains multivariate time series prediction using vector auto regression that gives reasonably good root mean squared error to predict temperature, humidity, light-dependent resistor, and gas time series.
On Certifying and Improving Generalization to Unseen Domains
Jun 24, 2022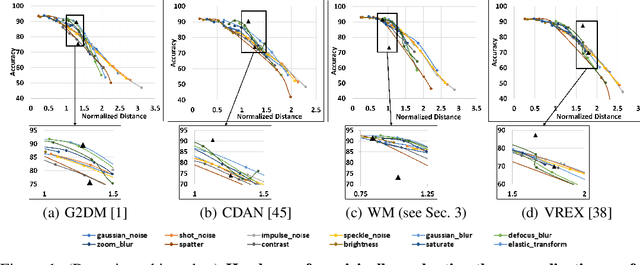
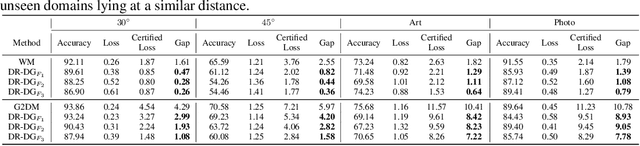
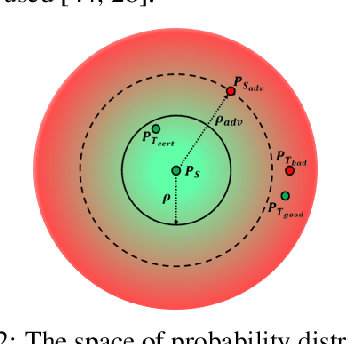
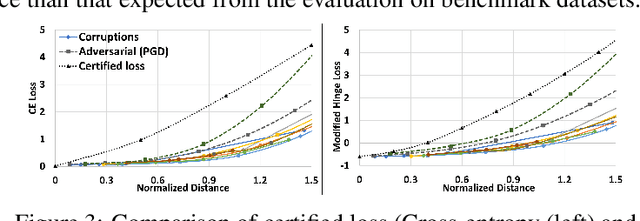
Domain Generalization (DG) aims to learn models whose performance remains high on unseen domains encountered at test-time by using data from multiple related source domains. Many existing DG algorithms reduce the divergence between source distributions in a representation space to potentially align the unseen domain close to the sources. This is motivated by the analysis that explains generalization to unseen domains using distributional distance (such as the Wasserstein distance) to the sources. However, due to the openness of the DG objective, it is challenging to evaluate DG algorithms comprehensively using a few benchmark datasets. In particular, we demonstrate that the accuracy of the models trained with DG methods varies significantly across unseen domains, generated from popular benchmark datasets. This highlights that the performance of DG methods on a few benchmark datasets may not be representative of their performance on unseen domains in the wild. To overcome this roadblock, we propose a universal certification framework based on distributionally robust optimization (DRO) that can efficiently certify the worst-case performance of any DG method. This enables a data-independent evaluation of a DG method complementary to the empirical evaluations on benchmark datasets. Furthermore, we propose a training algorithm that can be used with any DG method to provably improve their certified performance. Our empirical evaluation demonstrates the effectiveness of our method at significantly improving the worst-case loss (i.e., reducing the risk of failure of these models in the wild) without incurring a significant performance drop on benchmark datasets.
Decoupled Dynamic Spatial-Temporal Graph Neural Network for Traffic Forecasting
Jun 22, 2022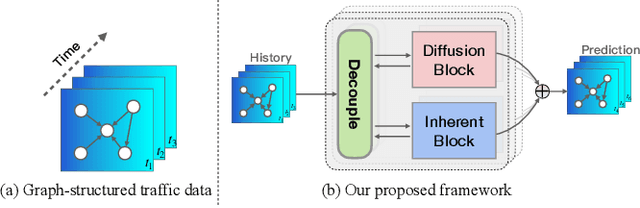

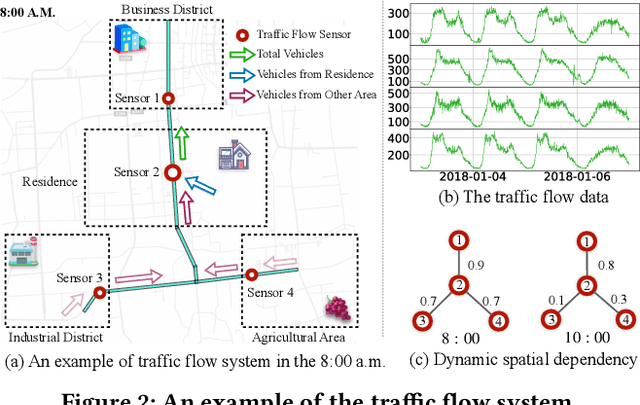
We all depend on mobility, and vehicular transportation affects the daily lives of most of us. Thus, the ability to forecast the state of traffic in a road network is an important functionality and a challenging task. Traffic data is often obtained from sensors deployed in a road network. Recent proposals on spatial-temporal graph neural networks have achieved great progress at modeling complex spatial-temporal correlations in traffic data, by modeling traffic data as a diffusion process. However, intuitively, traffic data encompasses two different kinds of hidden time series signals, namely the diffusion signals and inherent signals. Unfortunately, nearly all previous works coarsely consider traffic signals entirely as the outcome of the diffusion, while neglecting the inherent signals, which impacts model performance negatively. To improve modeling performance, we propose a novel Decoupled Spatial-Temporal Framework (DSTF) that separates the diffusion and inherent traffic information in a data-driven manner, which encompasses a unique estimation gate and a residual decomposition mechanism. The separated signals can be handled subsequently by the diffusion and inherent modules separately. Further, we propose an instantiation of DSTF, Decoupled Dynamic Spatial-Temporal Graph Neural Network (D2STGNN), that captures spatial-temporal correlations and also features a dynamic graph learning module that targets the learning of the dynamic characteristics of traffic networks. Extensive experiments with four real-world traffic datasets demonstrate that the framework is capable of advancing the state-of-the-art.
Simplex Neural Population Learning: Any-Mixture Bayes-Optimality in Symmetric Zero-sum Games
May 31, 2022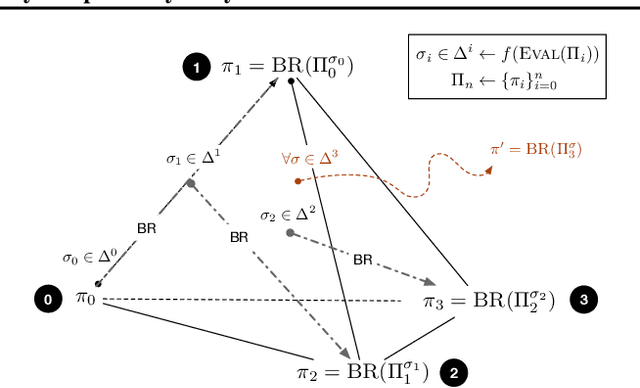
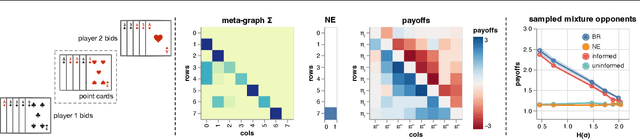
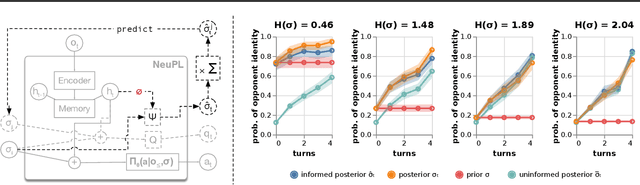
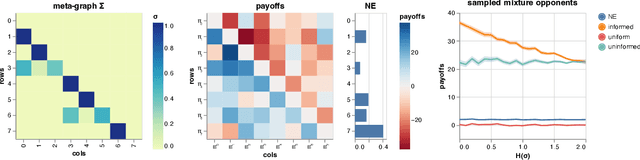
Learning to play optimally against any mixture over a diverse set of strategies is of important practical interests in competitive games. In this paper, we propose simplex-NeuPL that satisfies two desiderata simultaneously: i) learning a population of strategically diverse basis policies, represented by a single conditional network; ii) using the same network, learn best-responses to any mixture over the simplex of basis policies. We show that the resulting conditional policies incorporate prior information about their opponents effectively, enabling near optimal returns against arbitrary mixture policies in a game with tractable best-responses. We verify that such policies behave Bayes-optimally under uncertainty and offer insights in using this flexibility at test time. Finally, we offer evidence that learning best-responses to any mixture policies is an effective auxiliary task for strategic exploration, which, by itself, can lead to more performant populations.
Self-supervised Pretraining and Transfer Learning Enable Flu and COVID-19 Predictions in Small Mobile Sensing Datasets
May 26, 2022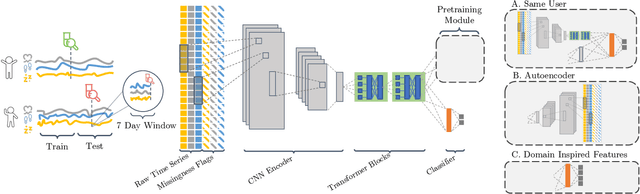
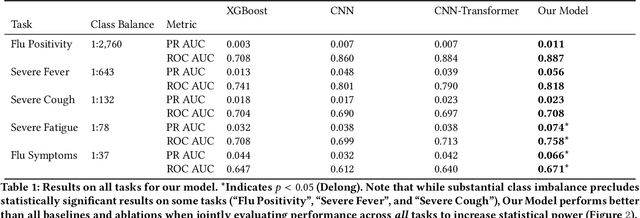
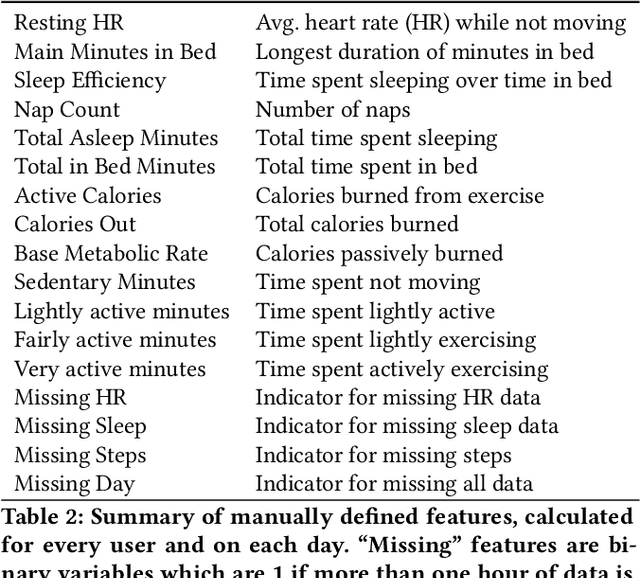
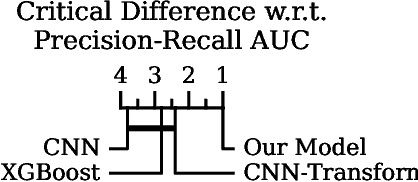
Detailed mobile sensing data from phones, watches, and fitness trackers offer an unparalleled opportunity to quantify and act upon previously unmeasurable behavioral changes in order to improve individual health and accelerate responses to emerging diseases. Unlike in natural language processing and computer vision, deep representation learning has yet to broadly impact this domain, in which the vast majority of research and clinical applications still rely on manually defined features and boosted tree models or even forgo predictive modeling altogether due to insufficient accuracy. This is due to unique challenges in the behavioral health domain, including very small datasets (~10^1 participants), which frequently contain missing data, consist of long time series with critical long-range dependencies (length>10^4), and extreme class imbalances (>10^3:1).
Data-driven reduced order models using invariant foliations, manifolds and autoencoders
Jun 24, 2022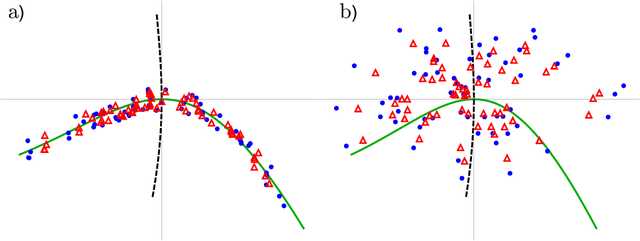

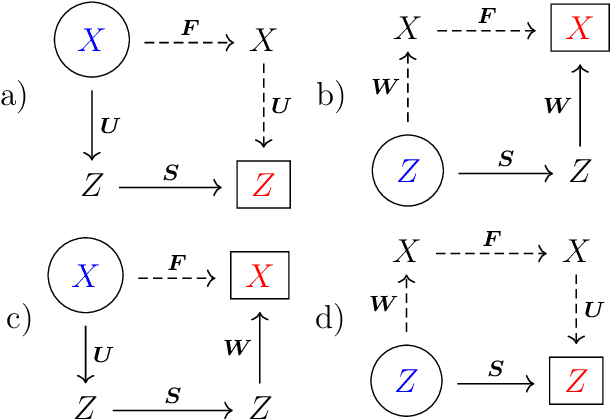
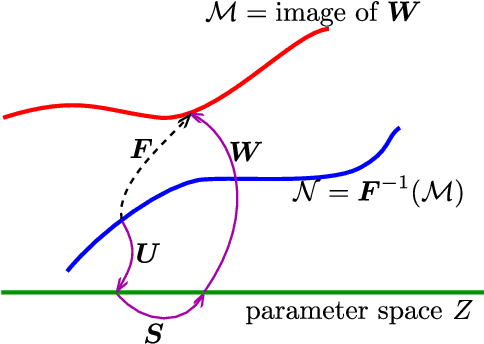
This paper explores the question: how to identify a reduced order model from data. There are three ways to relate data to a model: invariant foliations, invariant manifolds and autoencoders. Invariant manifolds cannot be fitted to data unless a hardware in a loop system is used. Autoencoders only identify the portion of the phase space where the data is, which is not necessarily an invariant manifold. Therefore for off-line data the only option is an invariant foliation. We note that Koopman eigenfunctions also define invariant foliations, but they are limited by the assumption of linearity and resulting singularites. Finding an invariant foliation requires approximating high-dimensional functions. We propose two solutions. If an accurate reduced order model is sought, a sparse polynomial approximation is used, with polynomial coefficients that are sparse hierarchical tensors. If an invariant manifold is sought, as a leaf of a foliation, the required high-dimensional function can be approximated by a low-dimensional polynomial. The two methods can be combined to find an accurate reduced order model and an invariant manifold. We also analyse the reduced order model in case of a focus type equilibrium, typical in mechanical systems. We note that the nonlinear coordinate system defined by the invariant foliation and the invariant manifold distorts instantaneous frequencies and damping ratios, which we correct. Through examples we illustrate the calculation of invariant foliations and manifolds, and at the same time show that Koopman eigenfunctions and autoencoders fail to capture accurate reduced order models under the same conditions.
CASS: Cross Architectural Self-Supervision for Medical Image Analysis
Jun 08, 2022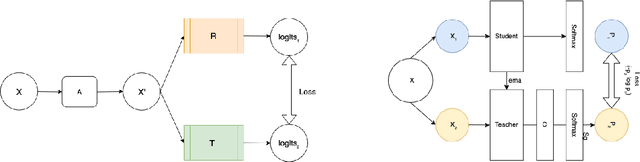
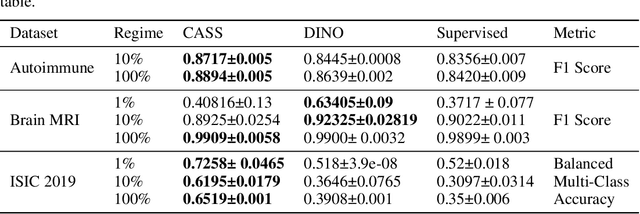


Recent advances in Deep Learning and Computer Vision have alleviated many of the bottlenecks, allowing algorithms to be label-free with better performance. Specifically, Transformers provide a global perspective of the image, which Convolutional Neural Networks (CNN) lack by design. Here we present \textbf{C}ross \textbf{A}rchitectural - \textbf{S}elf \textbf{S}upervision , a novel self-supervised learning approach which leverages transformers and CNN simultaneously, while also being computationally accessible to general practitioners via easily available cloud services. Compared to existing state-of-the-art self-supervised learning approaches, we empirically show CASS trained CNNs, and Transformers gained an average of 8.5\% with 100\% labelled data, 7.3\% with 10\% labelled data, and 11.5\% with 1\% labelled data, across three diverse datasets. Notably, one of the employed datasets included histopathology slides of an autoimmune disease, a topic underrepresented in Medical Imaging and has minimal data. In addition, our findings reveal that CASS is twice as efficient as other state-of-the-art methods in terms of training time.
GateNLP-UShef at SemEval-2022 Task 8: Entity-Enriched Siamese Transformer for Multilingual News Article Similarity
May 31, 2022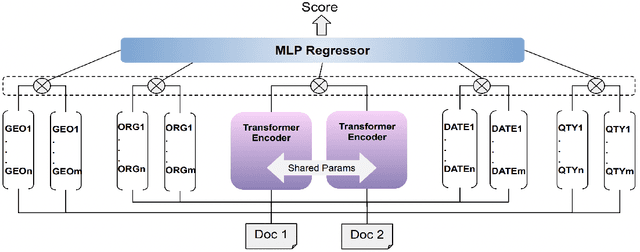
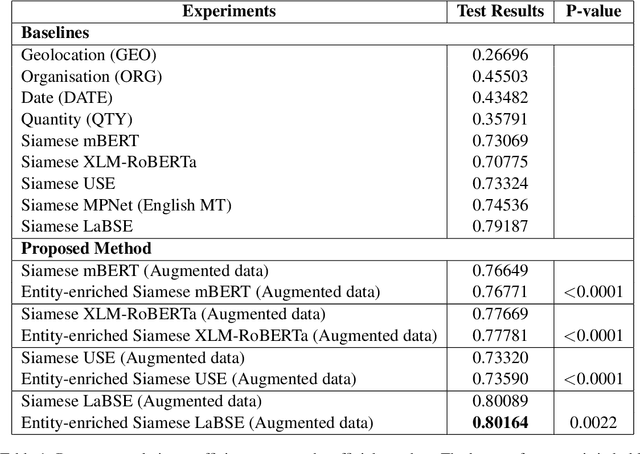
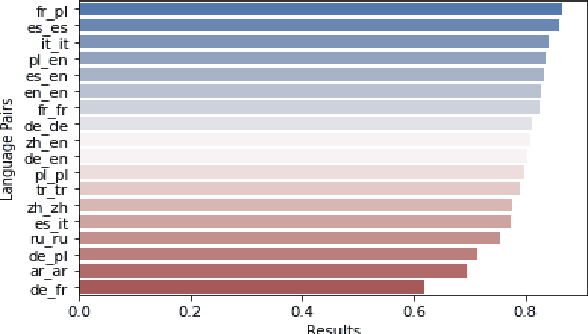
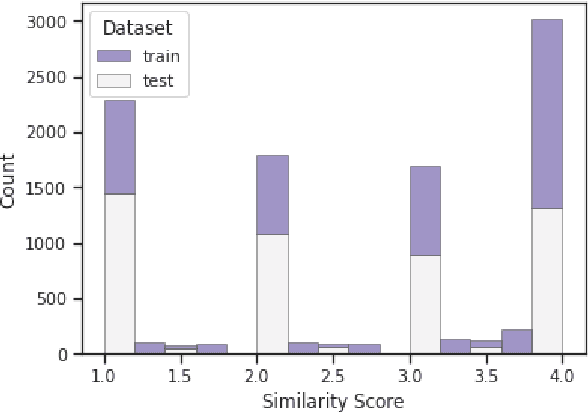
This paper describes the second-placed system on the leaderboard of SemEval-2022 Task 8: Multilingual News Article Similarity. We propose an entity-enriched Siamese Transformer which computes news article similarity based on different sub-dimensions, such as the shared narrative, entities, location and time of the event discussed in the news article. Our system exploits a Siamese network architecture using a Transformer encoder to learn document-level representations for the purpose of capturing the narrative together with the auxiliary entity-based features extracted from the news articles. The intuition behind using all these features together is to capture the similarity between news articles at different granularity levels and to assess the extent to which different news outlets write about "the same events". Our experimental results and detailed ablation study demonstrate the effectiveness and the validity of our proposed method.