 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Averaging Spatio-temporal Signals using Optimal Transport and Soft Alignments
Apr 08, 2022
Several fields in science, from genomics to neuroimaging, require monitoring populations (measures) that evolve with time. These complex datasets, describing dynamics with both time and spatial components, pose new challenges for data analysis. We propose in this work a new framework to carry out averaging of these datasets, with the goal of synthesizing a representative template trajectory from multiple trajectories. We show that this requires addressing three sources of invariance: shifts in time, space, and total population size (or mass/amplitude). Here we draw inspiration from dynamic time warping (DTW), optimal transport (OT) theory and its unbalanced extension (UOT) to propose a criterion that can address all three issues. This proposal leverages a smooth formulation of DTW (Soft-DTW) that is shown to capture temporal shifts, and UOT to handle both variations in space and size. Our proposed loss can be used to define spatio-temporal barycenters as Fr\'echet means. Using Fenchel duality, we show how these barycenters can be computed efficiently, in parallel, via a novel variant of entropy-regularized debiased UOT. Experiments on handwritten letters and brain imaging data confirm our theoretical findings and illustrate the effectiveness of the proposed loss for spatio-temporal data.
Deep Matching Prior: Test-Time Optimization for Dense Correspondence
Jun 06, 2021
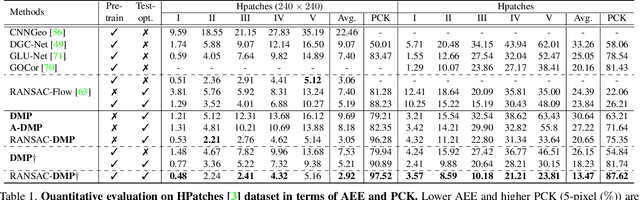
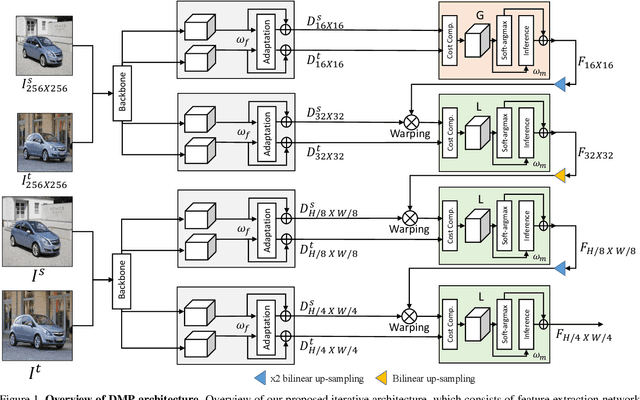
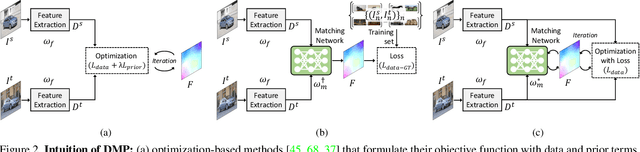
Conventional techniques to establish dense correspondences across visually or semantically similar images focused on designing a task-specific matching prior, which is difficult to model. To overcome this, recent learning-based methods have attempted to learn a good matching prior within a model itself on large training data. The performance improvement was apparent, but the need for sufficient training data and intensive learning hinders their applicability. Moreover, using the fixed model at test time does not account for the fact that a pair of images may require their own prior, thus providing limited performance and poor generalization to unseen images. In this paper, we show that an image pair-specific prior can be captured by solely optimizing the untrained matching networks on an input pair of images. Tailored for such test-time optimization for dense correspondence, we present a residual matching network and a confidence-aware contrastive loss to guarantee a meaningful convergence. Experiments demonstrate that our framework, dubbed Deep Matching Prior (DMP), is competitive, or even outperforms, against the latest learning-based methods on several benchmarks for geometric matching and semantic matching, even though it requires neither large training data nor intensive learning. With the networks pre-trained, DMP attains state-of-the-art performance on all benchmarks.
Computation Offloading and Resource Allocation in F-RANs: A Federated Deep Reinforcement Learning Approach
Jun 13, 2022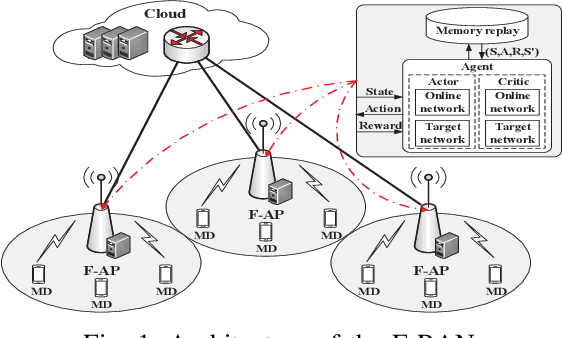
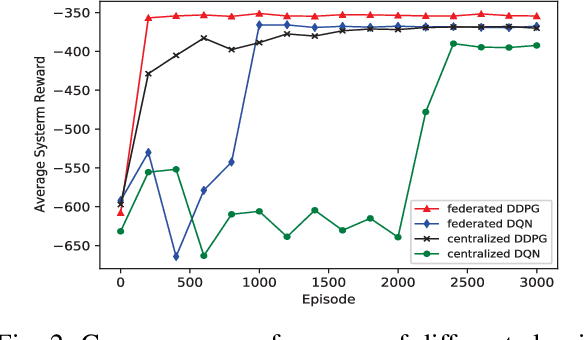
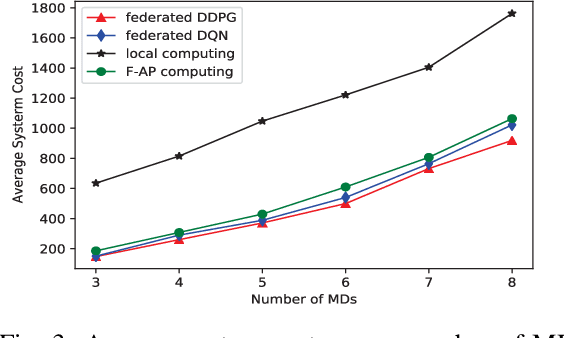
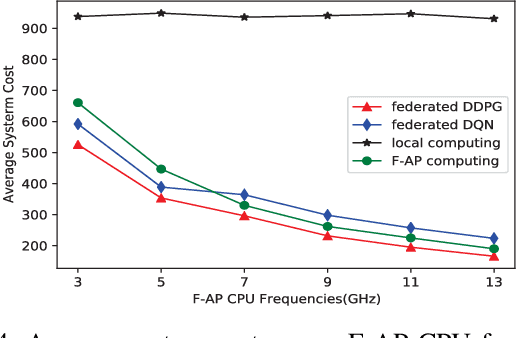
The fog radio access network (F-RAN) is a promising technology in which the user mobile devices (MDs) can offload computation tasks to the nearby fog access points (F-APs). Due to the limited resource of F-APs, it is important to design an efficient task offloading scheme. In this paper, by considering time-varying network environment, a dynamic computation offloading and resource allocation problem in F-RANs is formulated to minimize the task execution delay and energy consumption of MDs. To solve the problem, a federated deep reinforcement learning (DRL) based algorithm is proposed, where the deep deterministic policy gradient (DDPG) algorithm performs computation offloading and resource allocation in each F-AP. Federated learning is exploited to train the DDPG agents in order to decrease the computing complexity of training process and protect the user privacy. Simulation results show that the proposed federated DDPG algorithm can achieve lower task execution delay and energy consumption of MDs more quickly compared with the other existing strategies.
Population Diversity Leads to Short Running Times of Lexicase Selection
Apr 13, 2022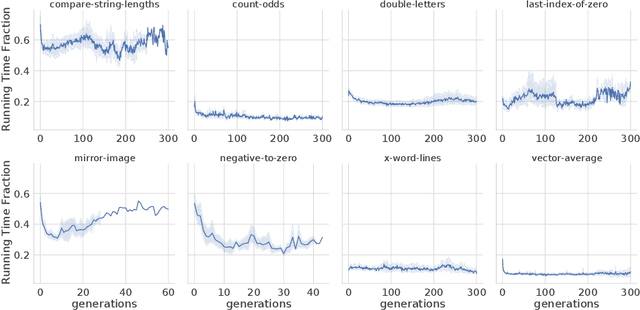
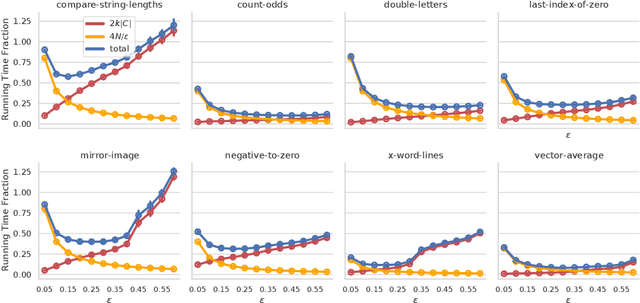
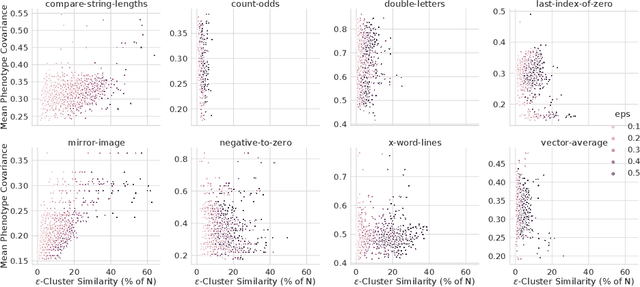
In this paper we investigate why the running time of lexicase parent selection is empirically much lower than its worst-case bound of O(N*C). We define a measure of population diversity and prove that high diversity leads to low running times O(N + C) of lexicase selection. We then show empirically that genetic programming populations evolved under lexicase selection are diverse for several program synthesis problems, and explore the resulting differences in running time bounds.
Controllable Image Enhancement
Jun 16, 2022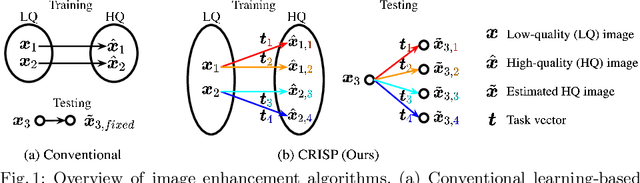
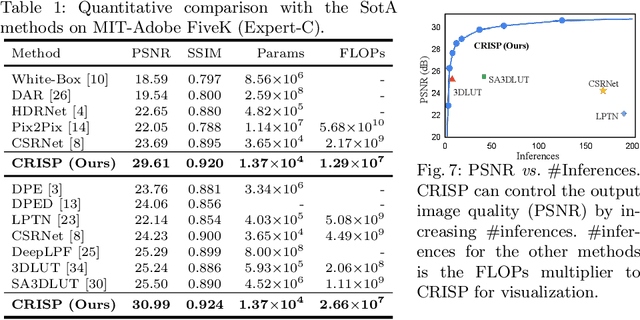
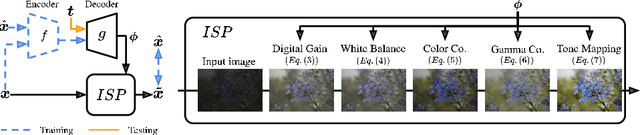

Editing flat-looking images into stunning photographs requires skill and time. Automated image enhancement algorithms have attracted increased interest by generating high-quality images without user interaction. However, the quality assessment of a photograph is subjective. Even in tone and color adjustments, a single photograph of auto-enhancement is challenging to fit user preferences which are subtle and even changeable. To address this problem, we present a semiautomatic image enhancement algorithm that can generate high-quality images with multiple styles by controlling a few parameters. We first disentangle photo retouching skills from high-quality images and build an efficient enhancement system for each skill. Specifically, an encoder-decoder framework encodes the retouching skills into latent codes and decodes them into the parameters of image signal processing (ISP) functions. The ISP functions are computationally efficient and consist of only 19 parameters. Despite our approach requiring multiple inferences to obtain the desired result, experimental results present that the proposed method achieves state-of-the-art performances on the benchmark dataset for image quality and model efficiency.
IRS Aided MEC Systems with Binary Offloading: A Unified Framework for Dynamic IRS Beamforming
May 29, 2022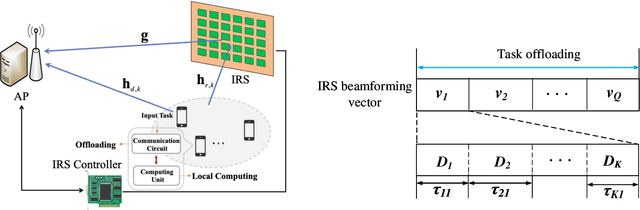
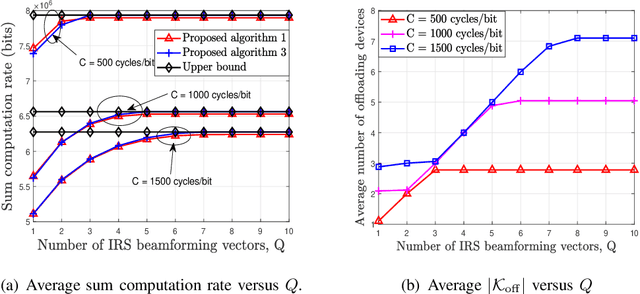
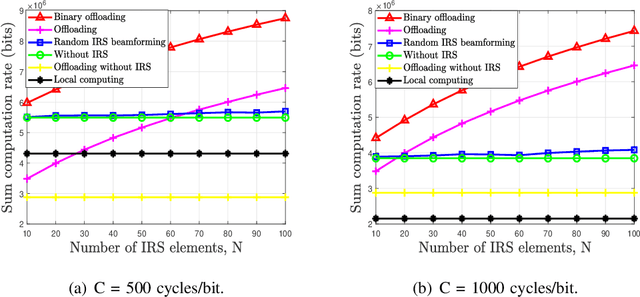
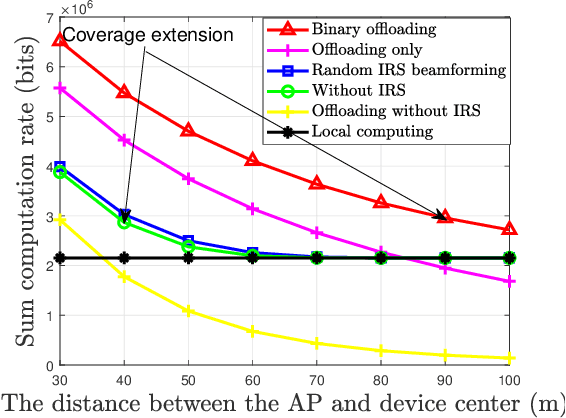
In this paper, we develop a unified dynamic intelligent reflecting surface (IRS) beamforming framework to boost the sum computation rate of an IRS-aided mobile edge computing (MEC) system, where each device follows a binary offloading policy. Specifically, the task of each device has to be either executed locally or offloaded to MEC servers as a whole with the aid of given number of IRS beamforming vectors available. By flexibly controlling the number of IRS reconfiguration times, the system can achieve a balance between the performance and associated signalling overhead. We aim to maximize the sum computation rate by jointly optimizing the computational mode selection for each device, offloading time allocation, and IRS beamforming vectors across time. Since the resulting optimization problem is non-convex and NP-hard, there are generally no standard methods to solve it optimally. To tackle this problem, we first propose a penalty-based successive convex approximation algorithm, where all the associated variables in the inner-layer iterations are optimized simultaneously and the obtained solution is guaranteed to be locally optimal. Then, we further derive the offloading activation condition for each device by deeply exploiting the intrinsic structure of the original optimization problem. According to the offloading activation condition, a low-complexity algorithm based on the successive refinement method is proposed to obtain high-quality solutions, which is more appealing for practical systems with a large number of devices and IRS elements. Moreover, the optimal condition for the proposed low-complexity algorithm is revealed. Numerical results demonstrate the effectiveness of our proposed algorithms and also unveil the fundamental performance-cost tradeoff of the proposed dynamic IRS beamforming framework.
DeepPhysics: a physics aware deep learning framework for real-time simulation
Sep 17, 2021

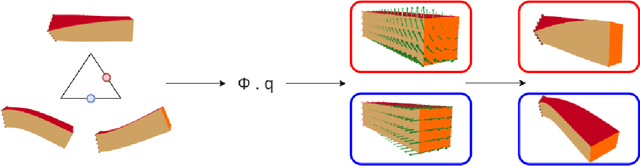
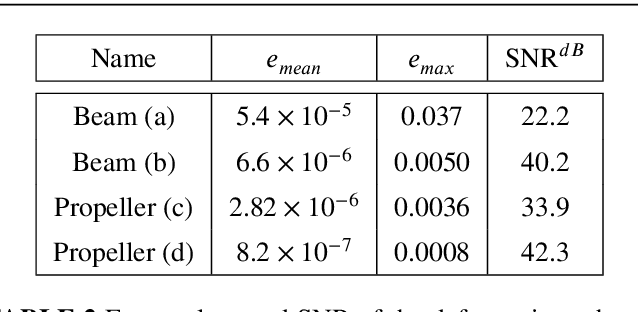
Real-time simulation of elastic structures is essential in many applications, from computer-guided surgical interventions to interactive design in mechanical engineering. The Finite Element Method is often used as the numerical method of reference for solving the partial differential equations associated with these problems. Yet, deep learning methods have recently shown that they could represent an alternative strategy to solve physics-based problems 1,2,3. In this paper, we propose a solution to simulate hyper-elastic materials using a data-driven approach, where a neural network is trained to learn the non-linear relationship between boundary conditions and the resulting displacement field. We also introduce a method to guarantee the validity of the solution. In total, we present three contributions: an optimized data set generation algorithm based on modal analysis, a physics-informed loss function, and a Hybrid Newton-Raphson algorithm. The method is applied to two benchmarks: a cantilever beam and a propeller. The results show that our network architecture trained with a limited amount of data can predict the displacement field in less than a millisecond. The predictions on various geometries, topologies, mesh resolutions, and boundary conditions are accurate to a few micrometers for non-linear deformations of several centimeters of amplitude.
Formulating Robustness Against Unforeseen Attacks
Apr 28, 2022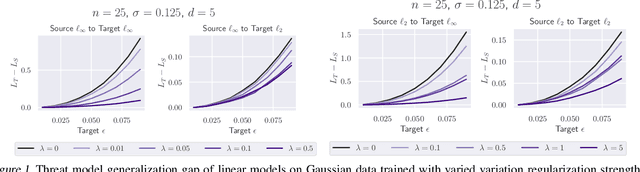
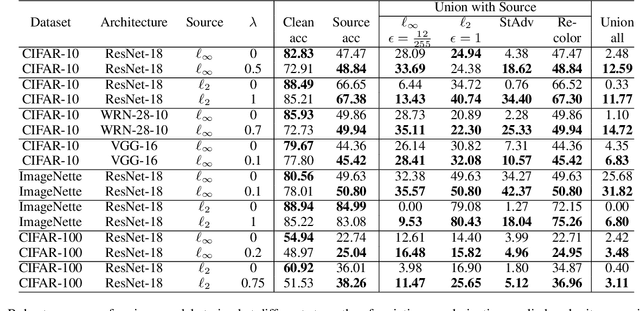
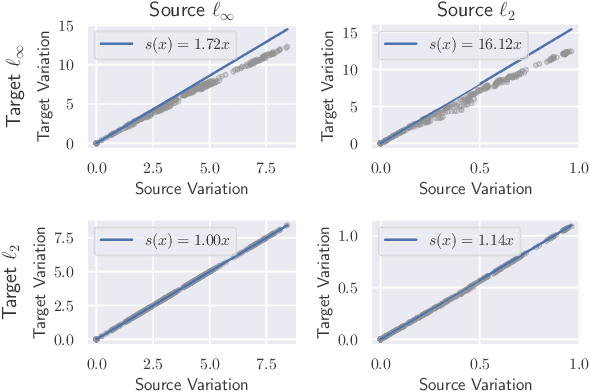
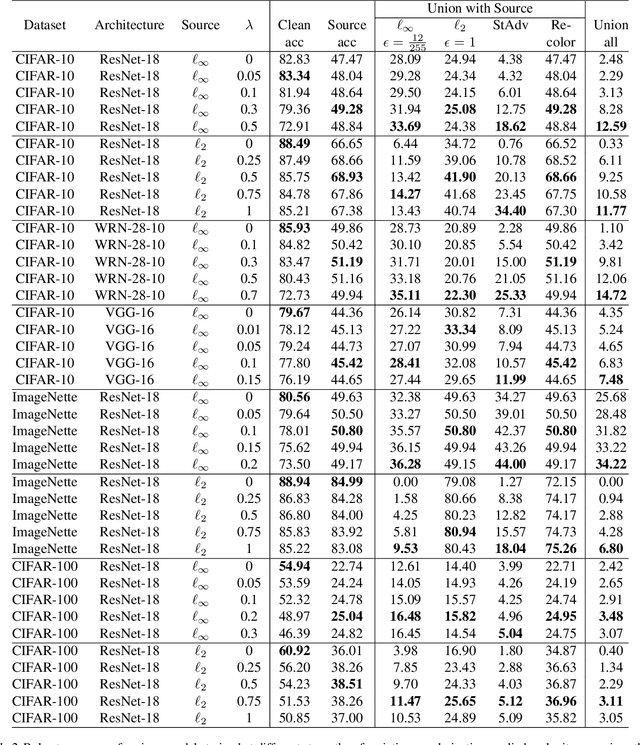
Existing defenses against adversarial examples such as adversarial training typically assume that the adversary will conform to a specific or known threat model, such as $\ell_p$ perturbations within a fixed budget. In this paper, we focus on the scenario where there is a mismatch in the threat model assumed by the defense during training, and the actual capabilities of the adversary at test time. We ask the question: if the learner trains against a specific "source" threat model, when can we expect robustness to generalize to a stronger unknown "target" threat model during test-time? Our key contribution is to formally define the problem of learning and generalization with an unforeseen adversary, which helps us reason about the increase in adversarial risk from the conventional perspective of a known adversary. Applying our framework, we derive a generalization bound which relates the generalization gap between source and target threat models to variation of the feature extractor, which measures the expected maximum difference between extracted features across a given threat model. Based on our generalization bound, we propose adversarial training with variation regularization (AT-VR) which reduces variation of the feature extractor across the source threat model during training. We empirically demonstrate that AT-VR can lead to improved generalization to unforeseen attacks during test-time compared to standard adversarial training on Gaussian and image datasets.
EventNeRF: Neural Radiance Fields from a Single Colour Event Camera
Jun 23, 2022
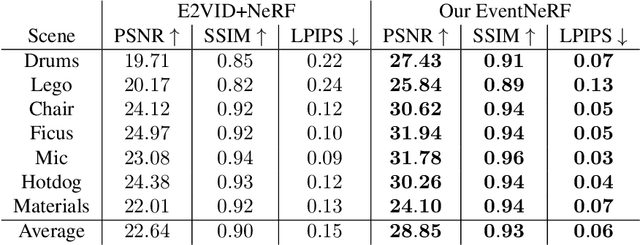

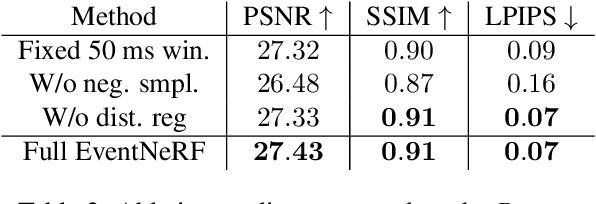
Learning coordinate-based volumetric 3D scene representations such as neural radiance fields (NeRF) has been so far studied assuming RGB or RGB-D images as inputs. At the same time, it is known from the neuroscience literature that human visual system (HVS) is tailored to process asynchronous brightness changes rather than synchronous RGB images, in order to build and continuously update mental 3D representations of the surroundings for navigation and survival. Visual sensors that were inspired by HVS principles are event cameras. Thus, events are sparse and asynchronous per-pixel brightness (or colour channel) change signals. In contrast to existing works on neural 3D scene representation learning, this paper approaches the problem from a new perspective. We demonstrate that it is possible to learn NeRF suitable for novel-view synthesis in the RGB space from asynchronous event streams. Our models achieve high visual accuracy of the rendered novel views of challenging scenes in the RGB space, even though they are trained with substantially fewer data (i.e., event streams from a single event camera moving around the object) and more efficiently (due to the inherent sparsity of event streams) than the existing NeRF models trained with RGB images. We will release our datasets and the source code, see https://4dqv.mpi-inf.mpg.de/EventNeRF/.
Enhancing a Student Productivity Model for Adaptive Problem-Solving Assistance
Jul 07, 2022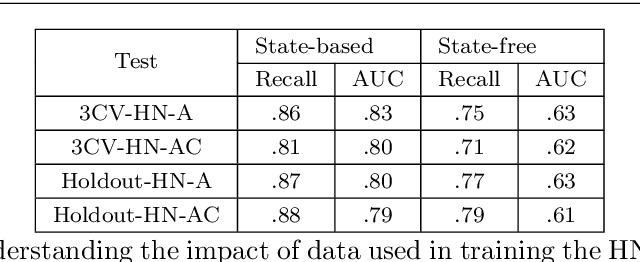
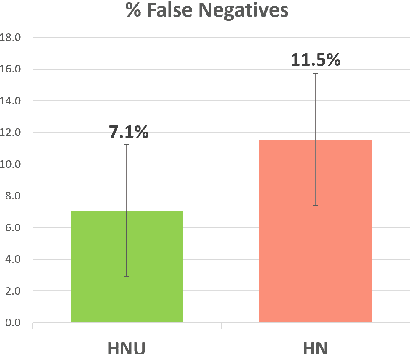
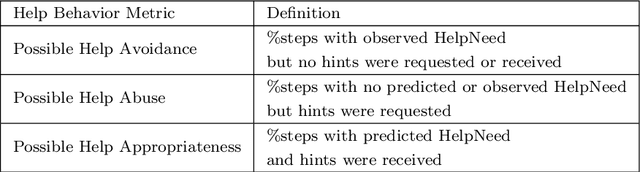
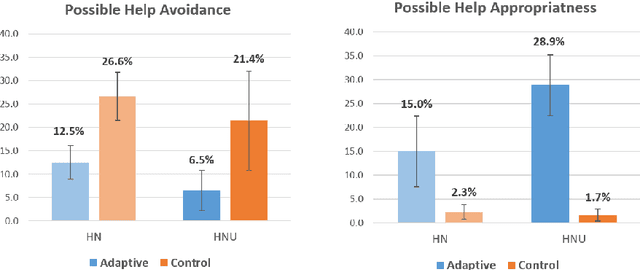
Research on intelligent tutoring systems has been exploring data-driven methods to deliver effective adaptive assistance. While much work has been done to provide adaptive assistance when students seek help, they may not seek help optimally. This had led to the growing interest in proactive adaptive assistance, where the tutor provides unsolicited assistance upon predictions of struggle or unproductivity. Determining when and whether to provide personalized support is a well-known challenge called the assistance dilemma. Addressing this dilemma is particularly challenging in open-ended domains, where there can be several ways to solve problems. Researchers have explored methods to determine when to proactively help students, but few of these methods have taken prior hint usage into account. In this paper, we present a novel data-driven approach to incorporate students' hint usage in predicting their need for help. We explore its impact in an intelligent tutor that deals with the open-ended and well-structured domain of logic proofs. We present a controlled study to investigate the impact of an adaptive hint policy based on predictions of HelpNeed that incorporate students' hint usage. We show empirical evidence to support that such a policy can save students a significant amount of time in training, and lead to improved posttest results, when compared to a control without proactive interventions. We also show that incorporating students' hint usage significantly improves the adaptive hint policy's efficacy in predicting students' HelpNeed, thereby reducing training unproductivity, reducing possible help avoidance, and increasing possible help appropriateness (a higher chance of receiving help when it was likely to be needed). We conclude with suggestions on the domains that can benefit from this approach as well as the requirements for adoption.