 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comparative Study of Faithfulness Metrics for Model Interpretability Methods
Apr 12, 2022

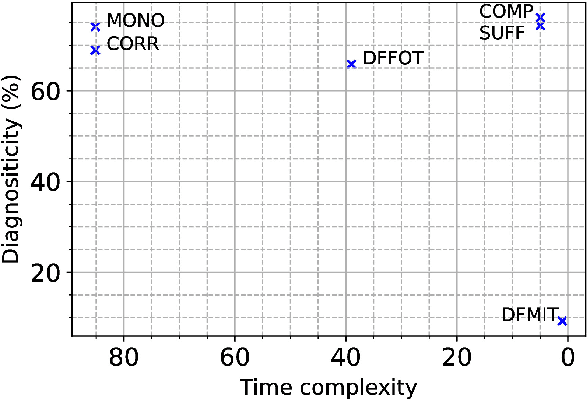
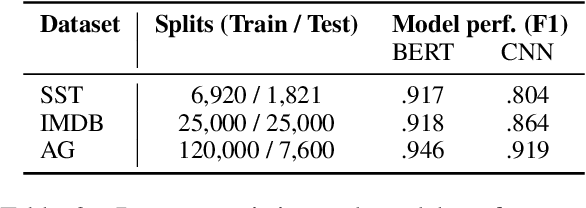
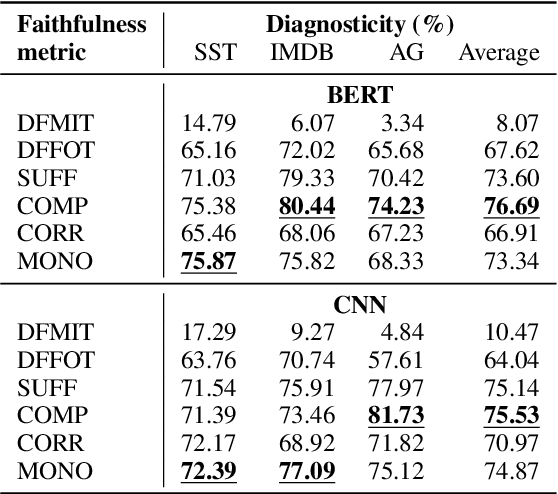
Interpretation methods to reveal the internal reasoning processes behind machine learning models have attracted increasing attention in recent years. To quantify the extent to which the identified interpretations truly reflect the intrinsic decision-making mechanisms, various faithfulness evaluation metrics have been proposed. However, we find that different faithfulness metrics show conflicting preferences when comparing different interpretations. Motivated by this observation, we aim to conduct a comprehensive and comparative study of the widely adopted faithfulness metrics. In particular, we introduce two assessment dimensions, namely diagnosticity and time complexity. Diagnosticity refers to the degree to which the faithfulness metric favours relatively faithful interpretations over randomly generated ones, and time complexity is measured by the average number of model forward passes. According to the experimental results, we find that sufficiency and comprehensiveness metrics have higher diagnosticity and lower time complexity than the other faithfulness metric
Domain Specific Concept Drift Detectors for Predicting Financial Time Series
Mar 22, 2021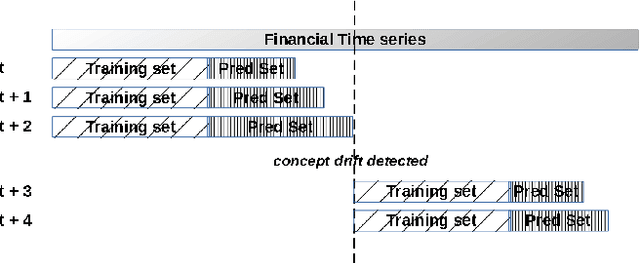
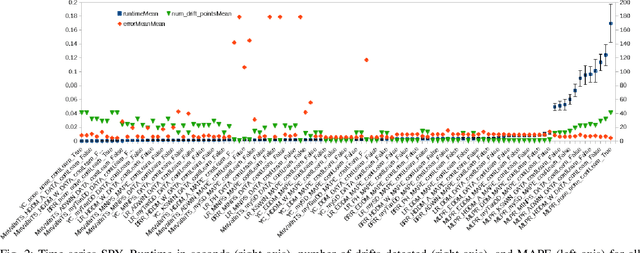
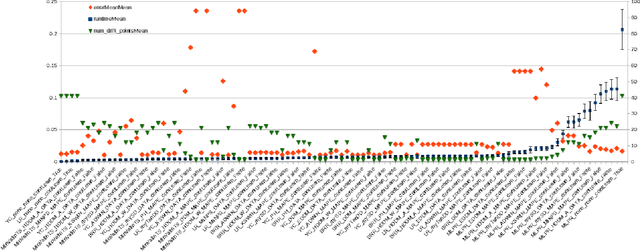
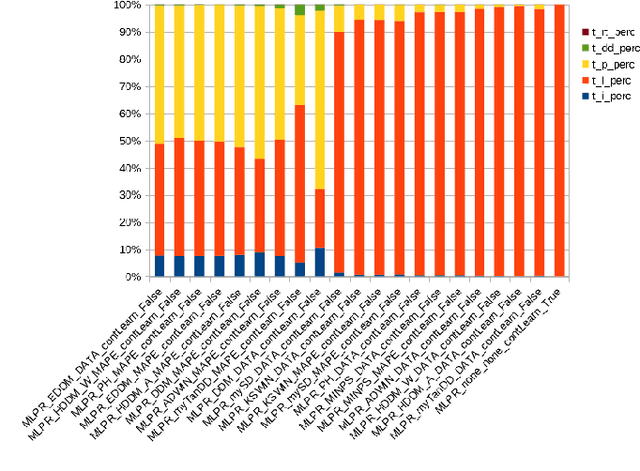
Concept drift detectors allow learning systems to maintain good accuracy on non-stationary data streams. Financial time series are an instance of non-stationary data streams whose concept drifts (market phases) are so important to affect investment decisions worldwide. This paper studies how concept drift detectors behave when applied to financial time series. General results are: a) concept drift detectors usually improve the runtime over continuous learning, b) their computational cost is usually a fraction of the learning and prediction steps of even basic learners, c) it is important to study concept drift detectors in combination with the learning systems they will operate with, and d) concept drift detectors can be directly applied to the time series of raw financial data and not only to the model's accuracy one. Moreover, the study introduces three simple concept drift detectors, tailored to financial time series, and shows that two of them can be at least as effective as the most sophisticated ones from the state of the art when applied to financial time series.
Grasp stability prediction with time series data based on STFT and LSTM
Jun 02, 2021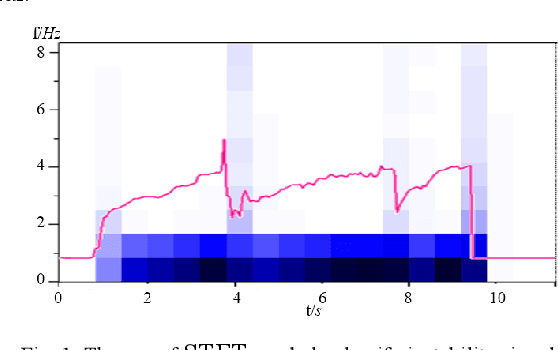


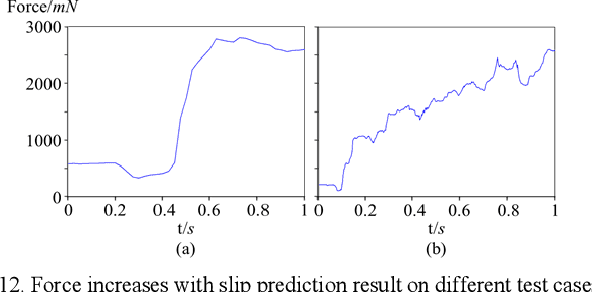
With an increasing demand for robots, robotic grasping will has a more important role in future applications. This paper takes grasp stability prediction as the key technology for grasping and tries to solve the problem with time series data inputs including the force and pressure data. Widely applied to more fields to predict unstable grasping with time series data, algorithms can significantly promote the application of artificial intelligence in traditional industries. This research investigates models that combine short-time Fourier transform (STFT) and long short-term memory (LSTM) and then tested generalizability with dexterous hand and suction cup gripper. The experiments suggest good results for grasp stability prediction with the force data and the generalized results in the pressure data. Among the 4 models, (Data + STFT) & LSTM delivers the best performance. We plan to perform more work on grasp stability prediction, generalize the findings to different types of sensors, and apply the grasp stability prediction in more grasping use cases in real life.
Enhancing a Student Productivity Model for Adaptive Problem-Solving Assistance
Jul 07, 2022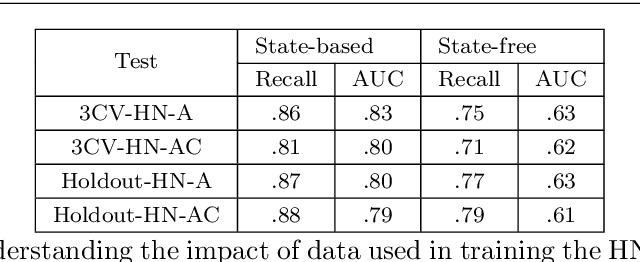
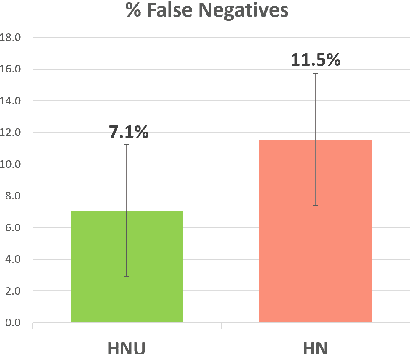
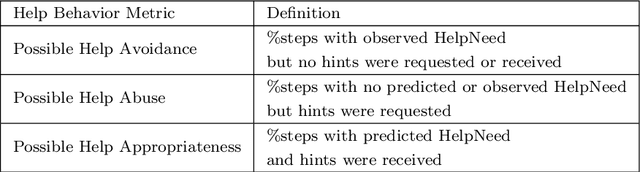
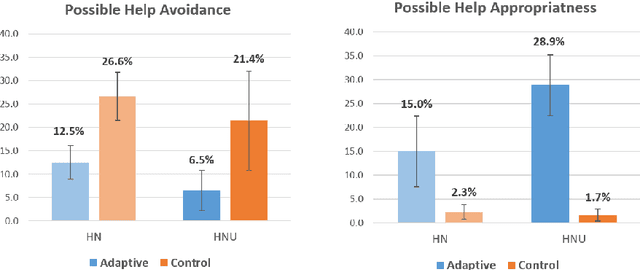
Research on intelligent tutoring systems has been exploring data-driven methods to deliver effective adaptive assistance. While much work has been done to provide adaptive assistance when students seek help, they may not seek help optimally. This had led to the growing interest in proactive adaptive assistance, where the tutor provides unsolicited assistance upon predictions of struggle or unproductivity. Determining when and whether to provide personalized support is a well-known challenge called the assistance dilemma. Addressing this dilemma is particularly challenging in open-ended domains, where there can be several ways to solve problems. Researchers have explored methods to determine when to proactively help students, but few of these methods have taken prior hint usage into account. In this paper, we present a novel data-driven approach to incorporate students' hint usage in predicting their need for help. We explore its impact in an intelligent tutor that deals with the open-ended and well-structured domain of logic proofs. We present a controlled study to investigate the impact of an adaptive hint policy based on predictions of HelpNeed that incorporate students' hint usage. We show empirical evidence to support that such a policy can save students a significant amount of time in training, and lead to improved posttest results, when compared to a control without proactive interventions. We also show that incorporating students' hint usage significantly improves the adaptive hint policy's efficacy in predicting students' HelpNeed, thereby reducing training unproductivity, reducing possible help avoidance, and increasing possible help appropriateness (a higher chance of receiving help when it was likely to be needed). We conclude with suggestions on the domains that can benefit from this approach as well as the requirements for adoption.
IRS Aided MEC Systems with Binary Offloading: A Unified Framework for Dynamic IRS Beamforming
May 29, 2022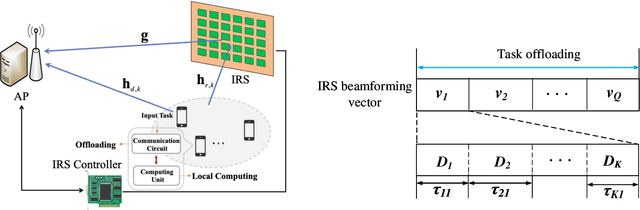
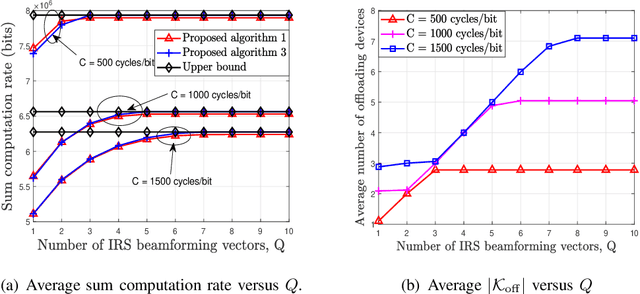
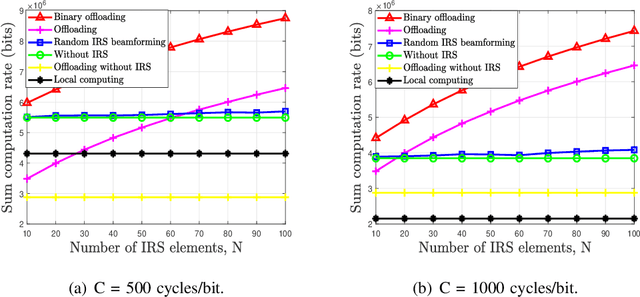
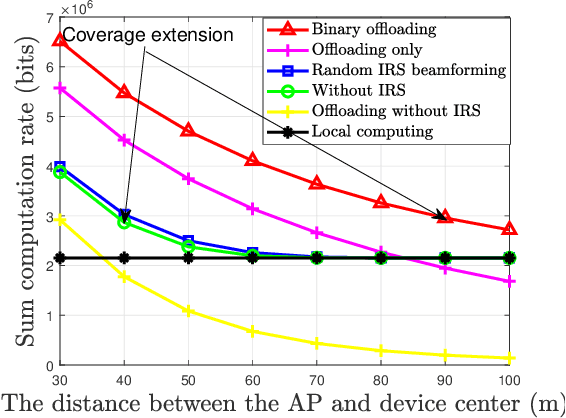
In this paper, we develop a unified dynamic intelligent reflecting surface (IRS) beamforming framework to boost the sum computation rate of an IRS-aided mobile edge computing (MEC) system, where each device follows a binary offloading policy. Specifically, the task of each device has to be either executed locally or offloaded to MEC servers as a whole with the aid of given number of IRS beamforming vectors available. By flexibly controlling the number of IRS reconfiguration times, the system can achieve a balance between the performance and associated signalling overhead. We aim to maximize the sum computation rate by jointly optimizing the computational mode selection for each device, offloading time allocation, and IRS beamforming vectors across time. Since the resulting optimization problem is non-convex and NP-hard, there are generally no standard methods to solve it optimally. To tackle this problem, we first propose a penalty-based successive convex approximation algorithm, where all the associated variables in the inner-layer iterations are optimized simultaneously and the obtained solution is guaranteed to be locally optimal. Then, we further derive the offloading activation condition for each device by deeply exploiting the intrinsic structure of the original optimization problem. According to the offloading activation condition, a low-complexity algorithm based on the successive refinement method is proposed to obtain high-quality solutions, which is more appealing for practical systems with a large number of devices and IRS elements. Moreover, the optimal condition for the proposed low-complexity algorithm is revealed. Numerical results demonstrate the effectiveness of our proposed algorithms and also unveil the fundamental performance-cost tradeoff of the proposed dynamic IRS beamforming framework.
EventNeRF: Neural Radiance Fields from a Single Colour Event Camera
Jun 23, 2022
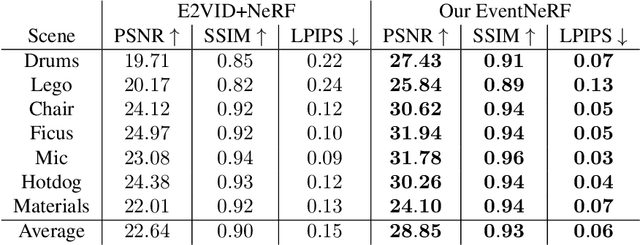

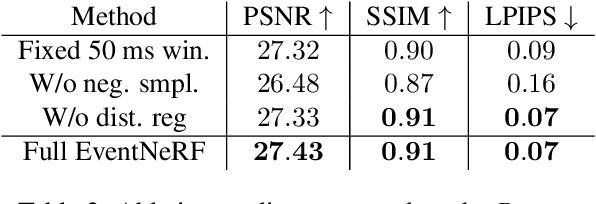
Learning coordinate-based volumetric 3D scene representations such as neural radiance fields (NeRF) has been so far studied assuming RGB or RGB-D images as inputs. At the same time, it is known from the neuroscience literature that human visual system (HVS) is tailored to process asynchronous brightness changes rather than synchronous RGB images, in order to build and continuously update mental 3D representations of the surroundings for navigation and survival. Visual sensors that were inspired by HVS principles are event cameras. Thus, events are sparse and asynchronous per-pixel brightness (or colour channel) change signals. In contrast to existing works on neural 3D scene representation learning, this paper approaches the problem from a new perspective. We demonstrate that it is possible to learn NeRF suitable for novel-view synthesis in the RGB space from asynchronous event streams. Our models achieve high visual accuracy of the rendered novel views of challenging scenes in the RGB space, even though they are trained with substantially fewer data (i.e., event streams from a single event camera moving around the object) and more efficiently (due to the inherent sparsity of event streams) than the existing NeRF models trained with RGB images. We will release our datasets and the source code, see https://4dqv.mpi-inf.mpg.de/EventNeRF/.
Averaging Spatio-temporal Signals using Optimal Transport and Soft Alignments
Apr 08, 2022Several fields in science, from genomics to neuroimaging, require monitoring populations (measures) that evolve with time. These complex datasets, describing dynamics with both time and spatial components, pose new challenges for data analysis. We propose in this work a new framework to carry out averaging of these datasets, with the goal of synthesizing a representative template trajectory from multiple trajectories. We show that this requires addressing three sources of invariance: shifts in time, space, and total population size (or mass/amplitude). Here we draw inspiration from dynamic time warping (DTW), optimal transport (OT) theory and its unbalanced extension (UOT) to propose a criterion that can address all three issues. This proposal leverages a smooth formulation of DTW (Soft-DTW) that is shown to capture temporal shifts, and UOT to handle both variations in space and size. Our proposed loss can be used to define spatio-temporal barycenters as Fr\'echet means. Using Fenchel duality, we show how these barycenters can be computed efficiently, in parallel, via a novel variant of entropy-regularized debiased UOT. Experiments on handwritten letters and brain imaging data confirm our theoretical findings and illustrate the effectiveness of the proposed loss for spatio-temporal data.
Paying Attention to Astronomical Transients: Photometric Classification with the Time-Series Transformer
May 13, 2021
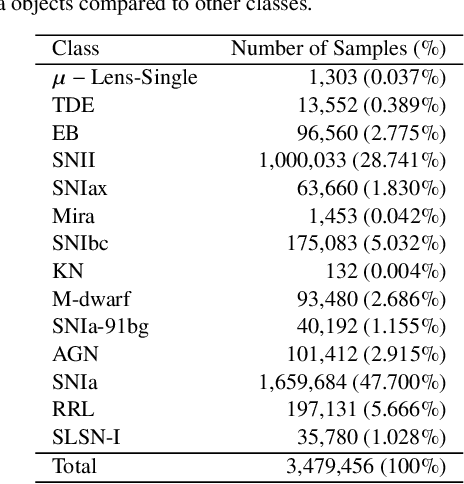
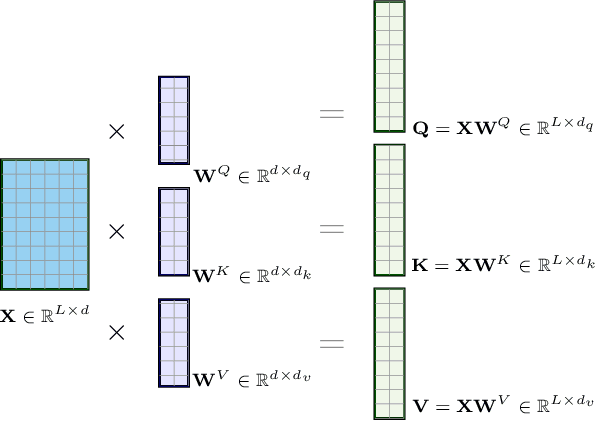
Future surveys such as the Legacy Survey of Space and Time (LSST) of the Vera C. Rubin Observatory will observe an order of magnitude more astrophysical transient events than any previous survey before. With this deluge of photometric data, it will be impossible for all such events to be classified by humans alone. Recent efforts have sought to leverage machine learning methods to tackle the challenge of astronomical transient classification, with ever improving success. Transformers are a recently developed deep learning architecture, first proposed for natural language processing, that have shown a great deal of recent success. In this work we develop a new transformer architecture, which uses multi-head self attention at its core, for general multi-variate time-series data. Furthermore, the proposed time-series transformer architecture supports the inclusion of an arbitrary number of additional features, while also offering interpretability. We apply the time-series transformer to the task of photometric classification, minimising the reliance of expert domain knowledge for feature selection, while achieving results comparable to state-of-the-art photometric classification methods. We achieve a weighted logarithmic-loss of 0.507 on imbalanced data in a representative setting using data from the Photometric LSST Astronomical Time-Series Classification Challenge (PLAsTiCC). Moreover, we achieve a micro-averaged receiver operating characteristic area under curve of 0.98 and micro-averaged precision-recall area under curve of 0.87.
Population Diversity Leads to Short Running Times of Lexicase Selection
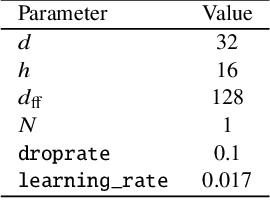
Apr 13, 2022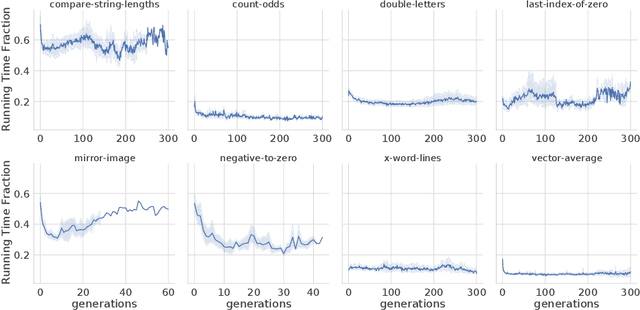
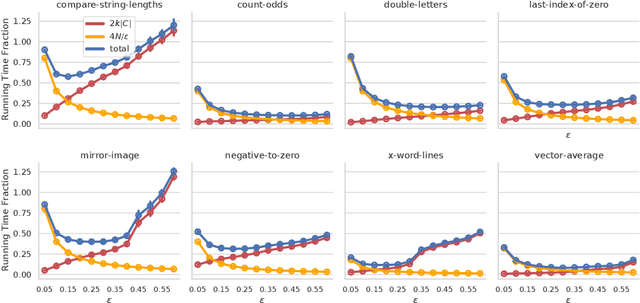
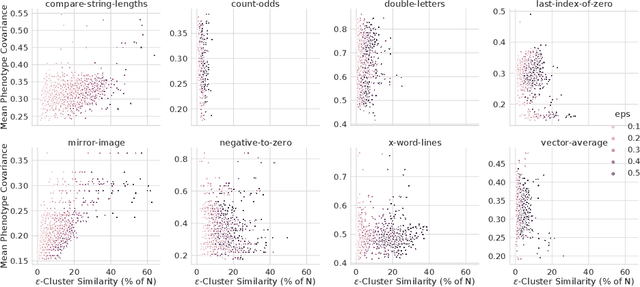
In this paper we investigate why the running time of lexicase parent selection is empirically much lower than its worst-case bound of O(N*C). We define a measure of population diversity and prove that high diversity leads to low running times O(N + C) of lexicase selection. We then show empirically that genetic programming populations evolved under lexicase selection are diverse for several program synthesis problems, and explore the resulting differences in running time bounds.
AttentionFlow: Visualising Influence in Networks of Time Series
Feb 03, 2021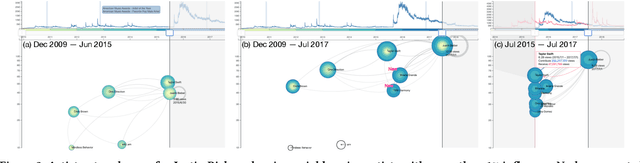
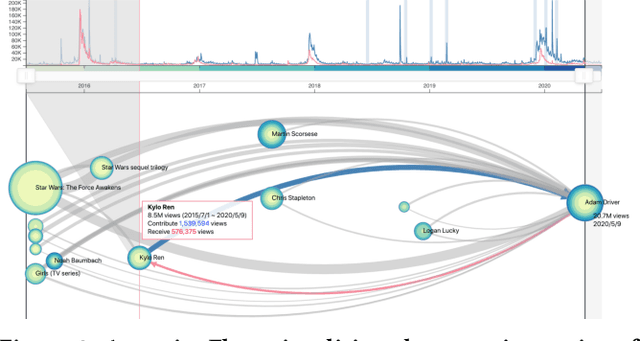
The collective attention on online items such as web pages, search terms, and videos reflects trends that are of social, cultural, and economic interest. Moreover, attention trends of different items exhibit mutual influence via mechanisms such as hyperlinks or recommendations. Many visualisation tools exist for time series, network evolution, or network influence; however, few systems connect all three. In this work, we present AttentionFlow, a new system to visualise networks of time series and the dynamic influence they have on one another. Centred around an ego node, our system simultaneously presents the time series on each node using two visual encodings: a tree ring for an overview and a line chart for details. AttentionFlow supports interactions such as overlaying time series of influence and filtering neighbours by time or flux. We demonstrate AttentionFlow using two real-world datasets, VevoMusic and WikiTraffic. We show that attention spikes in songs can be explained by external events such as major awards, or changes in the network such as the release of a new song. Separate case studies also demonstrate how an artist's influence changes over their career, and that correlated Wikipedia traffic is driven by cultural interests. More broadly, AttentionFlow can be generalised to visualise networks of time series on physical infrastructures such as road networks, or natural phenomena such as weather and geological measurements.
* Published in WSDM 2021. The demo is available at https://attentionflow.ml and code is available at https://github.com/alasdairtran/attentionflow