 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
STAR-RIS-Assisted Hybrid NOMA mmWave Communication: Optimization and Performance Analysis
May 13, 2022
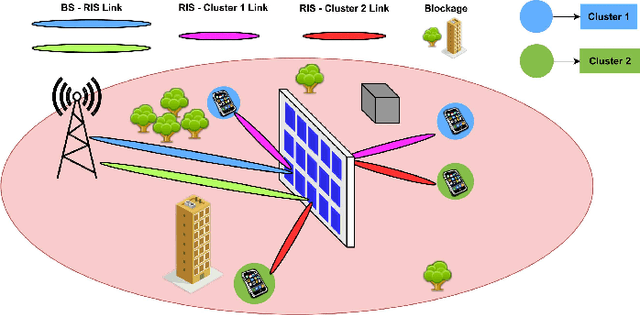
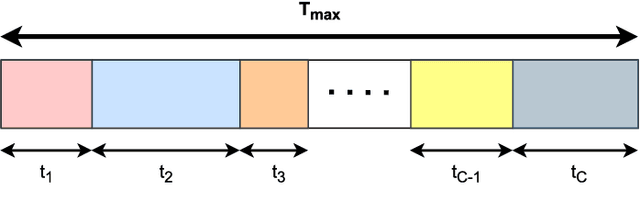
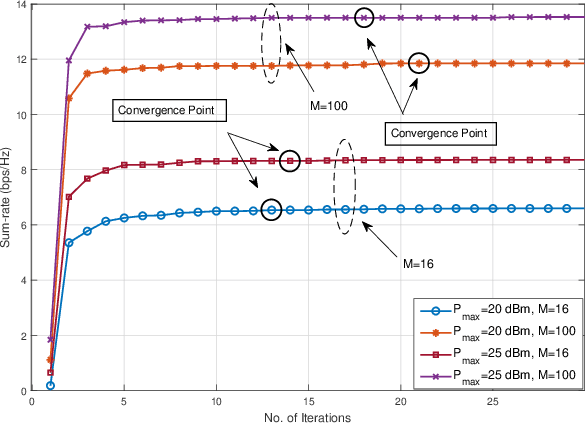
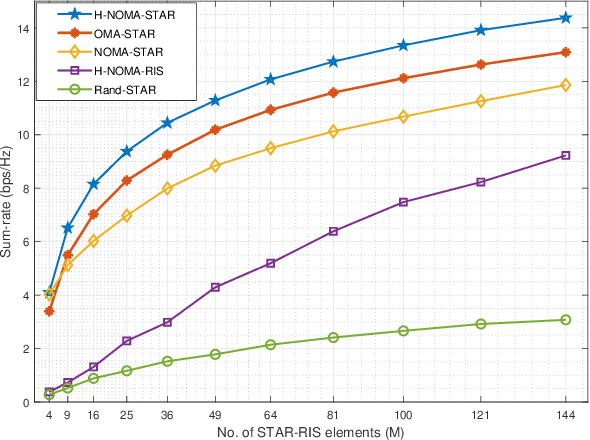
Simultaneously reflecting and transmitting reconfigurable intelligent surfaces (STAR-RIS) has recently emerged as prominent technology that exploits the transmissive property of RIS to mitigate the half-space coverage limitation of conventional RIS operating on millimeter-wave (mmWave). In this paper, we study a downlink STAR-RIS-based multi-user multiple-input single-output (MU-MISO) mmWave hybrid non-orthogonal multiple access (H-NOMA) wireless network, where a sum-rate maximization problem has been formulated. The design of active and passive beamforming vectors, time and power allocation for H-NOMA is a highly coupled non-convex problem. To handle the problem, we propose an optimization framework based on alternating optimization (AO) that iteratively solves active and passive beamforming sub-problems. Channel correlations and channel strength-based techniques have been proposed for a specific case of two-user optimal clustering and decoding order assignment, respectively, for which analytical solutions to joint power and time allocation for H-NOMA have also been derived. Simulation results show that: 1) the proposed framework leveraging H-NOMA outperforms conventional OMA and NOMA to maximize the achievable sum-rate; 2) using the proposed framework, the supported number of clusters for the given design constraints can be increased considerably; 3) through STAR-RIS, the number of elements can be significantly reduced as compared to conventional RIS to ensure a similar quality-of-service (QoS).
pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models
Jun 23, 2022



Knowledge tracing (KT) is the task of using students' historical learning interaction data to model their knowledge mastery over time so as to make predictions on their future interaction performance. Recently, remarkable progress has been made of using various deep learning techniques to solve the KT problem. However, the success behind deep learning based knowledge tracing (DLKT) approaches is still left somewhat mysterious and proper measurement and analysis of these DLKT approaches remain a challenge. First, data preprocessing procedures in existing works are often private and/or custom, which limits experimental standardization. Furthermore, existing DLKT studies often differ in terms of the evaluation protocol and are far away real-world educational contexts. To address these problems, we introduce a comprehensive python based benchmark platform, \textsc{pyKT}, to guarantee valid comparisons across DLKT methods via thorough evaluations. The \textsc{pyKT} library consists of a standardized set of integrated data preprocessing procedures on 7 popular datasets across different domains, and 10 frequently compared DLKT model implementations for transparent experiments. Results from our fine-grained and rigorous empirical KT studies yield a set of observations and suggestions for effective DLKT, e.g., wrong evaluation setting may cause label leakage that generally leads to performance inflation; and the improvement of many DLKT approaches is minimal compared to the very first DLKT model proposed by Piech et al. \cite{piech2015deep}. We have open sourced \textsc{pyKT} and our experimental results at \url{https://pykt.org/}. We welcome contributions from other research groups and practitioners.
Learning who is in the market from time series: market participant discovery through adversarial calibration of multi-agent simulators
Aug 02, 2021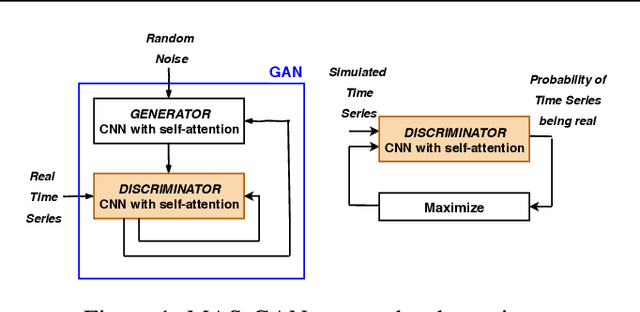
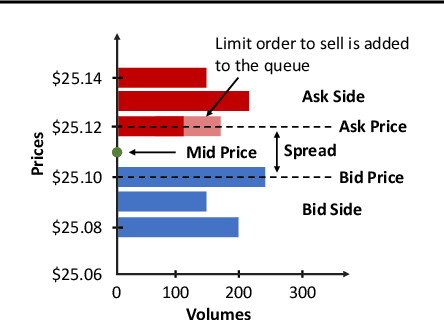
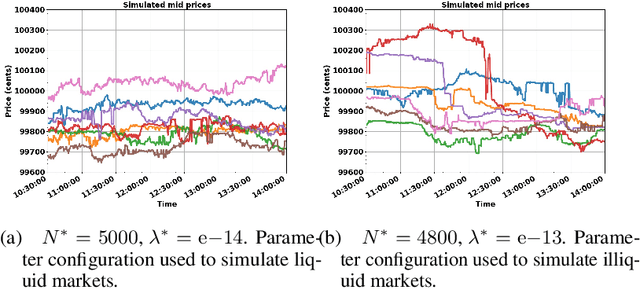
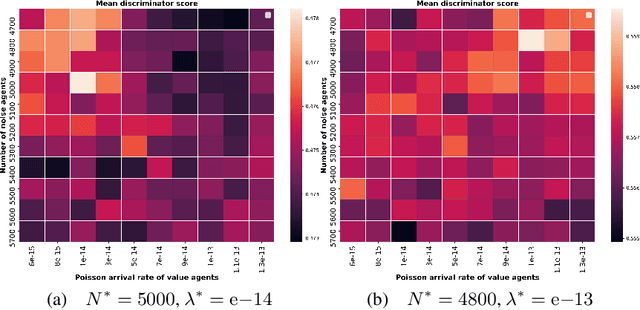
In electronic trading markets often only the price or volume time series, that result from interaction of multiple market participants, are directly observable. In order to test trading strategies before deploying them to real-time trading, multi-agent market environments calibrated so that the time series that result from interaction of simulated agents resemble historical are often used. To ensure adequate testing, one must test trading strategies in a variety of market scenarios -- which includes both scenarios that represent ordinary market days as well as stressed markets (most recently observed due to the beginning of COVID pandemic). In this paper, we address the problem of multi-agent simulator parameter calibration to allow simulator capture characteristics of different market regimes. We propose a novel two-step method to train a discriminator that is able to distinguish between "real" and "fake" price and volume time series as a part of GAN with self-attention, and then utilize it within an optimization framework to tune parameters of a simulator model with known agent archetypes to represent a market scenario. We conclude with experimental results that demonstrate effectiveness of our method.
Image-based Treatment Effect Heterogeneity
Jun 13, 2022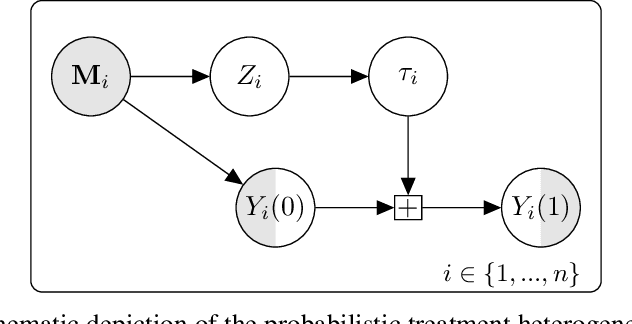
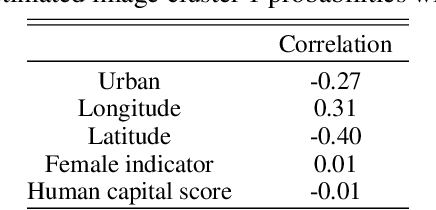
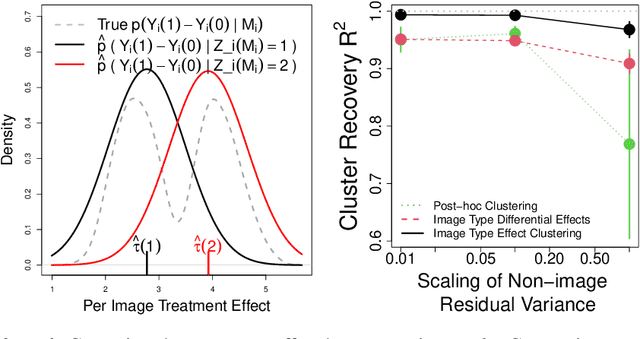
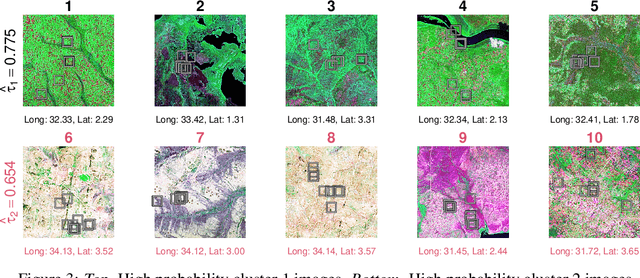
Randomized controlled trials (RCTs) are considered the gold standard for estimating the effects of interventions. Recent work has studied effect heterogeneity in RCTs by conditioning estimates on tabular variables such as age and ethnicity. However, such variables are often only observed near the time of the experiment and may fail to capture historical or geographical reasons for effect variation. When experiment units are associated with a particular location, satellite imagery can provide such historical and geographical information, yet there is no method which incorporates it for describing effect heterogeneity. In this paper, we develop such a method which estimates, using a deep probabilistic modeling framework, the clusters of images having the same distribution over treatment effects. We compare the proposed methods against alternatives in simulation and in an application to estimating the effects of an anti-poverty intervention in Uganda. A causal regularization penalty is introduced to ensure reliability of the cluster model in recovering Average Treatment Effects (ATEs). Finally, we discuss feasibility, limitations, and the applicability of these methods to other domains, such as medicine and climate science, where image information is prevalent. We make code for all modeling strategies publicly available in an open-source software package.
A real-time global re-localization framework for 3D LiDAR SLAM
Sep 01, 2021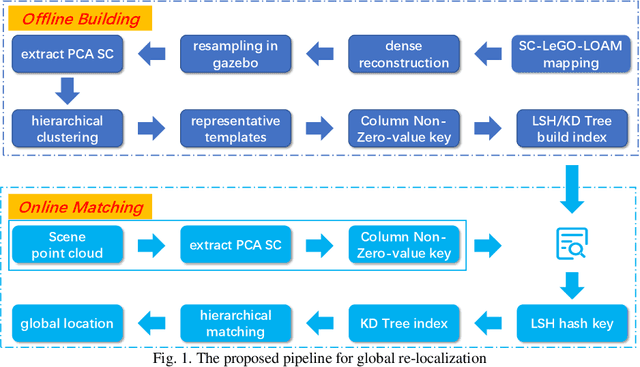

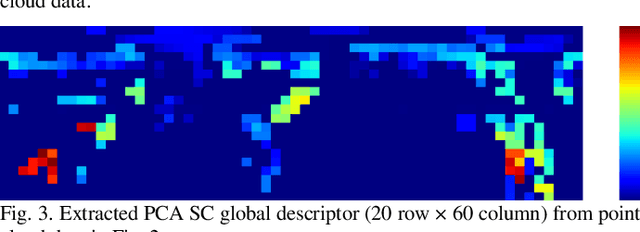

Simultaneous localization and mapping (SLAM) has been a hot research field in the past years. Against the backdrop of more affordable 3D LiDAR sensors, research on 3D LiDAR SLAM is becoming increasingly popular. Furthermore, the re-localization problem with a point cloud map is the foundation for other SLAM applications. In this paper, a template matching framework is proposed to re-localize a robot globally in a 3D LiDAR map. This presents two main challenges. First, most global descriptors for point cloud can only be used for place detection under a small local area. Therefore, in order to re-localize globally in the map, point clouds and descriptors(templates) are densely collected using a reconstructed mesh model at an offline stage by a physical simulation engine to expand the functional distance of point cloud descriptors. Second, the increased number of collected templates makes the matching stage too slow to meet the real-time requirement, for which a cascade matching method is presented for better efficiency. In the experiments, the proposed framework achieves 0.2-meter accuracy at about 10Hz matching speed using pure python implementation with 100k templates, which is effective and efficient for SLAM applications.
Cooperative Retriever and Ranker in Deep Recommenders
Jun 28, 2022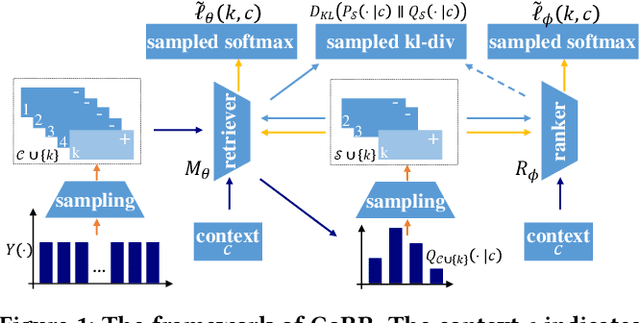

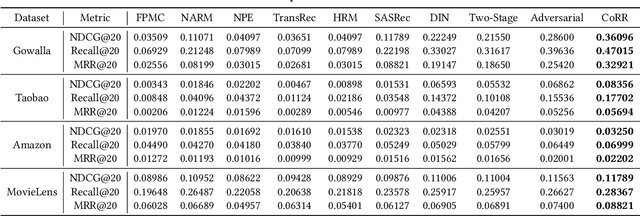
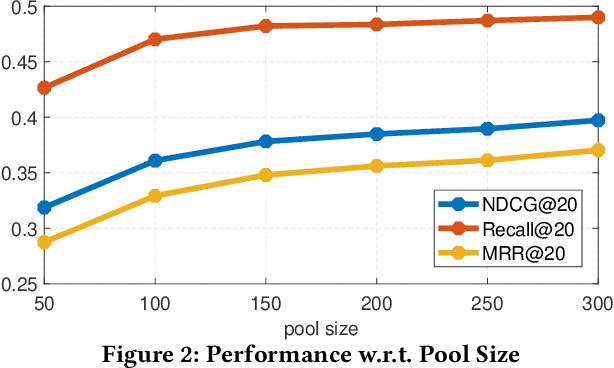
Deep recommender systems jointly leverage the retrieval and ranking operations to generate the recommendation result. The retriever targets selecting a small set of relevant candidates from the entire items with high efficiency; while the ranker, usually more precise but time-consuming, is supposed to identify the best items out of the retrieved candidates with high precision. However, the retriever and ranker are usually trained in poorly-cooperative ways, leading to limited recommendation performances when working as an entirety. In this work, we propose a novel DRS training framework CoRR(short for Cooperative Retriever and Ranker), where the retriever and ranker can be mutually reinforced. On one hand, the retriever is learned from recommendation data and the ranker via knowledge distillation; knowing that the ranker is more precise, the knowledge distillation may provide extra weak-supervision signals for the improvement of retrieval quality. On the other hand, the ranker is trained by learning to discriminate the truth positive items from hard negative candidates sampled from the retriever. With the iteration going on, the ranker may become more precise, which in return gives rise to informative training signals for the retriever; meanwhile, with the improvement of retriever, harder negative candidates can be sampled, which contributes to a higher discriminative capability of the ranker. To facilitate the effective conduct of CoRR, an asymptotic-unbiased approximation of KL divergence is introduced for the knowledge distillation over sampled items; besides, a scalable and adaptive strategy is developed to efficiently sample from the retriever. Comprehensive experimental studies are performed over four large-scale benchmark datasets, where CoRR improves the overall recommendation quality resulting from the cooperation between retriever and ranker.
Tight lower bounds for Dynamic Time Warping
Feb 14, 2021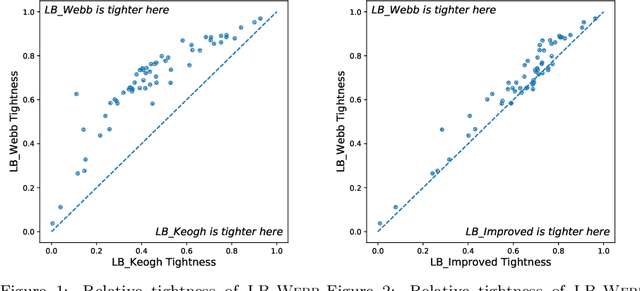
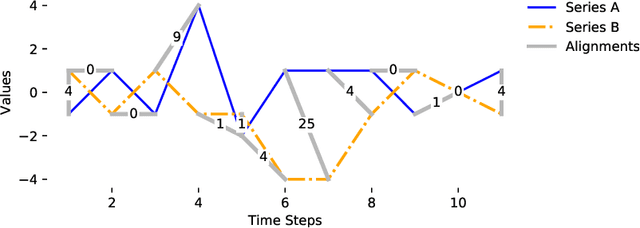
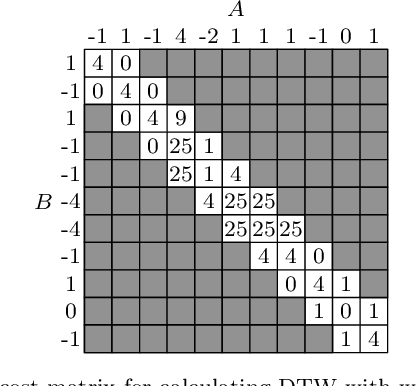
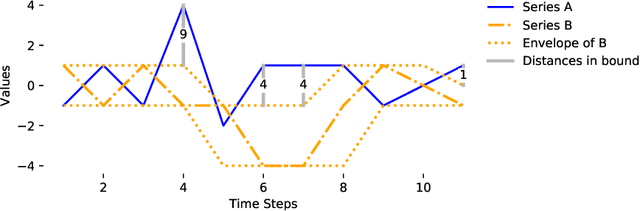
Dynamic Time Warping (DTW) is a popular similarity measure for aligning and comparing time series. Due to DTW's high computation time, lower bounds are often employed to screen poor matches. Many alternative lower bounds have been proposed, providing a range of different trade-offs between tightness and computational efficiency. LB Keogh provides a useful trade-off in many applications. Two recent lower bounds, LB Improved and LB Enhanced, are substantially tighter than LB Keogh. All three have the same worst case computational complexity - linear with respect to series length and constant with respect to window size. We present four new DTW lower bounds in the same complexity class. LB Petitjean is substantially tighter than LB Improved, with only modest additional computational overhead. LB Webb is more efficient than LB Improved, while often providing a tighter bound. LB Webb is always tighter than LB Keogh. The parameter free LB Webb is usually tighter than LB Enhanced. A parameterized variant, LB Webb Enhanced, is always tighter than LB Enhanced. A further variant, LB Webb*, is useful for some constrained distance functions. In extensive experiments, LB Webb proves to be very effective for nearest neighbor search.
Robust-RRT: Probabilistically-Complete Motion Planning for Uncertain Nonlinear Systems
May 16, 2022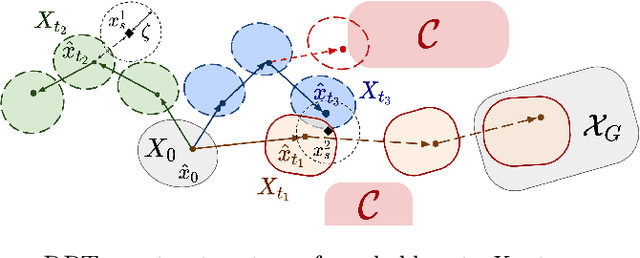
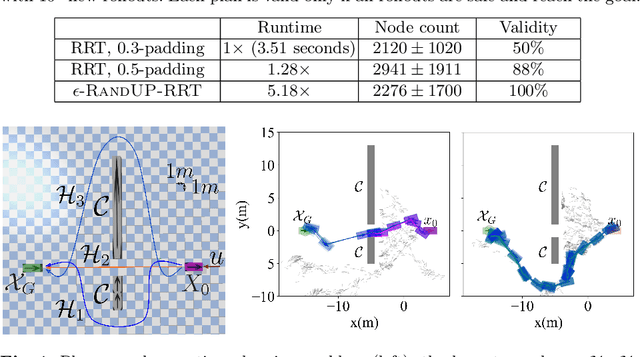
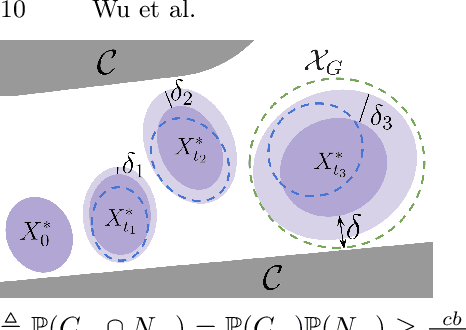

Robust motion planning entails computing a global motion plan that is safe under all possible uncertainty realizations, be it in the system dynamics, the robot's initial position, or with respect to external disturbances. Current approaches for robust motion planning either lack theoretical guarantees, or make restrictive assumptions on the system dynamics and uncertainty distributions. In this paper, we address these limitations by proposing the robust rapidly-exploring random-tree (Robust-RRT) algorithm, which integrates forward reachability analysis directly into sampling-based control trajectory synthesis. We prove that Robust-RRT is probabilistically complete (PC) for nonlinear Lipschitz continuous dynamical systems with bounded uncertainty. In other words, Robust-RRT eventually finds a robust motion plan that is feasible under all possible uncertainty realizations assuming such a plan exists. Our analysis applies even to unstable systems that admit only short-horizon feasible plans; this is because we explicitly consider the time evolution of reachable sets along control trajectories. Thanks to the explicit consideration of time dependency in our analysis, PC applies to unstabilizable systems. To the best of our knowledge, this is the most general PC proof for robust sampling-based motion planning, in terms of the types of uncertainties and dynamical systems it can handle. Considering that an exact computation of reachable sets can be computationally expensive for some dynamical systems, we incorporate sampling-based reachability analysis into Robust-RRT and demonstrate our robust planner on nonlinear, underactuated, and hybrid systems.
Real-time 10,000 km Straight-line Transmission using a Software-defined GPU-Based Receiver
Aug 16, 2021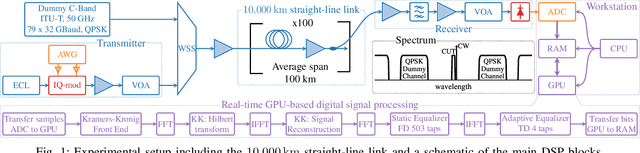
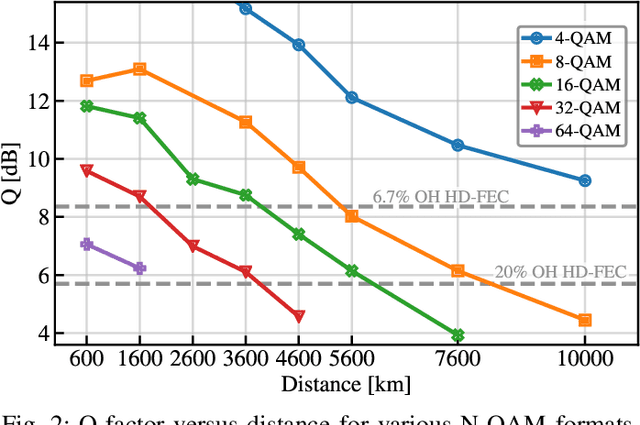
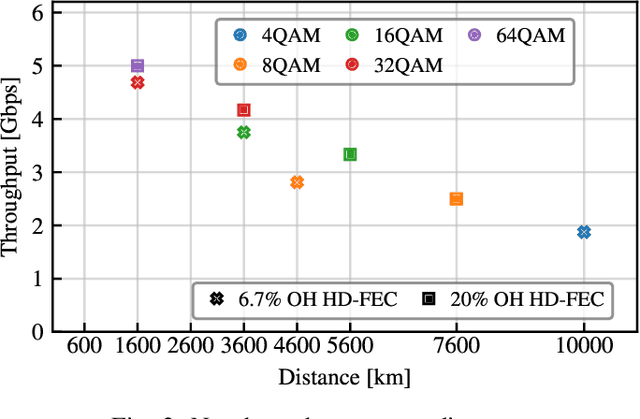
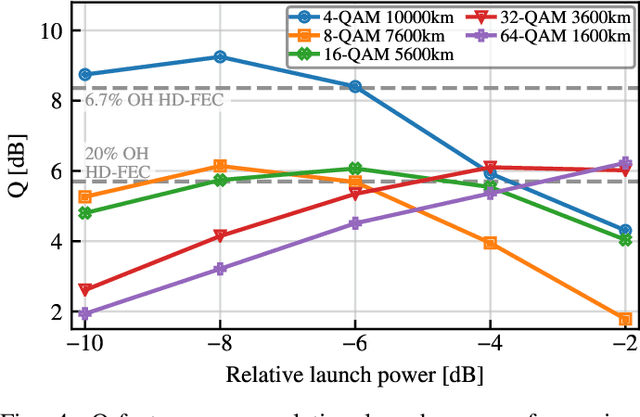
Real-time 10,000 km transmission over a straight-line link is achieved using a software-defined multi-modulation format receiver implemented on a commercial off-the-shelf general-purpose graphics processing unit (GPU). Minimum phase 1 GBaud 4-ary quadrature amplitude modulation (QAM) signals are transmitted over 10,000 km and successfully received after detection with a Kramers-Kronig (KK) coherent receiver. 8-, 16-, 32-, and 64-QAM are successfully transmitted over 7600, 5600, 3600, and 1600 km, respectively.
Transformer Lesion Tracker
Jun 13, 2022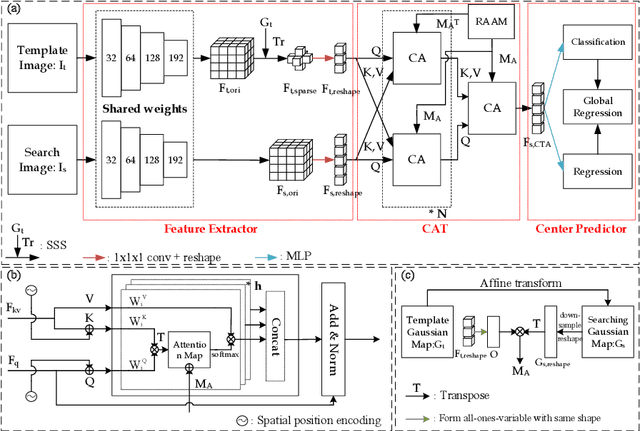
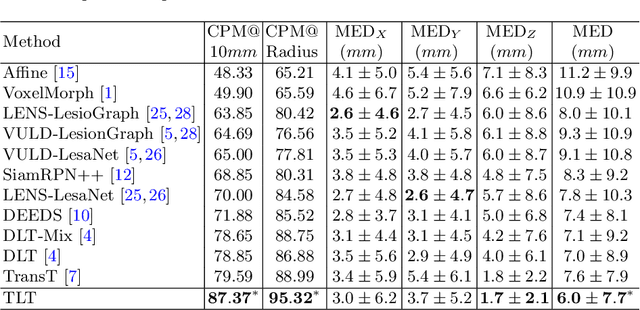
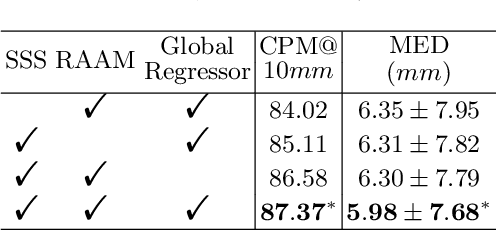

Evaluating lesion progression and treatment response via longitudinal lesion tracking plays a critical role in clinical practice. Automated approaches for this task are motivated by prohibitive labor costs and time consumption when lesion matching is done manually. Previous methods typically lack the integration of local and global information. In this work, we propose a transformer-based approach, termed Transformer Lesion Tracker (TLT). Specifically, we design a Cross Attention-based Transformer (CAT) to capture and combine both global and local information to enhance feature extraction. We also develop a Registration-based Anatomical Attention Module (RAAM) to introduce anatomical information to CAT so that it can focus on useful feature knowledge. A Sparse Selection Strategy (SSS) is presented for selecting features and reducing memory footprint in Transformer training. In addition, we use a global regression to further improve model performance. We conduct experiments on a public dataset to show the superiority of our method and find that our model performance has improved the average Euclidean center error by at least 14.3% (6mm vs. 7mm) compared with the state-of-the-art (SOTA). Code is available at https://github.com/TangWen920812/TLT.