 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Energy-Efficient Wake-Up Signalling for Machine-Type Devices Based on Traffic-Aware Long-Short Term Memory Prediction
Jun 13, 2022
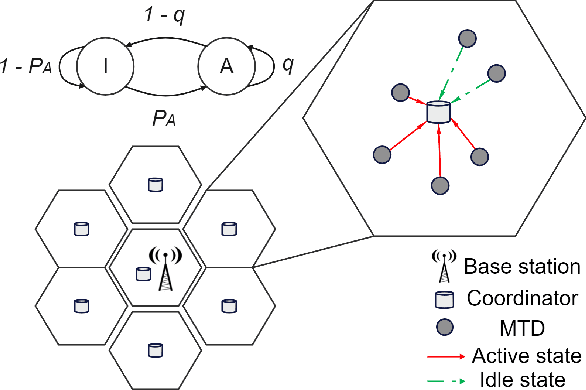
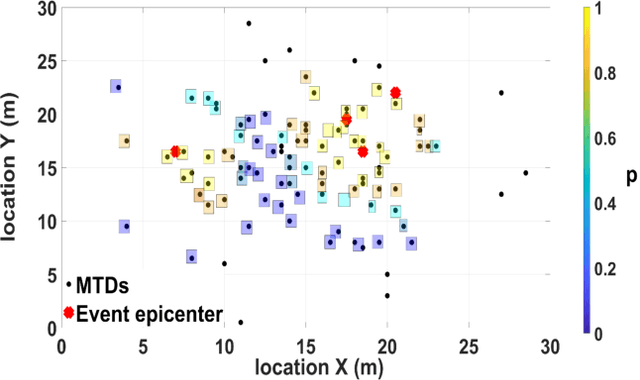
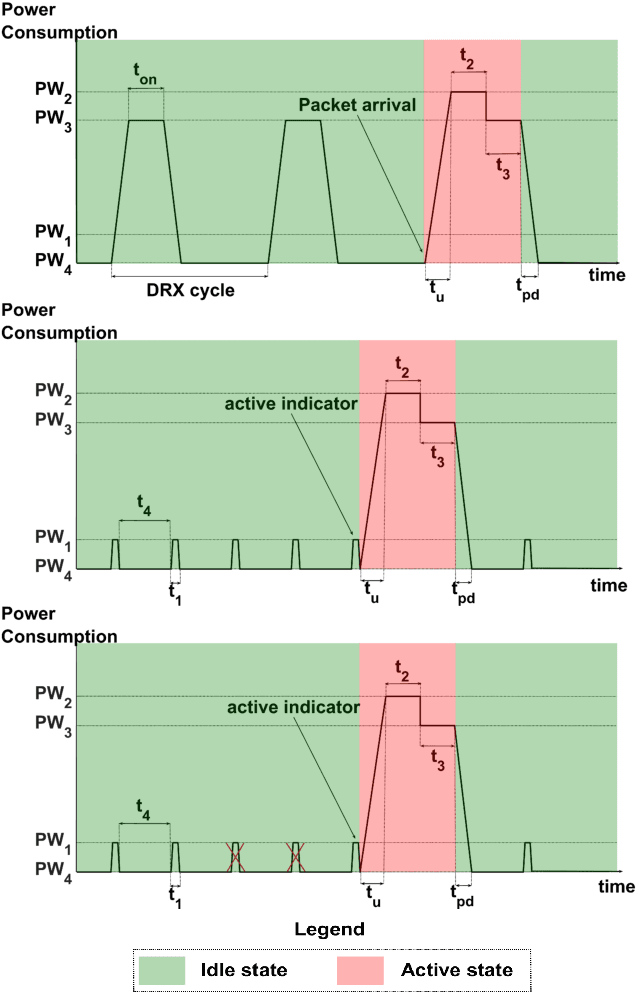
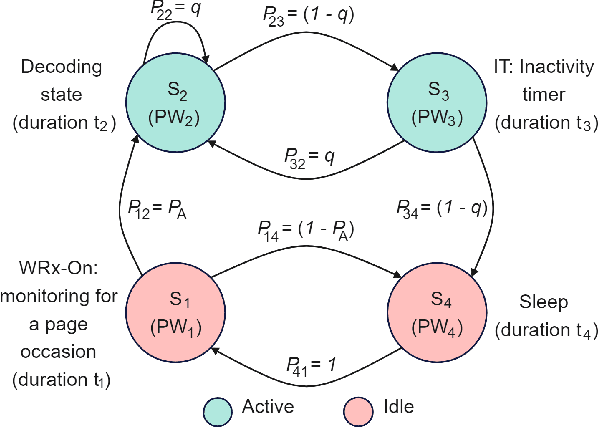
Reducing energy consumption is a pressing issue in low-power machine-type communication (MTC) networks. In this regard, the Wake-up Signal (WuS) technology, which aims to minimize the energy consumed by the radio interface of the machine-type devices (MTDs), stands as a promising solution. However, state-of-the-art WuS mechanisms use static operational parameters, so they cannot efficiently adapt to the system dynamics. To overcome this, we design a simple but efficient neural network to predict MTC traffic patterns and configure WuS accordingly. Our proposed forecasting WuS (FWuS) leverages an accurate long-short term memory (LSTM)- based traffic prediction that allows extending the sleep time of MTDs by avoiding frequent page monitoring occasions in idle state. Simulation results show the effectiveness of our approach. The traffic prediction errors are shown to be below 4%, being false alarm and miss-detection probabilities respectively below 8.8% and 1.3%. In terms of energy consumption reduction, FWuS can outperform the best benchmark mechanism in up to 32%. Finally, we certify the ability of FWuS to dynamically adapt to traffic density changes, promoting low-power MTC scalability
CLAP: Learning Audio Concepts From Natural Language Supervision
Jun 09, 2022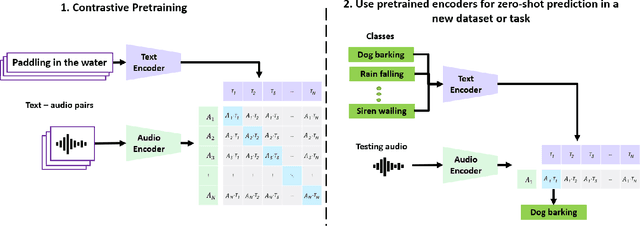
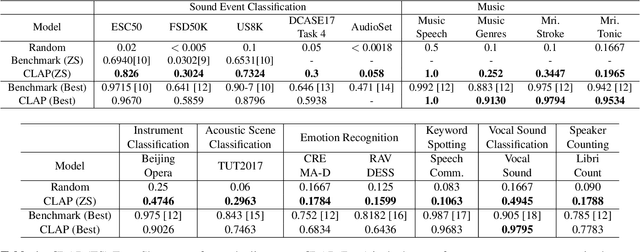
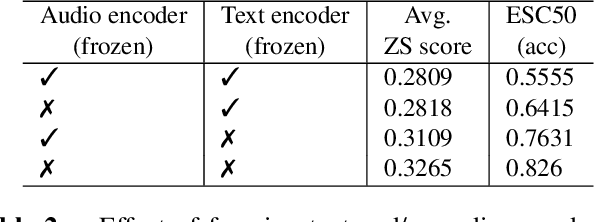
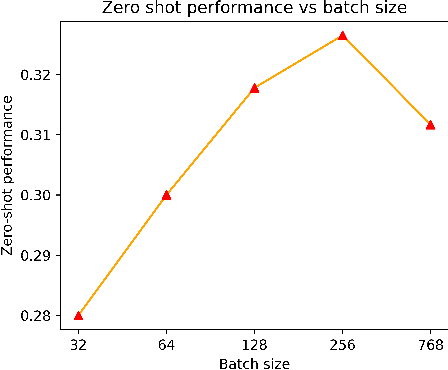
Mainstream Audio Analytics models are trained to learn under the paradigm of one class label to many recordings focusing on one task. Learning under such restricted supervision limits the flexibility of models because they require labeled audio for training and can only predict the predefined categories. Instead, we propose to learn audio concepts from natural language supervision. We call our approach Contrastive Language-Audio Pretraining (CLAP), which learns to connect language and audio by using two encoders and a contrastive learning to bring audio and text descriptions into a joint multimodal space. We trained CLAP with 128k audio and text pairs and evaluated it on 16 downstream tasks across 8 domains, such as Sound Event Classification, Music tasks, and Speech-related tasks. Although CLAP was trained with significantly less pairs than similar computer vision models, it establishes SoTA for Zero-Shot performance. Additionally, we evaluated CLAP in a supervised learning setup and achieve SoTA in 5 tasks. Hence, CLAP's Zero-Shot capability removes the need of training with class labels, enables flexible class prediction at inference time, and generalizes to multiple downstream tasks.
Simple Cues Lead to a Strong Multi-Object Tracker
Jun 13, 2022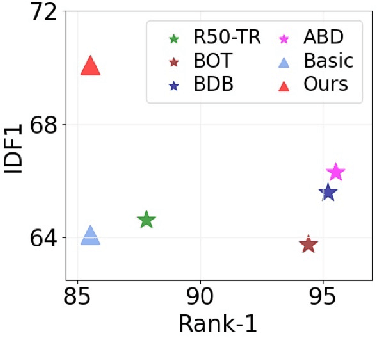

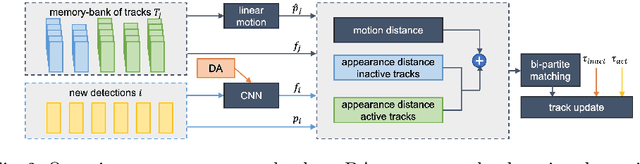
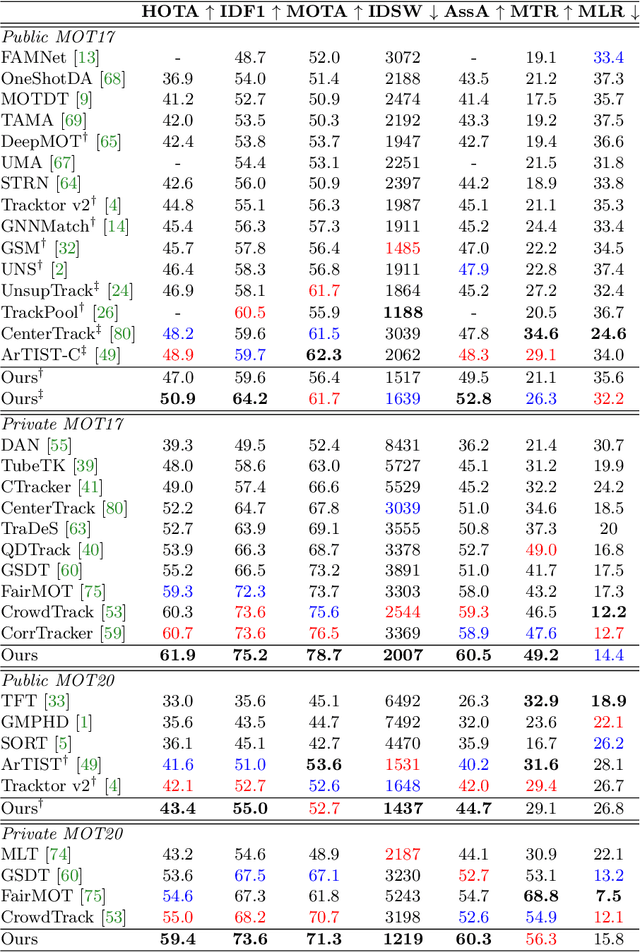
For a long time, the most common paradigm in Multi-Object Tracking was tracking-by-detection (TbD), where objects are first detected and then associated over video frames. For association, most models resource to motion and appearance cues. While still relying on these cues, recent approaches based on, e.g., attention have shown an ever-increasing need for training data and overall complex frameworks. We claim that 1) strong cues can be obtained from little amounts of training data if some key design choices are applied, 2) given these strong cues, standard Hungarian matching-based association is enough to obtain impressive results. Our main insight is to identify key components that allow a standard reidentification network to excel at appearance-based tracking. We extensively analyze its failure cases and show that a combination of our appearance features with a simple motion model leads to strong tracking results. Our model achieves state-of-the-art performance on MOT17 and MOT20 datasets outperforming previous state-of-the-art trackers by up to 5.4pp in IDF1 and 4.4pp in HOTA. We will release the code and models after the paper's acceptance.
Minimum projective linearizations of trees in linear time
Feb 17, 2021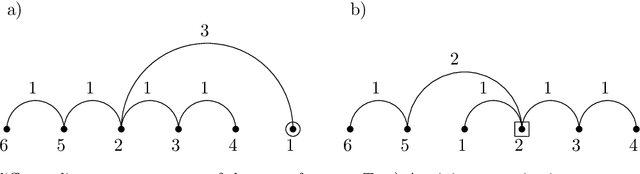

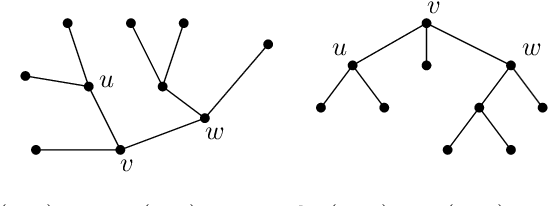
The minimum linear arrangement problem (MLA) consists of finding a mapping $\pi$ from vertices of a graph to integers that minimizes $\sum_{uv\in E}|\pi(u) - \pi(v)|$. For trees, various algorithms are available to solve the problem in polynomial time; the best known runs in subquadratic time in $n=|V|$. There exist variants of the MLA in which the arrangements are constrained to certain classes of projectivity. Iordanskii, and later Hochberg and Stallmann (HS), put forward $O(n)$-time algorithms that solve the problem when arrangements are constrained to be planar. We also consider linear arrangements of rooted trees that are constrained to be projective. Gildea and Temperley (GT) sketched an algorithm for the projectivity constraint which, as they claimed, runs in $O(n)$ but did not provide any justification of its cost. In contrast, Park and Levy claimed that GT's algorithm runs in $O(n \log d_{max})$ where $d_{max}$ is the maximum degree but did not provide sufficient detail. Here we correct an error in HS's algorithm for the planar case, show its relationship with the projective case, and derive an algorithm for the projective case that runs undoubtlessly in $O(n)$-time.
Asking the Right Questions in Low Resource Template Extraction
May 25, 2022
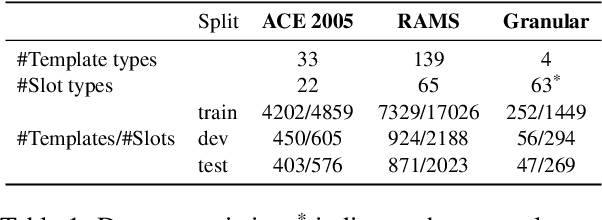
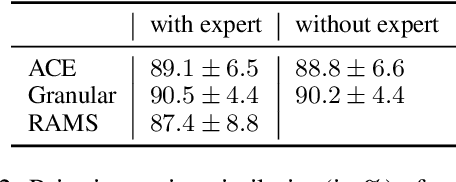
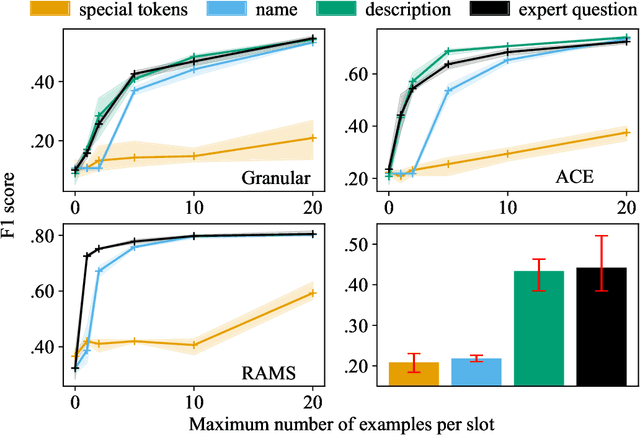
Information Extraction (IE) researchers are mapping tasks to Question Answering (QA) in order to leverage existing large QA resources, and thereby improve data efficiency. Especially in template extraction (TE), mapping an ontology to a set of questions can be more time-efficient than collecting labeled examples. We ask whether end users of TE systems can design these questions, and whether it is beneficial to involve an NLP practitioner in the process. We compare questions to other ways of phrasing natural language prompts for TE. We propose a novel model to perform TE with prompts, and find it benefits from questions over other styles of prompts, and that they do not require an NLP background to author.
Robust-RRT: Probabilistically-Complete Motion Planning for Uncertain Nonlinear Systems
May 16, 2022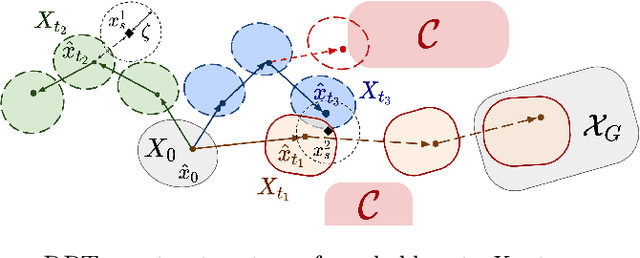
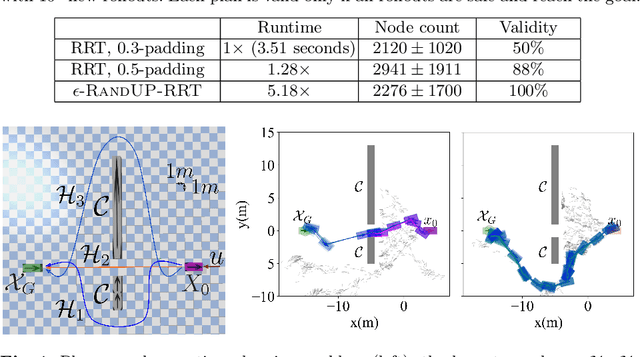
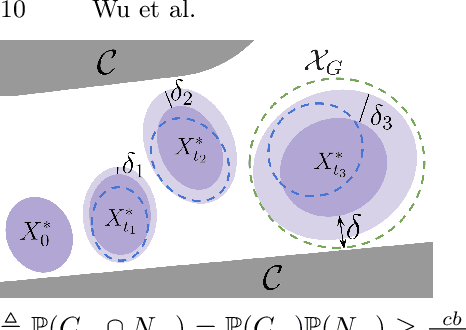

Robust motion planning entails computing a global motion plan that is safe under all possible uncertainty realizations, be it in the system dynamics, the robot's initial position, or with respect to external disturbances. Current approaches for robust motion planning either lack theoretical guarantees, or make restrictive assumptions on the system dynamics and uncertainty distributions. In this paper, we address these limitations by proposing the robust rapidly-exploring random-tree (Robust-RRT) algorithm, which integrates forward reachability analysis directly into sampling-based control trajectory synthesis. We prove that Robust-RRT is probabilistically complete (PC) for nonlinear Lipschitz continuous dynamical systems with bounded uncertainty. In other words, Robust-RRT eventually finds a robust motion plan that is feasible under all possible uncertainty realizations assuming such a plan exists. Our analysis applies even to unstable systems that admit only short-horizon feasible plans; this is because we explicitly consider the time evolution of reachable sets along control trajectories. Thanks to the explicit consideration of time dependency in our analysis, PC applies to unstabilizable systems. To the best of our knowledge, this is the most general PC proof for robust sampling-based motion planning, in terms of the types of uncertainties and dynamical systems it can handle. Considering that an exact computation of reachable sets can be computationally expensive for some dynamical systems, we incorporate sampling-based reachability analysis into Robust-RRT and demonstrate our robust planner on nonlinear, underactuated, and hybrid systems.
Parallel bandit architecture based on laser chaos for reinforcement learning
May 19, 2022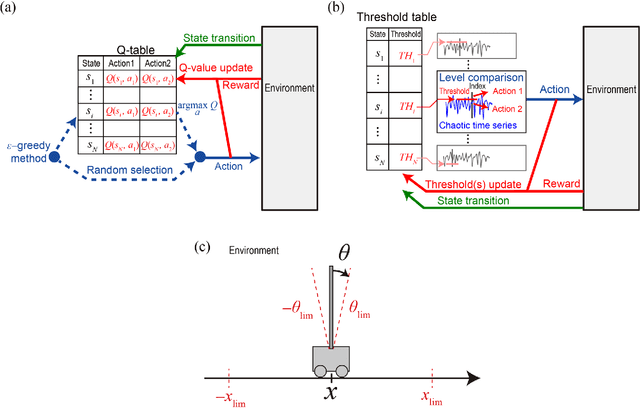

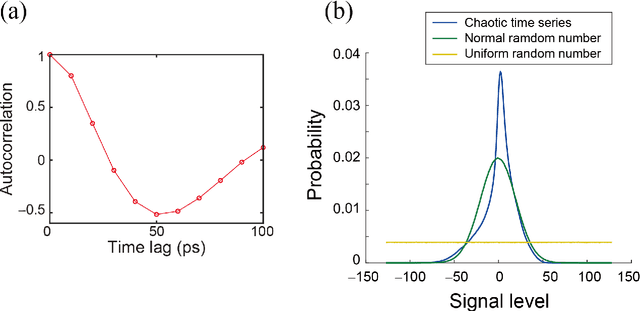
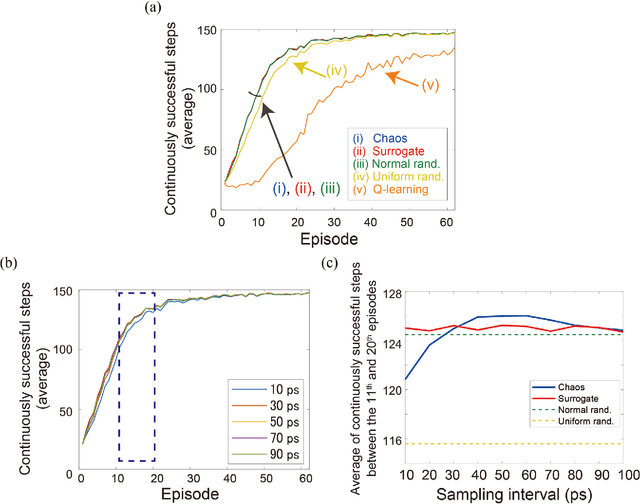
Accelerating artificial intelligence by photonics is an active field of study aiming to exploit the unique properties of photons. Reinforcement learning is an important branch of machine learning, and photonic decision-making principles have been demonstrated with respect to the multi-armed bandit problems. However, reinforcement learning could involve a massive number of states, unlike previously demonstrated bandit problems where the number of states is only one. Q-learning is a well-known approach in reinforcement learning that can deal with many states. The architecture of Q-learning, however, does not fit well photonic implementations due to its separation of update rule and the action selection. In this study, we organize a new architecture for multi-state reinforcement learning as a parallel array of bandit problems in order to benefit from photonic decision-makers, which we call parallel bandit architecture for reinforcement learning or PBRL in short. Taking a cart-pole balancing problem as an instance, we demonstrate that PBRL adapts to the environment in fewer time steps than Q-learning. Furthermore, PBRL yields faster adaptation when operated with a chaotic laser time series than the case with uniformly distributed pseudorandom numbers where the autocorrelation inherent in the laser chaos provides a positive effect. We also find that the variety of states that the system undergoes during the learning phase exhibits completely different properties between PBRL and Q-learning. The insights obtained through the present study are also beneficial for existing computing platforms, not just photonic realizations, in accelerating performances by the PBRL algorithms and correlated random sequences.
Surgical-VQA: Visual Question Answering in Surgical Scenes using Transformer
Jun 22, 2022
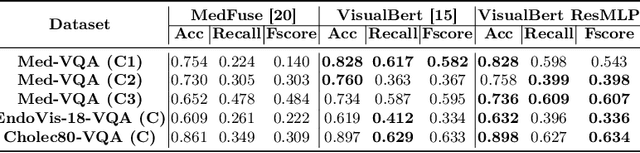
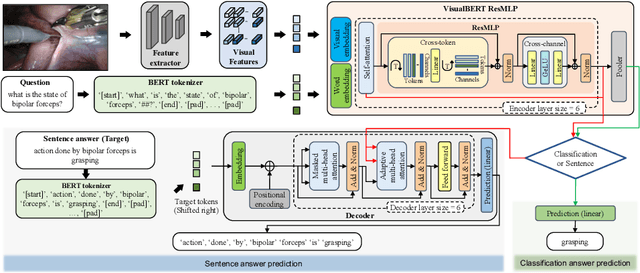
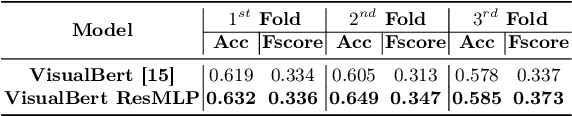
Visual question answering (VQA) in surgery is largely unexplored. Expert surgeons are scarce and are often overloaded with clinical and academic workloads. This overload often limits their time answering questionnaires from patients, medical students or junior residents related to surgical procedures. At times, students and junior residents also refrain from asking too many questions during classes to reduce disruption. While computer-aided simulators and recording of past surgical procedures have been made available for them to observe and improve their skills, they still hugely rely on medical experts to answer their questions. Having a Surgical-VQA system as a reliable 'second opinion' could act as a backup and ease the load on the medical experts in answering these questions. The lack of annotated medical data and the presence of domain-specific terms has limited the exploration of VQA for surgical procedures. In this work, we design a Surgical-VQA task that answers questionnaires on surgical procedures based on the surgical scene. Extending the MICCAI endoscopic vision challenge 2018 dataset and workflow recognition dataset further, we introduce two Surgical-VQA datasets with classification and sentence-based answers. To perform Surgical-VQA, we employ vision-text transformers models. We further introduce a residual MLP-based VisualBert encoder model that enforces interaction between visual and text tokens, improving performance in classification-based answering. Furthermore, we study the influence of the number of input image patches and temporal visual features on the model performance in both classification and sentence-based answering.
SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV Tracking
Jun 16, 2021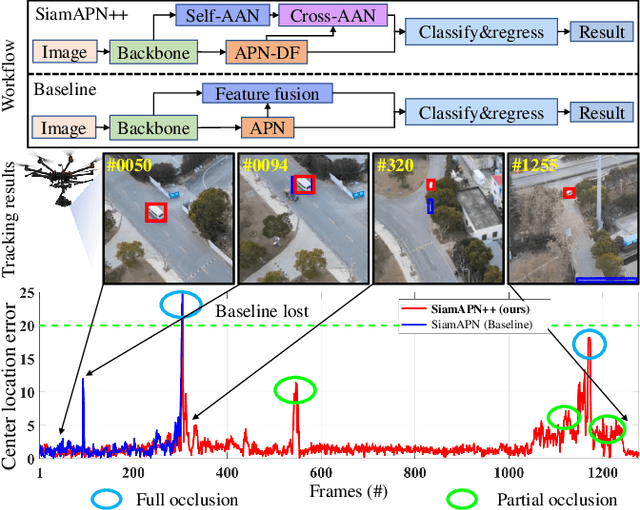
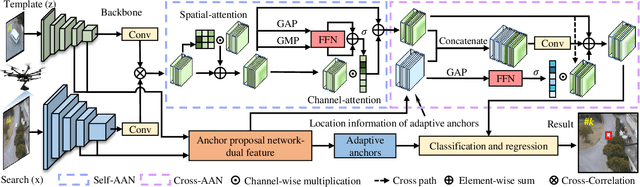
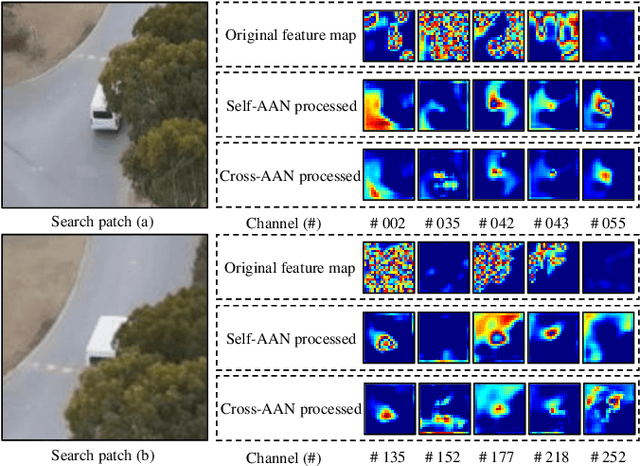
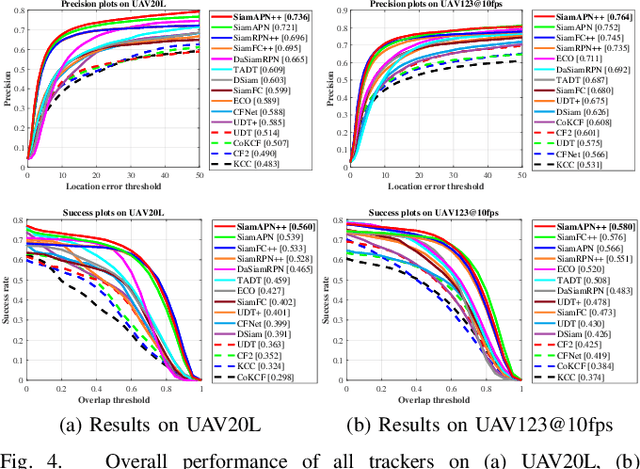
Recently, the Siamese-based method has stood out from multitudinous tracking methods owing to its state-of-the-art (SOTA) performance. Nevertheless, due to various special challenges in UAV tracking, \textit{e.g.}, severe occlusion, and fast motion, most existing Siamese-based trackers hardly combine superior performance with high efficiency. To this concern, in this paper, a novel attentional Siamese tracker (SiamAPN++) is proposed for real-time UAV tracking. By virtue of the attention mechanism, the attentional aggregation network (AAN) is conducted with self-AAN and cross-AAN, raising the expression ability of features eventually. The former AAN aggregates and models the self-semantic interdependencies of the single feature map via spatial and channel dimensions. The latter aims to aggregate the cross-interdependencies of different semantic features including the location information of anchors. In addition, the dual features version of the anchor proposal network is proposed to raise the robustness of proposing anchors, increasing the perception ability to objects with various scales. Experiments on two well-known authoritative benchmarks are conducted, where SiamAPN++ outperforms its baseline SiamAPN and other SOTA trackers. Besides, real-world tests onboard a typical embedded platform demonstrate that SiamAPN++ achieves promising tracking results with real-time speed.
AttX: Attentive Cross-Connections for Fusion of Wearable Signals in Emotion Recognition
Jun 09, 2022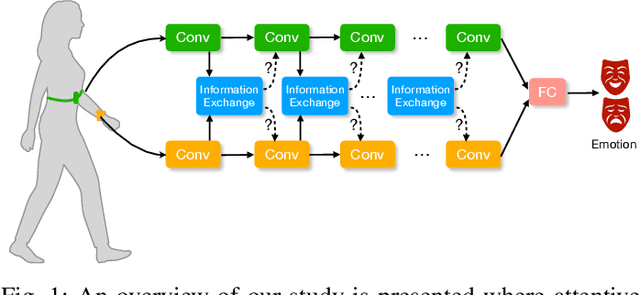
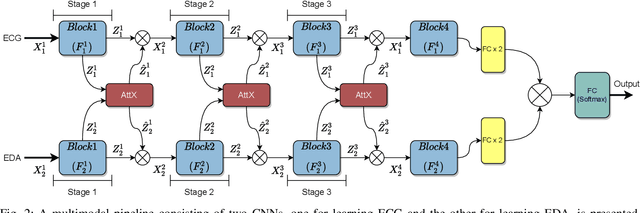
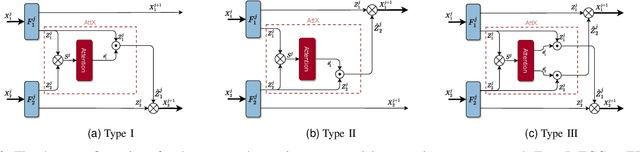
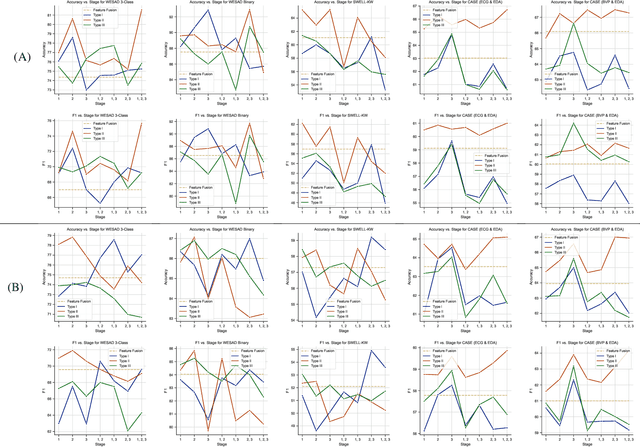
We propose cross-modal attentive connections, a new dynamic and effective technique for multimodal representation learning from wearable data. Our solution can be integrated into any stage of the pipeline, i.e., after any convolutional layer or block, to create intermediate connections between individual streams responsible for processing each modality. Additionally, our method benefits from two properties. First, it can share information uni-directionally (from one modality to the other) or bi-directionally. Second, it can be integrated into multiple stages at the same time to further allow network gradients to be exchanged in several touch-points. We perform extensive experiments on three public multimodal wearable datasets, WESAD, SWELL-KW, and CASE, and demonstrate that our method can effectively regulate and share information between different modalities to learn better representations. Our experiments further demonstrate that once integrated into simple CNN-based multimodal solutions (2, 3, or 4 modalities), our method can result in superior or competitive performance to state-of-the-art and outperform a variety of baseline uni-modal and classical multimodal methods.