 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Knowledge Distillation for Oriented Object Detection on Aerial Images
Jun 20, 2022

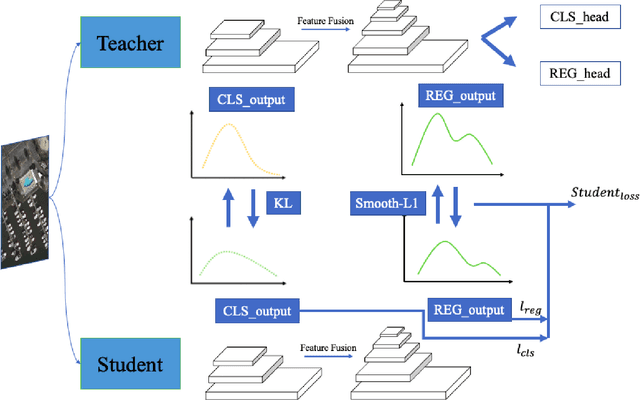
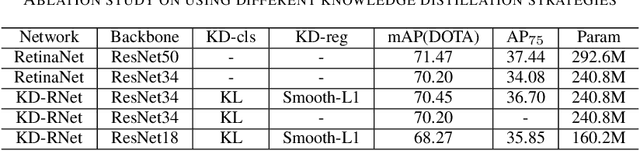
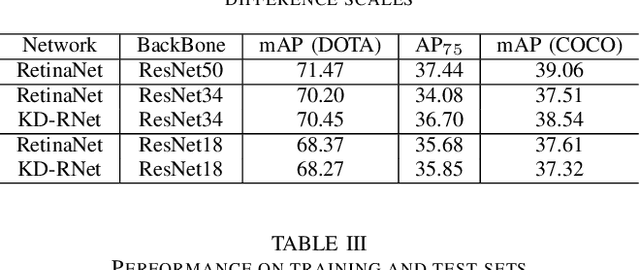
Deep convolutional neural network with increased number of parameters has achieved improved precision in task of object detection on natural images, where objects of interests are annotated with horizontal boundary boxes. On aerial images captured from the bird-view perspective, these improvements on model architecture and deeper convolutional layers can also boost the performance on oriented object detection task. However, it is hard to directly apply those state-of-the-art object detectors on the devices with limited computation resources, which necessitates lightweight models through model compression. In order to address this issue, we present a model compression method for rotated object detection on aerial images by knowledge distillation, namely KD-RNet. With a well-trained teacher oriented object detector with a large number of parameters, the obtained object category and location information are both transferred to a compact student network in KD-RNet by collaborative training strategy. Transferring the category information is achieved by knowledge distillation on predicted probability distribution, and a soft regression loss is adopted for handling displacement in location information transfer. The experimental result on a large-scale aerial object detection dataset (DOTA) demonstrates that the proposed KD-RNet model can achieve improved mean-average precision (mAP) with reduced number of parameters, at the same time, KD-RNet boost the performance on providing high quality detections with higher overlap with groundtruth annotations.
Wrist-Squeezing Force Feedback Improves Accuracy and Speed in Robotic Surgery Training
May 13, 2022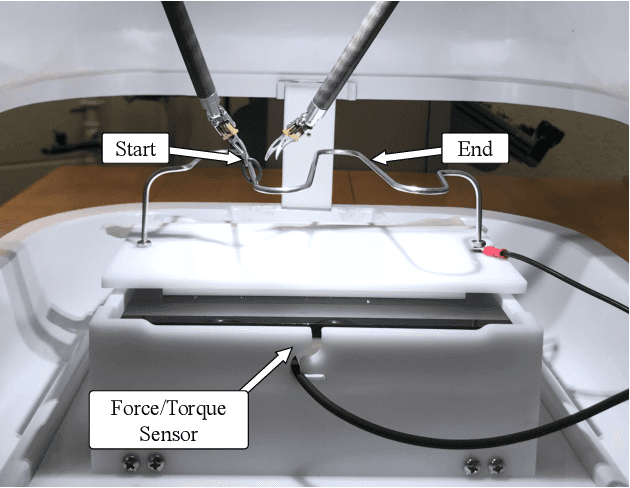
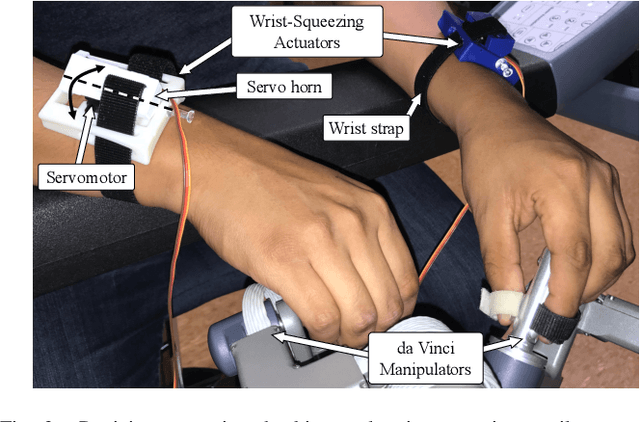
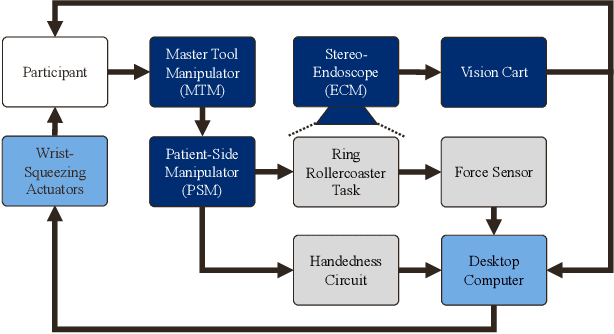
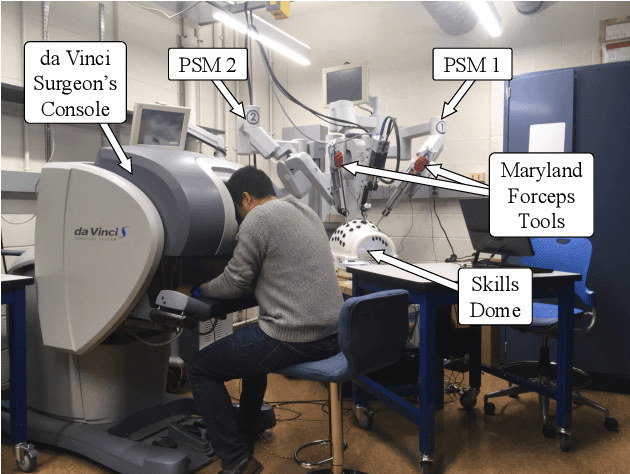
Current robotic minimally invasive surgery (RMIS) platforms provide surgeons with no haptic feedback of the robot's physical interactions. This limitation forces surgeons to rely heavily on visual feedback and can make it challenging for surgical trainees to manipulate tissue gently. Prior research has demonstrated that haptic feedback can increase task accuracy in RMIS training. However, it remains unclear whether these improvements represent a fundamental improvement in skill, or if they simply stem from re-prioritizing accuracy over task completion time. In this study, we provide haptic feedback of the force applied by the surgical instruments using custom wrist-squeezing devices. We hypothesize that individuals receiving haptic feedback will increase accuracy (produce less force) while increasing their task completion time, compared to a control group receiving no haptic feedback. To test this hypothesis, N=21 novice participants were asked to repeatedly complete a ring rollercoaster surgical training task as quickly as possible. Results show that participants receiving haptic feedback apply significantly less force (0.67 N) than the control group, and they complete the task no faster or slower than the control group after twelve repetitions. Furthermore, participants in the feedback group decreased their task completion times significantly faster (7.68%) than participants in the control group (5.26%). This form of haptic feedback, therefore, has the potential to help trainees improve their technical accuracy without compromising speed.
A Compression-Compilation Framework for On-mobile Real-time BERT Applications
May 30, 2021


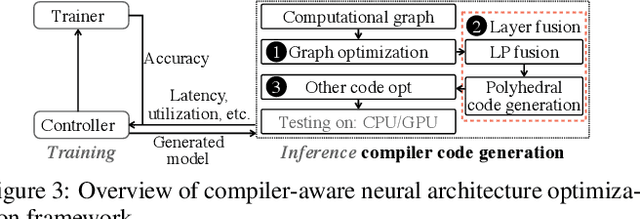
Transformer-based deep learning models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. In this paper, we propose a compression-compilation co-design framework that can guarantee the identified model to meet both resource and real-time specifications of mobile devices. Our framework applies a compiler-aware neural architecture optimization method (CANAO), which can generate the optimal compressed model that balances both accuracy and latency. We are able to achieve up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss. We present two types of BERT applications on mobile devices: Question Answering (QA) and Text Generation. Both can be executed in real-time with latency as low as 45ms. Videos for demonstrating the framework can be found on https://www.youtube.com/watch?v=_WIRvK_2PZI
No GPU? No problem: an ultra fast 3D detection of road users with a simple proposal generator and energy-based out-of-distribution PointNets
Jun 06, 2022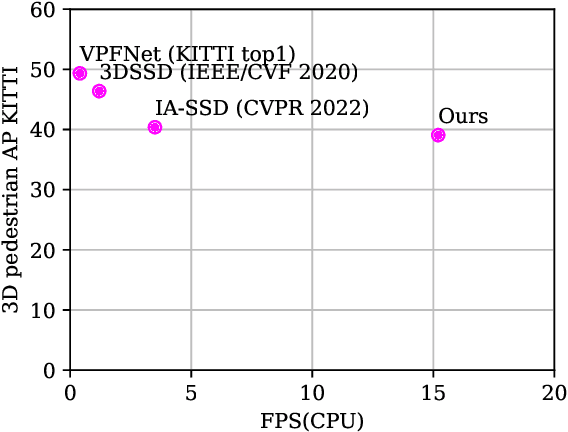
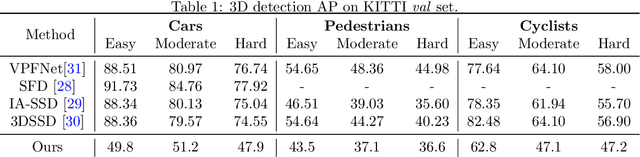
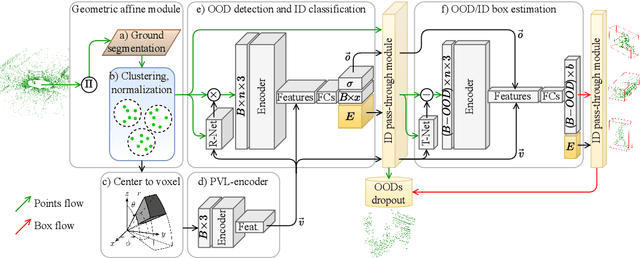
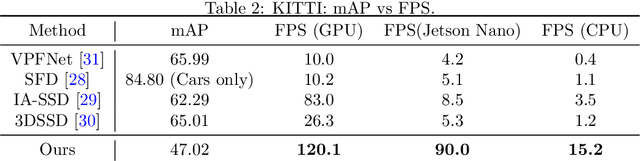
This paper presents a novel architecture for point cloud road user detection, which is based on a classical point cloud proposal generator approach, that utilizes simple geometrical rules. New methods are coupled with this technique to achieve extremely small computational requirement, and mAP that is comparable to the state-of-the-art. The idea is to specifically exploit geometrical rules in hopes of faster performance. The typical downsides of this approach, e.g. global context loss, are tackled in this paper, and solutions are presented. This approach allows real-time performance on a single core CPU, which is not the case with end-to-end solutions presented in the state-of-the-art. We have evaluated the performance of the method with the public KITTI dataset, and with our own annotated dataset collected with a small mobile robot platform. Moreover, we also present a novel ground segmentation method, which is evaluated with the public SemanticKITTI dataset.
Accelerating the Training of Video Super-Resolution Models
May 17, 2022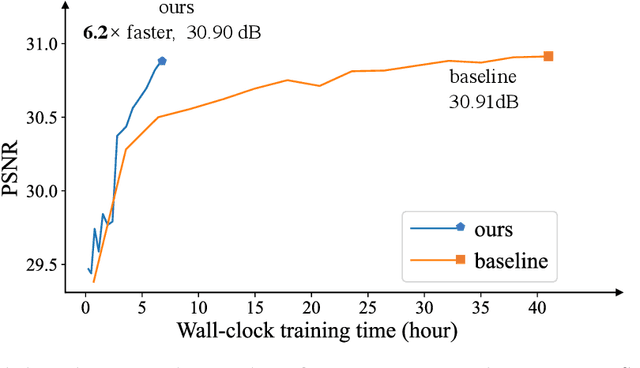
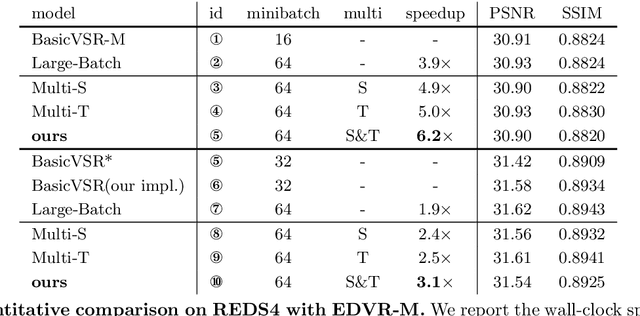
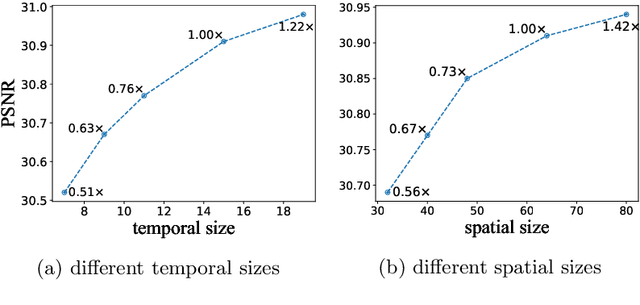

Despite that convolution neural networks (CNN) have recently demonstrated high-quality reconstruction for video super-resolution (VSR), efficiently training competitive VSR models remains a challenging problem. It usually takes an order of magnitude more time than training their counterpart image models, leading to long research cycles. Existing VSR methods typically train models with fixed spatial and temporal sizes from beginning to end. The fixed sizes are usually set to large values for good performance, resulting to slow training. However, is such a rigid training strategy necessary for VSR? In this work, we show that it is possible to gradually train video models from small to large spatial/temporal sizes, i.e., in an easy-to-hard manner. In particular, the whole training is divided into several stages and the earlier stage has smaller training spatial shape. Inside each stage, the temporal size also varies from short to long while the spatial size remains unchanged. Training is accelerated by such a multigrid training strategy, as most of computation is performed on smaller spatial and shorter temporal shapes. For further acceleration with GPU parallelization, we also investigate the large minibatch training without the loss in accuracy. Extensive experiments demonstrate that our method is capable of largely speeding up training (up to $6.2\times$ speedup in wall-clock training time) without performance drop for various VSR models. The code is available at https://github.com/TencentARC/Efficient-VSR-Training.
Structural Dropout for Model Width Compression
May 13, 2022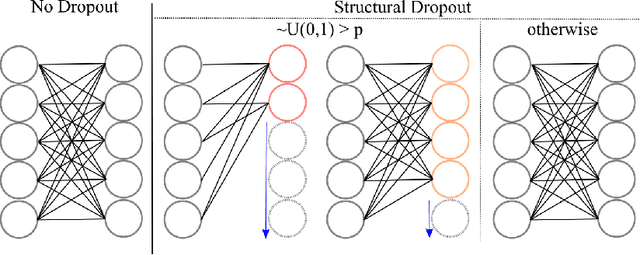

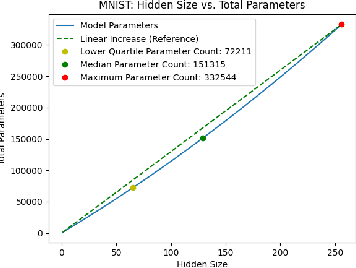
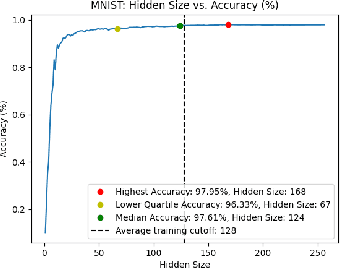
Existing ML models are known to be highly over-parametrized, and use significantly more resources than required for a given task. Prior work has explored compressing models offline, such as by distilling knowledge from larger models into much smaller ones. This is effective for compression, but does not give an empirical method for measuring how much the model can be compressed, and requires additional training for each compressed model. We propose a method that requires only a single training session for the original model and a set of compressed models. The proposed approach is a "structural" dropout that prunes all elements in the hidden state above a randomly chosen index, forcing the model to learn an importance ordering over its features. After learning this ordering, at inference time unimportant features can be pruned while retaining most accuracy, reducing parameter size significantly. In this work, we focus on Structural Dropout for fully-connected layers, but the concept can be applied to any kind of layer with unordered features, such as convolutional or attention layers. Structural Dropout requires no additional pruning/retraining, but requires additional validation for each possible hidden sizes. At inference time, a non-expert can select a memory versus accuracy trade-off that best suits their needs, across a wide range of highly compressed versus more accurate models.
Framework for Behavioral Disorder Detection Using Machine Learning and Application of Virtual Cognitive Behavioral Therapy in COVID-19 Pandemic
Apr 29, 2022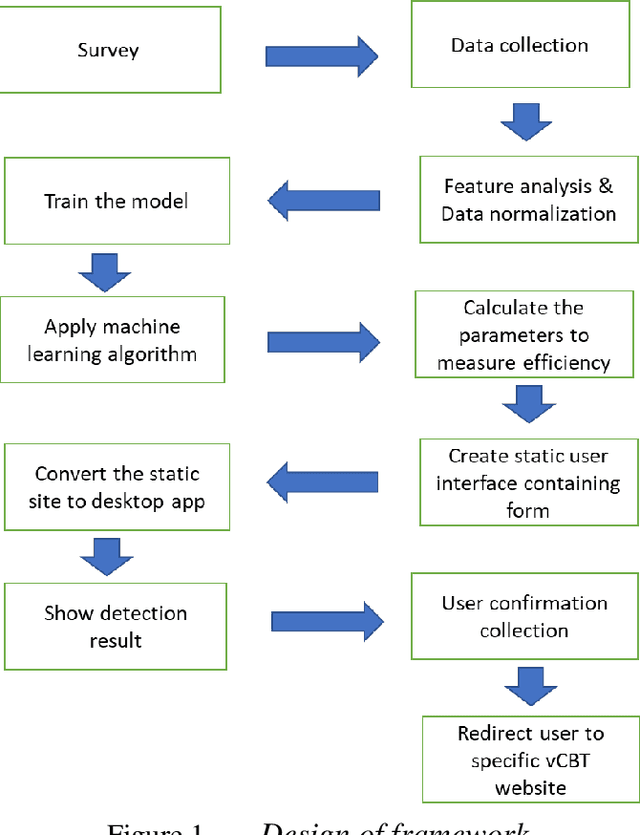
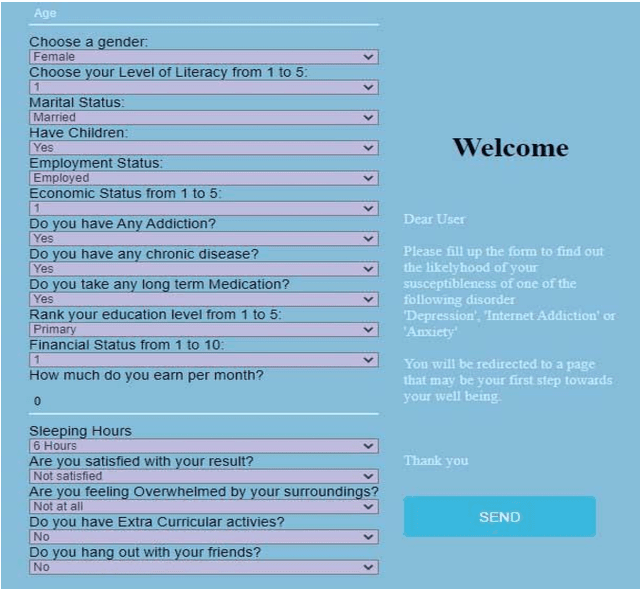


In this modern world, people are becoming more self-centered and unsocial. On the other hand, people are stressed, becoming more anxious during COVID-19 pandemic situation and exhibits symptoms of behavioral disorder. To measure the symptoms of behavioral disorder, usually psychiatrist use long hour sessions and inputs from specific questionnaire. This process is time consuming and sometime is ineffective to detect the right behavioral disorder. Also, reserved people sometime hesitate to follow this process. We have created a digital framework which can detect behavioral disorder and prescribe virtual Cognitive Behavioral Therapy (vCBT) for recovery. By using this framework people can input required data that are highly responsible for the three behavioral disorders namely depression, anxiety and internet addiction. We have applied machine learning technique to detect specific behavioral disorder from samples. This system guides the user with basic understanding and treatment through vCBT from anywhere any time which would potentially be the steppingstone for the user to be conscious and pursue right treatment.
EvoVGM: A Deep Variational Generative Model for Evolutionary Parameter Estimation
May 25, 2022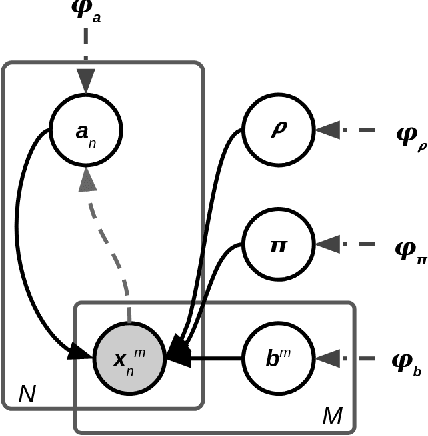
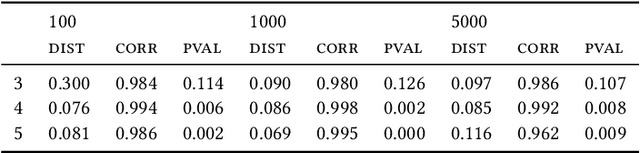
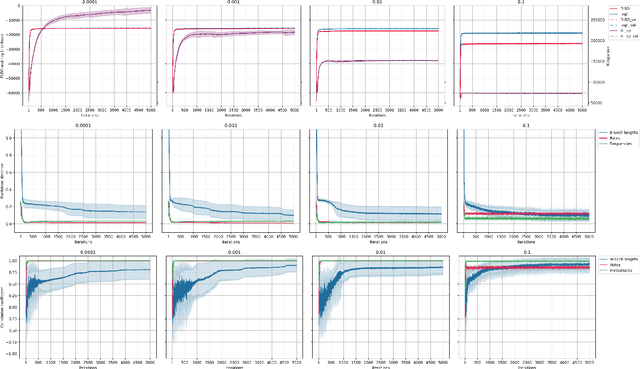
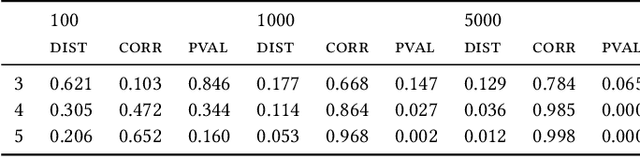
Most evolutionary-oriented deep generative models do not explicitly consider the underlying evolutionary dynamics of biological sequences as it is performed within the Bayesian phylogenetic inference framework. In this study, we propose a method for a deep variational Bayesian generative model that jointly approximates the true posterior of local biological evolutionary parameters and generates sequence alignments. Moreover, it is instantiated and tuned for continuous-time Markov chain substitution models such as JC69 and GTR. We train the model via a low-variance variational objective function and a gradient ascent algorithm. Here, we show the consistency and effectiveness of the method on synthetic sequence alignments simulated with several evolutionary scenarios and on a real virus sequence alignment.
Anomaly detection in surveillance videos using transformer based attention model
Jun 06, 2022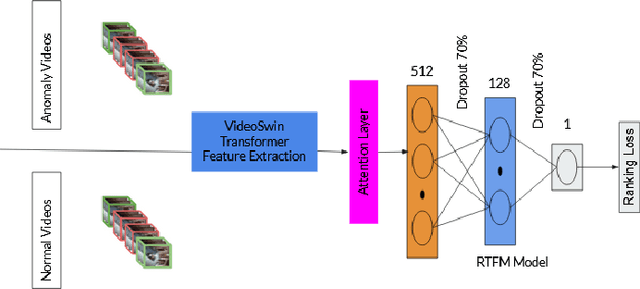
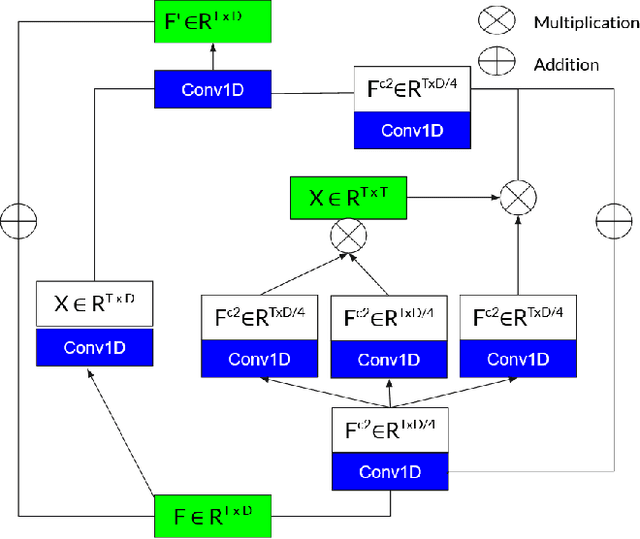

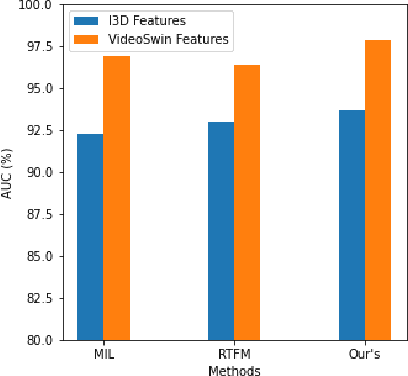
Surveillance footage can catch a wide range of realistic anomalies. This research suggests using a weakly supervised strategy to avoid annotating anomalous segments in training videos, which is time consuming. In this approach only video level labels are used to obtain frame level anomaly scores. Weakly supervised video anomaly detection (WSVAD) suffers from the wrong identification of abnormal and normal instances during the training process. Therefore it is important to extract better quality features from the available videos. WIth this motivation, the present paper uses better quality transformer-based features named Videoswin Features followed by the attention layer based on dilated convolution and self attention to capture long and short range dependencies in temporal domain. This gives us a better understanding of available videos. The proposed framework is validated on real-world dataset i.e. ShanghaiTech Campus dataset which results in competitive performance than current state-of-the-art methods. The model and the code are available at https://github.com/kapildeshpande/Anomaly-Detection-in-Surveillance-Videos
On Integrating Prior Knowledge into Gaussian Processes for Prognostic Health Monitoring
Jun 17, 2022
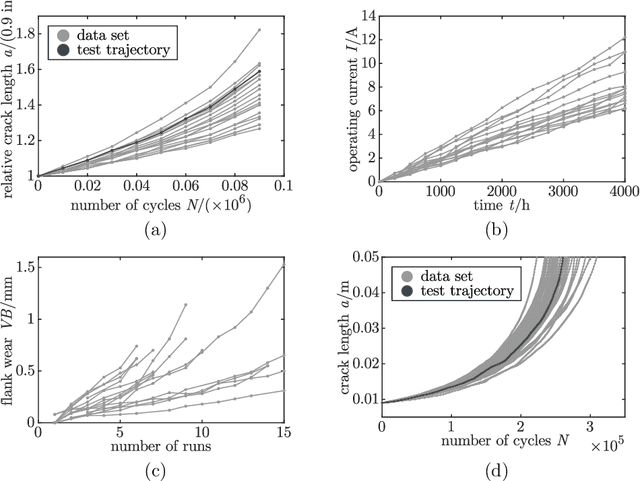

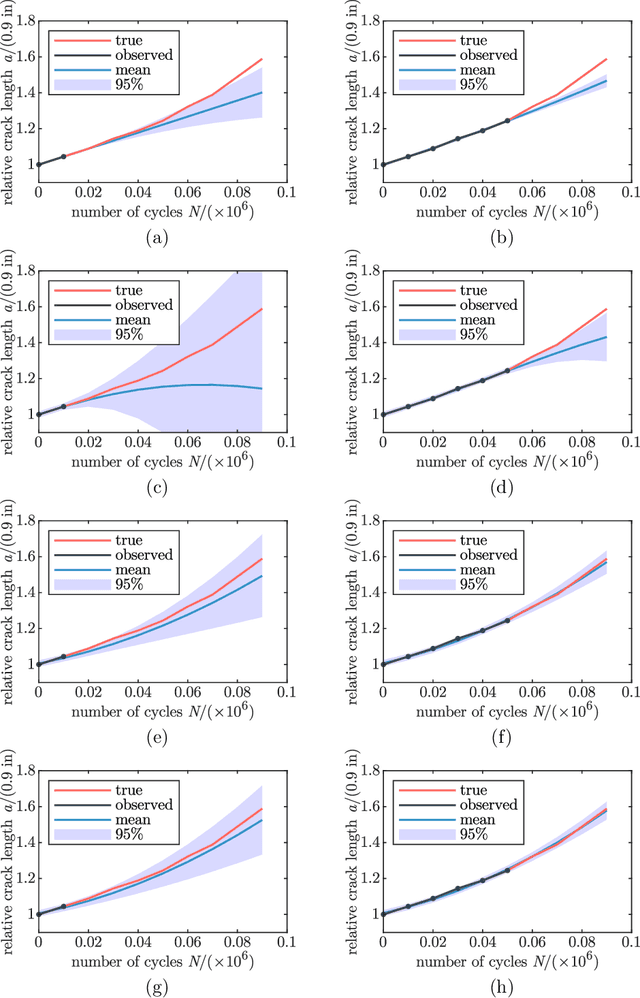
Gaussian process regression is a powerful method for predicting states based on given data. It has been successfully applied for probabilistic predictions of structural systems to quantify, for example, the crack growth in mechanical structures. Typically, predefined mean and covariance functions are employed to construct the Gaussian process model. Then, the model is updated using current data during operation while prior information based on previous data is ignored. However, predefined mean and covariance functions without prior information reduce the potential of Gaussian processes. This paper proposes a method to improve the predictive capabilities of Gaussian processes. We integrate prior knowledge by deriving the mean and covariance functions from previous data. More specifically, we first approximate previous data by a weighted sum of basis functions and then derive the mean and covariance functions directly from the estimated weight coefficients. Basis functions may be either estimated or derived from problem-specific governing equations to incorporate physical information. The applicability and effectiveness of this approach are demonstrated for fatigue crack growth, laser degradation, and milling machine wear data. We show that well-chosen mean and covariance functions, like those based on previous data, significantly increase look-ahead time and accuracy. Using physical basis functions further improves accuracy. In addition, computation effort for training is significantly reduced.