 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Human-AI Interaction Design in Machine Teaching
Jun 10, 2022
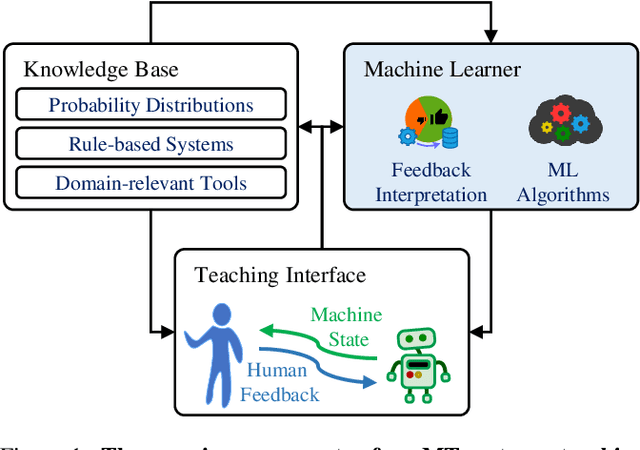

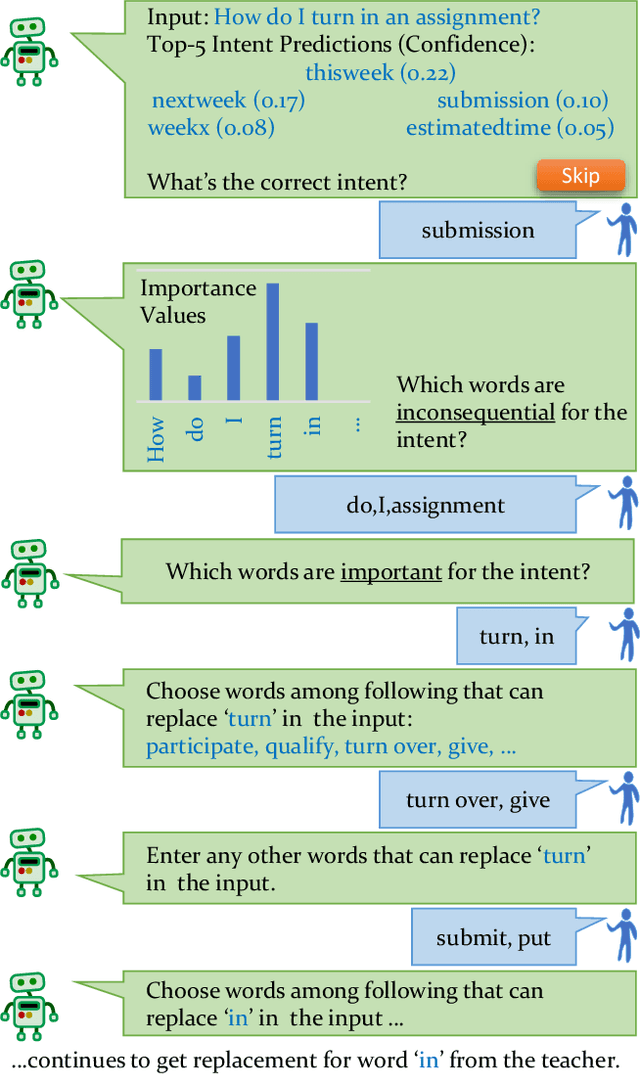
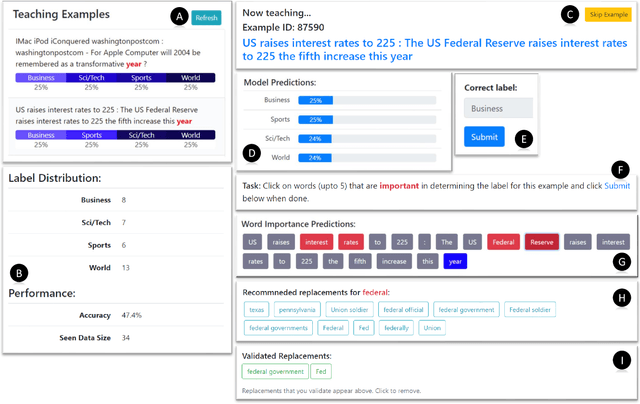
Machine Teaching (MT) is an interactive process where a human and a machine interact with the goal of training a machine learning model (ML) for a specified task. The human teacher communicates their task expertise and the machine student gathers the required data and knowledge to produce an ML model. MT systems are developed to jointly minimize the time spent on teaching and the learner's error rate. The design of human-AI interaction in an MT system not only impacts the teaching efficiency, but also indirectly influences the ML performance by affecting the teaching quality. In this paper, we build upon our previous work where we proposed an MT framework with three components, viz., the teaching interface, the machine learner, and the knowledge base, and focus on the human-AI interaction design involved in realizing the teaching interface. We outline design decisions that need to be addressed in developing an MT system beginning from an ML task. The paper follows the Socratic method entailing a dialogue between a curious student and a wise teacher.
Permutation Search of Tensor Network Structures via Local Sampling
Jun 14, 2022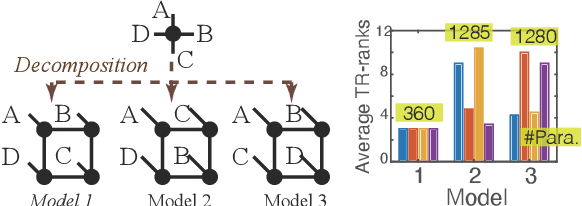
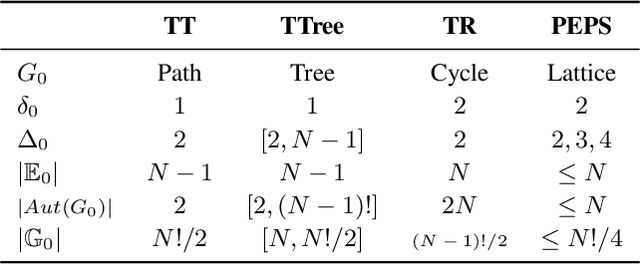
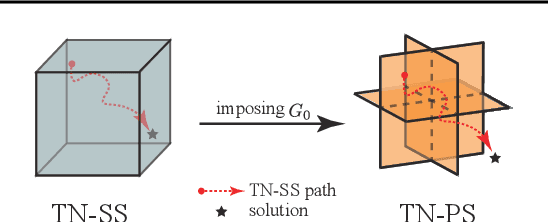
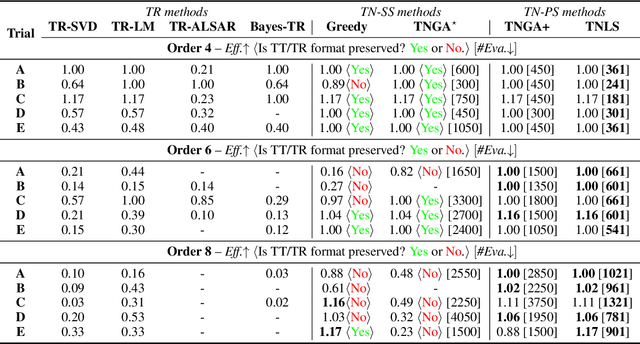
Recent works put much effort into tensor network structure search (TN-SS), aiming to select suitable tensor network (TN) structures, involving the TN-ranks, formats, and so on, for the decomposition or learning tasks. In this paper, we consider a practical variant of TN-SS, dubbed TN permutation search (TN-PS), in which we search for good mappings from tensor modes onto TN vertices (core tensors) for compact TN representations. We conduct a theoretical investigation of TN-PS and propose a practically-efficient algorithm to resolve the problem. Theoretically, we prove the counting and metric properties of search spaces of TN-PS, analyzing for the first time the impact of TN structures on these unique properties. Numerically, we propose a novel meta-heuristic algorithm, in which the searching is done by randomly sampling in a neighborhood established in our theory, and then recurrently updating the neighborhood until convergence. Numerical results demonstrate that the new algorithm can reduce the required model size of TNs in extensive benchmarks, implying the improvement in the expressive power of TNs. Furthermore, the computational cost for the new algorithm is significantly less than that in~\cite{li2020evolutionary}.
Deep Multi-Agent Reinforcement Learning with Hybrid Action Spaces based on Maximum Entropy
Jun 10, 2022

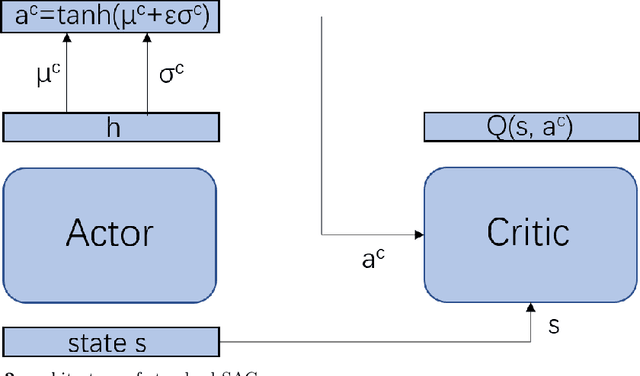
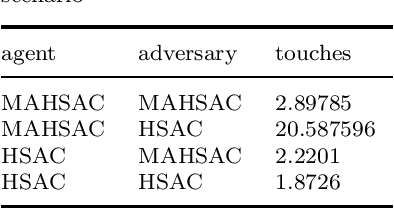
Multi-agent deep reinforcement learning has been applied to address a variety of complex problems with either discrete or continuous action spaces and achieved great success. However, most real-world environments cannot be described by only discrete action spaces or only continuous action spaces. And there are few works having ever utilized deep reinforcement learning (drl) to multi-agent problems with hybrid action spaces. Therefore, we propose a novel algorithm: Deep Multi-Agent Hybrid Soft Actor-Critic (MAHSAC) to fill this gap. This algorithm follows the centralized training but decentralized execution (CTDE) paradigm, and extend the Soft Actor-Critic algorithm (SAC) to handle hybrid action space problems in Multi-Agent environments based on maximum entropy. Our experiences are running on an easy multi-agent particle world with a continuous observation and discrete action space, along with some basic simulated physics. The experimental results show that MAHSAC has good performance in training speed, stability, and anti-interference ability. At the same time, it outperforms existing independent deep hybrid learning method in cooperative scenarios and competitive scenarios.
Stochastic Variance-Reduced Newton: Accelerating Finite-Sum Minimization with Large Batches
Jun 06, 2022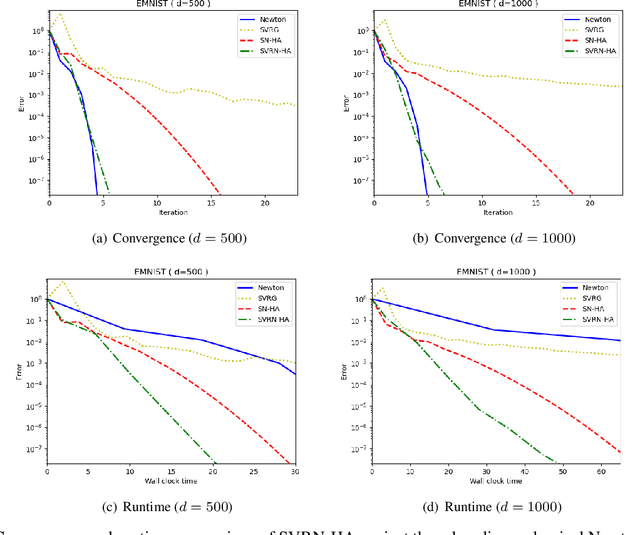
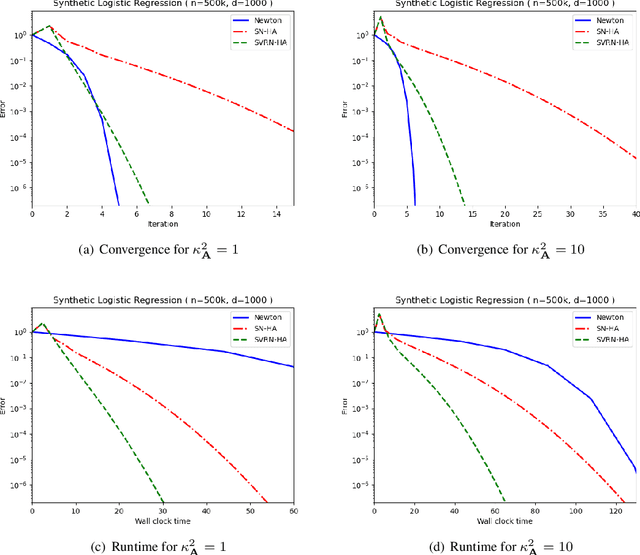
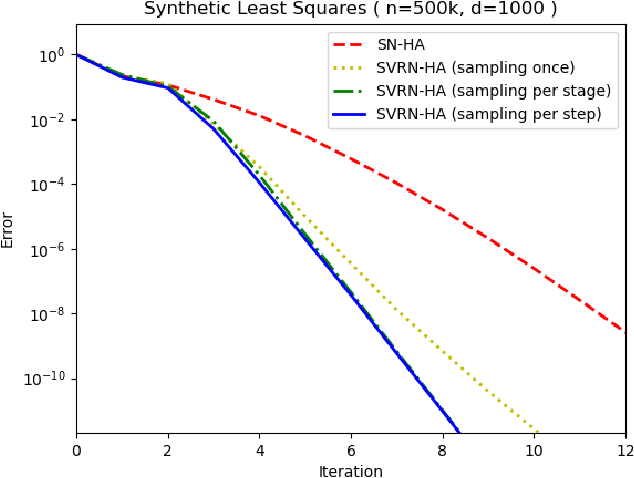
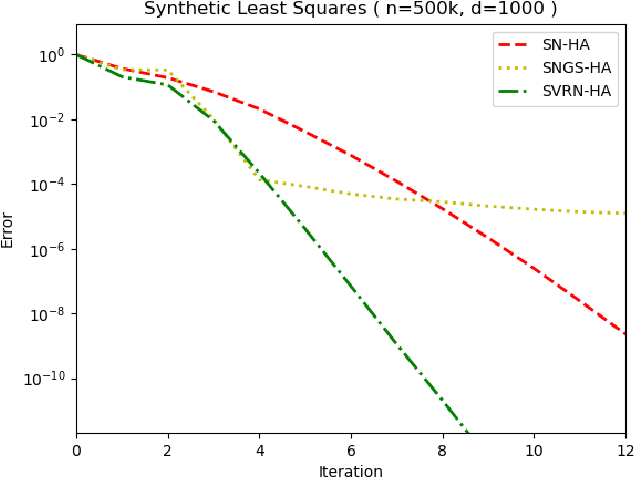
Stochastic variance reduction has proven effective at accelerating first-order algorithms for solving convex finite-sum optimization tasks such as empirical risk minimization. Incorporating additional second-order information has proven helpful in further improving the performance of these first-order methods. However, comparatively little is known about the benefits of using variance reduction to accelerate popular stochastic second-order methods such as Subsampled Newton. To address this, we propose Stochastic Variance-Reduced Newton (SVRN), a finite-sum minimization algorithm which enjoys all the benefits of second-order methods: simple unit step size, easily parallelizable large-batch operations, and fast local convergence, while at the same time taking advantage of variance reduction to achieve improved convergence rates (per data pass) for smooth and strongly convex problems. We show that SVRN can accelerate many stochastic second-order methods (such as Subsampled Newton) as well as iterative least squares solvers (such as Iterative Hessian Sketch), and it compares favorably to popular first-order methods with variance reduction.
Personalized PercepNet: Real-time, Low-complexity Target Voice Separation and Enhancement
Jun 08, 2021



The presence of multiple talkers in the surrounding environment poses a difficult challenge for real-time speech communication systems considering the constraints on network size and complexity. In this paper, we present Personalized PercepNet, a real-time speech enhancement model that separates a target speaker from a noisy multi-talker mixture without compromising on complexity of the recently proposed PercepNet. To enable speaker-dependent speech enhancement, we first show how we can train a perceptually motivated speaker embedder network to produce a representative embedding vector for the given speaker. Personalized PercepNet uses the target speaker embedding as additional information to pick out and enhance only the target speaker while suppressing all other competing sounds. Our experiments show that the proposed model significantly outperforms PercepNet and other baselines, both in terms of objective speech enhancement metrics and human opinion scores.
Online Convolutional Re-parameterization
Apr 02, 2022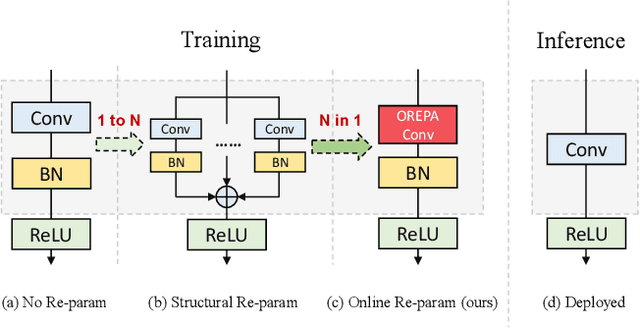
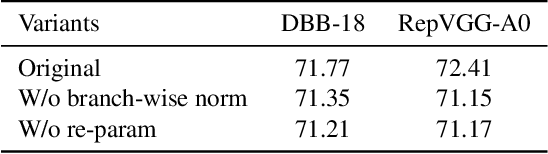
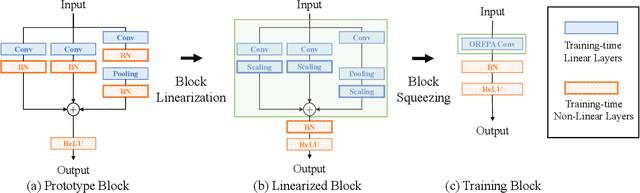
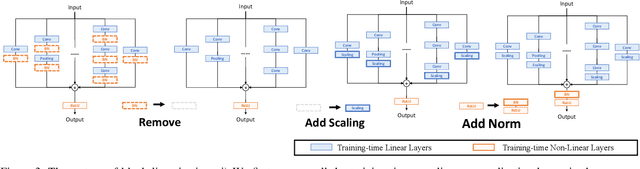
Structural re-parameterization has drawn increasing attention in various computer vision tasks. It aims at improving the performance of deep models without introducing any inference-time cost. Though efficient during inference, such models rely heavily on the complicated training-time blocks to achieve high accuracy, leading to large extra training cost. In this paper, we present online convolutional re-parameterization (OREPA), a two-stage pipeline, aiming to reduce the huge training overhead by squeezing the complex training-time block into a single convolution. To achieve this goal, we introduce a linear scaling layer for better optimizing the online blocks. Assisted with the reduced training cost, we also explore some more effective re-param components. Compared with the state-of-the-art re-param models, OREPA is able to save the training-time memory cost by about 70% and accelerate the training speed by around 2x. Meanwhile, equipped with OREPA, the models outperform previous methods on ImageNet by up to +0.6%.We also conduct experiments on object detection and semantic segmentation and show consistent improvements on the downstream tasks. Codes are available at https://github.com/JUGGHM/OREPA_CVPR2022 .
Towards Safe, Real-Time Systems: Stereo vs Images and LiDAR for 3D Object Detection
Feb 25, 2022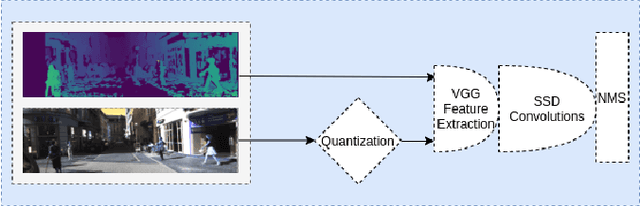

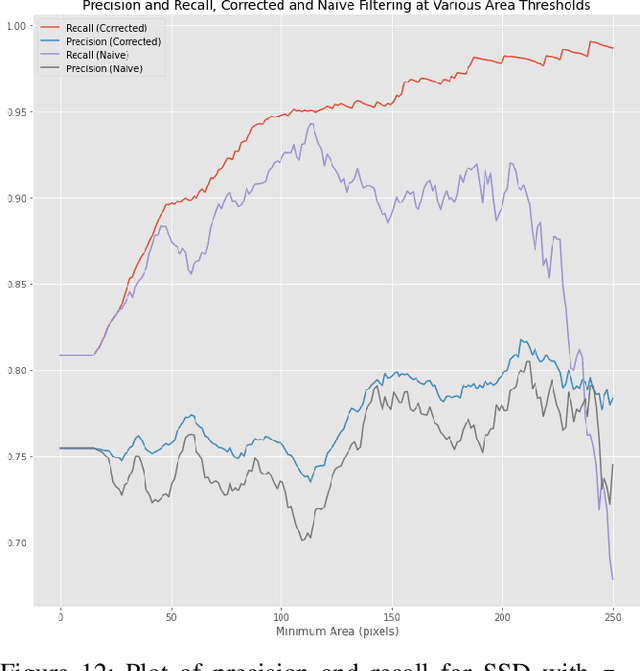
As object detectors rapidly improve, attention has expanded past image-only networks to include a range of 3D and multimodal frameworks, especially ones that incorporate LiDAR. However, due to cost, logistics, and even some safety considerations, stereo can be an appealing alternative. Towards understanding the efficacy of stereo as a replacement for monocular input or LiDAR in object detectors, we show that multimodal learning with traditional disparity algorithms can improve image-based results without increasing the number of parameters, and that learning over stereo error can impart similar 3D localization power to LiDAR in certain contexts. Furthermore, doing so also has calibration benefits with respect to image-only methods. We benchmark on the public dataset KITTI, and in doing so, reveal a few small but common algorithmic mistakes currently used in computing metrics on that set, and offer efficient, provably correct alternatives.
No GPU? No problem: an ultra fast 3D detection of road users with a simple proposal generator and energy-based out-of-distribution PointNets
Jun 06, 2022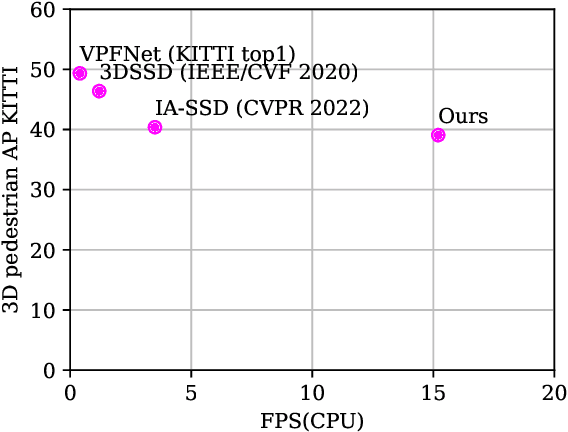
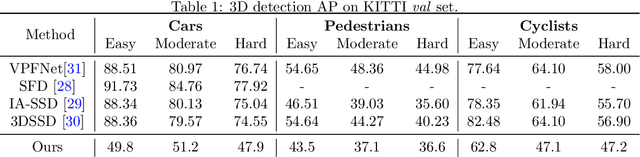
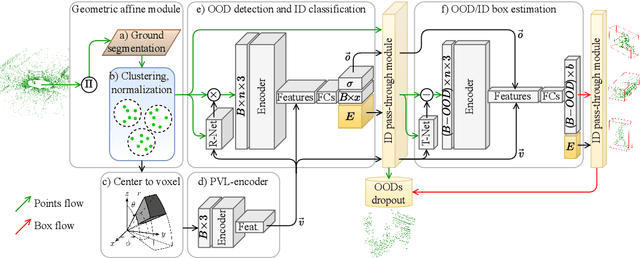
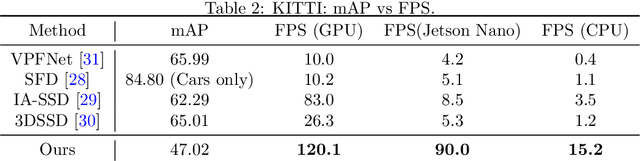
This paper presents a novel architecture for point cloud road user detection, which is based on a classical point cloud proposal generator approach, that utilizes simple geometrical rules. New methods are coupled with this technique to achieve extremely small computational requirement, and mAP that is comparable to the state-of-the-art. The idea is to specifically exploit geometrical rules in hopes of faster performance. The typical downsides of this approach, e.g. global context loss, are tackled in this paper, and solutions are presented. This approach allows real-time performance on a single core CPU, which is not the case with end-to-end solutions presented in the state-of-the-art. We have evaluated the performance of the method with the public KITTI dataset, and with our own annotated dataset collected with a small mobile robot platform. Moreover, we also present a novel ground segmentation method, which is evaluated with the public SemanticKITTI dataset.
On Integrating Prior Knowledge into Gaussian Processes for Prognostic Health Monitoring
Jun 17, 2022
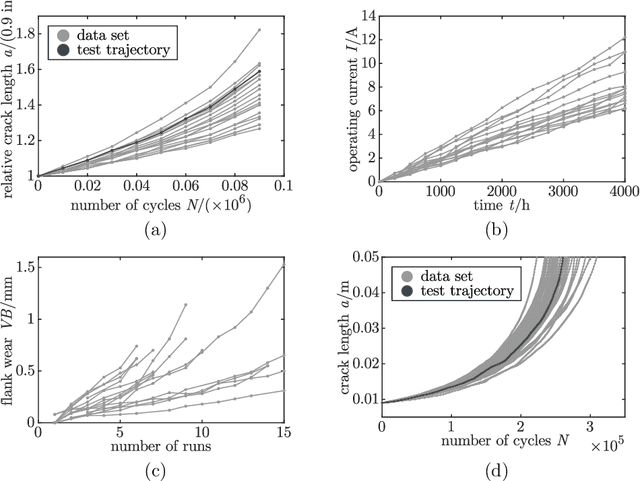

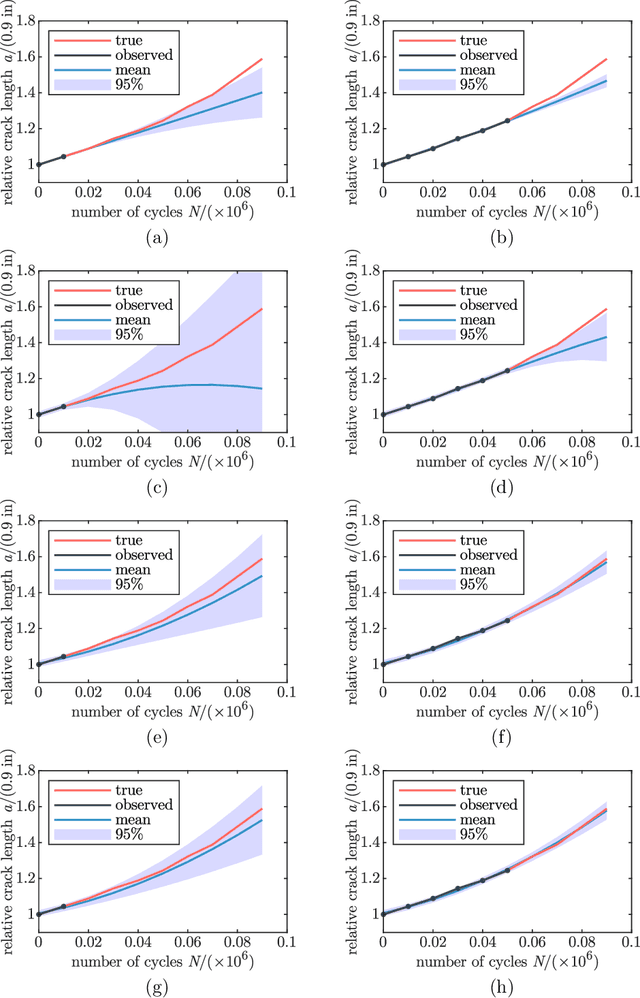
Gaussian process regression is a powerful method for predicting states based on given data. It has been successfully applied for probabilistic predictions of structural systems to quantify, for example, the crack growth in mechanical structures. Typically, predefined mean and covariance functions are employed to construct the Gaussian process model. Then, the model is updated using current data during operation while prior information based on previous data is ignored. However, predefined mean and covariance functions without prior information reduce the potential of Gaussian processes. This paper proposes a method to improve the predictive capabilities of Gaussian processes. We integrate prior knowledge by deriving the mean and covariance functions from previous data. More specifically, we first approximate previous data by a weighted sum of basis functions and then derive the mean and covariance functions directly from the estimated weight coefficients. Basis functions may be either estimated or derived from problem-specific governing equations to incorporate physical information. The applicability and effectiveness of this approach are demonstrated for fatigue crack growth, laser degradation, and milling machine wear data. We show that well-chosen mean and covariance functions, like those based on previous data, significantly increase look-ahead time and accuracy. Using physical basis functions further improves accuracy. In addition, computation effort for training is significantly reduced.
On Tackling Explanation Redundancy in Decision Trees
May 20, 2022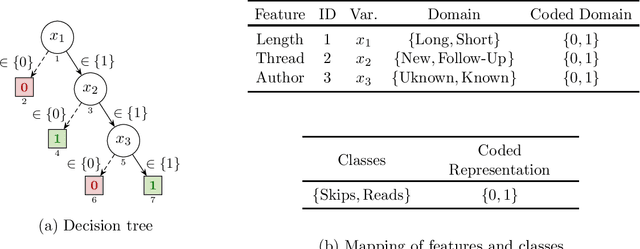

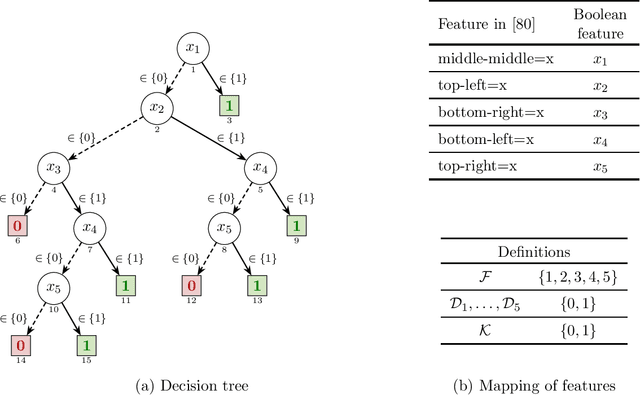
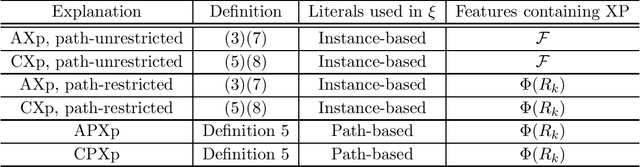
Decision trees (DTs) epitomize the ideal of interpretability of machine learning (ML) models. The interpretability of decision trees motivates explainability approaches by so-called intrinsic interpretability, and it is at the core of recent proposals for applying interpretable ML models in high-risk applications. The belief in DT interpretability is justified by the fact that explanations for DT predictions are generally expected to be succinct. Indeed, in the case of DTs, explanations correspond to DT paths. Since decision trees are ideally shallow, and so paths contain far fewer features than the total number of features, explanations in DTs are expected to be succinct, and hence interpretable. This paper offers both theoretical and experimental arguments demonstrating that, as long as interpretability of decision trees equates with succinctness of explanations, then decision trees ought not be deemed interpretable. The paper introduces logically rigorous path explanations and path explanation redundancy, and proves that there exist functions for which decision trees must exhibit paths with arbitrarily large explanation redundancy. The paper also proves that only a very restricted class of functions can be represented with DTs that exhibit no explanation redundancy. In addition, the paper includes experimental results substantiating that path explanation redundancy is observed ubiquitously in decision trees, including those obtained using different tree learning algorithms, but also in a wide range of publicly available decision trees. The paper also proposes polynomial-time algorithms for eliminating path explanation redundancy, which in practice require negligible time to compute. Thus, these algorithms serve to indirectly attain irreducible, and so succinct, explanations for decision trees.