 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Hawkes Processes for Discovering Time-evolving Communities' States behind Diffusion Processes
Jun 06, 2021
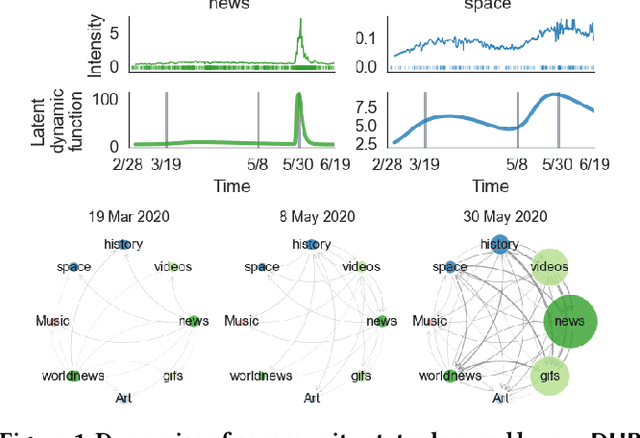
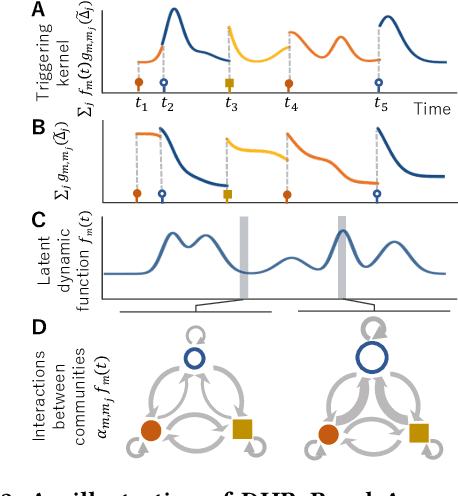
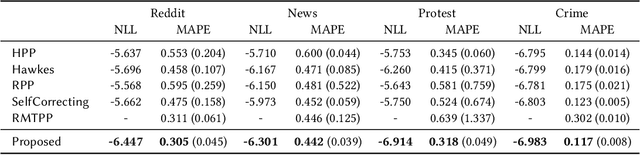
Sequences of events including infectious disease outbreaks, social network activities, and crimes are ubiquitous and the data on such events carry essential information about the underlying diffusion processes between communities (e.g., regions, online user groups). Modeling diffusion processes and predicting future events are crucial in many applications including epidemic control, viral marketing, and predictive policing. Hawkes processes offer a central tool for modeling the diffusion processes, in which the influence from the past events is described by the triggering kernel. However, the triggering kernel parameters, which govern how each community is influenced by the past events, are assumed to be static over time. In the real world, the diffusion processes depend not only on the influences from the past, but also the current (time-evolving) states of the communities, e.g., people's awareness of the disease and people's current interests. In this paper, we propose a novel Hawkes process model that is able to capture the underlying dynamics of community states behind the diffusion processes and predict the occurrences of events based on the dynamics. Specifically, we model the latent dynamic function that encodes these hidden dynamics by a mixture of neural networks. Then we design the triggering kernel using the latent dynamic function and its integral. The proposed method, termed DHP (Dynamic Hawkes Processes), offers a flexible way to learn complex representations of the time-evolving communities' states, while at the same time it allows to computing the exact likelihood, which makes parameter learning tractable. Extensive experiments on four real-world event datasets show that DHP outperforms five widely adopted methods for event prediction.
Achieving Multi-beam Gain in Intelligent Reflecting Surface Assisted Wireless Energy Transfer
May 18, 2022


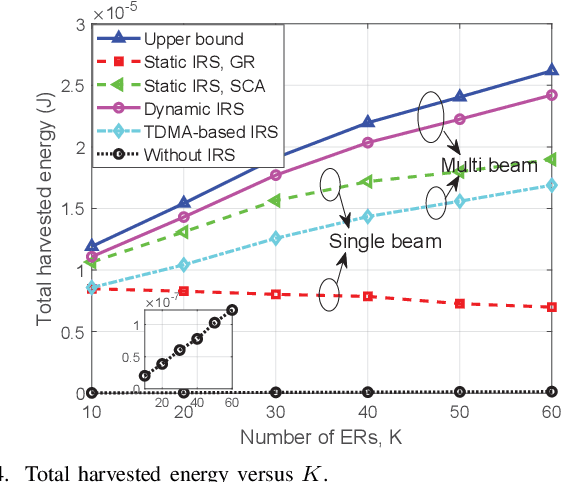
Intelligent reflecting surface (IRS) is a promising technology to boost the efficiency of wireless energy transfer (WET) systems. However, for a multiuser WET system, simultaneous multi-beam energy transmission is generally required to achieve the maximum performance, which may not be implemented by using the IRS having only a single set of coefficients. As a result, it remains unknowns how to exploit the IRS to approach such a performance upper bound. To answer this question, we aim to maximize the total harvested energy of a multiuser WET system subject to the user fairness constraints and the non-linear energy harvesting model. We first consider the static IRS beamforming scheme, which shows that the optimal IRS reflection matrix obtained by applying semidefinite relaxation is indeed of high rank in general as the number of energy receivers (ERs) increases, due to which the resulting rank-one solution by applying Gaussian Randomization may lead to significant loss. To achieve the multi-beam gain, we then propose a general time-division based novel framework by exploiting the IRS's dynamic passive beamforming. Moreover, it is able to achieve a good balance between the system performance and complexity by controlling the number of IRS shift patterns. Finally, we also propose a time-division multiple access (TDMA) based passive beamforming design for performance comparison. Simulation results demonstrate the necessity of multi-beam transmission and the superiority of the proposed dynamic IRS beamforming scheme over existing schemes.
Interpretable Gait Recognition by Granger Causality
Jun 15, 2022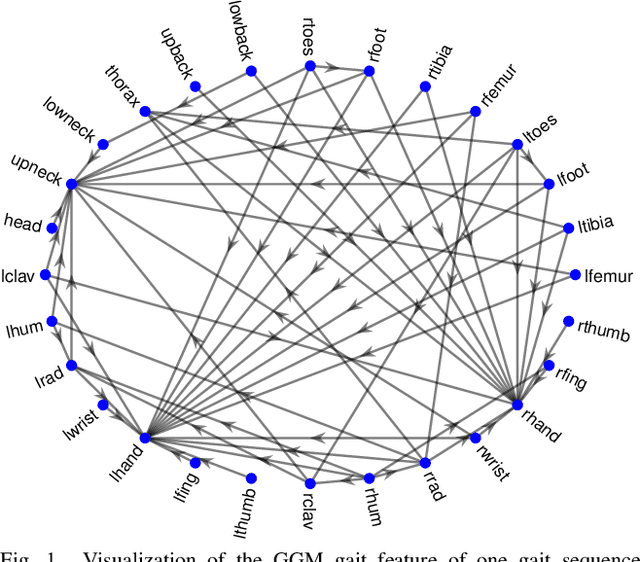
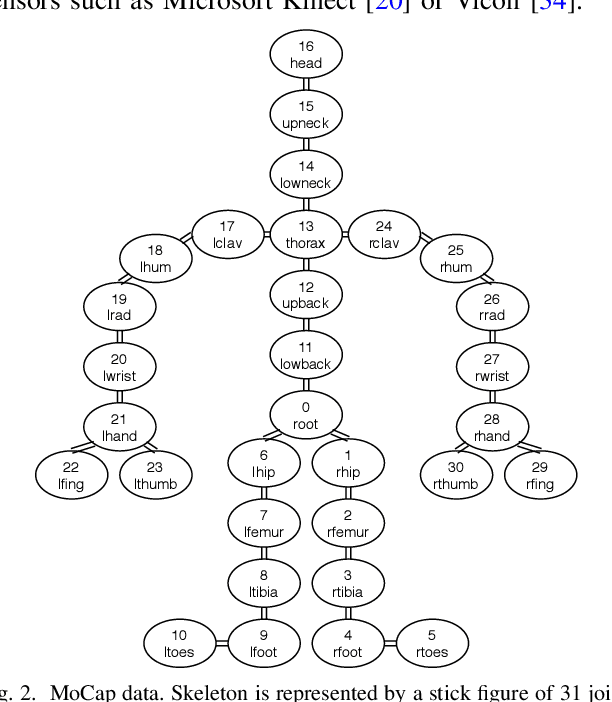
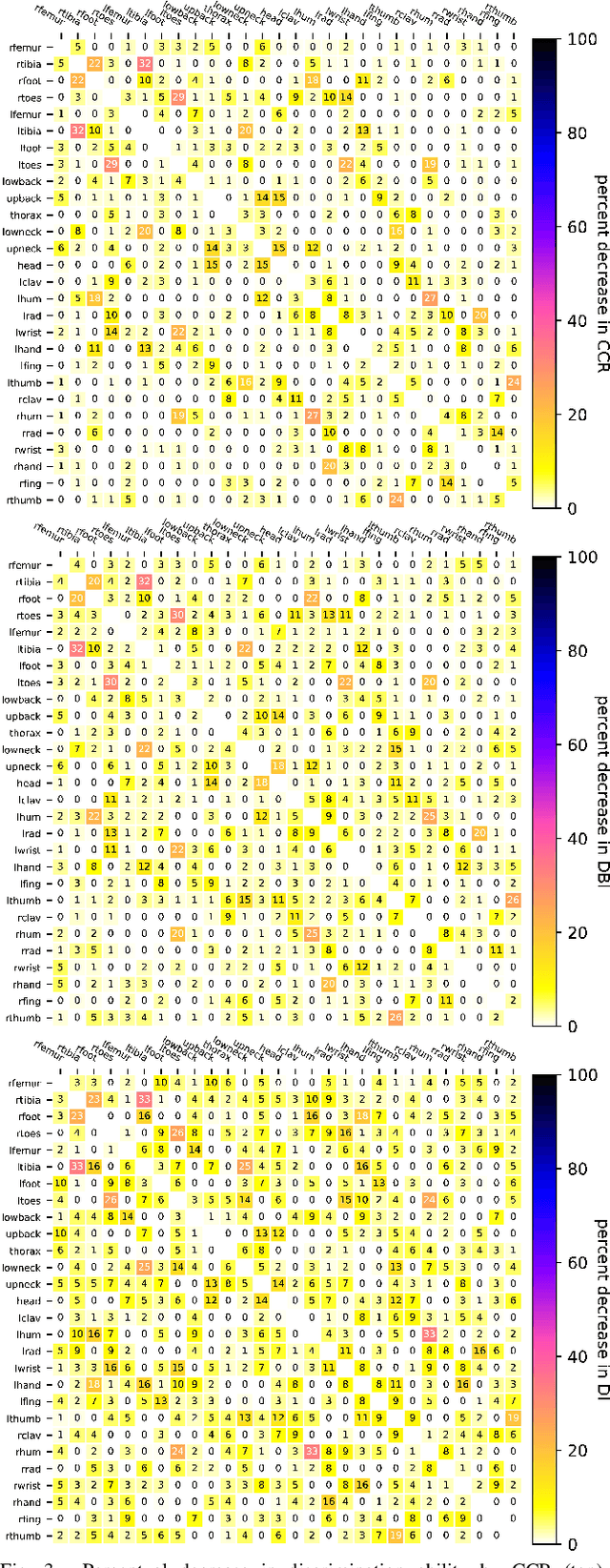
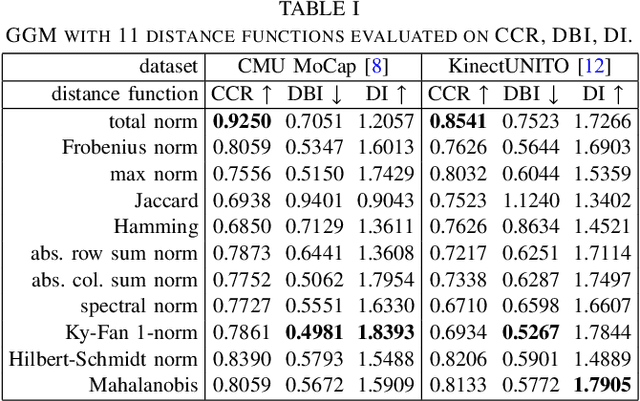
Which joint interactions in the human gait cycle can be used as biometric characteristics? Most current methods on gait recognition suffer from the lack of interpretability. We propose an interpretable feature representation of gait sequences by the graphical Granger causal inference. Gait sequence of a person in the standardized motion capture format, constituting a set of 3D joint spatial trajectories, is envisaged as a causal system of joints interacting in time. We apply the graphical Granger model (GGM) to obtain the so-called Granger causal graph among joints as a discriminative and visually interpretable representation of a person's gait. We evaluate eleven distance functions in the GGM feature space by established classification and class-separability evaluation metrics. Our experiments indicate that, depending on the metric, the most appropriate distance functions for the GGM are the total norm distance and the Ky-Fan 1-norm distance. Experiments also show that the GGM is able to detect the most discriminative joint interactions and that it outperforms five related interpretable models in correct classification rate and in Davies-Bouldin index. The proposed GGM model can serve as a complementary tool for gait analysis in kinesiology or for gait recognition in video surveillance.
Mean-Semivariance Policy Optimization via Risk-Averse Reinforcement Learning
Jun 15, 2022
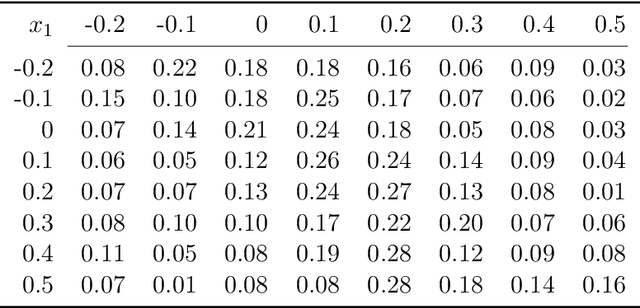
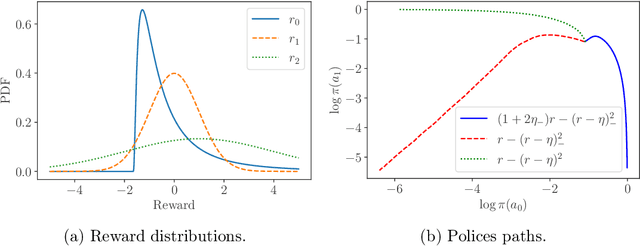
Keeping risk under control is often more crucial than maximizing expected reward in real-world decision-making situations, such as finance, robotics, autonomous driving, etc. The most natural choice of risk measures is variance, while it penalizes the upside volatility as much as the downside part. Instead, the (downside) semivariance, which captures negative deviation of a random variable under its mean, is more suitable for risk-averse proposes. This paper aims at optimizing the mean-semivariance (MSV) criterion in reinforcement learning w.r.t. steady rewards. Since semivariance is time-inconsistent and does not satisfy the standard Bellman equation, the traditional dynamic programming methods are inapplicable to MSV problems directly. To tackle this challenge, we resort to the Perturbation Analysis (PA) theory and establish the performance difference formula for MSV. We reveal that the MSV problem can be solved by iteratively solving a sequence of RL problems with a policy-dependent reward function. Further, we propose two on-policy algorithms based on the policy gradient theory and the trust region method. Finally, we conduct diverse experiments from simple bandit problems to continuous control tasks in MuJoCo, which demonstrate the effectiveness of our proposed methods.
Attention-based Domain Adaptation for Time Series Forecasting
Feb 17, 2021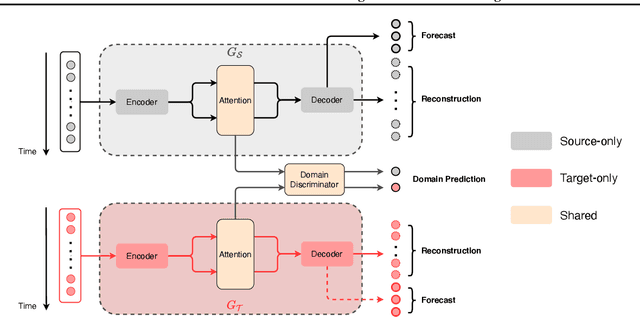
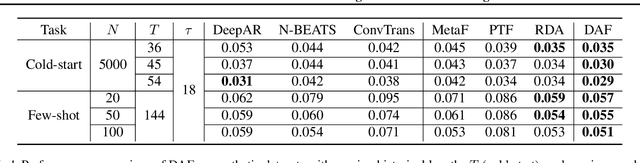

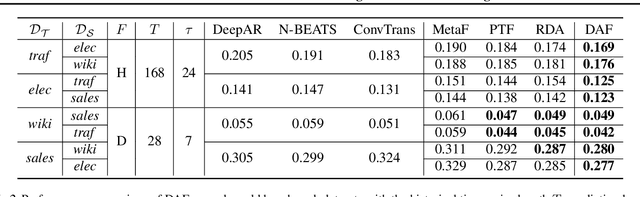
Recent years have witnessed deep neural networks gaining increasing popularity in the field of time series forecasting. A primary reason of their success is their ability to effectively capture complex temporal dynamics across multiple related time series. However, the advantages of these deep forecasters only start to emerge in the presence of a sufficient amount of data. This poses a challenge for typical forecasting problems in practice, where one either has a small number of time series, or limited observations per time series, or both. To cope with the issue of data scarcity, we propose a novel domain adaptation framework, Domain Adaptation Forecaster (DAF), that leverages the statistical strengths from another relevant domain with abundant data samples (source) to improve the performance on the domain of interest with limited data (target). In particular, we propose an attention-based shared module with a domain discriminator across domains as well as private modules for individual domains. This allows us to jointly train the source and target domains by generating domain-invariant latent features while retraining domain-specific features. Extensive experiments on various domains demonstrate that our proposed method outperforms state-of-the-art baselines on synthetic and real-world datasets.
NN3A: Neural Network supported Acoustic Echo Cancellation, Noise Suppression and Automatic Gain Control for Real-Time Communications
Oct 16, 2021
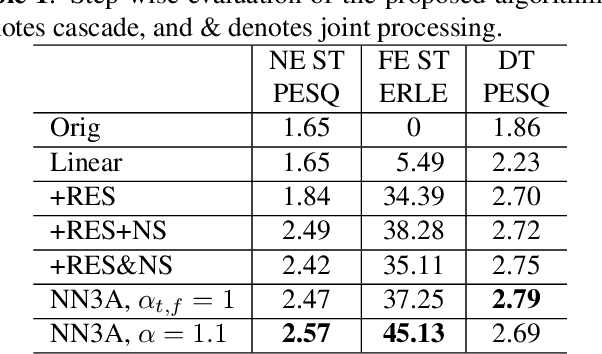
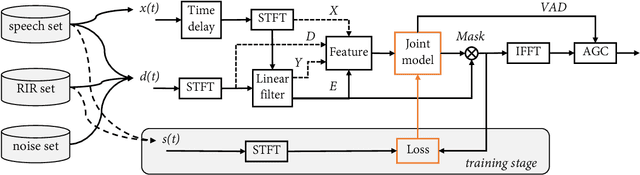
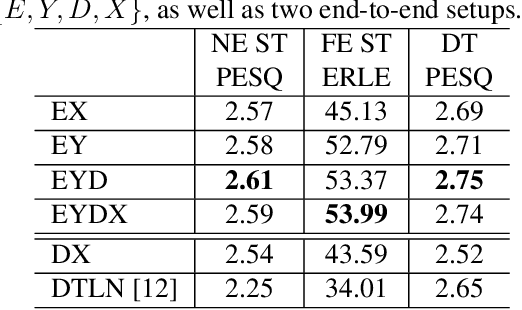
Acoustic echo cancellation (AEC), noise suppression (NS) and automatic gain control (AGC) are three often required modules for real-time communications (RTC). This paper proposes a neural network supported algorithm for RTC, namely NN3A, which incorporates an adaptive filter and a multi-task model for residual echo suppression, noise reduction and near-end speech activity detection. The proposed algorithm is shown to outperform both a method using separate models and an end-to-end alternative. It is further shown that there exists a trade-off in the model between residual suppression and near-end speech distortion, which could be balanced by a novel loss weighting function. Several practical aspects of training the joint model are also investigated to push its performance to limit.
Minimum projective linearizations of trees in linear time
Feb 17, 2021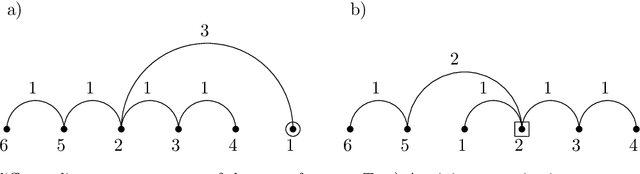

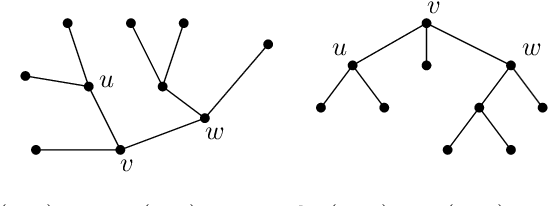
The minimum linear arrangement problem (MLA) consists of finding a mapping $\pi$ from vertices of a graph to integers that minimizes $\sum_{uv\in E}|\pi(u) - \pi(v)|$. For trees, various algorithms are available to solve the problem in polynomial time; the best known runs in subquadratic time in $n=|V|$. There exist variants of the MLA in which the arrangements are constrained to certain classes of projectivity. Iordanskii, and later Hochberg and Stallmann (HS), put forward $O(n)$-time algorithms that solve the problem when arrangements are constrained to be planar. We also consider linear arrangements of rooted trees that are constrained to be projective. Gildea and Temperley (GT) sketched an algorithm for the projectivity constraint which, as they claimed, runs in $O(n)$ but did not provide any justification of its cost. In contrast, Park and Levy claimed that GT's algorithm runs in $O(n \log d_{max})$ where $d_{max}$ is the maximum degree but did not provide sufficient detail. Here we correct an error in HS's algorithm for the planar case, show its relationship with the projective case, and derive an algorithm for the projective case that runs undoubtlessly in $O(n)$-time.
Plumber: A Modular Framework to Create Information Extraction Pipelines
Jun 03, 2022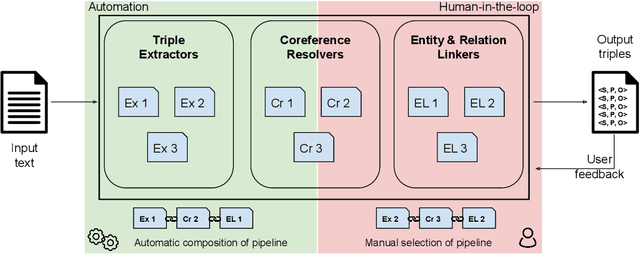
Information Extraction (IE) tasks are commonly studied topics in various domains of research. Hence, the community continuously produces multiple techniques, solutions, and tools to perform such tasks. However, running those tools and integrating them within existing infrastructure requires time, expertise, and resources. One pertinent task here is triples extraction and linking, where structured triples are extracted from a text and aligned to an existing Knowledge Graph (KG). In this paper, we present PLUMBER, the first framework that allows users to manually and automatically create suitable IE pipelines from a community-created pool of tools to perform triple extraction and alignment on unstructured text. Our approach provides an interactive medium to alter the pipelines and perform IE tasks. A short video to show the working of the framework for different use-cases is available online under: https://www.youtube.com/watch?v=XC9rJNIUv8g
SpecGrad: Diffusion Probabilistic Model based Neural Vocoder with Adaptive Noise Spectral Shaping
Mar 31, 2022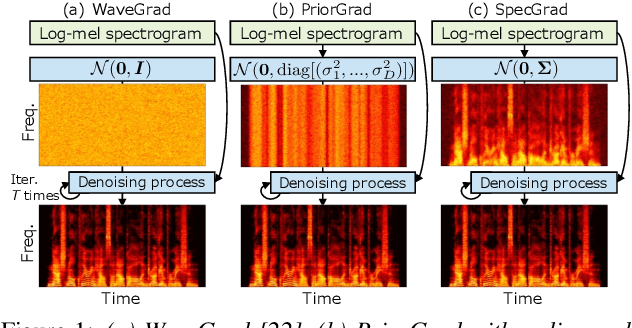
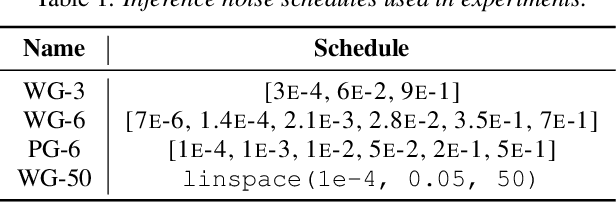
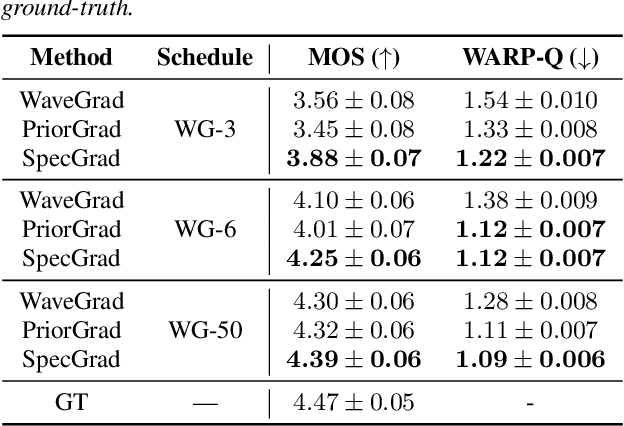
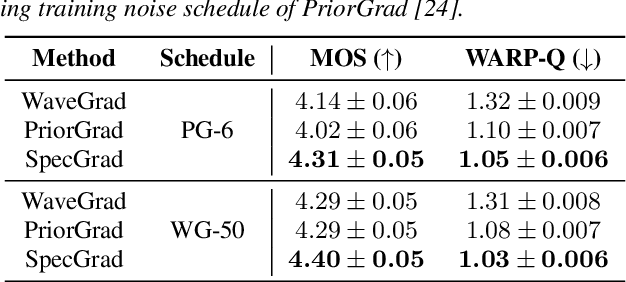
Neural vocoder using denoising diffusion probabilistic model (DDPM) has been improved by adaptation of the diffusion noise distribution to given acoustic features. In this study, we propose SpecGrad that adapts the diffusion noise so that its time-varying spectral envelope becomes close to the conditioning log-mel spectrogram. This adaptation by time-varying filtering improves the sound quality especially in the high-frequency bands. It is processed in the time-frequency domain to keep the computational cost almost the same as the conventional DDPM-based neural vocoders. Experimental results showed that SpecGrad generates higher-fidelity speech waveform than conventional DDPM-based neural vocoders in both analysis-synthesis and speech enhancement scenarios. Audio demos are available at wavegrad.github.io/specgrad/.
Characterization and Optimization of Integrated Silicon-Photonic Neural Networks under Fabrication-Process Variations
Apr 19, 2022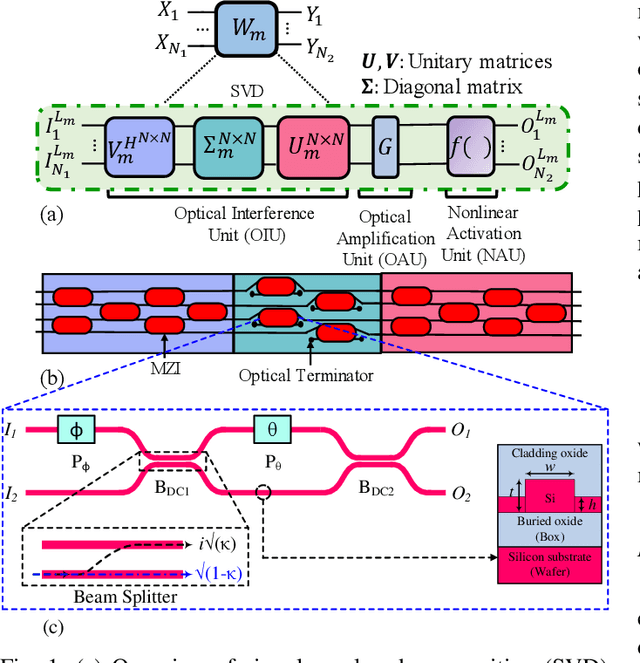
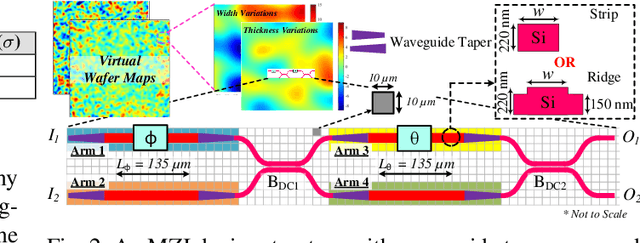
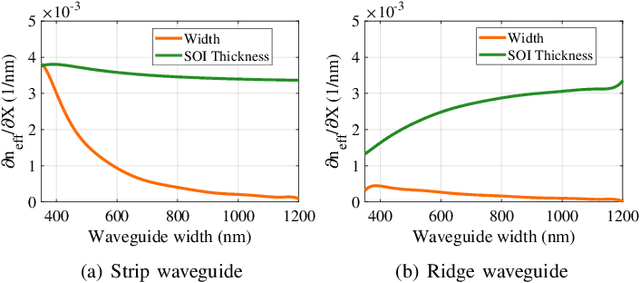
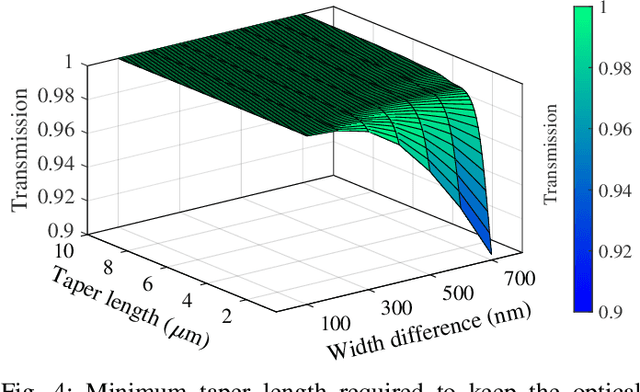
Silicon-photonic neural networks (SPNNs) have emerged as promising successors to electronic artificial intelligence (AI) accelerators by offering orders of magnitude lower latency and higher energy efficiency. Nevertheless, the underlying silicon photonic devices in SPNNs are sensitive to inevitable fabrication-process variations (FPVs) stemming from optical lithography imperfections. Consequently, the inferencing accuracy in an SPNN can be highly impacted by FPVs -- e.g., can drop to below 10% -- the impact of which is yet to be fully studied. In this paper, we, for the first time, model and explore the impact of FPVs in the waveguide width and silicon-on-insulator (SOI) thickness in coherent SPNNs that use Mach-Zehnder Interferometers (MZIs). Leveraging such models, we propose a novel variation-aware, design-time optimization solution to improve MZI tolerance to different FPVs in SPNNs. Simulation results for two example SPNNs of different scales under realistic and correlated FPVs indicate that the optimized MZIs can improve the inferencing accuracy by up to 93.95% for the MNIST handwritten digit dataset -- considered as an example in this paper -- which corresponds to a <0.5% accuracy loss compared to the variation-free case. The proposed one-time optimization method imposes low area overhead, and hence is applicable even to resource-constrained designs