 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the complexity of finding set repairs for data-graphs
Jun 15, 2022
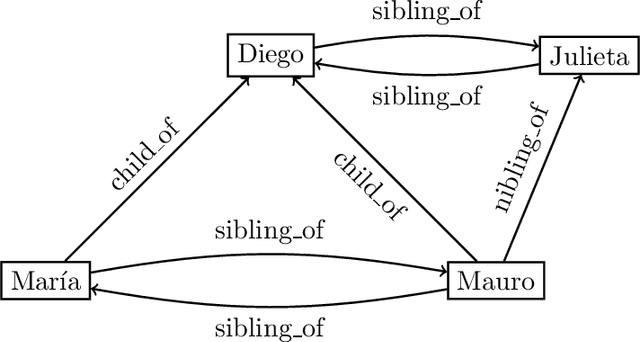
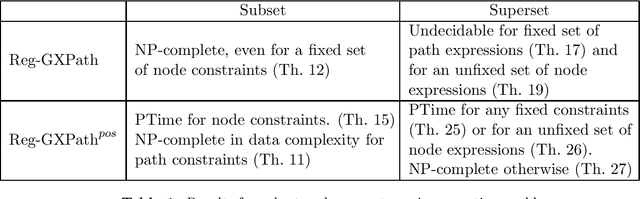
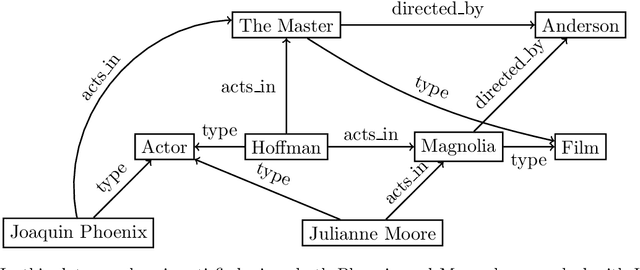
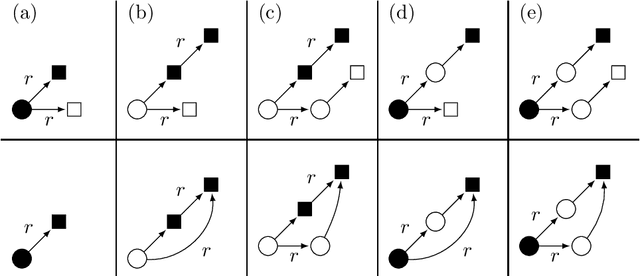
In the deeply interconnected world we live in, pieces of information link domains all around us. As graph databases embrace effectively relationships among data and allow processing and querying these connections efficiently, they are rapidly becoming a popular platform for storage that supports a wide range of domains and applications. As in the relational case, it is expected that data preserves a set of integrity constraints that define the semantic structure of the world it represents. When a database does not satisfy its integrity constraints, a possible approach is to search for a 'similar' database that does satisfy the constraints, also known as a repair. In this work, we study the problem of computing subset and superset repairs for graph databases with data values using a notion of consistency based on a set of Reg-GXPath expressions as integrity constraints. We show that for positive fragments of Reg-GXPath these problems admit a polynomial-time algorithm, while the full expressive power of the language renders them intractable.
Centralised Connectivity-Preserving Transformations by Rotation: 3 Musketeers for all Orthogonal Convex Shapes
Jul 07, 2022
We study a model of programmable matter systems consisting of $n$ devices lying on a 2-dimensional square grid, which are able to perform the minimal mechanical operation of rotating around each other. The goal is to transform an initial shape A into a target shape B. We are interested in characterising the class of shapes which can be transformed into each other in such a scenario, under the additional constraint of maintaining global connectivity at all times. This was one of the main problems left open by $[$Michail et al., JCSS'19$]$. Note that the considered question is about structural feasibility of transformations, which we exclusively deal with via centralised constructive proofs. Distributed solutions are left for future work and form an interesting research direction. Past work made some progress for the special class of nice shapes. We here consider the class of orthogonal convex shapes, where for any two nodes $u, v$ in a horizontal or vertical line on the grid, there is no empty cell between $u$ and $v$. We develop a generic centralised transformation and prove that, for any pair $A$, $B$ of colour-consistent orthogonal convex shapes, it can transform $A$ into $B$. In light of the existence of blocked shapes in the considered class, we use a minimal 3-node seed to trigger the transformation. The running time of our transformation is an optimal $O(n^2)$ sequential moves, where $n=|A|=|B|$. We leave as an open problem the existence of a universal connectivity-preserving transformation with a small seed. Our belief is that the techniques developed in this paper might prove useful to answer this.
A Large Scale Search Dataset for Unbiased Learning to Rank
Jul 07, 2022
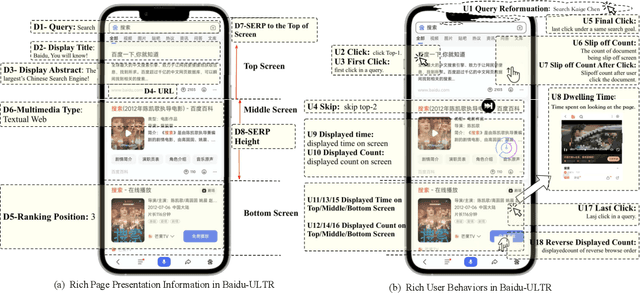
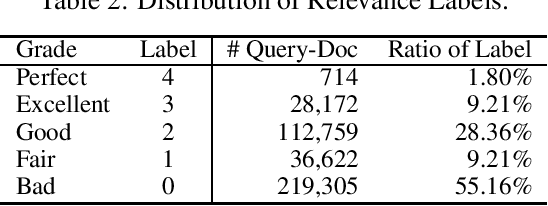
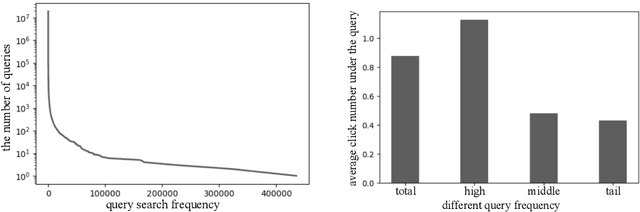
The unbiased learning to rank (ULTR) problem has been greatly advanced by recent deep learning techniques and well-designed debias algorithms. However, promising results on the existing benchmark datasets may not be extended to the practical scenario due to the following disadvantages observed from those popular benchmark datasets: (1) outdated semantic feature extraction where state-of-the-art large scale pre-trained language models like BERT cannot be exploited due to the missing of the original text;(2) incomplete display features for in-depth study of ULTR, e.g., missing the displayed abstract of documents for analyzing the click necessary bias; (3) lacking real-world user feedback, leading to the prevalence of synthetic datasets in the empirical study. To overcome the above disadvantages, we introduce the Baidu-ULTR dataset. It involves randomly sampled 1.2 billion searching sessions and 7,008 expert annotated queries, which is orders of magnitude larger than the existing ones. Baidu-ULTR provides:(1) the original semantic feature and a pre-trained language model for easy usage; (2) sufficient display information such as position, displayed height, and displayed abstract, enabling the comprehensive study of different biases with advanced techniques such as causal discovery and meta-learning; and (3) rich user feedback on search result pages (SERPs) like dwelling time, allowing for user engagement optimization and promoting the exploration of multi-task learning in ULTR. In this paper, we present the design principle of Baidu-ULTR and the performance of benchmark ULTR algorithms on this new data resource, favoring the exploration of ranking for long-tail queries and pre-training tasks for ranking. The Baidu-ULTR dataset and corresponding baseline implementation are available at https://github.com/ChuXiaokai/baidu_ultr_dataset.
SiaTrans: Siamese Transformer Network for RGB-D Salient Object Detection with Depth Image Classification
Jul 09, 2022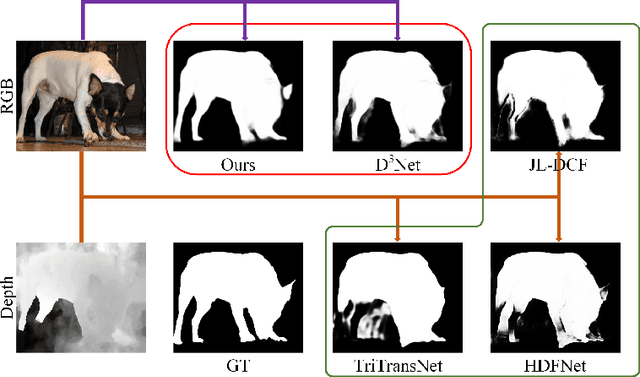
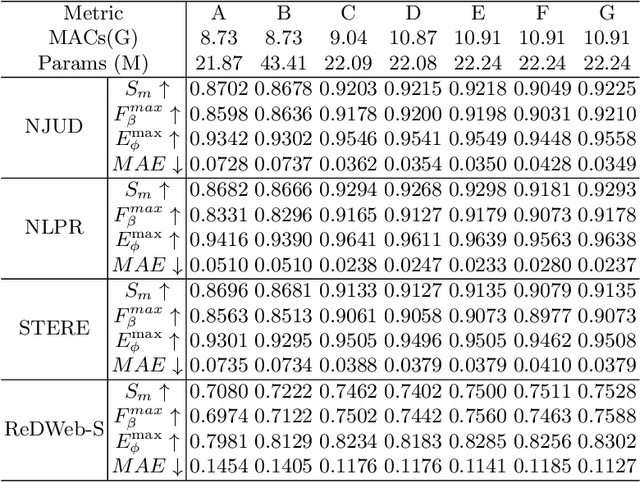
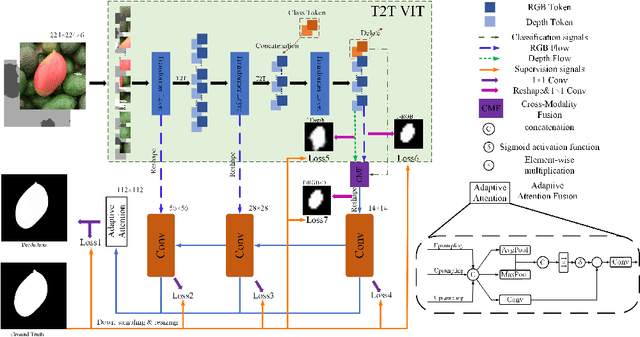
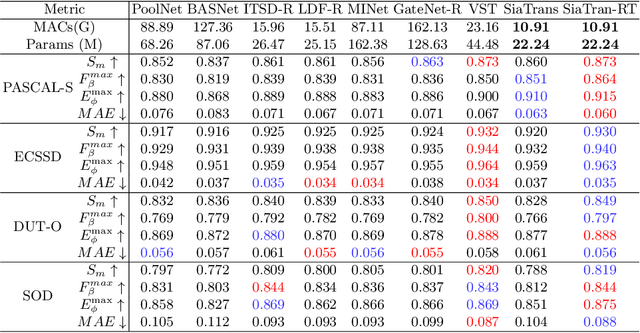
RGB-D SOD uses depth information to handle challenging scenes and obtain high-quality saliency maps. Existing state-of-the-art RGB-D saliency detection methods overwhelmingly rely on the strategy of directly fusing depth information. Although these methods improve the accuracy of saliency prediction through various cross-modality fusion strategies, misinformation provided by some poor-quality depth images can affect the saliency prediction result. To address this issue, a novel RGB-D salient object detection model (SiaTrans) is proposed in this paper, which allows training on depth image quality classification at the same time as training on SOD. In light of the common information between RGB and depth images on salient objects, SiaTrans uses a Siamese transformer network with shared weight parameters as the encoder and extracts RGB and depth features concatenated on the batch dimension, saving space resources without compromising performance. SiaTrans uses the Class token in the backbone network (T2T-ViT) to classify the quality of depth images without preventing the token sequence from going on with the saliency detection task. Transformer-based cross-modality fusion module (CMF) can effectively fuse RGB and depth information. And in the testing process, CMF can choose to fuse cross-modality information or enhance RGB information according to the quality classification signal of the depth image. The greatest benefit of our designed CMF and decoder is that they maintain the consistency of RGB and RGB-D information decoding: SiaTrans decodes RGB-D or RGB information under the same model parameters according to the classification signal during testing. Comprehensive experiments on nine RGB-D SOD benchmark datasets show that SiaTrans has the best overall performance and the least computation compared with recent state-of-the-art methods.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022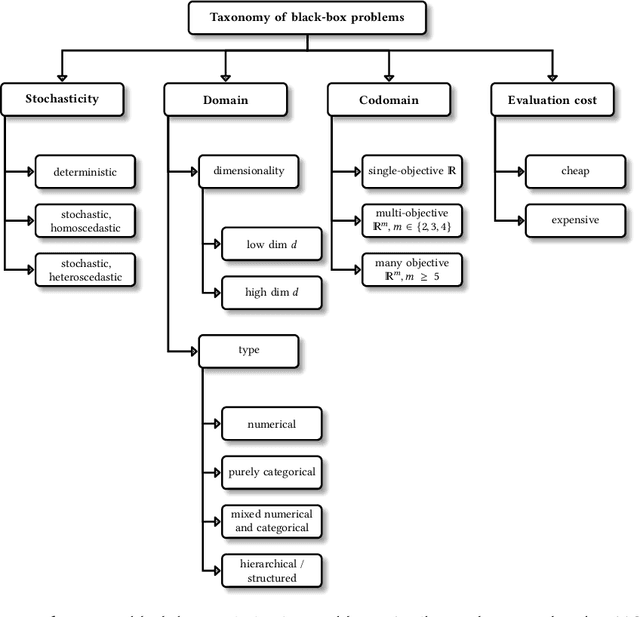
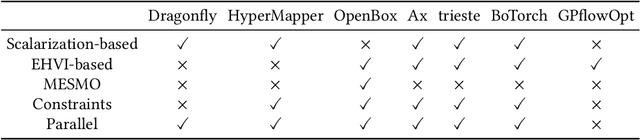
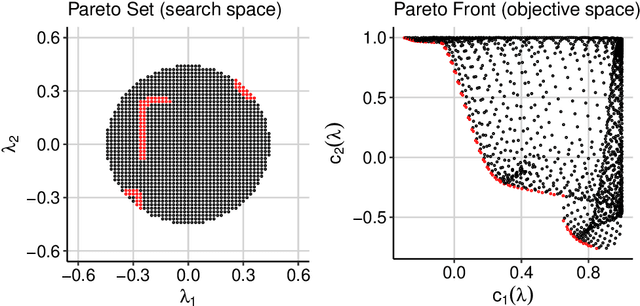
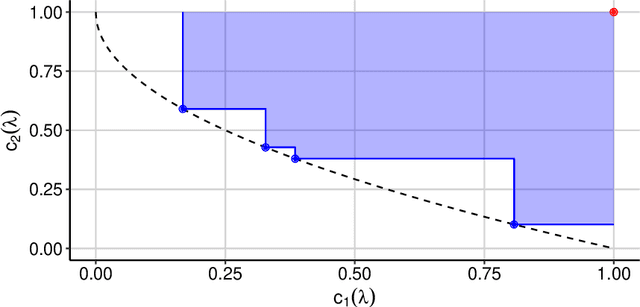
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
[Reproducibility Report] Explainable Deep One-Class Classification
Jun 06, 2022![Figure 1 for [Reproducibility Report] Explainable Deep One-Class Classification](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fc20a429ede0cb84dcece92c2346cffc906505256%2F3-Table1-1.png&w=640&q=75)
![Figure 2 for [Reproducibility Report] Explainable Deep One-Class Classification](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fc20a429ede0cb84dcece92c2346cffc906505256%2F6-Figure1-1.png&w=640&q=75)
![Figure 3 for [Reproducibility Report] Explainable Deep One-Class Classification](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fc20a429ede0cb84dcece92c2346cffc906505256%2F4-Table2-1.png&w=640&q=75)
![Figure 4 for [Reproducibility Report] Explainable Deep One-Class Classification](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fc20a429ede0cb84dcece92c2346cffc906505256%2F6-Figure2-1.png&w=640&q=75)
Fully Convolutional Data Description (FCDD), an explainable version of the Hypersphere Classifier (HSC), directly addresses image anomaly detection (AD) and pixel-wise AD without any post-hoc explainer methods. The authors claim that FCDD achieves results comparable with the state-of-the-art in sample-wise AD on Fashion-MNIST and CIFAR-10 and exceeds the state-of-the-art on the pixel-wise task on MVTec-AD. We reproduced the main results of the paper using the author's code with minor changes and provide runtime requirements to achieve if (CPU memory, GPU memory, and training time). We propose another analysis methodology using a critical difference diagram, and further investigate the test performance of the model during the training phase.
Continual Learning for Affective Robotics: A Proof of Concept for Wellbeing
Jun 22, 2022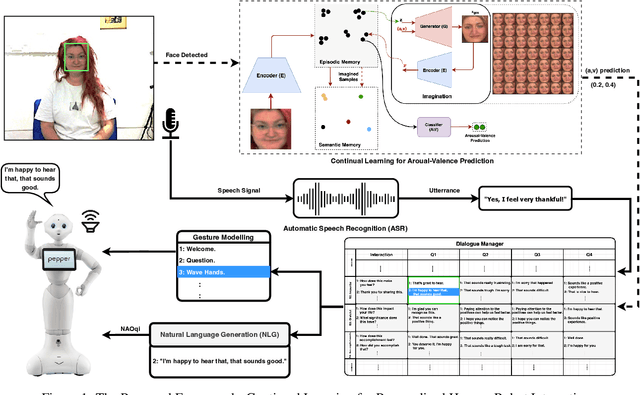
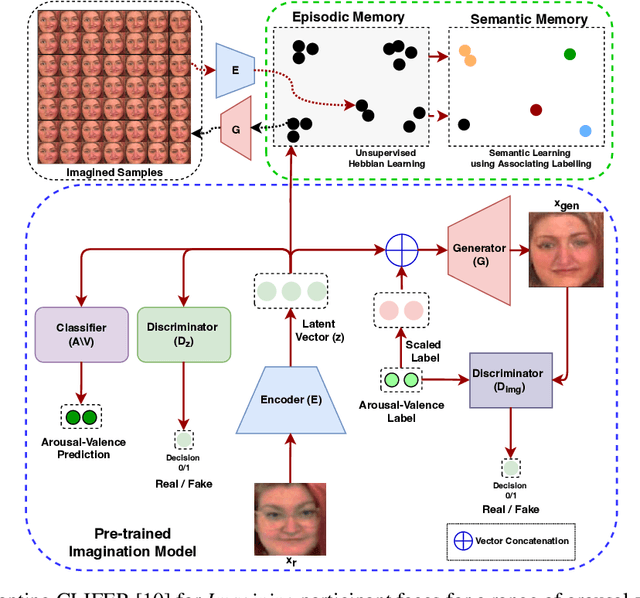
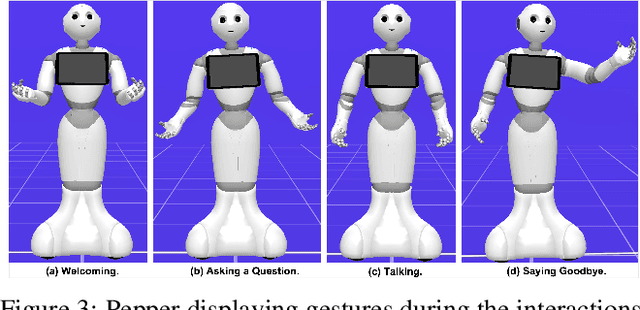

Sustaining real-world human-robot interactions requires robots to be sensitive to human behavioural idiosyncrasies and adapt their perception and behaviour models to cater to these individual preferences. For affective robots, this entails learning to adapt to individual affective behaviour to offer a personalised interaction experience to each individual. Continual Learning (CL) has been shown to enable real-time adaptation in agents, allowing them to learn with incrementally acquired data while preserving past knowledge. In this work, we present a novel framework for real-world application of CL for modelling personalised human-robot interactions using a CL-based affect perception mechanism. To evaluate the proposed framework, we undertake a proof-of-concept user study with 20 participants interacting with the Pepper robot using three variants of interaction behaviour: static and scripted, using affect-based adaptation without personalisation, and using affect-based adaptation with continual personalisation. Our results demonstrate a clear preference in the participants for CL-based continual personalisation with significant improvements observed in the robot's anthropomorphism, animacy and likeability ratings as well as the interactions being rated significantly higher for warmth and comfort as the robot is rated as significantly better at understanding how the participants feel.
Image Gradient Decomposition for Parallel and Memory-Efficient Ptychographic Reconstruction
May 12, 2022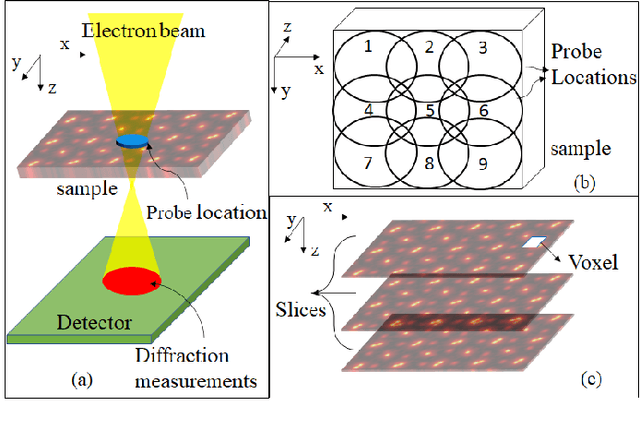
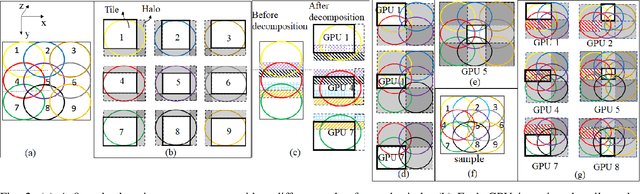
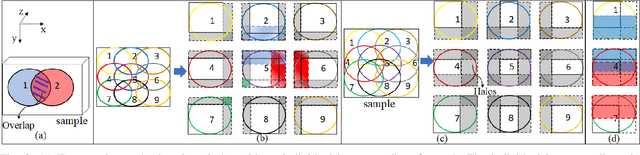
Ptychography is a popular microscopic imaging modality for many scientific discoveries and sets the record for highest image resolution. Unfortunately, the high image resolution for ptychographic reconstruction requires significant amount of memory and computations, forcing many applications to compromise their image resolution in exchange for a smaller memory footprint and a shorter reconstruction time. In this paper, we propose a novel image gradient decomposition method that significantly reduces the memory footprint for ptychographic reconstruction by tessellating image gradients and diffraction measurements into tiles. In addition, we propose a parallel image gradient decomposition method that enables asynchronous point-to-point communications and parallel pipelining with minimal overhead on a large number of GPUs. Our experiments on a Titanate material dataset (PbTiO3) with 16632 probe locations show that our Gradient Decomposition algorithm reduces memory footprint by 51 times. In addition, it achieves time-to-solution within 2.2 minutes by scaling to 4158 GPUs with a super-linear speedup at 364% efficiency. This performance is 2.7 times more memory efficient, 9 times more scalable and 86 times faster than the state-of-the-art algorithm.
Rethinking BiSeNet For Real-time Semantic Segmentation
Apr 27, 2021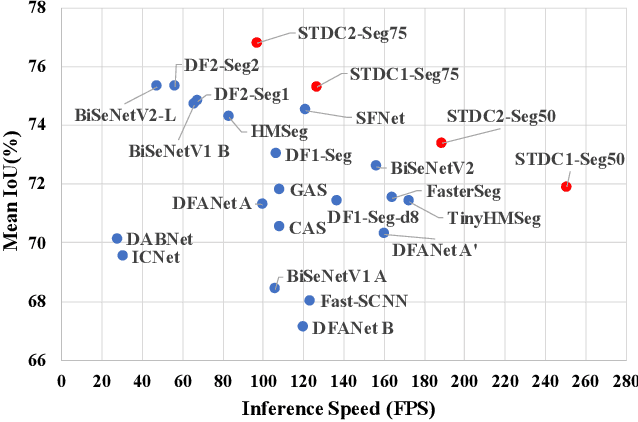
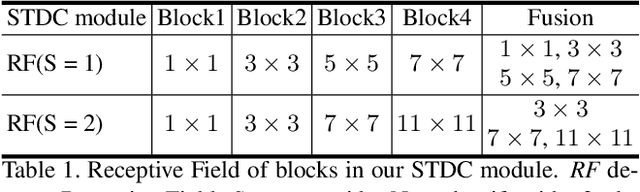
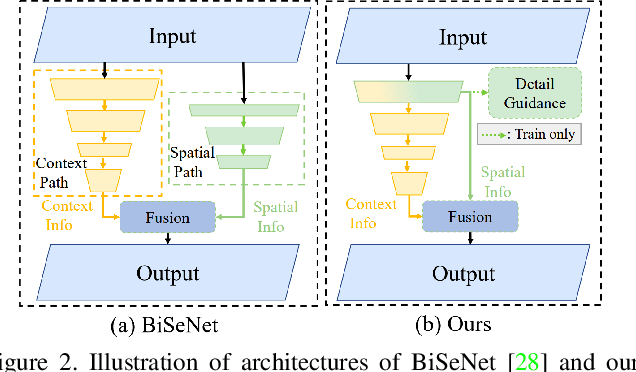
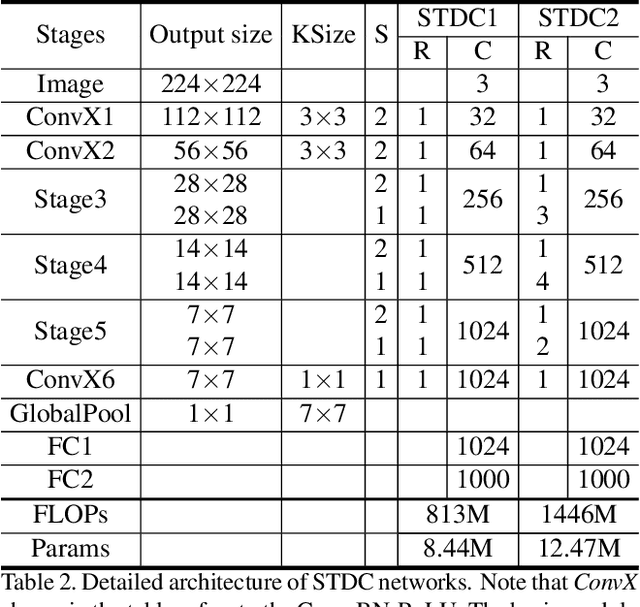
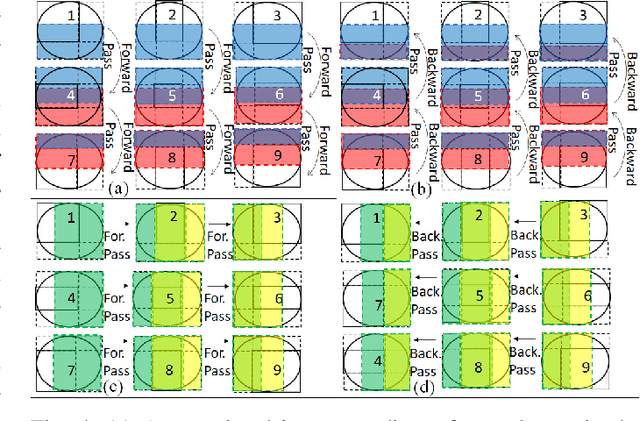
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
Automatic Detection of Interplanetary Coronal Mass Ejections in Solar Wind In Situ Data
May 07, 2022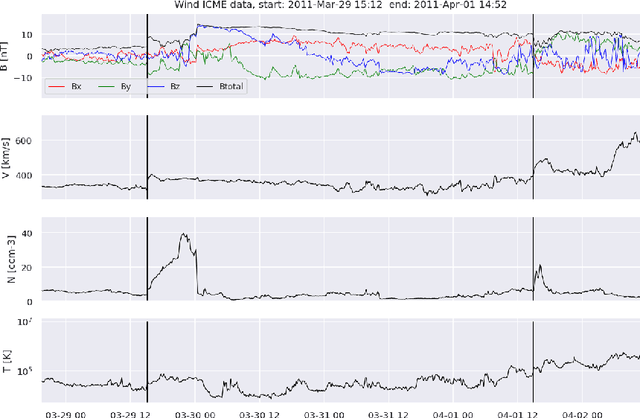
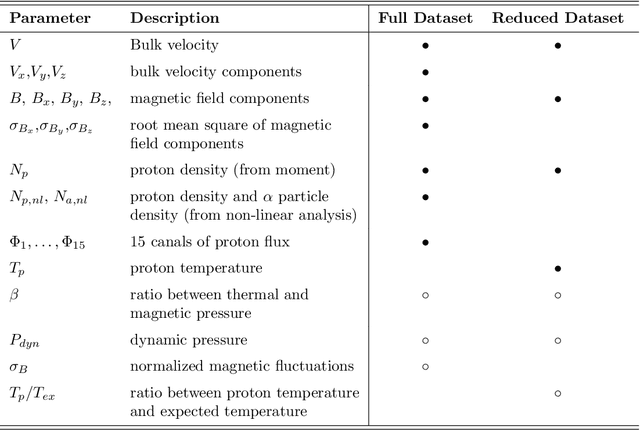
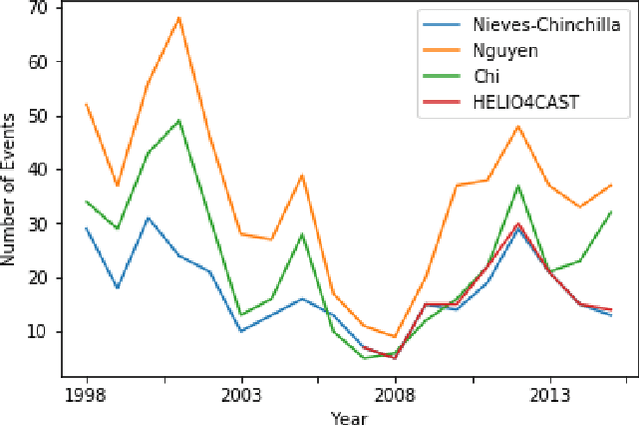
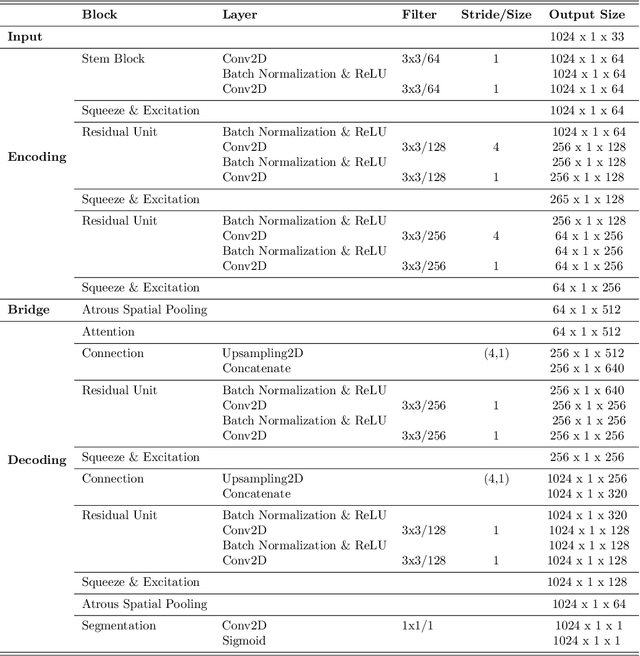
Interplanetary coronal mass ejections (ICMEs) are one of the main drivers for space weather disturbances. In the past, different approaches have been used to automatically detect events in existing time series resulting from solar wind in situ observations. However, accurate and fast detection still remains a challenge when facing the large amount of data from different instruments. For the automatic detection of ICMEs we propose a pipeline using a method that has recently proven successful in medical image segmentation. Comparing it to an existing method, we find that while achieving similar results, our model outperforms the baseline regarding training time by a factor of approximately 20, thus making it more applicable for other datasets. The method has been tested on in situ data from the Wind spacecraft between 1997 and 2015 with a True Skill Statistic (TSS) of 0.64. Out of the 640 ICMEs, 466 were detected correctly by our algorithm, producing a total of 254 False Positives. Additionally, it produced reasonable results on datasets with fewer features and smaller training sets from Wind, STEREO-A and STEREO-B with True Skill Statistics of 0.56, 0.57 and 0.53, respectively. Our pipeline manages to find the start of an ICME with a mean absolute error (MAE) of around 2 hours and 56 minutes, and the end time with a MAE of 3 hours and 20 minutes. The relatively fast training allows straightforward tuning of hyperparameters and could therefore easily be used to detect other structures and phenomena in solar wind data, such as corotating interaction regions.