 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Concepts and Algorithms for Agent-based Decentralized and Integrated Scheduling of Production and Auxiliary Processes
May 12, 2022
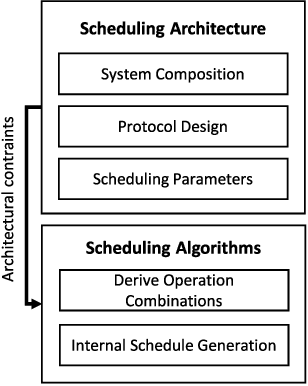
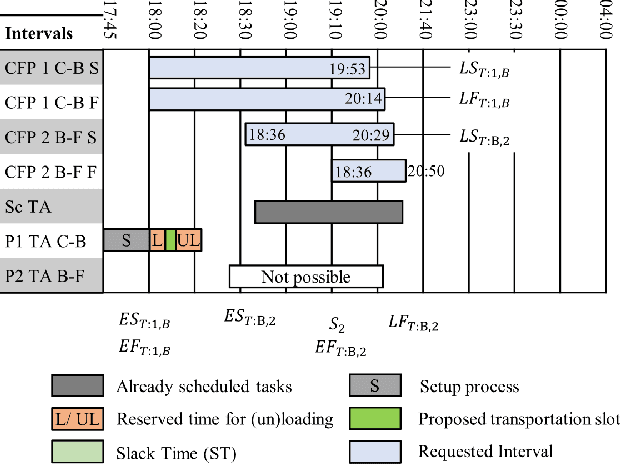
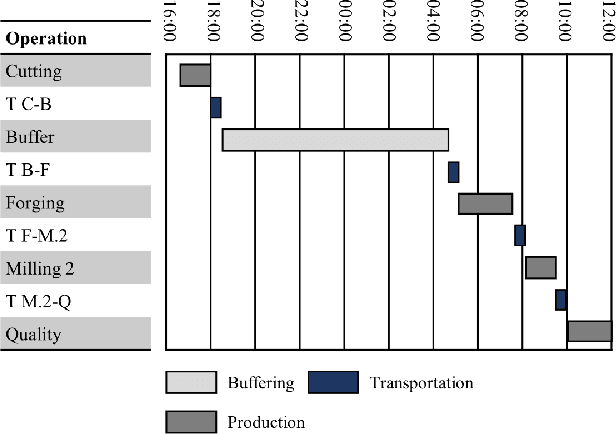
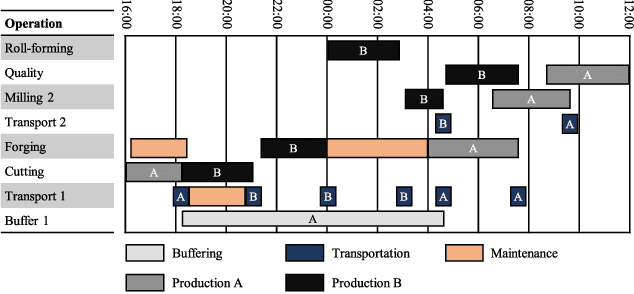
Individualized products and shorter product life cycles have driven companies to rethink traditional mass production. New concepts like Industry 4.0 foster the advent of decentralized production control and distribution of information. A promising technology for realizing such scenarios are Multi-agent systems. This contribution analyses the requirements for an agent-based decentralized and integrated scheduling approach. Part of the requirements is to develop a linearly scaling communication architecture, as the communication between the agents is a major driver of the scheduling execution time. The approach schedules production, transportation, buffering and shared resource operations such as tools in an integrated manner to account for interdependencies between them. Part of the logistics requirements reflect constraints for large workpieces such as buffer scarcity. The approach aims at providing a general solution that is also applicable to large system sizes that, for example, can be found in production networks with multiple companies. Further, it is applicable for different kinds of factory organization (flow shop, job shop etc.). The approach is explained using an example based on industrial requirements. Experiments have been conducted to evaluate the scheduling execution time. The results show the approach's linear scaling behavior. Also, analyses of the concurrent negotiation ability are conducted.
End-to-End Topology-Aware Machine Learning for Power System Reliability Assessment
May 30, 2022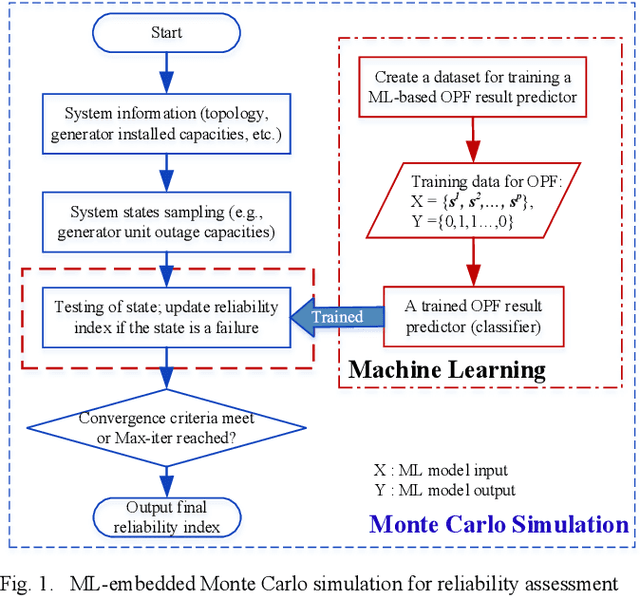
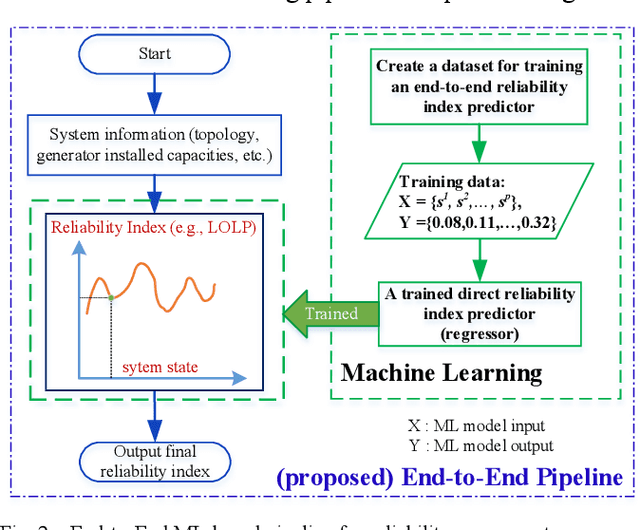
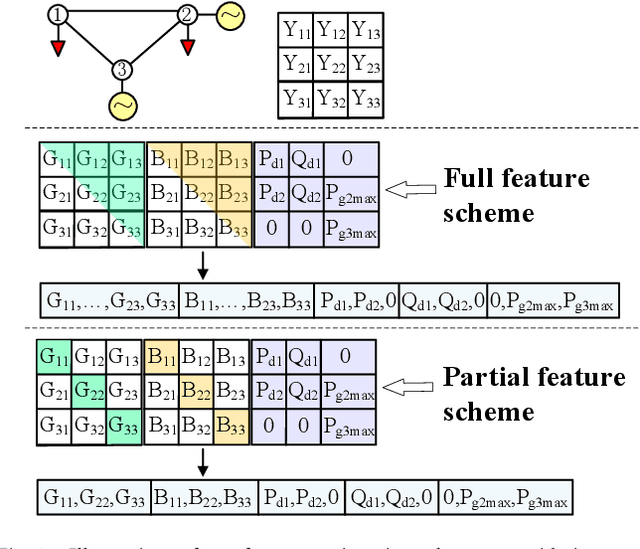
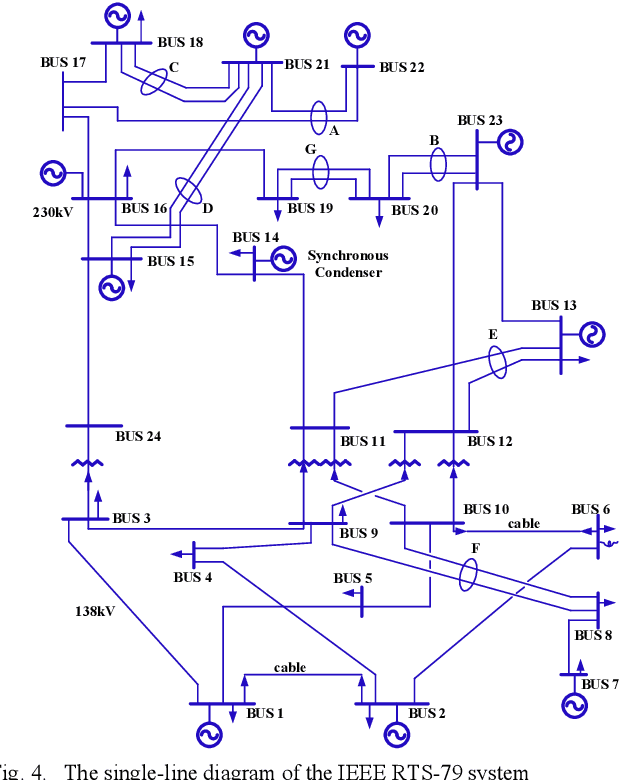
Conventional power system reliability suffers from the long run time of Monte Carlo simulation and the dimension-curse of analytic enumeration methods. This paper proposes a preliminary investigation on end-to-end machine learning for directly predicting the reliability index, e.g., the Loss of Load Probability (LOLP). By encoding the system admittance matrix into the input feature, the proposed machine learning pipeline can consider the impact of specific topology changes due to regular maintenances of transmission lines. Two models (Support Vector Machine and Boosting Trees) are trained and compared. Details regarding the training data creation and preprocessing are also discussed. Finally, experiments are conducted on the IEEE RTS-79 system. Results demonstrate the applicability of the proposed end-to-end machine learning pipeline in reliability assessment.
A Deep Learning Approach to Dst Index Prediction
May 05, 2022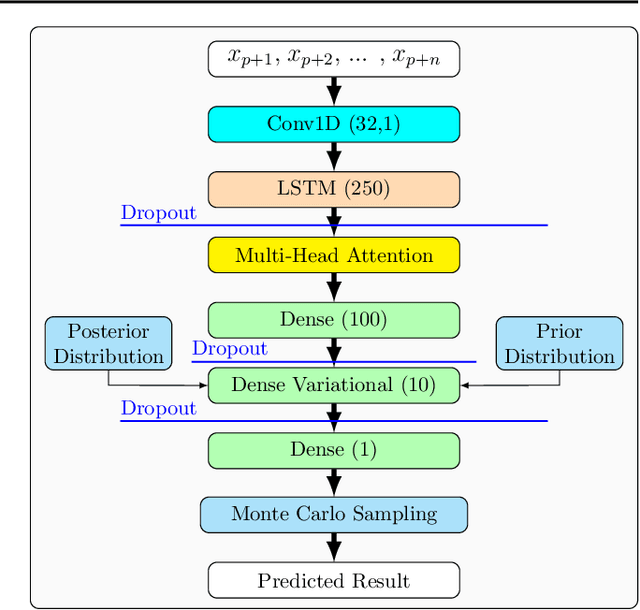
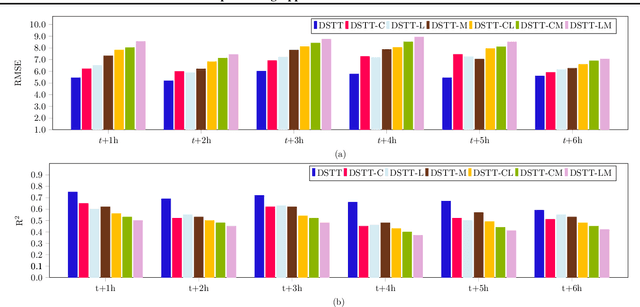
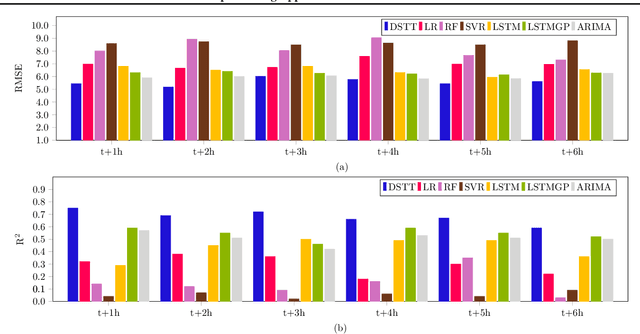
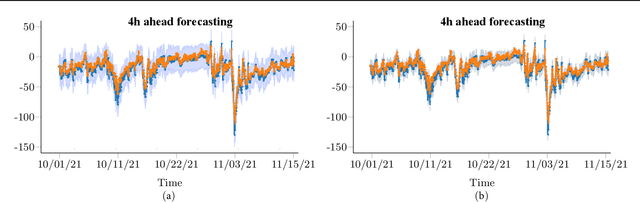
The disturbance storm time (Dst) index is an important and useful measurement in space weather research. It has been used to characterize the size and intensity of a geomagnetic storm. A negative Dst value means that the Earth's magnetic field is weakened, which happens during storms. In this paper, we present a novel deep learning method, called the Dst Transformer, to perform short-term, 1-6 hour ahead, forecasting of the Dst index based on the solar wind parameters provided by the NASA Space Science Data Coordinated Archive. The Dst Transformer combines a multi-head attention layer with Bayesian inference, which is capable of quantifying both aleatoric uncertainty and epistemic uncertainty when making Dst predictions. Experimental results show that the proposed Dst Transformer outperforms related machine learning methods in terms of the root mean square error and R-squared. Furthermore, the Dst Transformer can produce both data and model uncertainty quantification results, which can not be done by the existing methods. To our knowledge, this is the first time that Bayesian deep learning has been used for Dst index forecasting.
Rank-One Prior: Toward Real-Time Scene Recovery
Apr 07, 2021

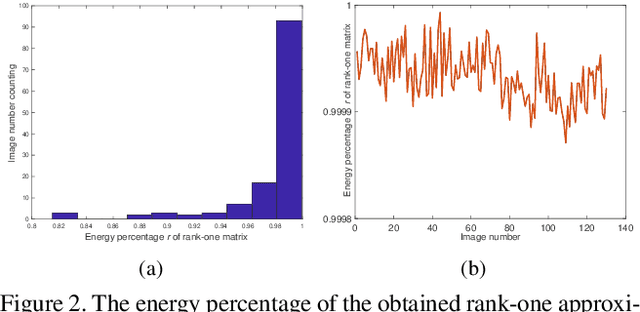
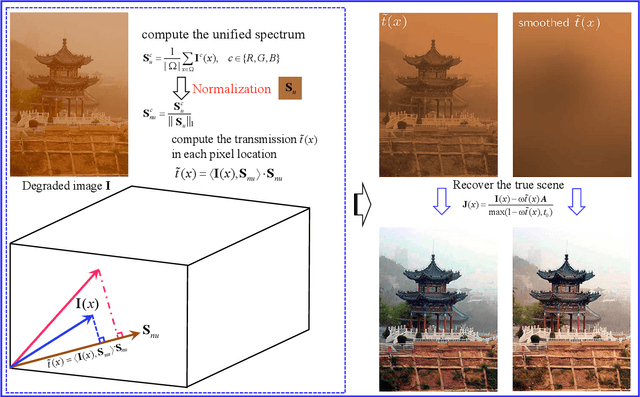
Scene recovery is a fundamental imaging task for several practical applications, e.g., video surveillance and autonomous vehicles, etc. To improve visual quality under different weather/imaging conditions, we propose a real-time light correction method to recover the degraded scenes in the cases of sandstorms, underwater, and haze. The heart of our work is that we propose an intensity projection strategy to estimate the transmission. This strategy is motivated by a straightforward rank-one transmission prior. The complexity of transmission estimation is $O(N)$ where $N$ is the size of the single image. Then we can recover the scene in real-time. Comprehensive experiments on different types of weather/imaging conditions illustrate that our method outperforms competitively several state-of-the-art imaging methods in terms of efficiency and robustness.
Real-time Face Mask Detection in Video Data
May 05, 2021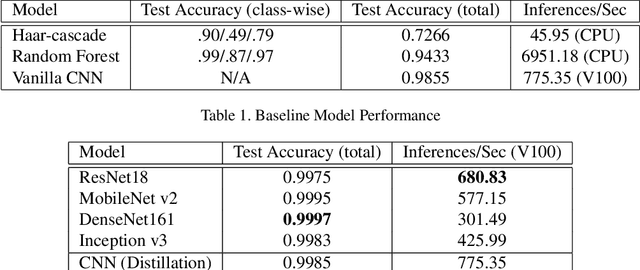
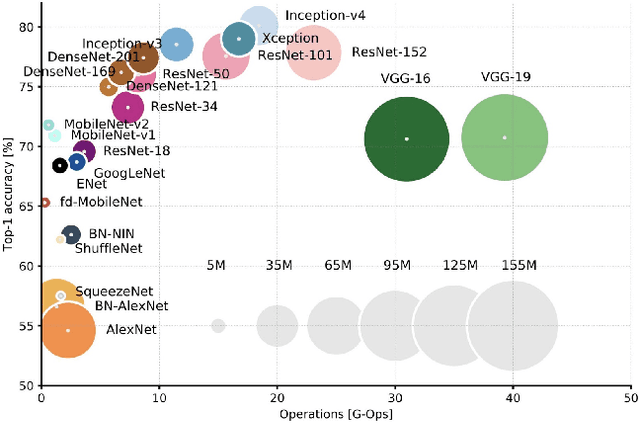
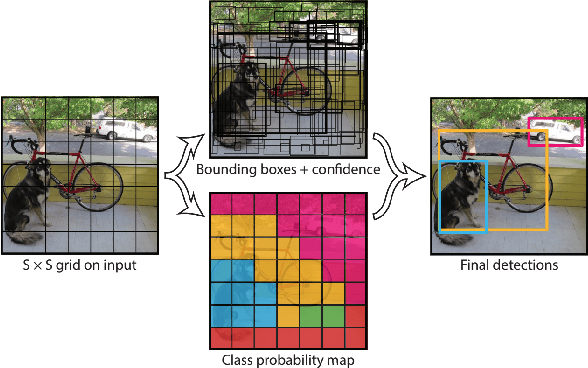
In response to the ongoing COVID-19 pandemic, we present a robust deep learning pipeline that is capable of identifying correct and incorrect mask-wearing from real-time video streams. To accomplish this goal, we devised two separate approaches and evaluated their performance and run-time efficiency. The first approach leverages a pre-trained face detector in combination with a mask-wearing image classifier trained on a large-scale synthetic dataset. The second approach utilizes a state-of-the-art object detection network to perform localization and classification of faces in one shot, fine-tuned on a small set of labeled real-world images. The first pipeline achieved a test accuracy of 99.97% on the synthetic dataset and maintained 6 FPS running on video data. The second pipeline achieved a mAP(0.5) of 89% on real-world images while sustaining 52 FPS on video data. We have concluded that if a larger dataset with bounding-box labels can be curated, this task is best suited using object detection architectures such as YOLO and SSD due to their superior inference speed and satisfactory performance on key evaluation metrics.
A Compression-Compilation Framework for On-mobile Real-time BERT Applications
Jun 06, 2021


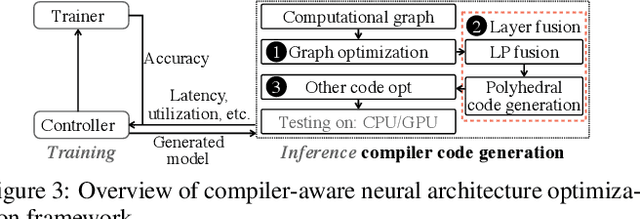
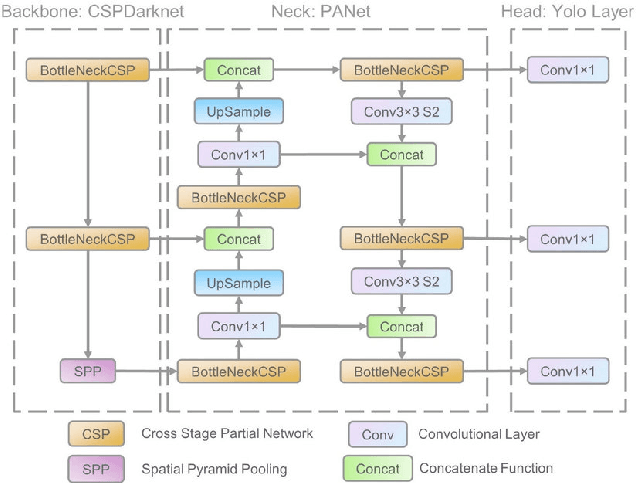
Transformer-based deep learning models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. In this paper, we propose a compression-compilation co-design framework that can guarantee the identified model to meet both resource and real-time specifications of mobile devices. Our framework applies a compiler-aware neural architecture optimization method (CANAO), which can generate the optimal compressed model that balances both accuracy and latency. We are able to achieve up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss. We present two types of BERT applications on mobile devices: Question Answering (QA) and Text Generation. Both can be executed in real-time with latency as low as 45ms. Videos for demonstrating the framework can be found on https://www.youtube.com/watch?v=_WIRvK_2PZI
NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video
Apr 01, 2021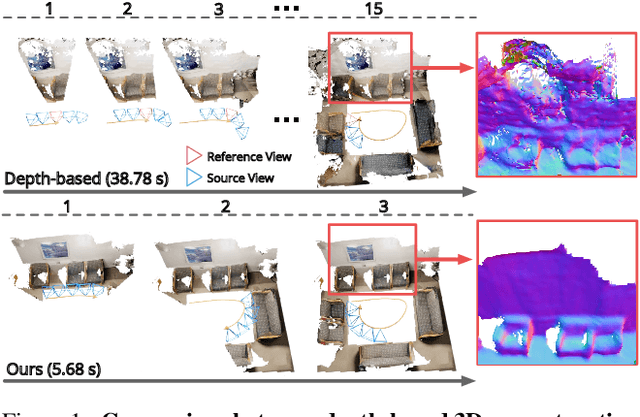
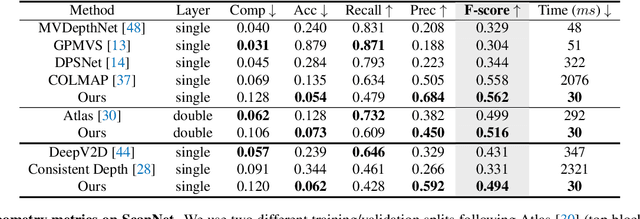
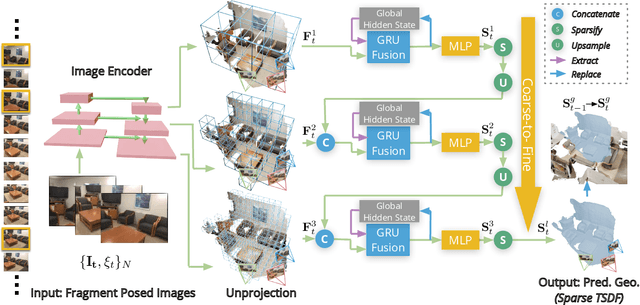
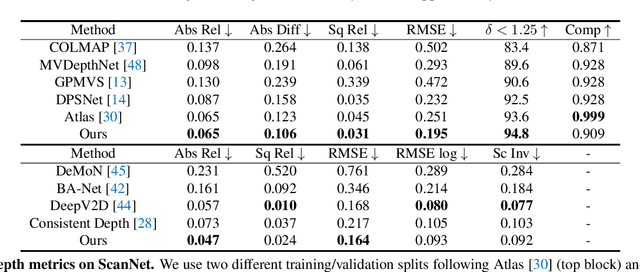
We present a novel framework named NeuralRecon for real-time 3D scene reconstruction from a monocular video. Unlike previous methods that estimate single-view depth maps separately on each key-frame and fuse them later, we propose to directly reconstruct local surfaces represented as sparse TSDF volumes for each video fragment sequentially by a neural network. A learning-based TSDF fusion module based on gated recurrent units is used to guide the network to fuse features from previous fragments. This design allows the network to capture local smoothness prior and global shape prior of 3D surfaces when sequentially reconstructing the surfaces, resulting in accurate, coherent, and real-time surface reconstruction. The experiments on ScanNet and 7-Scenes datasets show that our system outperforms state-of-the-art methods in terms of both accuracy and speed. To the best of our knowledge, this is the first learning-based system that is able to reconstruct dense coherent 3D geometry in real-time.
Achieving Multi-beam Gain in Intelligent Reflecting Surface Assisted Wireless Energy Transfer
May 18, 2022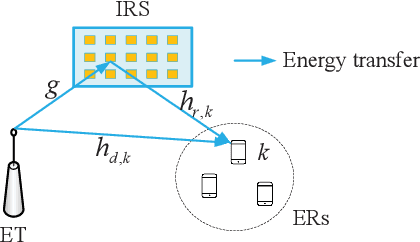


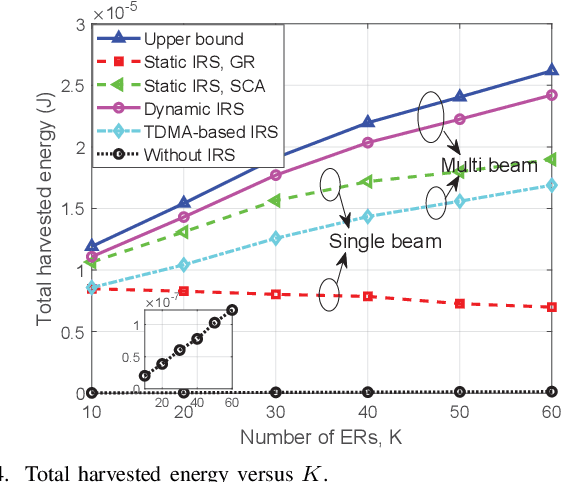
Intelligent reflecting surface (IRS) is a promising technology to boost the efficiency of wireless energy transfer (WET) systems. However, for a multiuser WET system, simultaneous multi-beam energy transmission is generally required to achieve the maximum performance, which may not be implemented by using the IRS having only a single set of coefficients. As a result, it remains unknowns how to exploit the IRS to approach such a performance upper bound. To answer this question, we aim to maximize the total harvested energy of a multiuser WET system subject to the user fairness constraints and the non-linear energy harvesting model. We first consider the static IRS beamforming scheme, which shows that the optimal IRS reflection matrix obtained by applying semidefinite relaxation is indeed of high rank in general as the number of energy receivers (ERs) increases, due to which the resulting rank-one solution by applying Gaussian Randomization may lead to significant loss. To achieve the multi-beam gain, we then propose a general time-division based novel framework by exploiting the IRS's dynamic passive beamforming. Moreover, it is able to achieve a good balance between the system performance and complexity by controlling the number of IRS shift patterns. Finally, we also propose a time-division multiple access (TDMA) based passive beamforming design for performance comparison. Simulation results demonstrate the necessity of multi-beam transmission and the superiority of the proposed dynamic IRS beamforming scheme over existing schemes.
Efficient Bayesian Network Structure Learning via Parameterized Local Search on Topological Orderings
Apr 06, 2022
In Bayesian Network Structure Learning (BNSL), one is given a variable set and parent scores for each variable and aims to compute a DAG, called Bayesian network, that maximizes the sum of parent scores, possibly under some structural constraints. Even very restricted special cases of BNSL are computationally hard, and, thus, in practice heuristics such as local search are used. A natural approach for a local search algorithm is a hill climbing strategy, where one replaces a given BNSL solution by a better solution within some pre-defined neighborhood as long as this is possible. We study ordering-based local search, where a solution is described via a topological ordering of the variables. We show that given such a topological ordering, one can compute an optimal DAG whose ordering is within inversion distance $r$ in subexponential FPT time; the parameter $r$ allows to balance between solution quality and running time of the local search algorithm. This running time bound can be achieved for BNSL without structural constraints and for all structural constraints that can be expressed via a sum of weights that are associated with each parent set. We also introduce a related distance called `window inversions distance' and show that the corresponding local search problem can also be solved in subexponential FPT time for the parameter $r$. For two further natural modification operations on the variable orderings, we show that algorithms with an FPT time for $r$ are unlikely. We also outline the limits of ordering-based local search by showing that it cannot be used for common structural constraints on the moralized graph of the network.
A Feature Selection Method for Multi-Dimension Time-Series Data
Apr 22, 2021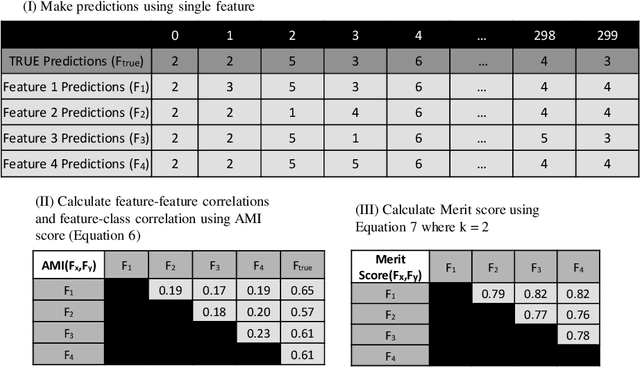
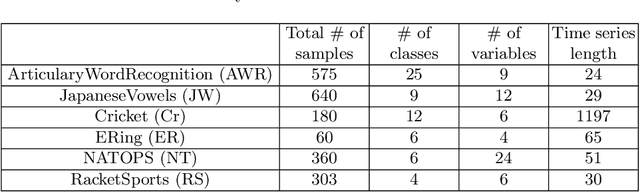
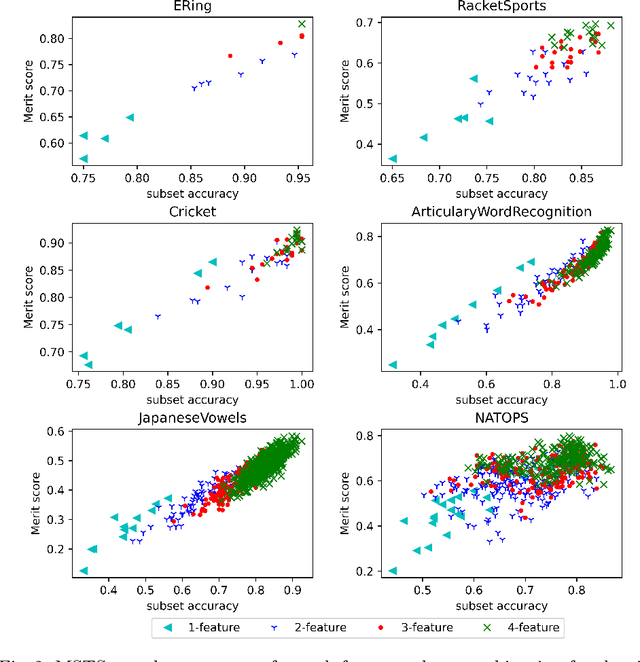
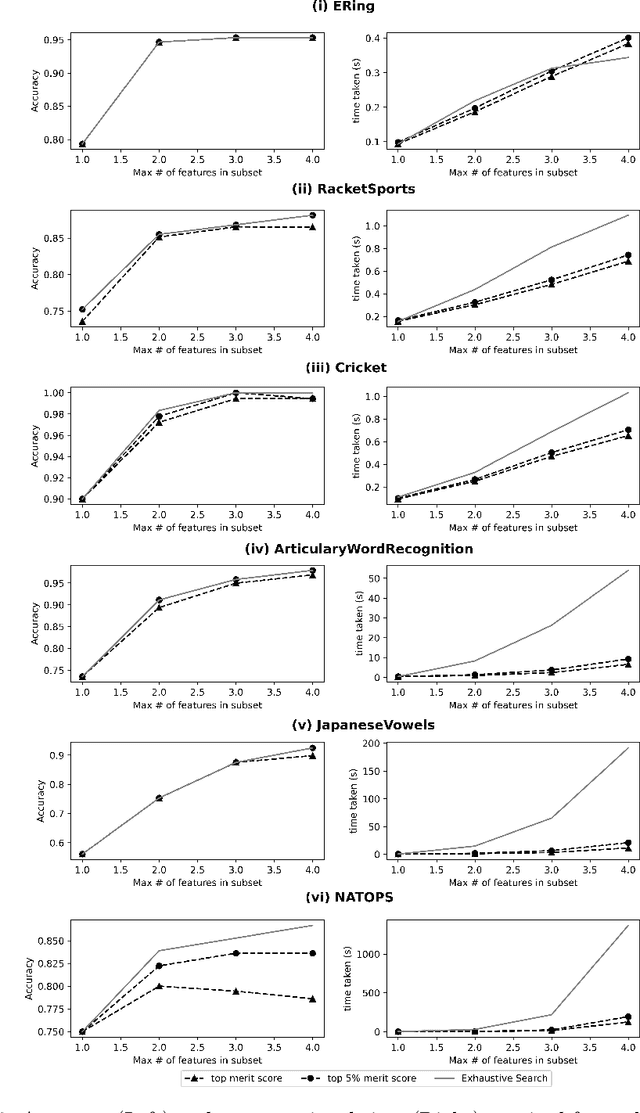
Time-series data in application areas such as motion capture and activity recognition is often multi-dimension. In these application areas data typically comes from wearable sensors or is extracted from video. There is a lot of redundancy in these data streams and good classification accuracy will often be achievable with a small number of features (dimensions). In this paper we present a method for feature subset selection on multidimensional time-series data based on mutual information. This method calculates a merit score (MSTS) based on correlation patterns of the outputs of classifiers trained on single features and the `best' subset is selected accordingly. MSTS was found to be significantly more efficient in terms of computational cost while also managing to maintain a good overall accuracy when compared to Wrapper-based feature selection, a feature selection strategy that is popular elsewhere in Machine Learning. We describe the motivations behind this feature selection strategy and evaluate its effectiveness on six time series datasets.
* 12 pages, 3 figures