 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ImPosIng: Implicit Pose Encoding for Efficient Camera Pose Estimation
May 05, 2022
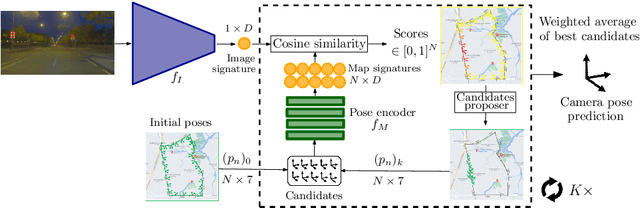
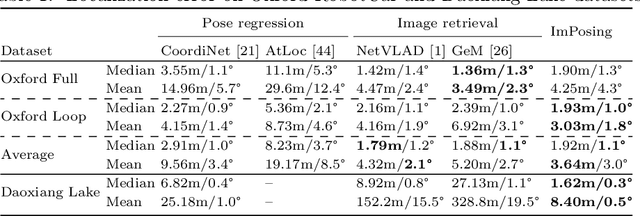


We propose a novel learning-based formulation for camera pose estimation that can perform relocalization accurately and in real-time in city-scale environments. Camera pose estimation algorithms determine the position and orientation from which an image has been captured, using a set of geo-referenced images or 3D scene representation. Our new localization paradigm, named Implicit Pose Encoding (ImPosing), embeds images and camera poses into a common latent representation with 2 separate neural networks, such that we can compute a similarity score for each image-pose pair. By evaluating candidates through the latent space in a hierarchical manner, the camera position and orientation are not directly regressed but incrementally refined. Compared to the representation used in structure-based relocalization methods, our implicit map is memory bounded and can be properly explored to improve localization performances against learning-based regression approaches. In this paper, we describe how to effectively optimize our learned modules, how to combine them to achieve real-time localization, and demonstrate results on diverse large scale scenarios that significantly outperform prior work in accuracy and computational efficiency.
A Survey of Decentralized Online Learning
May 01, 2022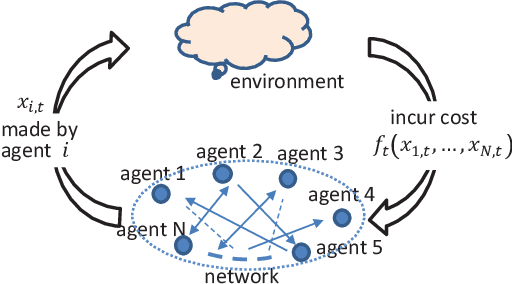

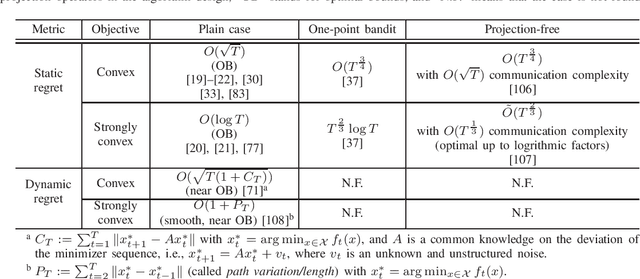
Decentralized online learning (DOL) has been increasingly researched in the last decade, mostly motivated by its wide applications in sensor networks, commercial buildings, robotics (e.g., decentralized target tracking and formation control), smart grids, deep learning, and so forth. In this problem, there are a network of agents who may be cooperative (i.e., decentralized online optimization) or noncooperative (i.e., online game) through local information exchanges, and the local cost function of each agent is often time-varying in dynamic and even adversarial environments. At each time, a decision must be made by each agent based on historical information at hand without knowing future information on cost functions. Although this problem has been extensively studied in the last decade, a comprehensive survey is lacking. Therefore, this paper provides a thorough overview of DOL from the perspective of problem settings, communication, computation, and performances. In addition, some potential future directions are also discussed in details.
Mean Embeddings with Test-Time Data Augmentation for Ensembling of Representations
Jun 15, 2021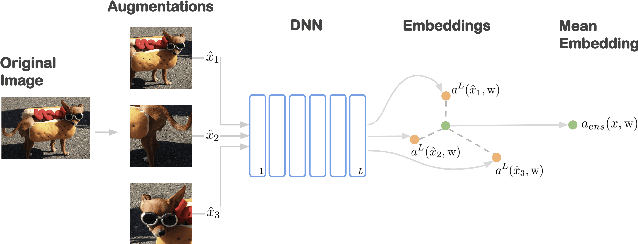
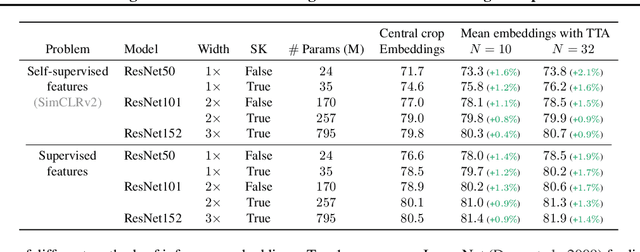
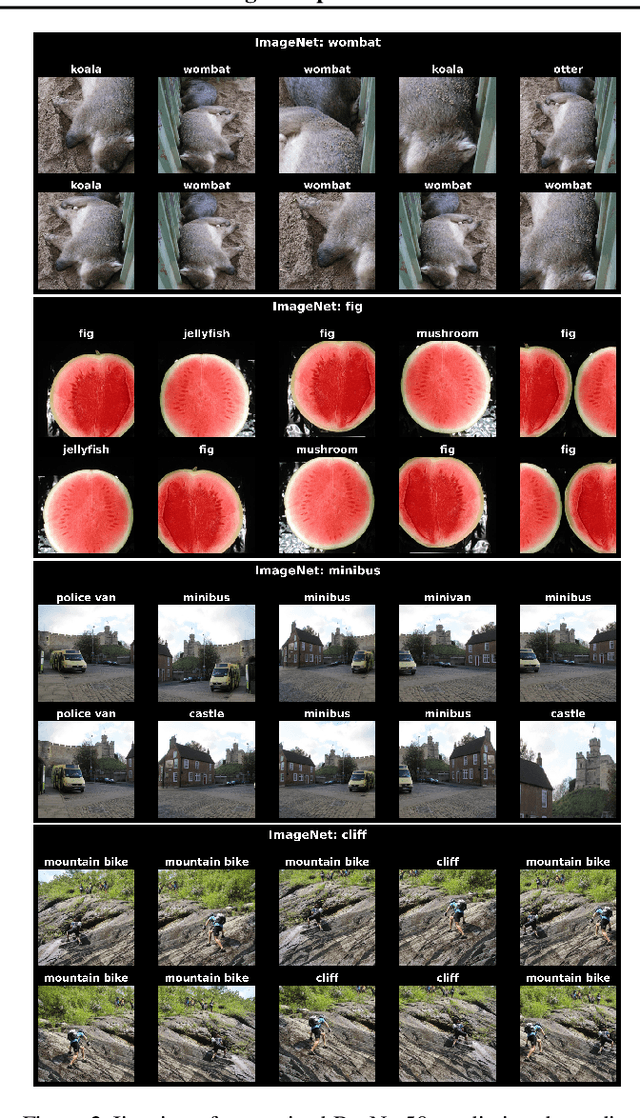
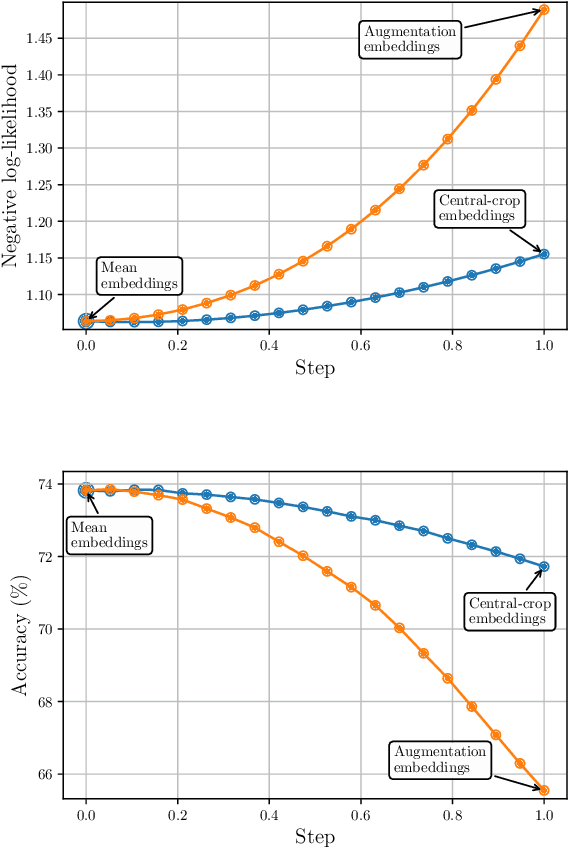
Averaging predictions over a set of models -- an ensemble -- is widely used to improve predictive performance and uncertainty estimation of deep learning models. At the same time, many machine learning systems, such as search, matching, and recommendation systems, heavily rely on embeddings. Unfortunately, due to misalignment of features of independently trained models, embeddings, cannot be improved with a naive deep ensemble like approach. In this work, we look at the ensembling of representations and propose mean embeddings with test-time augmentation (MeTTA) simple yet well-performing recipe for ensembling representations. Empirically we demonstrate that MeTTA significantly boosts the quality of linear evaluation on ImageNet for both supervised and self-supervised models. Even more exciting, we draw connections between MeTTA, image retrieval, and transformation invariant models. We believe that spreading the success of ensembles to inference higher-quality representations is the important step that will open many new applications of ensembling.
X-Risk Analysis for AI Research
Jun 18, 2022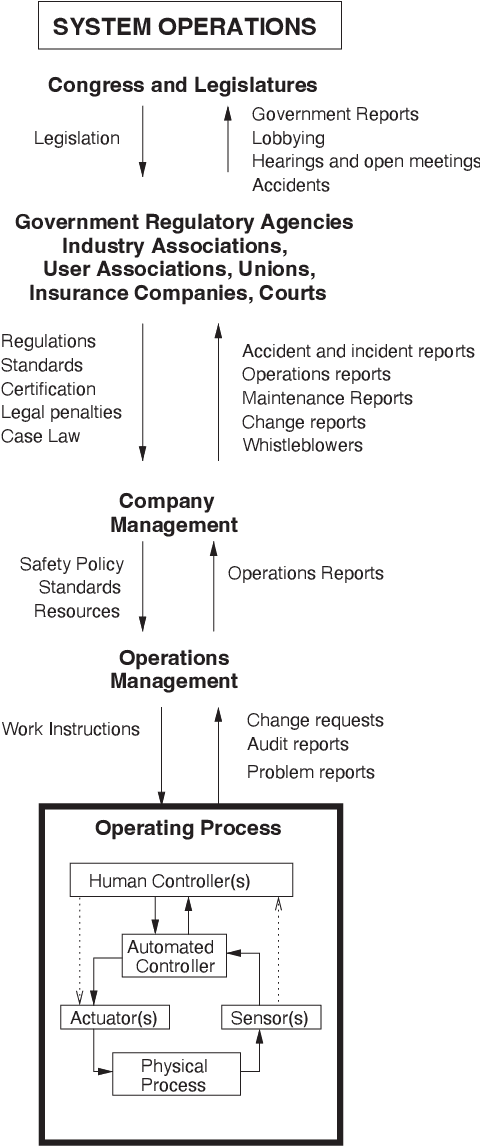
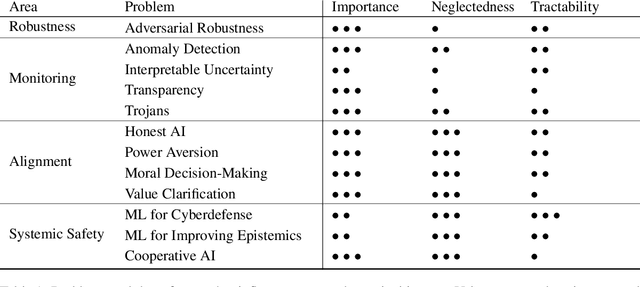
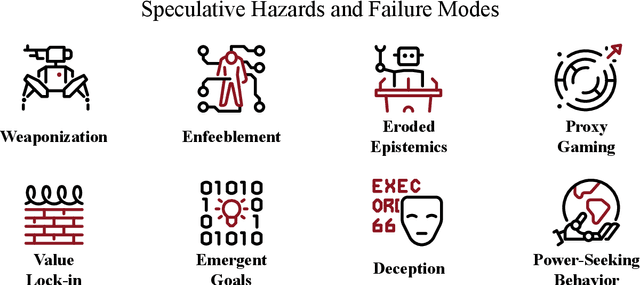
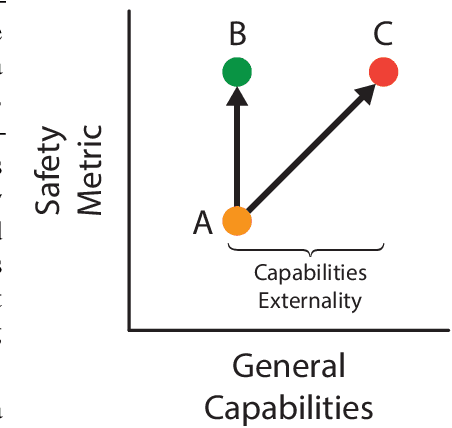
Artificial intelligence (AI) has the potential to greatly improve society, but as with any powerful technology, it comes with heightened risks and responsibilities. Current AI research lacks a systematic discussion of how to manage long-tail risks from AI systems, including speculative long-term risks. Keeping in mind the potential benefits of AI, there is some concern that building ever more intelligent and powerful AI systems could eventually result in systems that are more powerful than us; some say this is like playing with fire and speculate that this could create existential risks (x-risks). To add precision and ground these discussions, we provide a guide for how to analyze AI x-risk, which consists of three parts: First, we review how systems can be made safer today, drawing on time-tested concepts from hazard analysis and systems safety that have been designed to steer large processes in safer directions. Next, we discuss strategies for having long-term impacts on the safety of future systems. Finally, we discuss a crucial concept in making AI systems safer by improving the balance between safety and general capabilities. We hope this document and the presented concepts and tools serve as a useful guide for understanding how to analyze AI x-risk.
Learning to Drive Using Sparse Imitation Reinforcement Learning
May 24, 2022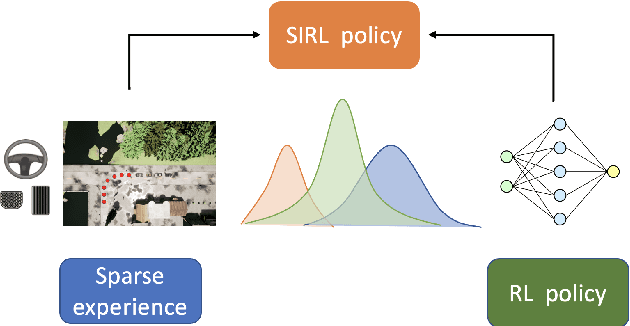

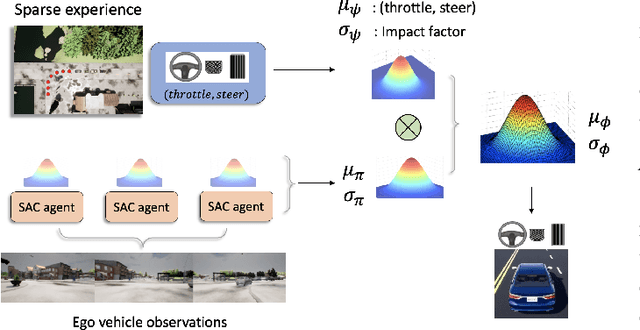
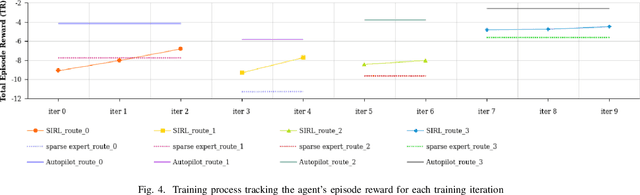
In this paper, we propose Sparse Imitation Reinforcement Learning (SIRL), a hybrid end-to-end control policy that combines the sparse expert driving knowledge with reinforcement learning (RL) policy for autonomous driving (AD) task in CARLA simulation environment. The sparse expert is designed based on hand-crafted rules which is suboptimal but provides a risk-averse strategy by enforcing experience for critical scenarios such as pedestrian and vehicle avoidance, and traffic light detection. As it has been demonstrated, training a RL agent from scratch is data-inefficient and time consuming particularly for the urban driving task, due to the complexity of situations stemming from the vast size of state space. Our SIRL strategy provides a solution to solve these problems by fusing the output distribution of the sparse expert policy and the RL policy to generate a composite driving policy. With the guidance of the sparse expert during the early training stage, SIRL strategy accelerates the training process and keeps the RL exploration from causing a catastrophe outcome, and ensures safe exploration. To some extent, the SIRL agent is imitating the driving expert's behavior. At the same time, it continuously gains knowledge during training therefore it keeps making improvement beyond the sparse expert, and can surpass both the sparse expert and a traditional RL agent. We experimentally validate the efficacy of proposed SIRL approach in a complex urban scenario within the CARLA simulator. Besides, we compare the SIRL agent's performance for risk-averse exploration and high learning efficiency with the traditional RL approach. We additionally demonstrate the SIRL agent's generalization ability to transfer the driving skill to unseen environment.
Time-Based CAN Intrusion Detection Benchmark
Jan 14, 2021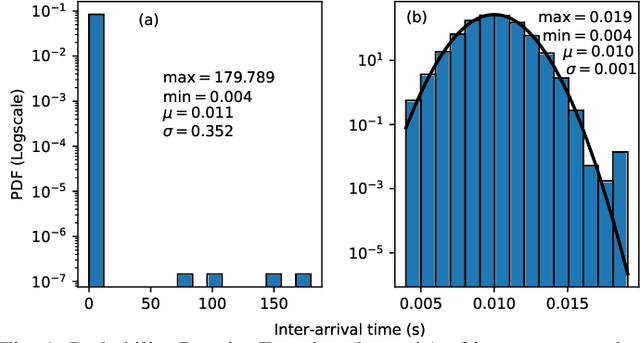
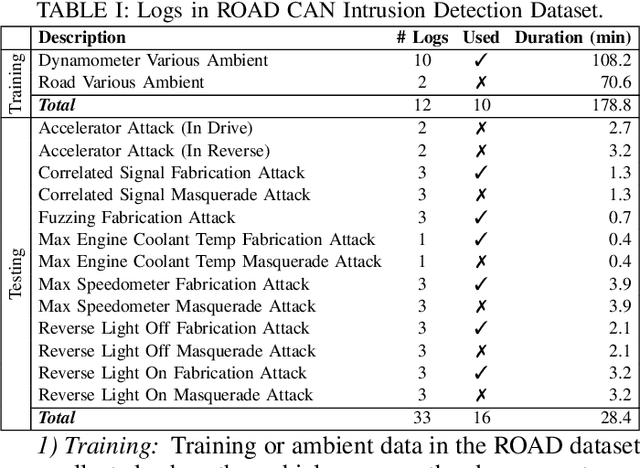
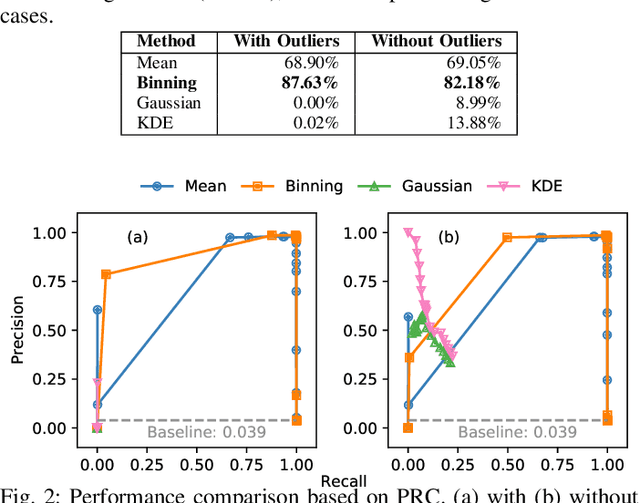
Modern vehicles are complex cyber-physical systems made of hundreds of electronic control units (ECUs) that communicate over controller area networks (CANs). This inherited complexity has expanded the CAN attack surface which is vulnerable to message injection attacks. These injections change the overall timing characteristics of messages on the bus, and thus, to detect these malicious messages, time-based intrusion detection systems (IDSs) have been proposed. However, time-based IDSs are usually trained and tested on low-fidelity datasets with unrealistic, labeled attacks. This makes difficult the task of evaluating, comparing, and validating IDSs. Here we detail and benchmark four time-based IDSs against the newly published ROAD dataset, the first open CAN IDS dataset with real (non-simulated) stealthy attacks with physically verified effects. We found that methods that perform hypothesis testing by explicitly estimating message timing distributions have lower performance than methods that seek anomalies in a distribution-related statistic. In particular, these "distribution-agnostic" based methods outperform "distribution-based" methods by at least 55% in area under the precision-recall curve (AUC-PR). Our results expand the body of knowledge of CAN time-based IDSs by providing details of these methods and reporting their results when tested on datasets with real advanced attacks. Finally, we develop an after-market plug-in detector using lightweight hardware, which can be used to deploy the best performing IDS method on nearly any vehicle.
Asynchrony Increases Efficiency: Time Encoding of Videos and Low-Rank Signals
Apr 29, 2021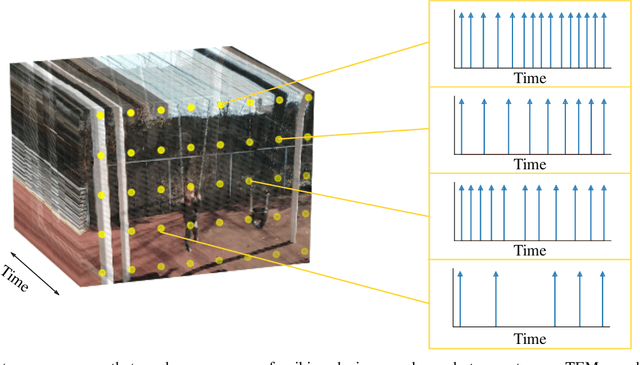
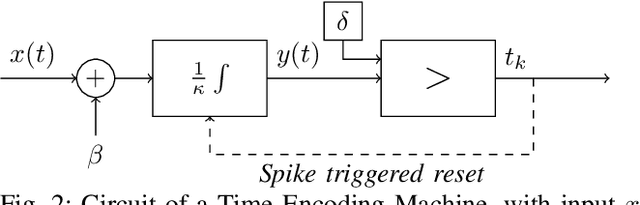
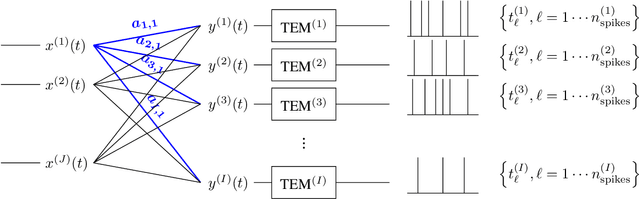
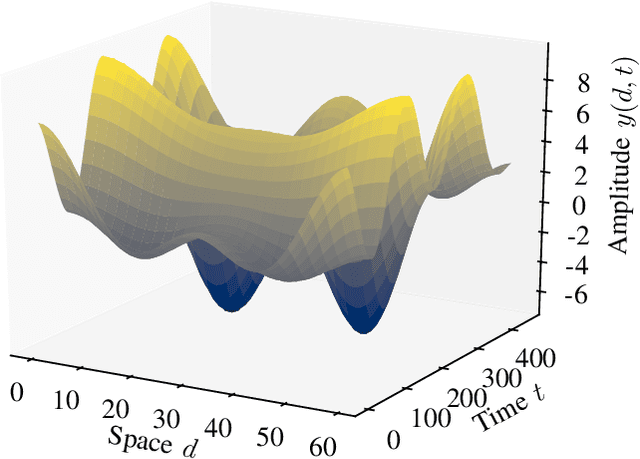
In event-based sensing, many sensors independently and asynchronously emit events when there is a change in their input. Event-based sensing can present significant improvements in power efficiency when compared to traditional sampling, because (1) the output is a stream of events where the important information lies in the timing of the events, and (2) the sensor can easily be controlled to output information only when interesting activity occurs at the input. Moreover, event-based sampling can often provide better resolution than standard uniform sampling. Not only does this occur because individual event-based sensors have higher temporal resolution, it also occurs because the asynchrony of events allows for less redundant and more informative encoding. We would like to explain how such curious results come about. To do so, we use ideal time encoding machines as a proxy for event-based sensors. We explore time encoding of signals with low rank structure, and apply the resulting theory to video. We then see how the asynchronous firing times of the time encoding machines allow for better reconstruction than in the standard sampling case, if we have a high spatial density of time encoding machines that fire less frequently.
Interpretable Gait Recognition by Granger Causality
Jun 15, 2022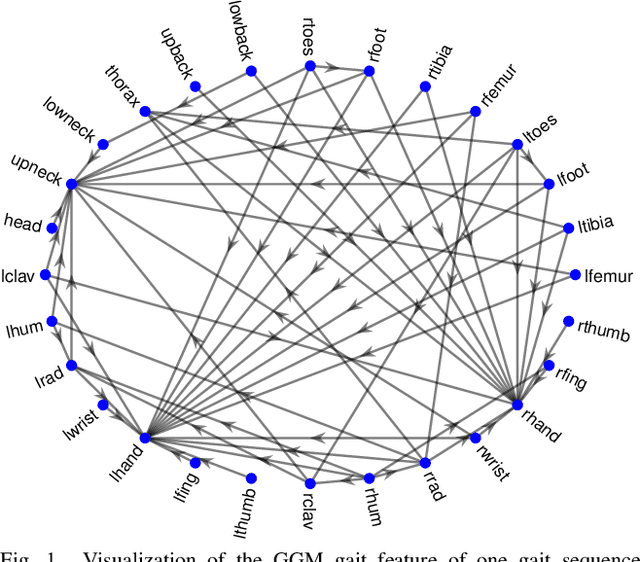
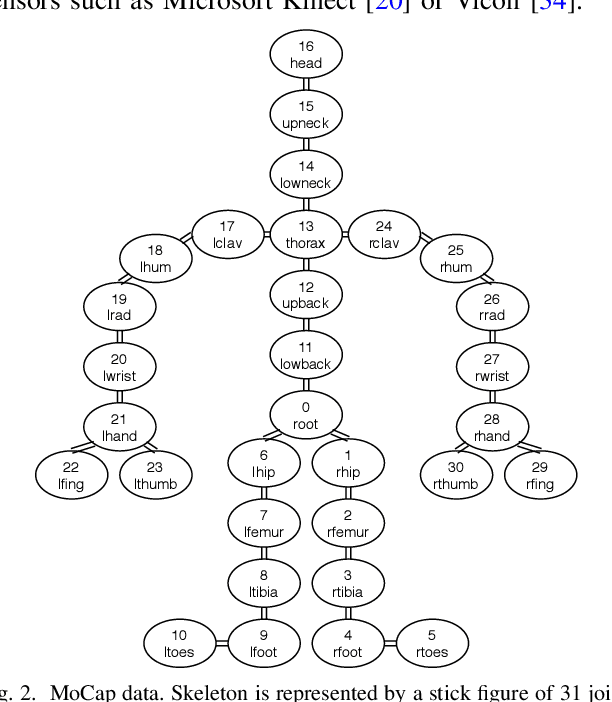
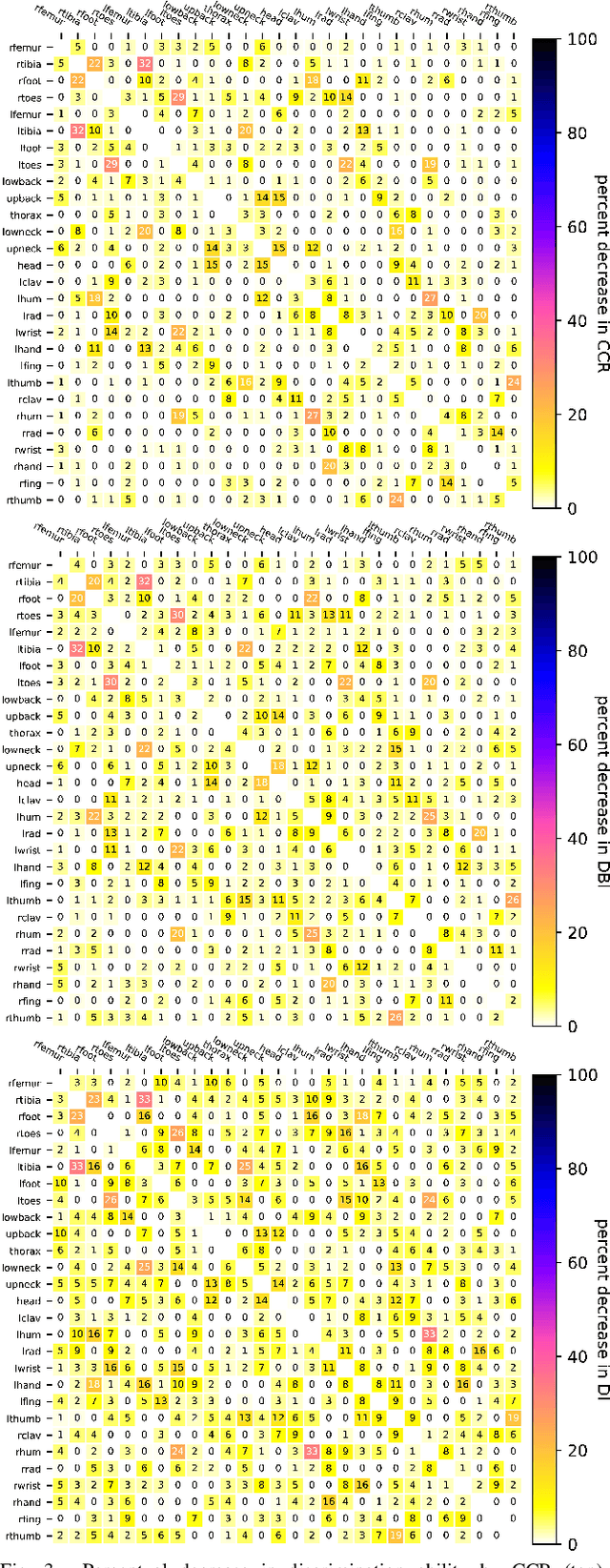
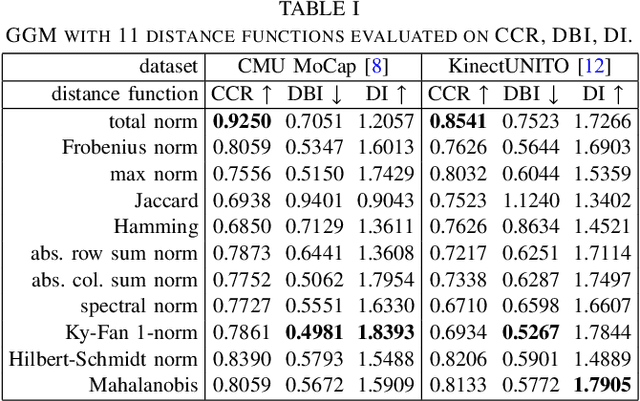
Which joint interactions in the human gait cycle can be used as biometric characteristics? Most current methods on gait recognition suffer from the lack of interpretability. We propose an interpretable feature representation of gait sequences by the graphical Granger causal inference. Gait sequence of a person in the standardized motion capture format, constituting a set of 3D joint spatial trajectories, is envisaged as a causal system of joints interacting in time. We apply the graphical Granger model (GGM) to obtain the so-called Granger causal graph among joints as a discriminative and visually interpretable representation of a person's gait. We evaluate eleven distance functions in the GGM feature space by established classification and class-separability evaluation metrics. Our experiments indicate that, depending on the metric, the most appropriate distance functions for the GGM are the total norm distance and the Ky-Fan 1-norm distance. Experiments also show that the GGM is able to detect the most discriminative joint interactions and that it outperforms five related interpretable models in correct classification rate and in Davies-Bouldin index. The proposed GGM model can serve as a complementary tool for gait analysis in kinesiology or for gait recognition in video surveillance.
Mean-Semivariance Policy Optimization via Risk-Averse Reinforcement Learning
Jun 15, 2022
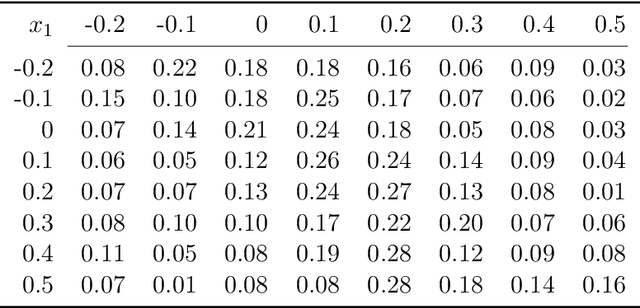
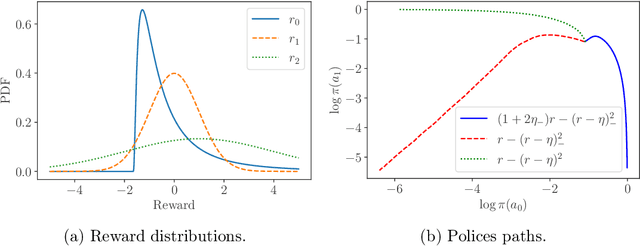
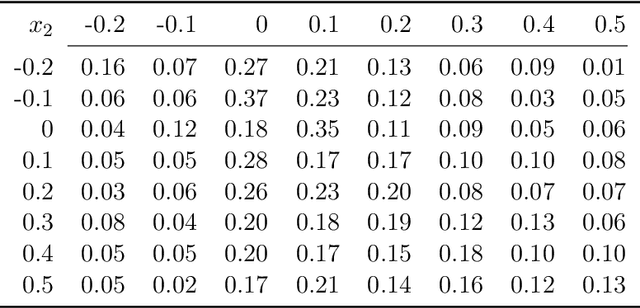
Keeping risk under control is often more crucial than maximizing expected reward in real-world decision-making situations, such as finance, robotics, autonomous driving, etc. The most natural choice of risk measures is variance, while it penalizes the upside volatility as much as the downside part. Instead, the (downside) semivariance, which captures negative deviation of a random variable under its mean, is more suitable for risk-averse proposes. This paper aims at optimizing the mean-semivariance (MSV) criterion in reinforcement learning w.r.t. steady rewards. Since semivariance is time-inconsistent and does not satisfy the standard Bellman equation, the traditional dynamic programming methods are inapplicable to MSV problems directly. To tackle this challenge, we resort to the Perturbation Analysis (PA) theory and establish the performance difference formula for MSV. We reveal that the MSV problem can be solved by iteratively solving a sequence of RL problems with a policy-dependent reward function. Further, we propose two on-policy algorithms based on the policy gradient theory and the trust region method. Finally, we conduct diverse experiments from simple bandit problems to continuous control tasks in MuJoCo, which demonstrate the effectiveness of our proposed methods.
End-to-End Topology-Aware Machine Learning for Power System Reliability Assessment
May 30, 2022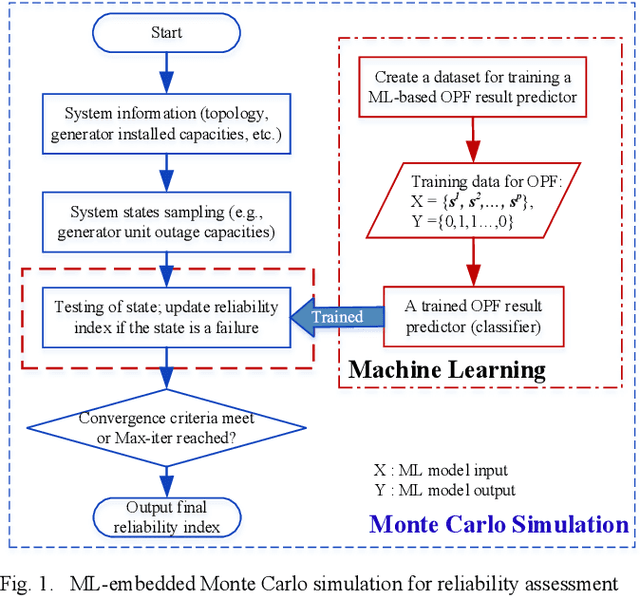
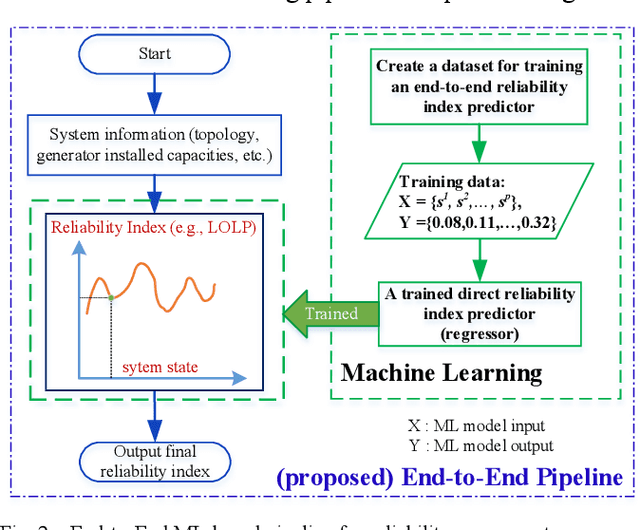
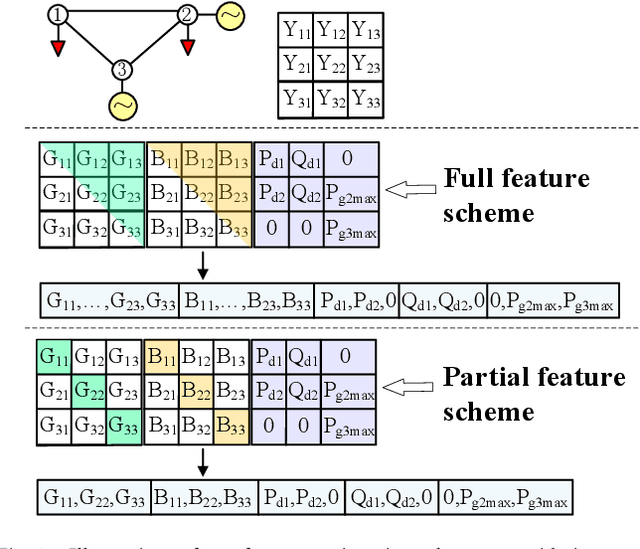
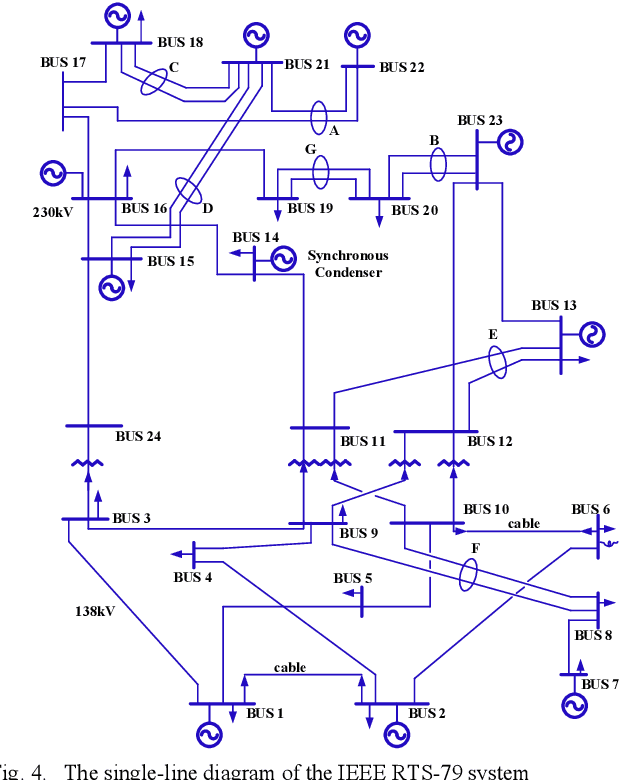
Conventional power system reliability suffers from the long run time of Monte Carlo simulation and the dimension-curse of analytic enumeration methods. This paper proposes a preliminary investigation on end-to-end machine learning for directly predicting the reliability index, e.g., the Loss of Load Probability (LOLP). By encoding the system admittance matrix into the input feature, the proposed machine learning pipeline can consider the impact of specific topology changes due to regular maintenances of transmission lines. Two models (Support Vector Machine and Boosting Trees) are trained and compared. Details regarding the training data creation and preprocessing are also discussed. Finally, experiments are conducted on the IEEE RTS-79 system. Results demonstrate the applicability of the proposed end-to-end machine learning pipeline in reliability assessment.