 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The DEBS 2022 Grand Challenge: Detecting Trading Trends in Financial Tick Data
Jun 23, 2022
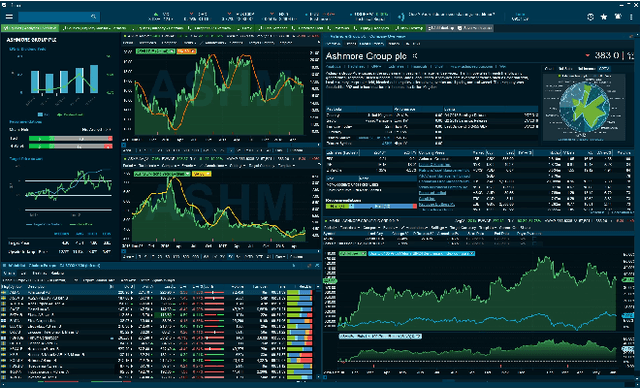
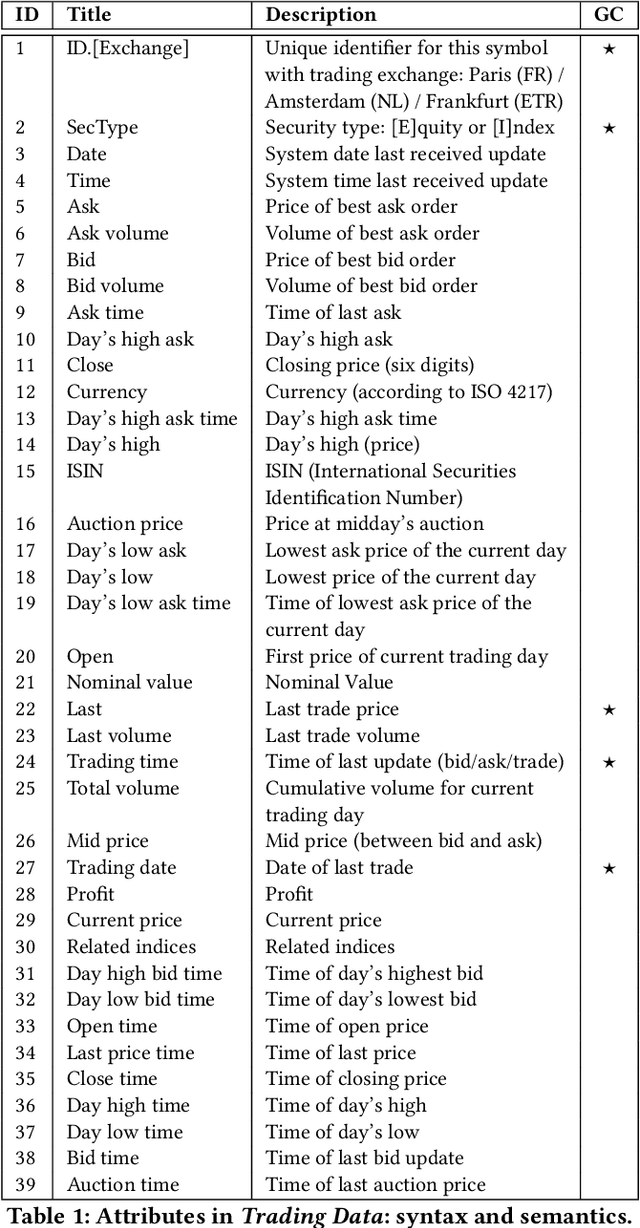
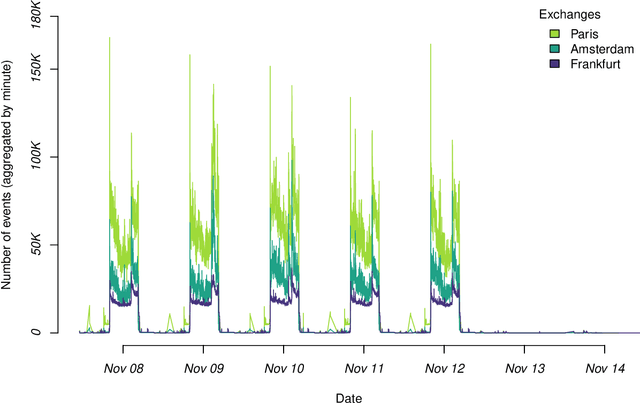
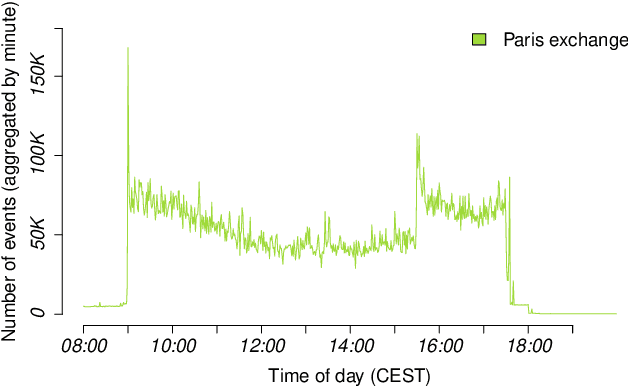
The DEBS Grand Challenge (GC) is an annual programming competition open to practitioners from both academia and industry. The GC 2022 edition focuses on real-time complex event processing of high-volume tick data provided by Infront Financial Technology GmbH. The goal of the challenge is to efficiently compute specific trend indicators and detect patterns in these indicators like those used by real-life traders to decide on buying or selling in financial markets. The data set Trading Data used for benchmarking contains 289 million tick events from approximately 5500+ financial instruments that had been traded on the three major exchanges Amsterdam (NL), Paris (FR), and Frankfurt am Main (GER) over the course of a full week in 2021. The data set is made publicly available. In addition to correctness and performance, submissions must explicitly focus on reusability and practicability. Hence, participants must address specific nonfunctional requirements and are asked to build upon open-source platforms. This paper describes the required scenario and the data set Trading Data, defines the queries of the problem statement, and explains the enhancements made to the evaluation platform Challenger that handles data distribution, dynamic subscriptions, and remote evaluation of the submissions.
Making a (Counterfactual) Difference One Rationale at a Time
Jan 13, 2022

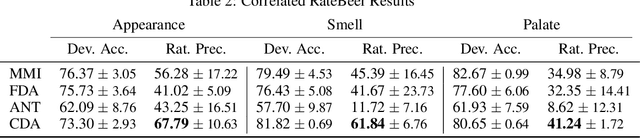
Rationales, snippets of extracted text that explain an inference, have emerged as a popular framework for interpretable natural language processing (NLP). Rationale models typically consist of two cooperating modules: a selector and a classifier with the goal of maximizing the mutual information (MMI) between the "selected" text and the document label. Despite their promises, MMI-based methods often pick up on spurious text patterns and result in models with nonsensical behaviors. In this work, we investigate whether counterfactual data augmentation (CDA), without human assistance, can improve the performance of the selector by lowering the mutual information between spurious signals and the document label. Our counterfactuals are produced in an unsupervised fashion using class-dependent generative models. From an information theoretic lens, we derive properties of the unaugmented dataset for which our CDA approach would succeed. The effectiveness of CDA is empirically evaluated by comparing against several baselines including an improved MMI-based rationale schema on two multi aspect datasets. Our results show that CDA produces rationales that better capture the signal of interest.
Microring resonators with external optical feedback for time delay reservoir computing
Sep 23, 2021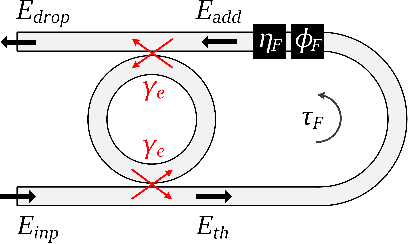
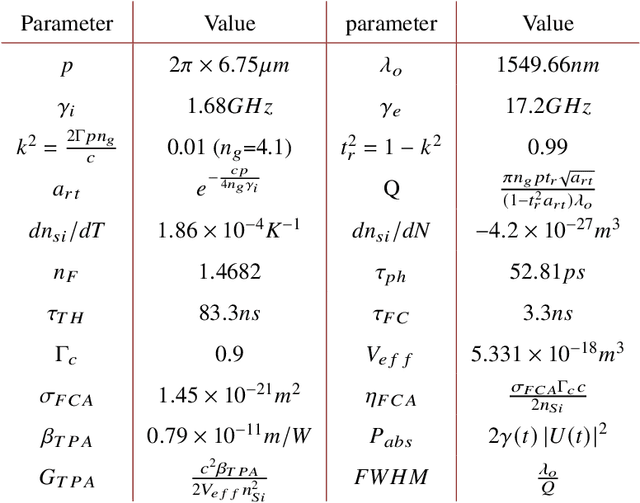
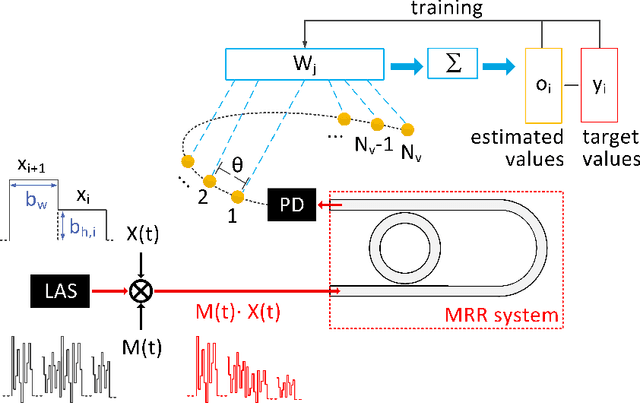
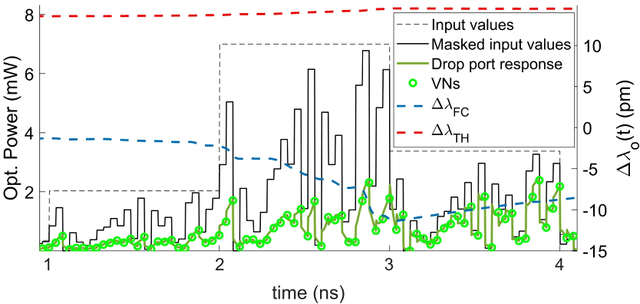
Microring resonators (MRRs) are a key photonic component in integrated devices, due to their small size, low insertion losses, and passive operation. While the MRRs have been established for optical filtering in wavelength-multiplexed systems, the nonlinear properties that they can exhibit give rise to new perspectives on their use. For instance, they have been recently considered for introducing optical nonlinearity in photonic reservoir computing systems. In this work, we present a detailed numerical investigation of a silicon MRR operation, in the presence of external optical feedback, in a time delay reservoir computing scheme. We demonstrate the versatility of this compact, passive device, by exploiting different operating regimes and solving computing tasks with diverse memory requirements. We show that when large memory is required, as it occurs in the Narma 10 task, the MRR nonlinearity does not play a significant role when the photodetection nonlinearity is involved, while the contribution of the external feedback is significant. On the contrary, for computing tasks such as the Mackey-Glass and the Santa Fe chaotic timeseries prediction, the MRR and the photodetection nonlinearities contribute both to efficient computation. The presence of optical feedback improves the prediction of the Mackey-Glass timeseries while plays a minor role in the Santa Fe timeseries case.
HealNet -- Self-Supervised Acute Wound Heal-Stage Classification
Jun 23, 2022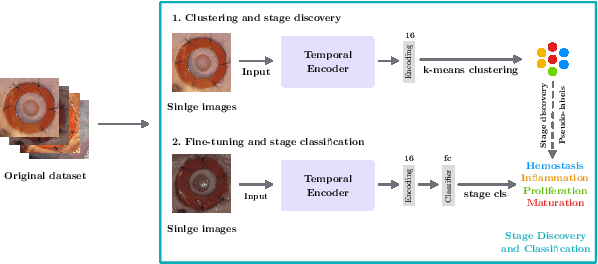
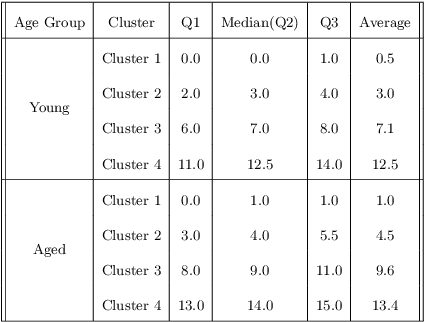


Identifying, tracking, and predicting wound heal-stage progression is a fundamental task towards proper diagnosis, effective treatment, facilitating healing, and reducing pain. Traditionally, a medical expert might observe a wound to determine the current healing state and recommend treatment. However, sourcing experts who can produce such a diagnosis solely from visual indicators can be difficult, time-consuming and expensive. In addition, lesions may take several weeks to undergo the healing process, demanding resources to monitor and diagnose continually. Automating this task can be challenging; datasets that follow wound progression from onset to maturation are small, rare, and often collected without computer vision in mind. To tackle these challenges, we introduce a self-supervised learning scheme composed of (a) learning embeddings of wound's temporal dynamics, (b) clustering for automatic stage discovery, and (c) fine-tuned classification. The proposed self-supervised and flexible learning framework is biologically inspired and trained on a small dataset with zero human labeling. The HealNet framework achieved high pre-text and downstream classification accuracy; when evaluated on held-out test data, HealNet achieved 97.7% pre-text accuracy and 90.62% heal-stage classification accuracy.
AFT-VO: Asynchronous Fusion Transformers for Multi-View Visual Odometry Estimation
Jun 26, 2022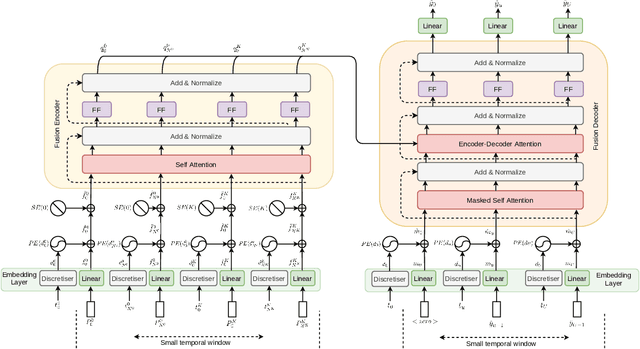
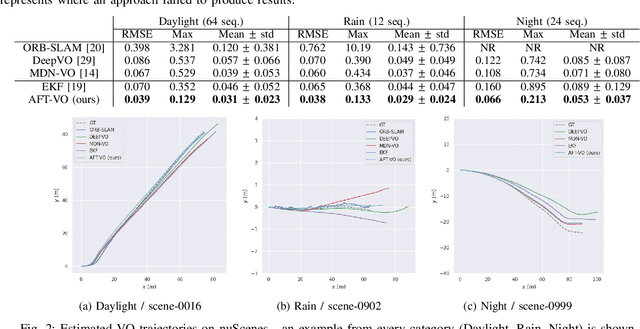
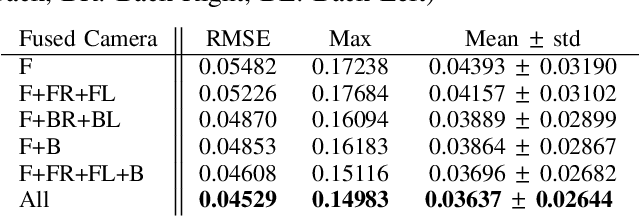
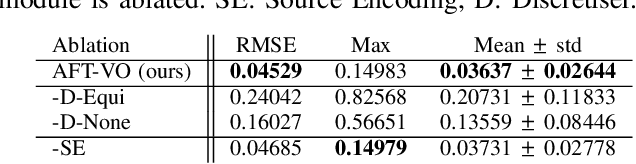
Motion estimation approaches typically employ sensor fusion techniques, such as the Kalman Filter, to handle individual sensor failures. More recently, deep learning-based fusion approaches have been proposed, increasing the performance and requiring less model-specific implementations. However, current deep fusion approaches often assume that sensors are synchronised, which is not always practical, especially for low-cost hardware. To address this limitation, in this work, we propose AFT-VO, a novel transformer-based sensor fusion architecture to estimate VO from multiple sensors. Our framework combines predictions from asynchronous multi-view cameras and accounts for the time discrepancies of measurements coming from different sources. Our approach first employs a Mixture Density Network (MDN) to estimate the probability distributions of the 6-DoF poses for every camera in the system. Then a novel transformer-based fusion module, AFT-VO, is introduced, which combines these asynchronous pose estimations, along with their confidences. More specifically, we introduce Discretiser and Source Encoding techniques which enable the fusion of multi-source asynchronous signals. We evaluate our approach on the popular nuScenes and KITTI datasets. Our experiments demonstrate that multi-view fusion for VO estimation provides robust and accurate trajectories, outperforming the state of the art in both challenging weather and lighting conditions.
An FPGA-based Solution for Convolution Operation Acceleration
Jun 09, 2022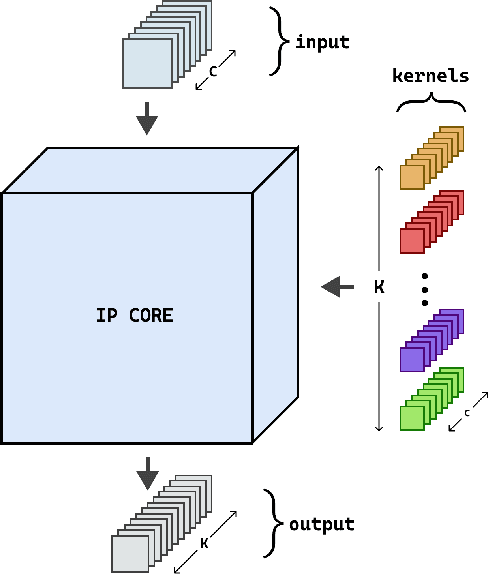

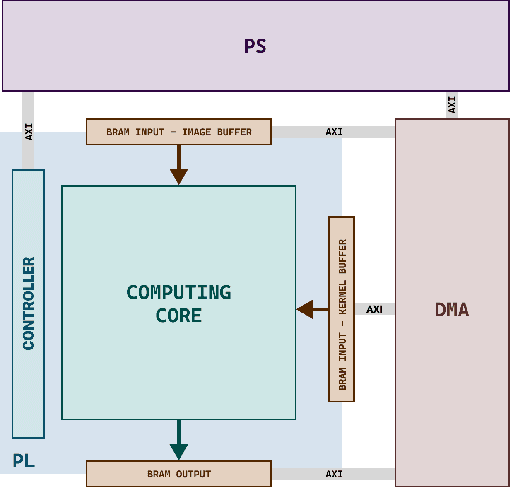
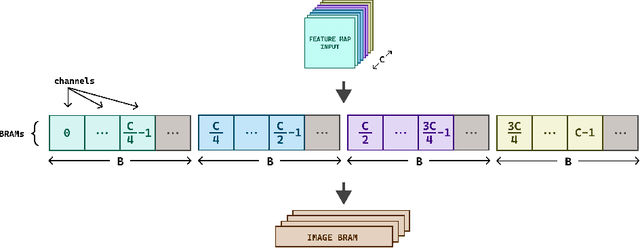
Hardware-based acceleration is an extensive attempt to facilitate many computationally-intensive mathematics operations. This paper proposes an FPGA-based architecture to accelerate the convolution operation - a complex and expensive computing step that appears in many Convolutional Neural Network models. We target the design to the standard convolution operation, intending to launch the product as an edge-AI solution. The project's purpose is to produce an FPGA IP core that can process a convolutional layer at a time. System developers can deploy the IP core with various FPGA families by using Verilog HDL as the primary design language for the architecture. The experimental results show that our single computing core synthesized on a simple edge computing FPGA board can offer 0.224 GOPS. When the board is fully utilized, 4.48 GOPS can be achieved.
cycle text2face: cycle text-to-face gan via transformers
Jun 09, 2022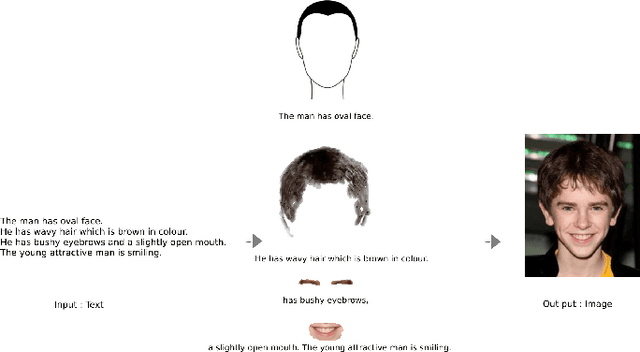

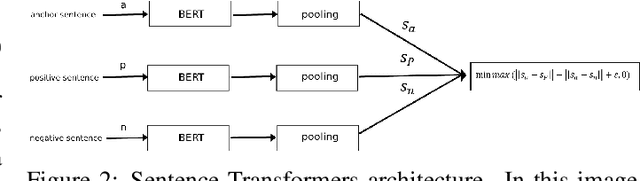

Text-to-face is a subset of text-to-image that require more complex architecture due to their more detailed production. In this paper, we present an encoder-decoder model called Cycle Text2Face. Cycle Text2Face is a new initiative in the encoder part, it uses a sentence transformer and GAN to generate the image described by the text. The Cycle is completed by reproducing the text of the face in the decoder part of the model. Evaluating the model using the CelebA dataset, leads to better results than previous GAN-based models. In measuring the quality of the generate face, in addition to satisfying the human audience, we obtain an FID score of 3.458. This model, with high-speed processing, provides quality face images in the short time.
A Quadratic Time Locally Optimal Algorithm for NP-hard Equal Cardinality Partition Optimization
Sep 16, 2021We study the optimization version of the equal cardinality set partition problem (where the absolute difference between the equal sized partitions' sums are minimized). While this problem is NP-hard and requires exponential complexity to solve in general, we have formulated a weaker version of this NP-hard problem, where the goal is to find a locally optimal solution. The local optimality considered in our work is under any swap between the opposing partitions' element pairs. To this end, we designed an algorithm which can produce such a locally optimal solution in $O(N^2)$ time and $O(N)$ space. Our approach does not require positive or integer inputs and works equally well under arbitrary input precisions. Thus, it is widely applicable in different problem scenarios.
Variational Heteroscedastic Volatility Model
Apr 11, 2022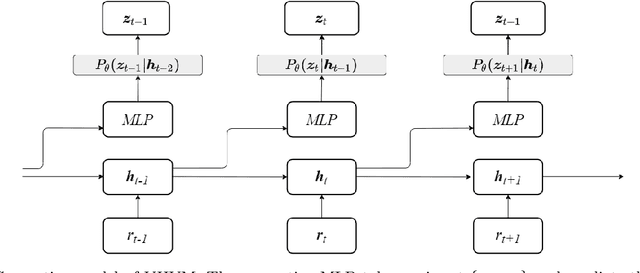

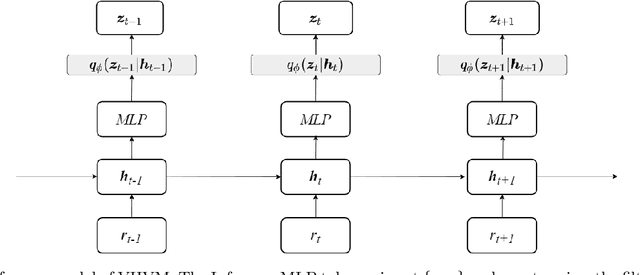

We propose Variational Heteroscedastic Volatility Model (VHVM) -- an end-to-end neural network architecture capable of modelling heteroscedastic behaviour in multivariate financial time series. VHVM leverages recent advances in several areas of deep learning, namely sequential modelling and representation learning, to model complex temporal dynamics between different asset returns. At its core, VHVM consists of a variational autoencoder to capture relationships between assets, and a recurrent neural network to model the time-evolution of these dependencies. The outputs of VHVM are time-varying conditional volatilities in the form of covariance matrices. We demonstrate the effectiveness of VHVM against existing methods such as Generalised AutoRegressive Conditional Heteroscedasticity (GARCH) and Stochastic Volatility (SV) models on a wide range of multivariate foreign currency (FX) datasets.
ENS-10: A Dataset For Post-Processing Ensemble Weather Forecast
Jun 29, 2022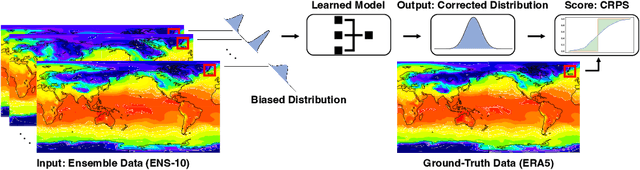
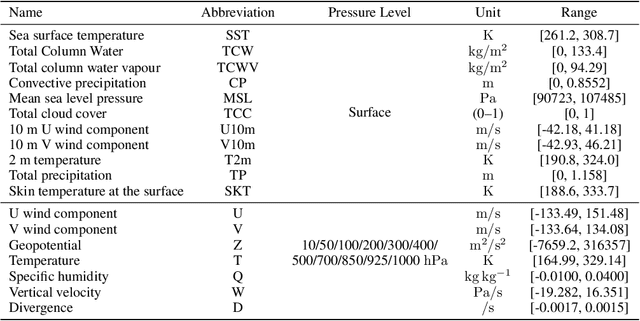
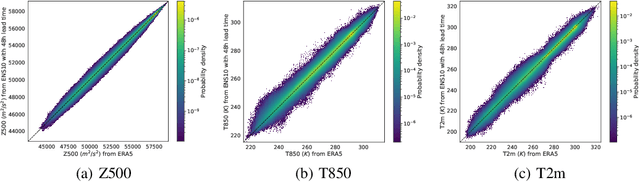
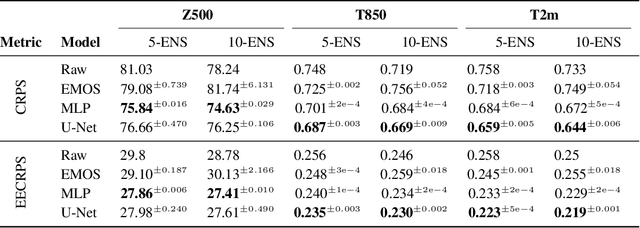
Post-processing ensemble prediction systems can improve weather forecasting, especially for extreme event prediction. In recent years, different machine learning models have been developed to improve the quality of the post-processing step. However, these models heavily rely on the data and generating such ensemble members requires multiple runs of numerical weather prediction models, at high computational cost. This paper introduces the ENS-10 dataset, consisting of ten ensemble members spread over 20 years (1998-2017). The ensemble members are generated by perturbing numerical weather simulations to capture the chaotic behavior of the Earth. To represent the three-dimensional state of the atmosphere, ENS-10 provides the most relevant atmospheric variables in 11 distinct pressure levels as well as the surface at 0.5-degree resolution. The dataset targets the prediction correction task at 48-hour lead time, which is essentially improving the forecast quality by removing the biases of the ensemble members. To this end, ENS-10 provides the weather variables for forecast lead times T=0, 24, and 48 hours (two data points per week). We provide a set of baselines for this task on ENS-10 and compare their performance in correcting the prediction of different weather variables. We also assess our baselines for predicting extreme events using our dataset. The ENS-10 dataset is available under the Creative Commons Attribution 4.0 International (CC BY 4.0) licence.