 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MIX-MAB: Reinforcement Learning-based Resource Allocation Algorithm for LoRaWAN
Jun 07, 2022
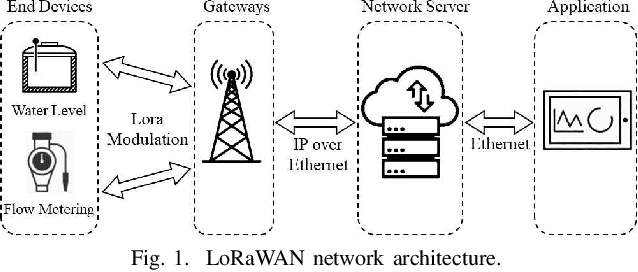
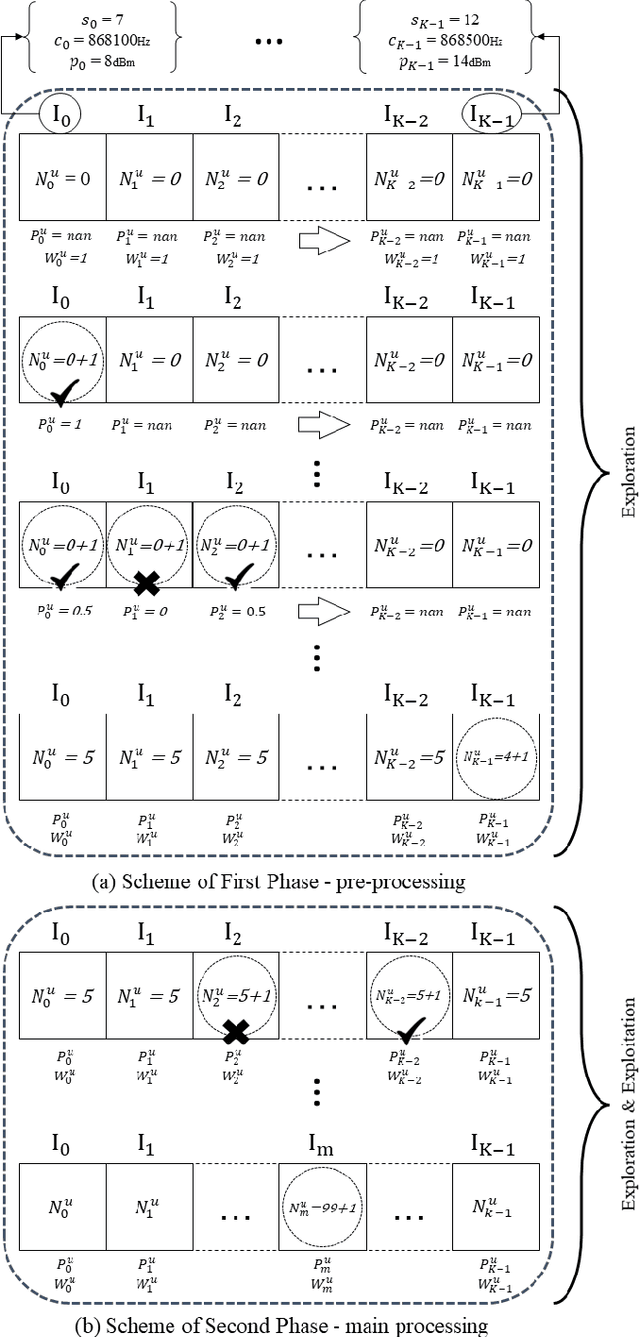
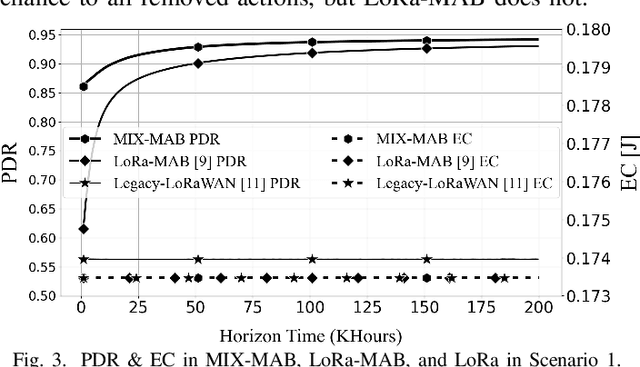
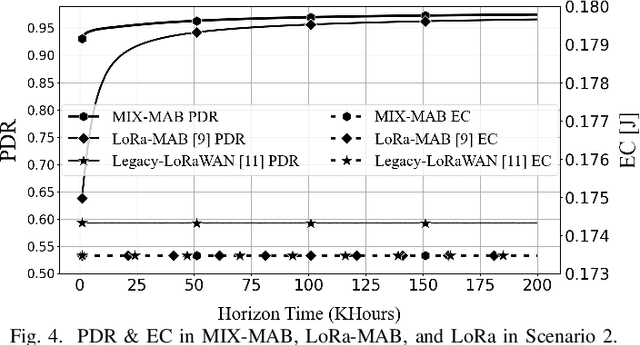
This paper focuses on improving the resource allocation algorithm in terms of packet delivery ratio (PDR), i.e., the number of successfully received packets sent by end devices (EDs) in a long-range wide-area network (LoRaWAN). Setting the transmission parameters significantly affects the PDR. Employing reinforcement learning (RL), we propose a resource allocation algorithm that enables the EDs to configure their transmission parameters in a distributed manner. We model the resource allocation problem as a multi-armed bandit (MAB) and then address it by proposing a two-phase algorithm named MIX-MAB, which consists of the exponential weights for exploration and exploitation (EXP3) and successive elimination (SE) algorithms. We evaluate the MIX-MAB performance through simulation results and compare it with other existing approaches. Numerical results show that the proposed solution performs better than the existing schemes in terms of convergence time and PDR.
Indian Legal Text Summarization: A Text Normalisation-based Approach
Jun 13, 2022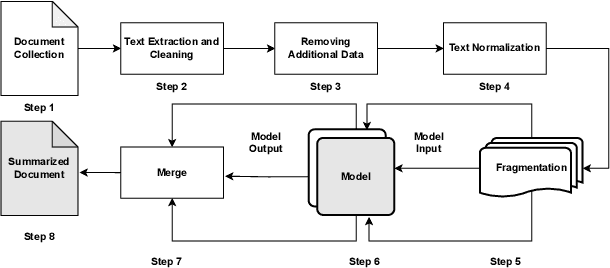
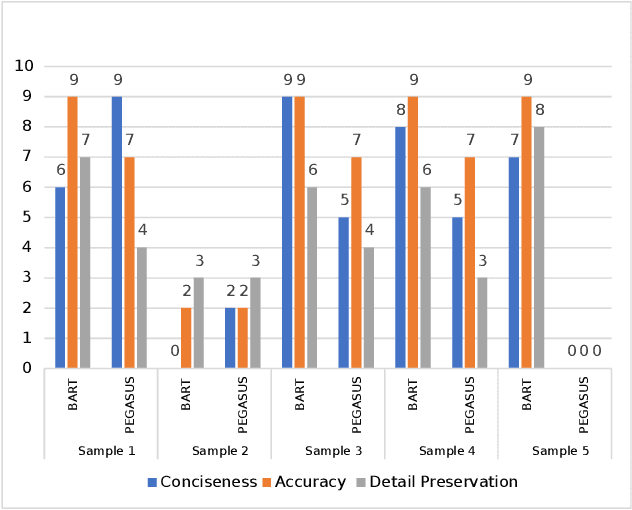
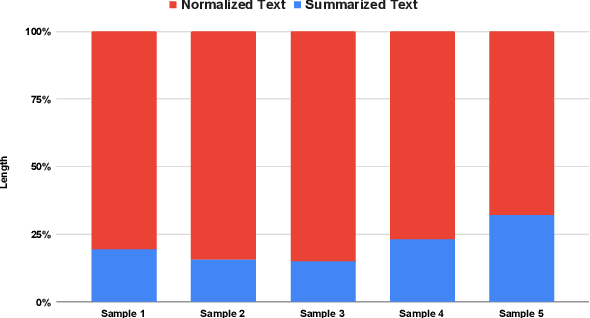

In the Indian court system, pending cases have long been a problem. There are more than 4 crore cases outstanding. Manually summarising hundreds of documents is a time-consuming and tedious task for legal stakeholders. Many state-of-the-art models for text summarization have emerged as machine learning has progressed. Domain-independent models don't do well with legal texts, and fine-tuning those models for the Indian Legal System is problematic due to a lack of publicly available datasets. To improve the performance of domain-independent models, the authors have proposed a methodology for normalising legal texts in the Indian context. The authors experimented with two state-of-the-art domain-independent models for legal text summarization, namely BART and PEGASUS. BART and PEGASUS are put through their paces in terms of extractive and abstractive summarization to understand the effectiveness of the text normalisation approach. Summarised texts are evaluated by domain experts on multiple parameters and using ROUGE metrics. It shows the proposed text normalisation approach is effective in legal texts with domain-independent models.
Convergence for score-based generative modeling with polynomial complexity
Jun 13, 2022Score-based generative modeling (SGM) is a highly successful approach for learning a probability distribution from data and generating further samples. We prove the first polynomial convergence guarantees for the core mechanic behind SGM: drawing samples from a probability density $p$ given a score estimate (an estimate of $\nabla \ln p$) that is accurate in $L^2(p)$. Compared to previous works, we do not incur error that grows exponentially in time or that suffers from a curse of dimensionality. Our guarantee works for any smooth distribution and depends polynomially on its log-Sobolev constant. Using our guarantee, we give a theoretical analysis of score-based generative modeling, which transforms white-noise input into samples from a learned data distribution given score estimates at different noise scales. Our analysis gives theoretical grounding to the observation that an annealed procedure is required in practice to generate good samples, as our proof depends essentially on using annealing to obtain a warm start at each step. Moreover, we show that a predictor-corrector algorithm gives better convergence than using either portion alone.
Square One Bias in NLP: Towards a Multi-Dimensional Exploration of the Research Manifold
Jun 20, 2022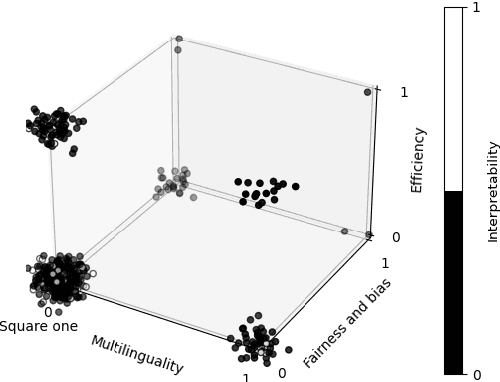
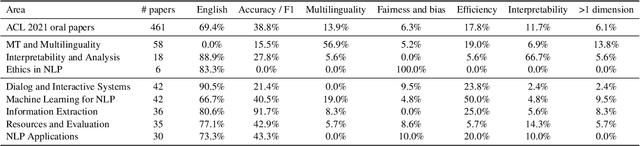
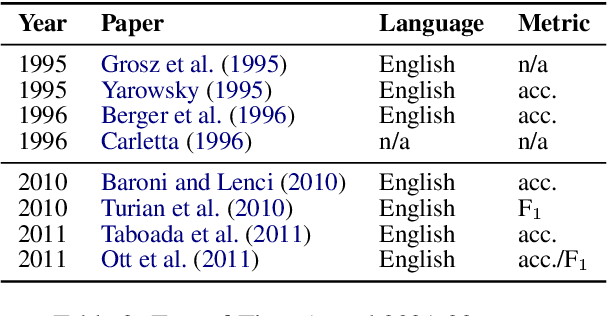

The prototypical NLP experiment trains a standard architecture on labeled English data and optimizes for accuracy, without accounting for other dimensions such as fairness, interpretability, or computational efficiency. We show through a manual classification of recent NLP research papers that this is indeed the case and refer to it as the square one experimental setup. We observe that NLP research often goes beyond the square one setup, e.g, focusing not only on accuracy, but also on fairness or interpretability, but typically only along a single dimension. Most work targeting multilinguality, for example, considers only accuracy; most work on fairness or interpretability considers only English; and so on. We show this through manual classification of recent NLP research papers and ACL Test-of-Time award recipients. Such one-dimensionality of most research means we are only exploring a fraction of the NLP research search space. We provide historical and recent examples of how the square one bias has led researchers to draw false conclusions or make unwise choices, point to promising yet unexplored directions on the research manifold, and make practical recommendations to enable more multi-dimensional research. We open-source the results of our annotations to enable further analysis at https://github.com/google-research/url-nlp
What Makes A Good Fisherman? Linear Regression under Self-Selection Bias
May 06, 2022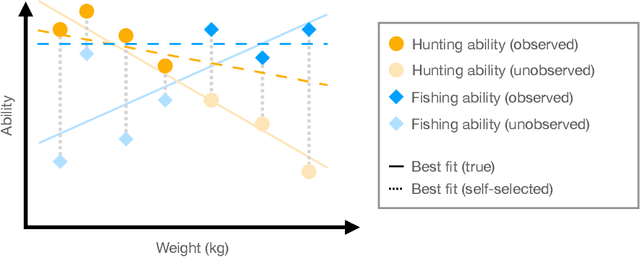
In the classical setting of self-selection, the goal is to learn $k$ models, simultaneously from observations $(x^{(i)}, y^{(i)})$ where $y^{(i)}$ is the output of one of $k$ underlying models on input $x^{(i)}$. In contrast to mixture models, where we observe the output of a randomly selected model, here the observed model depends on the outputs themselves, and is determined by some known selection criterion. For example, we might observe the highest output, the smallest output, or the median output of the $k$ models. In known-index self-selection, the identity of the observed model output is observable; in unknown-index self-selection, it is not. Self-selection has a long history in Econometrics and applications in various theoretical and applied fields, including treatment effect estimation, imitation learning, learning from strategically reported data, and learning from markets at disequilibrium. In this work, we present the first computationally and statistically efficient estimation algorithms for the most standard setting of this problem where the models are linear. In the known-index case, we require poly$(1/\varepsilon, k, d)$ sample and time complexity to estimate all model parameters to accuracy $\varepsilon$ in $d$ dimensions, and can accommodate quite general selection criteria. In the more challenging unknown-index case, even the identifiability of the linear models (from infinitely many samples) was not known. We show three results in this case for the commonly studied $\max$ self-selection criterion: (1) we show that the linear models are indeed identifiable, (2) for general $k$ we provide an algorithm with poly$(d) \exp(\text{poly}(k))$ sample and time complexity to estimate the regression parameters up to error $1/\text{poly}(k)$, and (3) for $k = 2$ we provide an algorithm for any error $\varepsilon$ and poly$(d, 1/\varepsilon)$ sample and time complexity.
Guided Safe Shooting: model based reinforcement learning with safety constraints
Jun 20, 2022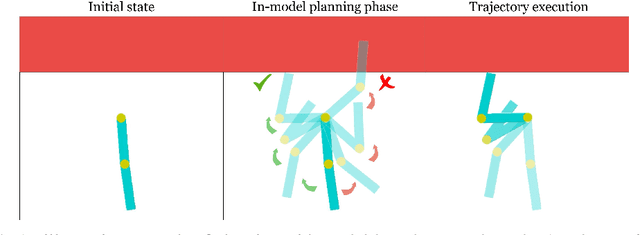
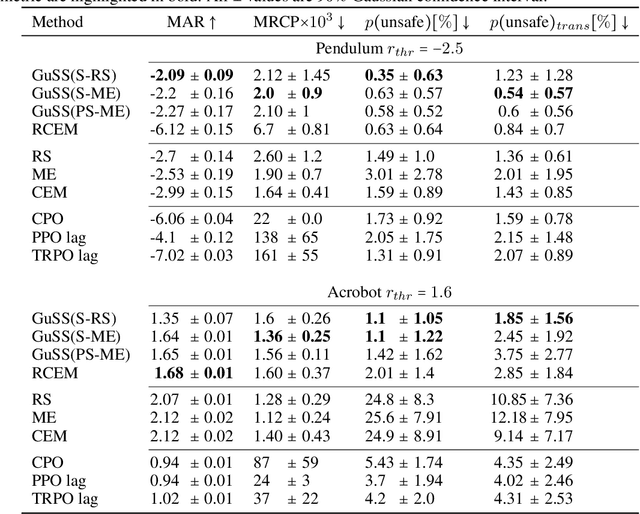
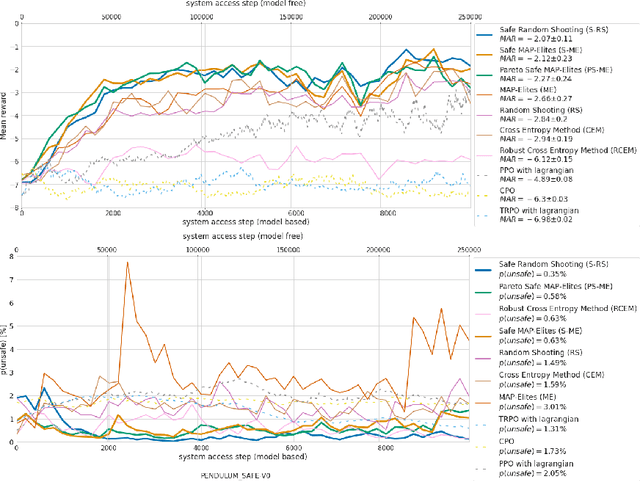
In the last decade, reinforcement learning successfully solved complex control tasks and decision-making problems, like the Go board game. Yet, there are few success stories when it comes to deploying those algorithms to real-world scenarios. One of the reasons is the lack of guarantees when dealing with and avoiding unsafe states, a fundamental requirement in critical control engineering systems. In this paper, we introduce Guided Safe Shooting (GuSS), a model-based RL approach that can learn to control systems with minimal violations of the safety constraints. The model is learned on the data collected during the operation of the system in an iterated batch fashion, and is then used to plan for the best action to perform at each time step. We propose three different safe planners, one based on a simple random shooting strategy and two based on MAP-Elites, a more advanced divergent-search algorithm. Experiments show that these planners help the learning agent avoid unsafe situations while maximally exploring the state space, a necessary aspect when learning an accurate model of the system. Furthermore, compared to model-free approaches, learning a model allows GuSS reducing the number of interactions with the real-system while still reaching high rewards, a fundamental requirement when handling engineering systems.
Depression Diagnosis and Forecast based on Mobile Phone Sensor Data
May 10, 2022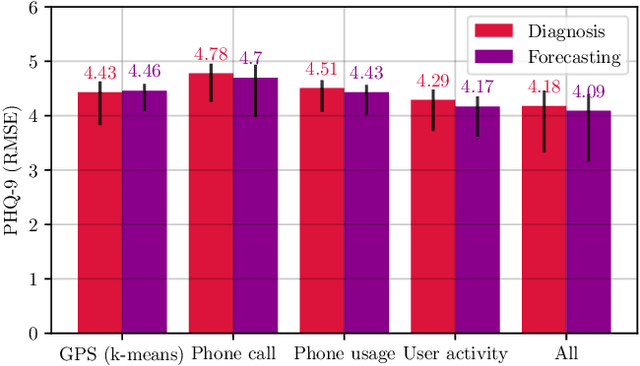
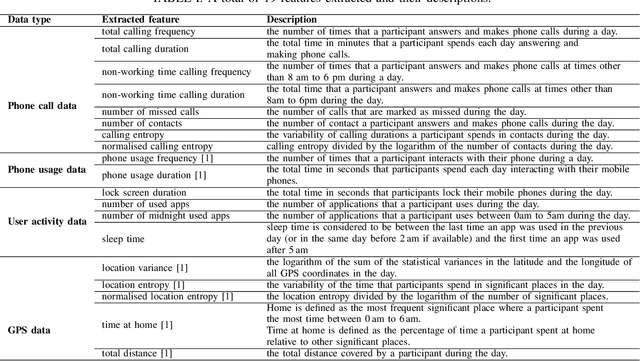

Previous studies have shown the correlation between sensor data collected from mobile phones and human depression states. Compared to the traditional self-assessment questionnaires, the passive data collected from mobile phones is easier to access and less time-consuming. In particular, passive mobile phone data can be collected on a flexible time interval, thus detecting moment-by-moment psychological changes and helping achieve earlier interventions. Moreover, while previous studies mainly focused on depression diagnosis using mobile phone data, depression forecasting has not received sufficient attention. In this work, we extract four types of passive features from mobile phone data, including phone call, phone usage, user activity, and GPS features. We implement a long short-term memory (LSTM) network in a subject-independent 10-fold cross-validation setup to model both a diagnostic and a forecasting tasks. Experimental results show that the forecasting task achieves comparable results with the diagnostic task, which indicates the possibility of forecasting depression from mobile phone sensor data. Our model achieves an accuracy of 77.0 % for major depression forecasting (binary), an accuracy of 53.7 % for depression severity forecasting (5 classes), and a best RMSE score of 4.094 (PHQ-9, range from 0 to 27).
ComENet: Towards Complete and Efficient Message Passing for 3D Molecular Graphs
Jun 17, 2022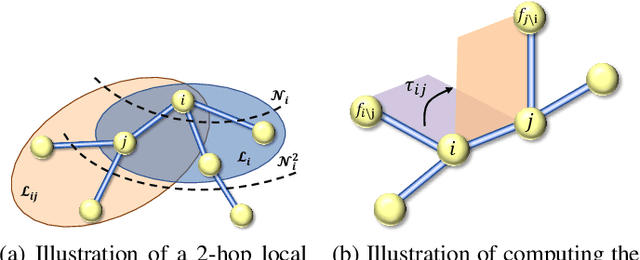

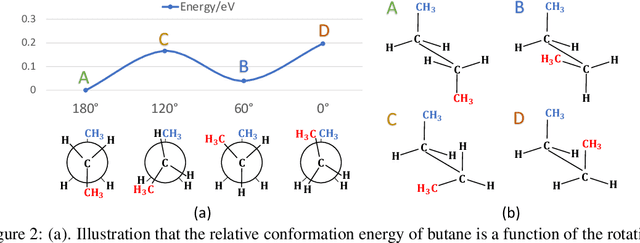

Many real-world data can be modeled as 3D graphs, but learning representations that incorporates 3D information completely and efficiently is challenging. Existing methods either use partial 3D information, or suffer from excessive computational cost. To incorporate 3D information completely and efficiently, we propose a novel message passing scheme that operates within 1-hop neighborhood. Our method guarantees full completeness of 3D information on 3D graphs by achieving global and local completeness. Notably, we propose the important rotation angles to fulfill global completeness. Additionally, we show that our method is orders of magnitude faster than prior methods. We provide rigorous proof of completeness and analysis of time complexity for our methods. As molecules are in essence quantum systems, we build the \underline{com}plete and \underline{e}fficient graph neural network (ComENet) by combing quantum inspired basis functions and the proposed message passing scheme. Experimental results demonstrate the capability and efficiency of ComENet, especially on real-world datasets that are large in both numbers and sizes of graphs. Our code is publicly available as part of the DIG library (\url{https://github.com/divelab/DIG}).
Extraction of instantaneous frequencies and amplitudes in nonstationary time-series data
Apr 03, 2021
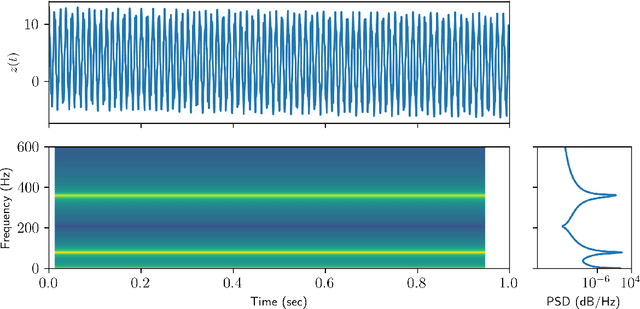
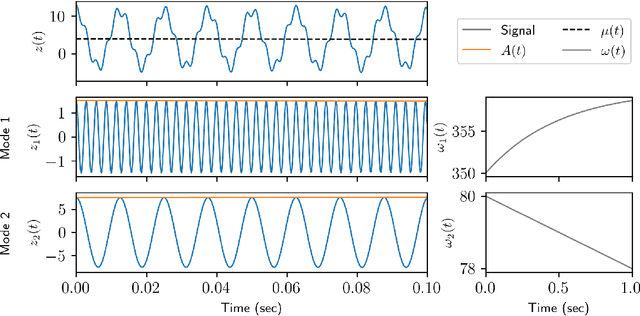
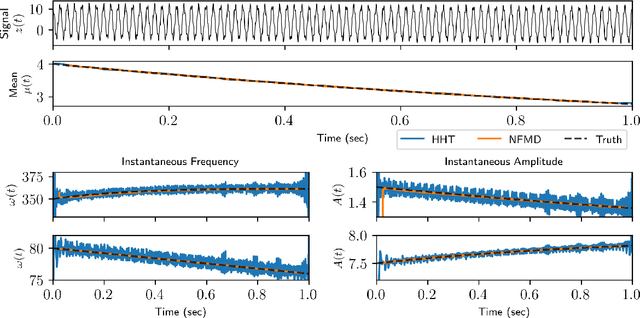
Time-series analysis is critical for a diversity of applications in science and engineering. By leveraging the strengths of modern gradient descent algorithms, the Fourier transform, multi-resolution analysis, and Bayesian spectral analysis, we propose a data-driven approach to time-frequency analysis that circumvents many of the shortcomings of classic approaches, including the extraction of nonstationary signals with discontinuities in their behavior. The method introduced is equivalent to a {\em nonstationary Fourier mode decomposition} (NFMD) for nonstationary and nonlinear temporal signals, allowing for the accurate identification of instantaneous frequencies and their amplitudes. The method is demonstrated on a diversity of time-series data, including on data from cantilever-based electrostatic force microscopy to quantify the time-dependent evolution of charging dynamics at the nanoscale.
S2RL: Do We Really Need to Perceive All States in Deep Multi-Agent Reinforcement Learning?
Jun 20, 2022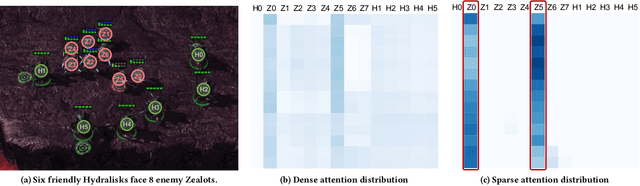
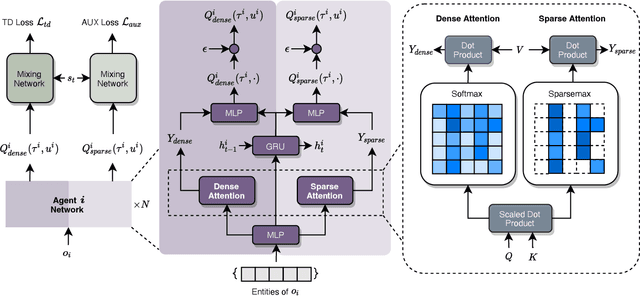
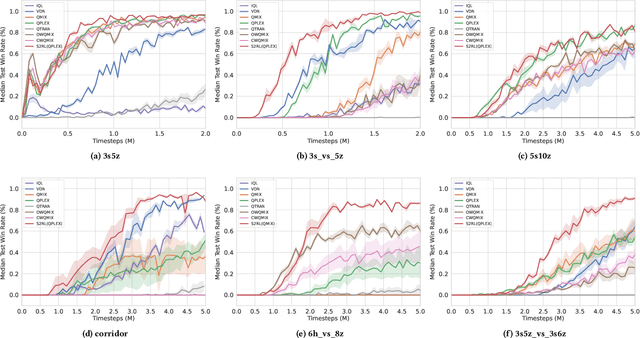
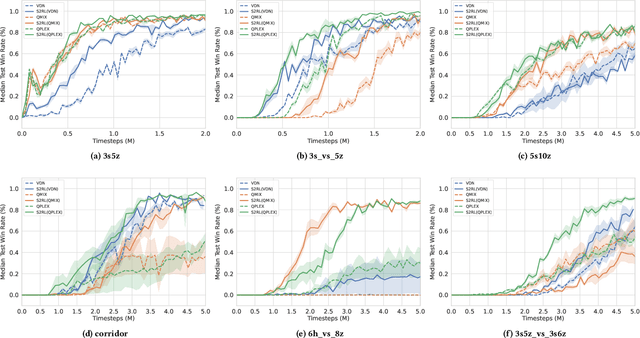
Collaborative multi-agent reinforcement learning (MARL) has been widely used in many practical applications, where each agent makes a decision based on its own observation. Most mainstream methods treat each local observation as an entirety when modeling the decentralized local utility functions. However, they ignore the fact that local observation information can be further divided into several entities, and only part of the entities is helpful to model inference. Moreover, the importance of different entities may change over time. To improve the performance of decentralized policies, the attention mechanism is used to capture features of local information. Nevertheless, existing attention models rely on dense fully connected graphs and cannot better perceive important states. To this end, we propose a sparse state based MARL (S2RL) framework, which utilizes a sparse attention mechanism to discard irrelevant information in local observations. The local utility functions are estimated through the self-attention and sparse attention mechanisms separately, then are combined into a standard joint value function and auxiliary joint value function in the central critic. We design the S2RL framework as a plug-and-play module, making it general enough to be applied to various methods. Extensive experiments on StarCraft II show that S2RL can significantly improve the performance of many state-of-the-art methods.