 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GP-ConvCNP: Better Generalization for Convolutional Conditional Neural Processes on Time Series Data
Jun 09, 2021
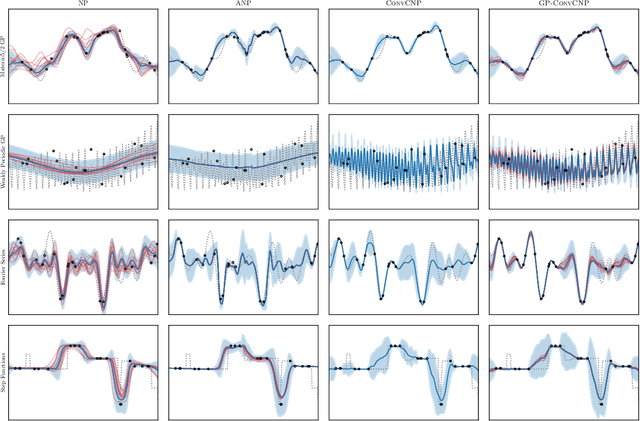
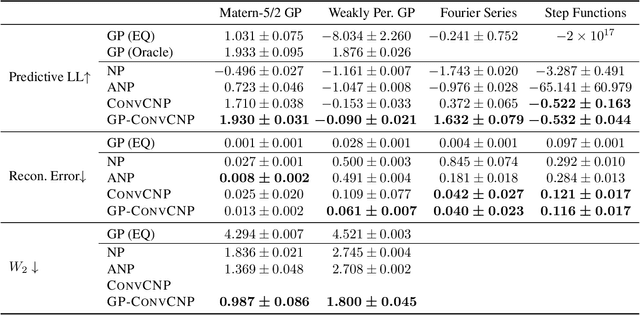
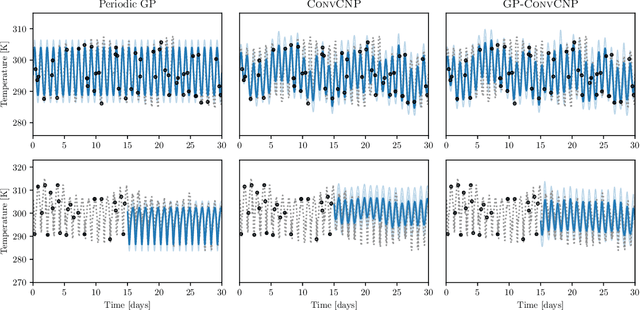
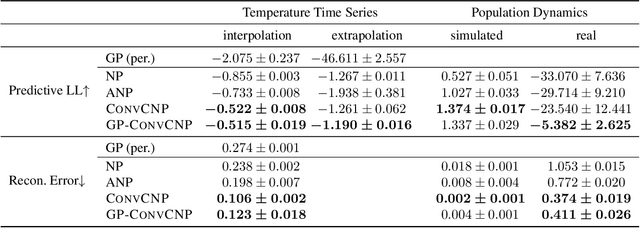
Neural Processes (NPs) are a family of conditional generative models that are able to model a distribution over functions, in a way that allows them to perform predictions at test time conditioned on a number of context points. A recent addition to this family, Convolutional Conditional Neural Processes (ConvCNP), have shown remarkable improvement in performance over prior art, but we find that they sometimes struggle to generalize when applied to time series data. In particular, they are not robust to distribution shifts and fail to extrapolate observed patterns into the future. By incorporating a Gaussian Process into the model, we are able to remedy this and at the same time improve performance within distribution. As an added benefit, the Gaussian Process reintroduces the possibility to sample from the model, a key feature of other members in the NP family.
Fundamentals of Wobbling and Hardware Impairments-Aware Air-to-Ground Channel Model
May 22, 2022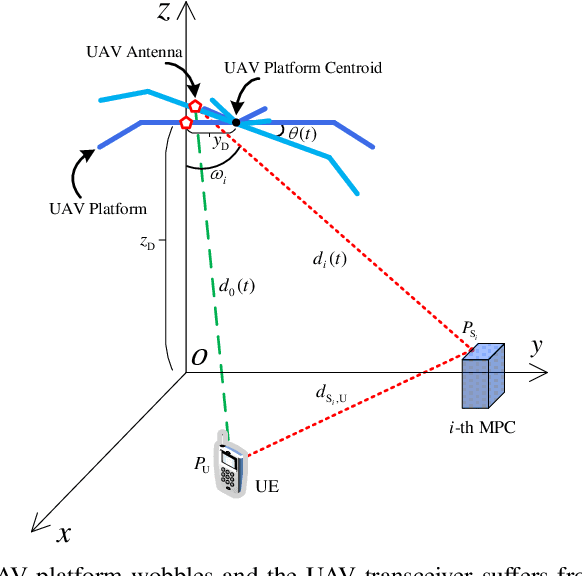
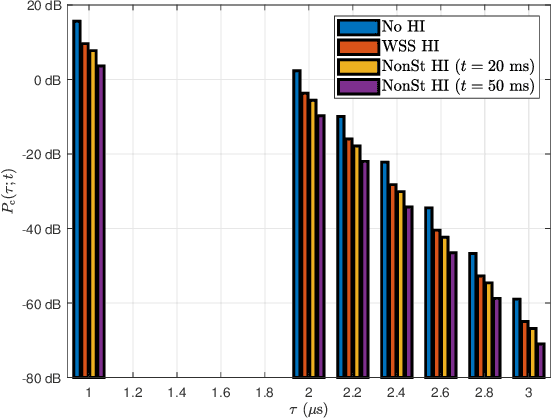
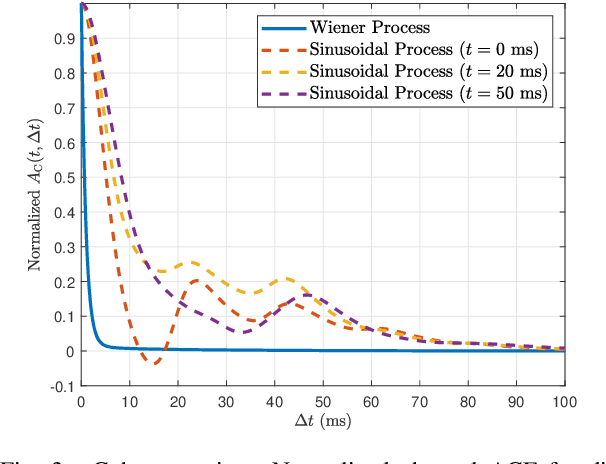
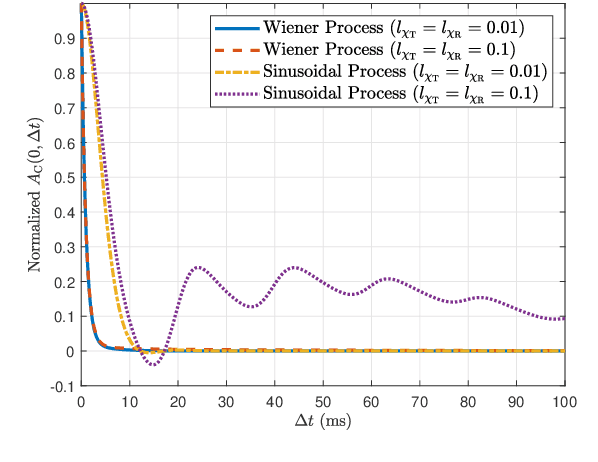
In this paper, we develop an impairments-aware air-to-ground unified channel model that incorporates the effect of both wobbling and hardware impairments, where the former is caused by random physical fluctuations of unmanned aerial vehicles (UAVs), and the latter by intrinsic radio frequency (RF) nonidealities at both the transmitter and receiver, such as phase noise, in-phase/quadrature (I/Q) imbalance, and power amplifier (PA) nonlinearity. The impact of UAV wobbling is modeled by two stochastic processes, i.e., the canonical Wiener process and the more realistic sinusoidal process. On the other hand, the aggregate impact of all hardware impairments is modeled as two multiplicative and additive distortion noise processes, which is a well-accepted model. For the sake of generality, we consider both wide-sense stationary (WSS) and nonstationary processes for the distortion noises. We then rigorously characterize the autocorrelation function (ACF) of the wireless channel, using which we provide a comprehensive analysis of four key channel-related metrics: (i) power delay profile (PDP), (ii) coherence time, (iii) coherence bandwidth, and (iv) power spectral density (PSD) of the distortion-plus-noise process. Furthermore, we evaluate these metrics with reasonable UAV wobbling and hardware impairment models to obtain useful insights. Quite noticeably, we demonstrate that even for small UAV wobbling, the coherence time severely degrades at high frequencies, which renders air-to-ground channel estimation very difficult at these frequencies. To the best of our understanding, this is the first work that characterizes the joint impact of UAV wobbling and hardware impairments on the air-to-ground wireless channel.
Nonlinear Hawkes Processes in Time-Varying System
Jun 09, 2021
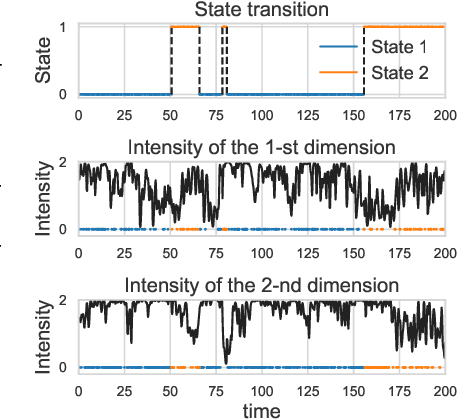
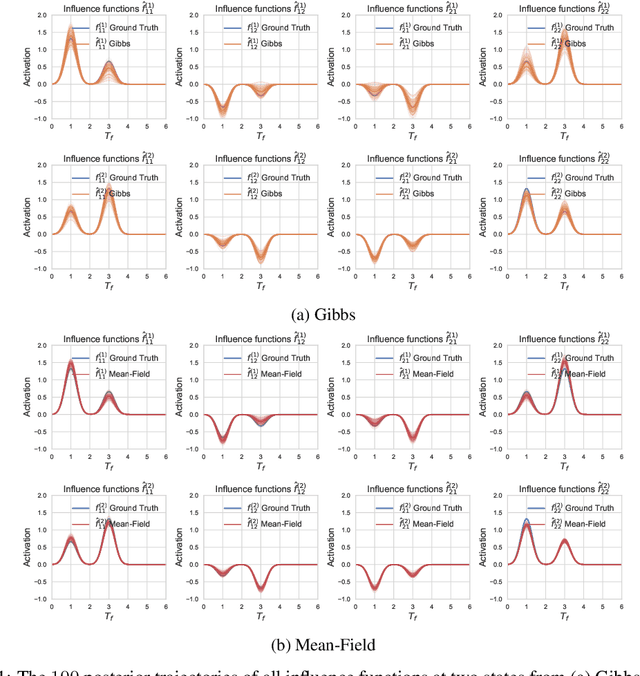
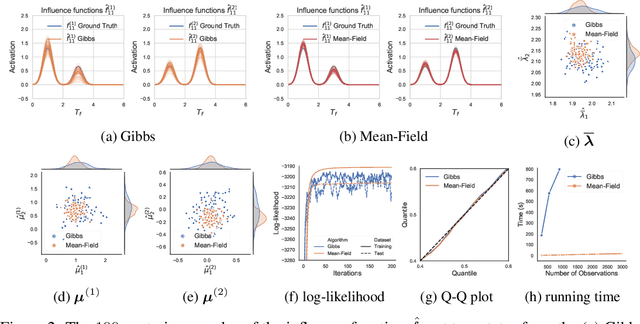
Hawkes processes are a class of point processes that have the ability to model the self- and mutual-exciting phenomena. Although the classic Hawkes processes cover a wide range of applications, their expressive ability is limited due to three key hypotheses: parametric, linear and homogeneous. Recent work has attempted to address these limitations separately. This work aims to overcome all three assumptions simultaneously by proposing the flexible state-switching Hawkes processes: a flexible, nonlinear and nonhomogeneous variant where a state process is incorporated to interact with the point processes. The proposed model empowers Hawkes processes to be applied to time-varying systems. For inference, we utilize the latent variable augmentation technique to design two efficient Bayesian inference algorithms: Gibbs sampler and mean-field variational inference, with analytical iterative updates to estimate the posterior. In experiments, our model achieves superior performance compared to the state-of-the-art competitors.
Predicting Human Performance in Vertical Hierarchical Menu Selection in Immersive AR Using Hand-gesture and Head-gaze
Jun 19, 2022
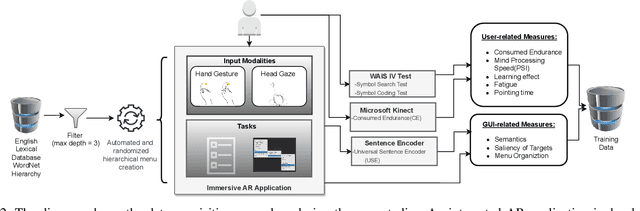

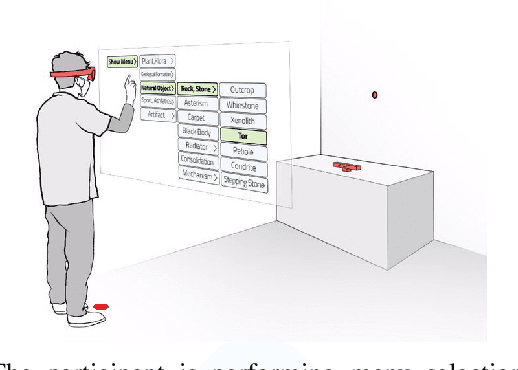
There are currently limited guidelines on designing user interfaces (UI) for immersive augmented reality (AR) applications. Designers must reflect on their experience designing UI for desktop and mobile applications and conjecture how a UI will influence AR users' performance. In this work, we introduce a predictive model for determining users' performance for a target UI without the subsequent involvement of participants in user studies. The model is trained on participants' responses to objective performance measures such as consumed endurance (CE) and pointing time (PT) using hierarchical drop-down menus. Large variability in the depth and context of the menus is ensured by randomly and dynamically creating the hierarchical drop-down menus and associated user tasks from words contained in the lexical database WordNet. Subjective performance bias is reduced by incorporating the users' non-verbal standard performance WAIS-IV during the model training. The semantic information of the menu is encoded using the Universal Sentence Encoder. We present the results of a user study that demonstrates that the proposed predictive model achieves high accuracy in predicting the CE on hierarchical menus of users with various cognitive abilities. To the best of our knowledge, this is the first work on predicting CE in designing UI for immersive AR applications.
StudioGAN: A Taxonomy and Benchmark of GANs for Image Synthesis
Jun 19, 2022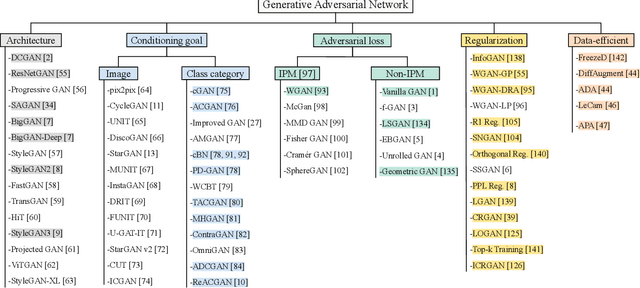
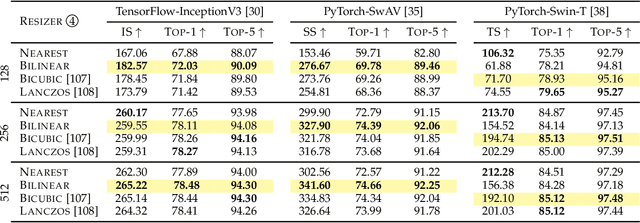
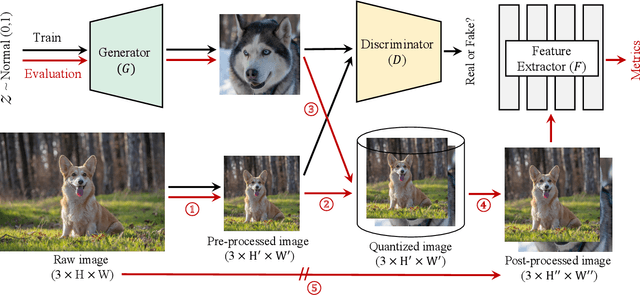
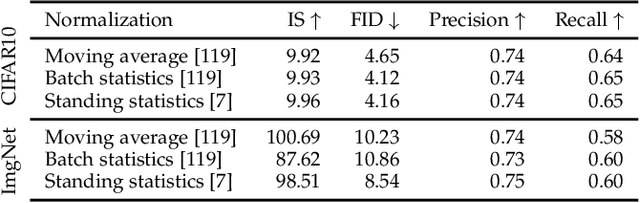
Generative Adversarial Network (GAN) is one of the state-of-the-art generative models for realistic image synthesis. While training and evaluating GAN becomes increasingly important, the current GAN research ecosystem does not provide reliable benchmarks for which the evaluation is conducted consistently and fairly. Furthermore, because there are few validated GAN implementations, researchers devote considerable time to reproducing baselines. We study the taxonomy of GAN approaches and present a new open-source library named StudioGAN. StudioGAN supports 7 GAN architectures, 9 conditioning methods, 4 adversarial losses, 13 regularization modules, 3 differentiable augmentations, 7 evaluation metrics, and 5 evaluation backbones. With our training and evaluation protocol, we present a large-scale benchmark using various datasets (CIFAR10, ImageNet, AFHQv2, FFHQ, and Baby/Papa/Granpa-ImageNet) and 3 different evaluation backbones (InceptionV3, SwAV, and Swin Transformer). Unlike other benchmarks used in the GAN community, we train representative GANs, including BigGAN, StyleGAN2, and StyleGAN3, in a unified training pipeline and quantify generation performance with 7 evaluation metrics. The benchmark evaluates other cutting-edge generative models(e.g., StyleGAN-XL, ADM, MaskGIT, and RQ-Transformer). StudioGAN provides GAN implementations, training, and evaluation scripts with the pre-trained weights. StudioGAN is available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.
Multiscale Sensor Fusion and Continuous Control with Neural CDEs
Mar 16, 2022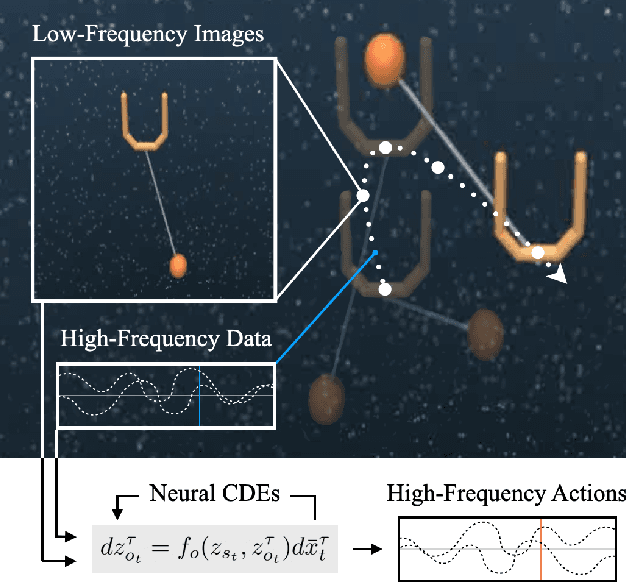
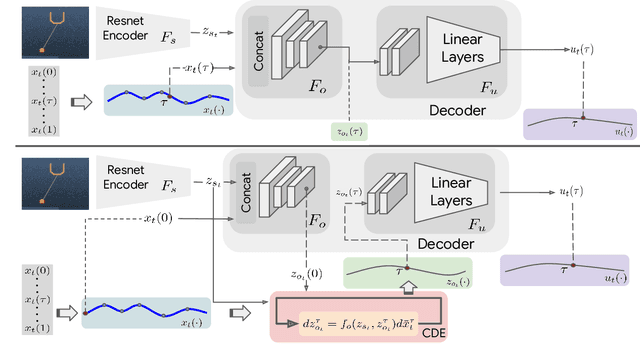
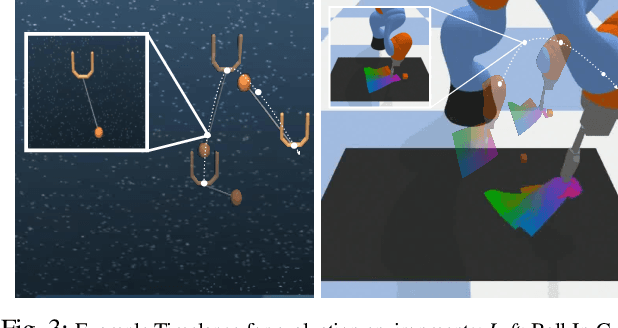
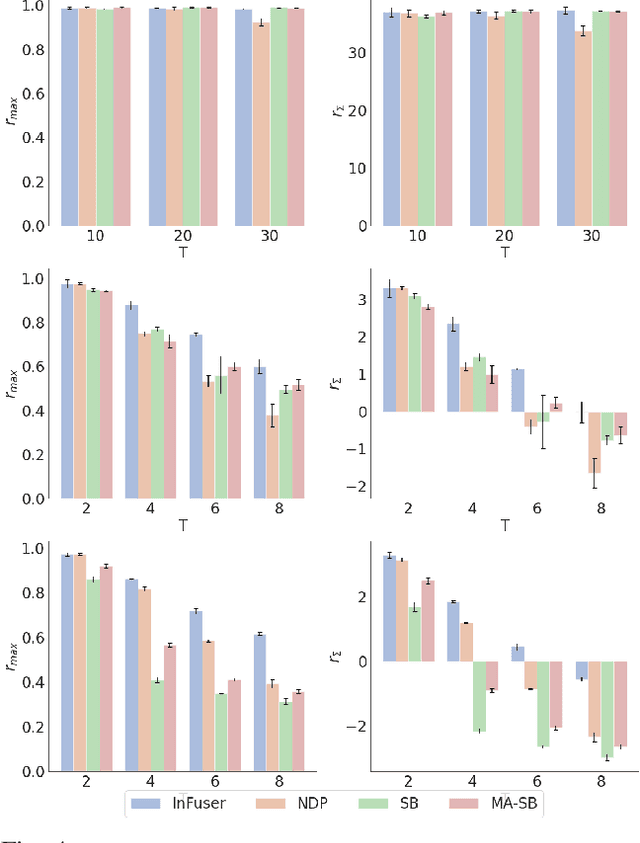
Though robot learning is often formulated in terms of discrete-time Markov decision processes (MDPs), physical robots require near-continuous multiscale feedback control. Machines operate on multiple asynchronous sensing modalities, each with different frequencies, e.g., video frames at 30Hz, proprioceptive state at 100Hz, force-torque data at 500Hz, etc. While the classic approach is to batch observations into fixed-time windows then pass them through feed-forward encoders (e.g., with deep networks), we show that there exists a more elegant approach -- one that treats policy learning as modeling latent state dynamics in continuous-time. Specifically, we present 'InFuser', a unified architecture that trains continuous time-policies with Neural Controlled Differential Equations (CDEs). InFuser evolves a single latent state representation over time by (In)tegrating and (Fus)ing multi-sensory observations (arriving at different frequencies), and inferring actions in continuous-time. This enables policies that can react to multi-frequency multi sensory feedback for truly end-to-end visuomotor control, without discrete-time assumptions. Behavior cloning experiments demonstrate that InFuser learns robust policies for dynamic tasks (e.g., swinging a ball into a cup) notably outperforming several baselines in settings where observations from one sensing modality can arrive at much sparser intervals than others.
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
Jun 30, 2022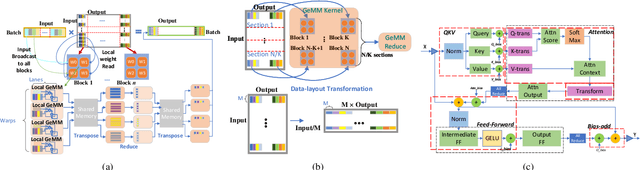
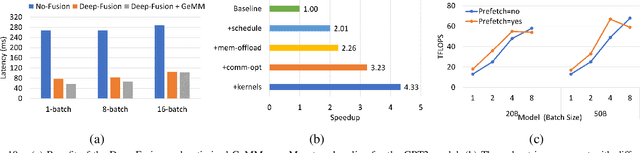
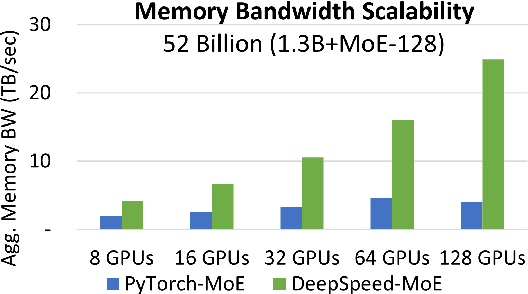
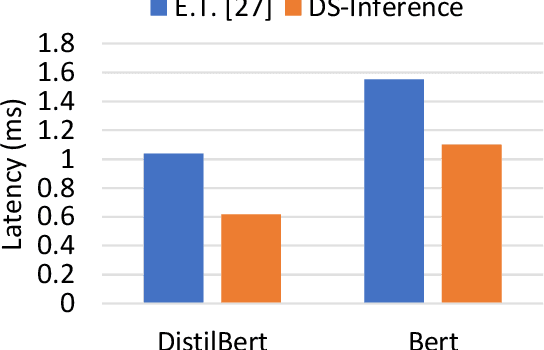
The past several years have witnessed the success of transformer-based models, and their scale and application scenarios continue to grow aggressively. The current landscape of transformer models is increasingly diverse: the model size varies drastically with the largest being of hundred-billion parameters; the model characteristics differ due to the sparsity introduced by the Mixture-of-Experts; the target application scenarios can be latency-critical or throughput-oriented; the deployment hardware could be single- or multi-GPU systems with different types of memory and storage, etc. With such increasing diversity and the fast-evolving pace of transformer models, designing a highly performant and efficient inference system is extremely challenging. In this paper, we present DeepSpeed Inference, a comprehensive system solution for transformer model inference to address the above-mentioned challenges. DeepSpeed Inference consists of (1) a multi-GPU inference solution to minimize latency while maximizing the throughput of both dense and sparse transformer models when they fit in aggregate GPU memory, and (2) a heterogeneous inference solution that leverages CPU and NVMe memory in addition to the GPU memory and compute to enable high inference throughput with large models which do not fit in aggregate GPU memory. DeepSpeed Inference reduces latency by up to 7.3X over the state-of-the-art for latency-oriented scenarios and increases throughput by over 1.5x for throughput-oriented scenarios. Moreover, it enables trillion parameter scale inference under real-time latency constraints by leveraging hundreds of GPUs, an unprecedented scale for inference. It can inference 25x larger models than with GPU-only solutions, while delivering a high throughput of 84 TFLOPS (over $50\%$ of A6000 peak).
Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline
Jun 16, 2022
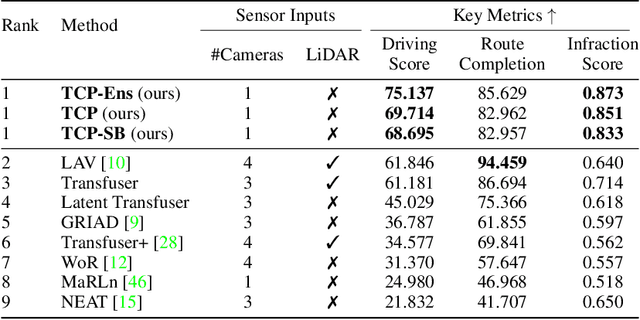
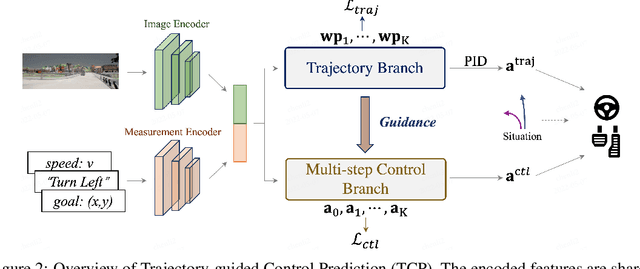

Current end-to-end autonomous driving methods either run a controller based on a planned trajectory or perform control prediction directly, which have spanned two separately studied lines of research. Seeing their potential mutual benefits to each other, this paper takes the initiative to explore the combination of these two well-developed worlds. Specifically, our integrated approach has two branches for trajectory planning and direct control, respectively. The trajectory branch predicts the future trajectory, while the control branch involves a novel multi-step prediction scheme such that the relationship between current actions and future states can be reasoned. The two branches are connected so that the control branch receives corresponding guidance from the trajectory branch at each time step. The outputs from two branches are then fused to achieve complementary advantages. Our results are evaluated in the closed-loop urban driving setting with challenging scenarios using the CARLA simulator. Even with a monocular camera input, the proposed approach ranks $first$ on the official CARLA Leaderboard, outperforming other complex candidates with multiple sensors or fusion mechanisms by a large margin. The source code and data will be made publicly available at https://github.com/OpenPerceptionX/TCP.
Real-Time Volumetric-Semantic Exploration and Mapping: An Uncertainty-Aware Approach
Sep 03, 2021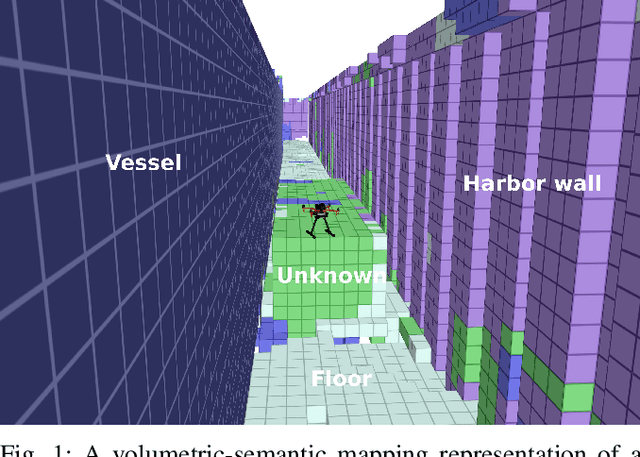
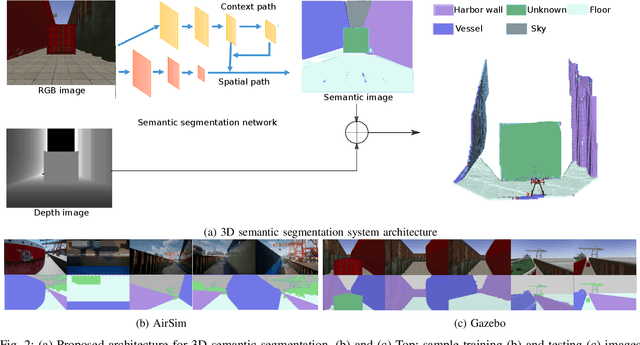
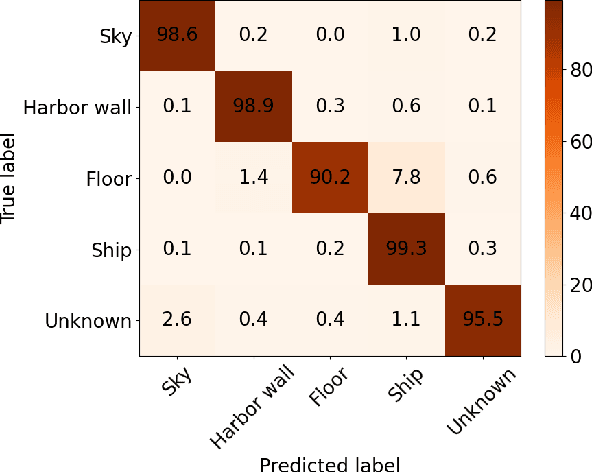

In this work we propose a holistic framework for autonomous aerial inspection tasks, using semantically-aware, yet, computationally efficient planning and mapping algorithms. The system leverages state-of-the-art receding horizon exploration techniques for next-best-view (NBV) planning with geometric and semantic segmentation information provided by state-of-the-art deep convolutional neural networks (DCNNs), with the goal of enriching environment representations. The contributions of this article are threefold, first we propose an efficient sensor observation model, and a reward function that encodes the expected information gains from the observations taken from specific view points. Second, we extend the reward function to incorporate not only geometric but also semantic probabilistic information, provided by a DCNN for semantic segmentation that operates in real-time. The incorporation of semantic information in the environment representation allows biasing exploration towards specific objects, while ignoring task-irrelevant ones during planning. Finally, we employ our approaches in an autonomous drone shipyard inspection task. A set of simulations in realistic scenarios demonstrate the efficacy and efficiency of the proposed framework when compared with the state-of-the-art.
Sparse Compressed Spiking Neural Network Accelerator for Object Detection
May 02, 2022
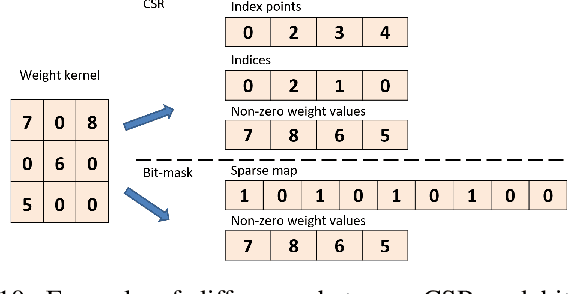
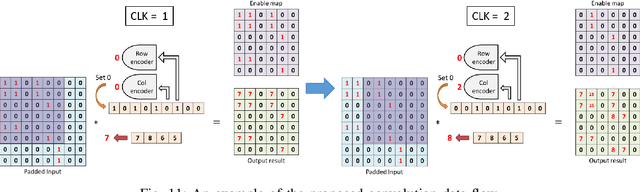
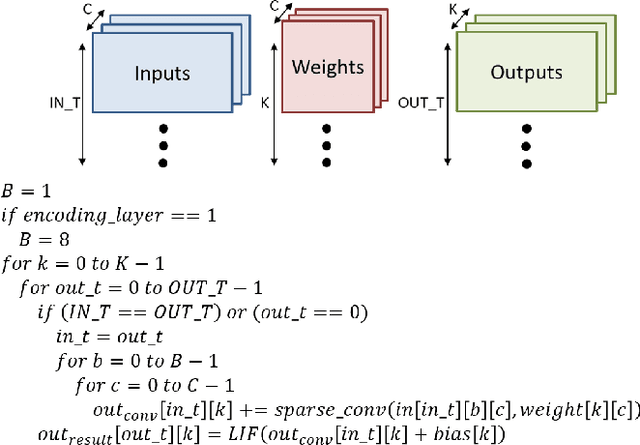
Spiking neural networks (SNNs), which are inspired by the human brain, have recently gained popularity due to their relatively simple and low-power hardware for transmitting binary spikes and highly sparse activation maps. However, because SNNs contain extra time dimension information, the SNN accelerator will require more buffers and take longer to infer, especially for the more difficult high-resolution object detection task. As a result, this paper proposes a sparse compressed spiking neural network accelerator that takes advantage of the high sparsity of activation maps and weights by utilizing the proposed gated one-to-all product for low power and highly parallel model execution. The experimental result of the neural network shows 71.5$\%$ mAP with mixed (1,3) time steps on the IVS 3cls dataset. The accelerator with the TSMC 28nm CMOS process can achieve 1024$\times$576@29 frames per second processing when running at 500MHz with 35.88TOPS/W energy efficiency and 1.05mJ energy consumption per frame.