 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Near-Exact Recovery for Tomographic Inverse Problems via Deep Learning
Jun 14, 2022
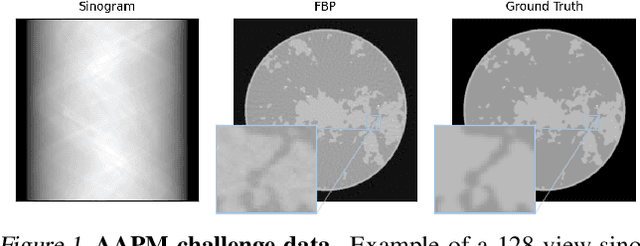
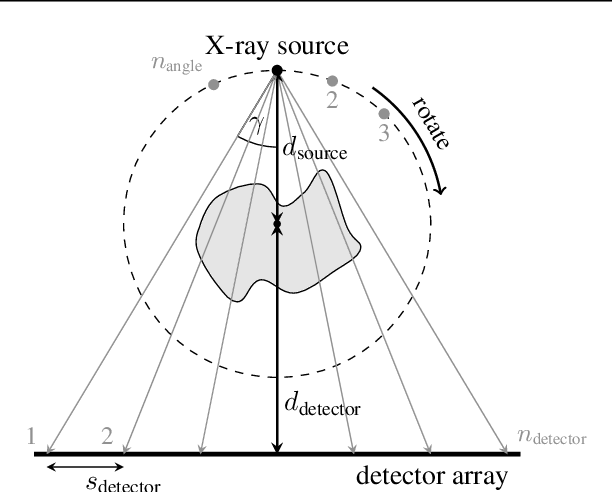
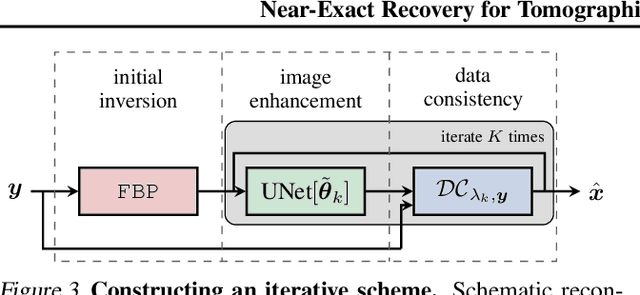

This work is concerned with the following fundamental question in scientific machine learning: Can deep-learning-based methods solve noise-free inverse problems to near-perfect accuracy? Positive evidence is provided for the first time, focusing on a prototypical computed tomography (CT) setup. We demonstrate that an iterative end-to-end network scheme enables reconstructions close to numerical precision, comparable to classical compressed sensing strategies. Our results build on our winning submission to the recent AAPM DL-Sparse-View CT Challenge. Its goal was to identify the state-of-the-art in solving the sparse-view CT inverse problem with data-driven techniques. A specific difficulty of the challenge setup was that the precise forward model remained unknown to the participants. Therefore, a key feature of our approach was to initially estimate the unknown fanbeam geometry in a data-driven calibration step. Apart from an in-depth analysis of our methodology, we also demonstrate its state-of-the-art performance on the open-access real-world dataset LoDoPaB CT.
Mean Embeddings with Test-Time Data Augmentation for Ensembling of Representations
Jun 15, 2021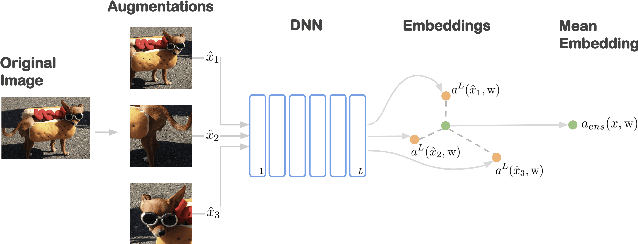
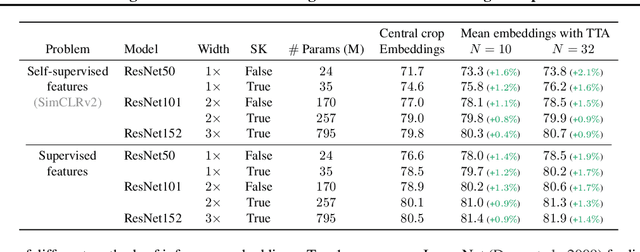
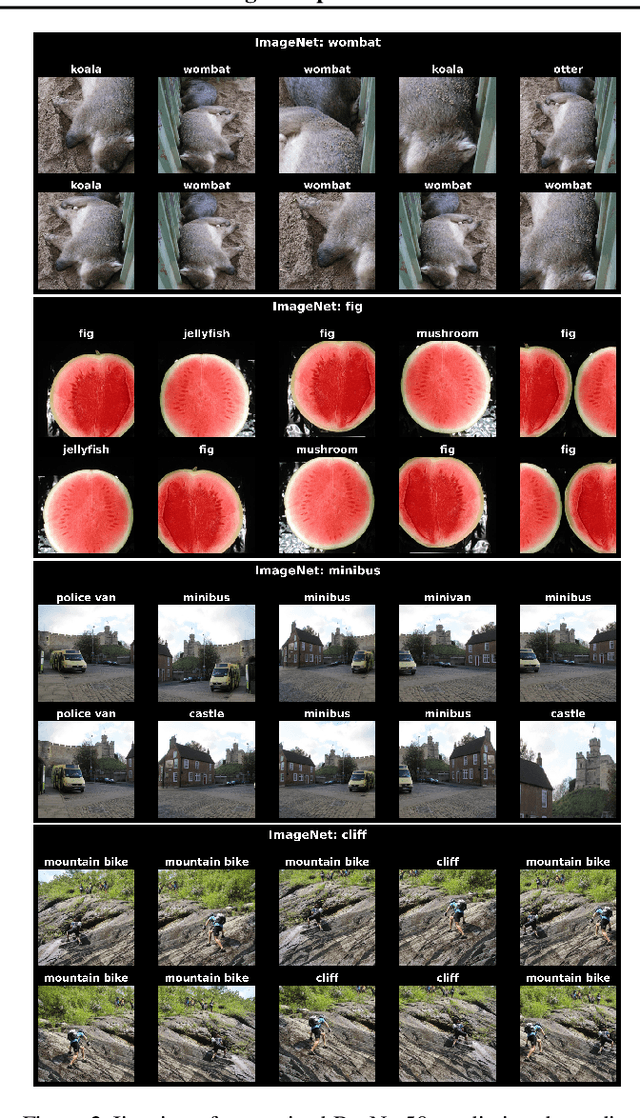
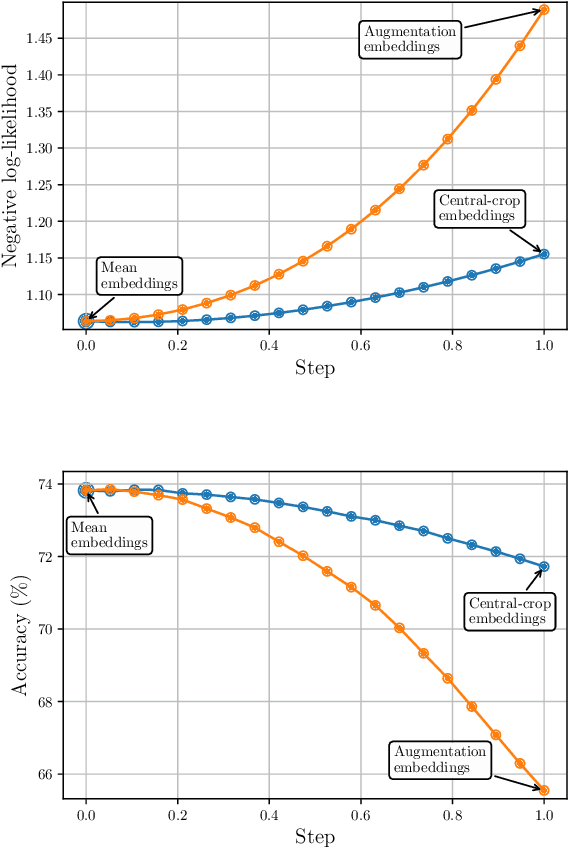
Averaging predictions over a set of models -- an ensemble -- is widely used to improve predictive performance and uncertainty estimation of deep learning models. At the same time, many machine learning systems, such as search, matching, and recommendation systems, heavily rely on embeddings. Unfortunately, due to misalignment of features of independently trained models, embeddings, cannot be improved with a naive deep ensemble like approach. In this work, we look at the ensembling of representations and propose mean embeddings with test-time augmentation (MeTTA) simple yet well-performing recipe for ensembling representations. Empirically we demonstrate that MeTTA significantly boosts the quality of linear evaluation on ImageNet for both supervised and self-supervised models. Even more exciting, we draw connections between MeTTA, image retrieval, and transformation invariant models. We believe that spreading the success of ensembles to inference higher-quality representations is the important step that will open many new applications of ensembling.
Zero Day Threat Detection Using Graph and Flow Based Security Telemetry
May 04, 2022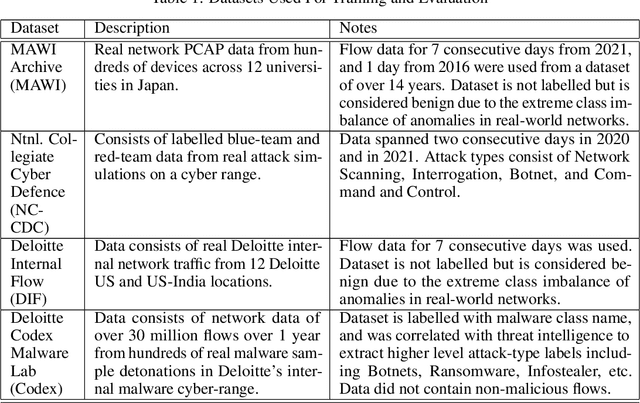
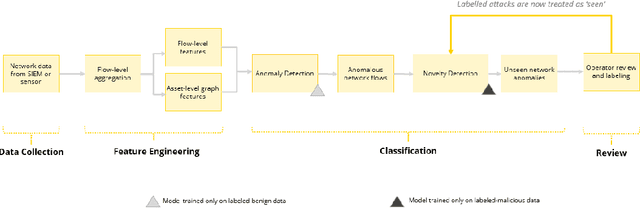
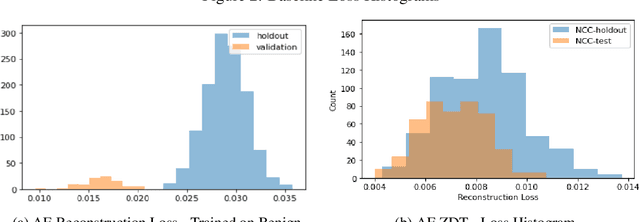

Zero Day Threats (ZDT) are novel methods used by malicious actors to attack and exploit information technology (IT) networks or infrastructure. In the past few years, the number of these threats has been increasing at an alarming rate and have been costing organizations millions of dollars to remediate. The increasing expansion of network attack surfaces and the exponentially growing number of assets on these networks necessitate the need for a robust AI-based Zero Day Threat detection model that can quickly analyze petabyte-scale data for potentially malicious and novel activity. In this paper, the authors introduce a deep learning based approach to Zero Day Threat detection that can generalize, scale, and effectively identify threats in near real-time. The methodology utilizes network flow telemetry augmented with asset-level graph features, which are passed through a dual-autoencoder structure for anomaly and novelty detection respectively. The models have been trained and tested on four large scale datasets that are representative of real-world organizational networks and they produce strong results with high precision and recall values. The models provide a novel methodology to detect complex threats with low false-positive rates that allow security operators to avoid alert fatigue while drastically reducing their mean time to response with near-real-time detection. Furthermore, the authors also provide a novel, labelled, cyber attack dataset generated from adversarial activity that can be used for validation or training of other models. With this paper, the authors' overarching goal is to provide a novel architecture and training methodology for cyber anomaly detectors that can generalize to multiple IT networks with minimal to no retraining while still maintaining strong performance.
Multi-Agent Deep Reinforcement Learning for Cost- and Delay-Sensitive Virtual Network Function Placement and Routing
Jun 24, 2022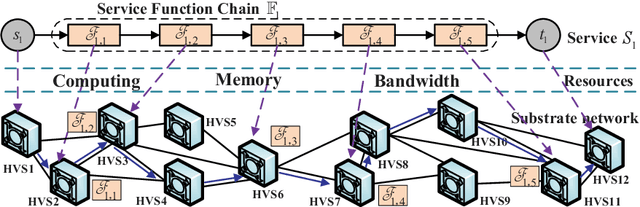
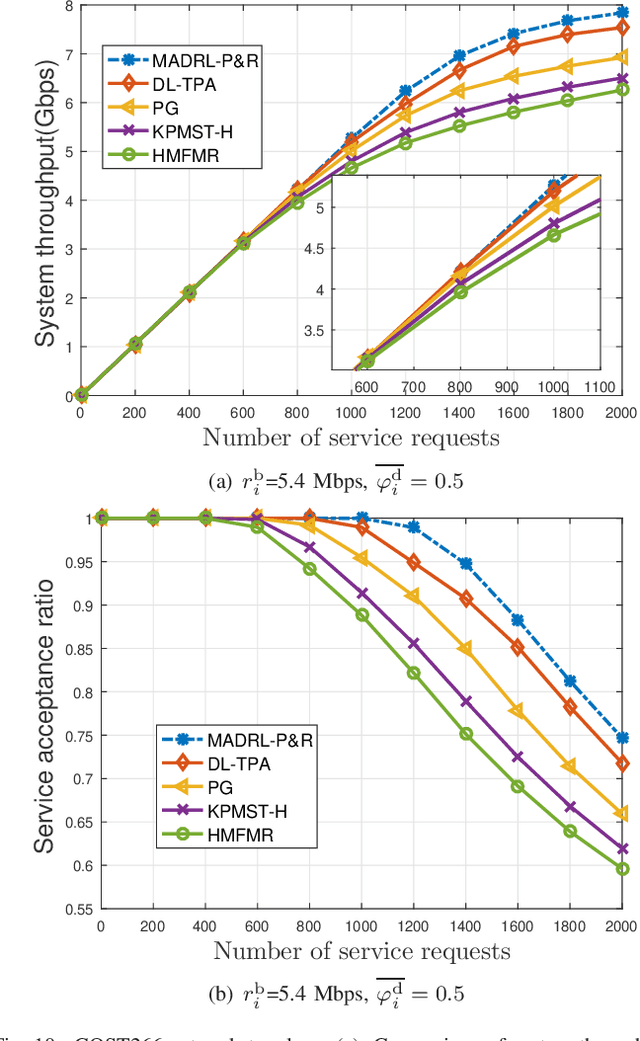
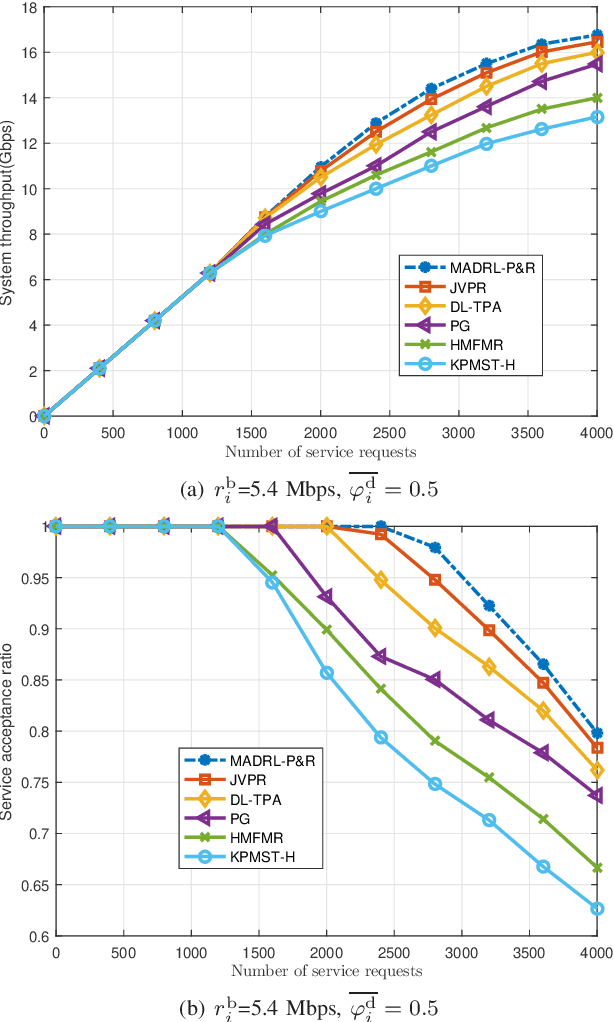
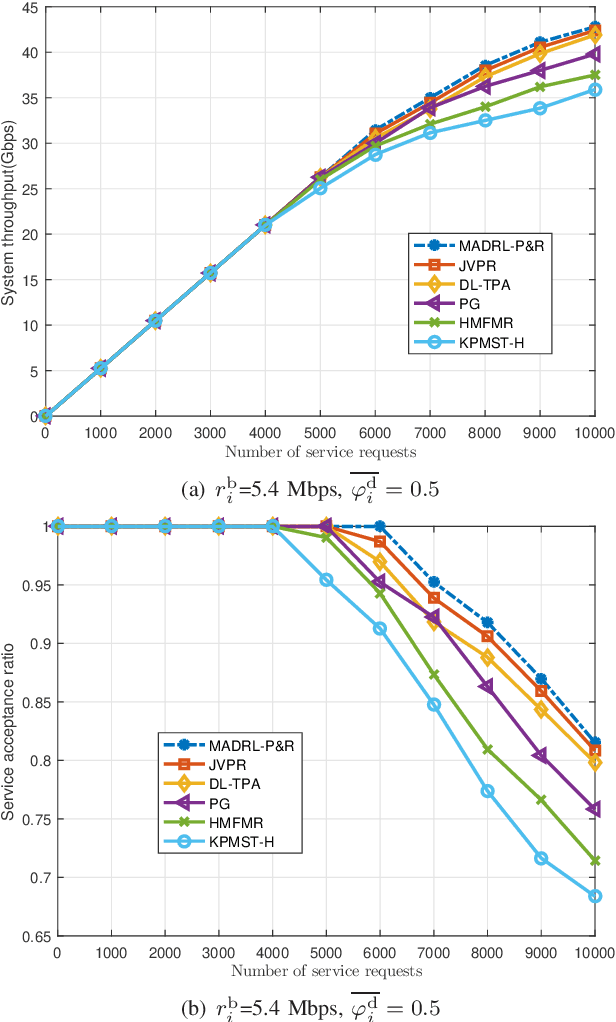
This paper proposes an effective and novel multiagent deep reinforcement learning (MADRL)-based method for solving the joint virtual network function (VNF) placement and routing (P&R), where multiple service requests with differentiated demands are delivered at the same time. The differentiated demands of the service requests are reflected by their delay- and cost-sensitive factors. We first construct a VNF P&R problem to jointly minimize a weighted sum of service delay and resource consumption cost, which is NP-complete. Then, the joint VNF P&R problem is decoupled into two iterative subtasks: placement subtask and routing subtask. Each subtask consists of multiple concurrent parallel sequential decision processes. By invoking the deep deterministic policy gradient method and multi-agent technique, an MADRL-P&R framework is designed to perform the two subtasks. The new joint reward and internal rewards mechanism is proposed to match the goals and constraints of the placement and routing subtasks. We also propose the parameter migration-based model-retraining method to deal with changing network topologies. Corroborated by experiments, the proposed MADRL-P&R framework is superior to its alternatives in terms of service cost and delay, and offers higher flexibility for personalized service demands. The parameter migration-based model-retraining method can efficiently accelerate convergence under moderate network topology changes.
A Novel 3D Non-Stationary Channel Model for 6G Indoor Visible Light Communication Systems
Apr 06, 2022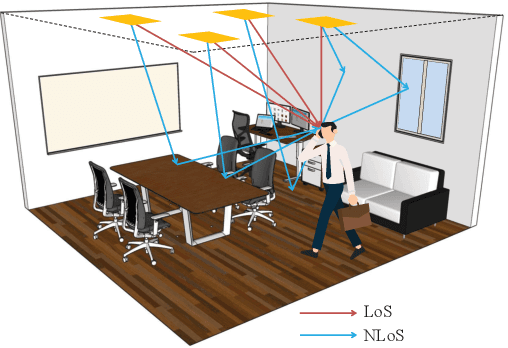
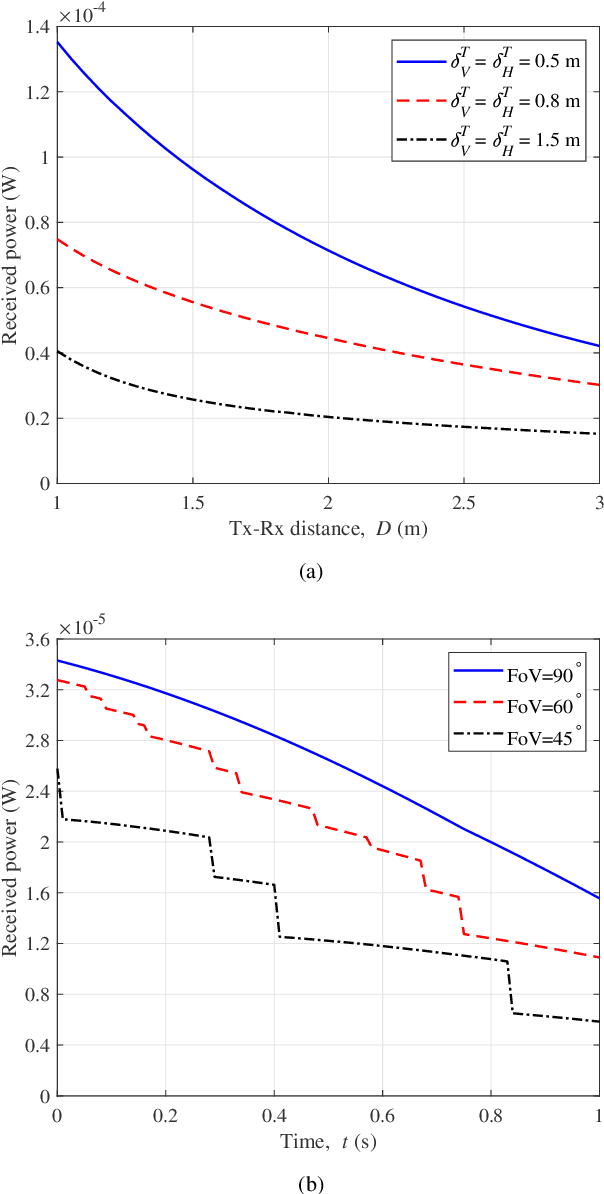
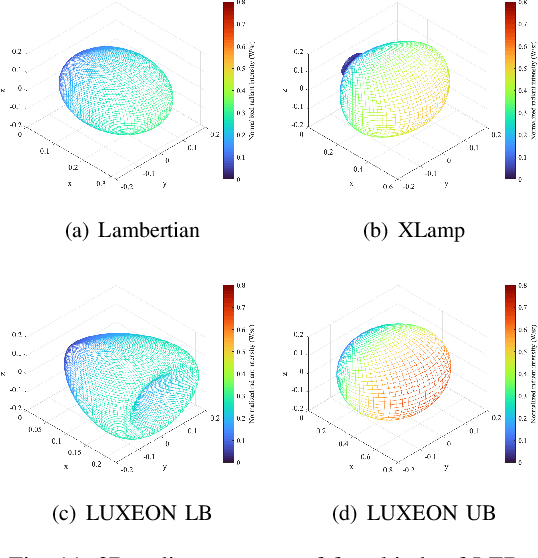
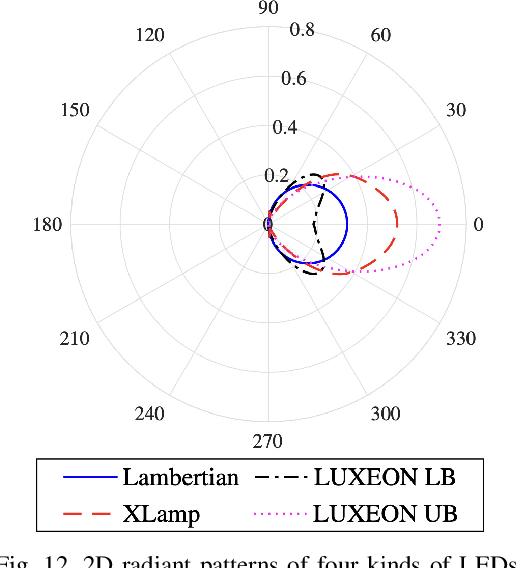
The visible light communication (VLC) technology has attracted much attention in the research of the sixth generation (6G) communication systems. In this paper, a novel three dimensional (3D) space-time-frequency non-stationary geometry-based stochastic model (GBSM) is proposed for indoor VLC channels. The proposed VLC GBSM can capture unique indoor VLC channel characteristics such as the space-time-frequency non-stationarity caused by large light-emitting diode (LED) arrays in indoor scenarios, long travelling paths, and large bandwidths of visible light waves, respectively. In addition, the proposed model can support special radiation patterns of LEDs, 3D translational and rotational motions of the optical receiver (Rx), and can be applied to angle diversity receivers (ADRs). Key channel properties are simulated and analyzed, including the space-time-frequency correlation function (STFCF), received power, root mean square (RMS) delay spread, and path loss (PL). Simulation results verify the space-time-frequency non-stationarity in indoor VLC channels. Finally, the accuracy and practicality of the proposed model are validated by comparing the simulation result of channel 3dB bandwidth with the existing measurement data. The proposed channel model will play a supporting role in the design of future 6G VLC systems.
Residual Graph Convolutional Recurrent Networks For Multi-step Traffic Flow Forecasting
May 03, 2022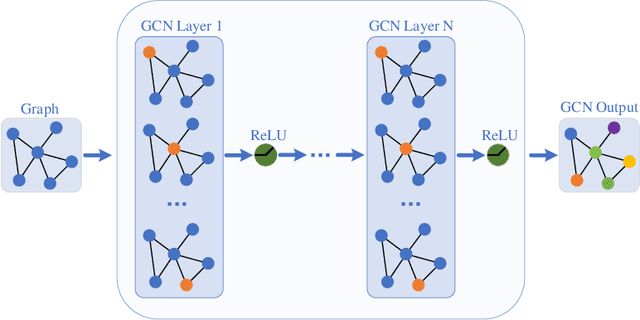

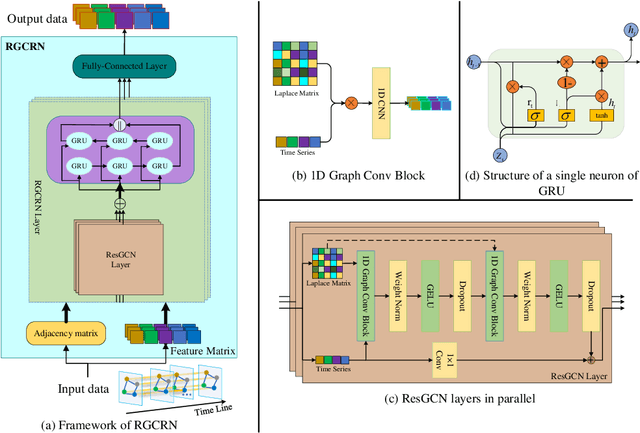
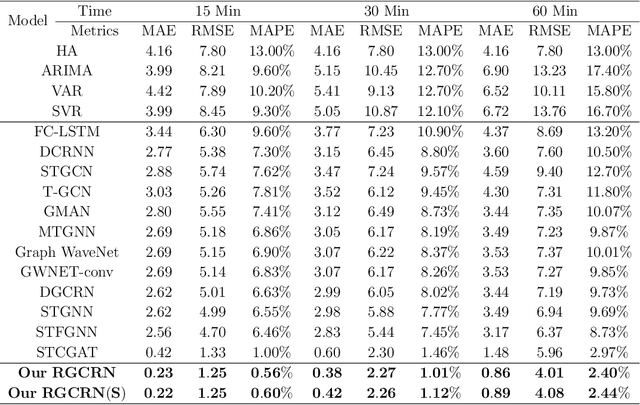
Traffic flow forecasting is essential for traffic planning, control and management. The main challenge of traffic forecasting tasks is accurately capturing traffic networks' spatial and temporal correlation. Although there are many traffic forecasting methods, most of them still have limitations in capturing spatial and temporal correlations. To improve traffic forecasting accuracy, we propose a new Spatial-temporal forecasting model, namely the Residual Graph Convolutional Recurrent Network (RGCRN). The model uses our proposed Residual Graph Convolutional Network (ResGCN) to capture the fine-grained spatial correlation of the traffic road network and then uses a Bi-directional Gated Recurrent Unit (BiGRU) to model time series with spatial information and obtains the temporal correlation by analysing the change in information transfer between the forward and reverse neurons of the time series data. Our comparative experimental results on two real datasets show that RGCRN improves on average by 20.66% compared to the best baseline model. You can get our source code and data through https://github.com/zhangshqii/RGCRN.
Fairness via In-Processing in the Over-parameterized Regime: A Cautionary Tale
Jun 29, 2022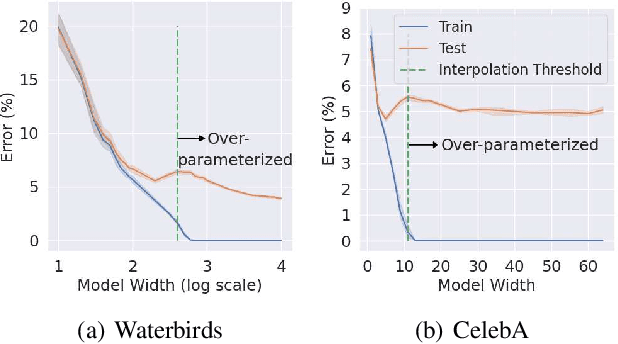
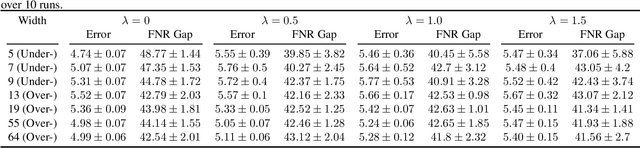
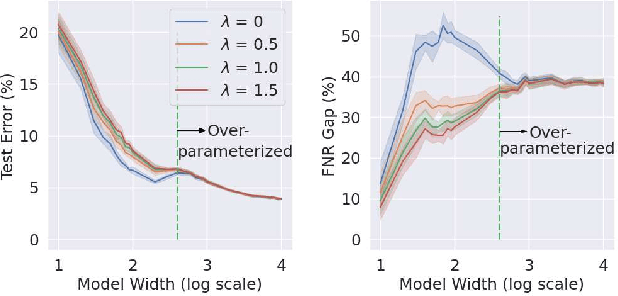

The success of DNNs is driven by the counter-intuitive ability of over-parameterized networks to generalize, even when they perfectly fit the training data. In practice, test error often continues to decrease with increasing over-parameterization, referred to as double descent. This allows practitioners to instantiate large models without having to worry about over-fitting. Despite its benefits, however, prior work has shown that over-parameterization can exacerbate bias against minority subgroups. Several fairness-constrained DNN training methods have been proposed to address this concern. Here, we critically examine MinDiff, a fairness-constrained training procedure implemented within TensorFlow's Responsible AI Toolkit, that aims to achieve Equality of Opportunity. We show that although MinDiff improves fairness for under-parameterized models, it is likely to be ineffective in the over-parameterized regime. This is because an overfit model with zero training loss is trivially group-wise fair on training data, creating an "illusion of fairness," thus turning off the MinDiff optimization (this will apply to any disparity-based measures which care about errors or accuracy. It won't apply to demographic parity). Within specified fairness constraints, under-parameterized MinDiff models can even have lower error compared to their over-parameterized counterparts (despite baseline over-parameterized models having lower error). We further show that MinDiff optimization is very sensitive to choice of batch size in the under-parameterized regime. Thus, fair model training using MinDiff requires time-consuming hyper-parameter searches. Finally, we suggest using previously proposed regularization techniques, viz. L2, early stopping and flooding in conjunction with MinDiff to train fair over-parameterized models.
NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video
Apr 01, 2021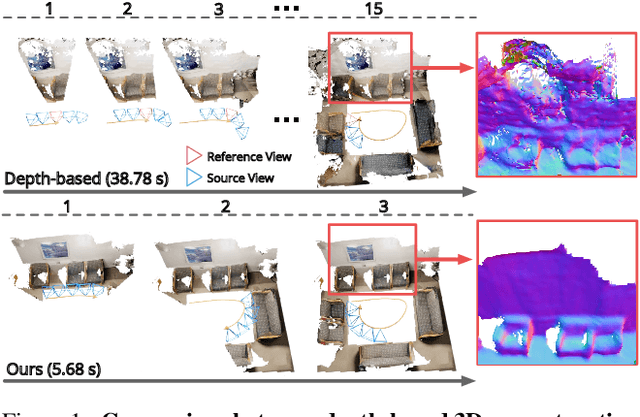
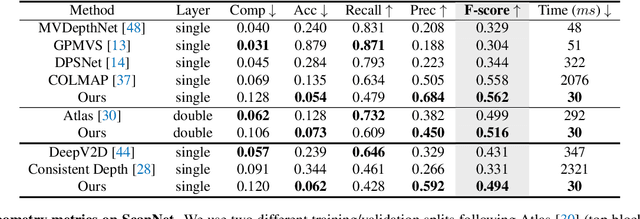
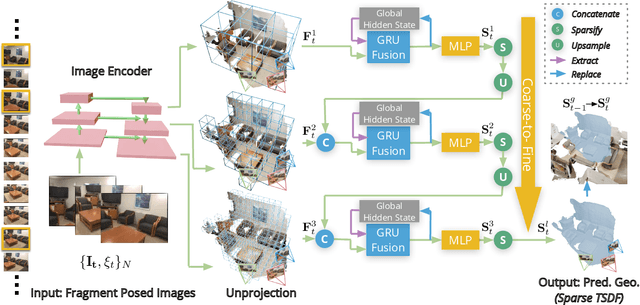
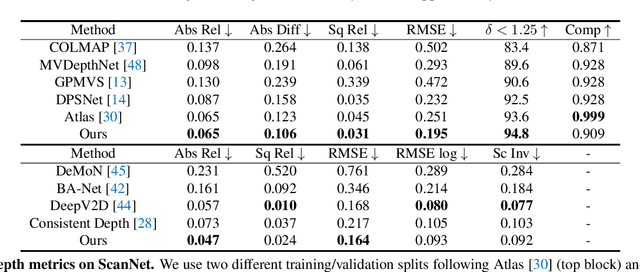
We present a novel framework named NeuralRecon for real-time 3D scene reconstruction from a monocular video. Unlike previous methods that estimate single-view depth maps separately on each key-frame and fuse them later, we propose to directly reconstruct local surfaces represented as sparse TSDF volumes for each video fragment sequentially by a neural network. A learning-based TSDF fusion module based on gated recurrent units is used to guide the network to fuse features from previous fragments. This design allows the network to capture local smoothness prior and global shape prior of 3D surfaces when sequentially reconstructing the surfaces, resulting in accurate, coherent, and real-time surface reconstruction. The experiments on ScanNet and 7-Scenes datasets show that our system outperforms state-of-the-art methods in terms of both accuracy and speed. To the best of our knowledge, this is the first learning-based system that is able to reconstruct dense coherent 3D geometry in real-time.
Sort by Structure: Language Model Ranking as Dependency Probing
Jun 10, 2022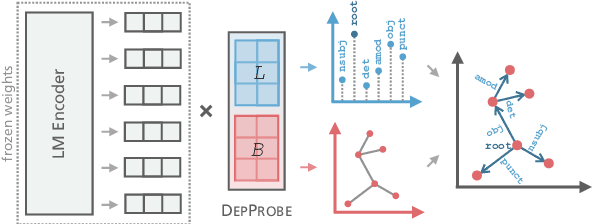
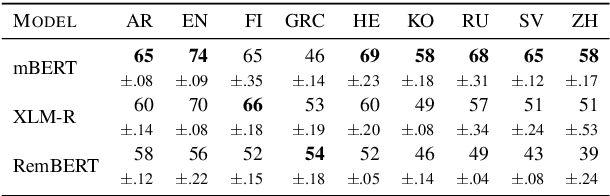
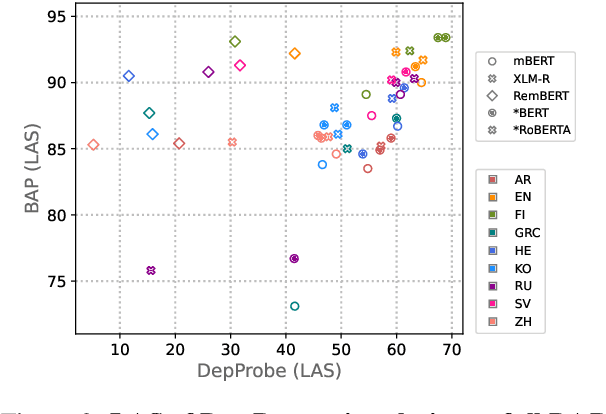
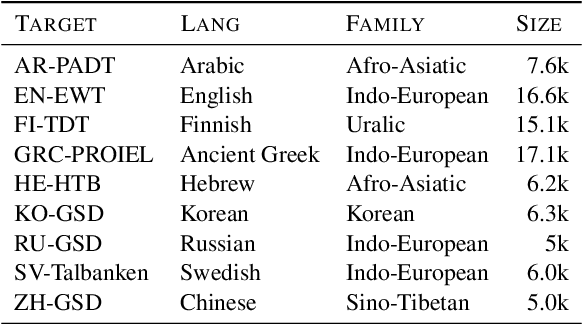
Making an informed choice of pre-trained language model (LM) is critical for performance, yet environmentally costly, and as such widely underexplored. The field of Computer Vision has begun to tackle encoder ranking, with promising forays into Natural Language Processing, however they lack coverage of linguistic tasks such as structured prediction. We propose probing to rank LMs, specifically for parsing dependencies in a given language, by measuring the degree to which labeled trees are recoverable from an LM's contextualized embeddings. Across 46 typologically and architecturally diverse LM-language pairs, our probing approach predicts the best LM choice 79% of the time using orders of magnitude less compute than training a full parser. Within this study, we identify and analyze one recently proposed decoupled LM - RemBERT - and find it strikingly contains less inherent dependency information, but often yields the best parser after full fine-tuning. Without this outlier our approach identifies the best LM in 89% of cases.
Real-time Face Mask Detection in Video Data
May 05, 2021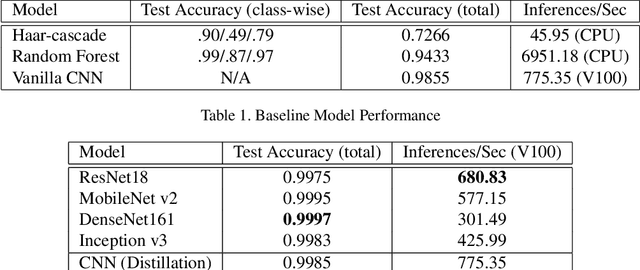
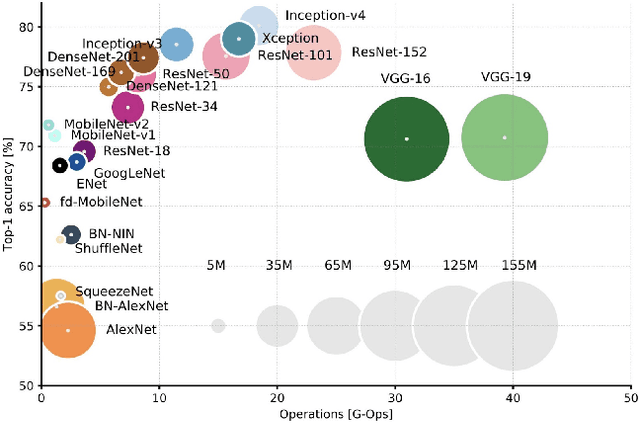
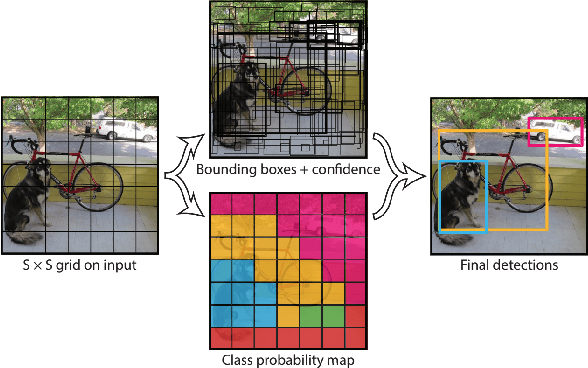
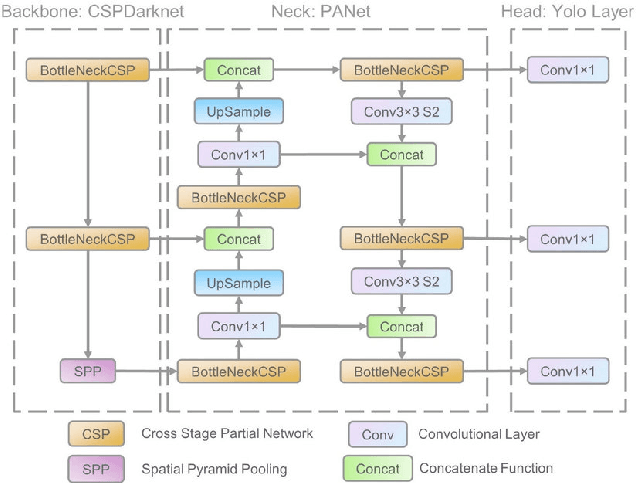
In response to the ongoing COVID-19 pandemic, we present a robust deep learning pipeline that is capable of identifying correct and incorrect mask-wearing from real-time video streams. To accomplish this goal, we devised two separate approaches and evaluated their performance and run-time efficiency. The first approach leverages a pre-trained face detector in combination with a mask-wearing image classifier trained on a large-scale synthetic dataset. The second approach utilizes a state-of-the-art object detection network to perform localization and classification of faces in one shot, fine-tuned on a small set of labeled real-world images. The first pipeline achieved a test accuracy of 99.97% on the synthetic dataset and maintained 6 FPS running on video data. The second pipeline achieved a mAP(0.5) of 89% on real-world images while sustaining 52 FPS on video data. We have concluded that if a larger dataset with bounding-box labels can be curated, this task is best suited using object detection architectures such as YOLO and SSD due to their superior inference speed and satisfactory performance on key evaluation metrics.