 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic generation of a large dictionary with concreteness/abstractness ratings based on a small human dictionary
Jun 13, 2022
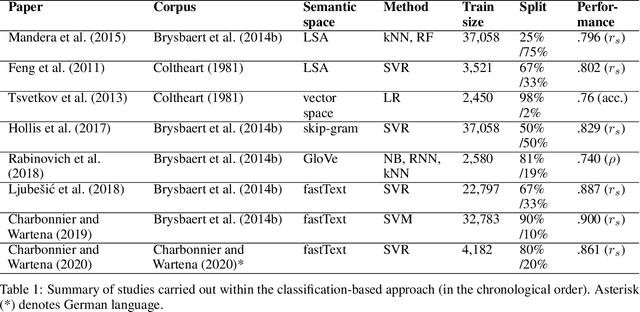
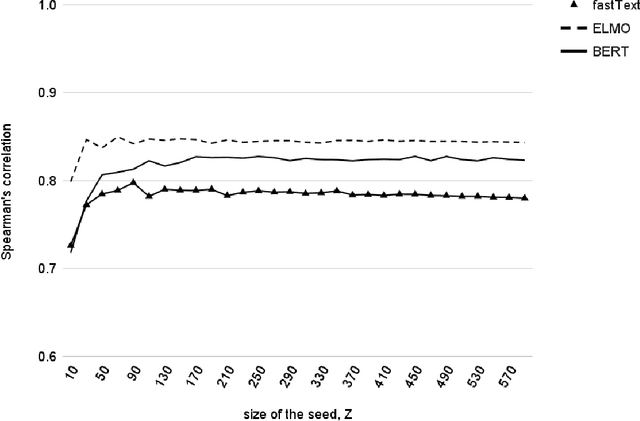

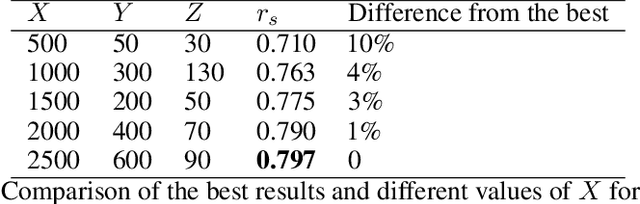
Concrete/abstract words are used in a growing number of psychological and neurophysiological research. For a few languages, large dictionaries have been created manually. This is a very time-consuming and costly process. To generate large high-quality dictionaries of concrete/abstract words automatically one needs extrapolating the expert assessments obtained on smaller samples. The research question that arises is how small such samples should be to do a good enough extrapolation. In this paper, we present a method for automatic ranking concreteness of words and propose an approach to significantly decrease amount of expert assessment. The method has been evaluated on a large test set for English. The quality of the constructed dictionaries is comparable to the expert ones. The correlation between predicted and expert ratings is higher comparing to the state-of-the-art methods.
Embodied vision for learning object representations
May 12, 2022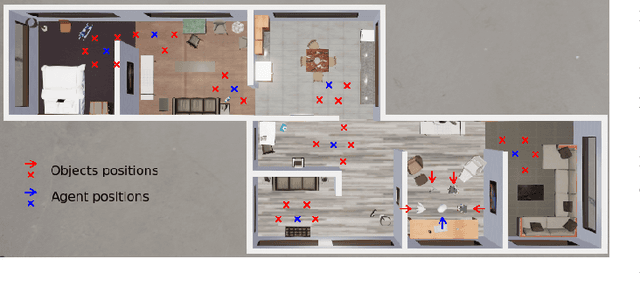


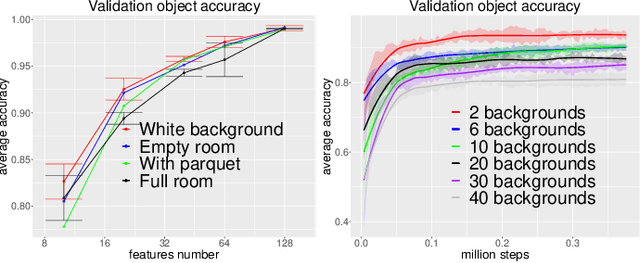
Recent time-contrastive learning approaches manage to learn invariant object representations without supervision. This is achieved by mapping successive views of an object onto close-by internal representations. When considering this learning approach as a model of the development of human object recognition, it is important to consider what visual input a toddler would typically observe while interacting with objects. First, human vision is highly foveated, with high resolution only available in the central region of the field of view. Second, objects may be seen against a blurry background due to infants' limited depth of field. Third, during object manipulation a toddler mostly observes close objects filling a large part of the field of view due to their rather short arms. Here, we study how these effects impact the quality of visual representations learnt through time-contrastive learning. To this end, we let a visually embodied agent "play" with objects in different locations of a near photo-realistic flat. During each play session the agent views an object in multiple orientations before turning its body to view another object. The resulting sequence of views feeds a time-contrastive learning algorithm. Our results show that visual statistics mimicking those of a toddler improve object recognition accuracy in both familiar and novel environments. We argue that this effect is caused by the reduction of features extracted in the background, a neural network bias for large features in the image and a greater similarity between novel and familiar background regions. We conclude that the embodied nature of visual learning may be crucial for understanding the development of human object perception.
A Single-Timescale Analysis For Stochastic Approximation With Multiple Coupled Sequences
Jun 21, 2022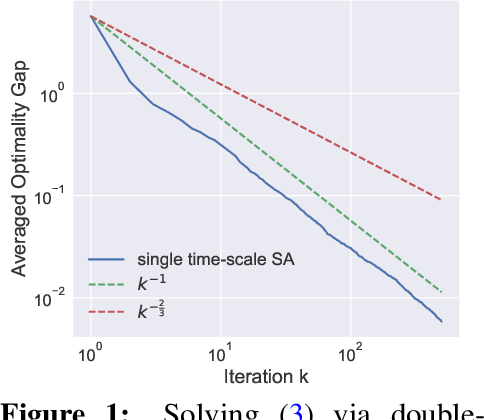

Stochastic approximation (SA) with multiple coupled sequences has found broad applications in machine learning such as bilevel learning and reinforcement learning (RL). In this paper, we study the finite-time convergence of nonlinear SA with multiple coupled sequences. Different from existing multi-timescale analysis, we seek for scenarios where a fine-grained analysis can provide the tight performance guarantee for multi-sequence single-timescale SA (STSA). At the heart of our analysis is the smoothness property of the fixed points in multi-sequence SA that holds in many applications. When all sequences have strongly monotone increments, we establish the iteration complexity of $\mathcal{O}(\epsilon^{-1})$ to achieve $\epsilon$-accuracy, which improves the existing $\mathcal{O}(\epsilon^{-1.5})$ complexity for two coupled sequences. When all but the main sequence have strongly monotone increments, we establish the iteration complexity of $\mathcal{O}(\epsilon^{-2})$. The merit of our results lies in that applying them to stochastic bilevel and compositional optimization problems, as well as RL problems leads to either relaxed assumptions or improvements over their existing performance guarantees.
SimA: Simple Softmax-free Attention for Vision Transformers
Jun 17, 2022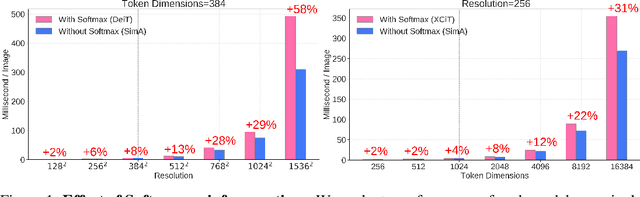
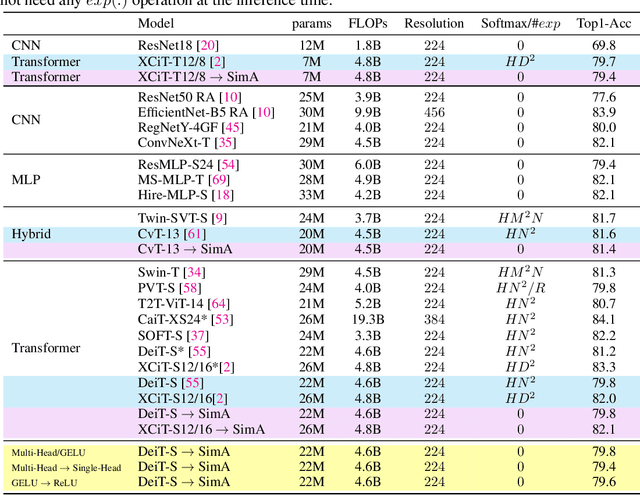
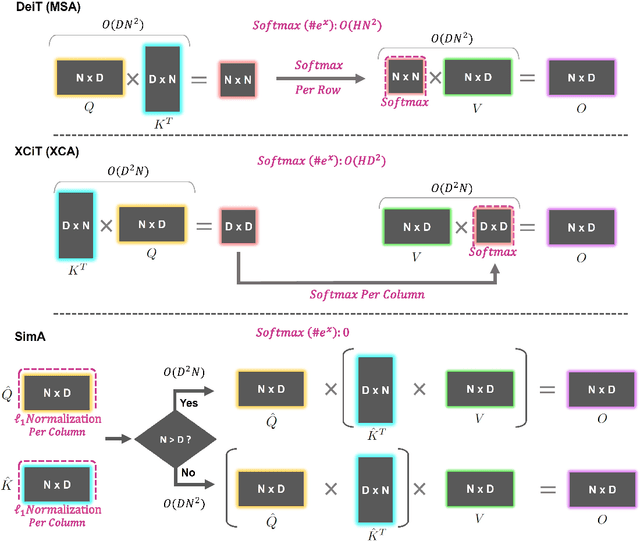
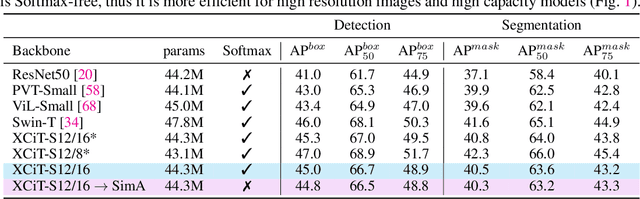
Recently, vision transformers have become very popular. However, deploying them in many applications is computationally expensive partly due to the Softmax layer in the attention block. We introduce a simple but effective, Softmax-free attention block, SimA, which normalizes query and key matrices with simple $\ell_1$-norm instead of using Softmax layer. Then, the attention block in SimA is a simple multiplication of three matrices, so SimA can dynamically change the ordering of the computation at the test time to achieve linear computation on the number of tokens or the number of channels. We empirically show that SimA applied to three SOTA variations of transformers, DeiT, XCiT, and CvT, results in on-par accuracy compared to the SOTA models, without any need for Softmax layer. Interestingly, changing SimA from multi-head to single-head has only a small effect on the accuracy, which simplifies the attention block further. The code is available here: $\href{https://github.com/UCDvision/sima}{\text{This https URL}}$
Using EBGAN for Anomaly Intrusion Detection
Jun 21, 2022
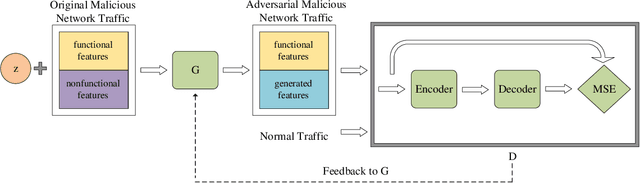
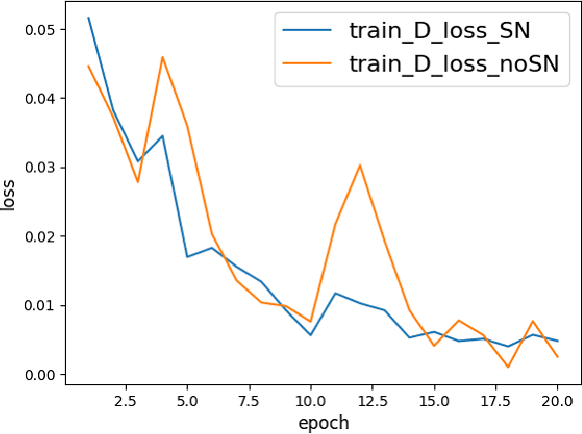
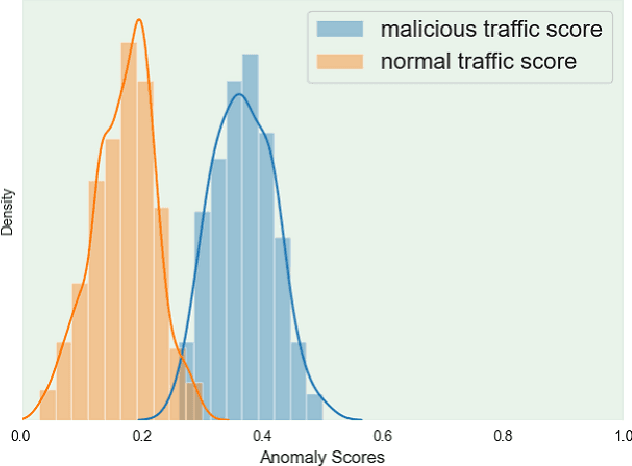
As an active network security protection scheme, intrusion detection system (IDS) undertakes the important responsibility of detecting network attacks in the form of malicious network traffic. Intrusion detection technology is an important part of IDS. At present, many scholars have carried out extensive research on intrusion detection technology. However, developing an efficient intrusion detection method for massive network traffic data is still difficult. Since Generative Adversarial Networks (GANs) have powerful modeling capabilities for complex high-dimensional data, they provide new ideas for addressing this problem. In this paper, we put forward an EBGAN-based intrusion detection method, IDS-EBGAN, that classifies network records as normal traffic or malicious traffic. The generator in IDS-EBGAN is responsible for converting the original malicious network traffic in the training set into adversarial malicious examples. This is because we want to use adversarial learning to improve the ability of discriminator to detect malicious traffic. At the same time, the discriminator adopts Autoencoder model. During testing, IDS-EBGAN uses reconstruction error of discriminator to classify traffic records.
A Comparative Study of Graph Matching Algorithms in Computer Vision
Jul 01, 2022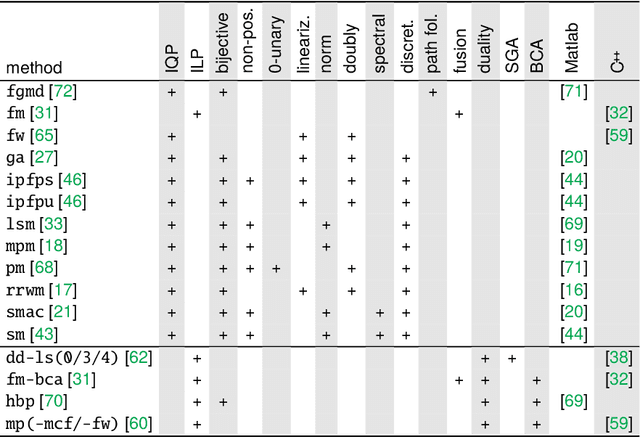
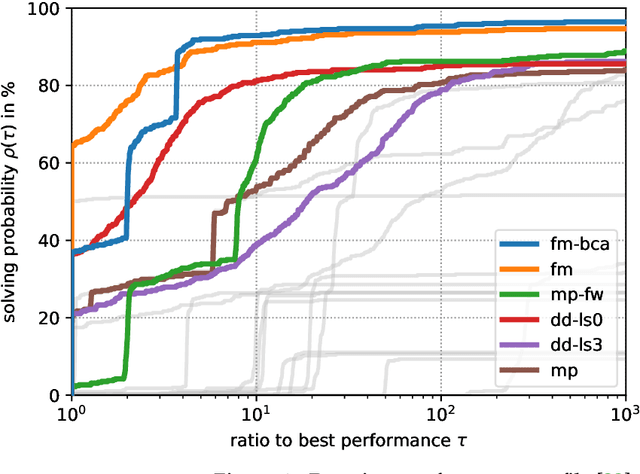

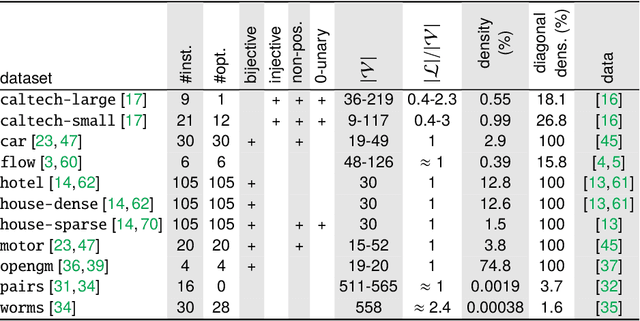
The graph matching optimization problem is an essential component for many tasks in computer vision, such as bringing two deformable objects in correspondence. Naturally, a wide range of applicable algorithms have been proposed in the last decades. Since a common standard benchmark has not been developed, their performance claims are often hard to verify as evaluation on differing problem instances and criteria make the results incomparable. To address these shortcomings, we present a comparative study of graph matching algorithms. We create a uniform benchmark where we collect and categorize a large set of existing and publicly available computer vision graph matching problems in a common format. At the same time we collect and categorize the most popular open-source implementations of graph matching algorithms. Their performance is evaluated in a way that is in line with the best practices for comparing optimization algorithms. The study is designed to be reproducible and extensible to serve as a valuable resource in the future. Our study provides three notable insights: 1.) popular problem instances are exactly solvable in substantially less than 1 second and, therefore, are insufficient for future empirical evaluations; 2.) the most popular baseline methods are highly inferior to the best available methods; 3.) despite the NP-hardness of the problem, instances coming from vision applications are often solvable in a few seconds even for graphs with more than 500 vertices.
Differentiable Divergences Between Time Series
Oct 16, 2020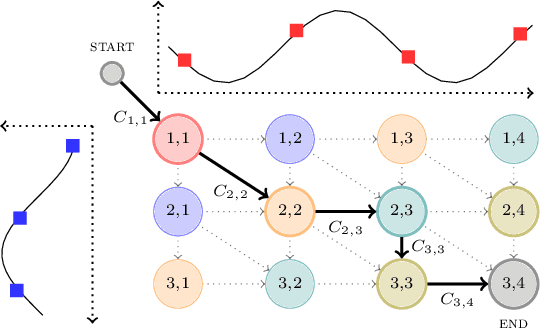

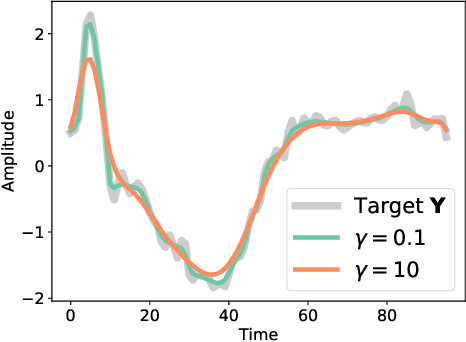
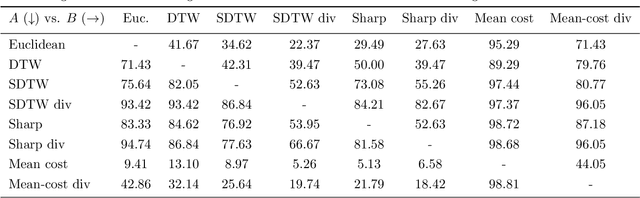
Computing the discrepancy between time series of variable sizes is notoriously challenging. While dynamic time warping (DTW) is popularly used for this purpose, it is not differentiable everywhere and is known to lead to bad local optima when used as a "loss". Soft-DTW addresses these issues, but it is not a positive definite divergence: due to the bias introduced by entropic regularization, it can be negative and it is not minimized when the time series are equal. We propose in this paper a new divergence, dubbed soft-DTW divergence, which aims to correct these issues. We study its properties; in particular, under conditions on the ground cost, we show that it is non-negative and minimized when the time series are equal. We also propose a new "sharp" variant by further removing entropic bias. We showcase our divergences on time series averaging and demonstrate significant accuracy improvements compared to both DTW and soft-DTW on 84 time series classification datasets.
Emotion recognition by fusing time synchronous and time asynchronous representations
Oct 27, 2020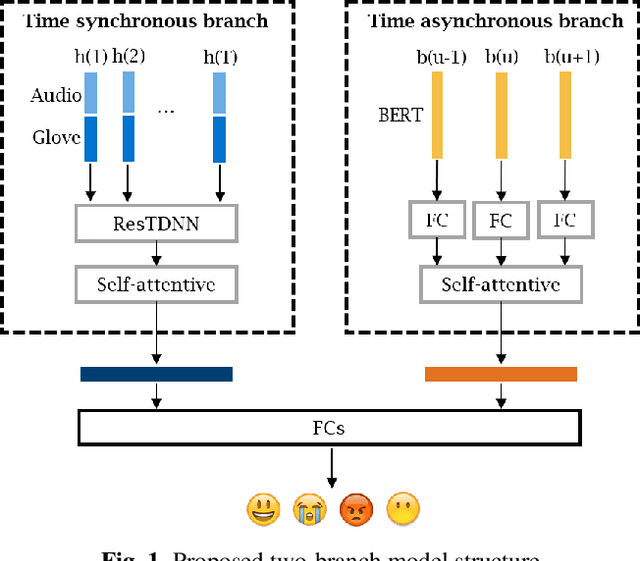



In this paper, a novel two-branch neural network model structure is proposed for multimodal emotion recognition, which consists of a time synchronous branch (TSB) and a time asynchronous branch (TAB). To capture correlations between each word and its acoustic realisation, the TSB combines speech and text modalities at each input window frame and then does pooling across time to form a single embedding vector. The TAB, by contrast, provides cross-utterance information by integrating sentence text embeddings from a number of context utterances into another embedding vector. The final emotion classification uses both the TSB and the TAB embeddings. Experimental results on the IEMOCAP dataset demonstrate that the two-branch structure achieves state-of-the-art results in 4-way classification with all common test setups. When using automatic speech recognition (ASR) output instead of manually transcribed reference text, it is shown that the cross-utterance information considerably improves the robustness against ASR errors. Furthermore, by incorporating an extra class for all the other emotions, the final 5-way classification system with ASR hypotheses can be viewed as a prototype for more realistic emotion recognition systems.
RoVaR: Robust Multi-agent Tracking through Dual-layer Diversity in Visual and RF Sensor Fusion
Jul 06, 2022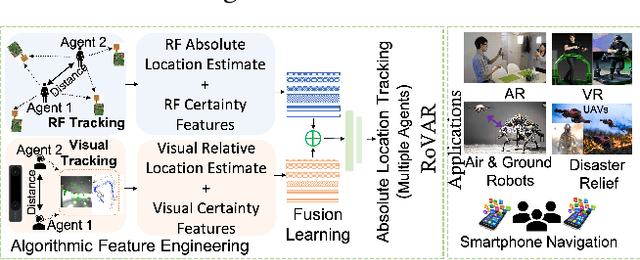

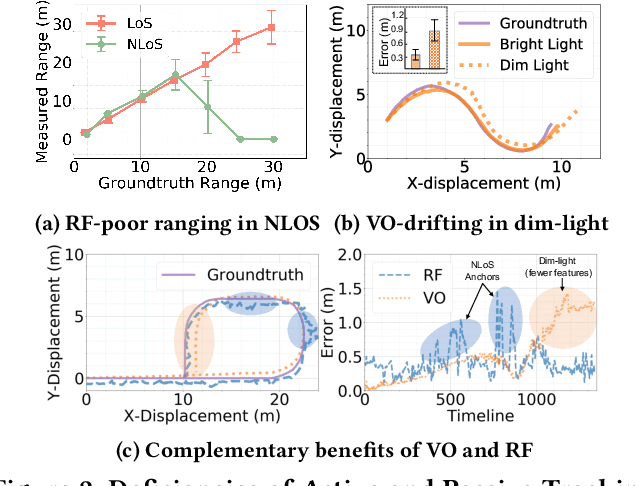
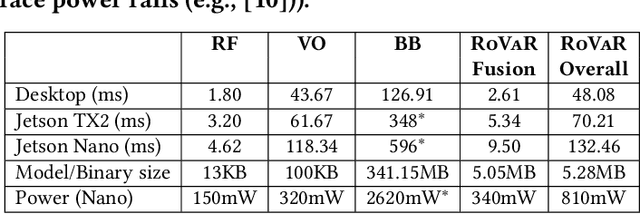
The plethora of sensors in our commodity devices provides a rich substrate for sensor-fused tracking. Yet, today's solutions are unable to deliver robust and high tracking accuracies across multiple agents in practical, everyday environments - a feature central to the future of immersive and collaborative applications. This can be attributed to the limited scope of diversity leveraged by these fusion solutions, preventing them from catering to the multiple dimensions of accuracy, robustness (diverse environmental conditions) and scalability (multiple agents) simultaneously. In this work, we take an important step towards this goal by introducing the notion of dual-layer diversity to the problem of sensor fusion in multi-agent tracking. We demonstrate that the fusion of complementary tracking modalities, - passive/relative (e.g., visual odometry) and active/absolute tracking (e.g., infrastructure-assisted RF localization) offer a key first layer of diversity that brings scalability while the second layer of diversity lies in the methodology of fusion, where we bring together the complementary strengths of algorithmic (for robustness) and data-driven (for accuracy) approaches. RoVaR is an embodiment of such a dual-layer diversity approach that intelligently attends to cross-modal information using algorithmic and data-driven techniques that jointly share the burden of accurately tracking multiple agents in the wild. Extensive evaluations reveal RoVaR's multi-dimensional benefits in terms of tracking accuracy (median of 15cm), robustness (in unseen environments), light weight (runs in real-time on mobile platforms such as Jetson Nano/TX2), to enable practical multi-agent immersive applications in everyday environments.
DIWIFT: Discovering Instance-wise Influential Features for Tabular Data
Jul 06, 2022
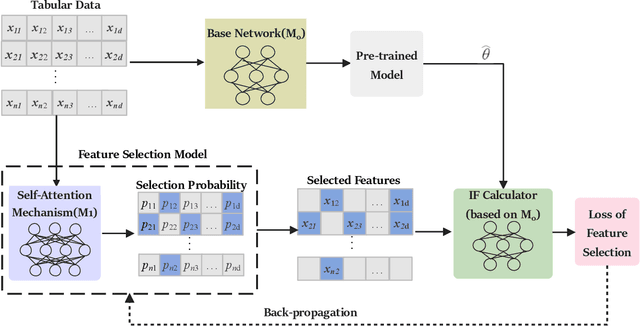
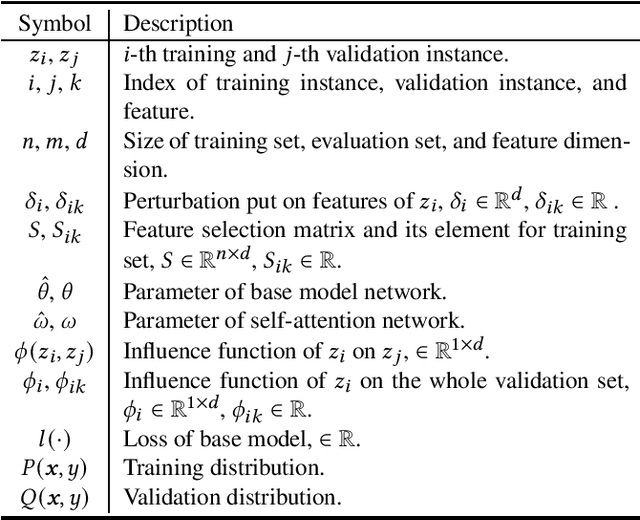
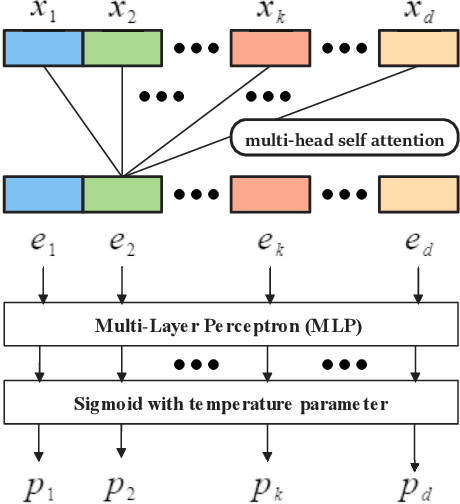
Tabular data is one of the most common data storage formats in business applications, ranging from retail, bank and E-commerce. These applications rely heavily on machine learning models to achieve business success. One of the critical problems in learning tabular data is to distinguish influential features from all the predetermined features. Global feature selection has been well-studied for quite some time, assuming that all instances have the same influential feature subsets. However, different instances rely on different feature subsets in practice, which also gives rise to that instance-wise feature selection receiving increasing attention in recent studies. In this paper, we first propose a novel method for discovering instance-wise influential features for tabular data (DIWIFT), the core of which is to introduce the influence function to measure the importance of an instance-wise feature. DIWIFT is capable of automatically discovering influential feature subsets of different sizes in different instances, which is different from global feature selection that considers all instances with the same influential feature subset. On the other hand, different from the previous instance-wise feature selection, DIWIFT minimizes the validation loss on the validation set and is thus more robust to the distribution shift existing in the training dataset and test dataset, which is important in tabular data. Finally, we conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness of our DIWIFT, compared it with baseline methods. Moreover, we also demonstrate the robustness of our method via some ablation experiments.