 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Uncoupled Learning Dynamics with $O(\log T)$ Swap Regret in Multiplayer Games
Apr 25, 2022
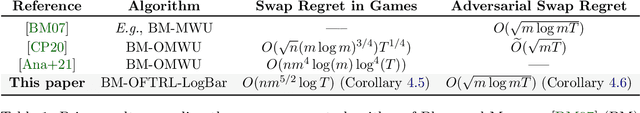
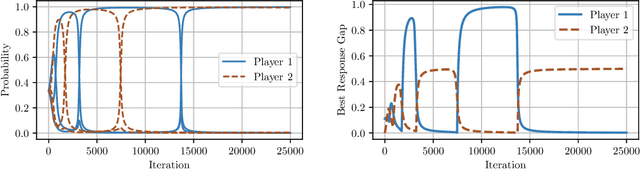
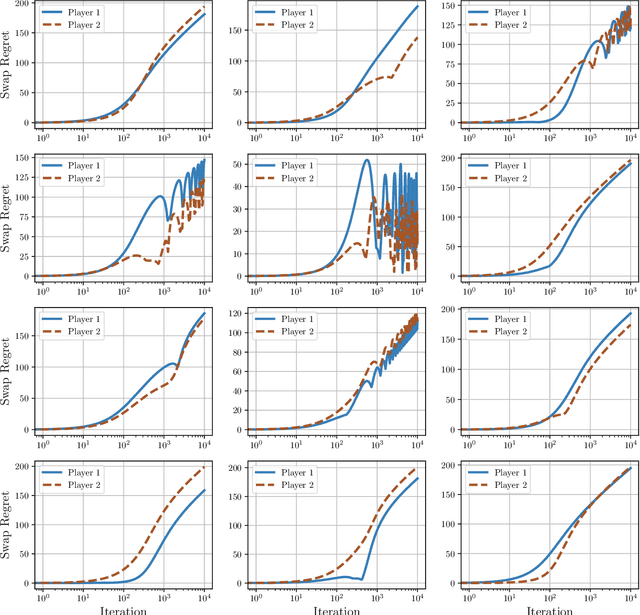
In this paper we establish efficient and \emph{uncoupled} learning dynamics so that, when employed by all players in a general-sum multiplayer game, the \emph{swap regret} of each player after $T$ repetitions of the game is bounded by $O(\log T)$, improving over the prior best bounds of $O(\log^4 (T))$. At the same time, we guarantee optimal $O(\sqrt{T})$ swap regret in the adversarial regime as well. To obtain these results, our primary contribution is to show that when all players follow our dynamics with a \emph{time-invariant} learning rate, the \emph{second-order path lengths} of the dynamics up to time $T$ are bounded by $O(\log T)$, a fundamental property which could have further implications beyond near-optimally bounding the (swap) regret. Our proposed learning dynamics combine in a novel way \emph{optimistic} regularized learning with the use of \emph{self-concordant barriers}. Further, our analysis is remarkably simple, bypassing the cumbersome framework of higher-order smoothness recently developed by Daskalakis, Fishelson, and Golowich (NeurIPS'21).
Energy-Efficient Mobile Robot Control via Run-time Monitoring of Environmental Complexity and Computing Workload
Sep 08, 2021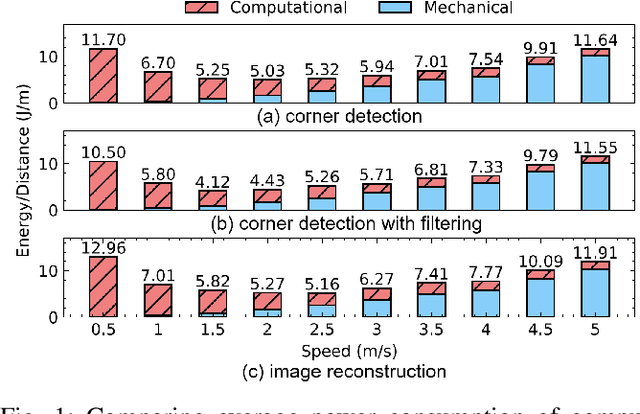

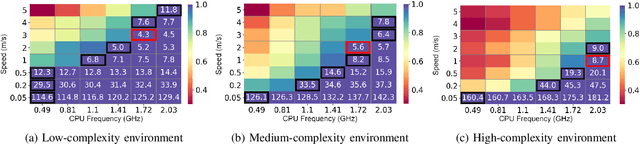
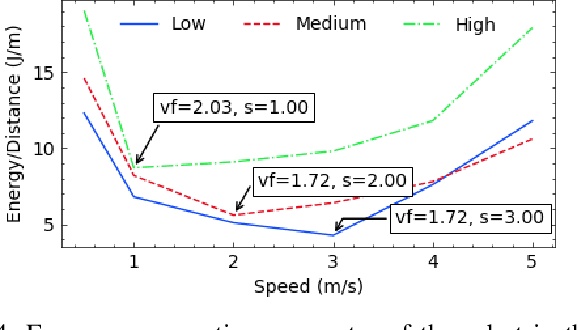
We propose an energy-efficient controller to minimize the energy consumption of a mobile robot by dynamically manipulating the mechanical and computational actuators of the robot. The mobile robot performs real-time vision-based applications based on an event-based camera. The actuators of the controller are CPU voltage/frequency for the computation part and motor voltage for the mechanical part. We show that independently considering speed control of the robot and voltage/frequency control of the CPU does not necessarily result in an energy-efficient solution. In fact, to obtain the highest efficiency, the computation and mechanical parts should be controlled together in synergy. We propose a fast hill-climbing optimization algorithm to allow the controller to find the best CPU/motor configuration at run-time and whenever the mobile robot is facing a new environment during its travel. Experimental results on a robot with Brushless DC Motors, Jetson TX2 board as the computing unit, and a DAVIS-346 event-based camera show that the proposed control algorithm can save battery energy by an average of 50.5%, 41%, and 30%, in low-complexity, medium-complexity, and high-complexity environments, over baselines.
Causal Transformer for Estimating Counterfactual Outcomes
Apr 14, 2022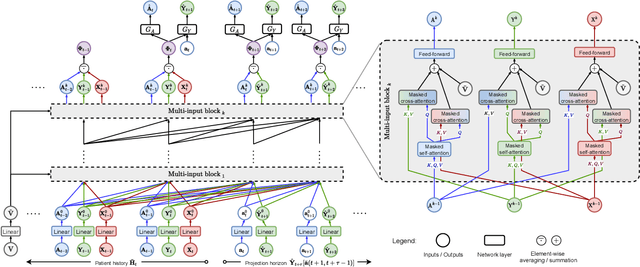
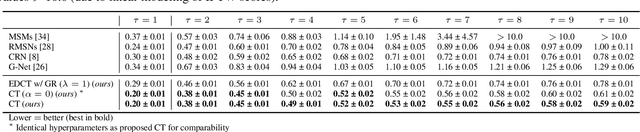
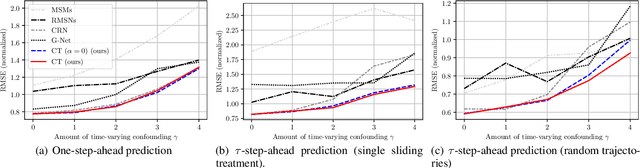

Estimating counterfactual outcomes over time from observational data is relevant for many applications (e.g., personalized medicine). Yet, state-of-the-art methods build upon simple long short-term memory (LSTM) networks, thus rendering inferences for complex, long-range dependencies challenging. In this paper, we develop a novel Causal Transformer for estimating counterfactual outcomes over time. Our model is specifically designed to capture complex, long-range dependencies among time-varying confounders. For this, we combine three transformer subnetworks with separate inputs for time-varying covariates, previous treatments, and previous outcomes into a joint network with in-between cross-attentions. We further develop a custom, end-to-end training procedure for our Causal Transformer. Specifically, we propose a novel counterfactual domain confusion loss to address confounding bias: it aims to learn adversarial balanced representations, so that they are predictive of the next outcome but non-predictive of the current treatment assignment. We evaluate our Causal Transformer based on synthetic and real-world datasets, where it achieves superior performance over current baselines. To the best of our knowledge, this is the first work proposing transformer-based architecture for estimating counterfactual outcomes from longitudinal data.
LT-OCF: Learnable-Time ODE-based Collaborative Filtering
Aug 18, 2021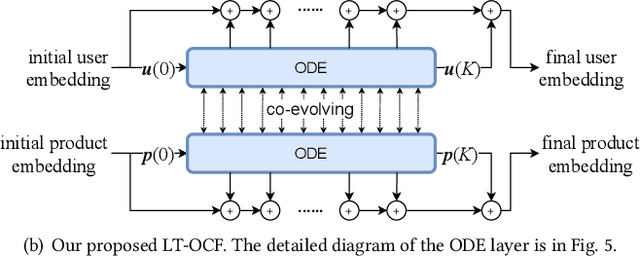
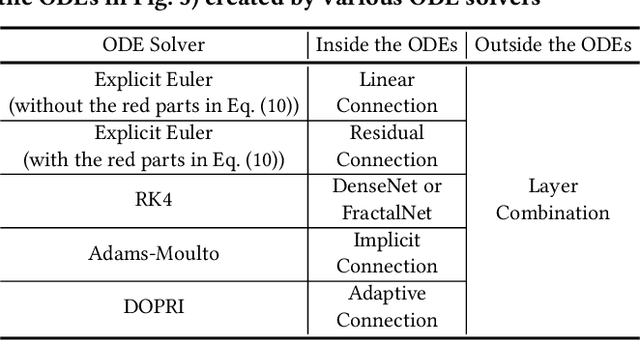
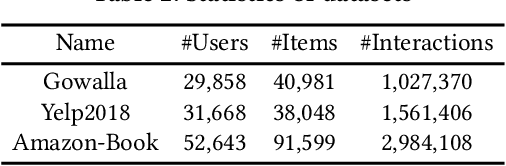
Collaborative filtering (CF) is a long-standing problem of recommender systems. Many novel methods have been proposed, ranging from classical matrix factorization to recent graph convolutional network-based approaches. After recent fierce debates, researchers started to focus on linear graph convolutional networks (GCNs) with a layer combination, which show state-of-the-art accuracy in many datasets. In this work, we extend them based on neural ordinary differential equations (NODEs), because the linear GCN concept can be interpreted as a differential equation, and present the method of Learnable-Time ODE-based Collaborative Filtering (LT-OCF). The main novelty in our method is that after redesigning linear GCNs on top of the NODE regime, i) we learn the optimal architecture rather than relying on manually designed ones, ii) we learn smooth ODE solutions that are considered suitable for CF, and iii) we test with various ODE solvers that internally build a diverse set of neural network connections. We also present a novel training method specialized to our method. In our experiments with three benchmark datasets, Gowalla, Yelp2018, and Amazon-Book, our method consistently shows better accuracy than existing methods, e.g., a recall of 0.0411 by LightGCN vs. 0.0442 by LT-OCF and an NDCG of 0.0315 by LightGCN vs. 0.0341 by LT-OCF in Amazon-Book. One more important discovery in our experiments that is worth mentioning is that our best accuracy was achieved by dense connections rather than linear connections.
Applications of Reinforcement Learning in Finance -- Trading with a Double Deep Q-Network
Jun 28, 2022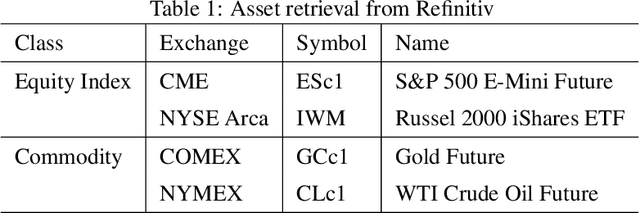
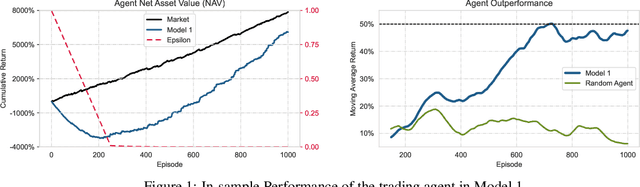
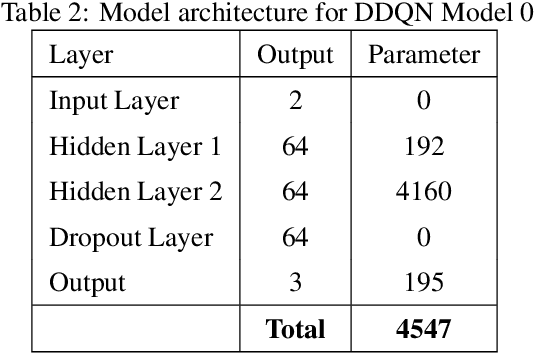
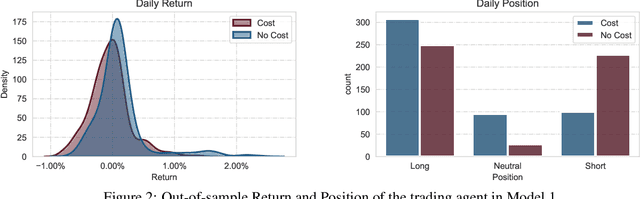
This paper presents a Double Deep Q-Network algorithm for trading single assets, namely the E-mini S&P 500 continuous futures contract. We use a proven setup as the foundation for our environment with multiple extensions. The features of our trading agent are constantly being expanded to include additional assets such as commodities, resulting in four models. We also respond to environmental conditions, including costs and crises. Our trading agent is first trained for a specific time period and tested on new data and compared with the long-and-hold strategy as a benchmark (market). We analyze the differences between the various models and the in-sample/out-of-sample performance with respect to the environment. The experimental results show that the trading agent follows an appropriate behavior. It can adjust its policy to different circumstances, such as more extensive use of the neutral position when trading costs are present. Furthermore, the net asset value exceeded that of the benchmark, and the agent outperformed the market in the test set. We provide initial insights into the behavior of an agent in a financial domain using a DDQN algorithm. The results of this study can be used for further development.
Back2Future: Leveraging Backfill Dynamics for Improving Real-time Predictions in Future
Jun 08, 2021

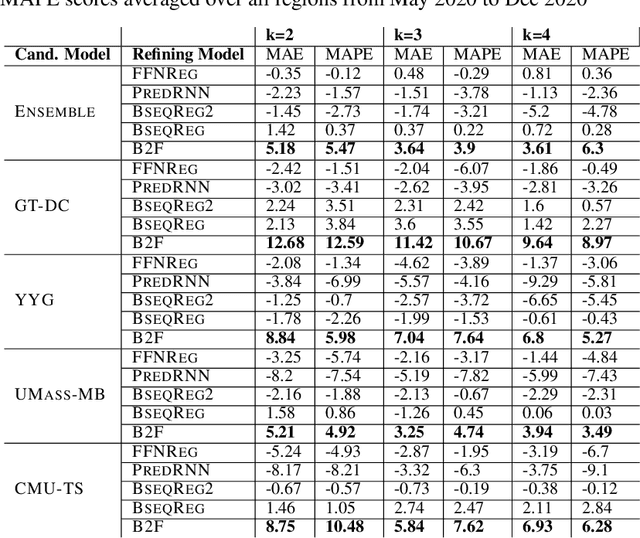
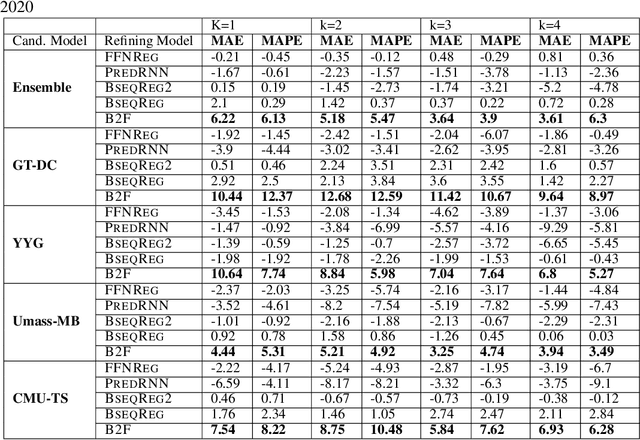
In real-time forecasting in public health, data collection is a non-trivial and demanding task. Often after initially released, it undergoes several revisions later (maybe due to human or technical constraints) - as a result, it may take weeks until the data reaches to a stable value. This so-called 'backfill' phenomenon and its effect on model performance has been barely studied in the prior literature. In this paper, we introduce the multi-variate backfill problem using COVID-19 as the motivating example. We construct a detailed dataset composed of relevant signals over the past year of the pandemic. We then systematically characterize several patterns in backfill dynamics and leverage our observations for formulating a novel problem and neural framework Back2Future that aims to refines a given model's predictions in real-time. Our extensive experiments demonstrate that our method refines the performance of top models for COVID-19 forecasting, in contrast to non-trivial baselines, yielding 18% improvement over baselines, enabling us obtain a new SOTA performance. In addition, we show that our model improves model evaluation too; hence policy-makers can better understand the true accuracy of forecasting models in real-time.
Multicast Scheduling for Multi-Message over Multi-Channel: A Permutation-based Wolpertinger Deep Reinforcement Learning Method
May 19, 2022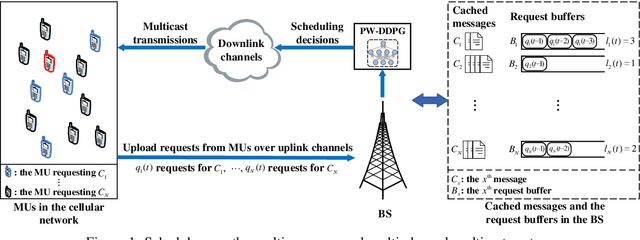
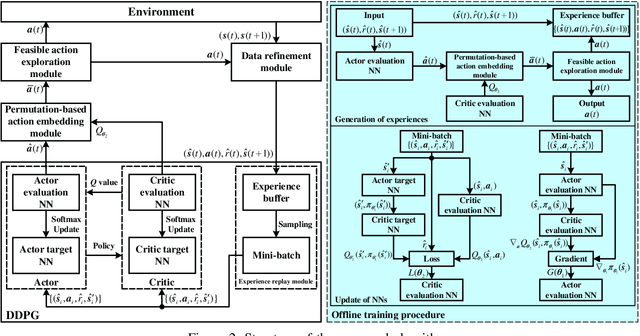
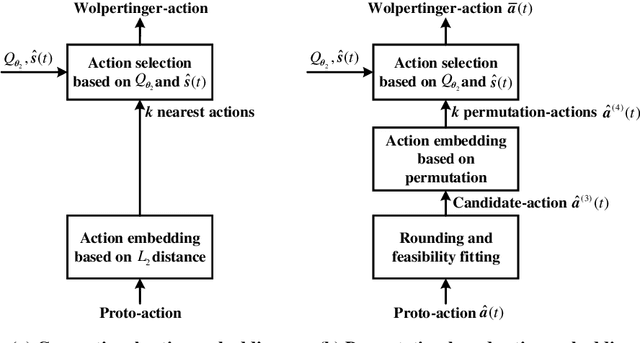
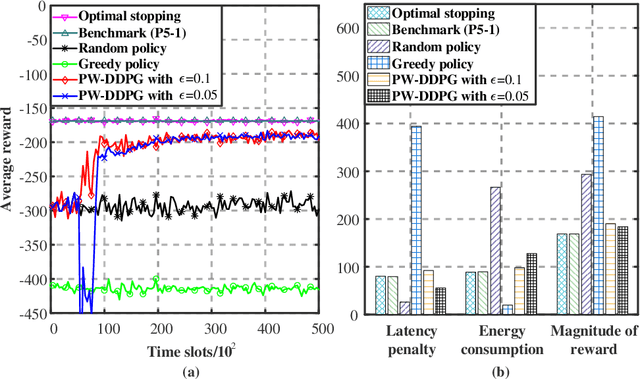
Multicasting is an efficient technique to simultaneously transmit common messages from the base station (BS) to multiple mobile users (MUs). The multicast scheduling problem for multiple messages over multiple channels, which jointly minimizes the energy consumption of the BS and the latency of serving asynchronized requests from the MUs, is formulated as an infinite-horizon Markov decision process (MDP) with large discrete action space and multiple time-varying constraints, which has not been efficiently addressed in the literatures. By studying the intrinsic features of this MDP under stationary policies and refining the reward function, we first simplify it to an equivalent form with a much smaller state space. Then, we propose a modified deep reinforcement learning (DRL) algorithm, namely the permutation-based Wolpertinger deep deterministic policy gradient (PW-DDPG), to solve the simplified problem. Specifically, PW-DDPG utilizes a permutation-based action embedding module to address the large discrete action space issue and a feasible exploration module to deal with the time-varying constraints. Moreover, as a benchmark, an upper bound of the considered MDP is derived by solving an integer programming problem. Numerical results validate that the proposed algorithm achieves close performance to the derived benchmark.
Providers-Clients-Robots: Framework for spatial-semantic planning for shared understanding in human-robot interaction
Jun 21, 2022

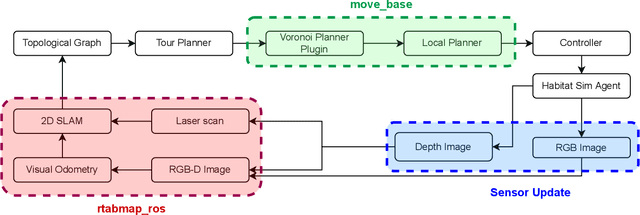
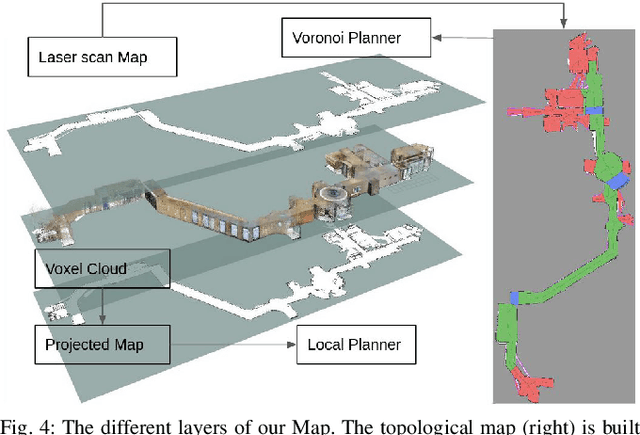
This paper develops a novel framework called Providers-Clients-Robots (PCR), applicable to socially assistive robots that support research on shared understanding in human-robot interactions. Providers, Clients, and Robots share an actionable and intuitive representation of the environment to create plans that best satisfy the combined needs of all parties. The plans are formed via interaction between the Client and the Robot based on a previously built multi-modal navigation graph. The explainable environmental representation in the form of a navigation graph is constructed collaboratively between Providers and Robots prior to interaction with Clients. We develop a realization of the proposed framework to create a spatial-semantic representation of an indoor environment autonomously. Moreover, we develop a planner that takes in constraints from Providers and Clients of the establishment and dynamically plans a sequence of visits to each area of interest. Evaluations show that the proposed realization of the PCR framework can successfully make plans while satisfying the specified time budget and sequence constraints and outperforming the greedy baseline.
Weakly Supervised Classification of Vital Sign Alerts as Real or Artifact
Jun 18, 2022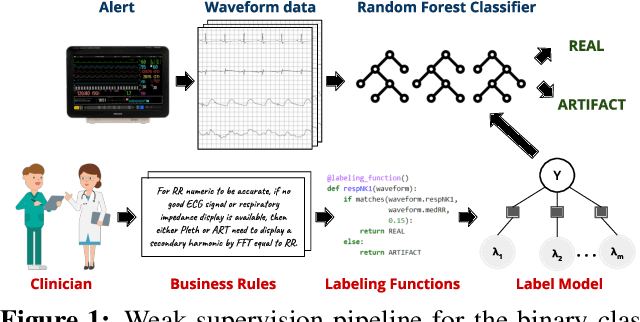

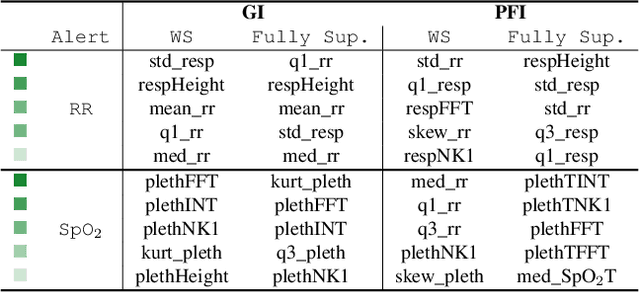
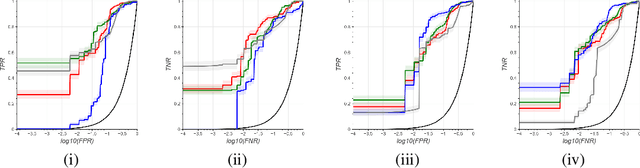
A significant proportion of clinical physiologic monitoring alarms are false. This often leads to alarm fatigue in clinical personnel, inevitably compromising patient safety. To combat this issue, researchers have attempted to build Machine Learning (ML) models capable of accurately adjudicating Vital Sign (VS) alerts raised at the bedside of hemodynamically monitored patients as real or artifact. Previous studies have utilized supervised ML techniques that require substantial amounts of hand-labeled data. However, manually harvesting such data can be costly, time-consuming, and mundane, and is a key factor limiting the widespread adoption of ML in healthcare (HC). Instead, we explore the use of multiple, individually imperfect heuristics to automatically assign probabilistic labels to unlabeled training data using weak supervision. Our weakly supervised models perform competitively with traditional supervised techniques and require less involvement from domain experts, demonstrating their use as efficient and practical alternatives to supervised learning in HC applications of ML.
A Pre-Computing Solution for Online Advertising Serving
Jul 04, 2022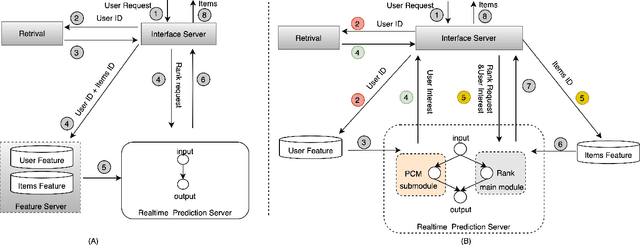

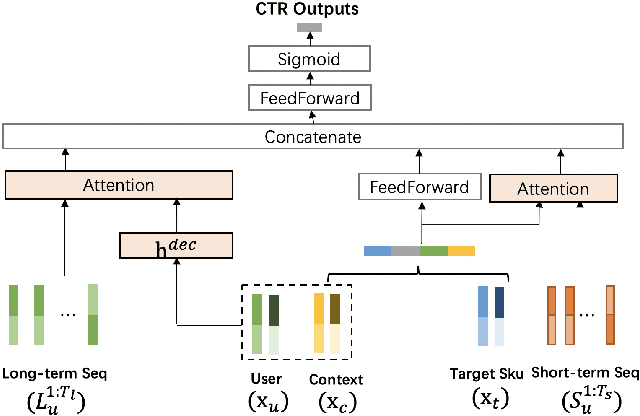
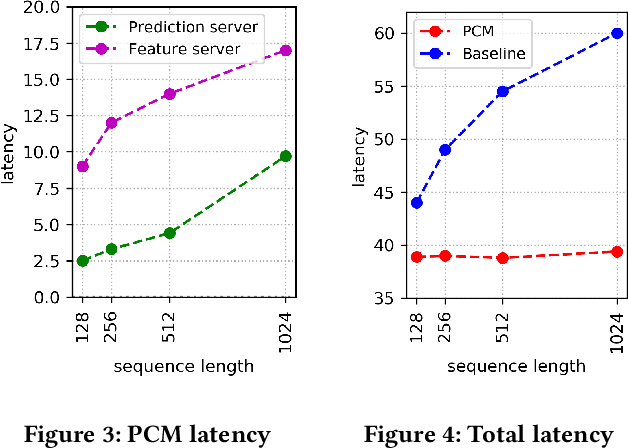
Click-Through Rate (CTR) prediction plays a key role in online advertising systems and online advertising. Constrained by strict requirements on online inference efficiency, it is often difficult to deploy useful but computationally intensive modules such as long-term behaviors modeling. Most recent works attempt to mitigate the online calculation issue of long historical behaviors by adopting two-stage methods to balance online efficiency and effectiveness. However, the information gaps caused by two-stage modeling may result in a diminished performance gain. In this work, we propose a novel framework called PCM to address this challenge in the view of system deployment. By deploying a pre-computing sub-module parallel to the retrieval stage, our PCM effectively reduces overall inference time which enables complex modeling in the ranking stage. Comprehensive offline and online experiments are conducted on the long-term user behaviors module to validate the effectiveness of our solution for the complex models. Moreover, our framework has been deployed into a large-scale real-world E-commerce system serving the main interface of hundreds of millions of active users, by deploying long sequential user behavior model in PCM. We achieved a 3\% CTR gain, with almost no increase in the ranking latency, compared to the base framework demonstrated from the online A/B test. To our knowledge, we are the first to propose an end-to-end solution for online training and deployment on complex CTR models from the system framework side.