 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pattern Sampling for Shapelet-based Time Series Classification
Feb 16, 2021
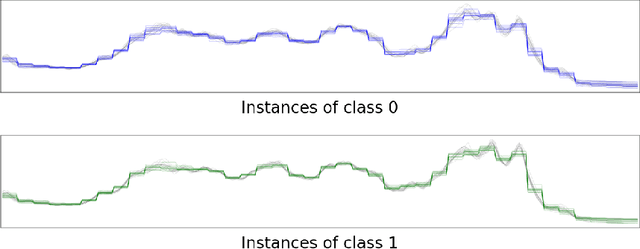
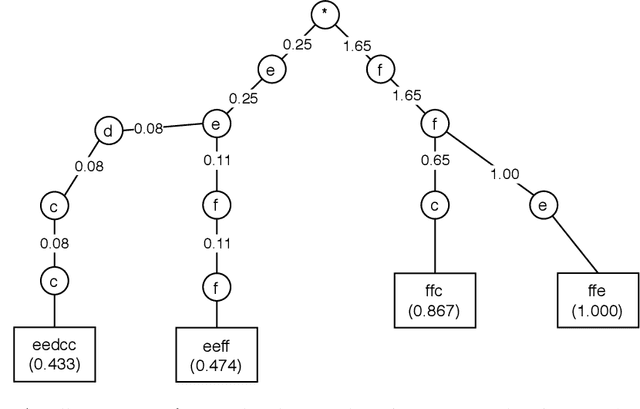
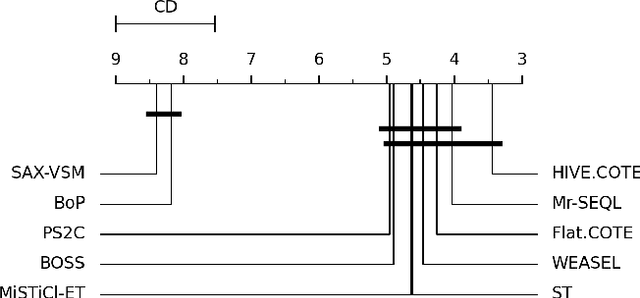
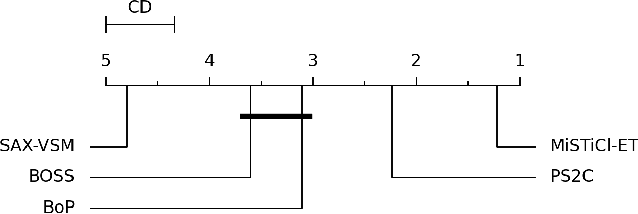
Subsequence-based time series classification algorithms provide accurate and interpretable models, but training these models is extremely computation intensive. The asymptotic time complexity of subsequence-based algorithms remains a higher-order polynomial, because these algorithms are based on exhaustive search for highly discriminative subsequences. Pattern sampling has been proposed as an effective alternative to mitigate the pattern explosion phenomenon. Therefore, we employ pattern sampling to extract discriminative features from discretized time series data. A weighted trie is created based on the discretized time series data to sample highly discriminative patterns. These sampled patterns are used to identify the shapelets which are used to transform the time series classification problem into a feature-based classification problem. Finally, a classification model can be trained using any off-the-shelf algorithm. Creating a pattern sampler requires a small number of patterns to be evaluated compared to an exhaustive search as employed by previous approaches. Compared to previously proposed algorithms, our approach requires considerably less computational and memory resources. Experiments demonstrate how the proposed approach fares in terms of classification accuracy and runtime performance.
A Neural Network-Prepended GLRT Framework for Signal Detection Under Nonlinear Distortions
Jun 15, 2022
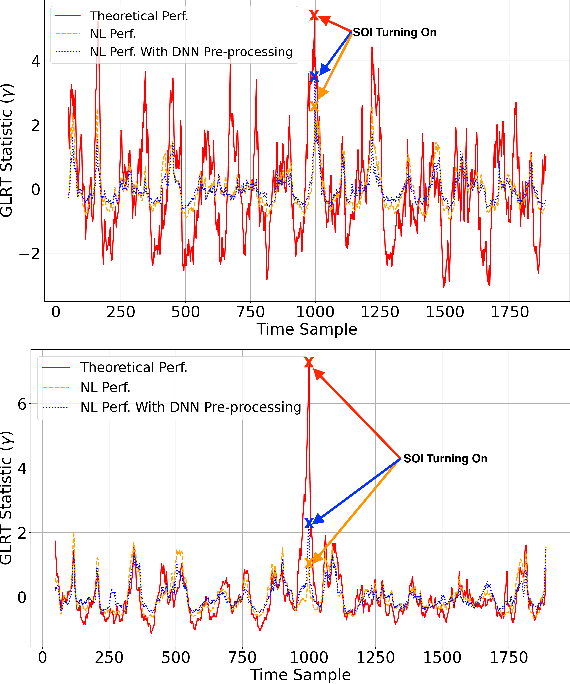
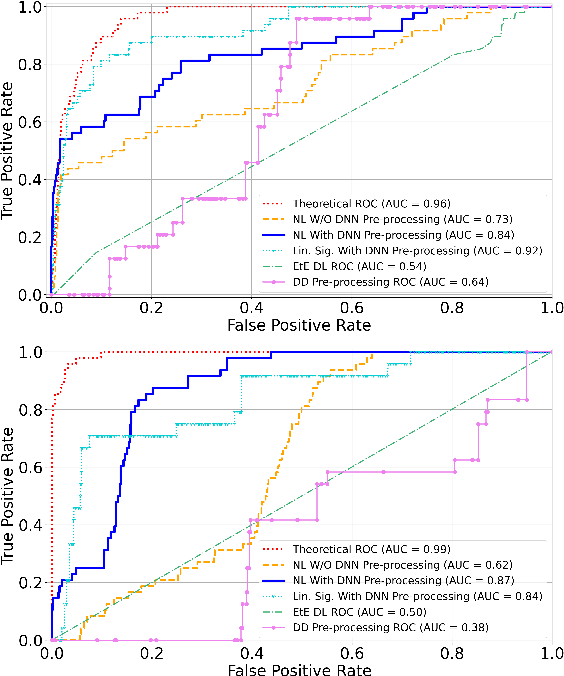
Many communications and sensing applications hinge on the detection of a signal in a noisy, interference-heavy environment. Signal processing theory yields techniques such as the generalized likelihood ratio test (GLRT) to perform detection when the received samples correspond to a linear observation model. Numerous practical applications exist, however, where the received signal has passed through a nonlinearity, causing significant performance degradation of the GLRT. In this work, we propose prepending the GLRT detector with a neural network classifier capable of identifying the particular nonlinear time samples in a received signal. We show that pre-processing received nonlinear signals using our trained classifier to eliminate excessively nonlinear samples (i) improves the detection performance of the GLRT on nonlinear signals and (ii) retains the theoretical guarantees provided by the GLRT on linear observation models for accurate signal detection.
Acquiring a Dynamic Light Field through a Single-Shot Coded Image
Apr 26, 2022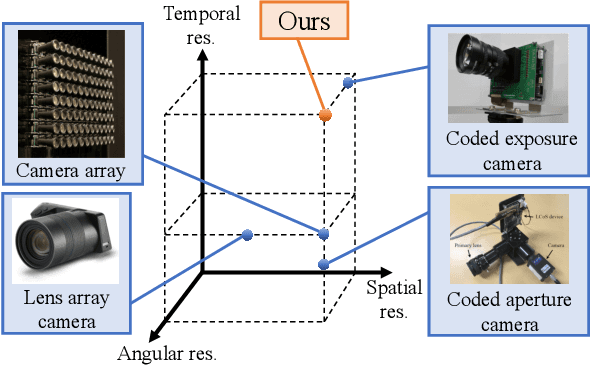
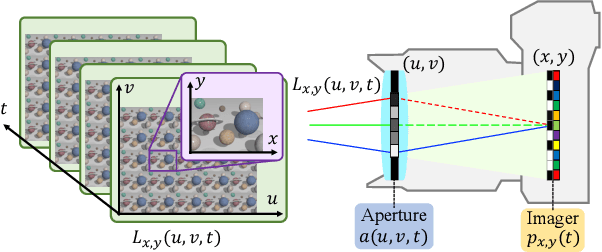
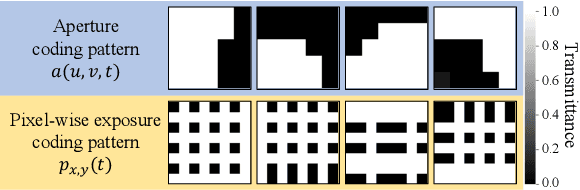

We propose a method for compressively acquiring a dynamic light field (a 5-D volume) through a single-shot coded image (a 2-D measurement). We designed an imaging model that synchronously applies aperture coding and pixel-wise exposure coding within a single exposure time. This coding scheme enables us to effectively embed the original information into a single observed image. The observed image is then fed to a convolutional neural network (CNN) for light-field reconstruction, which is jointly trained with the camera-side coding patterns. We also developed a hardware prototype to capture a real 3-D scene moving over time. We succeeded in acquiring a dynamic light field with 5x5 viewpoints over 4 temporal sub-frames (100 views in total) from a single observed image. Repeating capture and reconstruction processes over time, we can acquire a dynamic light field at 4x the frame rate of the camera. To our knowledge, our method is the first to achieve a finer temporal resolution than the camera itself in compressive light-field acquisition. Our software is available from our project webpage
Input-to-State Safety with Input Delay in Longitudinal Vehicle Control
May 29, 2022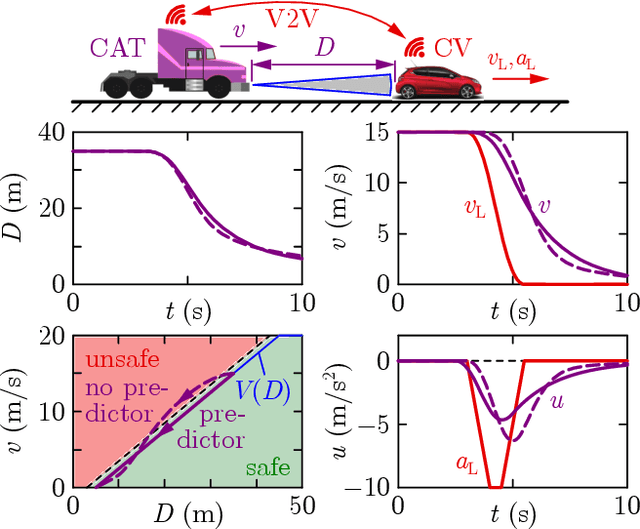
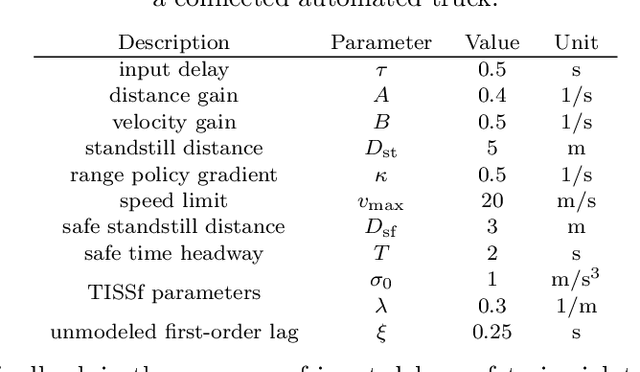
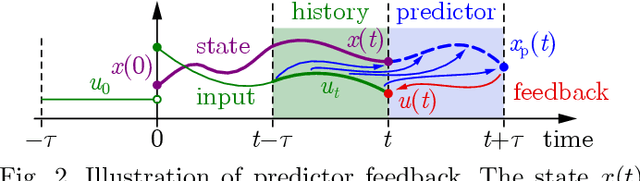
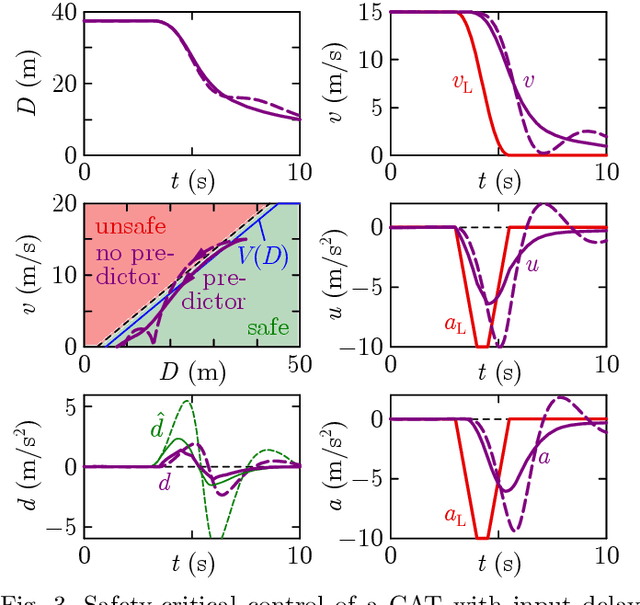
Safe longitudinal control is discussed for a connected automated truck traveling behind a preceding connected vehicle. A controller is proposed based on control barrier function theory and predictor feedback for provably safe, collision-free behavior by taking into account the significant response time of the truck as input delay and the uncertainty of its dynamical model as input disturbance. The benefits of the proposed controller compared to control designs that neglect the delay or treat the delay as disturbance are shown by numerical simulations.
Improving trajectory calculations using deep learning inspired single image superresolution
Jun 07, 2022

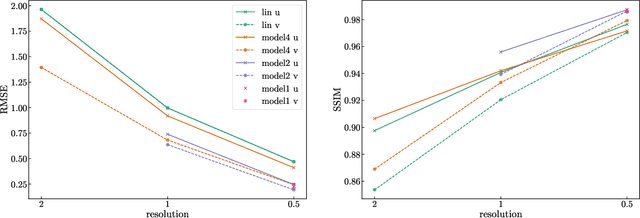

Lagrangian trajectory or particle dispersion models as well as semi-Lagrangian advection schemes require meteorological data such as wind, temperature and geopotential at the exact spatio-temporal locations of the particles that move independently from a regular grid. Traditionally, this high-resolution data has been obtained by interpolating the meteorological parameters from the gridded data of a meteorological model or reanalysis, e.g. using linear interpolation in space and time. However, interpolation errors are a large source of error for these models. Reducing them requires meteorological input fields with high space and time resolution, which may not always be available and can cause severe data storage and transfer problems. Here, we interpret this problem as a single image superresolution task. We interpret meteorological fields available at their native resolution as low-resolution images and train deep neural networks to up-scale them to higher resolution, thereby providing more accurate data for Lagrangian models. We train various versions of the state-of-the-art Enhanced Deep Residual Networks for Superresolution on low-resolution ERA5 reanalysis data with the goal to up-scale these data to arbitrary spatial resolution. We show that the resulting up-scaled wind fields have root-mean-squared errors half the size of the winds obtained with linear spatial interpolation at acceptable computational inference costs. In a test setup using the Lagrangian particle dispersion model FLEXPART and reduced-resolution wind fields, we demonstrate that absolute horizontal transport deviations of calculated trajectories from "ground-truth" trajectories calculated with undegraded 0.5{\deg} winds are reduced by at least 49.5% (21.8%) after 48 hours relative to trajectories using linear interpolation of the wind data when training on 2{\deg} to 1{\deg} (4{\deg} to 2{\deg}) resolution data.
Learning Model-Based Vehicle-Relocation Decisions for Real-Time Ride-Sharing: Hybridizing Learning and Optimization
May 27, 2021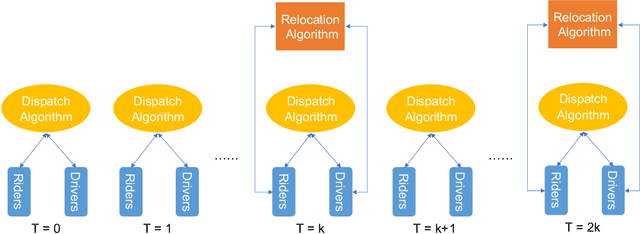

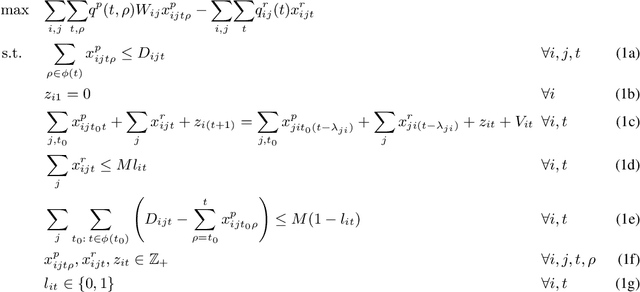
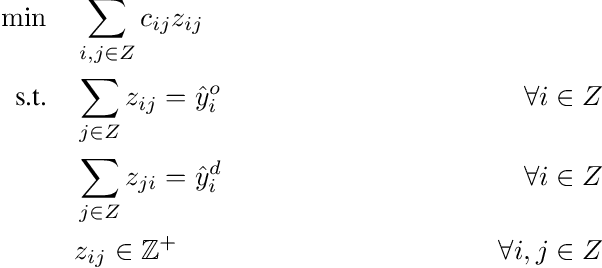
Large-scale ride-sharing systems combine real-time dispatching and routing optimization over a rolling time horizon with a model predictive control(MPC) component that relocates idle vehicles to anticipate the demand. The MPC optimization operates over a longer time horizon to compensate for the inherent myopic nature of the real-time dispatching. These longer time horizons are beneficial for the quality of the decisions but increase computational complexity. To address this computational challenge, this paper proposes a hybrid approach that combines machine learning and optimization. The machine-learning component learns the optimal solution to the MPC optimization on the aggregated level to overcome the sparsity and high-dimensionality of the MPC solutions. The optimization component transforms the machine-learning predictions back to the original granularity via a tractable transportation model. As a consequence, the original NP-hard MPC problem is reduced to a polynomial time prediction and optimization. Experimental results show that the hybrid approach achieves 27% further reduction in rider waiting time than the MPC optimization, thanks to its ability to model a longer time horizon within the computational limits.
LeNSE: Learning To Navigate Subgraph Embeddings for Large-Scale Combinatorial Optimisation
May 20, 2022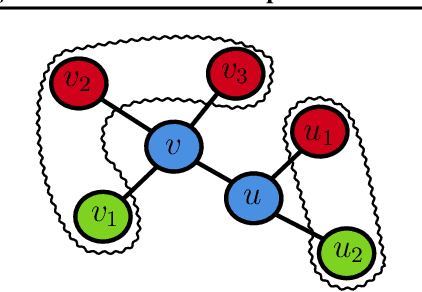
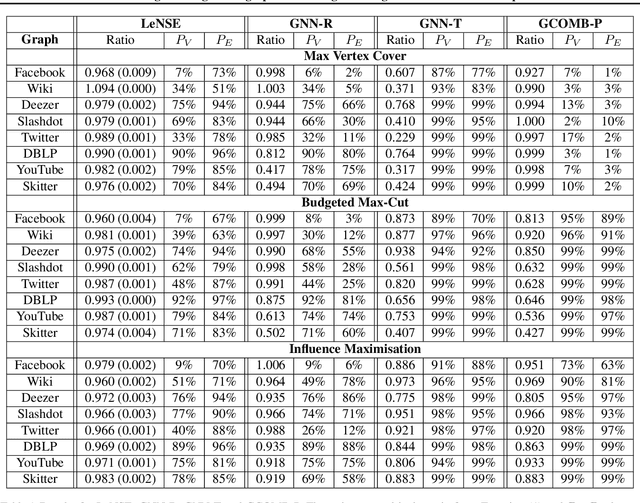
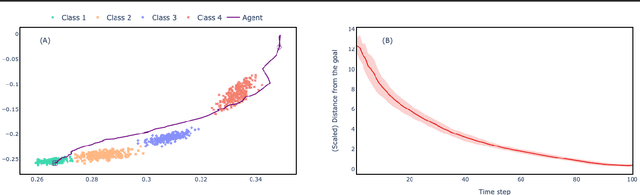
Combinatorial Optimisation problems arise in several application domains and are often formulated in terms of graphs. Many of these problems are NP-hard, but exact solutions are not always needed. Several heuristics have been developed to provide near-optimal solutions; however, they do not typically scale well with the size of the graph. We propose a low-complexity approach for identifying a (possibly much smaller) subgraph of the original graph where the heuristics can be run in reasonable time and with a high likelihood of finding a global near-optimal solution. The core component of our approach is LeNSE, a reinforcement learning algorithm that learns how to navigate the space of possible subgraphs using an Euclidean subgraph embedding as its map. To solve CO problems, LeNSE is provided with a discriminative embedding trained using any existing heuristics using only on a small portion of the original graph. When tested on three problems (vertex cover, max-cut and influence maximisation) using real graphs with up to $10$ million edges, LeNSE identifies small subgraphs yielding solutions comparable to those found by running the heuristics on the entire graph, but at a fraction of the total run time.
Frontiers and Exact Learning of ELI Queries under DL-Lite Ontologies
Apr 29, 2022We study ELI queries (ELIQs) in the presence of ontologies formulated in the description logic DL-Lite. For the dialect DL-LiteH, we show that ELIQs have a frontier (set of least general generalizations) that is of polynomial size and can be computed in polynomial time. In the dialect DL-LiteF, in contrast, frontiers may be infinite. We identify a natural syntactic restriction that enables the same positive results as for DL-LiteH. We use out results on frontiers to show that ELIQs are learnable in polynomial time in the presence of a DL-LiteH / restricted DL-LiteF ontology in Angluin's framework of exact learning with only membership queries.
Adversarial attacks on an optical neural network
Apr 29, 2022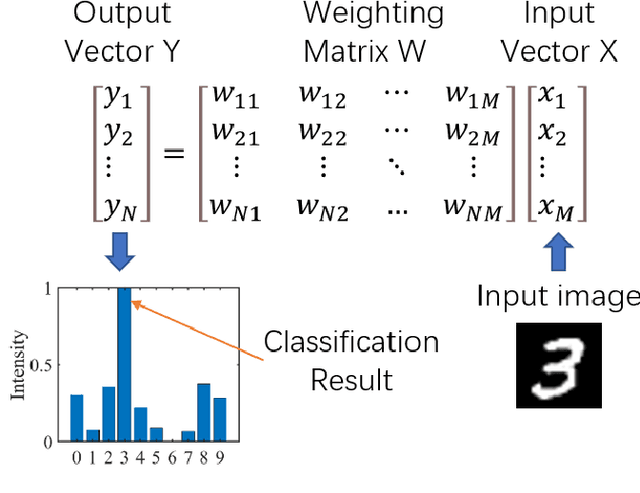
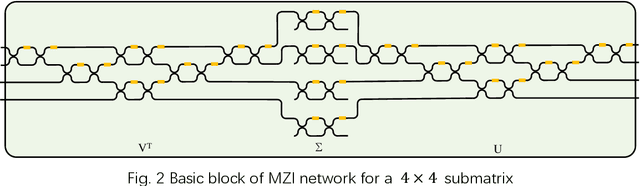
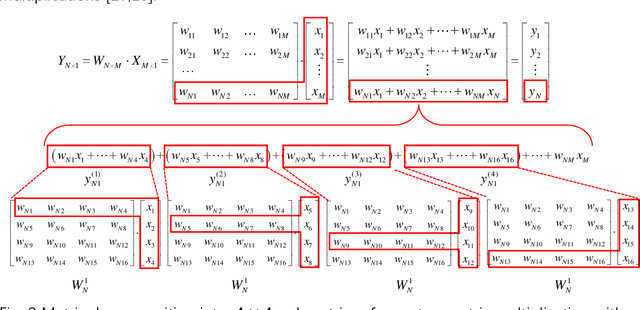
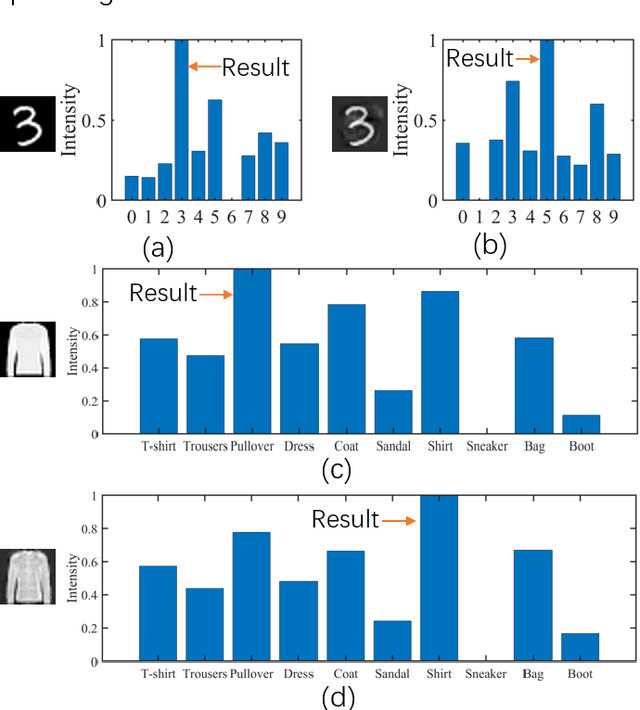
Adversarial attacks have been extensively investigated for machine learning systems including deep learning in the digital domain. However, the adversarial attacks on optical neural networks (ONN) have been seldom considered previously. In this work, we first construct an accurate image classifier with an ONN using a mesh of interconnected Mach-Zehnder interferometers (MZI). Then a corresponding adversarial attack scheme is proposed for the first time. The attacked images are visually very similar to the original ones but the ONN system becomes malfunctioned and generates wrong classification results in most time. The results indicate that adversarial attack is also a significant issue for optical machine learning systems.
iMAP: Implicit Mapping and Positioning in Real-Time
Mar 23, 2021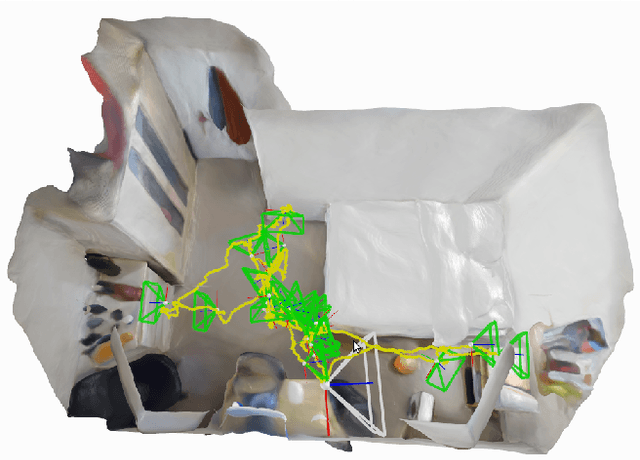
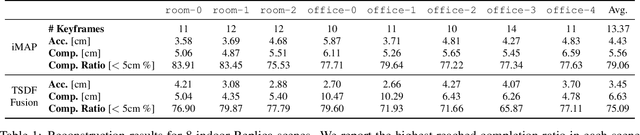
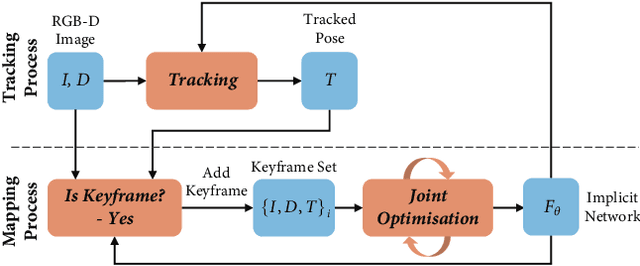

We show for the first time that a multilayer perceptron (MLP) can serve as the only scene representation in a real-time SLAM system for a handheld RGB-D camera. Our network is trained in live operation without prior data, building a dense, scene-specific implicit 3D model of occupancy and colour which is also immediately used for tracking. Achieving real-time SLAM via continual training of a neural network against a live image stream requires significant innovation. Our iMAP algorithm uses a keyframe structure and multi-processing computation flow, with dynamic information-guided pixel sampling for speed, with tracking at 10 Hz and global map updating at 2 Hz. The advantages of an implicit MLP over standard dense SLAM techniques include efficient geometry representation with automatic detail control and smooth, plausible filling-in of unobserved regions such as the back surfaces of objects.