 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Policy Optimization with Generalist-Specialist Learning
Jun 26, 2022
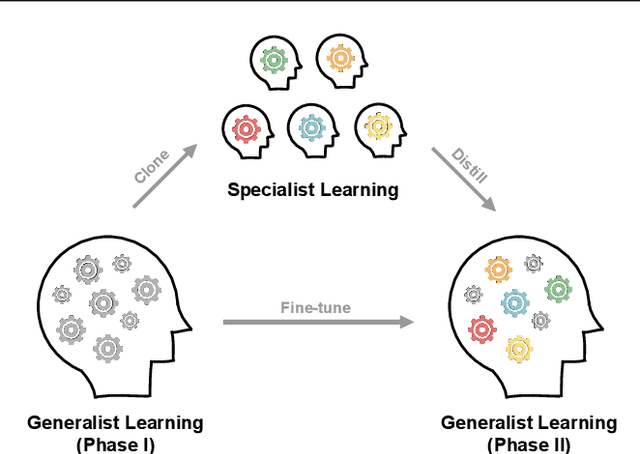

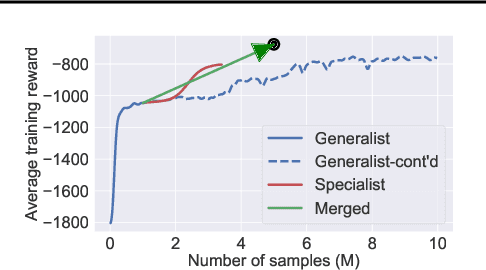

Generalization in deep reinforcement learning over unseen environment variations usually requires policy learning over a large set of diverse training variations. We empirically observe that an agent trained on many variations (a generalist) tends to learn faster at the beginning, yet its performance plateaus at a less optimal level for a long time. In contrast, an agent trained only on a few variations (a specialist) can often achieve high returns under a limited computational budget. To have the best of both worlds, we propose a novel generalist-specialist training framework. Specifically, we first train a generalist on all environment variations; when it fails to improve, we launch a large population of specialists with weights cloned from the generalist, each trained to master a selected small subset of variations. We finally resume the training of the generalist with auxiliary rewards induced by demonstrations of all specialists. In particular, we investigate the timing to start specialist training and compare strategies to learn generalists with assistance from specialists. We show that this framework pushes the envelope of policy learning on several challenging and popular benchmarks including Procgen, Meta-World and ManiSkill.
Ensemble random forest filter: An alternative to the ensemble Kalman filter for inverse modeling
Jul 08, 2022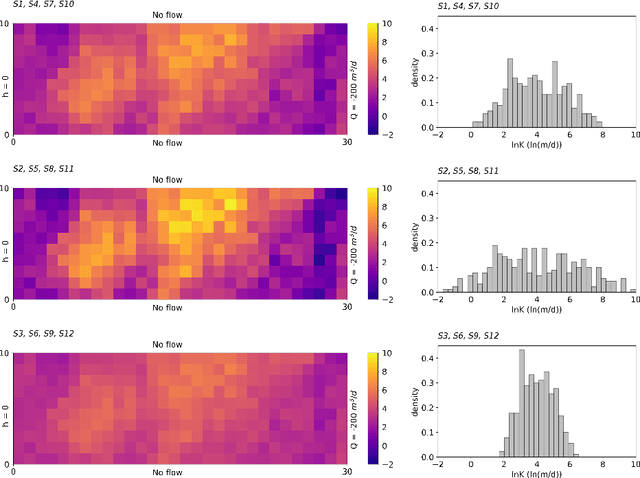
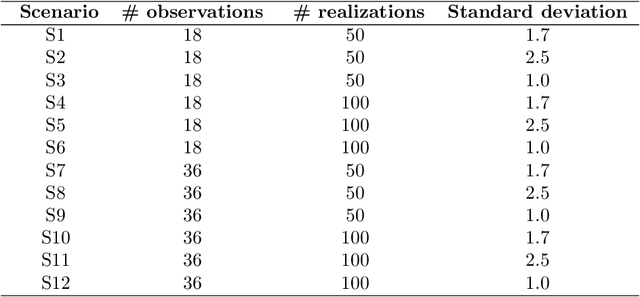

The ensemble random forest filter (ERFF) is presented as an alternative to the ensemble Kalman filter (EnKF) for the purpose of inverse modeling. The EnKF is a data assimilation approach that forecasts and updates parameter estimates sequentially in time as observations are being collected. The updating step is based on the experimental covariances computed from an ensemble of realizations and the updates are given as linear combinations of the differences between observations and forecasted system state values. The ERFF replaces the linear combination in the update step with a non-linear function represented by a random forest. In this way, the non-linear relationships between the parameters to be updated and the observations can be captured and a better update produced. The ERFF is demonstrated for the purpose of log-conductivity identification from piezometric head observations in a number of scenarios with varying degrees of heterogeneity (log-conductivity variances going from 1 up to 6.25 (ln m/d)2), number of realizations in the ensemble (50 or 100), and number of piezometric head observations (18 or 36). In all scenarios, the ERFF works well, being able to reconstruct the log-conductivity spatial heterogeneity while matching the observed piezometric heads at selected control points. For benchmarking purposes the ERFF is compared to the restart EnKF to find that the ERFF is superior to the EnKF for the number of ensemble realizations used (small in typical EnKF applications). Only when the number of realizations grows to 500, the restart EnKF is able to match the performance of the ERFF, albeit at triple the computational cost.
Inferring Granger Causality from Irregularly Sampled Time Series
Jun 04, 2021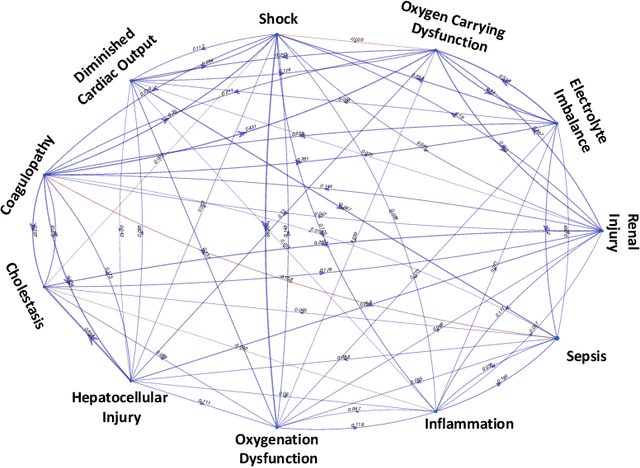
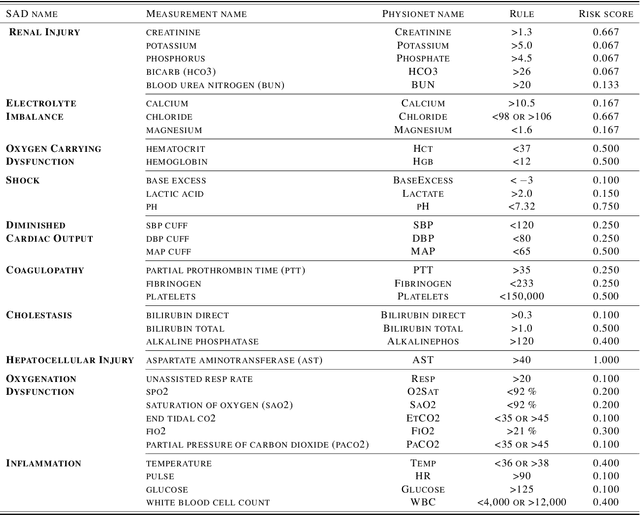
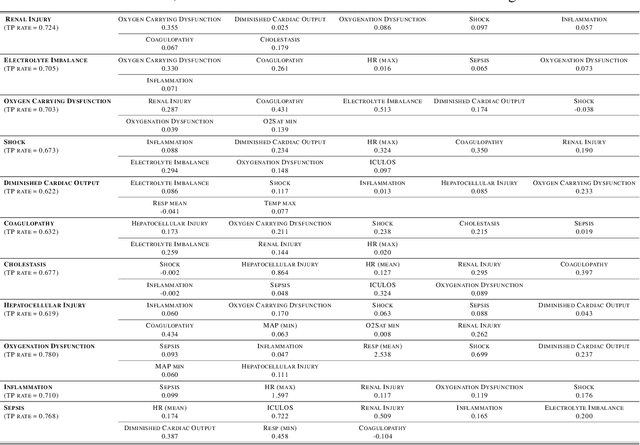
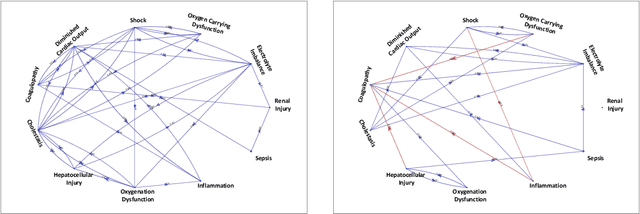
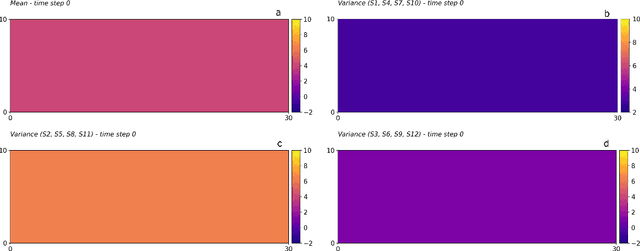
Continuous, automated surveillance systems that incorporate machine learning models are becoming increasingly more common in healthcare environments. These models can capture temporally dependent changes across multiple patient variables and can enhance a clinician's situational awareness by providing an early warning alarm of an impending adverse event such as sepsis. However, most commonly used methods, e.g., XGBoost, fail to provide an interpretable mechanism for understanding why a model produced a sepsis alarm at a given time. The black-box nature of many models is a severe limitation as it prevents clinicians from independently corroborating those physiologic features that have contributed to the sepsis alarm. To overcome this limitation, we propose a generalized linear model (GLM) approach to fit a Granger causal graph based on the physiology of several major sepsis-associated derangements (SADs). We adopt a recently developed stochastic monotone variational inequality-based estimator coupled with forwarding feature selection to learn the graph structure from both continuous and discrete-valued as well as regularly and irregularly sampled time series. Most importantly, we develop a non-asymptotic upper bound on the estimation error for any monotone link function in the GLM. We conduct real-data experiments and demonstrate that our proposed method can achieve comparable performance to popular and powerful prediction methods such as XGBoost while simultaneously maintaining a high level of interpretability.
Pattern Sampling for Shapelet-based Time Series Classification
Feb 16, 2021
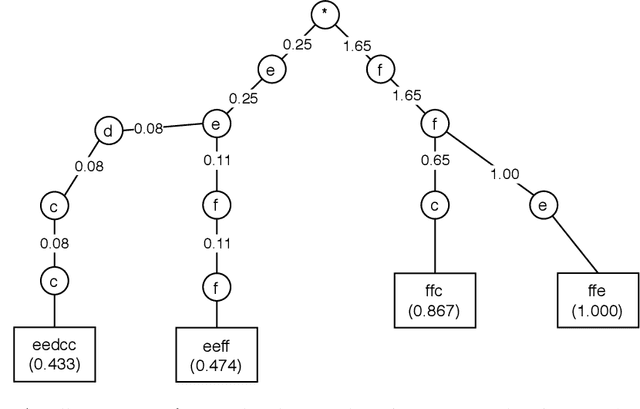
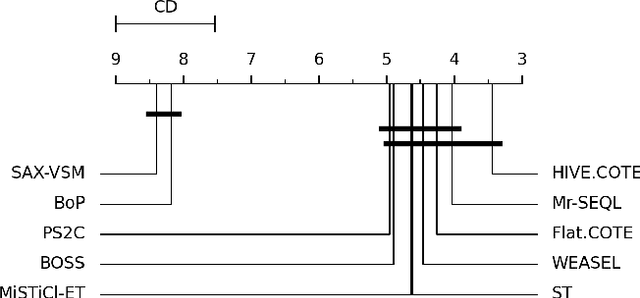
Subsequence-based time series classification algorithms provide accurate and interpretable models, but training these models is extremely computation intensive. The asymptotic time complexity of subsequence-based algorithms remains a higher-order polynomial, because these algorithms are based on exhaustive search for highly discriminative subsequences. Pattern sampling has been proposed as an effective alternative to mitigate the pattern explosion phenomenon. Therefore, we employ pattern sampling to extract discriminative features from discretized time series data. A weighted trie is created based on the discretized time series data to sample highly discriminative patterns. These sampled patterns are used to identify the shapelets which are used to transform the time series classification problem into a feature-based classification problem. Finally, a classification model can be trained using any off-the-shelf algorithm. Creating a pattern sampler requires a small number of patterns to be evaluated compared to an exhaustive search as employed by previous approaches. Compared to previously proposed algorithms, our approach requires considerably less computational and memory resources. Experiments demonstrate how the proposed approach fares in terms of classification accuracy and runtime performance.
Electricity Consumption Forecasting for Out-of-distribution Time-of-Use Tariffs
Feb 11, 2022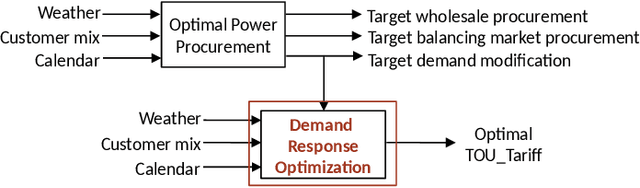
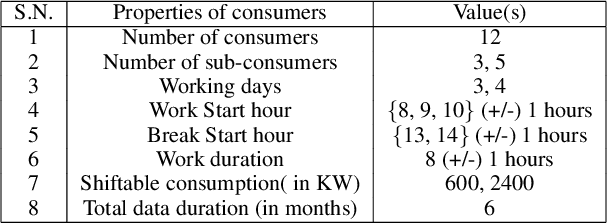
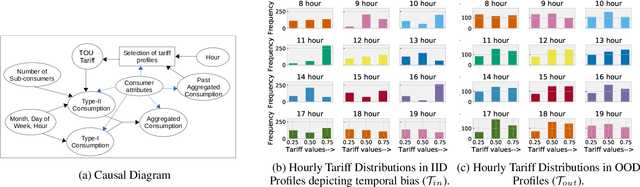

In electricity markets, retailers or brokers want to maximize profits by allocating tariff profiles to end consumers. One of the objectives of such demand response management is to incentivize the consumers to adjust their consumption so that the overall electricity procurement in the wholesale markets is minimized, e.g. it is desirable that consumers consume less during peak hours when cost of procurement for brokers from wholesale markets are high. We consider a greedy solution to maximize the overall profit for brokers by optimal tariff profile allocation. This in-turn requires forecasting electricity consumption for each user for all tariff profiles. This forecasting problem is challenging compared to standard forecasting problems due to following reasons: i. the number of possible combinations of hourly tariffs is high and retailers may not have considered all combinations in the past resulting in a biased set of tariff profiles tried in the past, ii. the profiles allocated in the past to each user is typically based on certain policy. These reasons violate the standard i.i.d. assumptions, as there is a need to evaluate new tariff profiles on existing customers and historical data is biased by the policies used in the past for tariff allocation. In this work, we consider several scenarios for forecasting and optimization under these conditions. We leverage the underlying structure of how consumers respond to variable tariff rates by comparing tariffs across hours and shifting loads, and propose suitable inductive biases in the design of deep neural network based architectures for forecasting under such scenarios. More specifically, we leverage attention mechanisms and permutation equivariant networks that allow desirable processing of tariff profiles to learn tariff representations that are insensitive to the biases in the data and still representative of the task.
A Review of Published Machine Learning Natural Language Processing Applications for Protocolling Radiology Imaging
Jun 23, 2022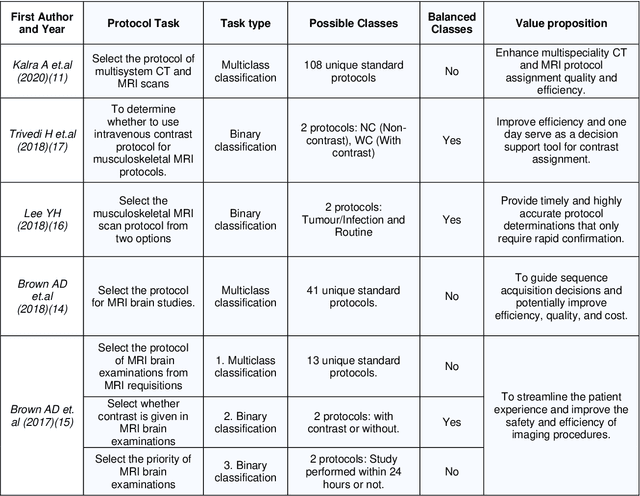
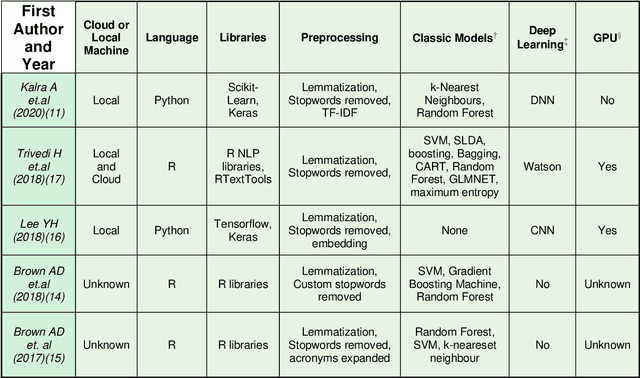
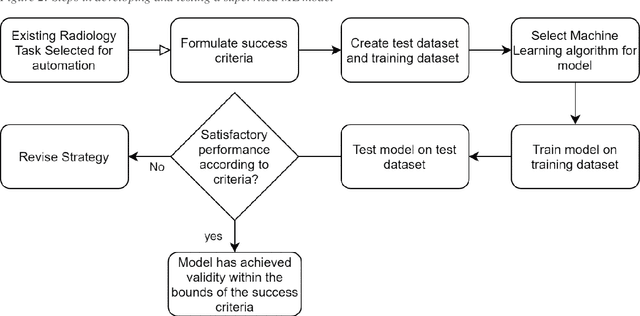
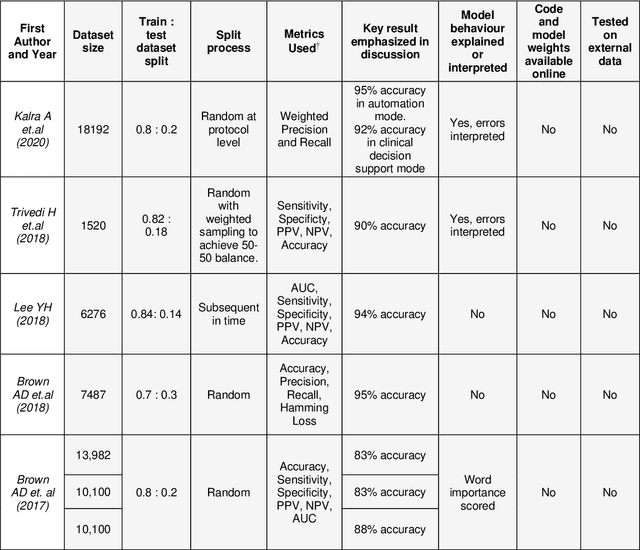
Machine learning (ML) is a subfield of Artificial intelligence (AI), and its applications in radiology are growing at an ever-accelerating rate. The most studied ML application is the automated interpretation of images. However, natural language processing (NLP), which can be combined with ML for text interpretation tasks, also has many potential applications in radiology. One such application is automation of radiology protocolling, which involves interpreting a clinical radiology referral and selecting the appropriate imaging technique. It is an essential task which ensures that the correct imaging is performed. However, the time that a radiologist must dedicate to protocolling could otherwise be spent reporting, communicating with referrers, or teaching. To date, there have been few publications in which ML models were developed that use clinical text to automate protocol selection. This article reviews the existing literature in this field. A systematic assessment of the published models is performed with reference to best practices suggested by machine learning convention. Progress towards implementing automated protocolling in a clinical setting is discussed.
Cliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments
May 17, 2022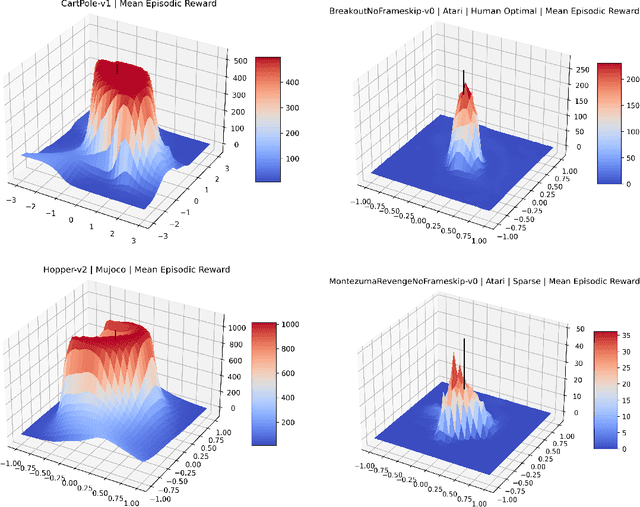
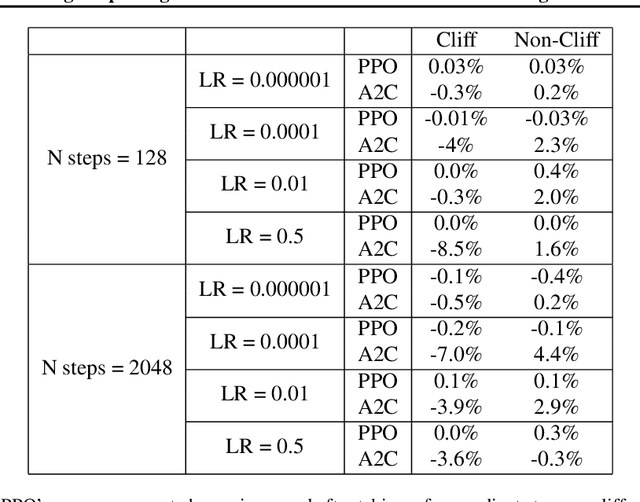
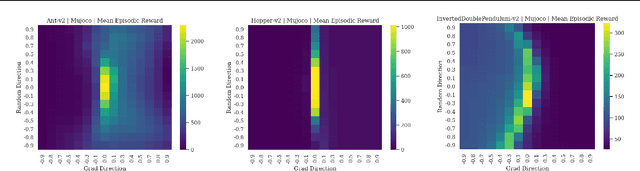
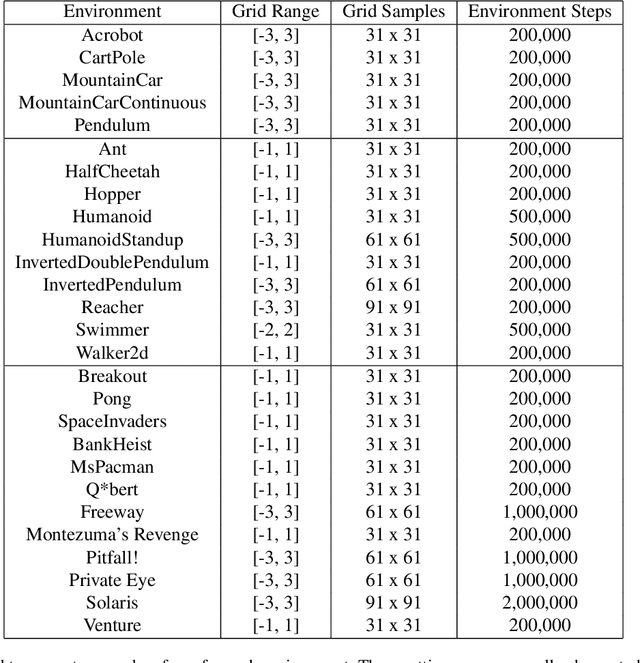
Visualizing optimization landscapes has led to many fundamental insights in numeric optimization, and novel improvements to optimization techniques. However, visualizations of the objective that reinforcement learning optimizes (the "reward surface") have only ever been generated for a small number of narrow contexts. This work presents reward surfaces and related visualizations of 27 of the most widely used reinforcement learning environments in Gym for the first time. We also explore reward surfaces in the policy gradient direction and show for the first time that many popular reinforcement learning environments have frequent "cliffs" (sudden large drops in expected return). We demonstrate that A2C often "dives off" these cliffs into low reward regions of the parameter space while PPO avoids them, confirming a popular intuition for PPO's improved performance over previous methods. We additionally introduce a highly extensible library that allows researchers to easily generate these visualizations in the future. Our findings provide new intuition to explain the successes and failures of modern RL methods, and our visualizations concretely characterize several failure modes of reinforcement learning agents in novel ways.
Learning Model-Based Vehicle-Relocation Decisions for Real-Time Ride-Sharing: Hybridizing Learning and Optimization
May 27, 2021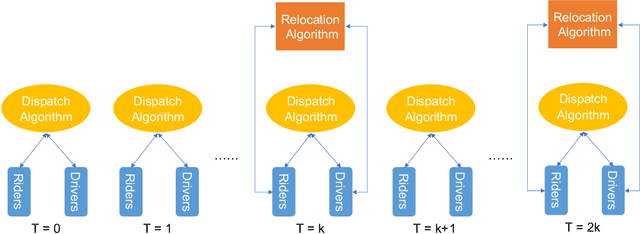

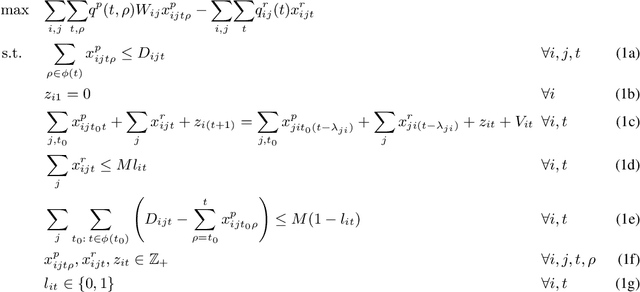
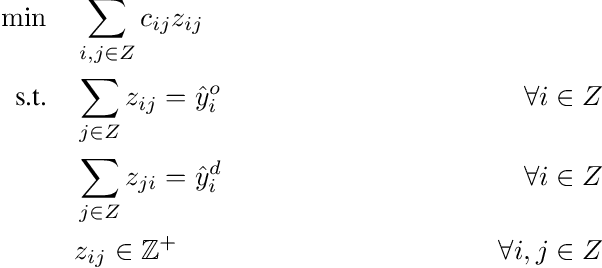
Large-scale ride-sharing systems combine real-time dispatching and routing optimization over a rolling time horizon with a model predictive control(MPC) component that relocates idle vehicles to anticipate the demand. The MPC optimization operates over a longer time horizon to compensate for the inherent myopic nature of the real-time dispatching. These longer time horizons are beneficial for the quality of the decisions but increase computational complexity. To address this computational challenge, this paper proposes a hybrid approach that combines machine learning and optimization. The machine-learning component learns the optimal solution to the MPC optimization on the aggregated level to overcome the sparsity and high-dimensionality of the MPC solutions. The optimization component transforms the machine-learning predictions back to the original granularity via a tractable transportation model. As a consequence, the original NP-hard MPC problem is reduced to a polynomial time prediction and optimization. Experimental results show that the hybrid approach achieves 27% further reduction in rider waiting time than the MPC optimization, thanks to its ability to model a longer time horizon within the computational limits.
Entropy-driven Sampling and Training Scheme for Conditional Diffusion Generation
Jun 23, 2022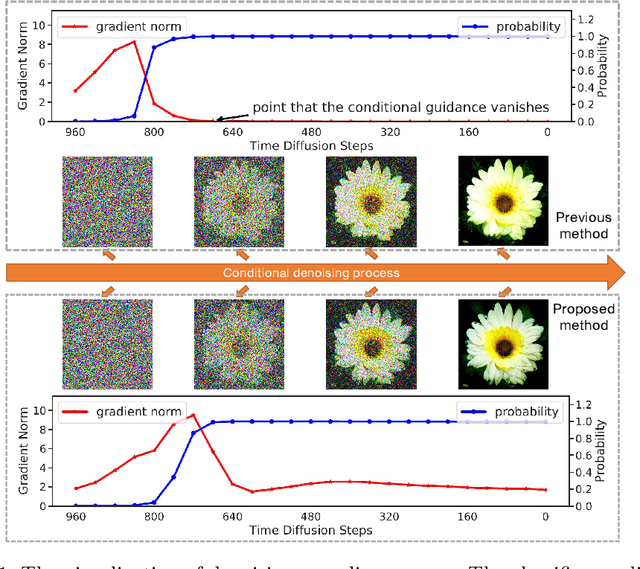
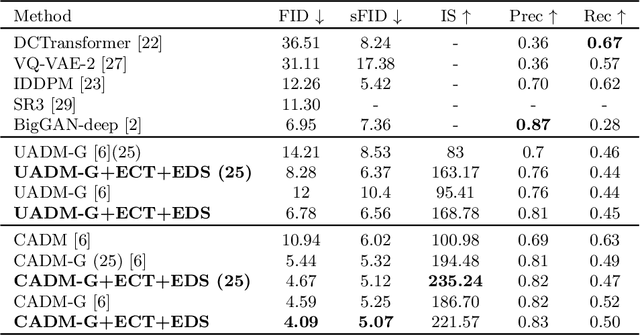
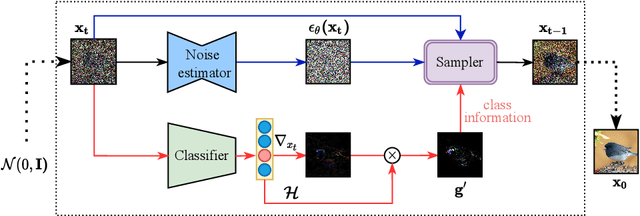
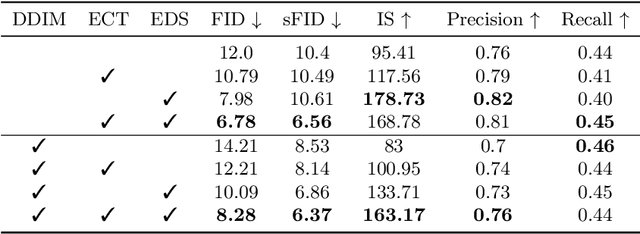
Denoising Diffusion Probabilistic Model (DDPM) is able to make flexible conditional image generation from prior noise to real data, by introducing an independent noise-aware classifier to provide conditional gradient guidance at each time step of denoising process. However, due to the ability of classifier to easily discriminate an incompletely generated image only with high-level structure, the gradient, which is a kind of class information guidance, tends to vanish early, leading to the collapse from conditional generation process into the unconditional process. To address this problem, we propose two simple but effective approaches from two perspectives. For sampling procedure, we introduce the entropy of predicted distribution as the measure of guidance vanishing level and propose an entropy-aware scaling method to adaptively recover the conditional semantic guidance. % for each generated sample. For training stage, we propose the entropy-aware optimization objectives to alleviate the overconfident prediction for noisy data.On ImageNet1000 256x256, with our proposed sampling scheme and trained classifier, the pretrained conditional and unconditional DDPM model can achieve 10.89% (4.59 to 4.09) and 43.5% (12 to 6.78) FID improvement respectively.
EXODUS: Stable and Efficient Training of Spiking Neural Networks
May 20, 2022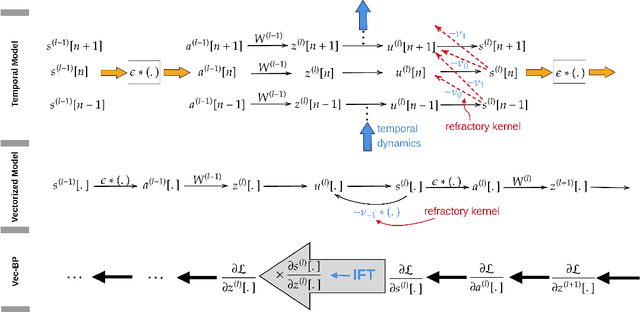
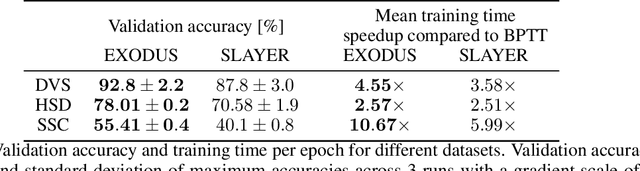
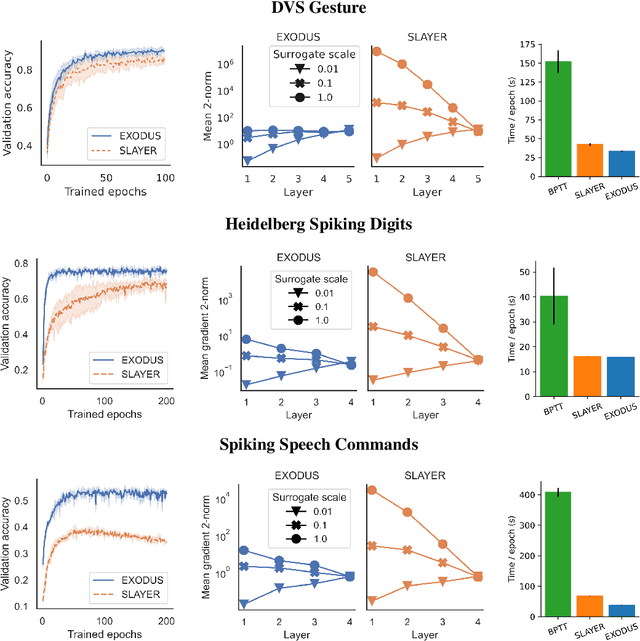

Spiking Neural Networks (SNNs) are gaining significant traction in machine learning tasks where energy-efficiency is of utmost importance. Training such networks using the state-of-the-art back-propagation through time (BPTT) is, however, very time-consuming. Previous work by Shrestha and Orchard [2018] employs an efficient GPU-accelerated back-propagation algorithm called SLAYER, which speeds up training considerably. SLAYER, however, does not take into account the neuron reset mechanism while computing the gradients, which we argue to be the source of numerical instability. To counteract this, SLAYER introduces a gradient scale hyperparameter across layers, which needs manual tuning. In this paper, (i) we modify SLAYER and design an algorithm called EXODUS, that accounts for the neuron reset mechanism and applies the Implicit Function Theorem (IFT) to calculate the correct gradients (equivalent to those computed by BPTT), (ii) we eliminate the need for ad-hoc scaling of gradients, thus, reducing the training complexity tremendously, (iii) we demonstrate, via computer simulations, that EXODUS is numerically stable and achieves a comparable or better performance than SLAYER especially in various tasks with SNNs that rely on temporal features. Our code is available at https://github.com/synsense/sinabs-exodus.