 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Aug-NeRF: Training Stronger Neural Radiance Fields with Triple-Level Physically-Grounded Augmentations
Jul 04, 2022
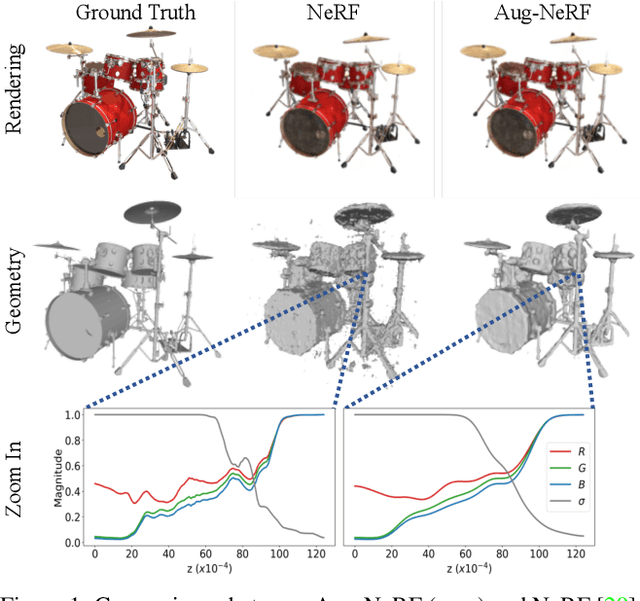
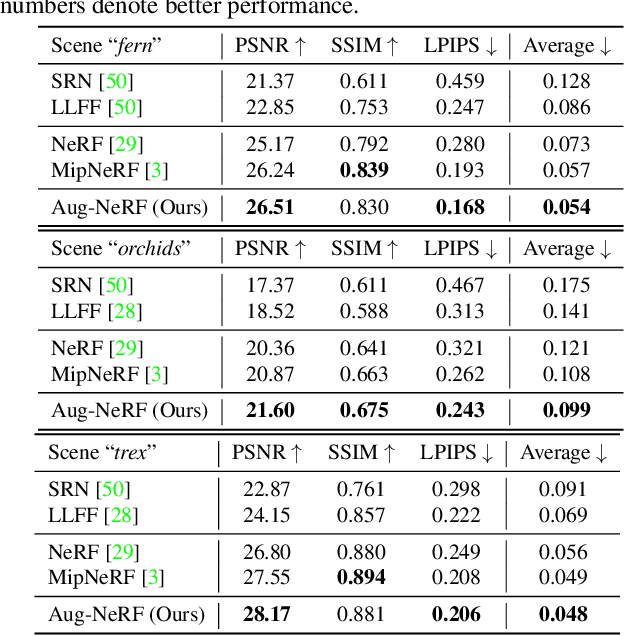
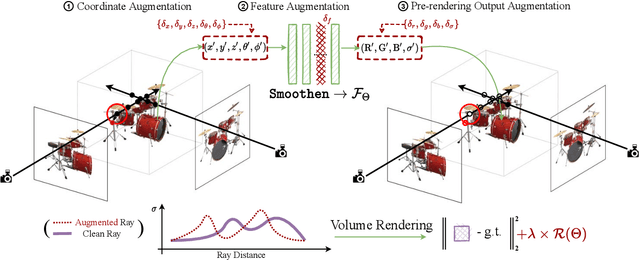
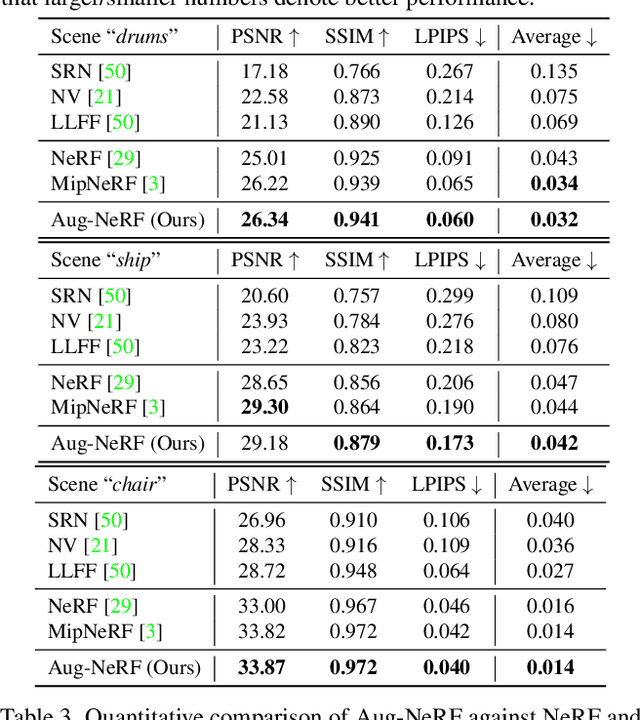
Neural Radiance Field (NeRF) regresses a neural parameterized scene by differentially rendering multi-view images with ground-truth supervision. However, when interpolating novel views, NeRF often yields inconsistent and visually non-smooth geometric results, which we consider as a generalization gap between seen and unseen views. Recent advances in convolutional neural networks have demonstrated the promise of advanced robust data augmentations, either random or learned, in enhancing both in-distribution and out-of-distribution generalization. Inspired by that, we propose Augmented NeRF (Aug-NeRF), which for the first time brings the power of robust data augmentations into regularizing the NeRF training. Particularly, our proposal learns to seamlessly blend worst-case perturbations into three distinct levels of the NeRF pipeline with physical grounds, including (1) the input coordinates, to simulate imprecise camera parameters at image capture; (2) intermediate features, to smoothen the intrinsic feature manifold; and (3) pre-rendering output, to account for the potential degradation factors in the multi-view image supervision. Extensive results demonstrate that Aug-NeRF effectively boosts NeRF performance in both novel view synthesis (up to 1.5dB PSNR gain) and underlying geometry reconstruction. Furthermore, thanks to the implicit smooth prior injected by the triple-level augmentations, Aug-NeRF can even recover scenes from heavily corrupted images, a highly challenging setting untackled before. Our codes are available in https://github.com/VITA-Group/Aug-NeRF.
Improving saliency models' predictions of the next fixation with humans' intrinsic cost of gaze shifts
Jul 09, 2022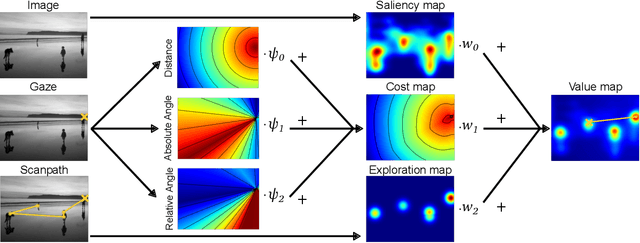
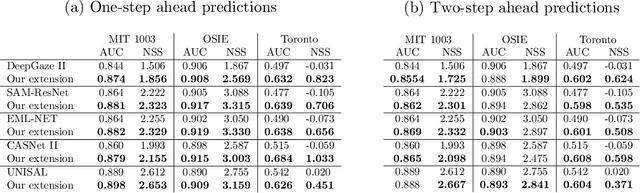
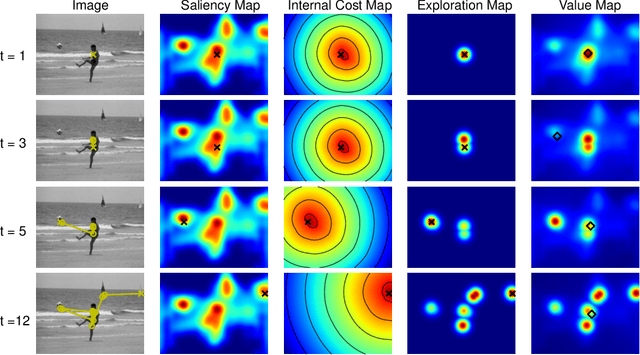
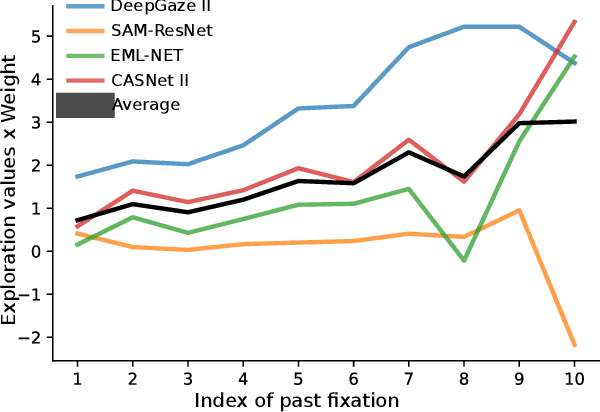
The human prioritization of image regions can be modeled in a time invariant fashion with saliency maps or sequentially with scanpath models. However, while both types of models have steadily improved on several benchmarks and datasets, there is still a considerable gap in predicting human gaze. Here, we leverage two recent developments to reduce this gap: theoretical analyses establishing a principled framework for predicting the next gaze target and the empirical measurement of the human cost for gaze switches independently of image content. We introduce an algorithm in the framework of sequential decision making, which converts any static saliency map into a sequence of dynamic history-dependent value maps, which are recomputed after each gaze shift. These maps are based on 1) a saliency map provided by an arbitrary saliency model, 2) the recently measured human cost function quantifying preferences in magnitude and direction of eye movements, and 3) a sequential exploration bonus, which changes with each subsequent gaze shift. The parameters of the spatial extent and temporal decay of this exploration bonus are estimated from human gaze data. The relative contributions of these three components were optimized on the MIT1003 dataset for the NSS score and are sufficient to significantly outperform predictions of the next gaze target on NSS and AUC scores for five state of the art saliency models on three image data sets. Thus, we provide an implementation of human gaze preferences, which can be used to improve arbitrary saliency models' predictions of humans' next gaze targets.
Automatic Prosody Annotation with Pre-Trained Text-Speech Model
Jun 16, 2022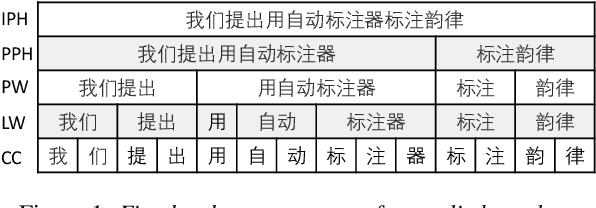
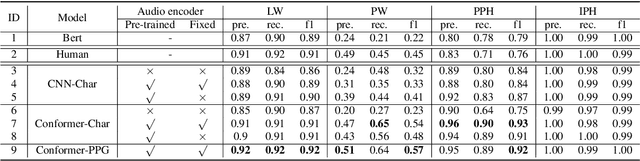
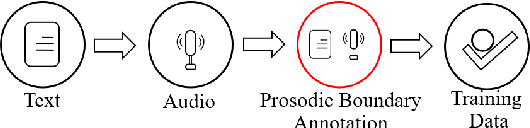

Prosodic boundary plays an important role in text-to-speech synthesis (TTS) in terms of naturalness and readability. However, the acquisition of prosodic boundary labels relies on manual annotation, which is costly and time-consuming. In this paper, we propose to automatically extract prosodic boundary labels from text-audio data via a neural text-speech model with pre-trained audio encoders. This model is pre-trained on text and speech data separately and jointly fine-tuned on TTS data in a triplet format: {speech, text, prosody}. The experimental results on both automatic evaluation and human evaluation demonstrate that: 1) the proposed text-speech prosody annotation framework significantly outperforms text-only baselines; 2) the quality of automatic prosodic boundary annotations is comparable to human annotations; 3) TTS systems trained with model-annotated boundaries are slightly better than systems that use manual ones.
Deep-learned orthogonal basis patterns for fast, noise-robust single-pixel imaging
May 18, 2022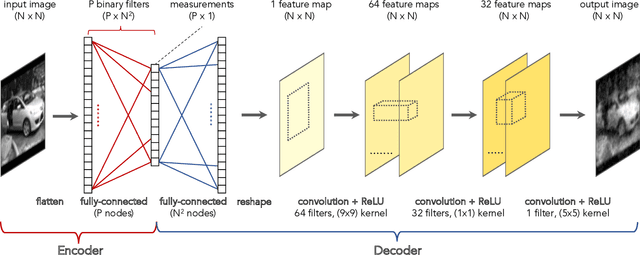

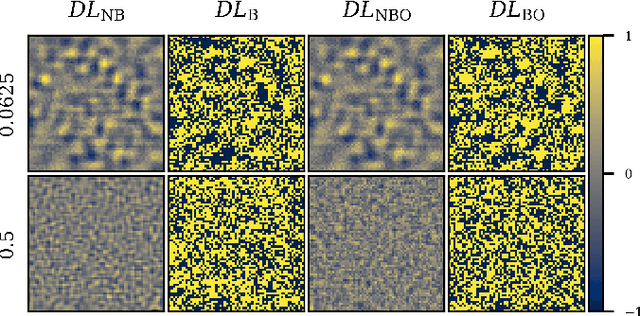
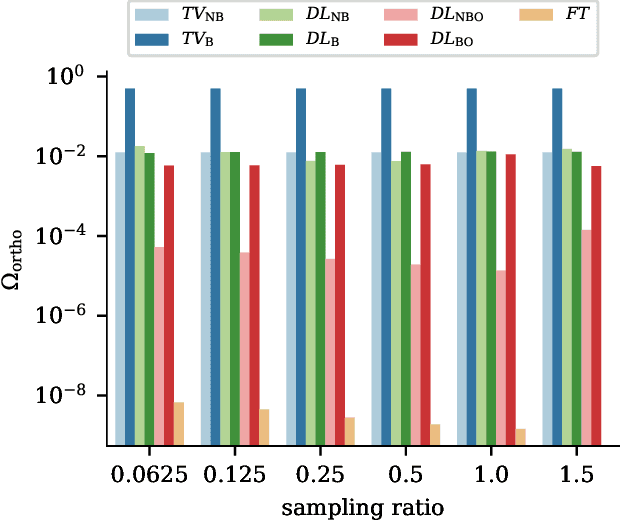
Single-pixel imaging (SPI) is a novel, unconventional method that goes beyond the notion of traditional cameras but can be computationally expensive and slow for real-time applications. Deep learning has been proposed as an alternative approach for solving the SPI reconstruction problem, but a detailed analysis of its performance and generated basis patterns when used for SPI is limited. We present a modified deep convolutional autoencoder network (DCAN) for SPI on 64x64 pixel images with up to 6.25% compression ratio and apply binary and orthogonality regularizers during training. Training a DCAN with these regularizers allows it to learn multiple measurement bases that have combinations of binary or non-binary, and orthogonal or non-orthogonal patterns. We compare the reconstruction quality, orthogonality of the patterns, and robustness to noise of the resulting DCAN models to traditional SPI reconstruction algorithms (such as Total Variation minimization and Fourier Transform). Our DCAN models can be trained to be robust to noise while still having fast enough reconstruction times (~3 ms per frame) to be viable for real-time imaging.
Recent Trends and Future Prospects of Neural Recording Circuits and Systems: A Tutorial Brief
May 27, 2022
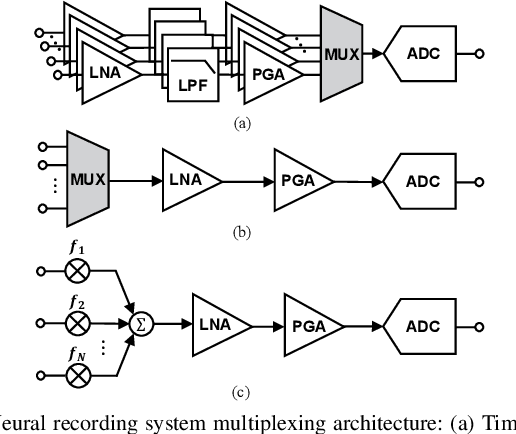
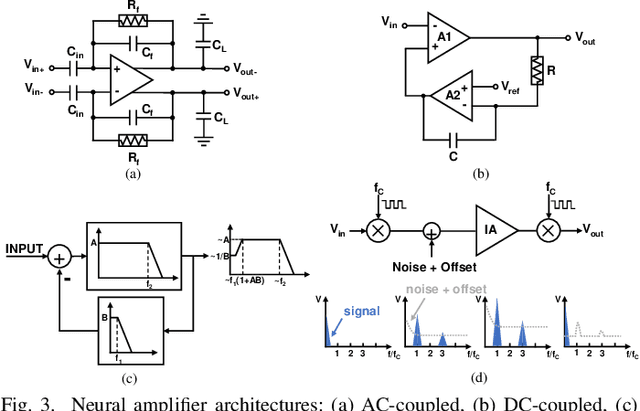
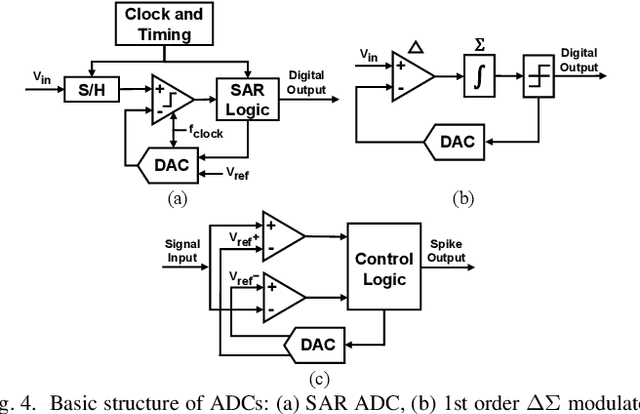
Recent years have seen fast advances in neural recording circuits and systems as they offer a promising way to investigate real-time brain monitoring and the closed-loop modulation of psychological disorders and neurodegenerative diseases. In this context, this tutorial brief presents a concise overview of concepts and design methodologies of neural recording, highlighting neural signal characteristics, system-level specifications and architectures, circuit-level implementation, and noise reduction techniques. Future trends and challenges of neural recording are finally discussed.
Squeeze All: Novel Estimator and Self-Normalized Bound for Linear Contextual Bandits
Jun 16, 2022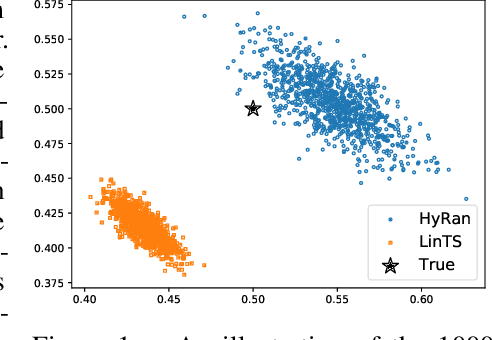
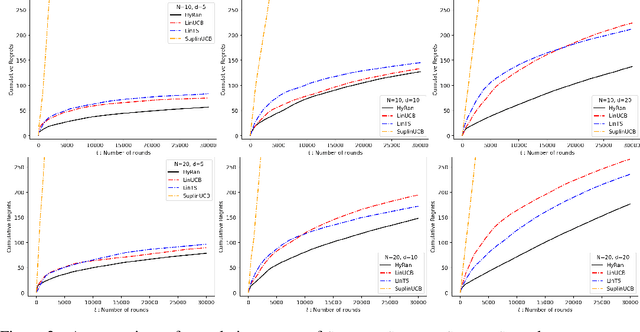
We propose a novel algorithm for linear contextual bandits with $O(\sqrt{dT \log T})$ regret bound, where $d$ is the dimension of contexts and $T$ is the time horizon. Our proposed algorithm is equipped with a novel estimator in which exploration is embedded through explicit randomization. Depending on the randomization, our proposed estimator takes contribution either from contexts of all arms or from selected contexts. We establish a self-normalized bound for our estimator, which allows a novel decomposition of the cumulative regret into additive dimension-dependent terms instead of multiplicative terms. We also prove a novel lower bound of $\Omega(\sqrt{dT})$ under our problem setting. Hence, the regret of our proposed algorithm matches the lower bound up to logarithmic factors. The numerical experiments support the theoretical guarantees and show that our proposed method outperforms the existing linear bandit algorithms.
Provable Generalization of Overparameterized Meta-learning Trained with SGD
Jun 18, 2022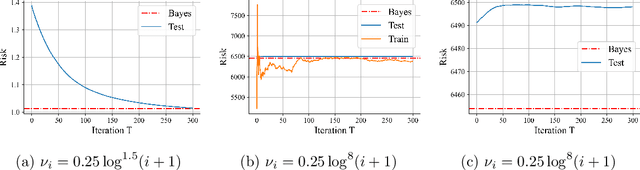
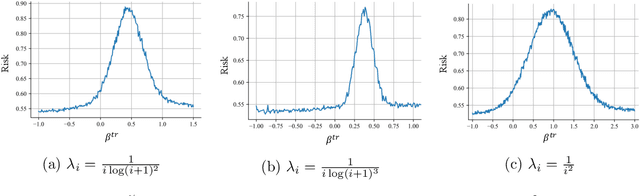
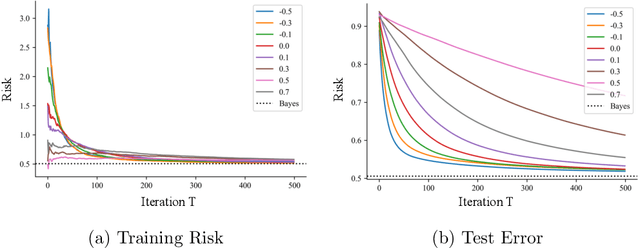
Despite the superior empirical success of deep meta-learning, theoretical understanding of overparameterized meta-learning is still limited. This paper studies the generalization of a widely used meta-learning approach, Model-Agnostic Meta-Learning (MAML), which aims to find a good initialization for fast adaptation to new tasks. Under a mixed linear regression model, we analyze the generalization properties of MAML trained with SGD in the overparameterized regime. We provide both upper and lower bounds for the excess risk of MAML, which captures how SGD dynamics affect these generalization bounds. With such sharp characterizations, we further explore how various learning parameters impact the generalization capability of overparameterized MAML, including explicitly identifying typical data and task distributions that can achieve diminishing generalization error with overparameterization, and characterizing the impact of adaptation learning rate on both excess risk and the early stopping time. Our theoretical findings are further validated by experiments.
Parallel Bayesian Optimization of Agent-based Transportation Simulation
Jul 11, 2022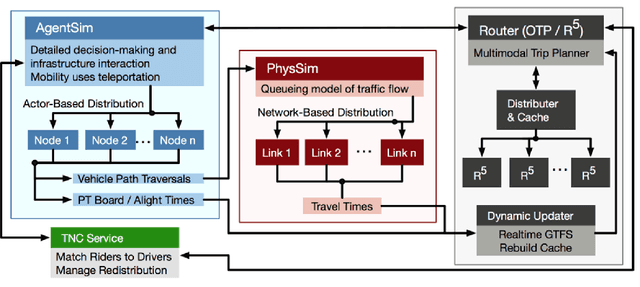
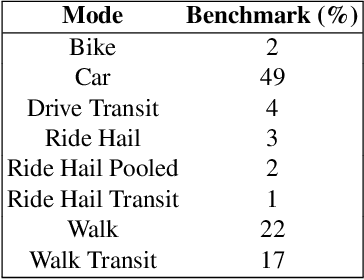
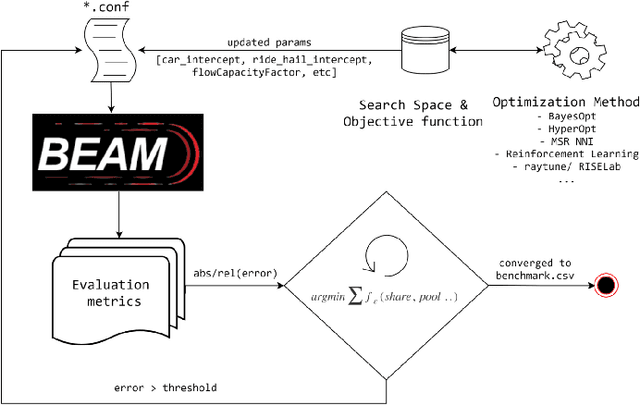
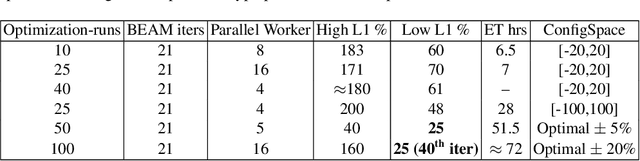
MATSim (Multi-Agent Transport Simulation Toolkit) is an open source large-scale agent-based transportation planning project applied to various areas like road transport, public transport, freight transport, regional evacuation, etc. BEAM (Behavior, Energy, Autonomy, and Mobility) framework extends MATSim to enable powerful and scalable analysis of urban transportation systems. The agents from the BEAM simulation exhibit 'mode choice' behavior based on multinomial logit model. In our study, we consider eight mode choices viz. bike, car, walk, ride hail, driving to transit, walking to transit, ride hail to transit, and ride hail pooling. The 'alternative specific constants' for each mode choice are critical hyperparameters in a configuration file related to a particular scenario under experimentation. We use the 'Urbansim-10k' BEAM scenario (with 10,000 population size) for all our experiments. Since these hyperparameters affect the simulation in complex ways, manual calibration methods are time consuming. We present a parallel Bayesian optimization method with early stopping rule to achieve fast convergence for the given multi-in-multi-out problem to its optimal configurations. Our model is based on an open source HpBandSter package. This approach combines hierarchy of several 1D Kernel Density Estimators (KDE) with a cheap evaluator (Hyperband, a single multidimensional KDE). Our model has also incorporated extrapolation based early stopping rule. With our model, we could achieve a 25% L1 norm for a large-scale BEAM simulation in fully autonomous manner. To the best of our knowledge, our work is the first of its kind applied to large-scale multi-agent transportation simulations. This work can be useful for surrogate modeling of scenarios with very large populations.
TENET: A Time-reversal Enhancement Network for Noise-robust ASR
Jul 04, 2021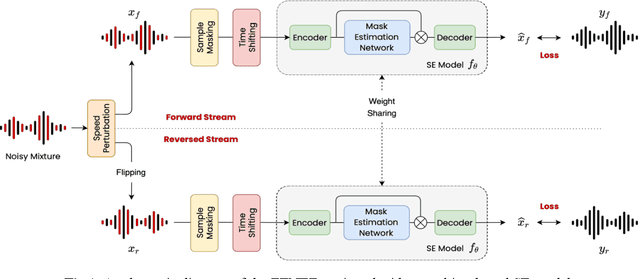
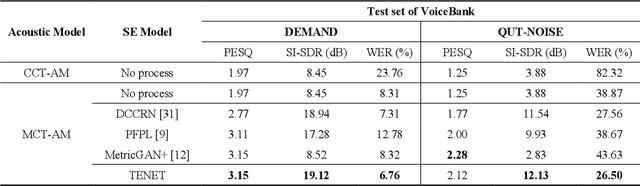
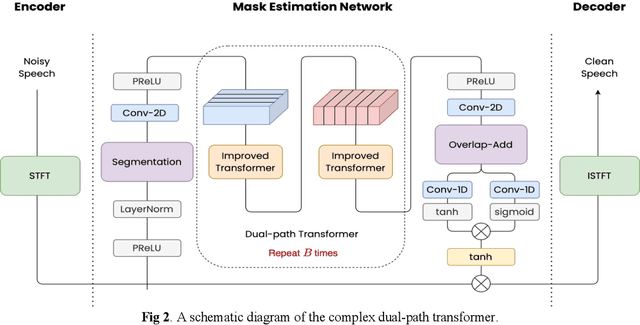
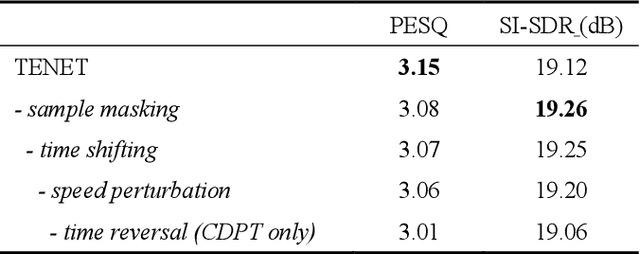
Due to the unprecedented breakthroughs brought about by deep learning, speech enhancement (SE) techniques have been developed rapidly and play an important role prior to acoustic modeling to mitigate noise effects on speech. To increase the perceptual quality of speech, current state-of-the-art in the SE field adopts adversarial training by connecting an objective metric to the discriminator. However, there is no guarantee that optimizing the perceptual quality of speech will necessarily lead to improved automatic speech recognition (ASR) performance. In this study, we present TENET, a novel Time-reversal Enhancement NETwork, which leverages the transformation of an input noisy signal itself, i.e., the time-reversed version, in conjunction with the siamese network and complex dual-path transformer to promote SE performance for noise-robust ASR. Extensive experiments conducted on the Voicebank-DEMAND dataset show that TENET can achieve state-of-the-art results compared to a few top-of-the-line methods in terms of both SE and ASR evaluation metrics. To demonstrate the model generalization ability, we further evaluate TENET on the test set of scenarios contaminated with unseen noise, and the results also confirm the superiority of this promising method.
Revisiting lp-constrained Softmax Loss: A Comprehensive Study
Jun 20, 2022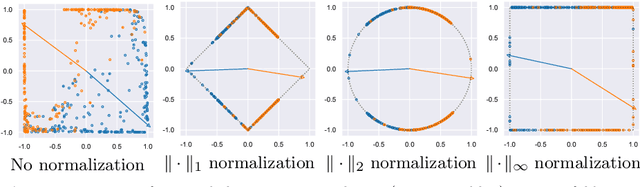
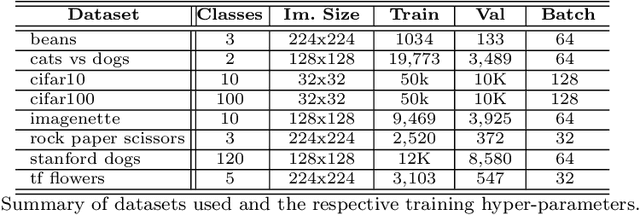

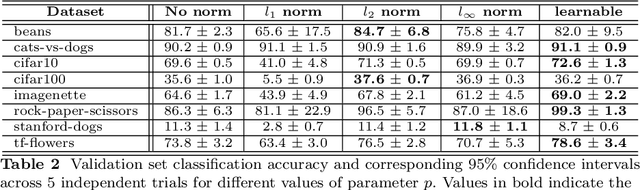
Normalization is a vital process for any machine learning task as it controls the properties of data and affects model performance at large. The impact of particular forms of normalization, however, has so far been investigated in limited domain-specific classification tasks and not in a general fashion. Motivated by the lack of such a comprehensive study, in this paper we investigate the performance of lp-constrained softmax loss classifiers across different norm orders, magnitudes, and data dimensions in both proof-of-concept classification problems and real-world popular image classification tasks. Experimental results suggest collectively that lp-constrained softmax loss classifiers not only can achieve more accurate classification results but, at the same time, appear to be less prone to overfitting. The core findings hold across the three popular deep learning architectures tested and eight datasets examined, and suggest that lp normalization is a recommended data representation practice for image classification in terms of performance and convergence, and against overfitting.