 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quantum Advantage in Variational Bayes Inference
Jul 07, 2022
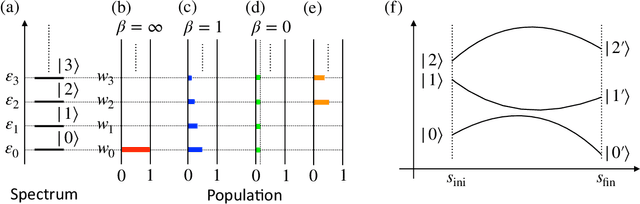
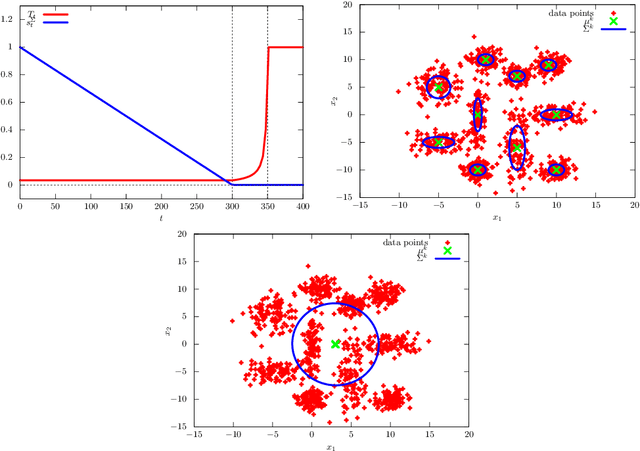
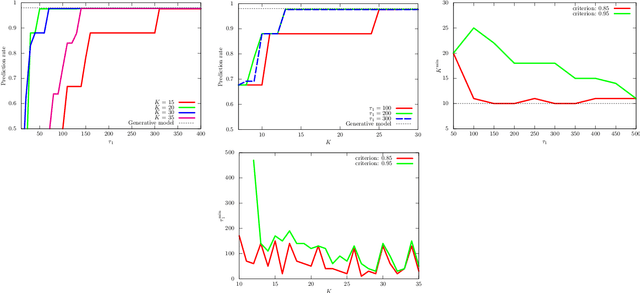
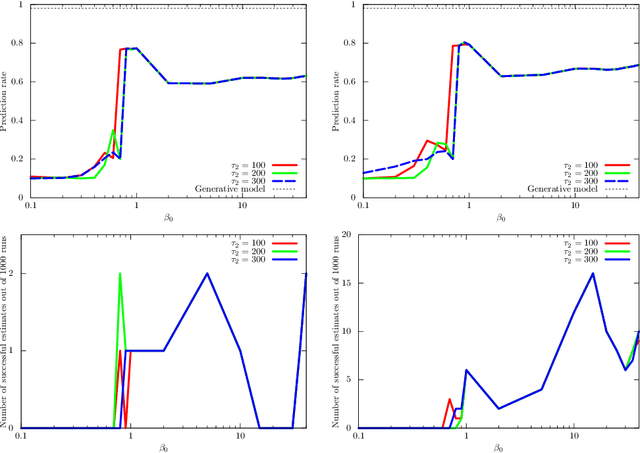
Variational Bayes (VB) inference algorithm is used widely to estimate both the parameters and the unobserved hidden variables in generative statistical models. The algorithm -- inspired by variational methods used in computational physics -- is iterative and can get easily stuck in local minima, even when classical techniques, such as deterministic annealing (DA), are used. We study a variational Bayes (VB) inference algorithm based on a non-traditional quantum annealing approach -- referred to as quantum annealing variational Bayes (QAVB) inference -- and show that there is indeed a quantum advantage to QAVB over its classical counterparts. In particular, we show that such better performance is rooted in key concepts from quantum mechanics: (i) the ground state of the Hamiltonian of a quantum system -- defined from the given variational Bayes (VB) problem -- corresponds to an optimal solution for the minimization problem of the variational free energy at very low temperatures; (ii) such a ground state can be achieved by a technique paralleling the quantum annealing process; and (iii) starting from this ground state, the optimal solution to the VB problem can be achieved by increasing the heat bath temperature to unity, and thereby avoiding local minima introduced by spontaneous symmetry breaking observed in classical physics based VB algorithms. We also show that the update equations of QAVB can be potentially implemented using $\lceil \log K \rceil$ qubits and $\mathcal{O} (K)$ operations per step. Thus, QAVB can match the time complexity of existing VB algorithms, while delivering higher performance.
BoAT v2 -- A Web-Based Dependency Annotation Tool with Focus on Agglutinative Languages
Jul 04, 2022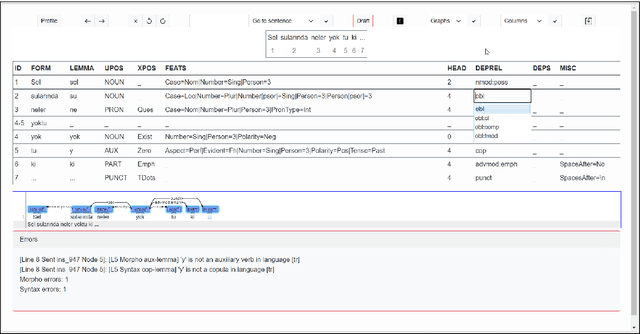
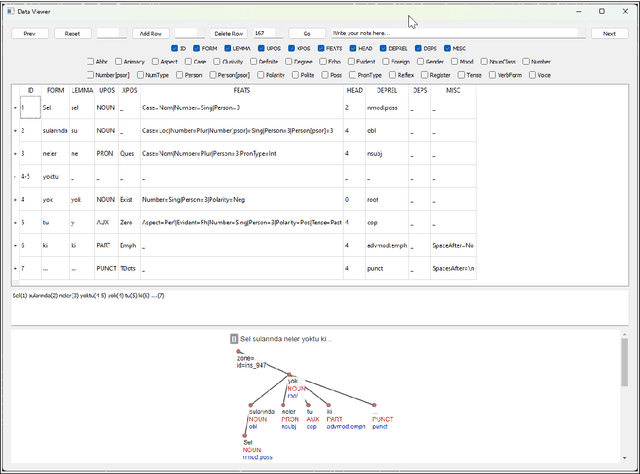
The value of quality treebanks is steadily increasing due to the crucial role they play in the development of natural language processing tools. The creation of such treebanks is enormously labor-intensive and time-consuming. Especially when the size of treebanks is considered, tools that support the annotation process are essential. Various annotation tools have been proposed, however, they are often not suitable for agglutinative languages such as Turkish. BoAT v1 was developed for annotating dependency relations and was subsequently used to create the manually annotated BOUN Treebank (UD_Turkish-BOUN). In this work, we report on the design and implementation of a dependency annotation tool BoAT v2 based on the experiences gained from the use of BoAT v1, which revealed several opportunities for improvement. BoAT v2 is a multi-user and web-based dependency annotation tool that is designed with a focus on the annotator user experience to yield valid annotations. The main objectives of the tool are to: (1) support creating valid and consistent annotations with increased speed, (2) significantly improve the user experience of the annotator, (3) support collaboration among annotators, and (4) provide an open-source and easily deployable web-based annotation tool with a flexible application programming interface (API) to benefit the scientific community. This paper discusses the requirements elicitation, design, and implementation of BoAT v2 along with examples.
WOLONet: Wave Outlooker for Efficient and High Fidelity Speech Synthesis
Jun 20, 2022
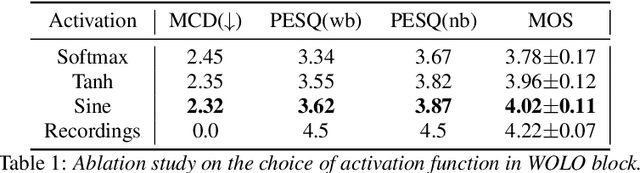
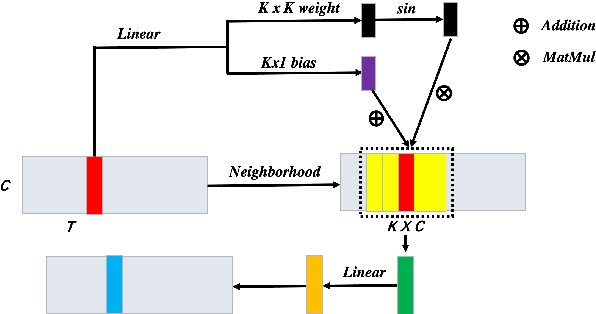
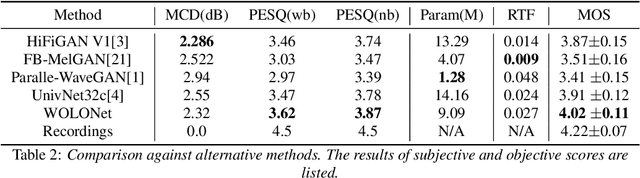
Recently, GAN-based neural vocoders such as Parallel WaveGAN, MelGAN, HiFiGAN, and UnivNet have become popular due to their lightweight and parallel structure, resulting in a real-time synthesized waveform with high fidelity, even on a CPU. HiFiGAN and UnivNet are two SOTA vocoders. Despite their high quality, there is still room for improvement. In this paper, motivated by the structure of Vision Outlooker from computer vision, we adopt a similar idea and propose an effective and lightweight neural vocoder called WOLONet. In this network, we develop a novel lightweight block that uses a location-variable, channel-independent, and depthwise dynamic convolutional kernel with sinusoidally activated dynamic kernel weights. To demonstrate the effectiveness and generalizability of our method, we perform an ablation study to verify our novel design and make a subjective and objective comparison with typical GAN-based vocoders. The results show that our WOLONet achieves the best generation quality while requiring fewer parameters than the two neural SOTA vocoders, HiFiGAN and UnivNet.
Deep Rotation Correction without Angle Prior
Jul 07, 2022



Not everybody can be equipped with professional photography skills and sufficient shooting time, and there can be some tilts in the captured images occasionally. In this paper, we propose a new and practical task, named Rotation Correction, to automatically correct the tilt with high content fidelity in the condition that the rotated angle is unknown. This task can be easily integrated into image editing applications, allowing users to correct the rotated images without any manual operations. To this end, we leverage a neural network to predict the optical flows that can warp the tilted images to be perceptually horizontal. Nevertheless, the pixel-wise optical flow estimation from a single image is severely unstable, especially in large-angle tilted images. To enhance its robustness, we propose a simple but effective prediction strategy to form a robust elastic warp. Particularly, we first regress the mesh deformation that can be transformed into robust initial optical flows. Then we estimate residual optical flows to facilitate our network the flexibility of pixel-wise deformation, further correcting the details of the tilted images. To establish an evaluation benchmark and train the learning framework, a comprehensive rotation correction dataset is presented with a large diversity in scenes and rotated angles. Extensive experiments demonstrate that even in the absence of the angle prior, our algorithm can outperform other state-of-the-art solutions requiring this prior. The codes and dataset will be available at https://github.com/nie-lang/RotationCorrection.
Computer-aided Tuberculosis Diagnosis with Attribute Reasoning Assistance
Jul 01, 2022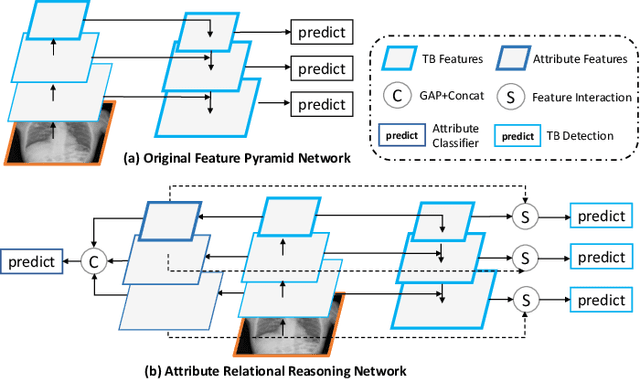
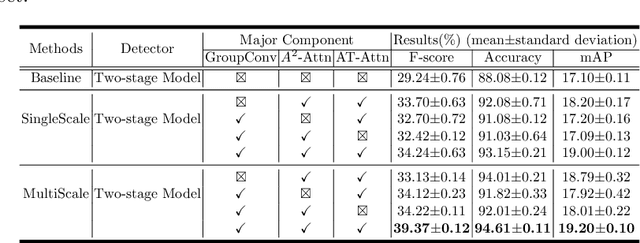
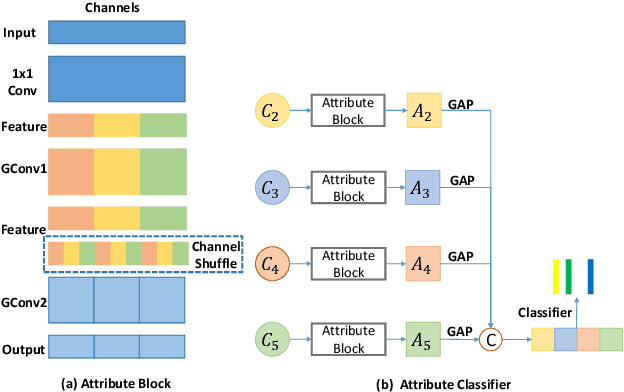
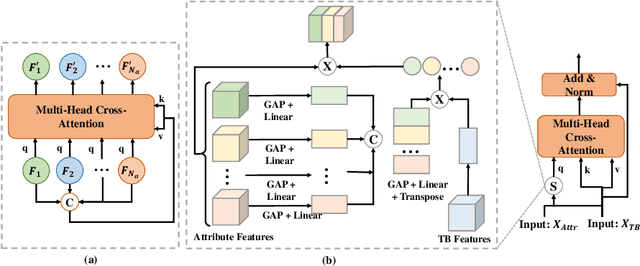
Although deep learning algorithms have been intensively developed for computer-aided tuberculosis diagnosis (CTD), they mainly depend on carefully annotated datasets, leading to much time and resource consumption. Weakly supervised learning (WSL), which leverages coarse-grained labels to accomplish fine-grained tasks, has the potential to solve this problem. In this paper, we first propose a new large-scale tuberculosis (TB) chest X-ray dataset, namely the tuberculosis chest X-ray attribute dataset (TBX-Att), and then establish an attribute-assisted weakly-supervised framework to classify and localize TB by leveraging the attribute information to overcome the insufficiency of supervision in WSL scenarios. Specifically, first, the TBX-Att dataset contains 2000 X-ray images with seven kinds of attributes for TB relational reasoning, which are annotated by experienced radiologists. It also includes the public TBX11K dataset with 11200 X-ray images to facilitate weakly supervised detection. Second, we exploit a multi-scale feature interaction model for TB area classification and detection with attribute relational reasoning. The proposed model is evaluated on the TBX-Att dataset and will serve as a solid baseline for future research. The code and data will be available at https://github.com/GangmingZhao/tb-attribute-weak-localization.
Not All Models Are Equal: Predicting Model Transferability in a Self-challenging Fisher Space
Jul 07, 2022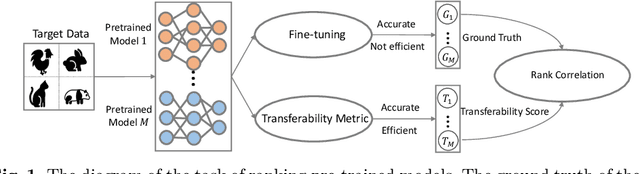
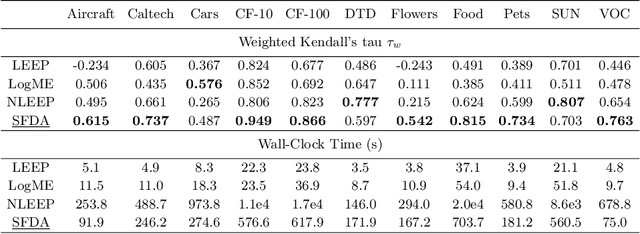
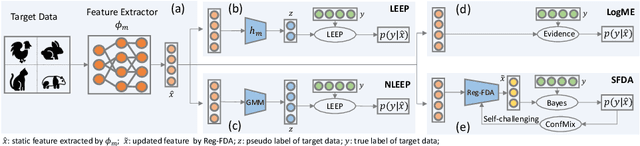
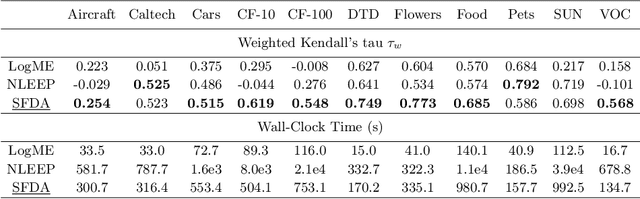
This paper addresses an important problem of ranking the pre-trained deep neural networks and screening the most transferable ones for downstream tasks. It is challenging because the ground-truth model ranking for each task can only be generated by fine-tuning the pre-trained models on the target dataset, which is brute-force and computationally expensive. Recent advanced methods proposed several lightweight transferability metrics to predict the fine-tuning results. However, these approaches only capture static representations but neglect the fine-tuning dynamics. To this end, this paper proposes a new transferability metric, called \textbf{S}elf-challenging \textbf{F}isher \textbf{D}iscriminant \textbf{A}nalysis (\textbf{SFDA}), which has many appealing benefits that existing works do not have. First, SFDA can embed the static features into a Fisher space and refine them for better separability between classes. Second, SFDA uses a self-challenging mechanism to encourage different pre-trained models to differentiate on hard examples. Third, SFDA can easily select multiple pre-trained models for the model ensemble. Extensive experiments on $33$ pre-trained models of $11$ downstream tasks show that SFDA is efficient, effective, and robust when measuring the transferability of pre-trained models. For instance, compared with the state-of-the-art method NLEEP, SFDA demonstrates an average of $59.1$\% gain while bringing $22.5$x speedup in wall-clock time. The code will be available at \url{https://github.com/TencentARC/SFDA}.
Ordered Subgraph Aggregation Networks
Jun 28, 2022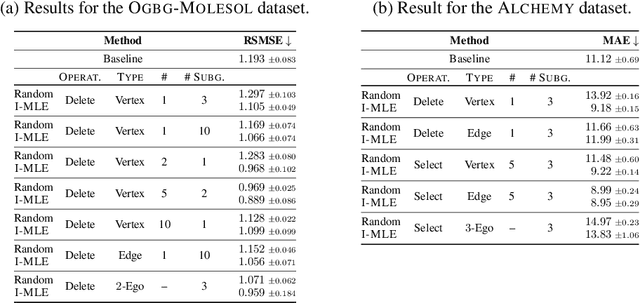
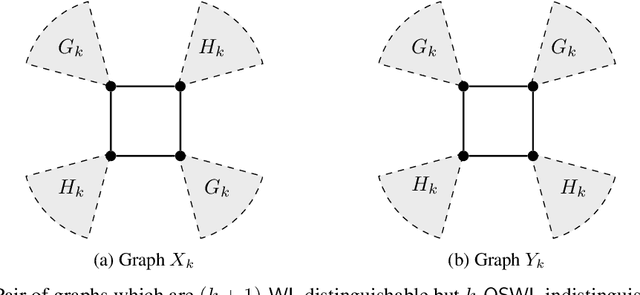
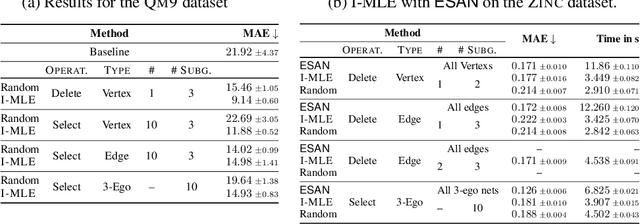

Numerous subgraph-enhanced graph neural networks (GNNs) have emerged recently, provably boosting the expressive power of standard (message-passing) GNNs. However, there is a limited understanding of how these approaches relate to each other and to the Weisfeiler--Leman hierarchy. Moreover, current approaches either use all subgraphs of a given size, sample them uniformly at random, or use hand-crafted heuristics instead of learning to select subgraphs in a data-driven manner. Here, we offer a unified way to study such architectures by introducing a theoretical framework and extending the known expressivity results of subgraph-enhanced GNNs. Concretely, we show that increasing subgraph size always increases the expressive power and develop a better understanding of their limitations by relating them to the established $k\text{-}\mathsf{WL}$ hierarchy. In addition, we explore different approaches for learning to sample subgraphs using recent methods for backpropagating through complex discrete probability distributions. Empirically, we study the predictive performance of different subgraph-enhanced GNNs, showing that our data-driven architectures increase prediction accuracy on standard benchmark datasets compared to non-data-driven subgraph-enhanced graph neural networks while reducing computation time.
Wild ToFu: Improving Range and Quality of Indirect Time-of-Flight Depth with RGB Fusion in Challenging Environments
Dec 07, 2021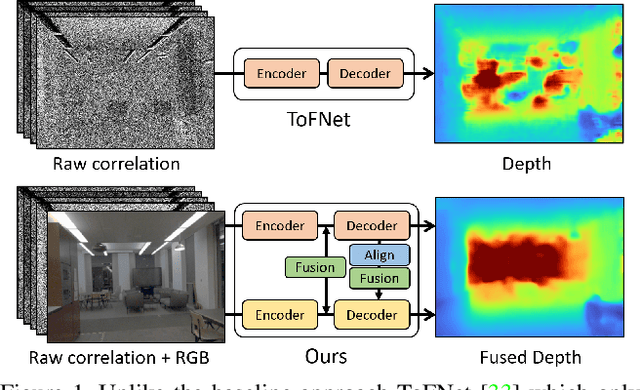

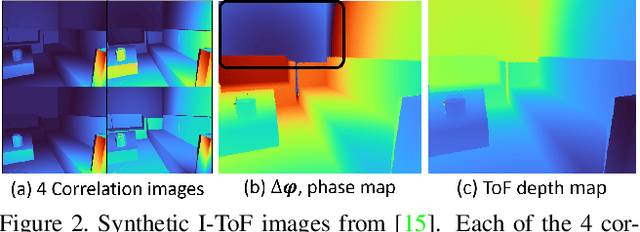
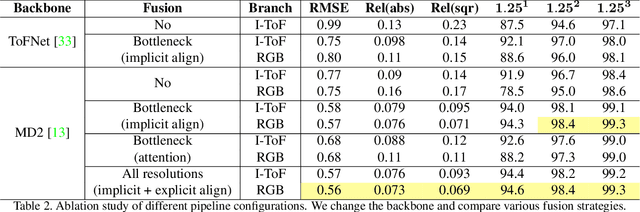
Indirect Time-of-Flight (I-ToF) imaging is a widespread way of depth estimation for mobile devices due to its small size and affordable price. Previous works have mainly focused on quality improvement for I-ToF imaging especially curing the effect of Multi Path Interference (MPI). These investigations are typically done in specifically constrained scenarios at close distance, indoors and under little ambient light. Surprisingly little work has investigated I-ToF quality improvement in real-life scenarios where strong ambient light and far distances pose difficulties due to an extreme amount of induced shot noise and signal sparsity, caused by the attenuation with limited sensor power and light scattering. In this work, we propose a new learning based end-to-end depth prediction network which takes noisy raw I-ToF signals as well as an RGB image and fuses their latent representation based on a multi step approach involving both implicit and explicit alignment to predict a high quality long range depth map aligned to the RGB viewpoint. We test our approach on challenging real-world scenes and show more than 40% RMSE improvement on the final depth map compared to the baseline approach.
Energy-Latency Attacks via Sponge Poisoning
Apr 11, 2022
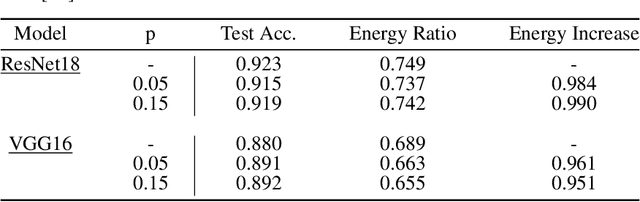
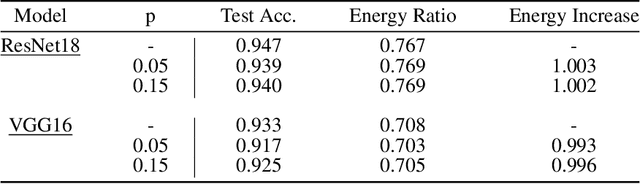
Sponge examples are test-time inputs carefully-optimized to increase energy consumption and latency of neural networks when deployed on hardware accelerators. In this work, we demonstrate that sponge attacks can also be implanted at training time, when model training is outsourced to a third party, via an attack that we call sponge poisoning. This attack allows one to increase the energy consumption and latency of machine-learning models indiscriminately on each test-time input. We present a novel formalization for sponge poisoning, overcoming the limitations related to the optimization of test-time sponge examples, and show that this attack is possible even if the attacker only controls a few poisoning samples and model updates. Our extensive experimental analysis, involving two deep learning architectures and three datasets, shows that sponge poisoning can almost completely vanish the effect of such hardware accelerators. Finally, we analyze activations of the resulting sponge models, identifying the module components that are more sensitive to this vulnerability.
Neural Parameterization for Dynamic Human Head Editing
Jul 01, 2022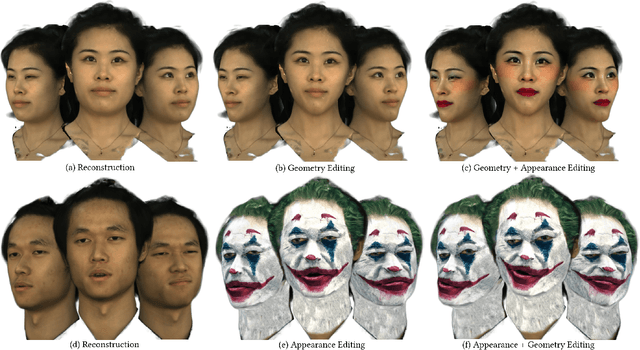

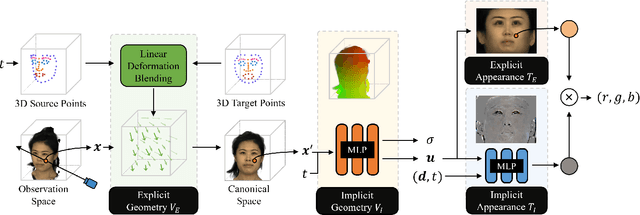

Implicit radiance functions emerged as a powerful scene representation for reconstructing and rendering photo-realistic views of a 3D scene. These representations, however, suffer from poor editability. On the other hand, explicit representations such as polygonal meshes allow easy editing but are not as suitable for reconstructing accurate details in dynamic human heads, such as fine facial features, hair, teeth, and eyes. In this work, we present Neural Parameterization (NeP), a hybrid representation that provides the advantages of both implicit and explicit methods. NeP is capable of photo-realistic rendering while allowing fine-grained editing of the scene geometry and appearance. We first disentangle the geometry and appearance by parameterizing the 3D geometry into 2D texture space. We enable geometric editability by introducing an explicit linear deformation blending layer. The deformation is controlled by a set of sparse key points, which can be explicitly and intuitively displaced to edit the geometry. For appearance, we develop a hybrid 2D texture consisting of an explicit texture map for easy editing and implicit view and time-dependent residuals to model temporal and view variations. We compare our method to several reconstruction and editing baselines. The results show that the NeP achieves almost the same level of rendering accuracy while maintaining high editability.