 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Review of Published Machine Learning Natural Language Processing Applications for Protocolling Radiology Imaging
Jun 23, 2022
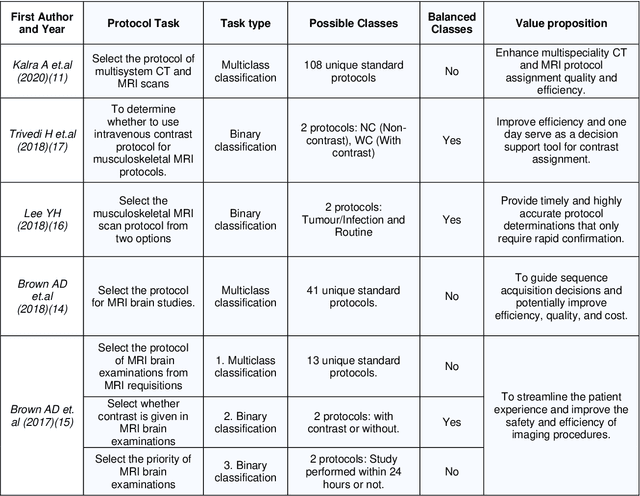
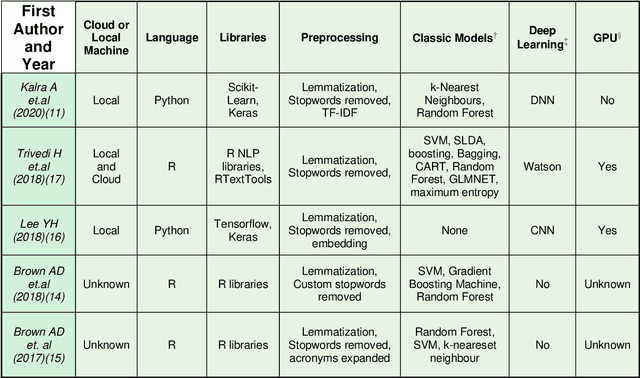
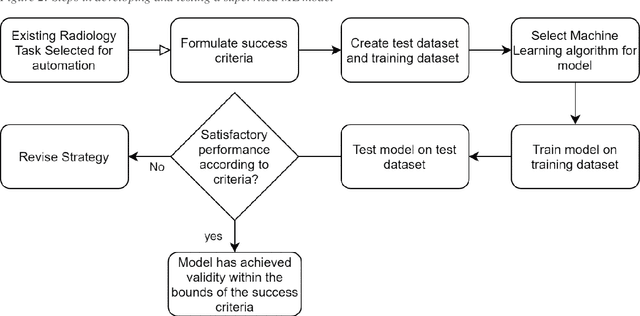
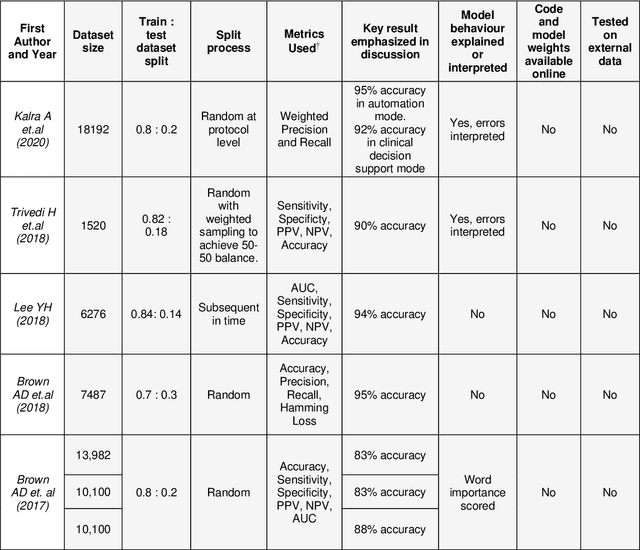
Machine learning (ML) is a subfield of Artificial intelligence (AI), and its applications in radiology are growing at an ever-accelerating rate. The most studied ML application is the automated interpretation of images. However, natural language processing (NLP), which can be combined with ML for text interpretation tasks, also has many potential applications in radiology. One such application is automation of radiology protocolling, which involves interpreting a clinical radiology referral and selecting the appropriate imaging technique. It is an essential task which ensures that the correct imaging is performed. However, the time that a radiologist must dedicate to protocolling could otherwise be spent reporting, communicating with referrers, or teaching. To date, there have been few publications in which ML models were developed that use clinical text to automate protocol selection. This article reviews the existing literature in this field. A systematic assessment of the published models is performed with reference to best practices suggested by machine learning convention. Progress towards implementing automated protocolling in a clinical setting is discussed.
Theory of Acceleration of Decision Making by Correlated Times Sequences
Mar 30, 2022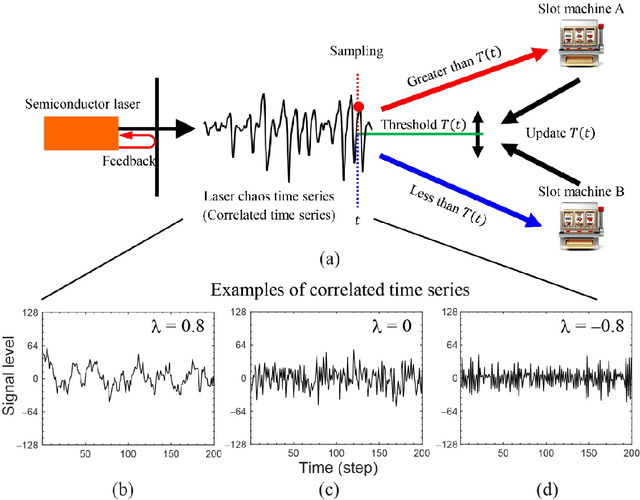
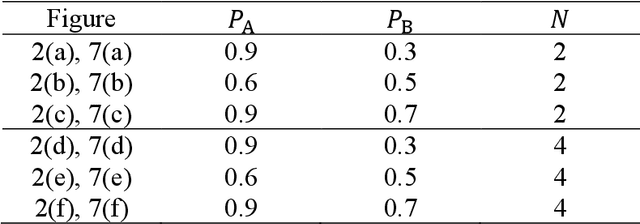
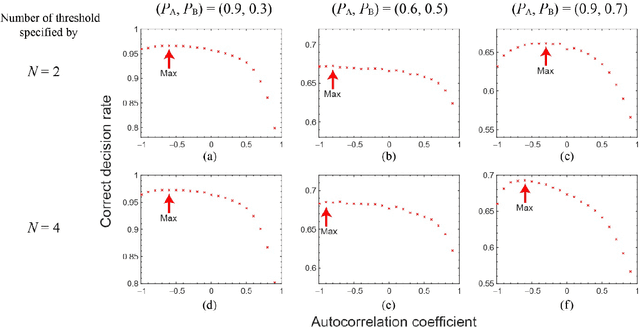
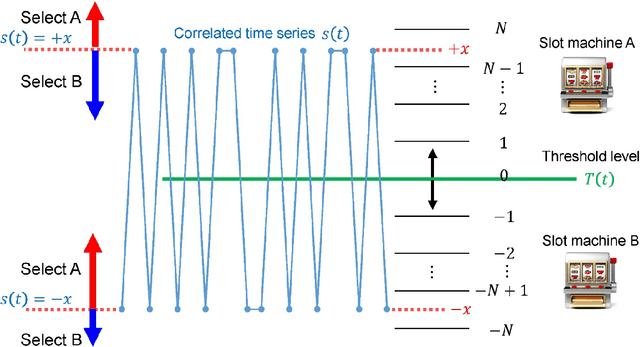
Photonic accelerators have been intensively studied to provide enhanced information processing capability to benefit from the unique attributes of physical processes. Recently, it has been reported that chaotically oscillating ultrafast time series from a laser, called laser chaos, provides the ability to solve multi-armed bandit (MAB) problems or decision-making problems at GHz order. Furthermore, it has been confirmed that the negatively correlated time-domain structure of laser chaos contributes to the acceleration of decision-making. However, the underlying mechanism of why decision-making is accelerated by correlated time series is unknown. In this paper, we demonstrate a theoretical model to account for the acceleration of decision-making by correlated time sequence. We first confirm the effectiveness of the negative autocorrelation inherent in time series for solving two-armed bandit problems using Fourier transform surrogate methods. We propose a theoretical model that concerns the correlated time series subjected to the decision-making system and the internal status of the system therein in a unified manner, inspired by correlated random walks. We demonstrate that the performance derived analytically by the theory agrees well with the numerical simulations, which confirms the validity of the proposed model and leads to optimal system design. The present study paves the new way for the effectiveness of correlated time series for decision-making, impacting artificial intelligence and other applications.
Faster Policy Learning with Continuous-Time Gradients
Dec 12, 2020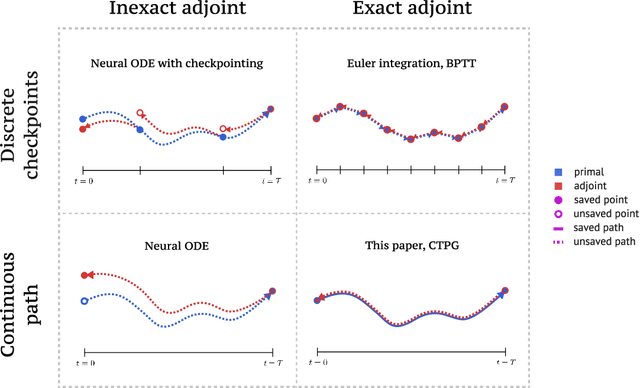
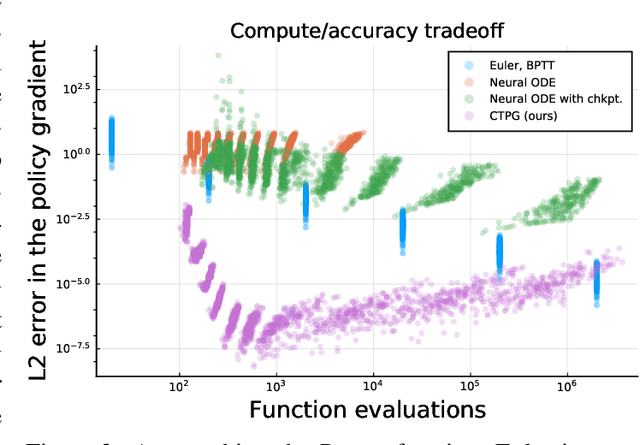
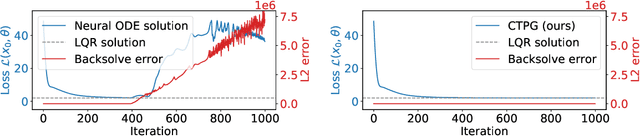
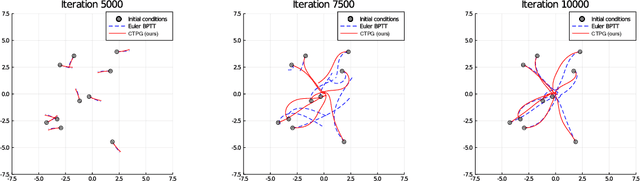
We study the estimation of policy gradients for continuous-time systems with known dynamics. By reframing policy learning in continuous-time, we show that it is possible construct a more efficient and accurate gradient estimator. The standard back-propagation through time estimator (BPTT) computes exact gradients for a crude discretization of the continuous-time system. In contrast, we approximate continuous-time gradients in the original system. With the explicit goal of estimating continuous-time gradients, we are able to discretize adaptively and construct a more efficient policy gradient estimator which we call the Continuous-Time Policy Gradient (CTPG). We show that replacing BPTT policy gradients with more efficient CTPG estimates results in faster and more robust learning in a variety of control tasks and simulators.
Video-based Surgical Skills Assessment using Long term Tool Tracking
Jul 05, 2022

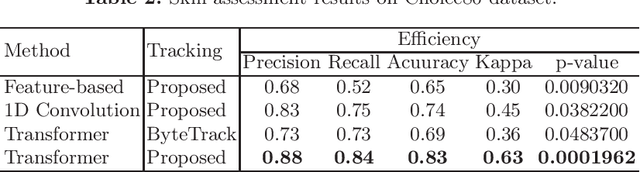
Mastering the technical skills required to perform surgery is an extremely challenging task. Video-based assessment allows surgeons to receive feedback on their technical skills to facilitate learning and development. Currently, this feedback comes primarily from manual video review, which is time-intensive and limits the feasibility of tracking a surgeon's progress over many cases. In this work, we introduce a motion-based approach to automatically assess surgical skills from surgical case video feed. The proposed pipeline first tracks surgical tools reliably to create motion trajectories and then uses those trajectories to predict surgeon technical skill levels. The tracking algorithm employs a simple yet effective re-identification module that improves ID-switch compared to other state-of-the-art methods. This is critical for creating reliable tool trajectories when instruments regularly move on- and off-screen or are periodically obscured. The motion-based classification model employs a state-of-the-art self-attention transformer network to capture short- and long-term motion patterns that are essential for skill evaluation. The proposed method is evaluated on an in-vivo (Cholec80) dataset where an expert-rated GOALS skill assessment of the Calot Triangle Dissection is used as a quantitative skill measure. We compare transformer-based skill assessment with traditional machine learning approaches using the proposed and state-of-the-art tracking. Our result suggests that using motion trajectories from reliable tracking methods is beneficial for assessing surgeon skills based solely on video streams.
Entropy-driven Sampling and Training Scheme for Conditional Diffusion Generation
Jun 23, 2022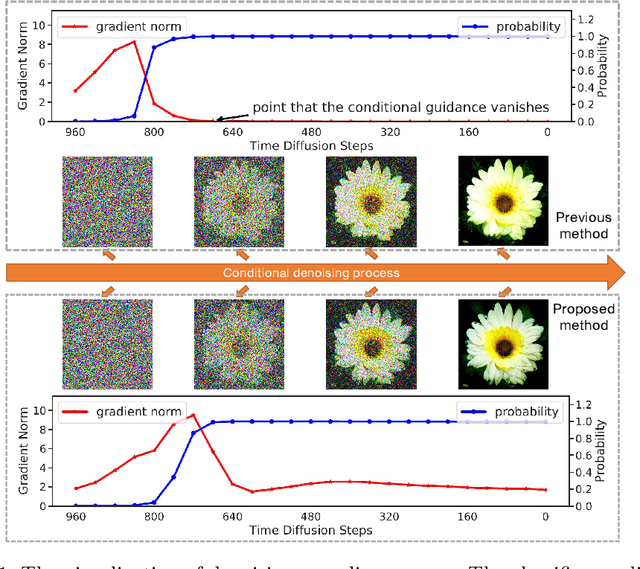
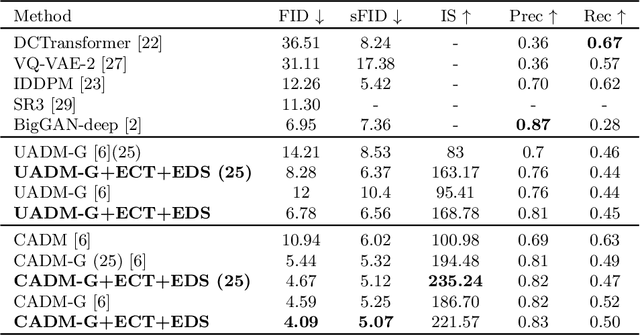
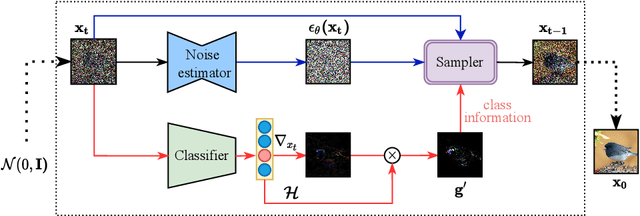
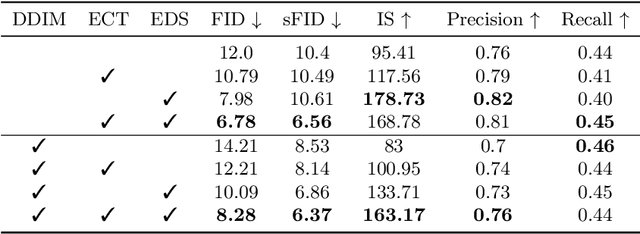
Denoising Diffusion Probabilistic Model (DDPM) is able to make flexible conditional image generation from prior noise to real data, by introducing an independent noise-aware classifier to provide conditional gradient guidance at each time step of denoising process. However, due to the ability of classifier to easily discriminate an incompletely generated image only with high-level structure, the gradient, which is a kind of class information guidance, tends to vanish early, leading to the collapse from conditional generation process into the unconditional process. To address this problem, we propose two simple but effective approaches from two perspectives. For sampling procedure, we introduce the entropy of predicted distribution as the measure of guidance vanishing level and propose an entropy-aware scaling method to adaptively recover the conditional semantic guidance. % for each generated sample. For training stage, we propose the entropy-aware optimization objectives to alleviate the overconfident prediction for noisy data.On ImageNet1000 256x256, with our proposed sampling scheme and trained classifier, the pretrained conditional and unconditional DDPM model can achieve 10.89% (4.59 to 4.09) and 43.5% (12 to 6.78) FID improvement respectively.
Predicting the Geoeffectiveness of CMEs Using Machine Learning
Jun 23, 2022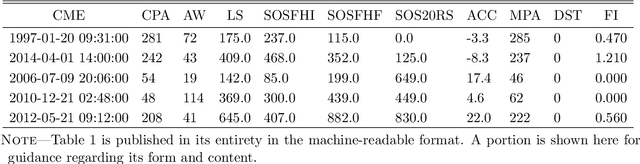
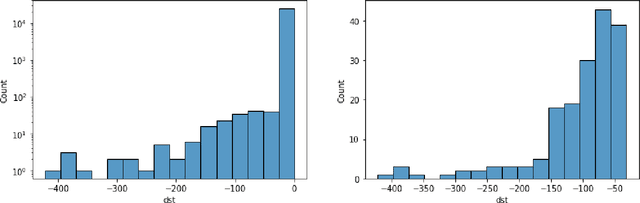
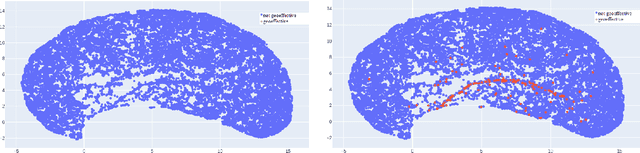

Coronal mass ejections (CMEs) are the most geoeffective space weather phenomena, being associated with large geomagnetic storms, having the potential to cause disturbances to telecommunication, satellite network disruptions, power grid damages and failures. Thus, considering these storms' potential effects on human activities, accurate forecasts of the geoeffectiveness of CMEs are paramount. This work focuses on experimenting with different machine learning methods trained on white-light coronagraph datasets of close to sun CMEs, to estimate whether such a newly erupting ejection has the potential to induce geomagnetic activity. We developed binary classification models using logistic regression, K-Nearest Neighbors, Support Vector Machines, feed forward artificial neural networks, as well as ensemble models. At this time, we limited our forecast to exclusively use solar onset parameters, to ensure extended warning times. We discuss the main challenges of this task, namely the extreme imbalance between the number of geoeffective and ineffective events in our dataset, along with their numerous similarities and the limited number of available variables. We show that even in such conditions, adequate hit rates can be achieved with these models.
Cliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments
May 17, 2022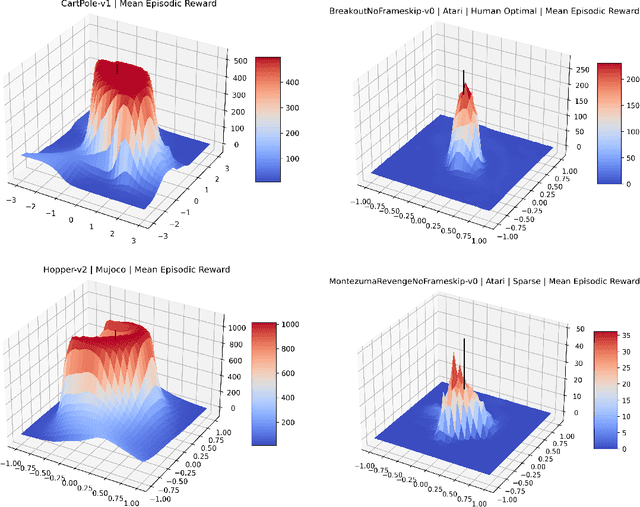
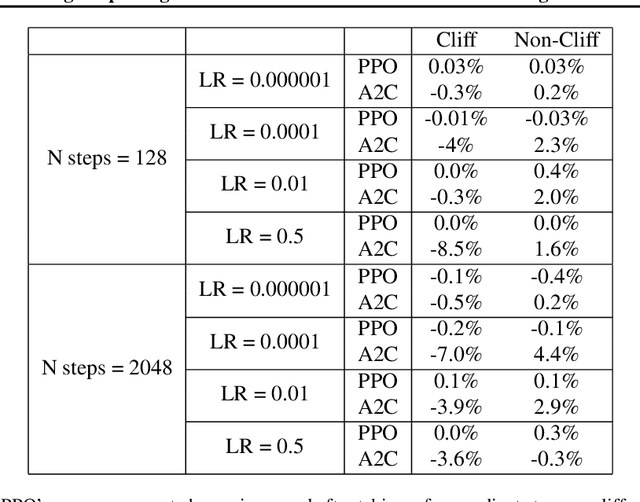
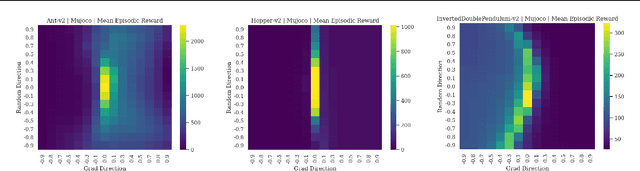
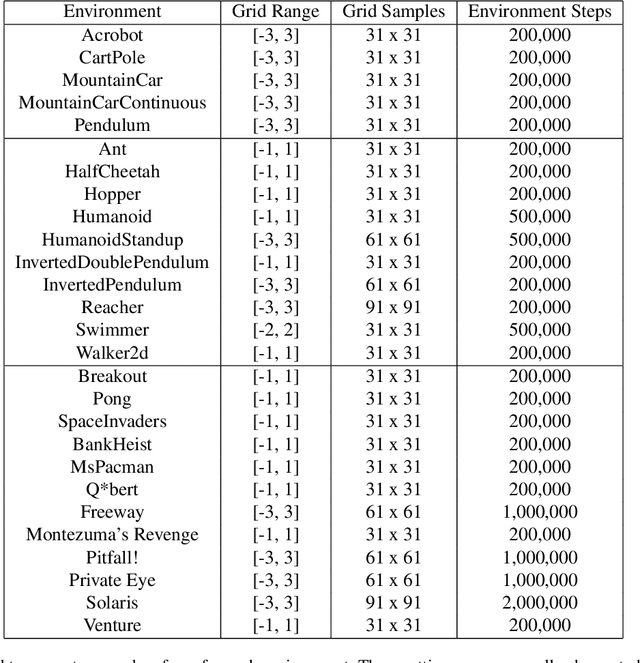
Visualizing optimization landscapes has led to many fundamental insights in numeric optimization, and novel improvements to optimization techniques. However, visualizations of the objective that reinforcement learning optimizes (the "reward surface") have only ever been generated for a small number of narrow contexts. This work presents reward surfaces and related visualizations of 27 of the most widely used reinforcement learning environments in Gym for the first time. We also explore reward surfaces in the policy gradient direction and show for the first time that many popular reinforcement learning environments have frequent "cliffs" (sudden large drops in expected return). We demonstrate that A2C often "dives off" these cliffs into low reward regions of the parameter space while PPO avoids them, confirming a popular intuition for PPO's improved performance over previous methods. We additionally introduce a highly extensible library that allows researchers to easily generate these visualizations in the future. Our findings provide new intuition to explain the successes and failures of modern RL methods, and our visualizations concretely characterize several failure modes of reinforcement learning agents in novel ways.
A Neural Network-Prepended GLRT Framework for Signal Detection Under Nonlinear Distortions
Jun 15, 2022
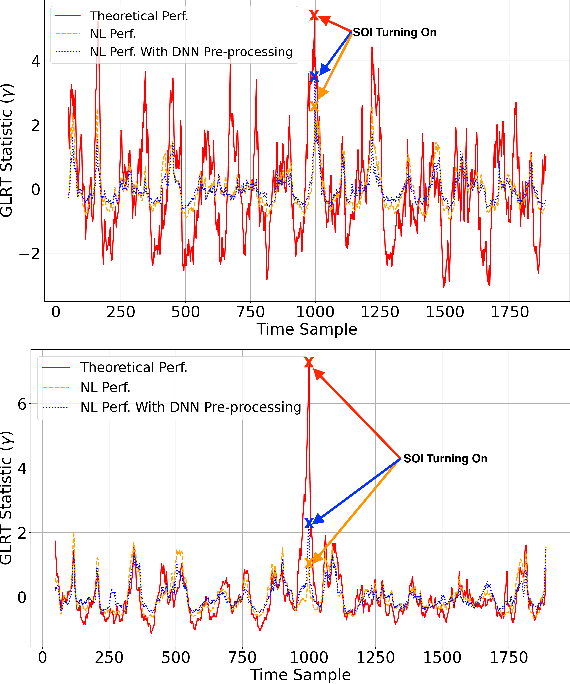
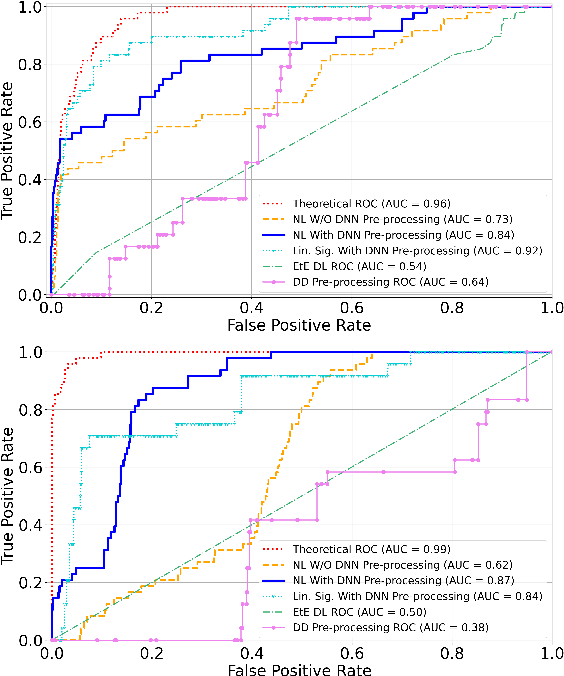
Many communications and sensing applications hinge on the detection of a signal in a noisy, interference-heavy environment. Signal processing theory yields techniques such as the generalized likelihood ratio test (GLRT) to perform detection when the received samples correspond to a linear observation model. Numerous practical applications exist, however, where the received signal has passed through a nonlinearity, causing significant performance degradation of the GLRT. In this work, we propose prepending the GLRT detector with a neural network classifier capable of identifying the particular nonlinear time samples in a received signal. We show that pre-processing received nonlinear signals using our trained classifier to eliminate excessively nonlinear samples (i) improves the detection performance of the GLRT on nonlinear signals and (ii) retains the theoretical guarantees provided by the GLRT on linear observation models for accurate signal detection.
EXODUS: Stable and Efficient Training of Spiking Neural Networks
May 20, 2022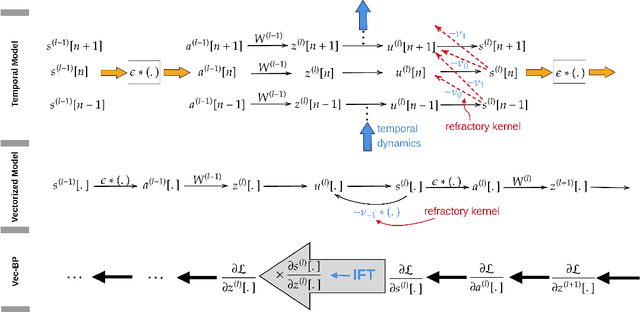
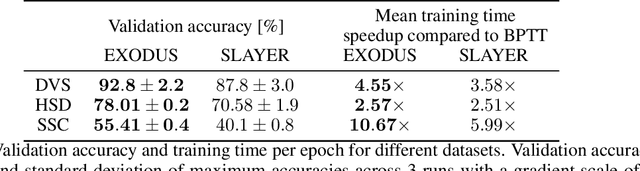
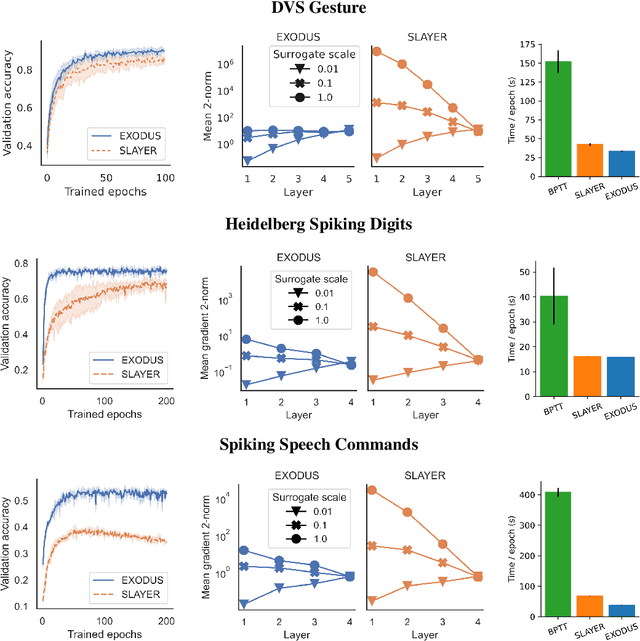

Spiking Neural Networks (SNNs) are gaining significant traction in machine learning tasks where energy-efficiency is of utmost importance. Training such networks using the state-of-the-art back-propagation through time (BPTT) is, however, very time-consuming. Previous work by Shrestha and Orchard [2018] employs an efficient GPU-accelerated back-propagation algorithm called SLAYER, which speeds up training considerably. SLAYER, however, does not take into account the neuron reset mechanism while computing the gradients, which we argue to be the source of numerical instability. To counteract this, SLAYER introduces a gradient scale hyperparameter across layers, which needs manual tuning. In this paper, (i) we modify SLAYER and design an algorithm called EXODUS, that accounts for the neuron reset mechanism and applies the Implicit Function Theorem (IFT) to calculate the correct gradients (equivalent to those computed by BPTT), (ii) we eliminate the need for ad-hoc scaling of gradients, thus, reducing the training complexity tremendously, (iii) we demonstrate, via computer simulations, that EXODUS is numerically stable and achieves a comparable or better performance than SLAYER especially in various tasks with SNNs that rely on temporal features. Our code is available at https://github.com/synsense/sinabs-exodus.
Improving trajectory calculations using deep learning inspired single image superresolution
Jun 07, 2022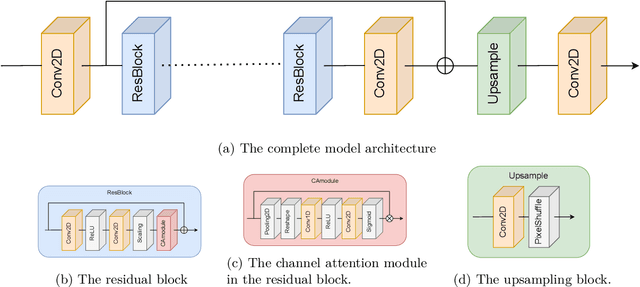

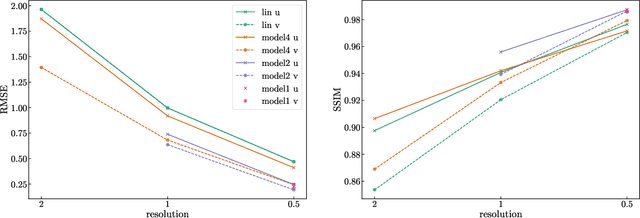

Lagrangian trajectory or particle dispersion models as well as semi-Lagrangian advection schemes require meteorological data such as wind, temperature and geopotential at the exact spatio-temporal locations of the particles that move independently from a regular grid. Traditionally, this high-resolution data has been obtained by interpolating the meteorological parameters from the gridded data of a meteorological model or reanalysis, e.g. using linear interpolation in space and time. However, interpolation errors are a large source of error for these models. Reducing them requires meteorological input fields with high space and time resolution, which may not always be available and can cause severe data storage and transfer problems. Here, we interpret this problem as a single image superresolution task. We interpret meteorological fields available at their native resolution as low-resolution images and train deep neural networks to up-scale them to higher resolution, thereby providing more accurate data for Lagrangian models. We train various versions of the state-of-the-art Enhanced Deep Residual Networks for Superresolution on low-resolution ERA5 reanalysis data with the goal to up-scale these data to arbitrary spatial resolution. We show that the resulting up-scaled wind fields have root-mean-squared errors half the size of the winds obtained with linear spatial interpolation at acceptable computational inference costs. In a test setup using the Lagrangian particle dispersion model FLEXPART and reduced-resolution wind fields, we demonstrate that absolute horizontal transport deviations of calculated trajectories from "ground-truth" trajectories calculated with undegraded 0.5{\deg} winds are reduced by at least 49.5% (21.8%) after 48 hours relative to trajectories using linear interpolation of the wind data when training on 2{\deg} to 1{\deg} (4{\deg} to 2{\deg}) resolution data.