 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian Inference in High-Dimensional Time-Serieswith the Orthogonal Stochastic Linear Mixing Model
Jun 25, 2021
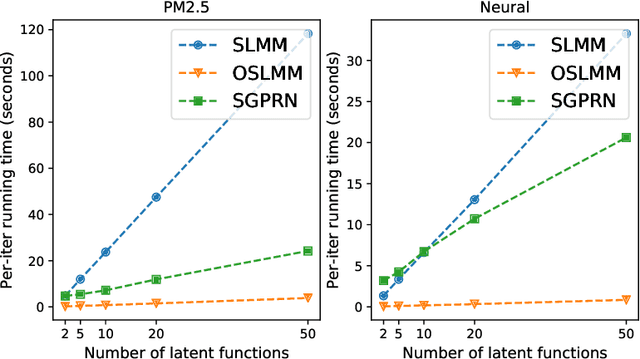
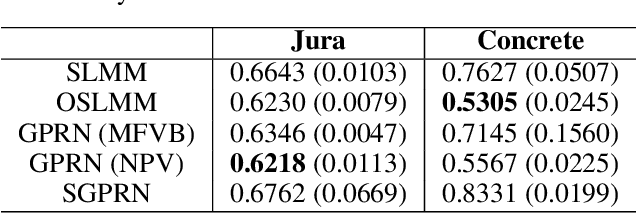
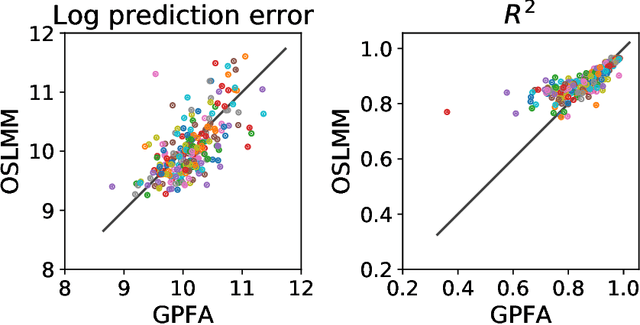
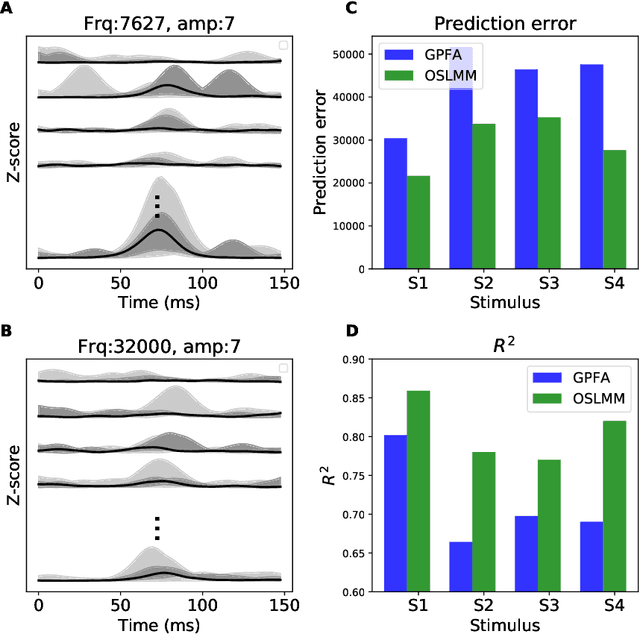
Many modern time-series datasets contain large numbers of output response variables sampled for prolonged periods of time. For example, in neuroscience, the activities of 100s-1000's of neurons are recorded during behaviors and in response to sensory stimuli. Multi-output Gaussian process models leverage the nonparametric nature of Gaussian processes to capture structure across multiple outputs. However, this class of models typically assumes that the correlations between the output response variables are invariant in the input space. Stochastic linear mixing models (SLMM) assume the mixture coefficients depend on input, making them more flexible and effective to capture complex output dependence. However, currently, the inference for SLMMs is intractable for large datasets, making them inapplicable to several modern time-series problems. In this paper, we propose a new regression framework, the orthogonal stochastic linear mixing model (OSLMM) that introduces an orthogonal constraint amongst the mixing coefficients. This constraint reduces the computational burden of inference while retaining the capability to handle complex output dependence. We provide Markov chain Monte Carlo inference procedures for both SLMM and OSLMM and demonstrate superior model scalability and reduced prediction error of OSLMM compared with state-of-the-art methods on several real-world applications. In neurophysiology recordings, we use the inferred latent functions for compact visualization of population responses to auditory stimuli, and demonstrate superior results compared to a competing method (GPFA). Together, these results demonstrate that OSLMM will be useful for the analysis of diverse, large-scale time-series datasets.
fairDMS: Rapid Model Training by Data and Model Reuse
Apr 20, 2022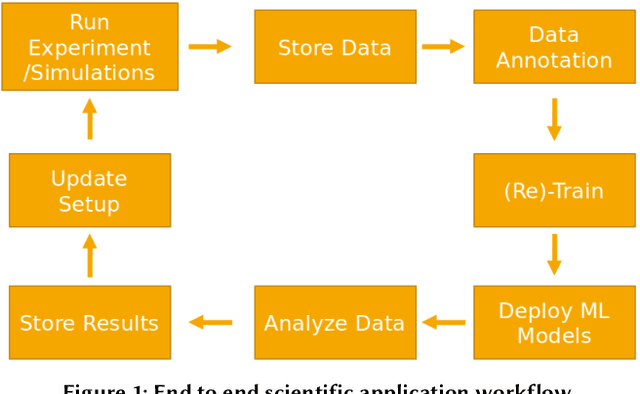
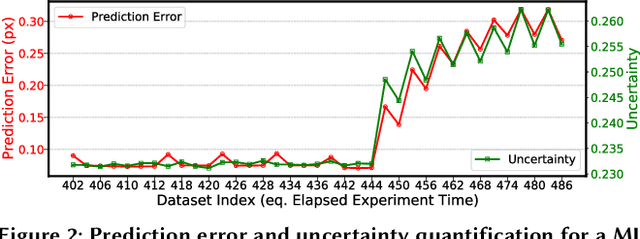
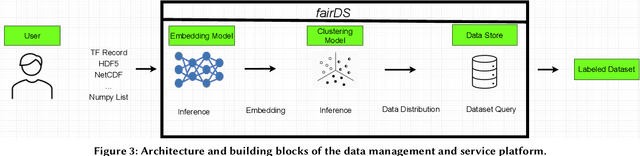
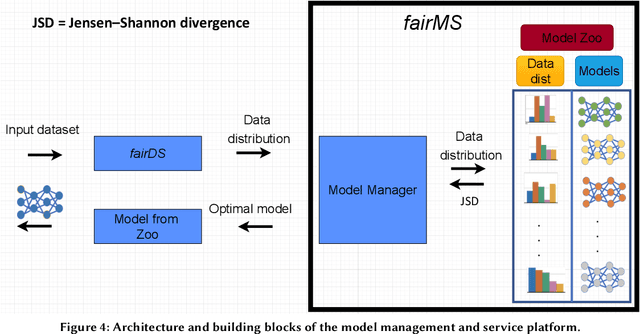
Extracting actionable information from data sources such as the Linac Coherent Light Source (LCLS-II) and Advanced Photon Source Upgrade (APS-U) is becoming more challenging due to the fast-growing data generation rate. The rapid analysis possible with ML methods can enable fast feedback loops that can be used to adjust experimental setups in real-time, for example when errors occur or interesting events are detected. However, to avoid degradation in ML performance over time due to changes in an instrument or sample, we need a way to update ML models rapidly while an experiment is running. We present here a data service and model service to accelerate deep neural network training with a focus on ML-based scientific applications. Our proposed data service achieves 100x speedup in terms of data labeling compare to the current state-of-the-art. Further, our model service achieves up to 200x improvement in training speed. Overall, fairDMS achieves up to 92x speedup in terms of end-to-end model updating time.
Learning Discriminative Prototypes with Dynamic Time Warping
Mar 17, 2021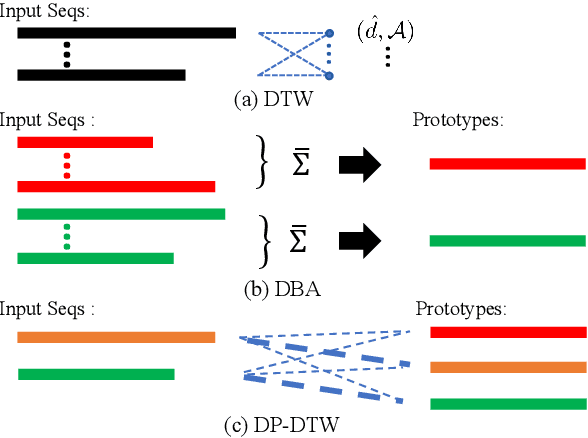

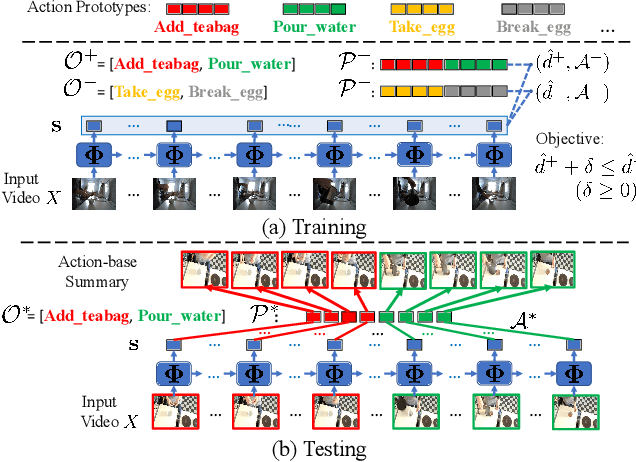
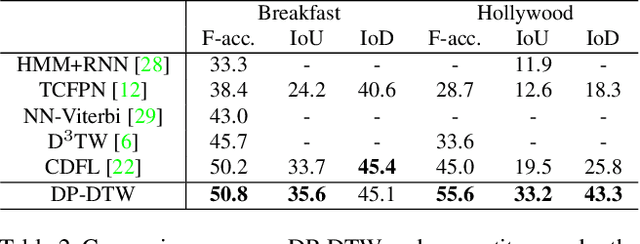
Dynamic Time Warping (DTW) is widely used for temporal data processing. However, existing methods can neither learn the discriminative prototypes of different classes nor exploit such prototypes for further analysis. We propose Discriminative Prototype DTW (DP-DTW), a novel method to learn class-specific discriminative prototypes for temporal recognition tasks. DP-DTW shows superior performance compared to conventional DTWs on time series classification benchmarks. Combined with end-to-end deep learning, DP-DTW can handle challenging weakly supervised action segmentation problems and achieves state of the art results on standard benchmarks. Moreover, detailed reasoning on the input video is enabled by the learned action prototypes. Specifically, an action-based video summarization can be obtained by aligning the input sequence with action prototypes.
On-Device Training Under 256KB Memory
Jun 30, 2022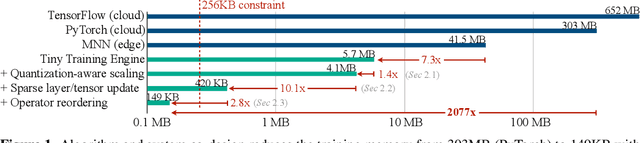
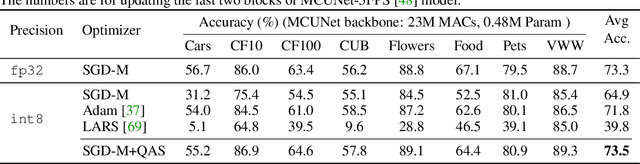
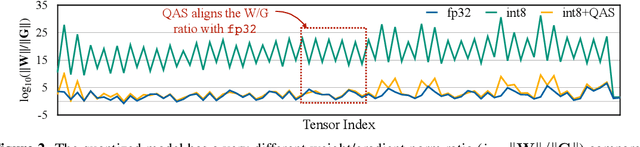
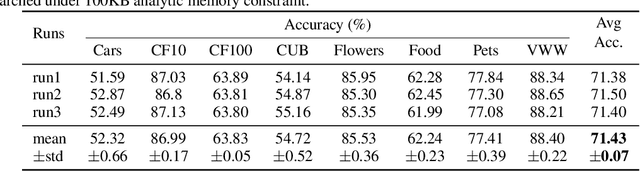
On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to mixed bit-precision and the lack of normalization; (2) the limited hardware resource (memory and computation) does not allow full backward computation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offloads the runtime auto-differentiation to compile time. Our framework is the first practical solution for on-device transfer learning of visual recognition on tiny IoT devices (e.g., a microcontroller with only 256KB SRAM), using less than 1/100 of the memory of existing frameworks while matching the accuracy of cloud training+edge deployment for the tinyML application VWW. Our study enables IoT devices to not only perform inference but also continuously adapt to new data for on-device lifelong learning.
Distributed Learning for Time-varying Networks: A Scalable Design
Jul 31, 2021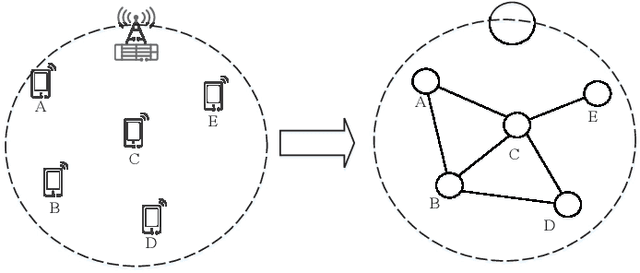
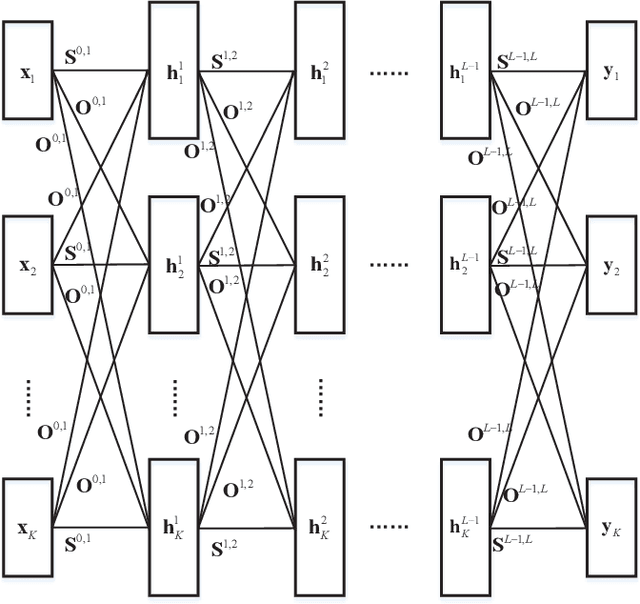
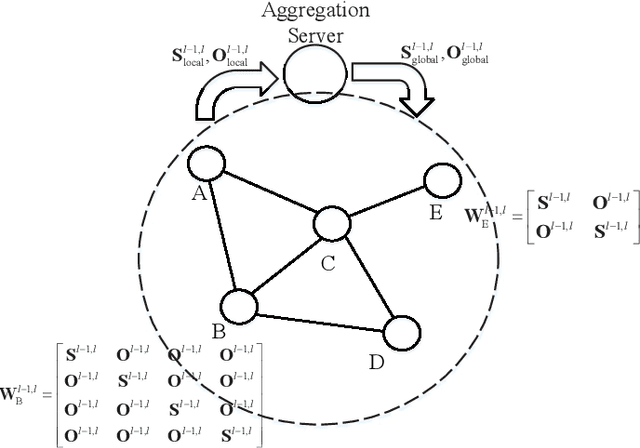
The wireless network is undergoing a trend from "onnection of things" to "connection of intelligence". With data spread over the communication networks and computing capability enhanced on the devices, distributed learning becomes a hot topic in both industrial and academic communities. Many frameworks, such as federated learning and federated distillation, have been proposed. However, few of them takes good care of obstacles such as the time-varying topology resulted by the characteristics of wireless networks. In this paper, we propose a distributed learning framework based on a scalable deep neural network (DNN) design. By exploiting the permutation equivalence and invariance properties of the learning tasks, the DNNs with different scales for different clients can be built up based on two basic parameter sub-matrices. Further, model aggregation can also be conducted based on these two sub-matrices to improve the learning convergence and performance. Finally, simulation results verify the benefits of the proposed framework by compared with some baselines.
Fair Shares: Feasibility, Domination and Incentives
May 16, 2022We consider fair allocation of a set $M$ of indivisible goods to $n$ equally-entitled agents, with no monetary transfers. Every agent $i$ has a valuation $v_i$ from some given class of valuation functions. A share $s$ is a function that maps a pair $(v_i,n)$ to a value, with the interpretation that if an allocation of $M$ to $n$ agents fails to give agent $i$ a bundle of value at least equal to $s(v_i,n)$, this serves as evidence that the allocation is not fair towards $i$. For such an interpretation to make sense, we would like the share to be feasible, meaning that for any valuations in the class, there is an allocation that gives every agent at least her share. The maximin share was a natural candidate for a feasible share for additive valuations. However, Kurokawa, Procaccia and Wang [2018] show that it is not feasible. We initiate a systematic study of the family of feasible shares. We say that a share is \emph{self maximizing} if truth-telling maximizes the implied guarantee. We show that every feasible share is dominated by some self-maximizing and feasible share. We seek to identify those self-maximizing feasible shares that are polynomial time computable, and offer the highest share values. We show that a SM-dominating feasible share -- one that dominates every self-maximizing (SM) feasible share -- does not exist for additive valuations (and beyond). Consequently, we relax the domination property to that of domination up to a multiplicative factor of $\rho$ (called $\rho$-dominating). For additive valuations we present shares that are feasible, self-maximizing and polynomial-time computable. For $n$ agents we present such a share that is $\frac{2n}{3n-1}$-dominating. For two agents we present such a share that is $(1 - \epsilon)$-dominating. Moreover, for these shares we present poly-time algorithms that compute allocations that give every agent at least her share.
A Neural Beam Filter for Real-time Multi-channel Speech Enhancement
Feb 05, 2022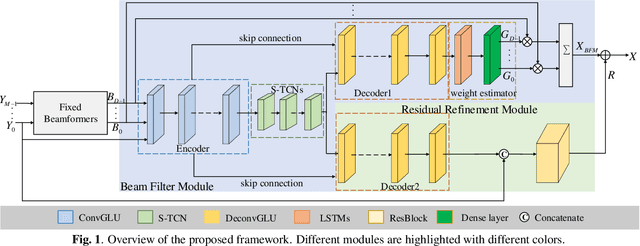
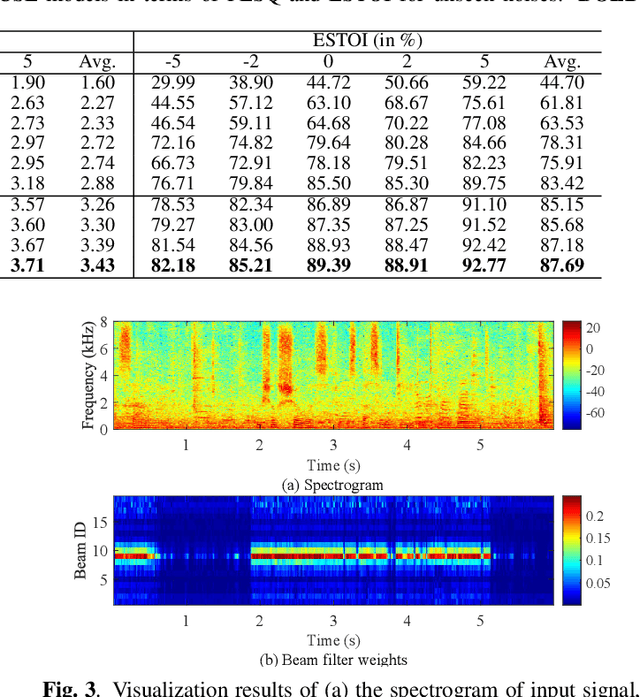
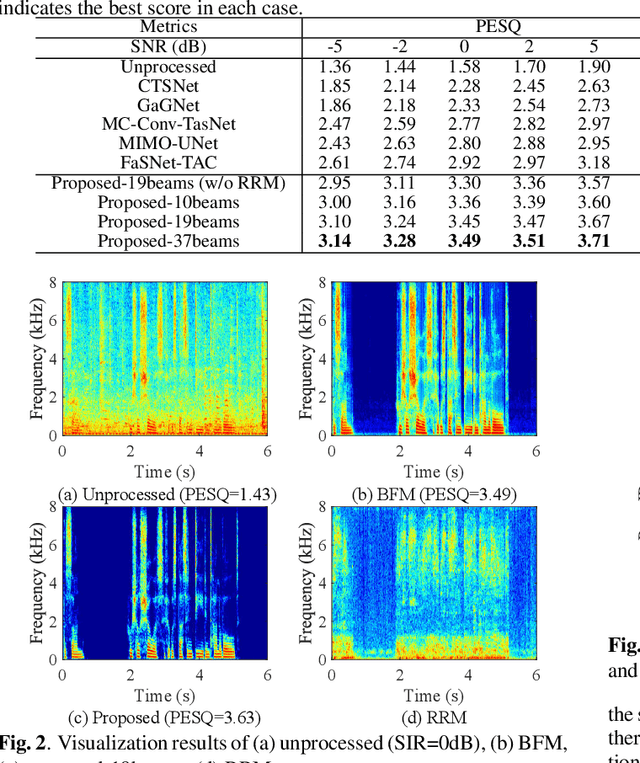
Most deep learning-based multi-channel speech enhancement methods focus on designing a set of beamforming coefficients to directly filter the low signal-to-noise ratio signals received by microphones, which hinders the performance of these approaches. To handle these problems, this paper designs a causal neural beam filter that fully exploits the spatial-spectral information in the beam domain. Specifically, multiple beams are designed to steer towards all directions using a parameterized super-directive beamformer in the first stage. After that, the neural spatial filter is learned by simultaneously modeling the spatial and spectral discriminability of the speech and the interference, so as to extract the desired speech coarsely in the second stage. Finally, to further suppress the interference components especially at low frequencies, a residual estimation module is adopted to refine the output of the second stage. Experimental results demonstrate that the proposed approach outperforms many state-of-the-art multi-channel methods on the generated multi-channel speech dataset based on the DNS-Challenge dataset.
Uncertain Time Series Classification With Shapelet Transform
Feb 03, 2021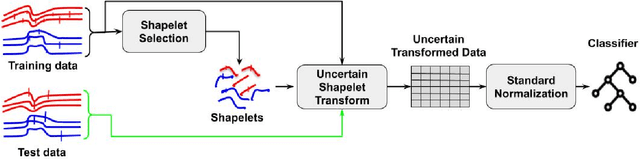
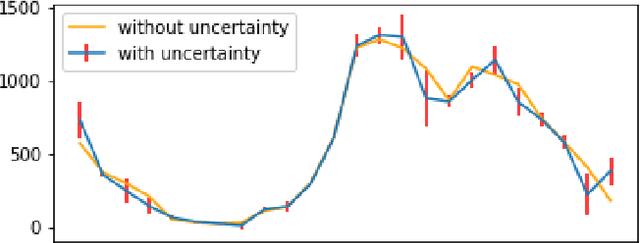

Time series classification is a task that aims at classifying chronological data. It is used in a diverse range of domains such as meteorology, medicine and physics. In the last decade, many algorithms have been built to perform this task with very appreciable accuracy. However, applications where time series have uncertainty has been under-explored. Using uncertainty propagation techniques, we propose a new uncertain dissimilarity measure based on Euclidean distance. We then propose the uncertain shapelet transform algorithm for the classification of uncertain time series. The large experiments we conducted on state of the art datasets show the effectiveness of our contribution. The source code of our contribution and the datasets we used are all available on a public repository.
Fast Bayesian Inference with Batch Bayesian Quadrature via Kernel Recombination
Jun 09, 2022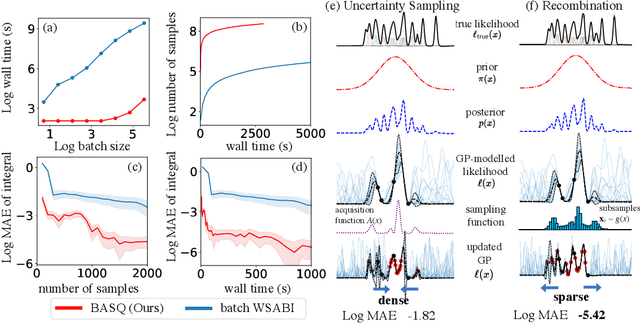

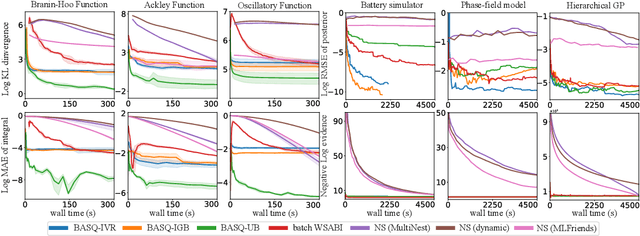
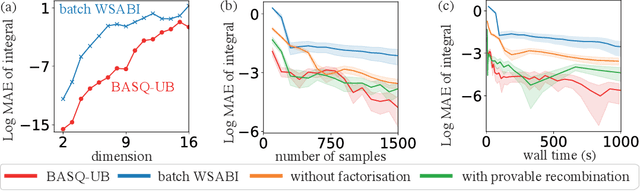
Calculation of Bayesian posteriors and model evidences typically requires numerical integration. Bayesian quadrature (BQ), a surrogate-model-based approach to numerical integration, is capable of superb sample efficiency, but its lack of parallelisation has hindered its practical applications. In this work, we propose a parallelised (batch) BQ method, employing techniques from kernel quadrature, that possesses a provably-exponential convergence rate. Additionally, just as with Nested Sampling, our method permits simultaneous inference of both posteriors and model evidence. Samples from our BQ surrogate model are re-selected to give a sparse set of samples, via a kernel recombination algorithm, requiring negligible additional time to increase the batch size. Empirically, we find that our approach significantly outperforms the sampling efficiency of both state-of-the-art BQ techniques and Nested Sampling in various real-world datasets, including lithium-ion battery analytics.
Passivity-based control for haptic teleoperation of a legged manipulator in presence of time-delays
Aug 17, 2021

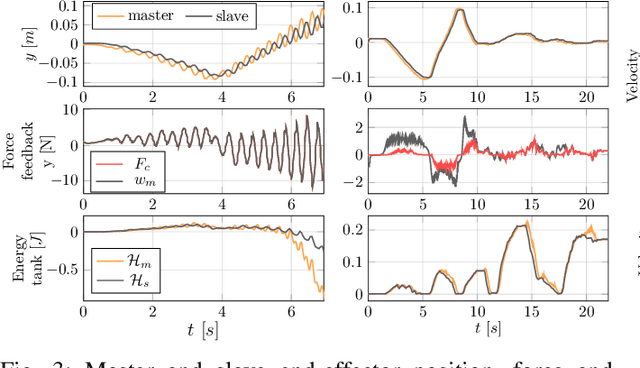
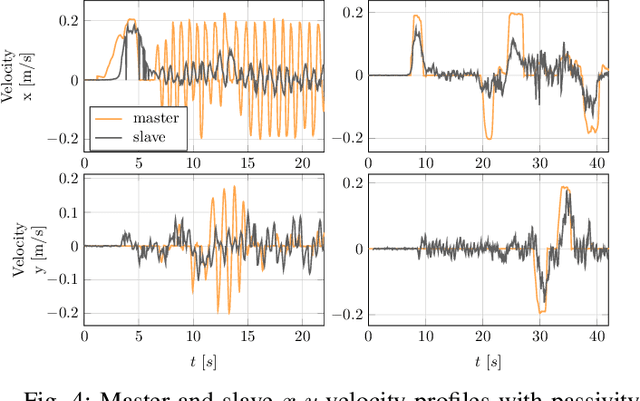
When dealing with the haptic teleoperation of multi-limbed mobile manipulators, the problem of mitigating the destabilizing effects arising from the communication link between the haptic device and the remote robot has not been properly addressed. In this work, we propose a passive control architecture to haptically teleoperate a legged mobile manipulator, while remaining stable in the presence of time delays and frequency mismatches in the master and slave controllers. At the master side, a discrete-time energy modulation of the control input is proposed. At the slave side, passivity constraints are included in an optimization-based whole-body controller to satisfy the energy limitations. A hybrid teleoperation scheme allows the human operator to remotely operate the robot's end-effector while in stance mode, and its base velocity in locomotion mode. The resulting control architecture is demonstrated on a quadrupedal robot with an artificial delay added to the network.