 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continual evaluation for lifelong learning: Identifying the stability gap
May 26, 2022
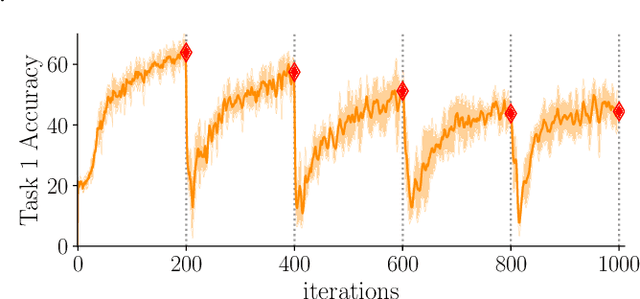
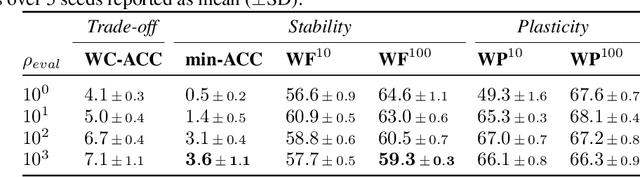
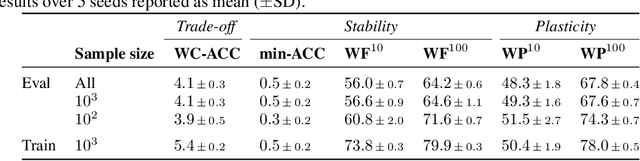
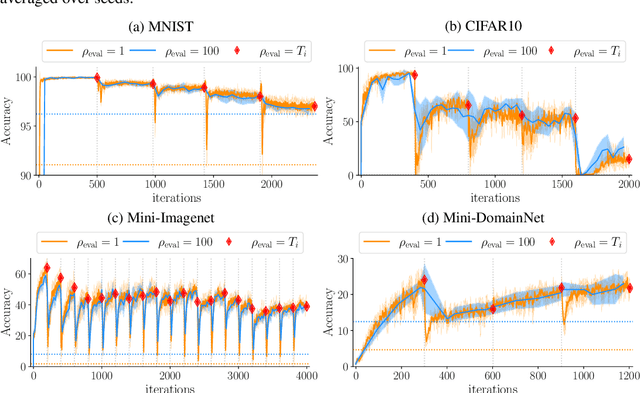
Introducing a time dependency on the data generating distribution has proven to be difficult for gradient-based training of neural networks, as the greedy updates result in catastrophic forgetting of previous timesteps. Continual learning aims to overcome the greedy optimization to enable continuous accumulation of knowledge over time. The data stream is typically divided into locally stationary distributions, called tasks, allowing task-based evaluation on held-out data from the training tasks. Contemporary evaluation protocols and metrics in continual learning are task-based and quantify the trade-off between stability and plasticity only at task transitions. However, our empirical evidence suggests that between task transitions significant, temporary forgetting can occur, remaining unidentified in task-based evaluation. Therefore, we propose a framework for continual evaluation that establishes per-iteration evaluation and define a new set of metrics that enables identifying the worst-case performance of the learner over its lifetime. Performing continual evaluation, we empirically identify that replay suffers from a stability gap: upon learning a new task, there is a substantial but transient decrease in performance on past tasks. Further conceptual and empirical analysis suggests not only replay-based, but also regularization-based continual learning methods are prone to the stability gap.
Fleet-DAgger: Interactive Robot Fleet Learning with Scalable Human Supervision
Jun 29, 2022
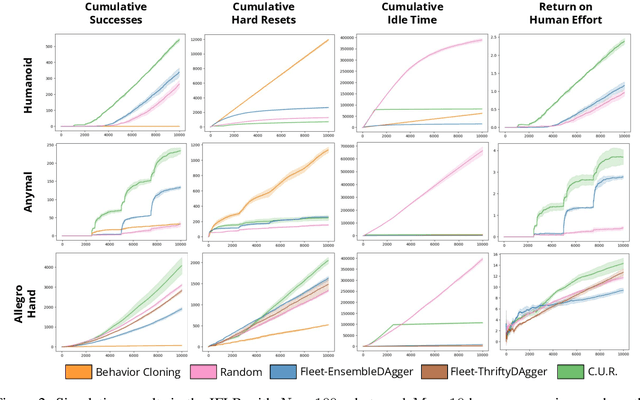
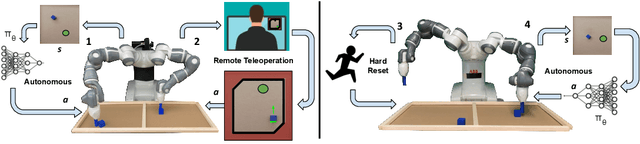
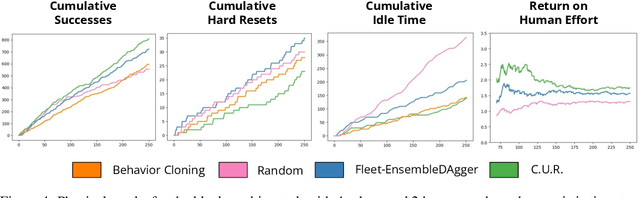
Commercial and industrial deployments of robot fleets often fall back on remote human teleoperators during execution when robots are at risk or unable to make task progress. With continual learning, interventions from the remote pool of humans can also be used to improve the robot fleet control policy over time. A central question is how to effectively allocate limited human attention to individual robots. Prior work addresses this in the single-robot, single-human setting. We formalize the Interactive Fleet Learning (IFL) setting, in which multiple robots interactively query and learn from multiple human supervisors. We present a fully implemented open-source IFL benchmark suite of GPU-accelerated Isaac Gym environments for the evaluation of IFL algorithms. We propose Fleet-DAgger, a family of IFL algorithms, and compare a novel Fleet-DAgger algorithm to 4 baselines in simulation. We also perform 1000 trials of a physical block-pushing experiment with 4 ABB YuMi robot arms. Experiments suggest that the allocation of humans to robots significantly affects robot fleet performance, and that our algorithm achieves up to 8.8x higher return on human effort than baselines. See https://tinyurl.com/fleet-dagger for code, videos, and supplemental material.
Abstraction and Refinement: Towards Scalable and Exact Verification of Neural Networks
Jul 02, 2022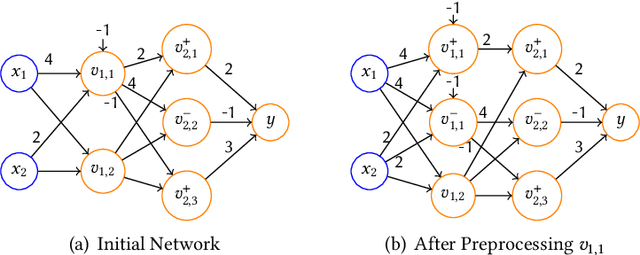
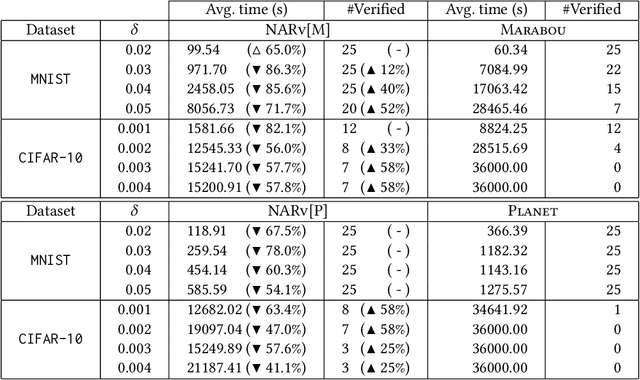
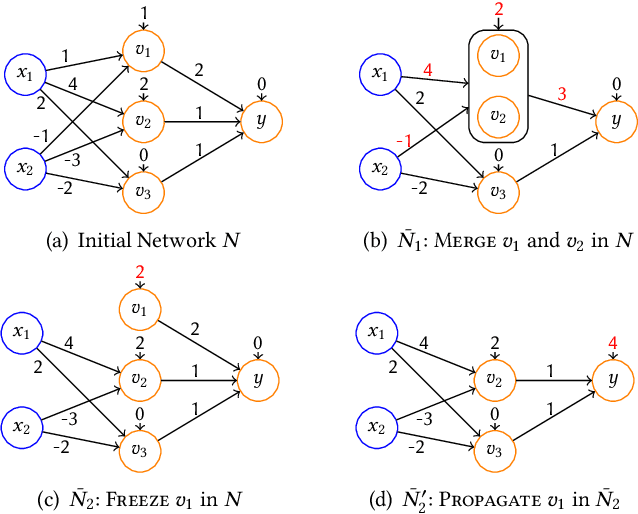
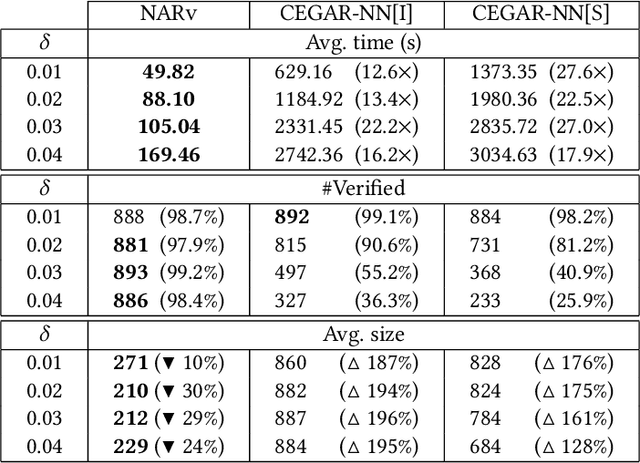
As a new programming paradigm, deep neural networks (DNNs) have been increasingly deployed in practice, but the lack of robustness hinders their applications in safety-critical domains. While there are techniques for verifying DNNs with formal guarantees, they are limited in scalability and accuracy. In this paper, we present a novel abstraction-refinement approach for scalable and exact DNN verification. Specifically, we propose a novel abstraction to break down the size of DNNs by over-approximation. The result of verifying the abstract DNN is always conclusive if no spurious counterexample is reported. To eliminate spurious counterexamples introduced by abstraction, we propose a novel counterexample-guided refinement that refines the abstract DNN to exclude a given spurious counterexample while still over-approximating the original one. Our approach is orthogonal to and can be integrated with many existing verification techniques. For demonstration, we implement our approach using two promising and exact tools Marabou and Planet as the underlying verification engines, and evaluate on widely-used benchmarks ACAS Xu, MNIST and CIFAR-10. The results show that our approach can boost their performance by solving more problems and reducing up to 86.3% and 78.0% verification time, respectively. Compared to the most relevant abstraction-refinement approach, our approach is 11.6-26.6 times faster.
Provably Precise, Succinct and Efficient Explanations for Decision Trees
May 19, 2022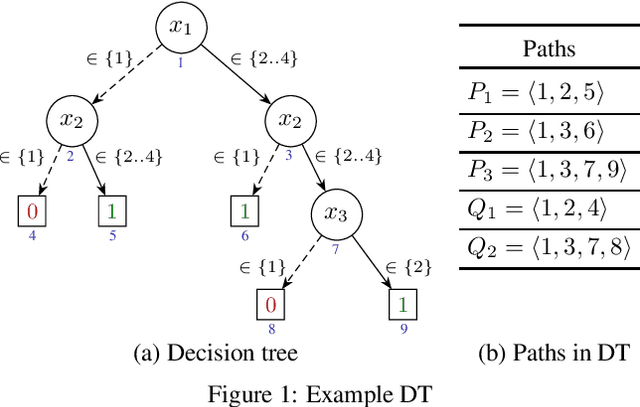

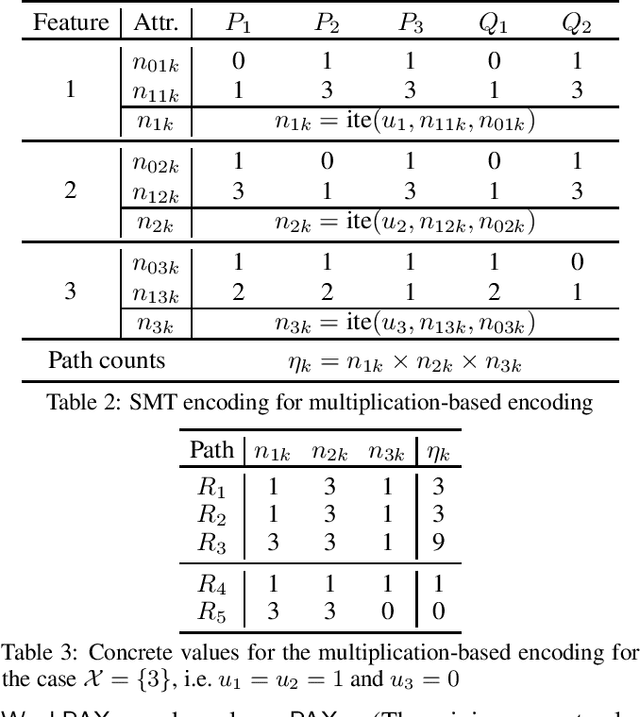
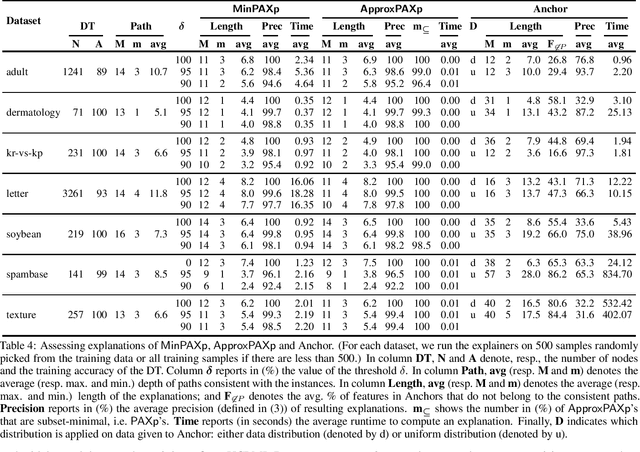
Decision trees (DTs) embody interpretable classifiers. DTs have been advocated for deployment in high-risk applications, but also for explaining other complex classifiers. Nevertheless, recent work has demonstrated that predictions in DTs ought to be explained with rigorous approaches. Although rigorous explanations can be computed in polynomial time for DTs, their size may be beyond the cognitive limits of human decision makers. This paper investigates the computation of {\delta}-relevant sets for DTs. {\delta}-relevant sets denote explanations that are succinct and provably precise. These sets represent generalizations of rigorous explanations, which are precise with probability one, and so they enable trading off explanation size for precision. The paper proposes two logic encodings for computing smallest {\delta}-relevant sets for DTs. The paper further devises a polynomial-time algorithm for computing {\delta}-relevant sets which are not guaranteed to be subset-minimal, but for which the experiments show to be most often subset-minimal in practice. The experimental results also demonstrate the practical efficiency of computing smallest {\delta}-relevant sets.
AggNet: Learning to Aggregate Faces for Group Membership Verification
Jun 17, 2022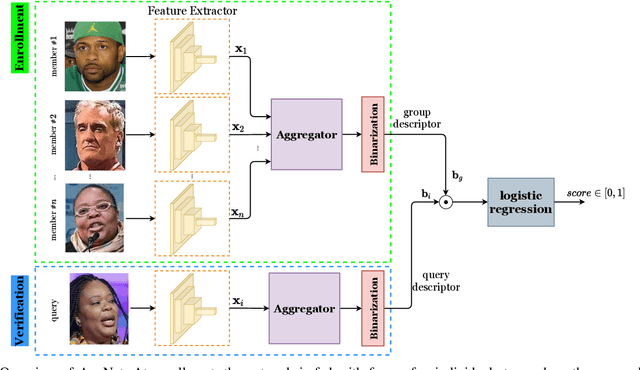
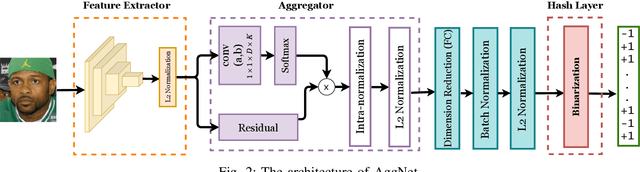
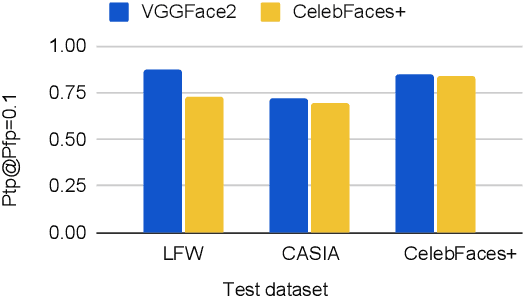
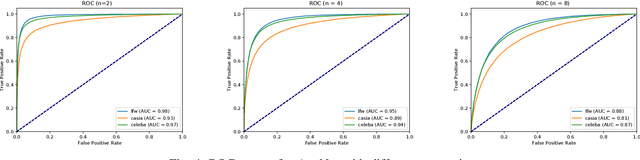
In some face recognition applications, we are interested to verify whether an individual is a member of a group, without revealing their identity. Some existing methods, propose a mechanism for quantizing precomputed face descriptors into discrete embeddings and aggregating them into one group representation. However, this mechanism is only optimized for a given closed set of individuals and needs to learn the group representations from scratch every time the groups are changed. In this paper, we propose a deep architecture that jointly learns face descriptors and the aggregation mechanism for better end-to-end performances. The system can be applied to new groups with individuals never seen before and the scheme easily manages new memberships or membership endings. We show through experiments on multiple large-scale wild-face datasets, that the proposed method leads to higher verification performance compared to other baselines.
ReMix: A General and Efficient Framework for Multiple Instance Learning based Whole Slide Image Classification
Jul 05, 2022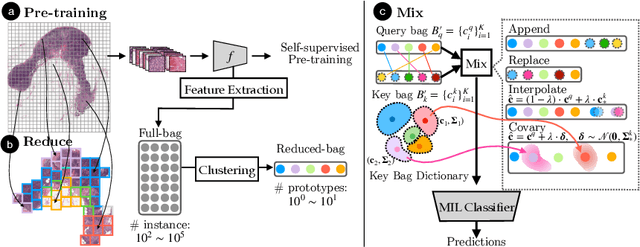
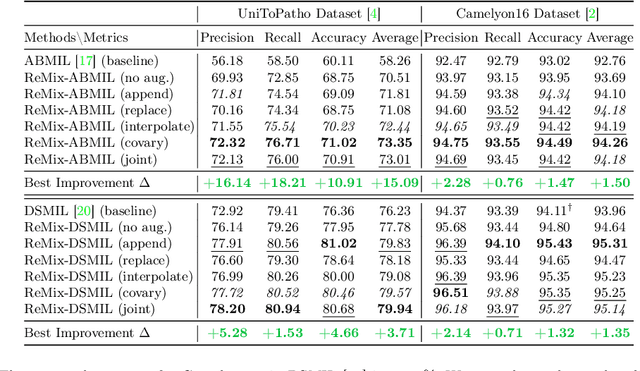
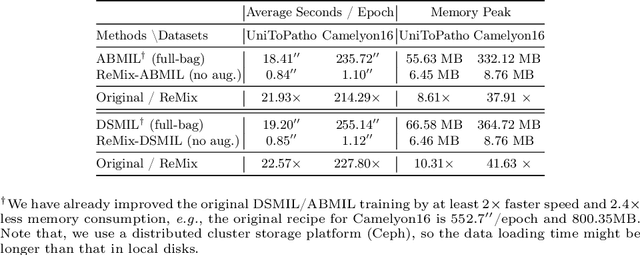

Whole slide image (WSI) classification often relies on deep weakly supervised multiple instance learning (MIL) methods to handle gigapixel resolution images and slide-level labels. Yet the decent performance of deep learning comes from harnessing massive datasets and diverse samples, urging the need for efficient training pipelines for scaling to large datasets and data augmentation techniques for diversifying samples. However, current MIL-based WSI classification pipelines are memory-expensive and computation-inefficient since they usually assemble tens of thousands of patches as bags for computation. On the other hand, despite their popularity in other tasks, data augmentations are unexplored for WSI MIL frameworks. To address them, we propose ReMix, a general and efficient framework for MIL based WSI classification. It comprises two steps: reduce and mix. First, it reduces the number of instances in WSI bags by substituting instances with instance prototypes, i.e., patch cluster centroids. Then, we propose a ``Mix-the-bag'' augmentation that contains four online, stochastic and flexible latent space augmentations. It brings diverse and reliable class-identity-preserving semantic changes in the latent space while enforcing semantic-perturbation invariance. We evaluate ReMix on two public datasets with two state-of-the-art MIL methods. In our experiments, consistent improvements in precision, accuracy, and recall have been achieved but with orders of magnitude reduced training time and memory consumption, demonstrating ReMix's effectiveness and efficiency. Code is available.
Streaming non-autoregressive model for any-to-many voice conversion
Jun 15, 2022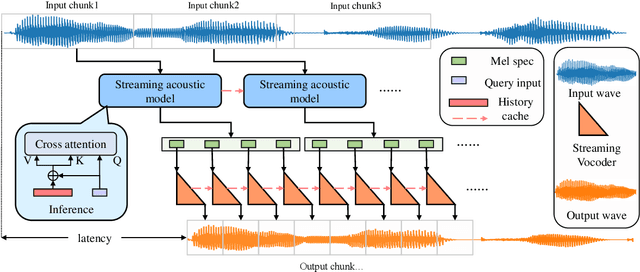
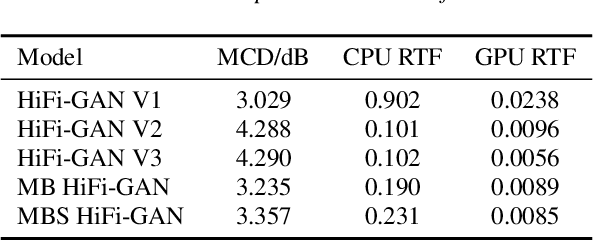
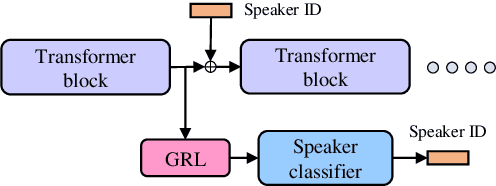
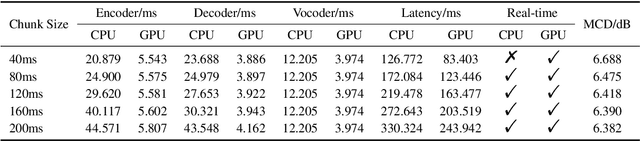
Voice conversion models have developed for decades, and current mainstream research focuses on non-streaming voice conversion. However, streaming voice conversion is more suitable for practical application scenarios than non-streaming voice conversion. In this paper, we propose a streaming any-to-many voice conversion based on fully non-autoregressive model, which includes a streaming transformer based acoustic model and a streaming vocoder. Streaming transformer based acoustic model is composed of a pre-trained encoder from streaming end-to-end based automatic speech recognition model and a decoder modified on FastSpeech blocks. Streaming vocoder is designed for streaming task with pseudo quadrature mirror filter bank and causal convolution. Experimental results show that the proposed method achieves significant performance both in latency and conversion quality and can be real-time on CPU and GPU.
CoCoPIE XGen: A Full-Stack AI-Oriented Optimizing Framework
Jun 21, 2022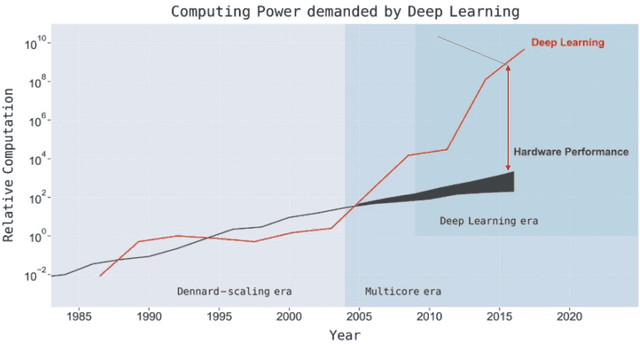
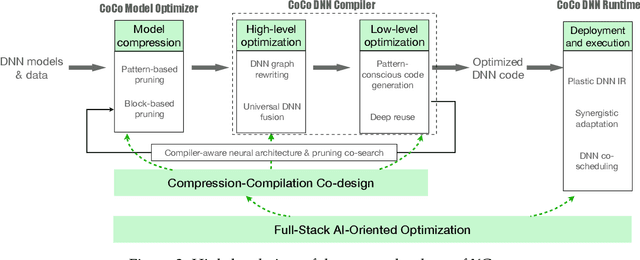

There is a growing demand for shifting the delivery of AI capability from data centers on the cloud to edge or end devices, exemplified by the fast emerging real-time AI-based apps running on smartphones, AR/VR devices, autonomous vehicles, and various IoT devices. The shift has however been seriously hampered by the large growing gap between DNN computing demands and the computing power on edge or end devices. This article presents the design of XGen, an optimizing framework for DNN designed to bridge the gap. XGen takes cross-cutting co-design as its first-order consideration. Its full-stack AI-oriented optimizations consist of a number of innovative optimizations at every layer of the DNN software stack, all designed in a cooperative manner. The unique technology makes XGen able to optimize various DNNs, including those with an extreme depth (e.g., BERT, GPT, other transformers), and generate code that runs several times faster than those from existing DNN frameworks, while delivering the same level of accuracy.
Pre-RTL DNN Hardware Evaluator With Fused Layer Support
May 02, 2022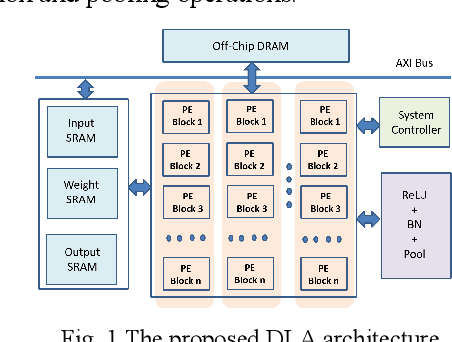
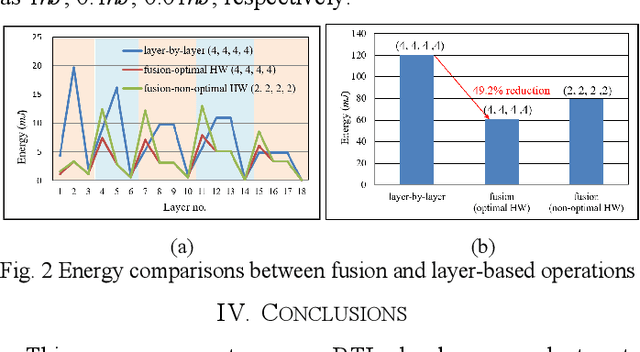
With the popularity of the deep neural network (DNN), hardware accelerators are demanded for real time execution. However, lengthy design process and fast evolving DNN models make hardware evaluation hard to meet the time to market need. This paper proposes a pre-RTL DNN hardware evaluator that supports conventional layer-by-layer processing as well as the fused layer processing for low external bandwidth requirement. The evaluator supports two state-of-the-art accelerator architectures and finds the best hardware and layer fusion group The experimental results show the layer fusion scheme can achieve 55.6% memory bandwidth reduction, 36.7% latency improvement and 49.2% energy reduction compared with layer-by-layer operation.
Online learning of windmill time series using Long Short-term Cognitive Networks
Jul 01, 2021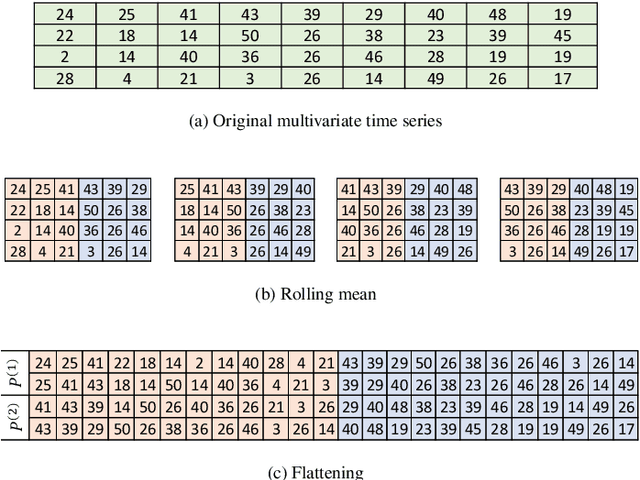
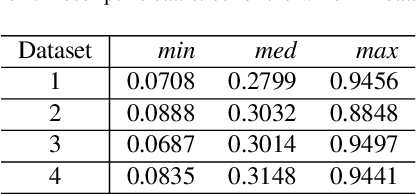
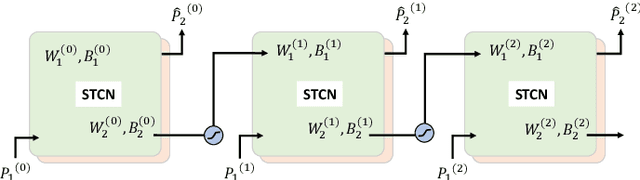
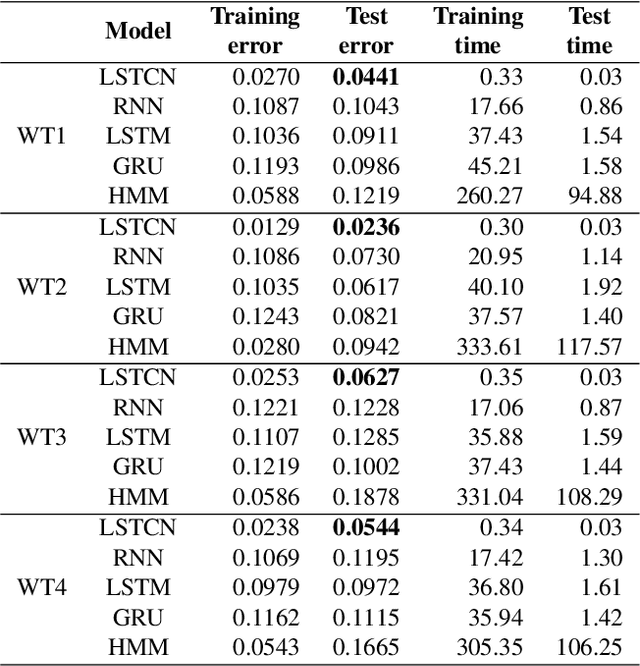
Forecasting windmill time series is often the basis of other processes such as anomaly detection, health monitoring, or maintenance scheduling. The amount of data generated on windmill farms makes online learning the most viable strategy to follow. Such settings require retraining the model each time a new batch of data is available. However, update the model with the new information is often very expensive to perform using traditional Recurrent Neural Networks (RNNs). In this paper, we use Long Short-term Cognitive Networks (LSTCNs) to forecast windmill time series in online settings. These recently introduced neural systems consist of chained Short-term Cognitive Network blocks, each processing a temporal data chunk. The learning algorithm of these blocks is based on a very fast, deterministic learning rule that makes LSTCNs suitable for online learning tasks. The numerical simulations using a case study with four windmills showed that our approach reported the lowest forecasting errors with respect to a simple RNN, a Long Short-term Memory, a Gated Recurrent Unit, and a Hidden Markov Model. What is perhaps more important is that the LSTCN approach is significantly faster than these state-of-the-art models.