 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coexistence between Task- and Data-Oriented Communications: A Whittle's Index Guided Multi-Agent Reinforcement Learning Approach
May 19, 2022
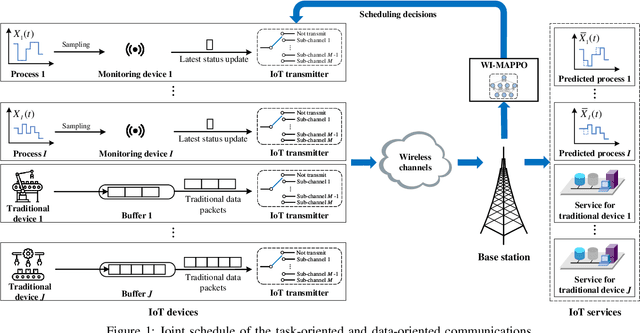
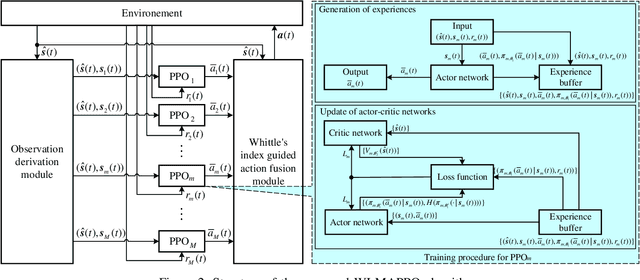
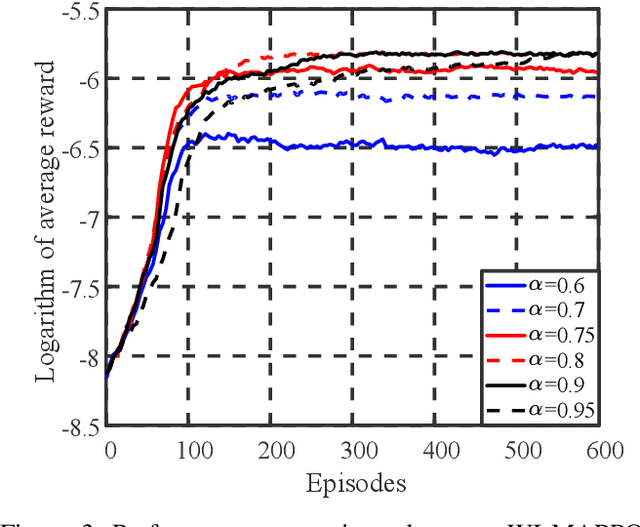
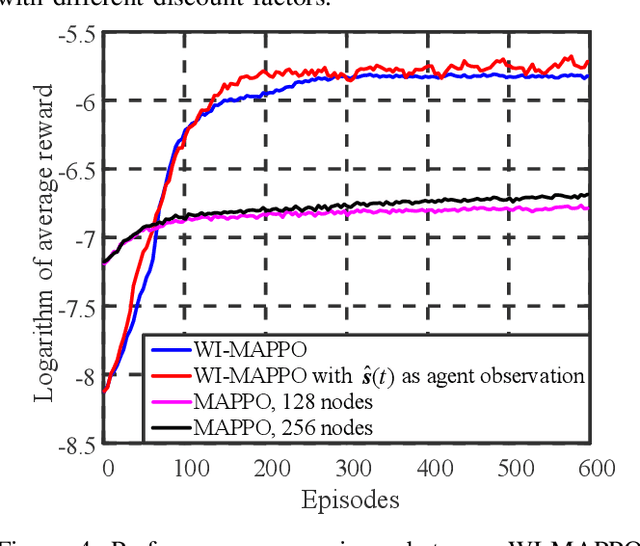
We investigate the coexistence of task-oriented and data-oriented communications in a IoT system that shares a group of channels, and study the scheduling problem to jointly optimize the weighted age of incorrect information (AoII) and throughput, which are the performance metrics of the two types of communications, respectively. This problem is formulated as a Markov decision problem, which is difficult to solve due to the large discrete action space and the time-varying action constraints induced by the stochastic availability of channels. By exploiting the intrinsic properties of this problem and reformulating the reward function based on channel statistics, we first simplify the solution space, state space, and optimality criteria, and convert it to an equivalent Markov game, for which the large discrete action space issue is greatly relieved. Then, we propose a Whittle's index guided multi-agent proximal policy optimization (WI-MAPPO) algorithm to solve the considered game, where the embedded Whittle's index module further shrinks the action space, and the proposed offline training algorithm extends the training kernel of conventional MAPPO to address the issue of time-varying constraints. Finally, numerical results validate that the proposed algorithm significantly outperforms state-of-the-art age of information (AoI) based algorithms under scenarios with insufficient channel resources.
Saturation region of Freeway Networks under Safe Microscopic Ramp Metering
Jul 05, 2022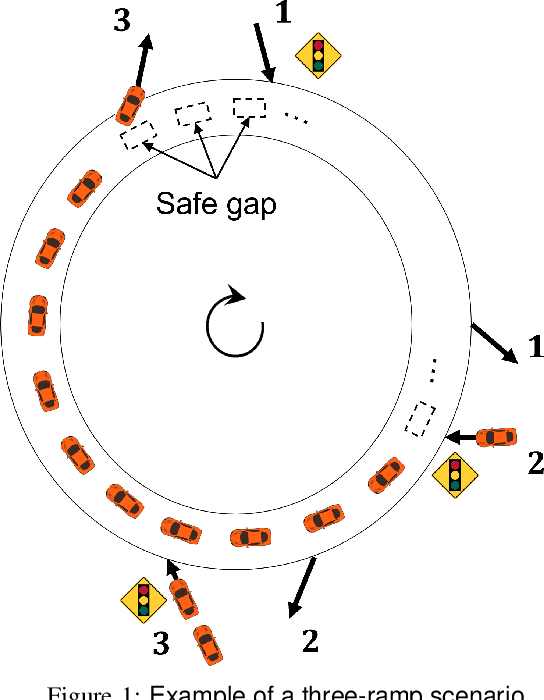
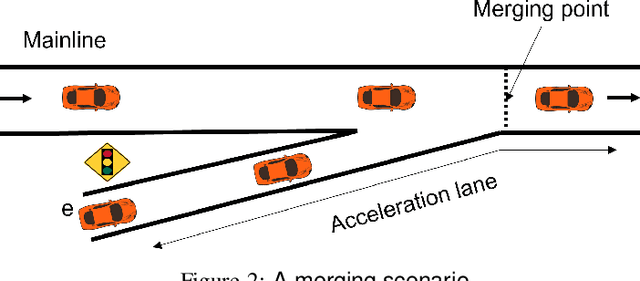
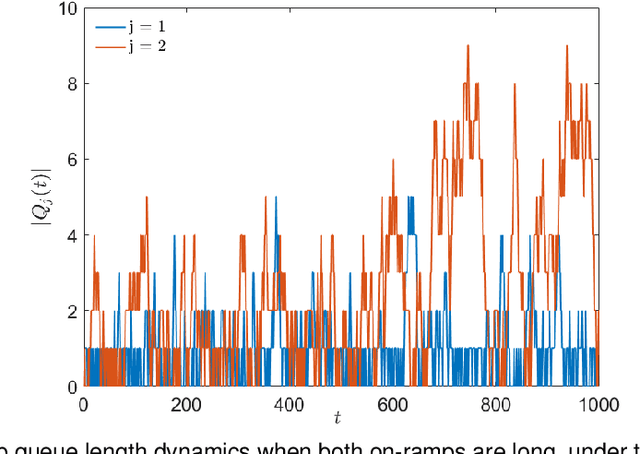
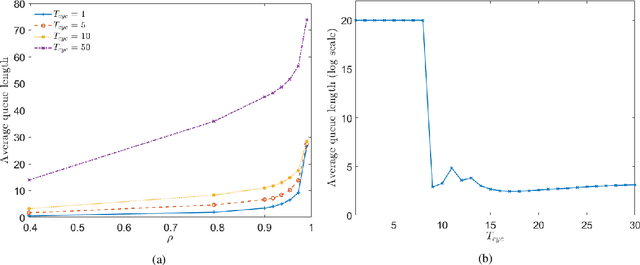
We consider ramp metering at the microscopic level subject to vehicle safety constraint. The traffic network is abstracted by a ring road with multiple on- and off-ramps. The arrival times of vehicles to the on-ramps, as well as their destination off-ramps are modeled by exogenous stochastic processes. Once a vehicle is released from an on-ramp, it accelerates towards the free flow speed if it is not obstructed by another vehicle; once it gets close to another vehicle, it adopts a safe behavior. The vehicle exits the traffic network once it reaches its destination off-ramp. We design traffic-responsive ramp metering policies which maximize the saturation region of the network. The saturation region of a policy is defined as the set of demands, i.e., arrival rates and the routing matrix, for which the queue lengths at all the on-ramps remain bounded in expectation. The proposed ramp metering policies operate under synchronous cycles during which an on-ramp does not release more vehicles than its queue length at the beginning of the cycle. We provide three policies under which, respectively, each on-ramp (i) pauses release for a time-interval at the end of the cycle, or (ii) modulates the release rate during the cycle, or (iii) adopts a conservative safety criterion for release during the cycle. None of the policies, however, require information about the demand. The saturation region of these policies is characterized by studying stochastic stability of the induced Markov chains, and is proven to be maximal when the merging speed of all on-ramps equals the free flow speed. Simulations are provided to illustrate the performance of the policies.
Emotion recognition by fusing time synchronous and time asynchronous representations
Oct 27, 2020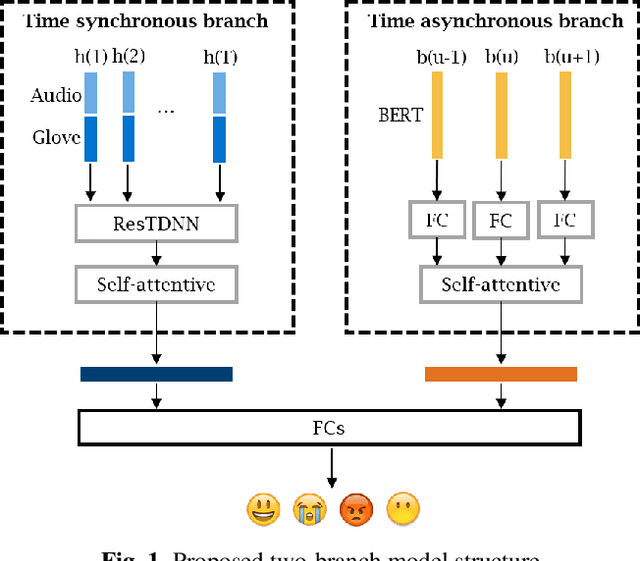



In this paper, a novel two-branch neural network model structure is proposed for multimodal emotion recognition, which consists of a time synchronous branch (TSB) and a time asynchronous branch (TAB). To capture correlations between each word and its acoustic realisation, the TSB combines speech and text modalities at each input window frame and then does pooling across time to form a single embedding vector. The TAB, by contrast, provides cross-utterance information by integrating sentence text embeddings from a number of context utterances into another embedding vector. The final emotion classification uses both the TSB and the TAB embeddings. Experimental results on the IEMOCAP dataset demonstrate that the two-branch structure achieves state-of-the-art results in 4-way classification with all common test setups. When using automatic speech recognition (ASR) output instead of manually transcribed reference text, it is shown that the cross-utterance information considerably improves the robustness against ASR errors. Furthermore, by incorporating an extra class for all the other emotions, the final 5-way classification system with ASR hypotheses can be viewed as a prototype for more realistic emotion recognition systems.
PTFlash : A deep learning framework for isothermal two-phase equilibrium calculations
May 19, 2022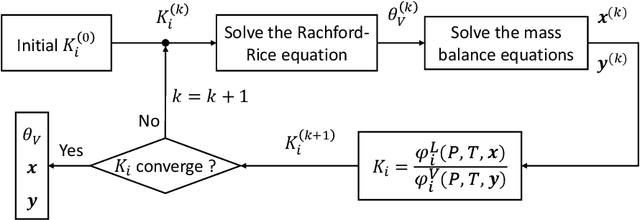
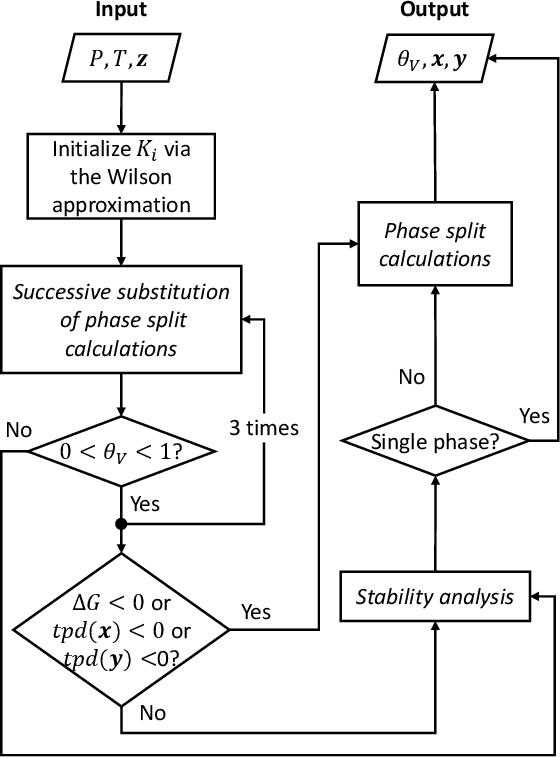
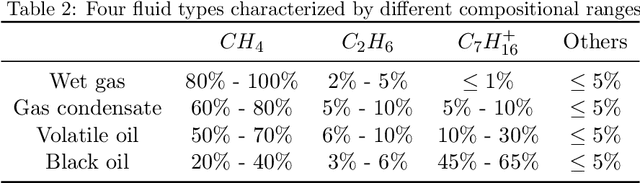
Phase equilibrium calculations are an essential part of numerical simulations of multi-component multi-phase flow in porous media, accounting for the largest share of the computational time. In this work, we introduce a GPUenabled, fast, and parallel framework, PTFlash, that vectorizes algorithms required for isothermal two-phase flash calculations using PyTorch, and can facilitate a wide range of downstream applications. In addition, to further accelerate PTFlash, we design two task-specific neural networks, one for predicting the stability of given mixtures and the other for providing estimates of the distribution coefficients, which are trained offline and help shorten computation time by sidestepping stability analysis and reducing the number of iterations to reach convergence. The evaluation of PTFlash was conducted on three case studies involving hydrocarbons, CO 2 and N 2 , for which the phase equilibrium was tested over a large range of temperature, pressure and composition conditions, using the Soave-Redlich-Kwong (SRK) equation of state. We compare PTFlash with an in-house thermodynamic library, Carnot, written in C++ and performing flash calculations one by one on CPU. Results show speed-ups on large scale calculations up to two order of magnitudes, while maintaining perfect precision with the reference solution provided by Carnot.
The Temporal Dictionary Ensemble (TDE) Classifier for Time Series Classification
May 09, 2021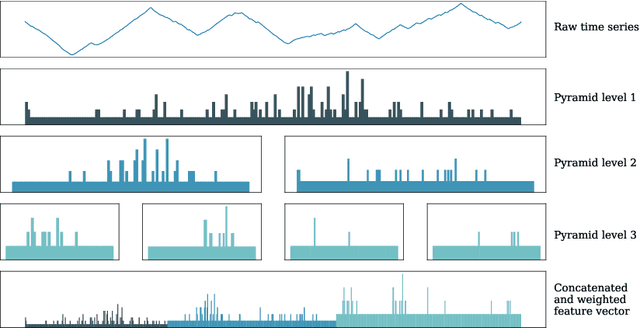
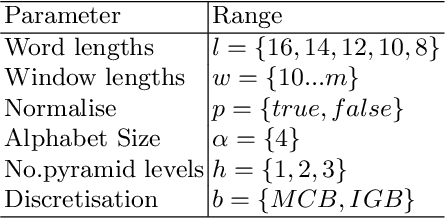
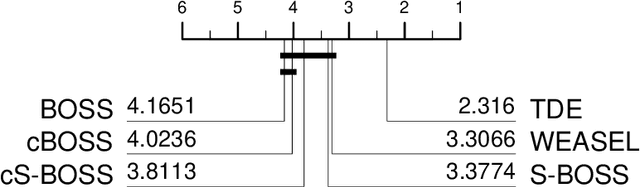
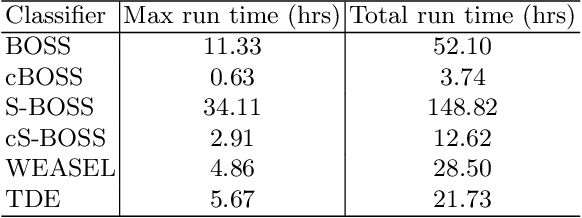
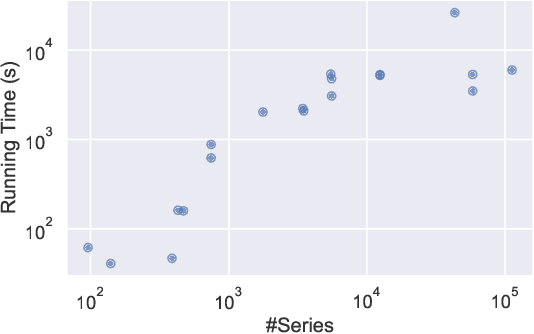
Using bag of words representations of time series is a popular approach to time series classification. These algorithms involve approximating and discretising windows over a series to form words, then forming a count of words over a given dictionary. Classifiers are constructed on the resulting histograms of word counts. A 2017 evaluation of a range of time series classifiers found the bag of symbolic-fourier approximation symbols (BOSS) ensemble the best of the dictionary based classifiers. It forms one of the components of hierarchical vote collective of transformation-based ensembles (HIVE-COTE), which represents the current state of the art. Since then, several new dictionary based algorithms have been proposed that are more accurate or more scalable (or both) than BOSS. We propose a further extension of these dictionary based classifiers that combines the best elements of the others combined with a novel approach to constructing ensemble members based on an adaptive Gaussian process model of the parameter space. We demonstrate that the temporal dictionary ensemble (TDE) is more accurate than other dictionary based approaches. Furthermore, unlike the other classifiers, if we replace BOSS in HIVE-COTE with TDE, HIVE-COTE is significantly more accurate. We also show this new version of HIVE-COTE is significantly more accurate than the current best deep learning approach, a recently proposed hybrid tree ensemble and a recently introduced competitive classifier making use of highly randomised convolutional kernels. This advance represents a new state of the art for time series classification.
* arXiv admin note: text overlap with arXiv:1911.12008
Interpretable Feature Construction for Time Series Extrinsic Regression
Mar 15, 2021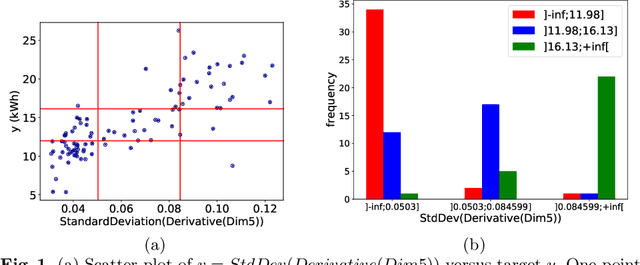
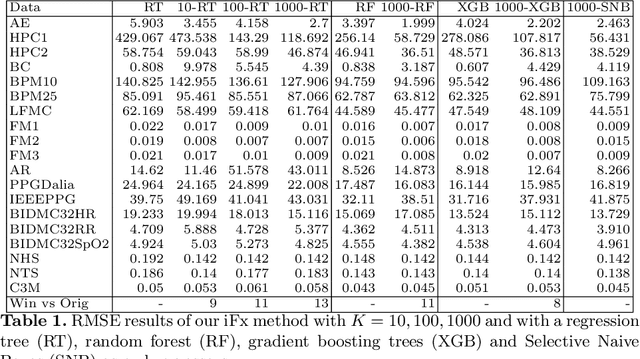
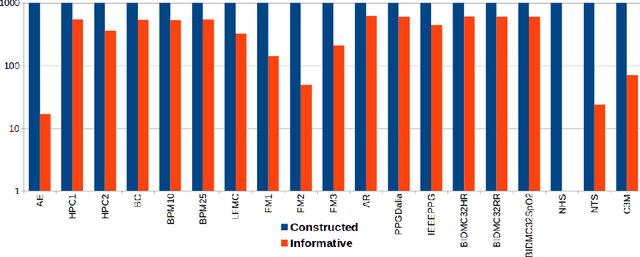
Supervised learning of time series data has been extensively studied for the case of a categorical target variable. In some application domains, e.g., energy, environment and health monitoring, it occurs that the target variable is numerical and the problem is known as time series extrinsic regression (TSER). In the literature, some well-known time series classifiers have been extended for TSER problems. As first benchmarking studies have focused on predictive performance, very little attention has been given to interpretability. To fill this gap, in this paper, we suggest an extension of a Bayesian method for robust and interpretable feature construction and selection in the context of TSER. Our approach exploits a relational way to tackle with TSER: (i), we build various and simple representations of the time series which are stored in a relational data scheme, then, (ii), a propositionalisation technique (based on classical aggregation / selection functions from the relational data field) is applied to build interpretable features from secondary tables to "flatten" the data; and (iii), the constructed features are filtered out through a Bayesian Maximum A Posteriori approach. The resulting transformed data can be processed with various existing regressors. Experimental validation on various benchmark data sets demonstrates the benefits of the suggested approach.
Robust and Recursively Feasible Real-Time Trajectory Planning in Unknown Environments
Jul 14, 2021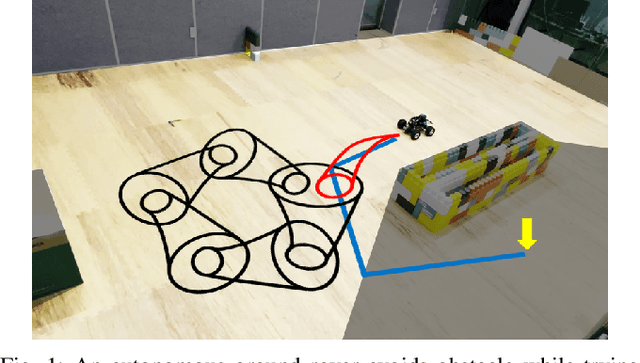
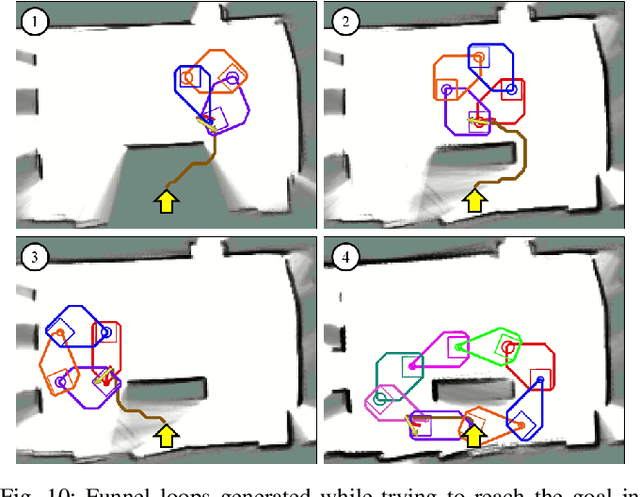
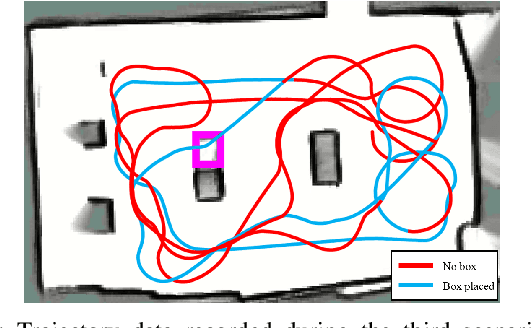
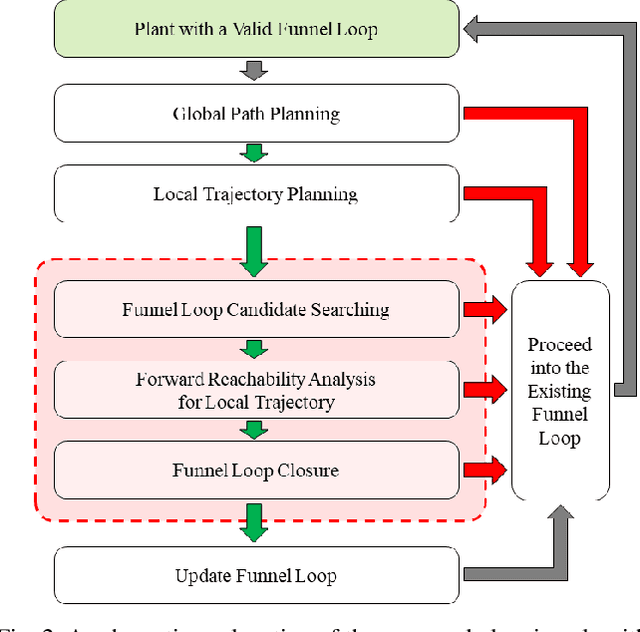
Motion planners for mobile robots in unknown environments face the challenge of simultaneously maintaining both robustness against unmodeled uncertainties and persistent feasibility of the trajectory-finding problem. That is, while dealing with uncertainties, a motion planner must update its trajectory, adapting to the newly revealed environment in real-time; failing to do so may involve unsafe circumstances. Many existing planning algorithms guarantee these by maintaining the clearance needed to perform an emergency brake, which is itself a robust and persistently feasible maneuver. However, such maneuvers are not applicable for systems in which braking is impossible or risky, such as fixed-wing aircraft. To that end, we propose a real-time robust planner that recursively guarantees persistent feasibility without any need of braking. The planner ensures robustness against bounded uncertainties and persistent feasibility by constructing a loop of sequentially composed funnels, starting from the receding horizon local trajectory's forward reachable set. We implement the proposed algorithm for a robotic car tracking a speed-fixed reference trajectory. The experiment results show that the proposed algorithm can be run at faster than 16 Hz, while successfully keeping the system away from entering any dead-end, to maintain safety and feasibility.
Gradient-Enhanced Physics-Informed Neural Networks for Power Systems Operational Support
Jun 21, 2022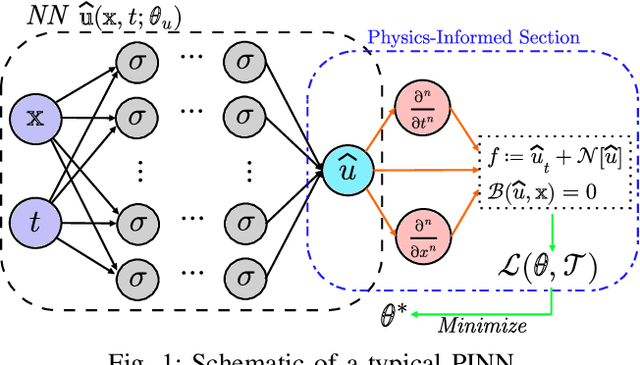
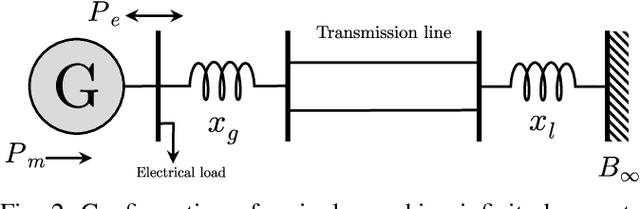
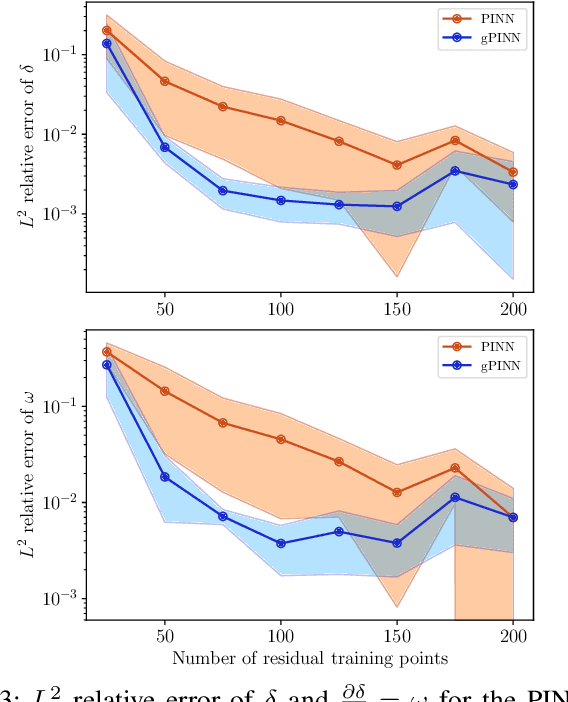
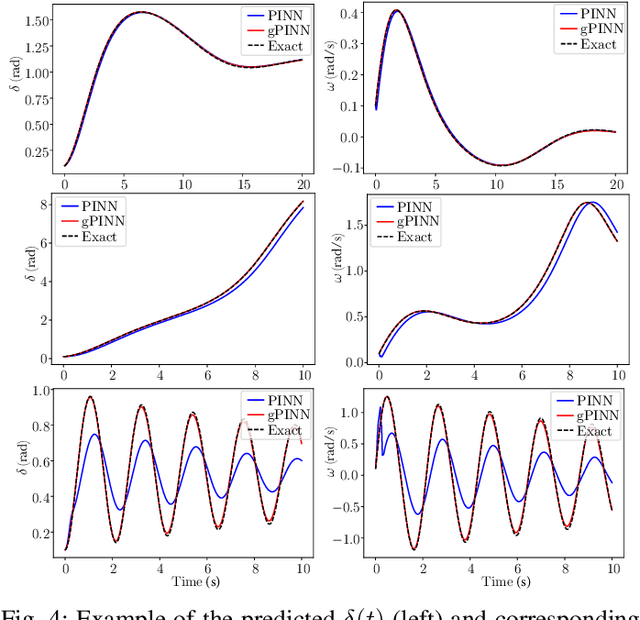
The application of deep learning methods to speed up the resolution of challenging power flow problems has recently shown very encouraging results. However, power system dynamics are not snap-shot, steady-state operations. These dynamics must be considered to ensure that the optimal solutions provided by these models adhere to practical dynamical constraints, avoiding frequency fluctuations and grid instabilities. Unfortunately, dynamic system models based on ordinary or partial differential equations are frequently unsuitable for direct application in control or state estimates due to their high computational costs. To address these challenges, this paper introduces a machine learning method to approximate the behavior of power systems dynamics in near real time. The proposed framework is based on gradient-enhanced physics-informed neural networks (gPINNs) and encodes the underlying physical laws governing power systems. A key characteristic of the proposed gPINN is its ability to train without the need of generating expensive training data. The paper illustrates the potential of the proposed approach in both forward and inverse problems in a single-machine infinite bus system for predicting rotor angles and frequency, and uncertain parameters such as inertia and damping to showcase its potential for a range of power systems applications.
Scaling up Kernels in 3D CNNs
Jun 21, 2022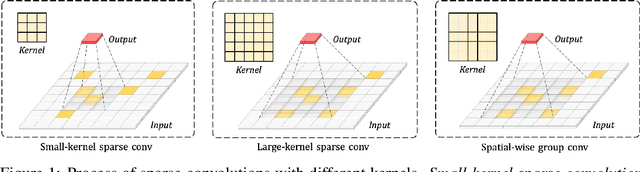
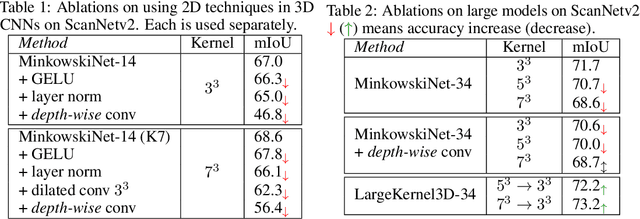

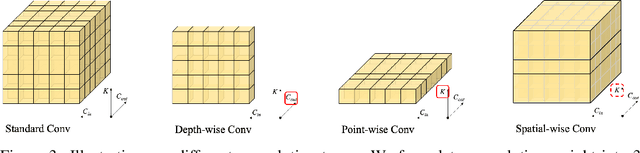
Recent advances in 2D CNNs and vision transformers (ViTs) reveal that large kernels are essential for enough receptive fields and high performance. Inspired by this literature, we examine the feasibility and challenges of 3D large-kernel designs. We demonstrate that applying large convolutional kernels in 3D CNNs has more difficulties in both performance and efficiency. Existing techniques that work well in 2D CNNs are ineffective in 3D networks, including the popular depth-wise convolutions. To overcome these obstacles, we present the spatial-wise group convolution and its large-kernel module (SW-LK block). It avoids the optimization and efficiency issues of naive 3D large kernels. Our large-kernel 3D CNN network, i.e., LargeKernel3D, yields non-trivial improvements on various 3D tasks, including semantic segmentation and object detection. Notably, it achieves 73.9% mIoU on the ScanNetv2 semantic segmentation and 72.8% NDS nuScenes object detection benchmarks, ranking 1st on the nuScenes LIDAR leaderboard. It is further boosted to 74.2% NDS with a simple multi-modal fusion. LargeKernel3D attains comparable or superior results than its CNN and transformer counterparts. For the first time, we show that large kernels are feasible and essential for 3D networks.
On-Device Training Under 256KB Memory
Jun 30, 2022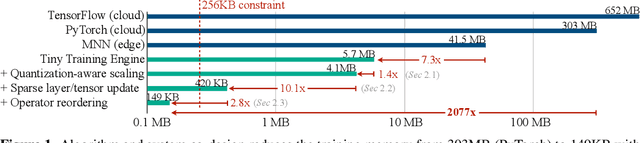
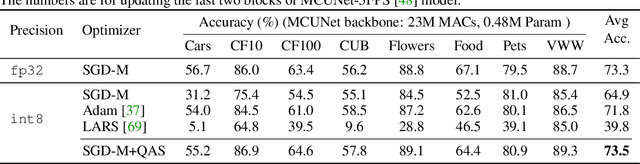
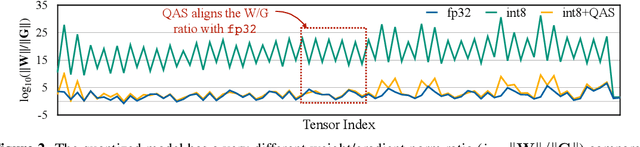
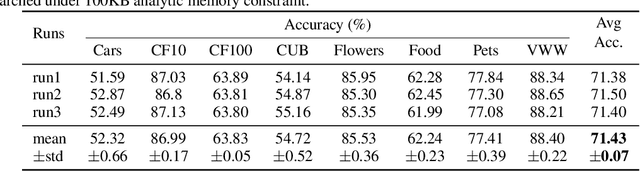
On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to mixed bit-precision and the lack of normalization; (2) the limited hardware resource (memory and computation) does not allow full backward computation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offloads the runtime auto-differentiation to compile time. Our framework is the first practical solution for on-device transfer learning of visual recognition on tiny IoT devices (e.g., a microcontroller with only 256KB SRAM), using less than 1/100 of the memory of existing frameworks while matching the accuracy of cloud training+edge deployment for the tinyML application VWW. Our study enables IoT devices to not only perform inference but also continuously adapt to new data for on-device lifelong learning.