 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Chimera: A Hybrid Machine Learning Driven Multi-Objective Design Space Exploration Tool for FPGA High-Level Synthesis
Jul 03, 2022
In recent years, hardware accelerators based on field-programmable gate arrays (FPGAs) have been widely adopted, thanks to FPGAs' extraordinary flexibility. However, with the high flexibility comes the difficulty in design and optimization. Conventionally, these accelerators are designed with low-level hardware descriptive languages, which means creating large designs with complex behavior is extremely difficult. Therefore, high-level synthesis (HLS) tools were created to simplify hardware designs for FPGAs. They enable the user to create hardware designs using high-level languages and provide various optimization directives to help to improve the performance of the synthesized hardware. However, applying these optimizations to achieve high performance is time-consuming and usually requires expert knowledge. To address this difficulty, we present an automated design space exploration tool for applying HLS optimization directives, called Chimera, which significantly reduces the human effort and expertise needed for creating high-performance HLS designs. It utilizes a novel multi-objective exploration method that seamlessly integrates active learning, evolutionary algorithm, and Thompson sampling, making it capable of finding a set of optimized designs on a Pareto curve with only a small number of design points evaluated during the exploration. In the experiments, in less than 24 hours, this hybrid method explored design points that have the same or superior performance compared to highly optimized hand-tuned designs created by expert HLS users from the Rosetta benchmark suite. In addition to discovering the extreme points, it also explores a Pareto frontier, where the elbow point can potentially save up to 26\% of Flip-Flop resource with negligibly higher latency.
Algorithm for Constrained Markov Decision Process with Linear Convergence
Jun 03, 2022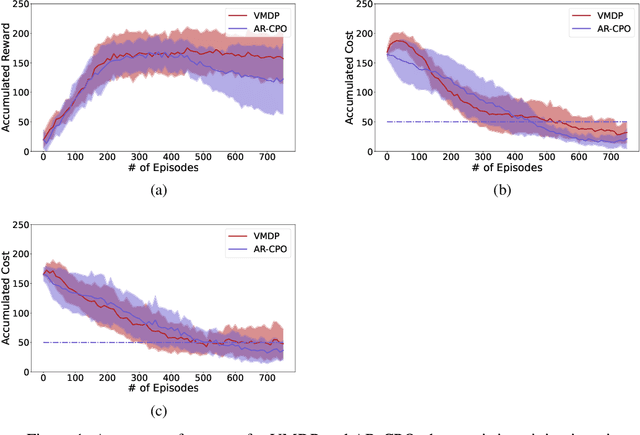

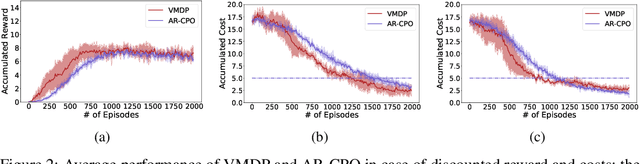
The problem of constrained Markov decision process is considered. An agent aims to maximize the expected accumulated discounted reward subject to multiple constraints on its costs (the number of constraints is relatively small). A new dual approach is proposed with the integration of two ingredients: entropy regularized policy optimizer and Vaidya's dual optimizer, both of which are critical to achieve faster convergence. The finite-time error bound of the proposed approach is provided. Despite the challenge of the nonconcave objective subject to nonconcave constraints, the proposed approach is shown to converge (with linear rate) to the global optimum. The complexity expressed in terms of the optimality gap and the constraint violation significantly improves upon the existing primal-dual approaches.
Play It Cool: Dynamic Shifting Prevents Thermal Throttling
Jun 22, 2022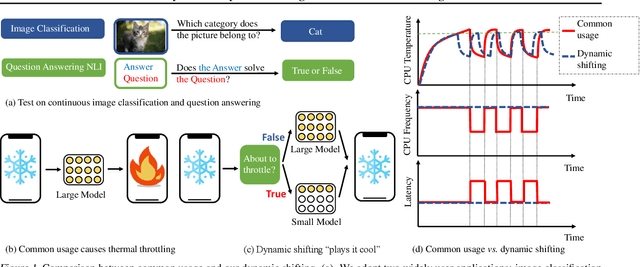
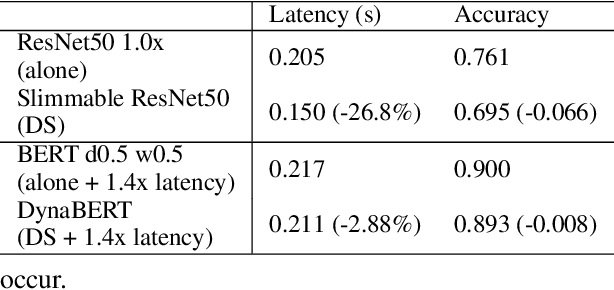
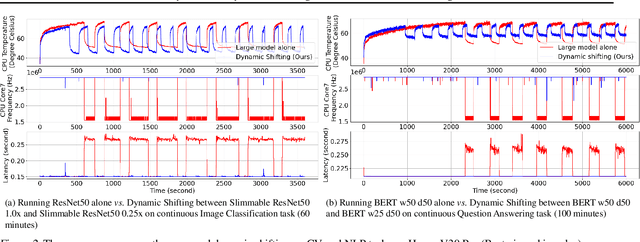
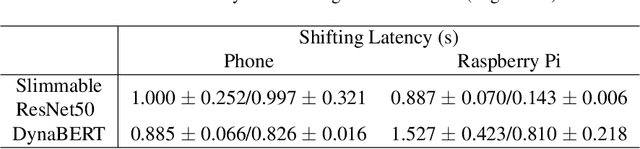
Machine learning (ML) has entered the mobile era where an enormous number of ML models are deployed on edge devices. However, running common ML models on edge devices continuously may generate excessive heat from the computation, forcing the device to "slow down" to prevent overheating, a phenomenon called thermal throttling. This paper studies the impact of thermal throttling on mobile phones: when it occurs, the CPU clock frequency is reduced, and the model inference latency may increase dramatically. This unpleasant inconsistent behavior has a substantial negative effect on user experience, but it has been overlooked for a long time. To counter thermal throttling, we propose to utilize dynamic networks with shared weights and dynamically shift between large and small ML models seamlessly according to their thermal profile, i.e., shifting to a small model when the system is about to throttle. With the proposed dynamic shifting, the application runs consistently without experiencing CPU clock frequency degradation and latency increase. In addition, we also study the resulting accuracy when dynamic shifting is deployed and show that our approach provides a reasonable trade-off between model latency and model accuracy.
LT-OCF: Learnable-Time ODE-based Collaborative Filtering
Aug 16, 2021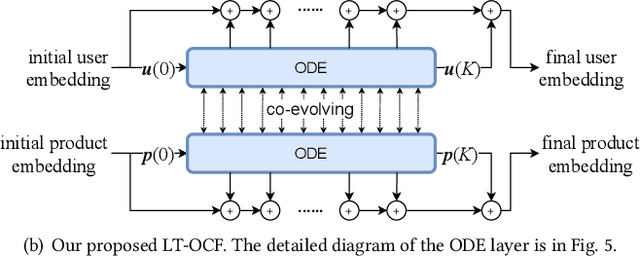
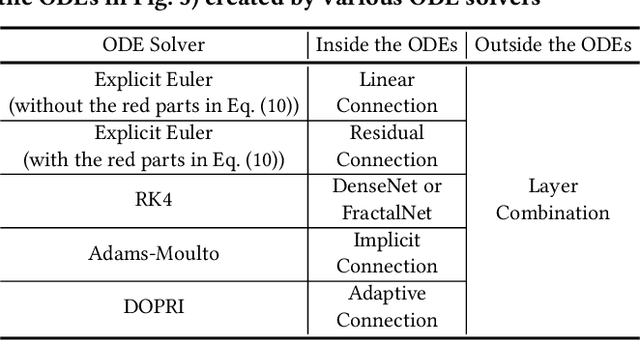
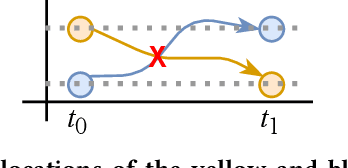
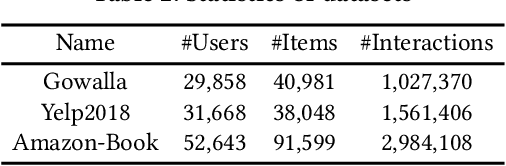
Collaborative filtering (CF) is a long-standing problem of recommender systems. Many novel methods have been proposed, ranging from classical matrix factorization to recent graph convolutional network-based approaches. After recent fierce debates, researchers started to focus on linear graph convolutional networks (GCNs) with a layer combination, which show state-of-the-art accuracy in many datasets. In this work, we extend them based on neural ordinary differential equations (NODEs), because the linear GCN concept can be interpreted as a differential equation, and present the method of Learnable-Time ODE-based Collaborative Filtering (LT-OCF). The main novelty in our method is that after redesigning linear GCNs on top of the NODE regime, i) we learn the optimal architecture rather than relying on manually designed ones, ii) we learn smooth ODE solutions that are considered suitable for CF, and iii) we test with various ODE solvers that internally build a diverse set of neural network connections. We also present a novel training method specialized to our method. In our experiments with three benchmark datasets, Gowalla, Yelp2018, and Amazon-Book, our method consistently shows better accuracy than existing methods, e.g., a recall of 0.0411 by LightGCN vs. 0.0442 by LT-OCF and an NDCG of 0.0315 by LightGCN vs. 0.0341 by LT-OCF in Amazon-Book. One more important discovery in our experiments that is worth mentioning is that our best accuracy was achieved by dense connections rather than linear connections.
Conformalized Online Learning: Online Calibration Without a Holdout Set
May 19, 2022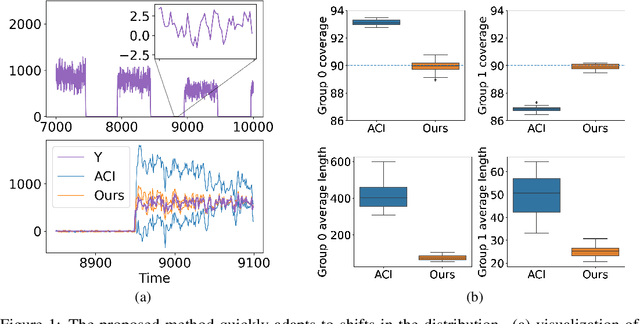

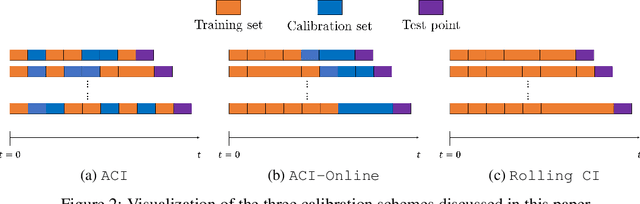
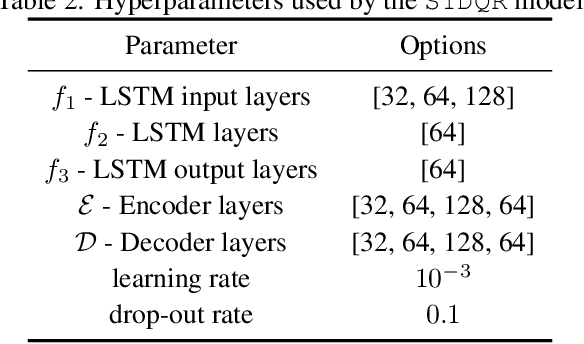
We develop a framework for constructing uncertainty sets with a valid coverage guarantee in an online setting, in which the underlying data distribution can drastically -- and even adversarially -- shift over time. The technique we propose is highly flexible as it can be integrated with any online learning algorithm, requiring minimal implementation effort and computational cost. A key advantage of our method over existing alternatives -- which also build on conformal inference -- is that we do not need to split the data into training and holdout calibration sets. This allows us to fit the predictive model in a fully online manner, utilizing the most recent observation for constructing calibrated uncertainty sets. Consequently, and in contrast with existing techniques, (i) the sets we build can quickly adapt to new changes in the distribution; and (ii) our procedure does not require refitting the model at each time step. Using synthetic and real-world benchmark data sets, we demonstrate the validity of our theory and the improved performance of our proposal over existing techniques. To demonstrate the greater flexibility of the proposed method, we show how to construct valid intervals for a multiple-output regression problem that previous sequential calibration methods cannot handle due to impractical computational and memory requirements.
Automatic Detection of Interplanetary Coronal Mass Ejections in Solar Wind In Situ Data
May 07, 2022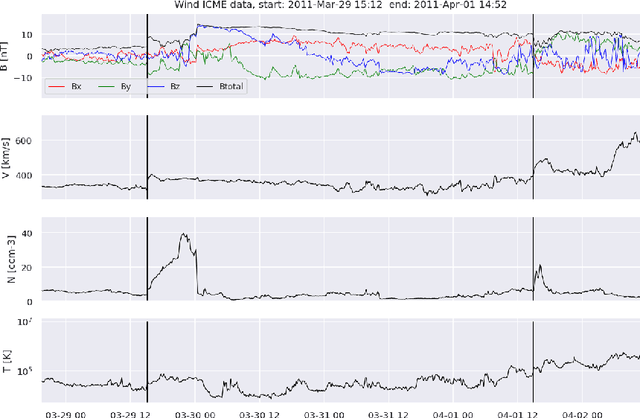
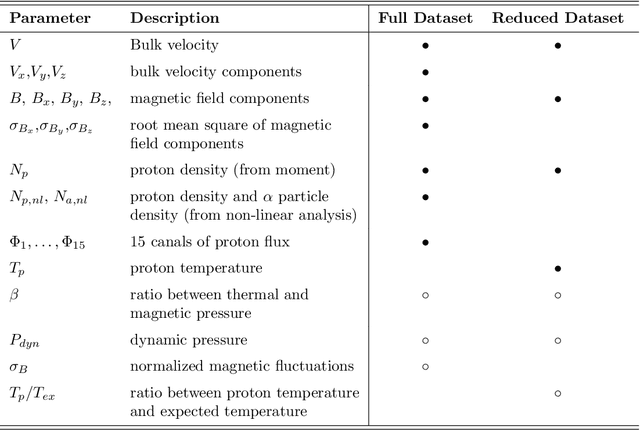
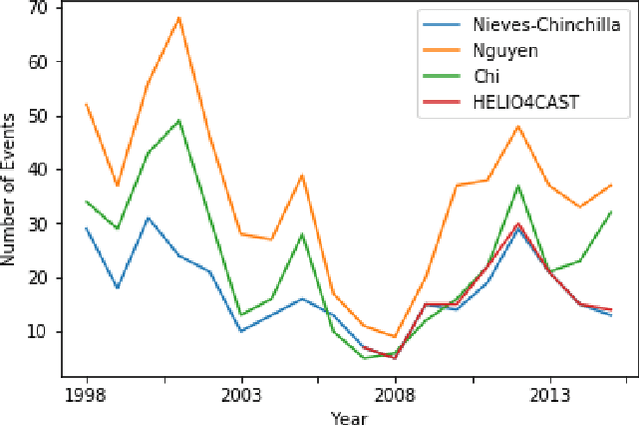
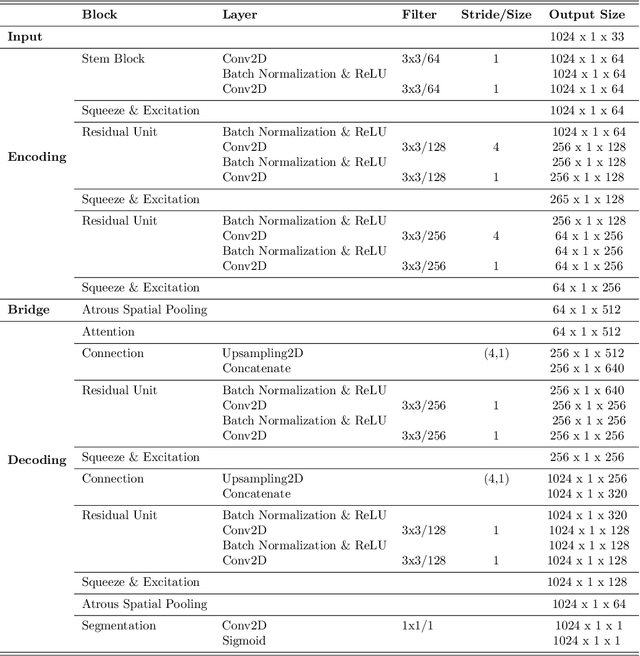
Interplanetary coronal mass ejections (ICMEs) are one of the main drivers for space weather disturbances. In the past, different approaches have been used to automatically detect events in existing time series resulting from solar wind in situ observations. However, accurate and fast detection still remains a challenge when facing the large amount of data from different instruments. For the automatic detection of ICMEs we propose a pipeline using a method that has recently proven successful in medical image segmentation. Comparing it to an existing method, we find that while achieving similar results, our model outperforms the baseline regarding training time by a factor of approximately 20, thus making it more applicable for other datasets. The method has been tested on in situ data from the Wind spacecraft between 1997 and 2015 with a True Skill Statistic (TSS) of 0.64. Out of the 640 ICMEs, 466 were detected correctly by our algorithm, producing a total of 254 False Positives. Additionally, it produced reasonable results on datasets with fewer features and smaller training sets from Wind, STEREO-A and STEREO-B with True Skill Statistics of 0.56, 0.57 and 0.53, respectively. Our pipeline manages to find the start of an ICME with a mean absolute error (MAE) of around 2 hours and 56 minutes, and the end time with a MAE of 3 hours and 20 minutes. The relatively fast training allows straightforward tuning of hyperparameters and could therefore easily be used to detect other structures and phenomena in solar wind data, such as corotating interaction regions.
Making a (Counterfactual) Difference One Rationale at a Time
Jan 13, 2022

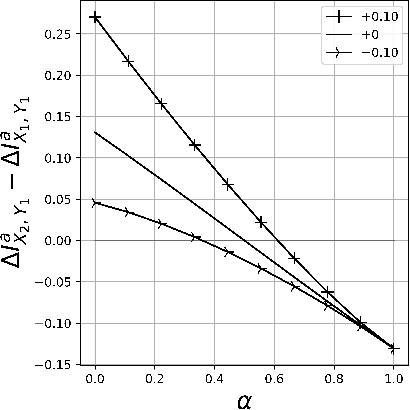
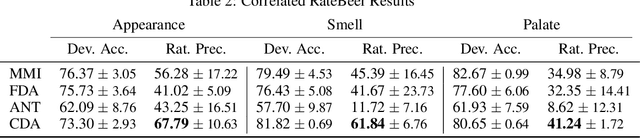
Rationales, snippets of extracted text that explain an inference, have emerged as a popular framework for interpretable natural language processing (NLP). Rationale models typically consist of two cooperating modules: a selector and a classifier with the goal of maximizing the mutual information (MMI) between the "selected" text and the document label. Despite their promises, MMI-based methods often pick up on spurious text patterns and result in models with nonsensical behaviors. In this work, we investigate whether counterfactual data augmentation (CDA), without human assistance, can improve the performance of the selector by lowering the mutual information between spurious signals and the document label. Our counterfactuals are produced in an unsupervised fashion using class-dependent generative models. From an information theoretic lens, we derive properties of the unaugmented dataset for which our CDA approach would succeed. The effectiveness of CDA is empirically evaluated by comparing against several baselines including an improved MMI-based rationale schema on two multi aspect datasets. Our results show that CDA produces rationales that better capture the signal of interest.
Visualising Deep Network's Time-Series Representations
Mar 12, 2021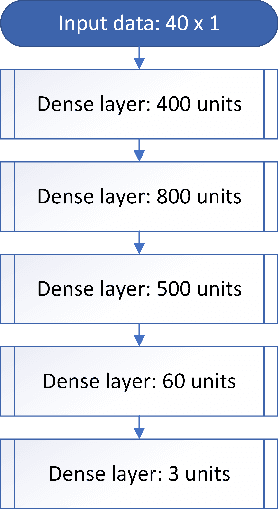
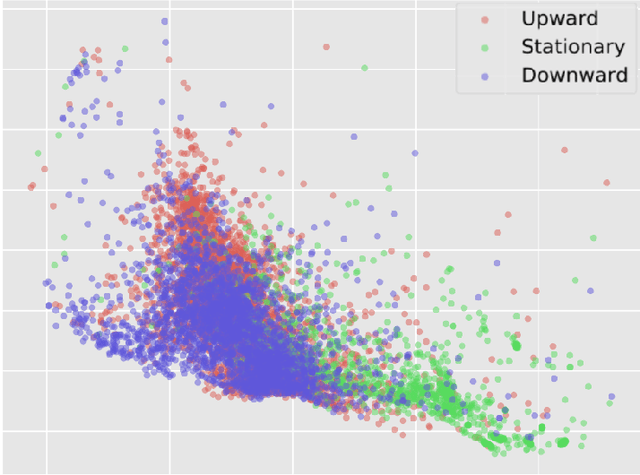
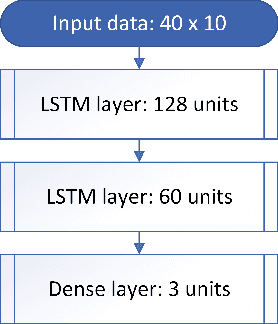
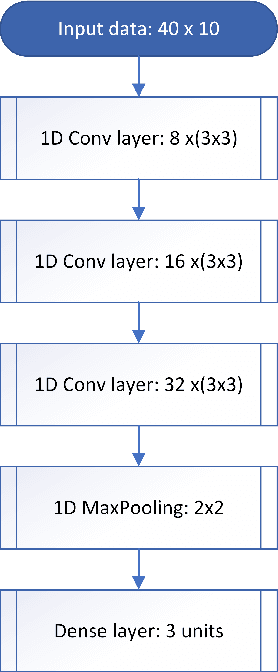
Despite the popularisation of the machine learning models, more often than not they still operate as black boxes with no insight into what is happening inside the model. There exist a few methods that allow to visualise and explain why the model has made a certain prediction. Those methods, however, allow viewing the causal link between the input and output of the model without presenting how the model learns to represent the data. In this paper, a method that addresses that issue is proposed, with a focus on visualising multi-dimensional time-series data. Experiments on a high-frequency stock market dataset show that the method provides fast and discernible visualisations. Large datasets can be visualised quickly and on one plot, which makes it easy for a user to compare the learned representations of the data. The developed method successfully combines known and proven techniques to provide novel insight into the inner workings of time-series classifier models.
Quaternion variational integration for inertial maneuvering in a biomimetic UAV
Jun 25, 2022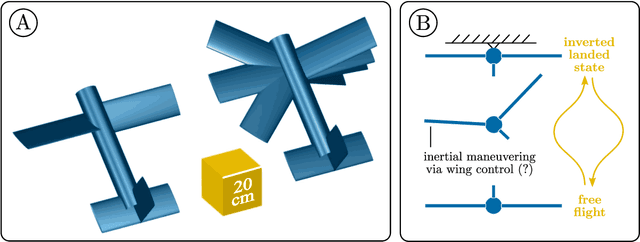
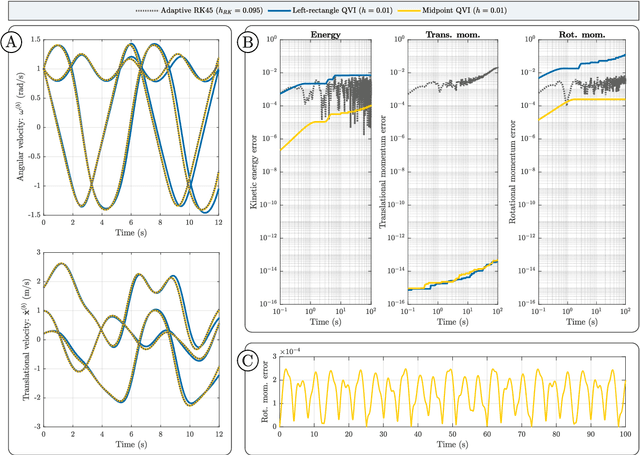
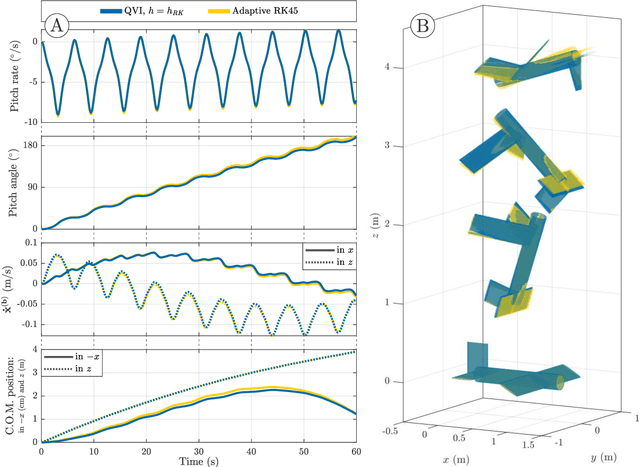
Biological flying, gliding, and falling creatures are capable of extraordinary forms of inertial maneuvering: free-space maneuvering based on fine control of their multibody dynamics, as typified by the self-righting reflexes of cats. However, designing inertial maneuvering capability into biomimetic robots, such as biomimetic unmanned aerial vehicles (UAVs) is challenging. Accurately simulating this maneuvering requires numerical integrators that can ensure both singularity-free integration, and momentum and energy conservation, in a strongly coupled system - properties unavailable in existing conventional integrators. In this work, we develop a pair of novel quaternion variational integrators (QVI) showing these properties, and demonstrate their capability for simulating inertial maneuvering in a biomimetic UAV showing complex multibody-dynamics coupling. Being quaternion-valued, these QVIs are innately singularity-free; and being variational, they can show excellent energy and momentum conservation properties. We explore the effect of variational integration order (left-rectangle vs. midpoint) on the conservation properties of integrator, and conclude that, in complex coupled systems in which canonical momenta may be time-varying, the midpoint integrator is required. The resulting midpoint QVI is well-suited to the analysis of inertial maneuvering in a biomimetic UAV - a feature that we demonstrate in simulation - and of other complex dynamical systems.
Deep Video Prediction for Time Series Forecasting
Feb 24, 2021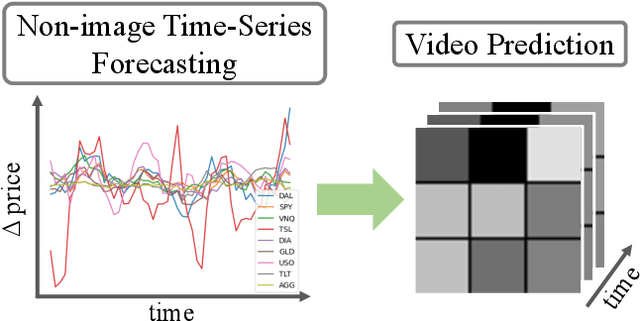


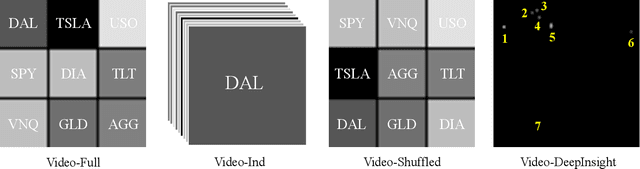
Time series forecasting is essential for decision making in many domains. In this work, we address the challenge of predicting prices evolution among multiple potentially interacting financial assets. A solution to this problem has obvious importance for governments, banks, and investors. Statistical methods such as Auto Regressive Integrated Moving Average (ARIMA) are widely applied to these problems. In this paper, we propose to approach economic time series forecasting of multiple financial assets in a novel way via video prediction. Given past prices of multiple potentially interacting financial assets, we aim to predict the prices evolution in the future. Instead of treating the snapshot of prices at each time point as a vector, we spatially layout these prices in 2D as an image, such that we can harness the power of CNNs in learning a latent representation for these financial assets. Thus, the history of these prices becomes a sequence of images, and our goal becomes predicting future images. We build on a state-of-the-art video prediction method for forecasting future images. Our experiments involve the prediction task of the price evolution of nine financial assets traded in U.S. stock markets. The proposed method outperforms baselines including ARIMA, Prophet, and variations of the proposed method, demonstrating the benefits of harnessing the power of CNNs in the problem of economic time series forecasting.