 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Road Segmentation in Challenging Domains Using Similar Place Priors
May 27, 2022
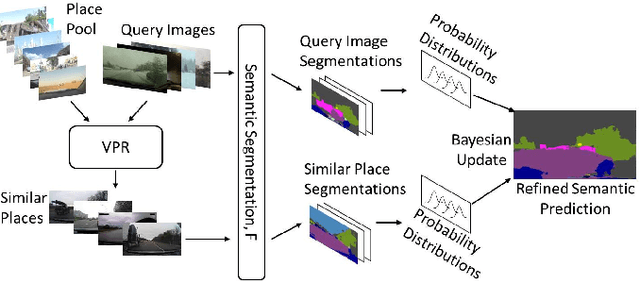
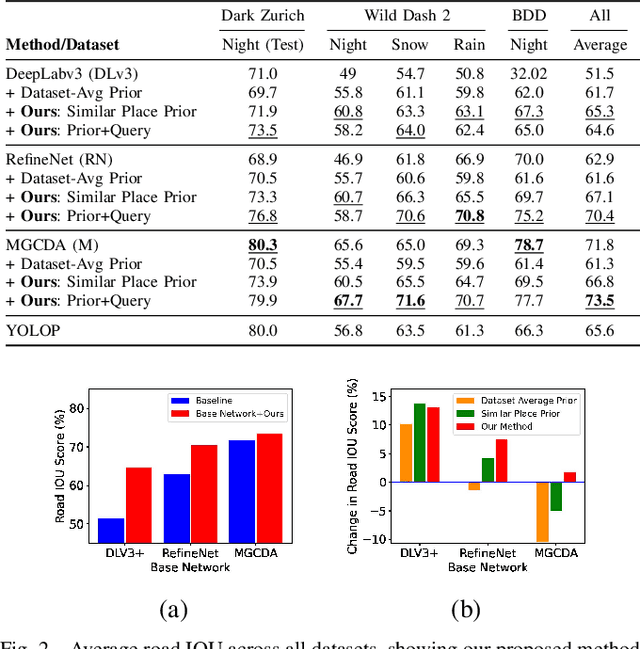
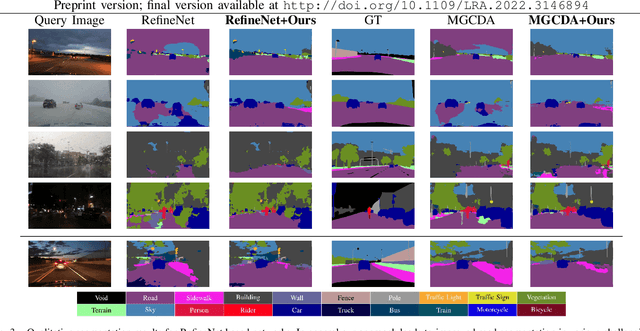
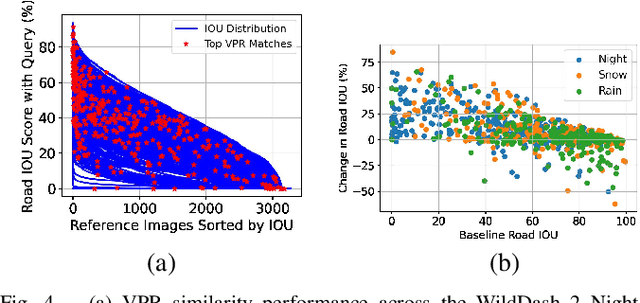
Road segmentation in challenging domains, such as night, snow or rain, is a difficult task. Most current approaches boost performance using fine-tuning, domain adaptation, style transfer, or by referencing previously acquired imagery. These approaches share one or more of three significant limitations: a reliance on large amounts of annotated training data that can be costly to obtain, both anticipation of and training data from the type of environmental conditions expected at inference time, and/or imagery captured from a previous visit to the location. In this research, we remove these restrictions by improving road segmentation based on similar places. We use Visual Place Recognition (VPR) to find similar but geographically distinct places, and fuse segmentations for query images and these similar place priors using a Bayesian approach and novel segmentation quality metric. Ablation studies show the need to re-evaluate notions of VPR utility for this task. We demonstrate the system achieving state-of-the-art road segmentation performance across multiple challenging condition scenarios including night time and snow, without requiring any prior training or previous access to the same geographical locations. Furthermore, we show that this method is network agnostic, improves multiple baseline techniques and is competitive against methods specialised for road prediction.
* Accepted into IEEE Robotics and Automation Letters (RA-L) and presented at IEEE International Conference on Robotics and Automation (ICRA 2022)
UMSNet: An Universal Multi-sensor Network for Human Activity Recognition
May 24, 2022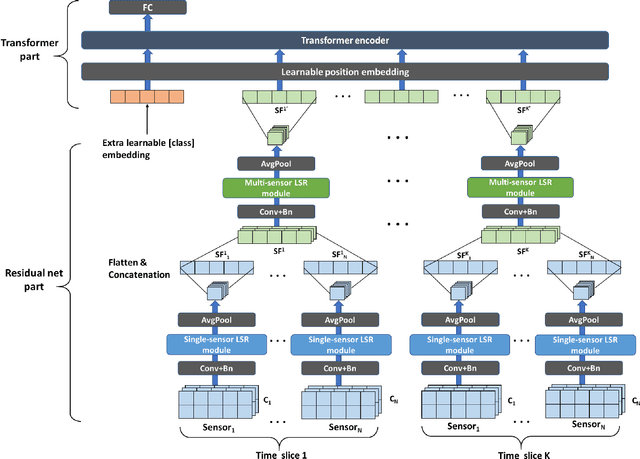

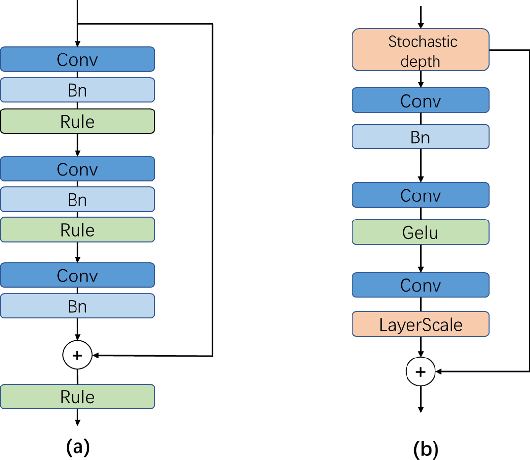
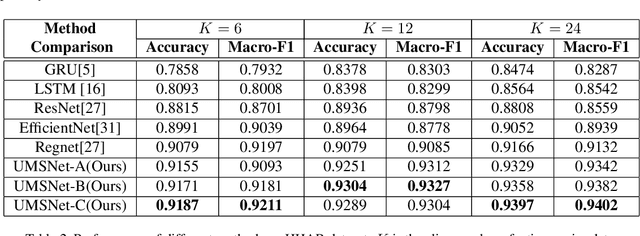
Human activity recognition (HAR) based on multimodal sensors has become a rapidly growing branch of biometric recognition and artificial intelligence. However, how to fully mine multimodal time series data and effectively learn accurate behavioral features has always been a hot topic in this field. Practical applications also require a well-generalized framework that can quickly process a variety of raw sensor data and learn better feature representations. This paper proposes a universal multi-sensor network (UMSNet) for human activity recognition. In particular, we propose a new lightweight sensor residual block (called LSR block), which improves the performance by reducing the number of activation function and normalization layers, and adding inverted bottleneck structure and grouping convolution. Then, the Transformer is used to extract the relationship of series features to realize the classification and recognition of human activities. Our framework has a clear structure and can be directly applied to various types of multi-modal Time Series Classification (TSC) tasks after simple specialization. Extensive experiments show that the proposed UMSNet outperforms other state-of-the-art methods on two popular multi-sensor human activity recognition datasets (i.e. HHAR dataset and MHEALTH dataset).
Efficient Algorithms for Planning with Participation Constraints
May 16, 2022
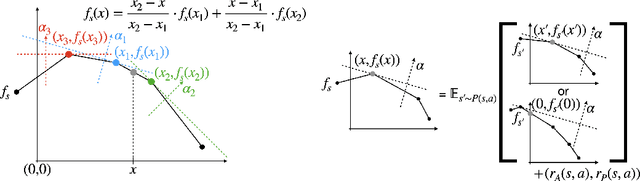
We consider the problem of planning with participation constraints introduced in [Zhang et al., 2022]. In this problem, a principal chooses actions in a Markov decision process, resulting in separate utilities for the principal and the agent. However, the agent can and will choose to end the process whenever his expected onward utility becomes negative. The principal seeks to compute and commit to a policy that maximizes her expected utility, under the constraint that the agent should always want to continue participating. We provide the first polynomial-time exact algorithm for this problem for finite-horizon settings, where previously only an additive $\varepsilon$-approximation algorithm was known. Our approach can also be extended to the (discounted) infinite-horizon case, for which we give an algorithm that runs in time polynomial in the size of the input and $\log(1/\varepsilon)$, and returns a policy that is optimal up to an additive error of $\varepsilon$.
Chairs Can be Stood on: Overcoming Object Bias in Human-Object Interaction Detection
Jul 06, 2022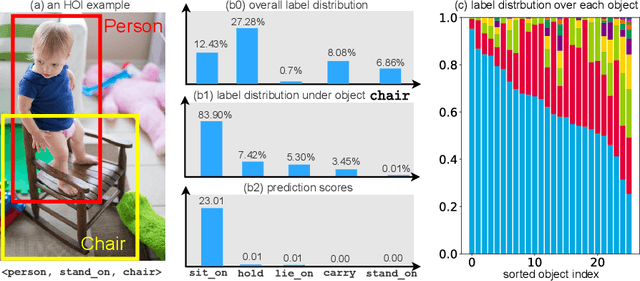
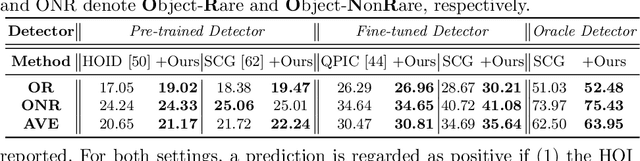
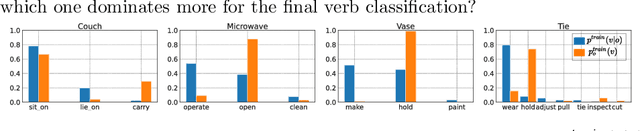
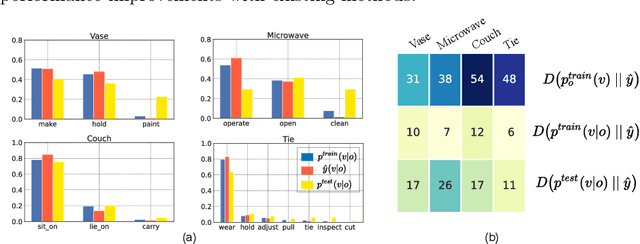
Detecting Human-Object Interaction (HOI) in images is an important step towards high-level visual comprehension. Existing work often shed light on improving either human and object detection, or interaction recognition. However, due to the limitation of datasets, these methods tend to fit well on frequent interactions conditioned on the detected objects, yet largely ignoring the rare ones, which is referred to as the object bias problem in this paper. In this work, we for the first time, uncover the problem from two aspects: unbalanced interaction distribution and biased model learning. To overcome the object bias problem, we propose a novel plug-and-play Object-wise Debiasing Memory (ODM) method for re-balancing the distribution of interactions under detected objects. Equipped with carefully designed read and write strategies, the proposed ODM allows rare interaction instances to be more frequently sampled for training, thereby alleviating the object bias induced by the unbalanced interaction distribution. We apply this method to three advanced baselines and conduct experiments on the HICO-DET and HOI-COCO datasets. To quantitatively study the object bias problem, we advocate a new protocol for evaluating model performance. As demonstrated in the experimental results, our method brings consistent and significant improvements over baselines, especially on rare interactions under each object. In addition, when evaluating under the conventional standard setting, our method achieves new state-of-the-art on the two benchmarks.
Fast Causal Orientation Learning in Directed Acyclic Graphs
May 27, 2022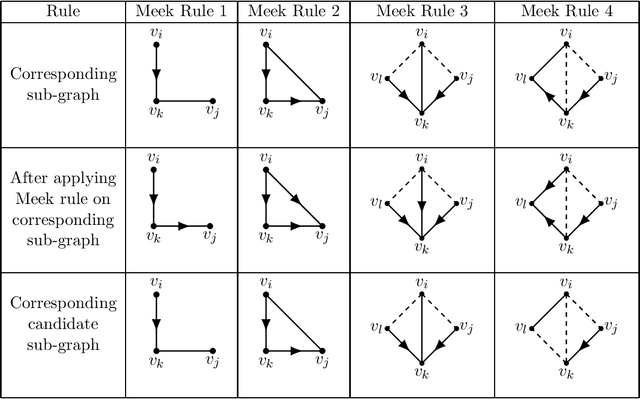

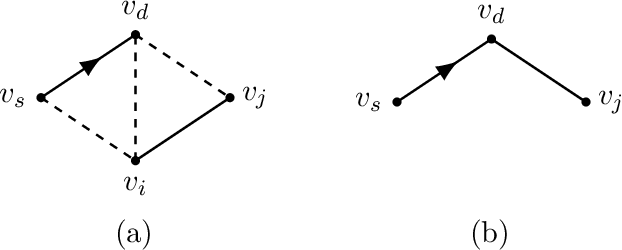
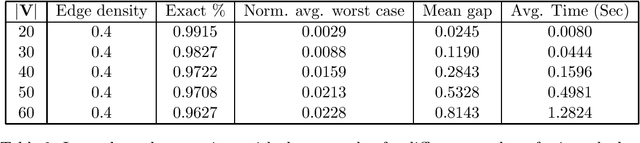
Causal relationships among a set of variables are commonly represented by a directed acyclic graph. The orientations of some edges in the causal DAG can be discovered from observational/interventional data. Further edges can be oriented by iteratively applying so-called Meek rules. Inferring edges' orientations from some previously oriented edges, which we call Causal Orientation Learning (COL), is a common problem in various causal discovery tasks. In these tasks, it is often required to solve multiple COL problems and therefore applying Meek rules could be time-consuming. Motivated by Meek rules, we introduce Meek functions that can be utilized in solving COL problems. In particular, we show that these functions have some desirable properties, enabling us to speed up the process of applying Meek rules. In particular, we propose a dynamic programming (DP) based method to apply Meek functions. Moreover, based on the proposed DP method, we present a lower bound on the number of edges that can be oriented as a result of intervention. We also propose a method to check whether some oriented edges belong to a causal DAG. Experimental results show that the proposed methods can outperform previous work in several causal discovery tasks in terms of running-time.
StarEnhancer: Learning Real-Time and Style-Aware Image Enhancement
Aug 02, 2021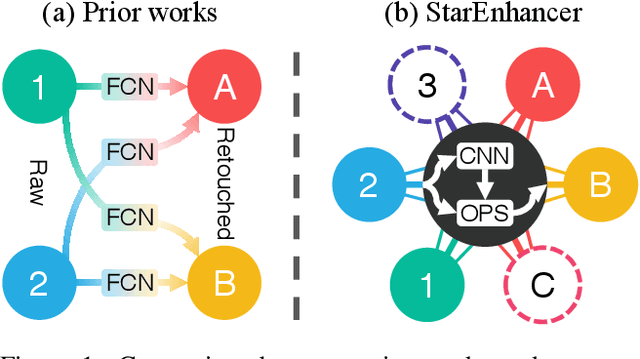
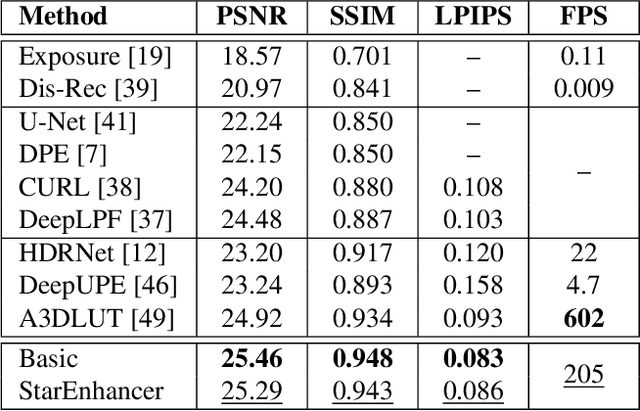
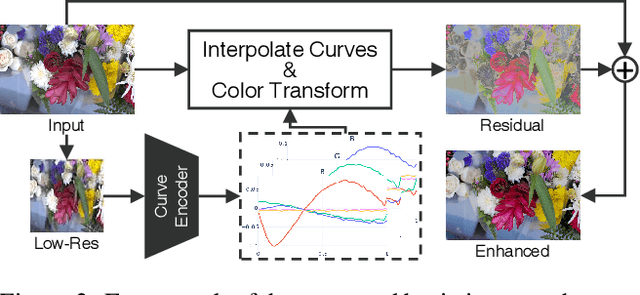
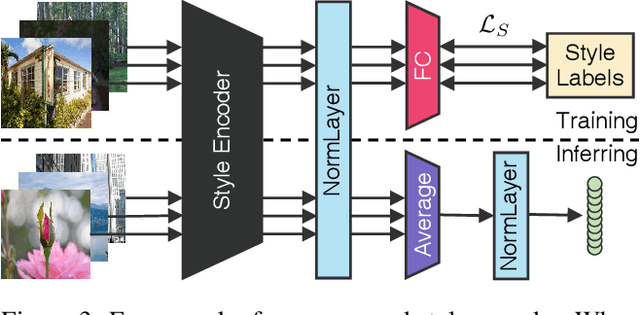
Image enhancement is a subjective process whose targets vary with user preferences. In this paper, we propose a deep learning-based image enhancement method covering multiple tonal styles using only a single model dubbed StarEnhancer. It can transform an image from one tonal style to another, even if that style is unseen. With a simple one-time setting, users can customize the model to make the enhanced images more in line with their aesthetics. To make the method more practical, we propose a well-designed enhancer that can process a 4K-resolution image over 200 FPS but surpasses the contemporaneous single style image enhancement methods in terms of PSNR, SSIM, and LPIPS. Finally, our proposed enhancement method has good interactability, which allows the user to fine-tune the enhanced image using intuitive options.
Continuous-Time Spatiotemporal Calibration of a Rolling Shutter Camera---IMU System
Aug 16, 2021
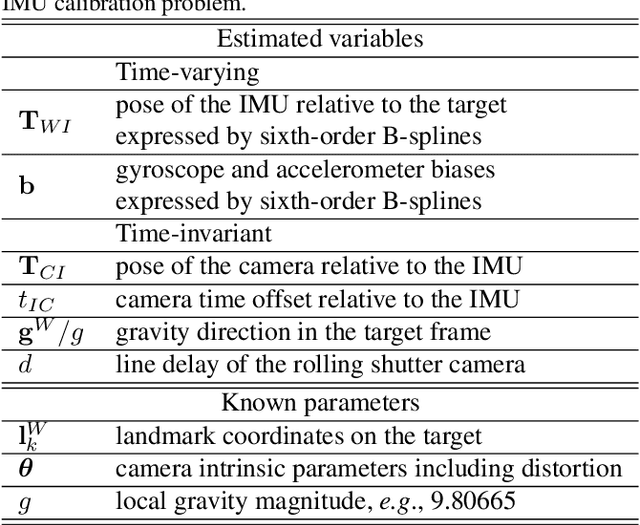
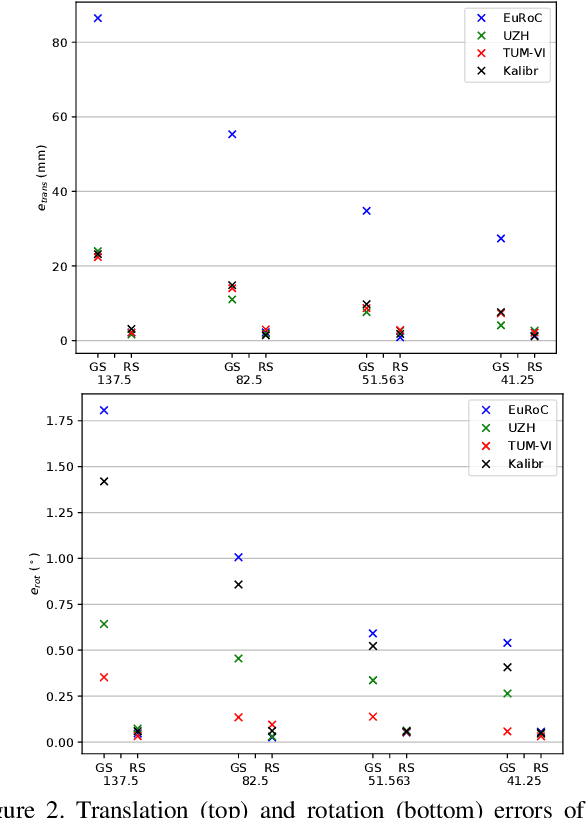
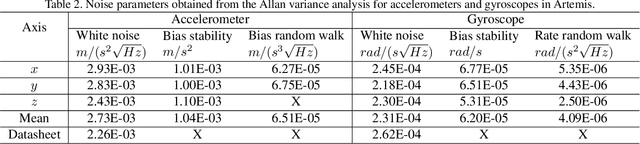
The rolling shutter (RS) mechanism is widely used by consumer-grade cameras, which are essential parts in smartphones and autonomous vehicles. The RS effect leads to image distortion upon relative motion between a camera and the scene. This effect needs to be considered in video stabilization, structure from motion, and vision-aided odometry, for which recent studies have improved earlier global shutter (GS) methods by accounting for the RS effect. However, it is still unclear how the RS affects spatiotemporal calibration of the camera in a sensor assembly, which is crucial to good performance in aforementioned applications. This work takes the camera-IMU system as an example and looks into the RS effect on its spatiotemporal calibration. To this end, we develop a calibration method for a RS-camera-IMU system with continuous-time B-splines by using a calibration target. Unlike in calibrating GS cameras, every observation of a landmark on the target has a unique camera pose fitted by continuous-time B-splines. With simulated data generated from four sets of public calibration data, we show that RS can noticeably affect the extrinsic parameters, causing errors about 1$^\circ$ in orientation and 2 $cm$ in translation with a RS setting as in common smartphone cameras. With real data collected by two industrial camera-IMU systems, we find that considering the RS effect gives more accurate and consistent spatiotemporal calibration. Moreover, our method also accurately calibrates the inter-line delay of the RS. The code for simulation and calibration is publicly available.
Mixed-Timescale Deep-Unfolding for Joint Channel Estimation and Hybrid Beamforming
Jun 08, 2022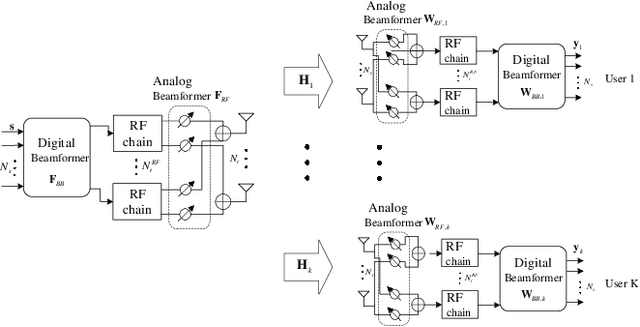
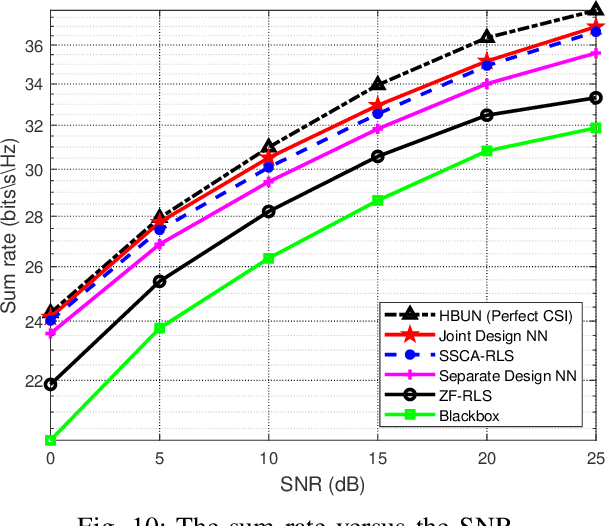
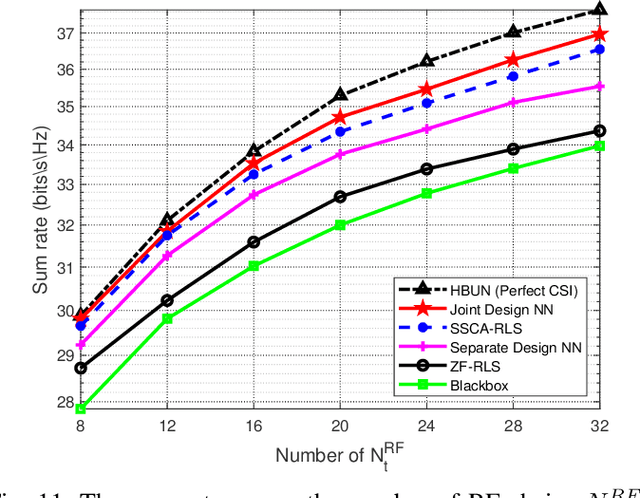
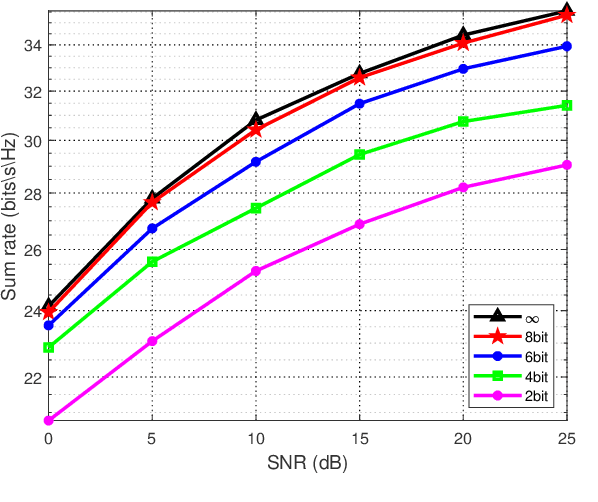
In massive multiple-input multiple-output (MIMO) systems, hybrid analog-digital beamforming is an essential technique for exploiting the potential array gain without using a dedicated radio frequency chain for each antenna. However, due to the large number of antennas, the conventional channel estimation and hybrid beamforming algorithms generally require high computational complexity and signaling overhead. In this work, we propose an end-to-end deep-unfolding neural network (NN) joint channel estimation and hybrid beamforming (JCEHB) algorithm to maximize the system sum rate in time-division duplex (TDD) massive MIMO. Specifically, the recursive least-squares (RLS) algorithm and stochastic successive convex approximation (SSCA) algorithm are unfolded for channel estimation and hybrid beamforming, respectively. In order to reduce the signaling overhead, we consider a mixed-timescale hybrid beamforming scheme, where the analog beamforming matrices are optimized based on the channel state information (CSI) statistics offline, while the digital beamforming matrices are designed at each time slot based on the estimated low-dimensional equivalent CSI matrices. We jointly train the analog beamformers together with the trainable parameters of the RLS and SSCA induced deep-unfolding NNs based on the CSI statistics offline. During data transmission, we estimate the low-dimensional equivalent CSI by the RLS induced deep-unfolding NN and update the digital beamformers. In addition, we propose a mixed-timescale deep-unfolding NN where the analog beamformers are optimized online, and extend the framework to frequency-division duplex (FDD) systems where channel feedback is considered. Simulation results show that the proposed algorithm can significantly outperform conventional algorithms with reduced computational complexity and signaling overhead.
Efficient textual explanations for complex road and traffic scenarios based on semantic segmentation
Jun 02, 2022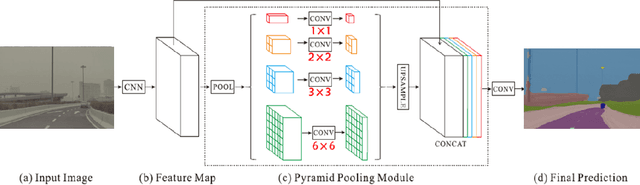

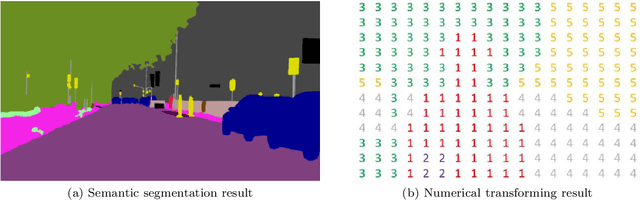
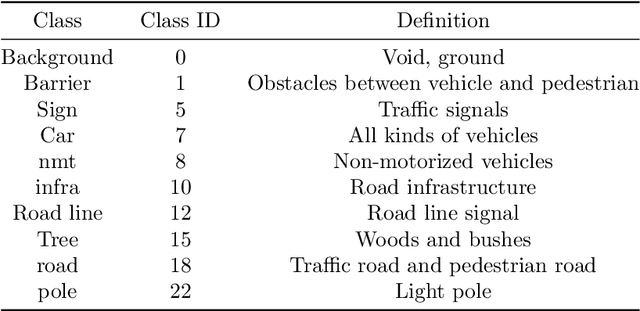
The complex driving environment brings great challenges to the visual perception of autonomous vehicles. It's essential to extract clear and explainable information from the complex road and traffic scenarios and offer clues to decision and control. However, the previous scene explanation had been implemented as a separate model. The black box model makes it difficult to interpret the driving environment. It cannot detect comprehensive textual information and requires a high computational load and time consumption. Thus, this study proposed a comprehensive and efficient textual explanation model. From 336k video frames of the driving environment, critical images of complex road and traffic scenarios were selected into a dataset. Through transfer learning, this study established an accurate and efficient segmentation model to obtain the critical traffic elements in the environment. Based on the XGBoost algorithm, a comprehensive model was developed. The model provided textual information about states of traffic elements, the motion of conflict objects, and scenario complexity. The approach was verified on the real-world road. It improved the perception accuracy of critical traffic elements to 78.8%. The time consumption reached 13 minutes for each epoch, which was 11.5 times more efficient than the pre-trained network. The textual information analyzed from the model was also accordant with reality. The findings offer clear and explainable information about the complex driving environment, which lays a foundation for subsequent decision and control. It can improve the visual perception ability and enrich the prior knowledge and judgments of complex traffic situations.
Bounding the Width of Neural Networks via Coupled Initialization -- A Worst Case Analysis
Jun 26, 2022
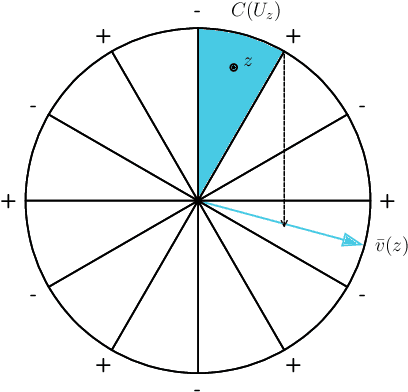
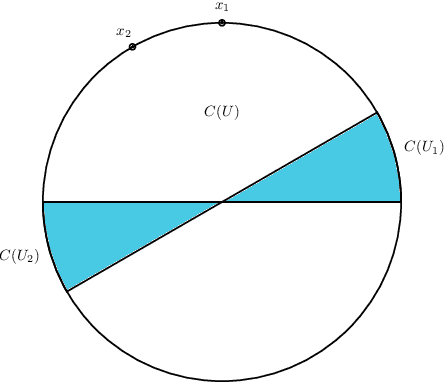
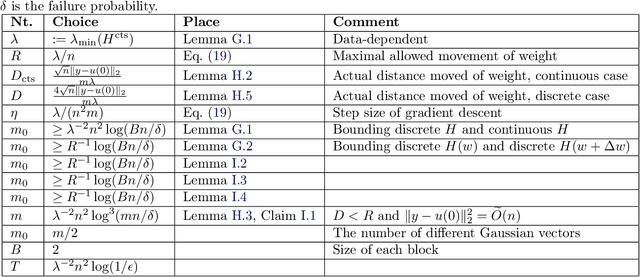
A common method in training neural networks is to initialize all the weights to be independent Gaussian vectors. We observe that by instead initializing the weights into independent pairs, where each pair consists of two identical Gaussian vectors, we can significantly improve the convergence analysis. While a similar technique has been studied for random inputs [Daniely, NeurIPS 2020], it has not been analyzed with arbitrary inputs. Using this technique, we show how to significantly reduce the number of neurons required for two-layer ReLU networks, both in the under-parameterized setting with logistic loss, from roughly $\gamma^{-8}$ [Ji and Telgarsky, ICLR 2020] to $\gamma^{-2}$, where $\gamma$ denotes the separation margin with a Neural Tangent Kernel, as well as in the over-parameterized setting with squared loss, from roughly $n^4$ [Song and Yang, 2019] to $n^2$, implicitly also improving the recent running time bound of [Brand, Peng, Song and Weinstein, ITCS 2021]. For the under-parameterized setting we also prove new lower bounds that improve upon prior work, and that under certain assumptions, are best possible.