 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pattern Sampling for Shapelet-based Time Series Classification
Feb 16, 2021
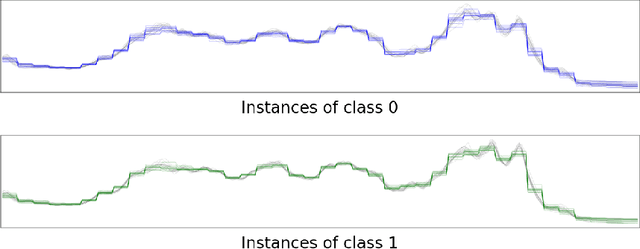
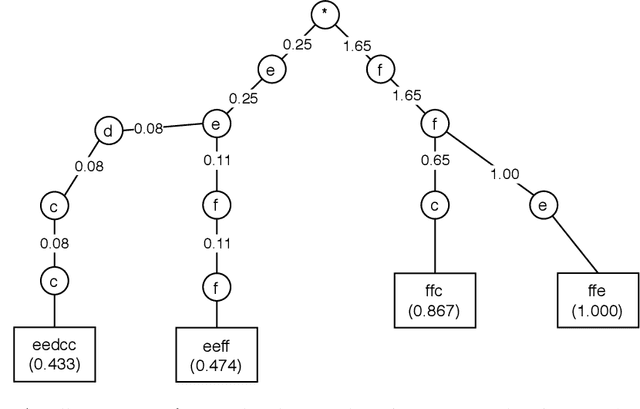
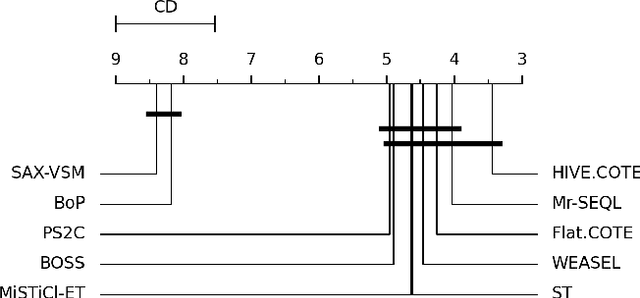
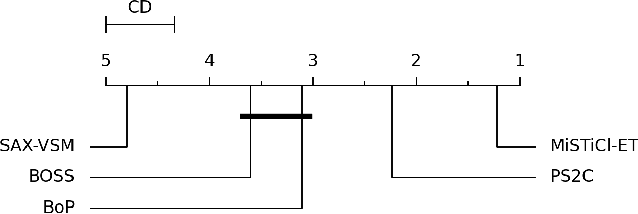
Subsequence-based time series classification algorithms provide accurate and interpretable models, but training these models is extremely computation intensive. The asymptotic time complexity of subsequence-based algorithms remains a higher-order polynomial, because these algorithms are based on exhaustive search for highly discriminative subsequences. Pattern sampling has been proposed as an effective alternative to mitigate the pattern explosion phenomenon. Therefore, we employ pattern sampling to extract discriminative features from discretized time series data. A weighted trie is created based on the discretized time series data to sample highly discriminative patterns. These sampled patterns are used to identify the shapelets which are used to transform the time series classification problem into a feature-based classification problem. Finally, a classification model can be trained using any off-the-shelf algorithm. Creating a pattern sampler requires a small number of patterns to be evaluated compared to an exhaustive search as employed by previous approaches. Compared to previously proposed algorithms, our approach requires considerably less computational and memory resources. Experiments demonstrate how the proposed approach fares in terms of classification accuracy and runtime performance.
On the complexity of finding set repairs for data-graphs
Jun 15, 2022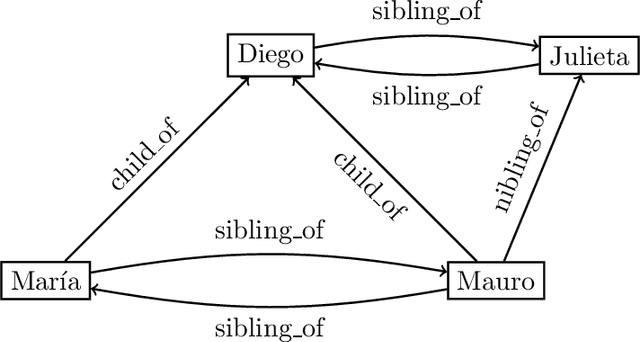
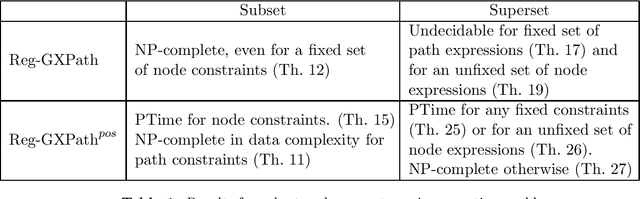
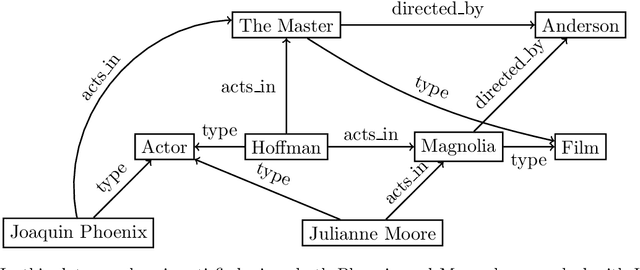
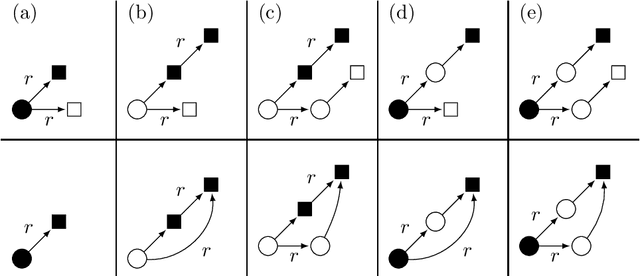
In the deeply interconnected world we live in, pieces of information link domains all around us. As graph databases embrace effectively relationships among data and allow processing and querying these connections efficiently, they are rapidly becoming a popular platform for storage that supports a wide range of domains and applications. As in the relational case, it is expected that data preserves a set of integrity constraints that define the semantic structure of the world it represents. When a database does not satisfy its integrity constraints, a possible approach is to search for a 'similar' database that does satisfy the constraints, also known as a repair. In this work, we study the problem of computing subset and superset repairs for graph databases with data values using a notion of consistency based on a set of Reg-GXPath expressions as integrity constraints. We show that for positive fragments of Reg-GXPath these problems admit a polynomial-time algorithm, while the full expressive power of the language renders them intractable.
Continual Learning for Affective Robotics: A Proof of Concept for Wellbeing
Jun 22, 2022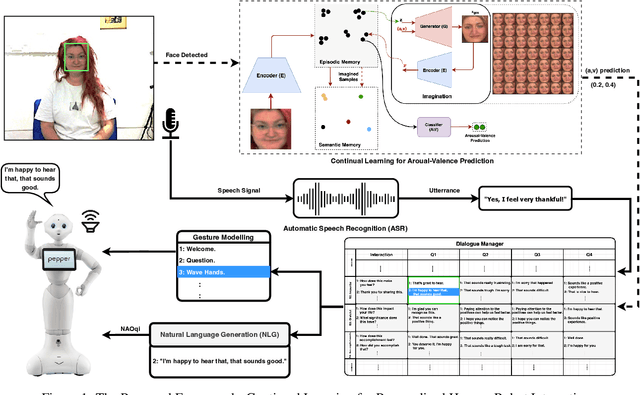
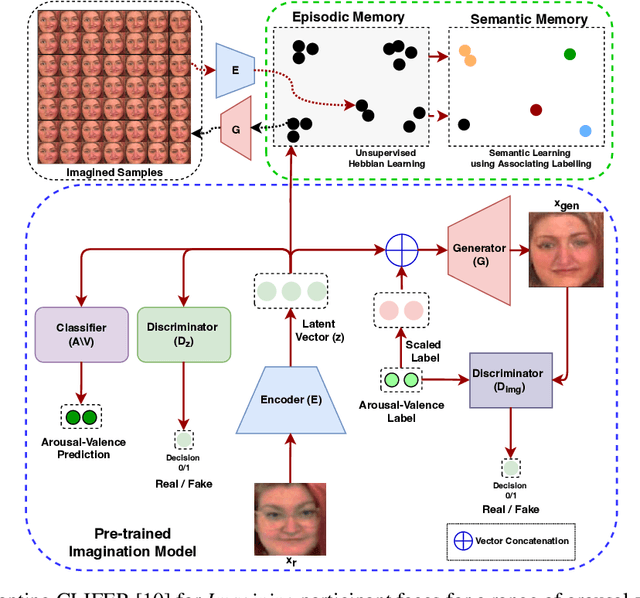
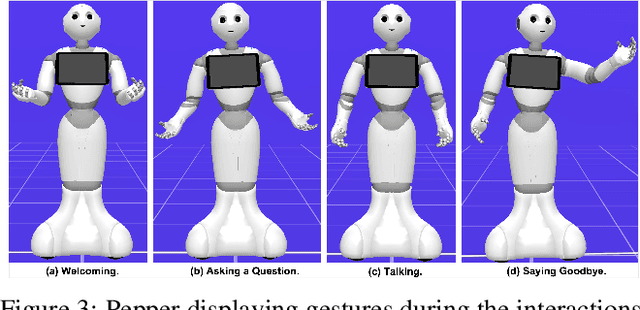

Sustaining real-world human-robot interactions requires robots to be sensitive to human behavioural idiosyncrasies and adapt their perception and behaviour models to cater to these individual preferences. For affective robots, this entails learning to adapt to individual affective behaviour to offer a personalised interaction experience to each individual. Continual Learning (CL) has been shown to enable real-time adaptation in agents, allowing them to learn with incrementally acquired data while preserving past knowledge. In this work, we present a novel framework for real-world application of CL for modelling personalised human-robot interactions using a CL-based affect perception mechanism. To evaluate the proposed framework, we undertake a proof-of-concept user study with 20 participants interacting with the Pepper robot using three variants of interaction behaviour: static and scripted, using affect-based adaptation without personalisation, and using affect-based adaptation with continual personalisation. Our results demonstrate a clear preference in the participants for CL-based continual personalisation with significant improvements observed in the robot's anthropomorphism, animacy and likeability ratings as well as the interactions being rated significantly higher for warmth and comfort as the robot is rated as significantly better at understanding how the participants feel.
Forecast combinations: an over 50-year review
May 09, 2022
Forecast combinations have flourished remarkably in the forecasting community and, in recent years, have become part of the mainstream of forecasting research and activities. Combining multiple forecasts produced from the single (target) series is now widely used to improve accuracy through the integration of information gleaned from different sources, thereby mitigating the risk of identifying a single "best" forecast. Combination schemes have evolved from simple combination methods without estimation, to sophisticated methods involving time-varying weights, nonlinear combinations, correlations among components, and cross-learning. They include combining point forecasts, and combining probabilistic forecasts. This paper provides an up-to-date review of the extensive literature on forecast combinations, together with reference to available open-source software implementations. We discuss the potential and limitations of various methods and highlight how these ideas have developed over time. Some important issues concerning the utility of forecast combinations are also surveyed. Finally, we conclude with current research gaps and potential insights for future research.
iMAP: Implicit Mapping and Positioning in Real-Time
Mar 23, 2021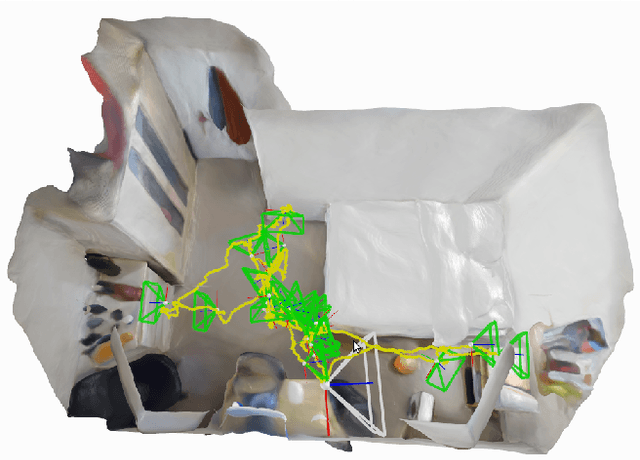
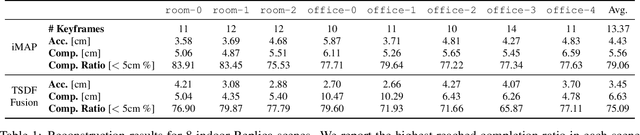
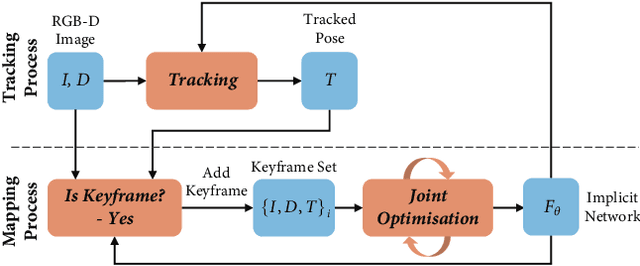

We show for the first time that a multilayer perceptron (MLP) can serve as the only scene representation in a real-time SLAM system for a handheld RGB-D camera. Our network is trained in live operation without prior data, building a dense, scene-specific implicit 3D model of occupancy and colour which is also immediately used for tracking. Achieving real-time SLAM via continual training of a neural network against a live image stream requires significant innovation. Our iMAP algorithm uses a keyframe structure and multi-processing computation flow, with dynamic information-guided pixel sampling for speed, with tracking at 10 Hz and global map updating at 2 Hz. The advantages of an implicit MLP over standard dense SLAM techniques include efficient geometry representation with automatic detail control and smooth, plausible filling-in of unobserved regions such as the back surfaces of objects.
LT-OCF: Learnable-Time ODE-based Collaborative Filtering
Aug 18, 2021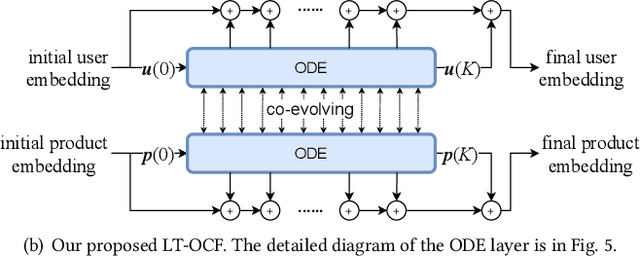
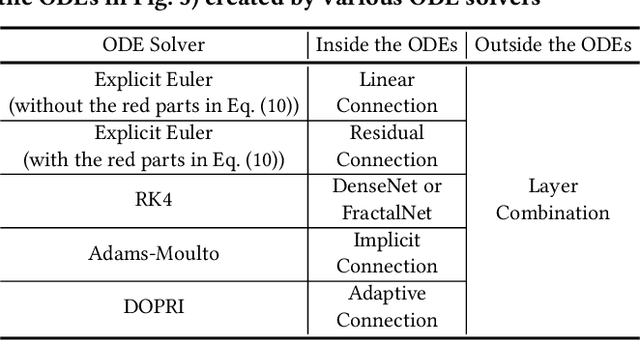
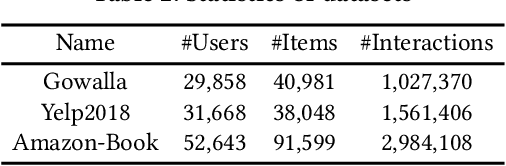
Collaborative filtering (CF) is a long-standing problem of recommender systems. Many novel methods have been proposed, ranging from classical matrix factorization to recent graph convolutional network-based approaches. After recent fierce debates, researchers started to focus on linear graph convolutional networks (GCNs) with a layer combination, which show state-of-the-art accuracy in many datasets. In this work, we extend them based on neural ordinary differential equations (NODEs), because the linear GCN concept can be interpreted as a differential equation, and present the method of Learnable-Time ODE-based Collaborative Filtering (LT-OCF). The main novelty in our method is that after redesigning linear GCNs on top of the NODE regime, i) we learn the optimal architecture rather than relying on manually designed ones, ii) we learn smooth ODE solutions that are considered suitable for CF, and iii) we test with various ODE solvers that internally build a diverse set of neural network connections. We also present a novel training method specialized to our method. In our experiments with three benchmark datasets, Gowalla, Yelp2018, and Amazon-Book, our method consistently shows better accuracy than existing methods, e.g., a recall of 0.0411 by LightGCN vs. 0.0442 by LT-OCF and an NDCG of 0.0315 by LightGCN vs. 0.0341 by LT-OCF in Amazon-Book. One more important discovery in our experiments that is worth mentioning is that our best accuracy was achieved by dense connections rather than linear connections.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022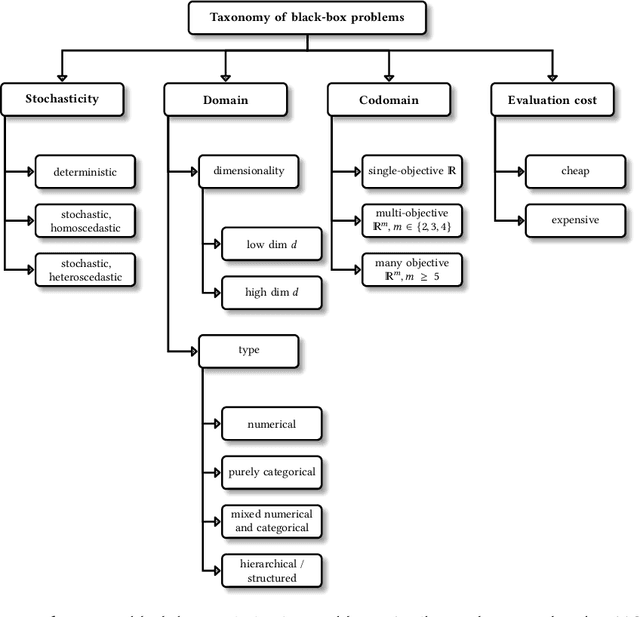
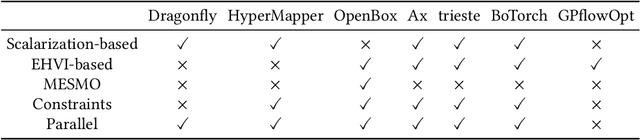
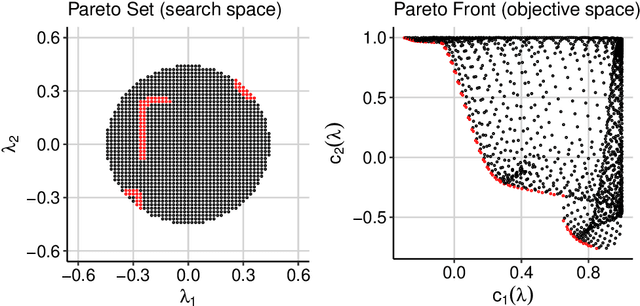
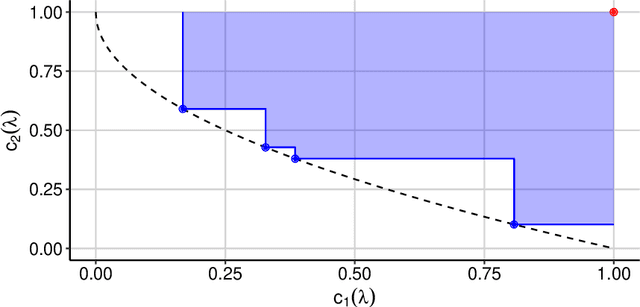
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
On stochastic stabilization via non-smooth control Lyapunov functions
May 26, 2022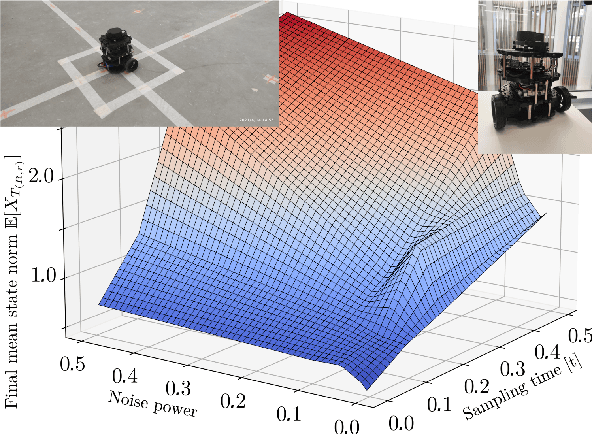
Control Lyapunov function is a central tool in stabilization. It generalizes an abstract energy function -- a Lyapunov function -- to the case of controlled systems. It is a known fact that most control Lyapunov functions are non-smooth -- so is the case in non-holonomic systems, like wheeled robots and cars. Frameworks for stabilization using non-smooth control Lyapunov functions exist, like Dini aiming and steepest descent. This work generalizes the related results to the stochastic case. As the groundwork, sampled control scheme is chosen in which control actions are computed at discrete moments in time using discrete measurements of the system state. In such a setup, special attention should be paid to the sample-to-sample behavior of the control Lyapunov function. A particular challenge here is a random noise acting on the system. The central result of this work is a theorem that states, roughly, that if there is a, generally non-smooth, control Lyapunov function, the given stochastic dynamical system can be practically stabilized in the sample-and-hold mode meaning that the control actions are held constant within sampling time steps. A particular control method chosen is based on Moreau-Yosida regularization, in other words, inf-convolution of the control Lyapunov function, but the overall framework is extendable to further control schemes. It is assumed that the system noise be bounded almost surely, although the case of unbounded noise is briefly addressed.
Deployment of an IoT System for Adaptive In-Situ Soundscape Augmentation
Apr 29, 2022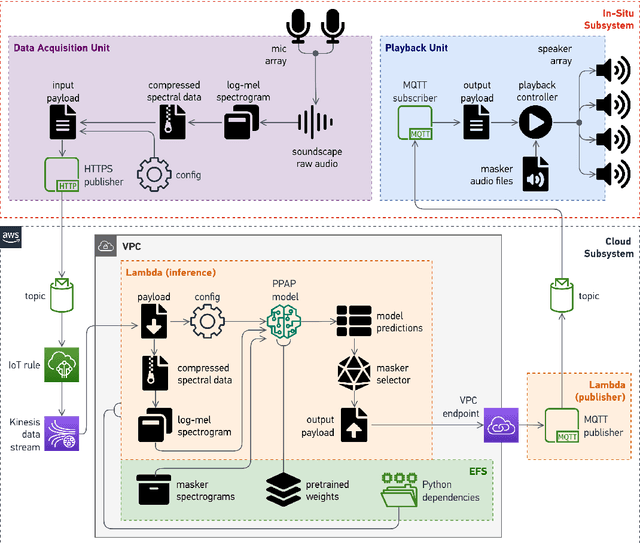
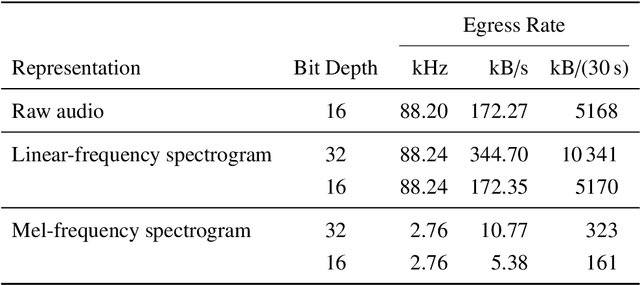
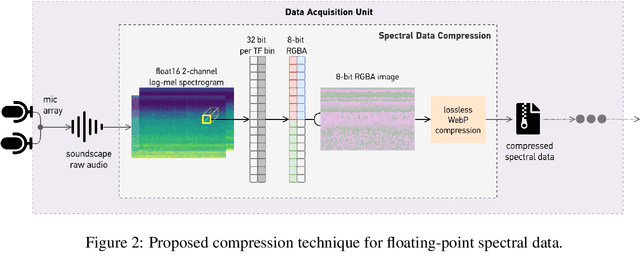
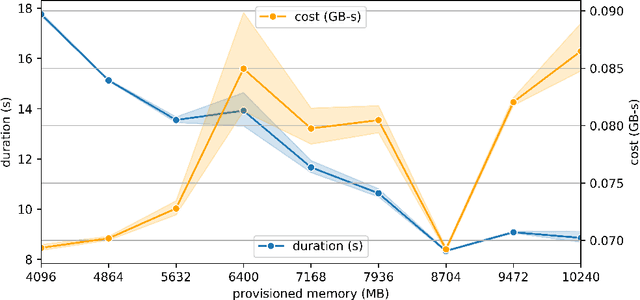
Soundscape augmentation is an emerging approach for noise mitigation by introducing additional sounds known as "maskers" to increase acoustic comfort. Traditionally, the choice of maskers is often predicated on expert guidance or post-hoc analysis which can be time-consuming and sometimes arbitrary. Moreover, this often results in a static set of maskers that are inflexible to the dynamic nature of real-world acoustic environments. Overcoming the inflexibility of traditional soundscape augmentation is twofold. First, given a snapshot of a soundscape, the system must be able to select an optimal masker without human supervision. Second, the system must also be able to react to changes in the acoustic environment with near real-time latency. In this work, we harness the combined prowess of cloud computing and the Internet of Things (IoT) to allow in-situ listening and playback using microcontrollers while delegating computationally expensive inference tasks to the cloud. In particular, a serverless cloud architecture was used for inference, ensuring near real-time latency and scalability without the need to provision computing resources. A working prototype of the system is currently being deployed in a public area experiencing high traffic noise, as well as undergoing public evaluation for future improvements.
Real-time Spatio-temporal Event Detection on Geotagged Social Media
Jun 23, 2021
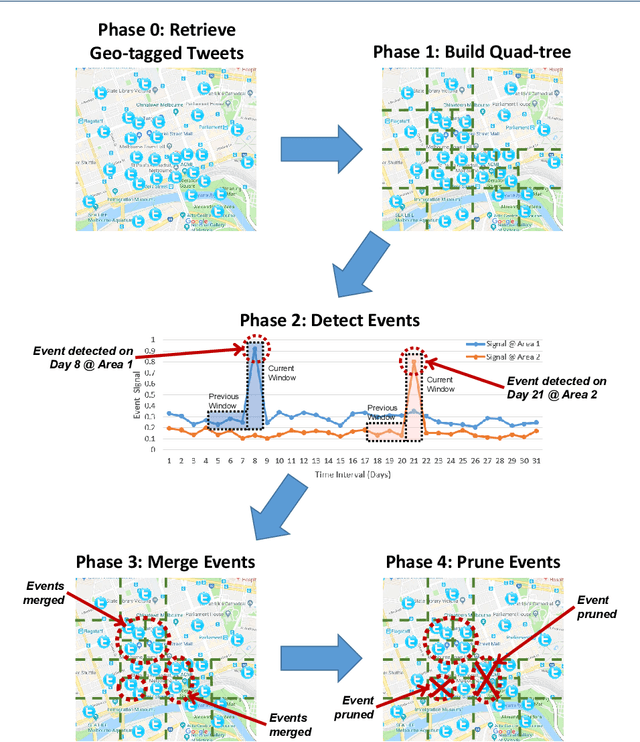


A key challenge in mining social media data streams is to identify events which are actively discussed by a group of people in a specific local or global area. Such events are useful for early warning for accident, protest, election or breaking news. However, neither the list of events nor the resolution of both event time and space is fixed or known beforehand. In this work, we propose an online spatio-temporal event detection system using social media that is able to detect events at different time and space resolutions. First, to address the challenge related to the unknown spatial resolution of events, a quad-tree method is exploited in order to split the geographical space into multiscale regions based on the density of social media data. Then, a statistical unsupervised approach is performed that involves Poisson distribution and a smoothing method for highlighting regions with unexpected density of social posts. Further, event duration is precisely estimated by merging events happening in the same region at consecutive time intervals. A post processing stage is introduced to filter out events that are spam, fake or wrong. Finally, we incorporate simple semantics by using social media entities to assess the integrity, and accuracy of detected events. The proposed method is evaluated using different social media datasets: Twitter and Flickr for different cities: Melbourne, London, Paris and New York. To verify the effectiveness of the proposed method, we compare our results with two baseline algorithms based on fixed split of geographical space and clustering method. For performance evaluation, we manually compute recall and precision. We also propose a new quality measure named strength index, which automatically measures how accurate the reported event is.