 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Solving the capacitated vehicle routing problem with timing windows using rollouts and MAX-SAT
Jun 14, 2022
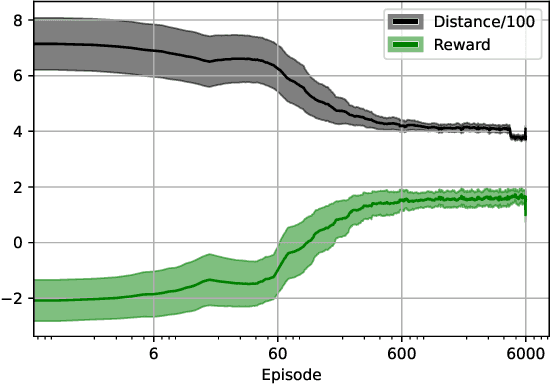
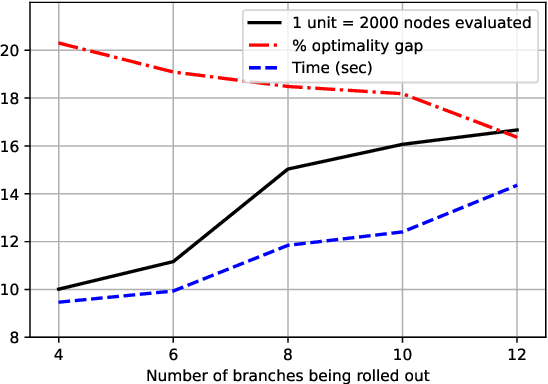

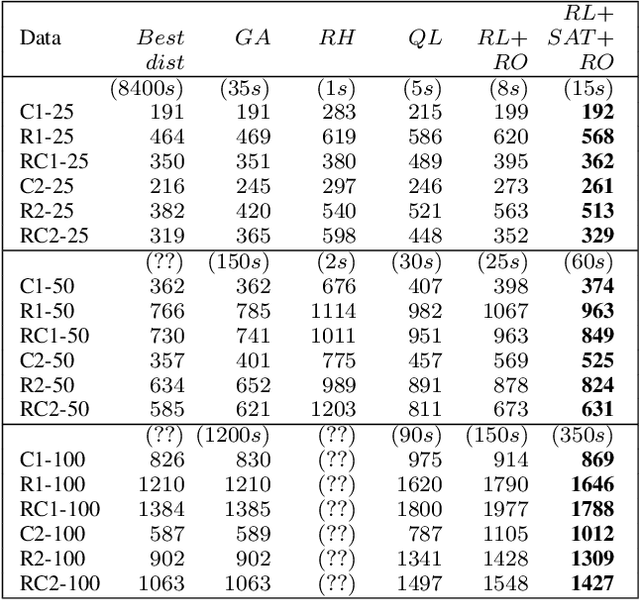
The vehicle routing problem is a well known class of NP-hard combinatorial optimisation problems in literature. Traditional solution methods involve either carefully designed heuristics, or time-consuming metaheuristics. Recent work in reinforcement learning has been a promising alternative approach, but has found it difficult to compete with traditional methods in terms of solution quality. This paper proposes a hybrid approach that combines reinforcement learning, policy rollouts, and a satisfiability solver to enable a tunable tradeoff between computation times and solution quality. Results on a popular public data set show that the algorithm is able to produce solutions closer to optimal levels than existing learning based approaches, and with shorter computation times than meta-heuristics. The approach requires minimal design effort and is able to solve unseen problems of arbitrary scale without additional training. Furthermore, the methodology is generalisable to other combinatorial optimisation problems.
Channel Importance Matters in Few-Shot Image Classification
Jun 20, 2022

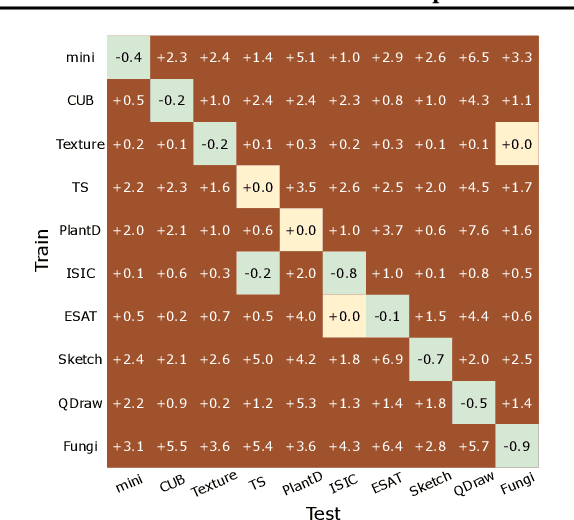
Few-Shot Learning (FSL) requires vision models to quickly adapt to brand-new classification tasks with a shift in task distribution. Understanding the difficulties posed by this task distribution shift is central to FSL. In this paper, we show that a simple channel-wise feature transformation may be the key to unraveling this secret from a channel perspective. When facing novel few-shot tasks in the test-time datasets, this transformation can greatly improve the generalization ability of learned image representations, while being agnostic to the choice of training algorithms and datasets. Through an in-depth analysis of this transformation, we find that the difficulty of representation transfer in FSL stems from the severe channel bias problem of image representations: channels may have different importance in different tasks, while convolutional neural networks are likely to be insensitive, or respond incorrectly to such a shift. This points out a core problem of the generalization ability of modern vision systems and needs further attention in the future. Our code is available at https://github.com/Frankluox/Channel_Importance_FSL.
Interpretable Feature Construction for Time Series Extrinsic Regression
Mar 15, 2021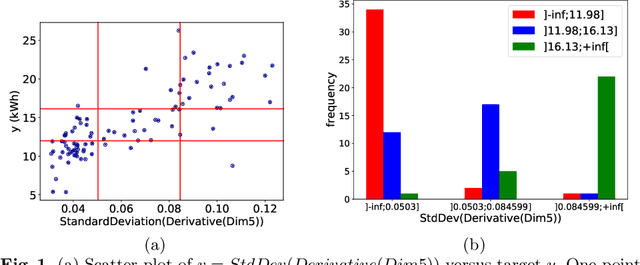
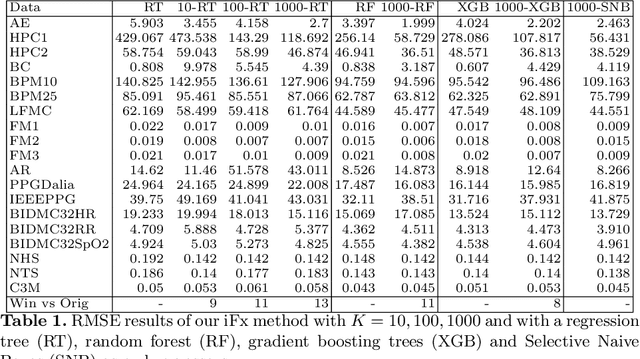
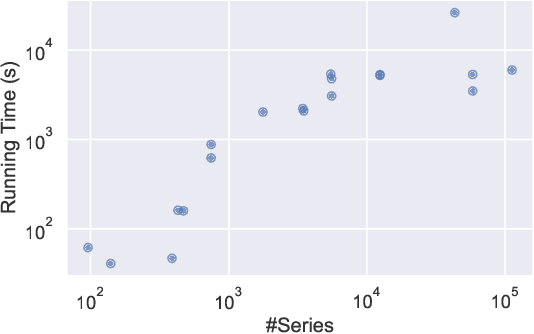
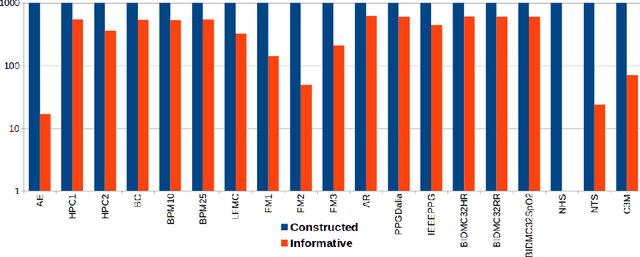
Supervised learning of time series data has been extensively studied for the case of a categorical target variable. In some application domains, e.g., energy, environment and health monitoring, it occurs that the target variable is numerical and the problem is known as time series extrinsic regression (TSER). In the literature, some well-known time series classifiers have been extended for TSER problems. As first benchmarking studies have focused on predictive performance, very little attention has been given to interpretability. To fill this gap, in this paper, we suggest an extension of a Bayesian method for robust and interpretable feature construction and selection in the context of TSER. Our approach exploits a relational way to tackle with TSER: (i), we build various and simple representations of the time series which are stored in a relational data scheme, then, (ii), a propositionalisation technique (based on classical aggregation / selection functions from the relational data field) is applied to build interpretable features from secondary tables to "flatten" the data; and (iii), the constructed features are filtered out through a Bayesian Maximum A Posteriori approach. The resulting transformed data can be processed with various existing regressors. Experimental validation on various benchmark data sets demonstrates the benefits of the suggested approach.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022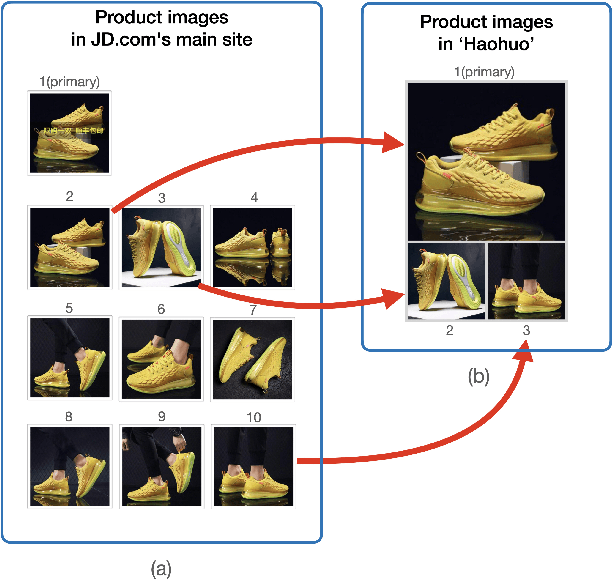

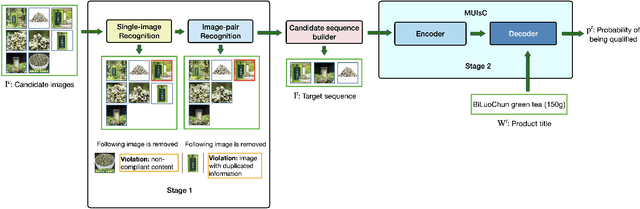
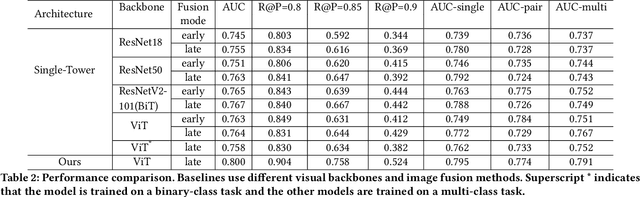
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
The DEBS 2022 Grand Challenge: Detecting Trading Trends in Financial Tick Data
Jun 23, 2022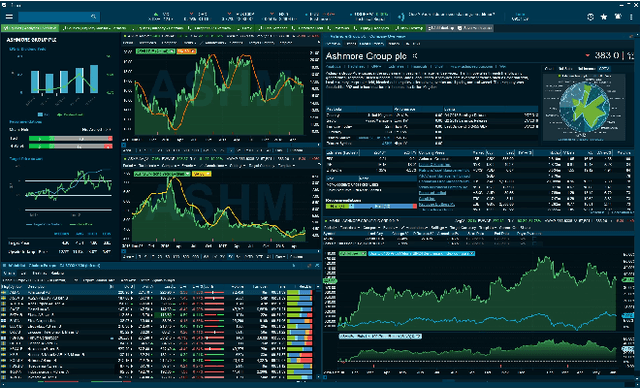
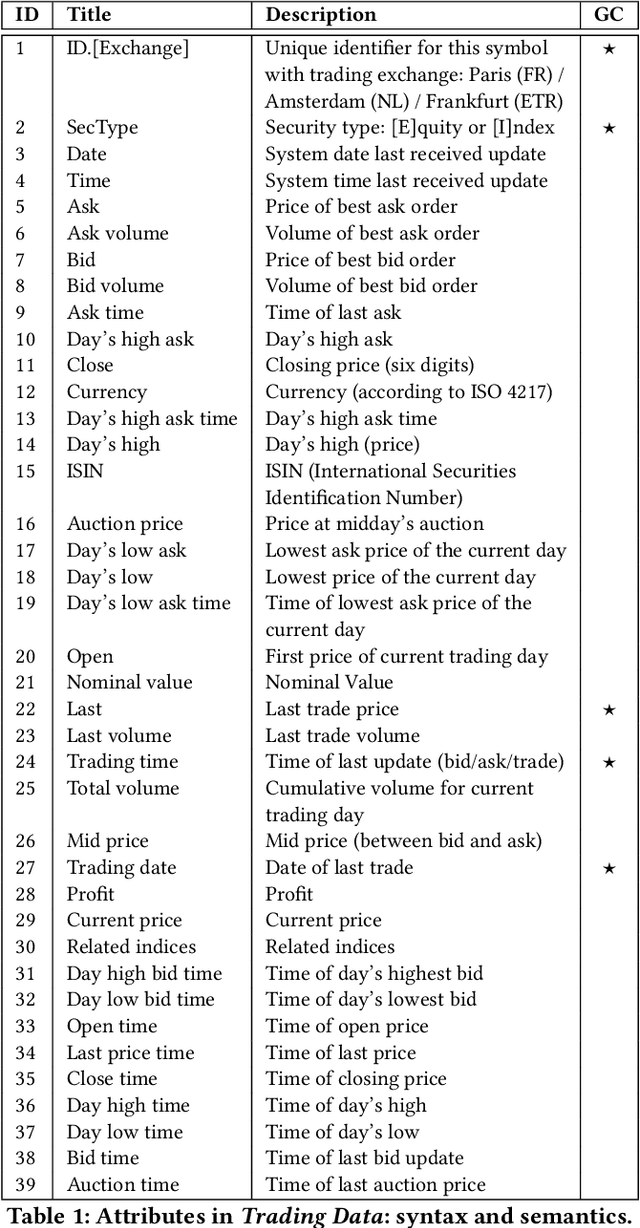
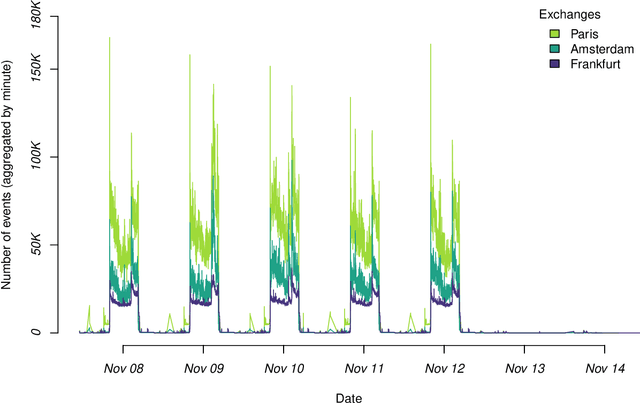
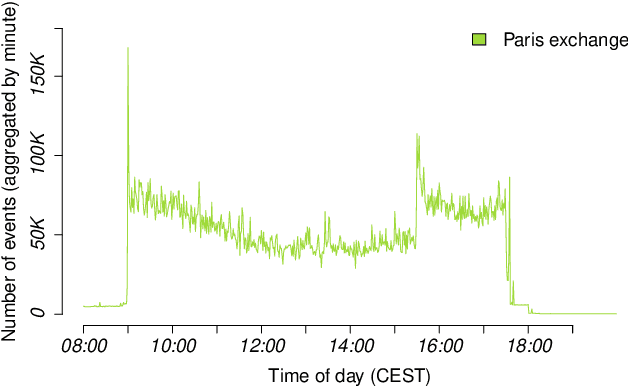
The DEBS Grand Challenge (GC) is an annual programming competition open to practitioners from both academia and industry. The GC 2022 edition focuses on real-time complex event processing of high-volume tick data provided by Infront Financial Technology GmbH. The goal of the challenge is to efficiently compute specific trend indicators and detect patterns in these indicators like those used by real-life traders to decide on buying or selling in financial markets. The data set Trading Data used for benchmarking contains 289 million tick events from approximately 5500+ financial instruments that had been traded on the three major exchanges Amsterdam (NL), Paris (FR), and Frankfurt am Main (GER) over the course of a full week in 2021. The data set is made publicly available. In addition to correctness and performance, submissions must explicitly focus on reusability and practicability. Hence, participants must address specific nonfunctional requirements and are asked to build upon open-source platforms. This paper describes the required scenario and the data set Trading Data, defines the queries of the problem statement, and explains the enhancements made to the evaluation platform Challenger that handles data distribution, dynamic subscriptions, and remote evaluation of the submissions.
An Efficient Modern Baseline for FloodNet VQA
May 30, 2022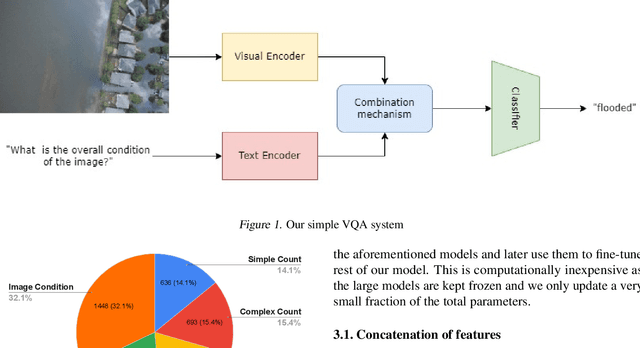
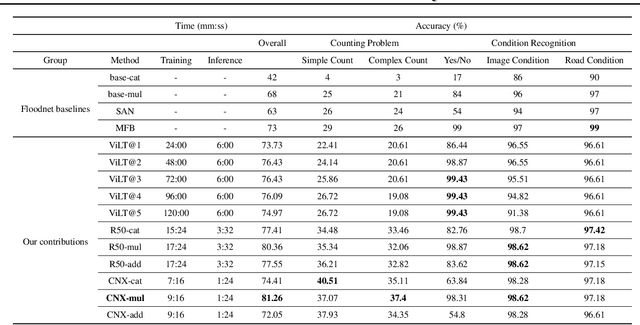
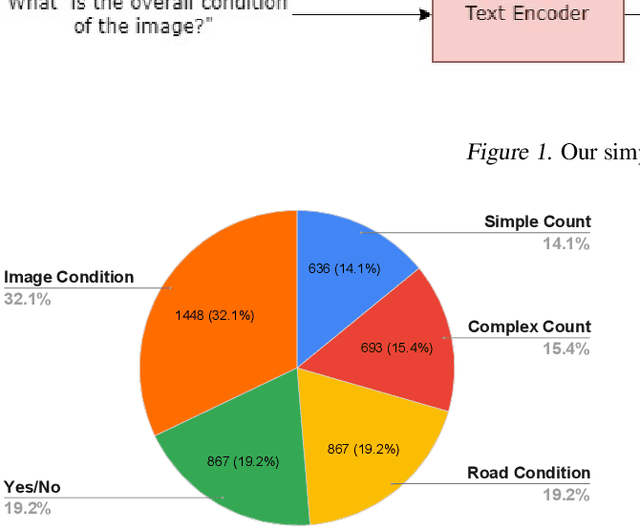
Designing efficient and reliable VQA systems remains a challenging problem, more so in the case of disaster management and response systems. In this work, we revisit fundamental combination methods like concatenation, addition and element-wise multiplication with modern image and text feature abstraction models. We design a simple and efficient system which outperforms pre-existing methods on the FloodNet dataset and achieves state-of-the-art performance. This simplified system requires significantly less training and inference time than modern VQA architectures. We also study the performance of various backbones and report their consolidated results. Code is available at https://github.com/sahilkhose/floodnet_vqa.
The Temporal Dictionary Ensemble (TDE) Classifier for Time Series Classification
May 09, 2021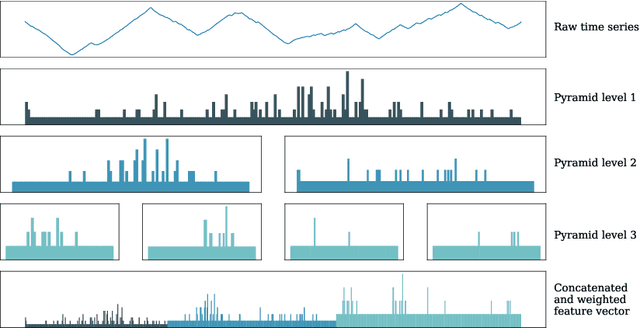
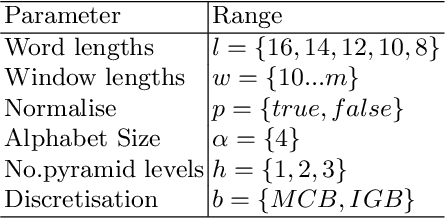
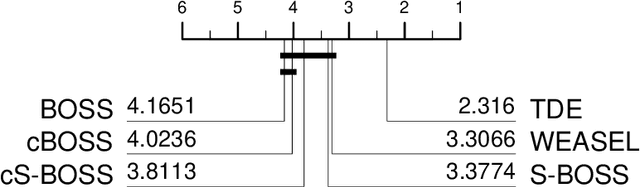
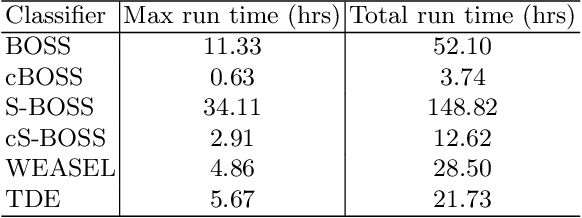
Using bag of words representations of time series is a popular approach to time series classification. These algorithms involve approximating and discretising windows over a series to form words, then forming a count of words over a given dictionary. Classifiers are constructed on the resulting histograms of word counts. A 2017 evaluation of a range of time series classifiers found the bag of symbolic-fourier approximation symbols (BOSS) ensemble the best of the dictionary based classifiers. It forms one of the components of hierarchical vote collective of transformation-based ensembles (HIVE-COTE), which represents the current state of the art. Since then, several new dictionary based algorithms have been proposed that are more accurate or more scalable (or both) than BOSS. We propose a further extension of these dictionary based classifiers that combines the best elements of the others combined with a novel approach to constructing ensemble members based on an adaptive Gaussian process model of the parameter space. We demonstrate that the temporal dictionary ensemble (TDE) is more accurate than other dictionary based approaches. Furthermore, unlike the other classifiers, if we replace BOSS in HIVE-COTE with TDE, HIVE-COTE is significantly more accurate. We also show this new version of HIVE-COTE is significantly more accurate than the current best deep learning approach, a recently proposed hybrid tree ensemble and a recently introduced competitive classifier making use of highly randomised convolutional kernels. This advance represents a new state of the art for time series classification.
* arXiv admin note: text overlap with arXiv:1911.12008
Fully Convolutional One-Stage 3D Object Detection on LiDAR Range Images
May 27, 2022

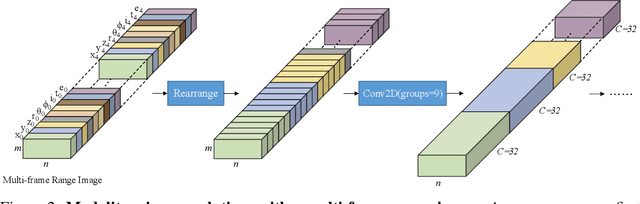
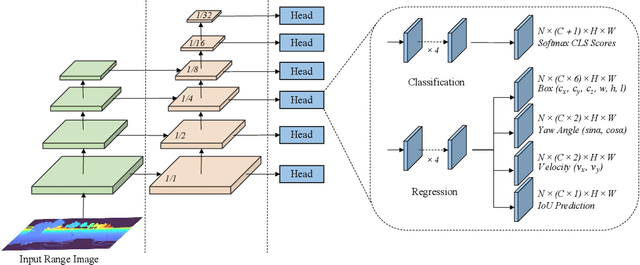
We present a simple yet effective fully convolutional one-stage 3D object detector for LiDAR point clouds of autonomous driving scenes, termed FCOS-LiDAR. Unlike the dominant methods that use the bird-eye view (BEV), our proposed detector detects objects from the range view (RV, a.k.a. range image) of the LiDAR points. Due to the range view's compactness and compatibility with the LiDAR sensors' sampling process on self-driving cars, the range view-based object detector can be realized by solely exploiting the vanilla 2D convolutions, departing from the BEV-based methods which often involve complicated voxelization operations and sparse convolutions. For the first time, we show that an RV-based 3D detector with standard 2D convolutions alone can achieve comparable performance to state-of-the-art BEV-based detectors while being significantly faster and simpler. More importantly, almost all previous range view-based detectors only focus on single-frame point clouds, since it is challenging to fuse multi-frame point clouds into a single range view. In this work, we tackle this challenging issue with a novel range view projection mechanism, and for the first time demonstrate the benefits of fusing multi-frame point clouds for a range-view based detector. Extensive experiments on nuScenes show the superiority of our proposed method and we believe that our work can be strong evidence that an RV-based 3D detector can compare favourably with the current mainstream BEV-based detectors.
ProSTformer: Pre-trained Progressive Space-Time Self-attention Model for Traffic Flow Forecasting
Nov 03, 2021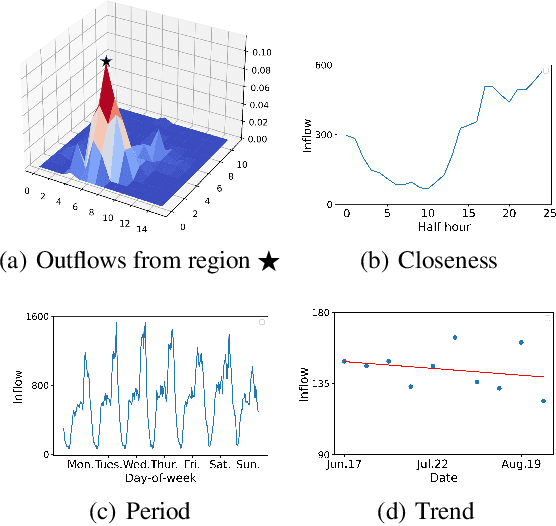
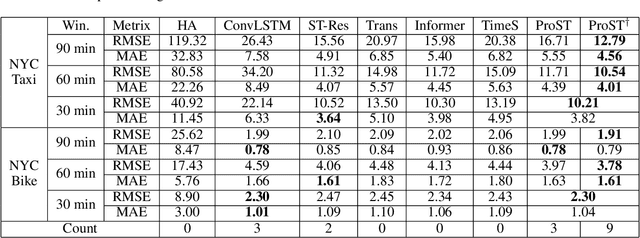
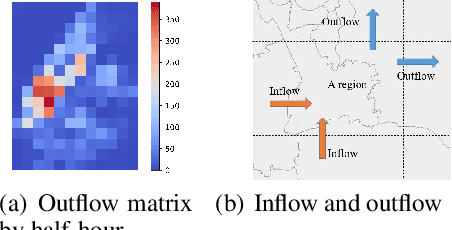
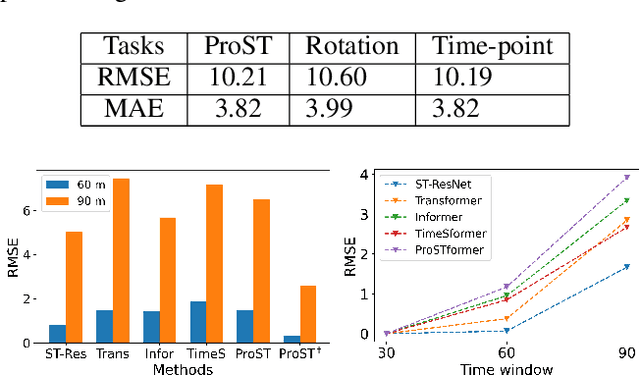
Traffic flow forecasting is essential and challenging to intelligent city management and public safety. Recent studies have shown the potential of convolution-free Transformer approach to extract the dynamic dependencies among complex influencing factors. However, two issues prevent the approach from being effectively applied in traffic flow forecasting. First, it ignores the spatiotemporal structure of the traffic flow videos. Second, for a long sequence, it is hard to focus on crucial attention due to the quadratic times dot-product computation. To address the two issues, we first factorize the dependencies and then design a progressive space-time self-attention mechanism named ProSTformer. It has two distinctive characteristics: (1) corresponding to the factorization, the self-attention mechanism progressively focuses on spatial dependence from local to global regions, on temporal dependence from inside to outside fragment (i.e., closeness, period, and trend), and finally on external dependence such as weather, temperature, and day-of-week; (2) by incorporating the spatiotemporal structure into the self-attention mechanism, each block in ProSTformer highlights the unique dependence by aggregating the regions with spatiotemporal positions to significantly decrease the computation. We evaluate ProSTformer on two traffic datasets, and each dataset includes three separate datasets with big, medium, and small scales. Despite the radically different design compared to the convolutional architectures for traffic flow forecasting, ProSTformer performs better or the same on the big scale datasets than six state-of-the-art baseline methods by RMSE. When pre-trained on the big scale datasets and transferred to the medium and small scale datasets, ProSTformer achieves a significant enhancement and behaves best.
HealNet -- Self-Supervised Acute Wound Heal-Stage Classification
Jun 23, 2022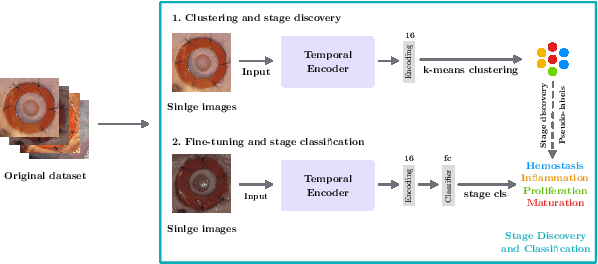
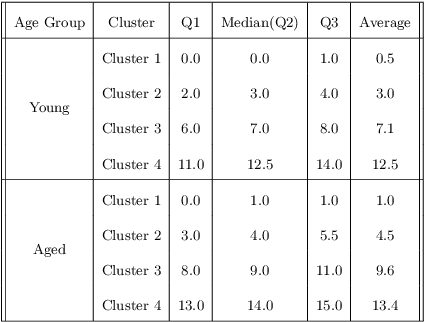


Identifying, tracking, and predicting wound heal-stage progression is a fundamental task towards proper diagnosis, effective treatment, facilitating healing, and reducing pain. Traditionally, a medical expert might observe a wound to determine the current healing state and recommend treatment. However, sourcing experts who can produce such a diagnosis solely from visual indicators can be difficult, time-consuming and expensive. In addition, lesions may take several weeks to undergo the healing process, demanding resources to monitor and diagnose continually. Automating this task can be challenging; datasets that follow wound progression from onset to maturation are small, rare, and often collected without computer vision in mind. To tackle these challenges, we introduce a self-supervised learning scheme composed of (a) learning embeddings of wound's temporal dynamics, (b) clustering for automatic stage discovery, and (c) fine-tuned classification. The proposed self-supervised and flexible learning framework is biologically inspired and trained on a small dataset with zero human labeling. The HealNet framework achieved high pre-text and downstream classification accuracy; when evaluated on held-out test data, HealNet achieved 97.7% pre-text accuracy and 90.62% heal-stage classification accuracy.