 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Partitura: A Python Package for Symbolic Music Processing
Jun 02, 2022
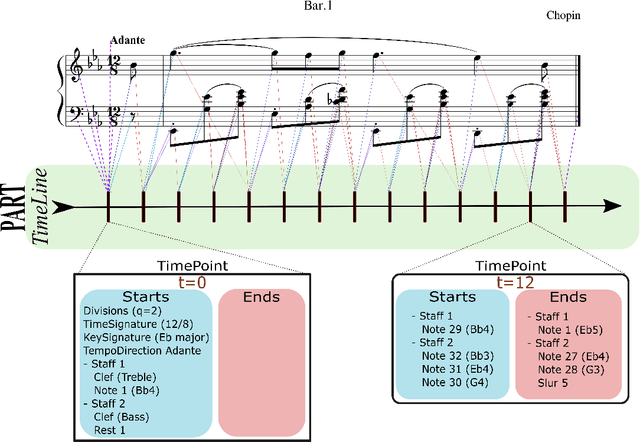

Partitura is a lightweight Python package for handling symbolic musical information. It provides easy access to features commonly used in music information retrieval tasks, like note arrays (lists of timed pitched events) and 2D piano roll matrices, as well as other score elements such as time and key signatures, performance directives, and repeat structures. Partitura can load musical scores (in MEI, MusicXML, Kern, and MIDI formats), MIDI performances, and score-to-performance alignments. The package includes some tools for music analysis, such as automatic pitch spelling, key signature identification, and voice separation. Partitura is an open-source project and is available at https://github.com/CPJKU/partitura/.
Softmax-free Linear Transformers
Jul 05, 2022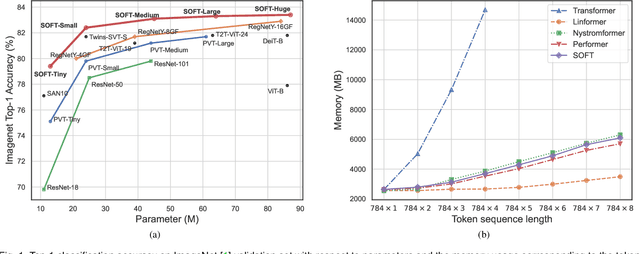

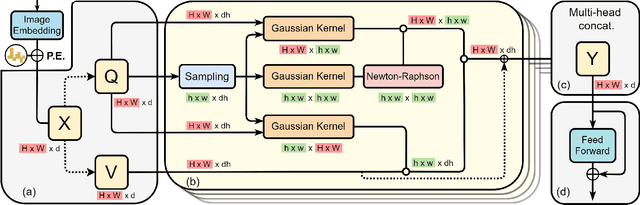
Vision transformers (ViTs) have pushed the state-of-the-art for various visual recognition tasks by patch-wise image tokenization followed by stacked self-attention operations. Employing self-attention modules results in a quadratic complexity in both computation and memory usage. Various attempts on approximating the self-attention computation with linear complexity have thus been made in Natural Language Processing. However, an in-depth analysis in this work reveals that they are either theoretically flawed or empirically ineffective for visual recognition. We identify that their limitations are rooted in retaining the softmax self-attention during approximations. Specifically, conventional self-attention is computed by normalizing the scaled dot-product between token feature vectors. Preserving the softmax operation challenges any subsequent linearization efforts. Under this insight, a SOftmax-Free Transformer (abbreviated as SOFT) is proposed for the first time. To eliminate the softmax operator in self-attention, a Gaussian kernel function is adopted to replace the dot-product similarity. This enables a full self-attention matrix to be approximated via a low-rank matrix decomposition. The robustness of our approximation is achieved by calculating its Moore-Penrose inverse using a Newton-Raphson method. Further, an efficient symmetric normalization is introduced on the low-rank self-attention for enhancing model generalizability and transferability. Extensive experiments on ImageNet, COCO and ADE20K show that our SOFT significantly improves the computational efficiency of existing ViT variants. Crucially, with a linear complexity, much longer token sequences are permitted in SOFT, resulting in superior trade-off between accuracy and complexity.
AFT-VO: Asynchronous Fusion Transformers for Multi-View Visual Odometry Estimation
Jun 26, 2022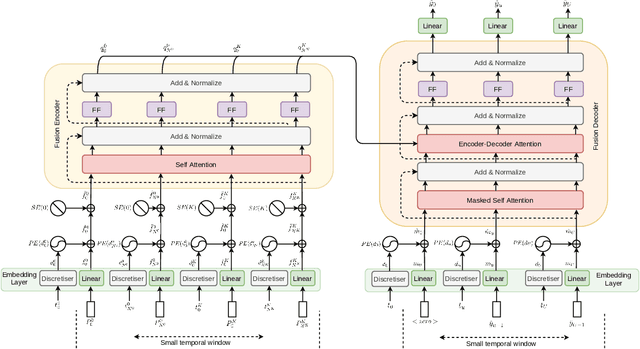
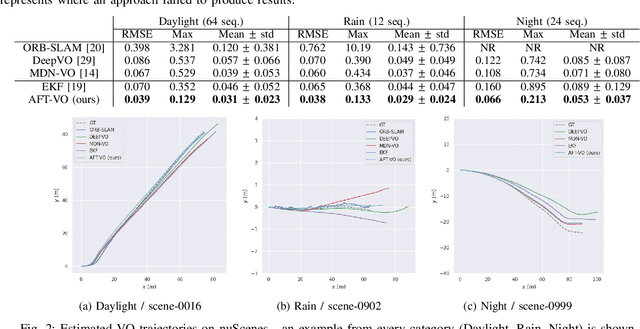
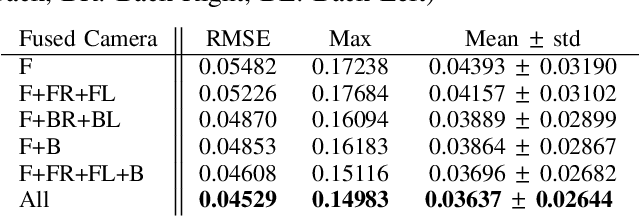
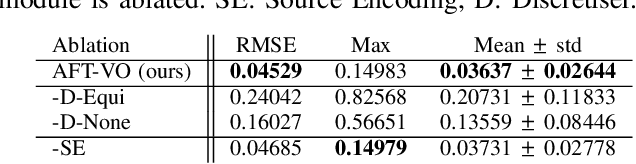
Motion estimation approaches typically employ sensor fusion techniques, such as the Kalman Filter, to handle individual sensor failures. More recently, deep learning-based fusion approaches have been proposed, increasing the performance and requiring less model-specific implementations. However, current deep fusion approaches often assume that sensors are synchronised, which is not always practical, especially for low-cost hardware. To address this limitation, in this work, we propose AFT-VO, a novel transformer-based sensor fusion architecture to estimate VO from multiple sensors. Our framework combines predictions from asynchronous multi-view cameras and accounts for the time discrepancies of measurements coming from different sources. Our approach first employs a Mixture Density Network (MDN) to estimate the probability distributions of the 6-DoF poses for every camera in the system. Then a novel transformer-based fusion module, AFT-VO, is introduced, which combines these asynchronous pose estimations, along with their confidences. More specifically, we introduce Discretiser and Source Encoding techniques which enable the fusion of multi-source asynchronous signals. We evaluate our approach on the popular nuScenes and KITTI datasets. Our experiments demonstrate that multi-view fusion for VO estimation provides robust and accurate trajectories, outperforming the state of the art in both challenging weather and lighting conditions.
Solving the capacitated vehicle routing problem with timing windows using rollouts and MAX-SAT
Jun 14, 2022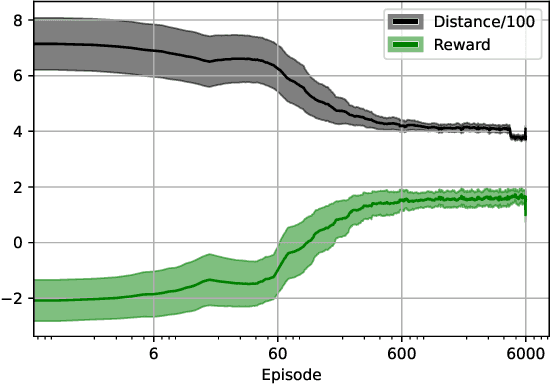
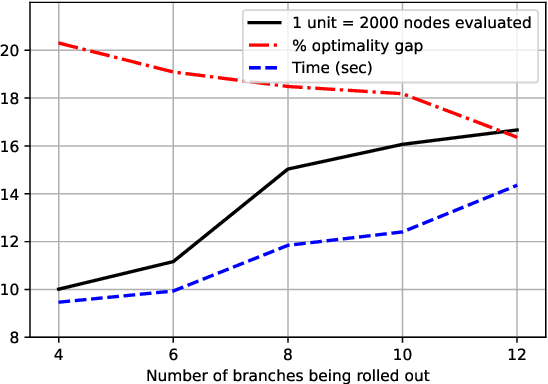

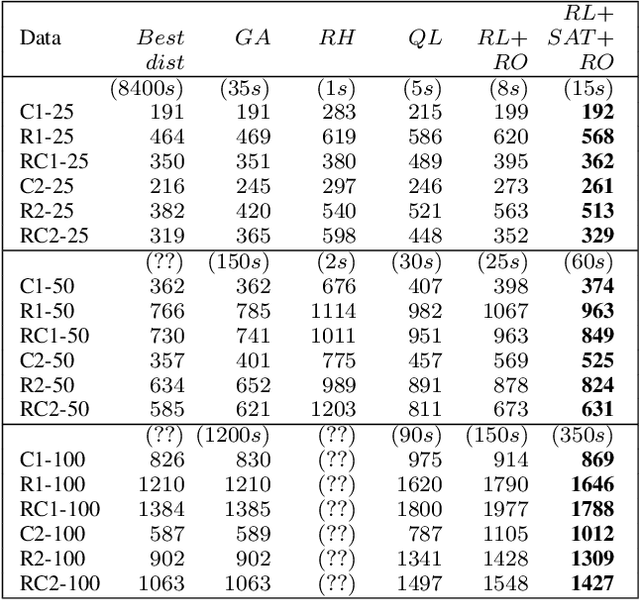
The vehicle routing problem is a well known class of NP-hard combinatorial optimisation problems in literature. Traditional solution methods involve either carefully designed heuristics, or time-consuming metaheuristics. Recent work in reinforcement learning has been a promising alternative approach, but has found it difficult to compete with traditional methods in terms of solution quality. This paper proposes a hybrid approach that combines reinforcement learning, policy rollouts, and a satisfiability solver to enable a tunable tradeoff between computation times and solution quality. Results on a popular public data set show that the algorithm is able to produce solutions closer to optimal levels than existing learning based approaches, and with shorter computation times than meta-heuristics. The approach requires minimal design effort and is able to solve unseen problems of arbitrary scale without additional training. Furthermore, the methodology is generalisable to other combinatorial optimisation problems.
Approximating Discontinuous Nash Equilibrial Values of Two-Player General-Sum Differential Games
Jul 05, 2022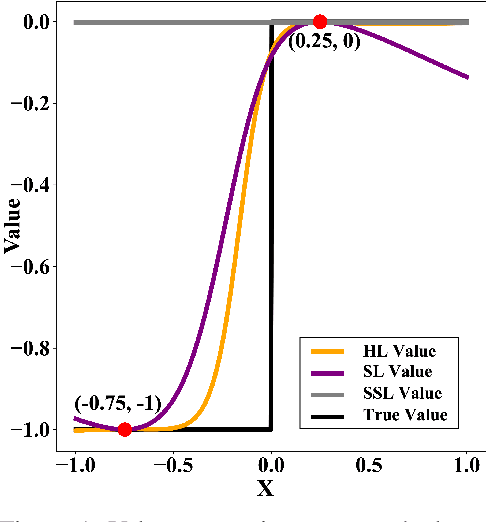
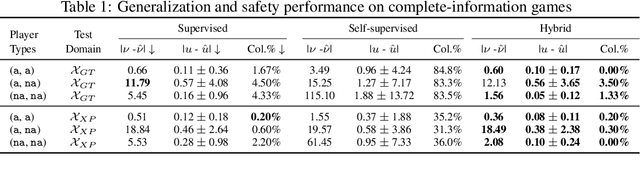
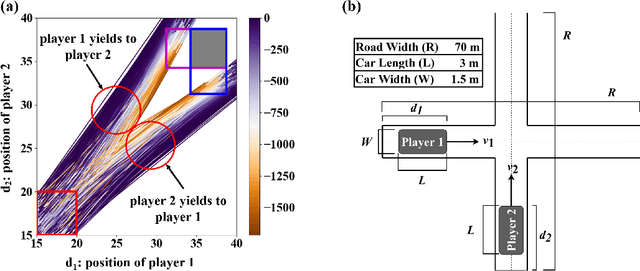

Finding Nash equilibrial policies for two-player differential games requires solving Hamilton-Jacobi-Isaacs PDEs. Recent studies achieved success in circumventing the curse of dimensionality in solving such PDEs with underlying applications to human-robot interactions (HRI), by adopting self-supervised (physics-informed) neural networks as universal value approximators. This paper extends from previous SOTA on zero-sum games with continuous values to general-sum games with discontinuous values, where the discontinuity is caused by that of the players' losses. We show that due to its lack of convergence proof and generalization analysis on discontinuous losses, the existing self-supervised learning technique fails to generalize and raises safety concerns in an autonomous driving application. Our solution is to first pre-train the value network on supervised Nash equilibria, and then refine it by minimizing a loss that combines the supervised data with the PDE and boundary conditions. Importantly, the demonstrated advantage of the proposed learning method against purely supervised and self-supervised approaches requires careful choice of the neural activation function: Among $\texttt{relu}$, $\texttt{sin}$, and $\texttt{tanh}$, we show that $\texttt{tanh}$ is the only choice that achieves optimal generalization and safety performance. Our conjecture is that $\texttt{tanh}$ (similar to $\texttt{sin}$) allows continuity of value and its gradient, which is sufficient for the convergence of learning, and at the same time is expressive enough (similar to $\texttt{relu}$) at approximating discontinuous value landscapes. Lastly, we apply our method to approximating control policies for an incomplete-information interaction and demonstrate its contribution to safe interactions.
Cliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments
May 14, 2022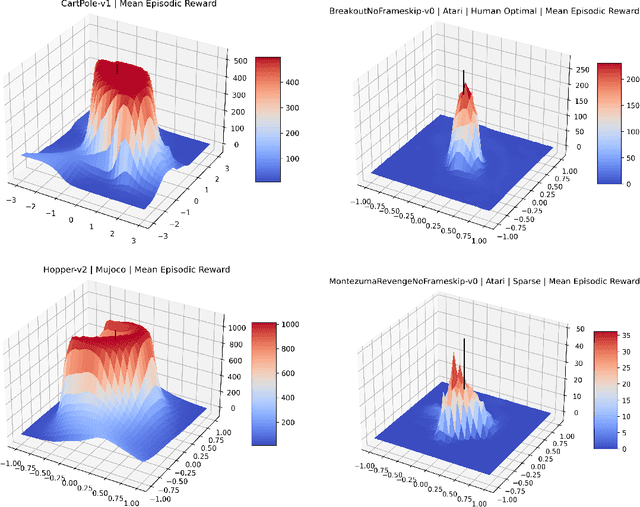
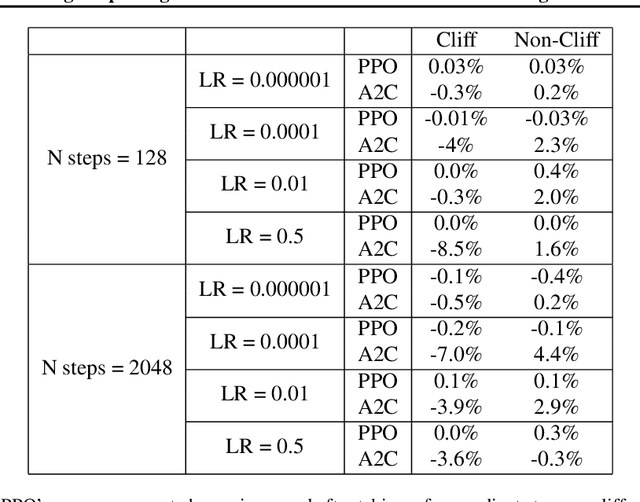
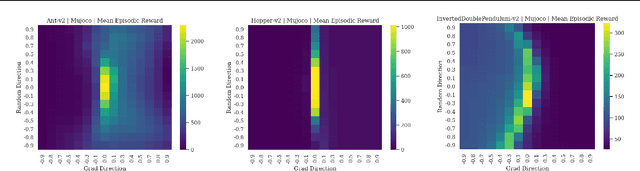
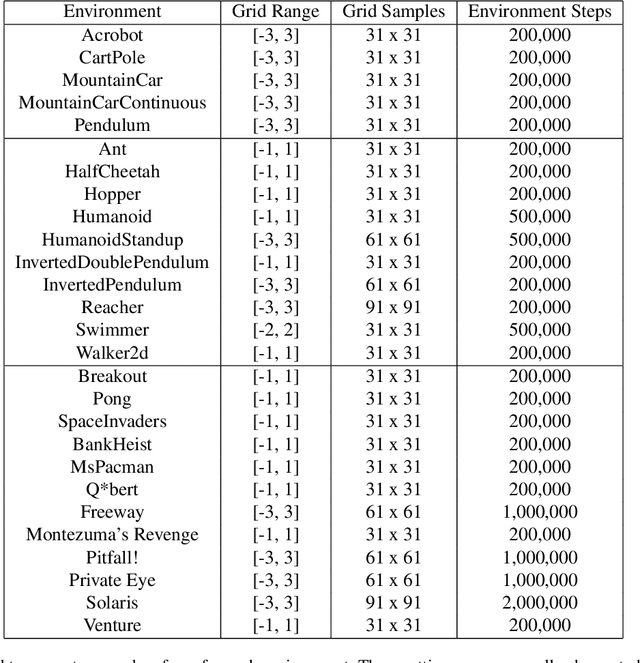
Visualizing optimization landscapes has led to many fundamental insights in numeric optimization, and novel improvements to optimization techniques. However, visualizations of the objective that reinforcement learning optimizes (the "reward surface") have only ever been generated for a small number of narrow contexts. This work presents reward surfaces and related visualizations of 27 of the most widely used reinforcement learning environments in Gym for the first time. We also explore reward surfaces in the policy gradient direction and show for the first time that many popular reinforcement learning environments have frequent "cliffs" (sudden large drops in expected return). We demonstrate that A2C often "dives off" these cliffs into low reward regions of the parameter space while PPO avoids them, confirming a popular intuition for PPO's improved performance over previous methods. We additionally introduce a highly extensible library that allows researchers to easily generate these visualizations in the future. Our findings provide new intuition to explain the successes and failures of modern RL methods, and our visualizations concretely characterize several failure modes of reinforcement learning agents in novel ways.
HealNet -- Self-Supervised Acute Wound Heal-Stage Classification
Jun 23, 2022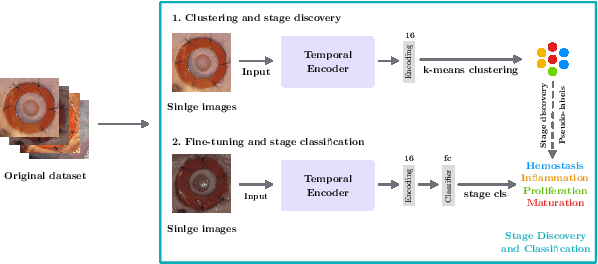


Identifying, tracking, and predicting wound heal-stage progression is a fundamental task towards proper diagnosis, effective treatment, facilitating healing, and reducing pain. Traditionally, a medical expert might observe a wound to determine the current healing state and recommend treatment. However, sourcing experts who can produce such a diagnosis solely from visual indicators can be difficult, time-consuming and expensive. In addition, lesions may take several weeks to undergo the healing process, demanding resources to monitor and diagnose continually. Automating this task can be challenging; datasets that follow wound progression from onset to maturation are small, rare, and often collected without computer vision in mind. To tackle these challenges, we introduce a self-supervised learning scheme composed of (a) learning embeddings of wound's temporal dynamics, (b) clustering for automatic stage discovery, and (c) fine-tuned classification. The proposed self-supervised and flexible learning framework is biologically inspired and trained on a small dataset with zero human labeling. The HealNet framework achieved high pre-text and downstream classification accuracy; when evaluated on held-out test data, HealNet achieved 97.7% pre-text accuracy and 90.62% heal-stage classification accuracy.
ENS-10: A Dataset For Post-Processing Ensemble Weather Forecast
Jun 29, 2022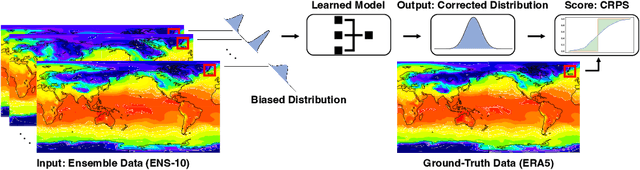
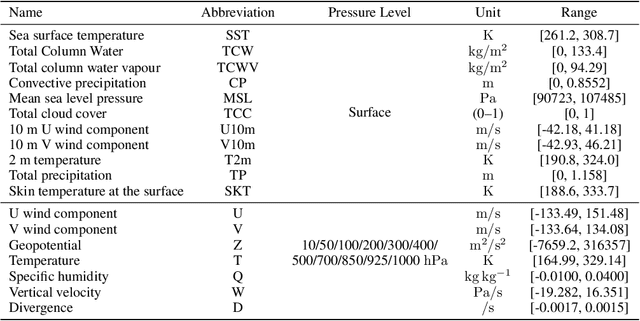
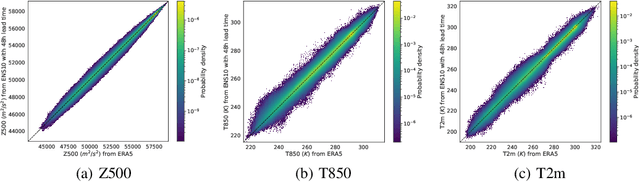
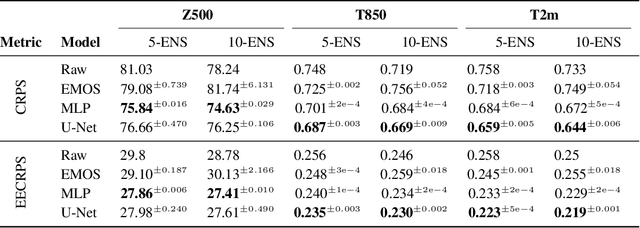
Post-processing ensemble prediction systems can improve weather forecasting, especially for extreme event prediction. In recent years, different machine learning models have been developed to improve the quality of the post-processing step. However, these models heavily rely on the data and generating such ensemble members requires multiple runs of numerical weather prediction models, at high computational cost. This paper introduces the ENS-10 dataset, consisting of ten ensemble members spread over 20 years (1998-2017). The ensemble members are generated by perturbing numerical weather simulations to capture the chaotic behavior of the Earth. To represent the three-dimensional state of the atmosphere, ENS-10 provides the most relevant atmospheric variables in 11 distinct pressure levels as well as the surface at 0.5-degree resolution. The dataset targets the prediction correction task at 48-hour lead time, which is essentially improving the forecast quality by removing the biases of the ensemble members. To this end, ENS-10 provides the weather variables for forecast lead times T=0, 24, and 48 hours (two data points per week). We provide a set of baselines for this task on ENS-10 and compare their performance in correcting the prediction of different weather variables. We also assess our baselines for predicting extreme events using our dataset. The ENS-10 dataset is available under the Creative Commons Attribution 4.0 International (CC BY 4.0) licence.
Transferable Graph Backdoor Attack
Jul 05, 2022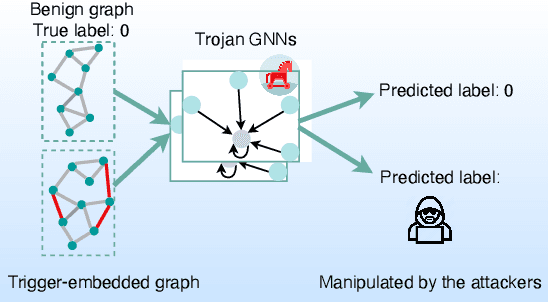

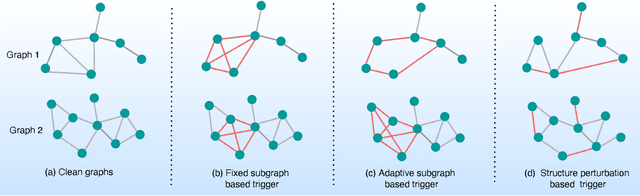
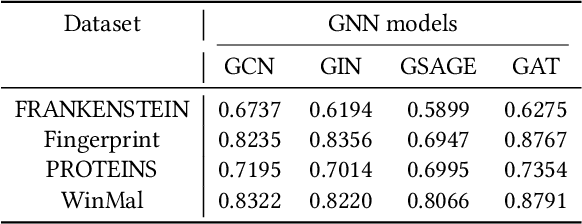
Graph Neural Networks (GNNs) have achieved tremendous success in many graph mining tasks benefitting from the message passing strategy that fuses the local structure and node features for better graph representation learning. Despite the success of GNNs, and similar to other types of deep neural networks, GNNs are found to be vulnerable to unnoticeable perturbations on both graph structure and node features. Many adversarial attacks have been proposed to disclose the fragility of GNNs under different perturbation strategies to create adversarial examples. However, vulnerability of GNNs to successful backdoor attacks was only shown recently. In this paper, we disclose the TRAP attack, a Transferable GRAPh backdoor attack. The core attack principle is to poison the training dataset with perturbation-based triggers that can lead to an effective and transferable backdoor attack. The perturbation trigger for a graph is generated by performing the perturbation actions on the graph structure via a gradient based score matrix from a surrogate model. Compared with prior works, TRAP attack is different in several ways: i) it exploits a surrogate Graph Convolutional Network (GCN) model to generate perturbation triggers for a blackbox based backdoor attack; ii) it generates sample-specific perturbation triggers which do not have a fixed pattern; and iii) the attack transfers, for the first time in the context of GNNs, to different GNN models when trained with the forged poisoned training dataset. Through extensive evaluations on four real-world datasets, we demonstrate the effectiveness of the TRAP attack to build transferable backdoors in four different popular GNNs using four real-world datasets.
Detecting Unknown DGAs without Context Information
May 30, 2022
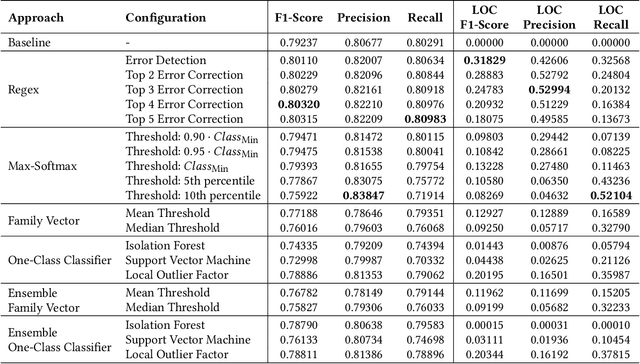
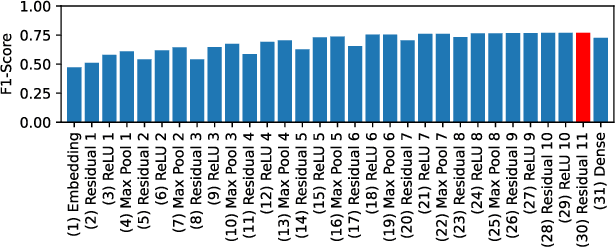
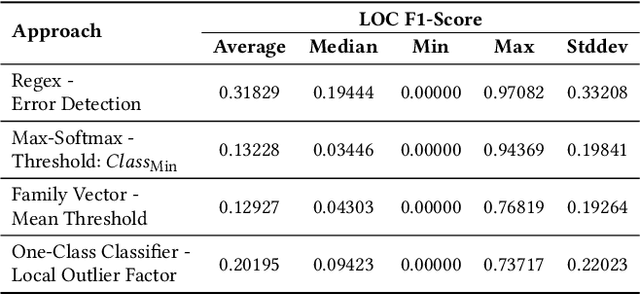
New malware emerges at a rapid pace and often incorporates Domain Generation Algorithms (DGAs) to avoid blocking the malware's connection to the command and control (C2) server. Current state-of-the-art classifiers are able to separate benign from malicious domains (binary classification) and attribute them with high probability to the DGAs that generated them (multiclass classification). While binary classifiers can label domains of yet unknown DGAs as malicious, multiclass classifiers can only assign domains to DGAs that are known at the time of training, limiting the ability to uncover new malware families. In this work, we perform a comprehensive study on the detection of new DGAs, which includes an evaluation of 59,690 classifiers. We examine four different approaches in 15 different configurations and propose a simple yet effective approach based on the combination of a softmax classifier and regular expressions (regexes) to detect multiple unknown DGAs with high probability. At the same time, our approach retains state-of-the-art classification performance for known DGAs. Our evaluation is based on a leave-one-group-out cross-validation with a total of 94 DGA families. By using the maximum number of known DGAs, our evaluation scenario is particularly difficult and close to the real world. All of the approaches examined are privacy-preserving, since they operate without context and exclusively on a single domain to be classified. We round up our study with a thorough discussion of class-incremental learning strategies that can adapt an existing classifier to newly discovered classes.