 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PhySRNet: Physics informed super-resolution network for application in computational solid mechanics
Jun 30, 2022
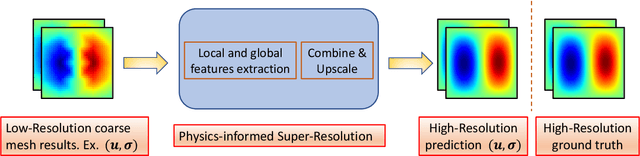
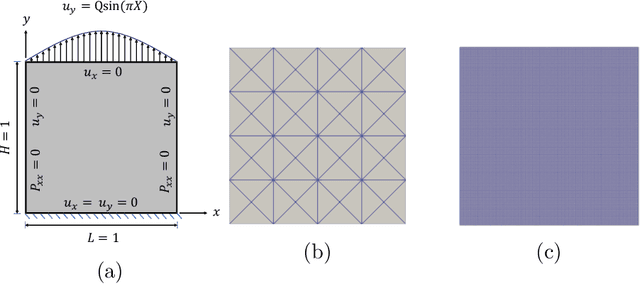
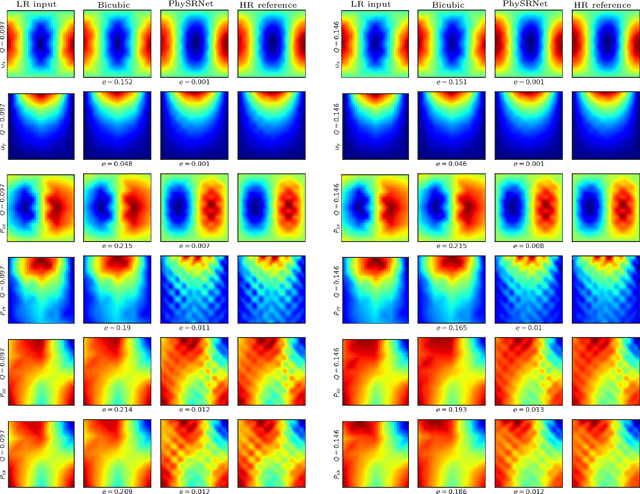
Traditional approaches based on finite element analyses have been successfully used to predict the macro-scale behavior of heterogeneous materials (composites, multicomponent alloys, and polycrystals) widely used in industrial applications. However, this necessitates the mesh size to be smaller than the characteristic length scale of the microstructural heterogeneities in the material leading to computationally expensive and time-consuming calculations. The recent advances in deep learning based image super-resolution (SR) algorithms open up a promising avenue to tackle this computational challenge by enabling researchers to enhance the spatio-temporal resolution of data obtained from coarse mesh simulations. However, technical challenges still remain in developing a high-fidelity SR model for application to computational solid mechanics, especially for materials undergoing large deformation. This work aims at developing a physics-informed deep learning based super-resolution framework (PhySRNet) which enables reconstruction of high-resolution deformation fields (displacement and stress) from their low-resolution counterparts without requiring high-resolution labeled data. We design a synthetic case study to illustrate the effectiveness of the proposed framework and demonstrate that the super-resolved fields match the accuracy of an advanced numerical solver running at 400 times the coarse mesh resolution while simultaneously satisfying the (highly nonlinear) governing laws. The approach opens the door to applying machine learning and traditional numerical approaches in tandem to reduce computational complexity accelerate scientific discovery and engineering design.
Massive MIMO for Serving Federated Learning and Non-Federated Learning Users
May 21, 2022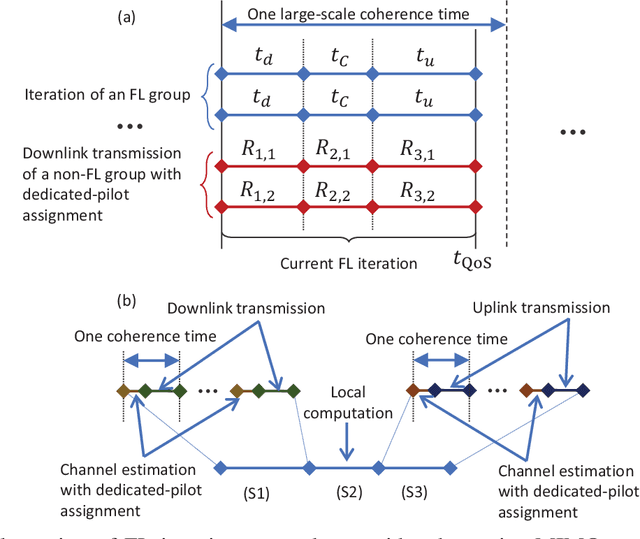
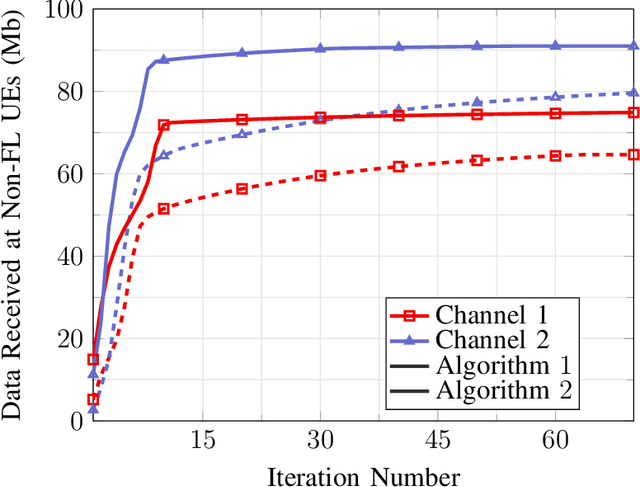
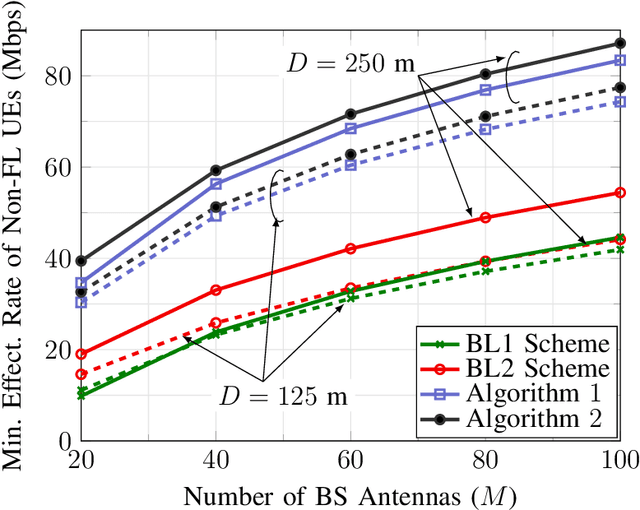
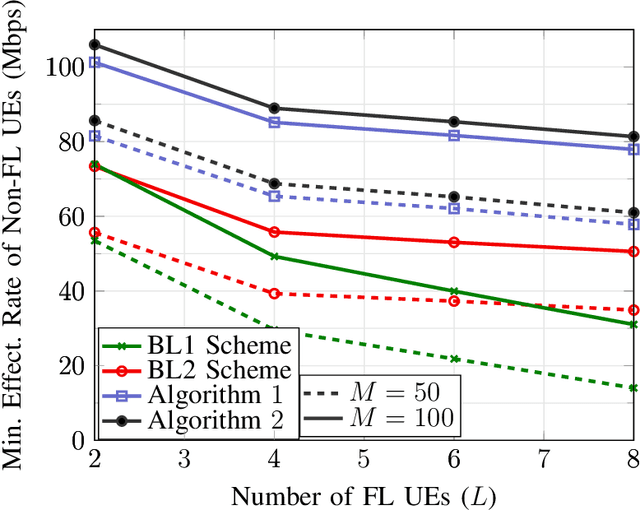
With its privacy preservation and communication efficiency, federated learning (FL) has emerged as a promising learning framework for beyond 5G wireless networks. It is anticipated that future wireless networks will jointly serve both FL and downlink non-FL user groups in the same time-frequency resource. While in the downlink of each FL iteration, both groups jointly receive data from the base station in the same time-frequency resource, the uplink of each FL iteration requires bidirectional communication to support uplink transmission for FL users and downlink transmission for non-FL users. To overcome this challenge, we present half-duplex (HD) and full-duplex (FD) communication schemes to serve both groups. More specifically, we adopt the massive multiple-input multiple-output technology and aim to maximize the minimum effective rate of non-FL users under a quality of service (QoS) latency constraint for FL users. Since the formulated problem is highly nonconvex, we propose a power control algorithm based on successive convex approximation to find a stationary solution. Numerical results show that the proposed solutions perform significantly better than the considered baselines schemes. Moreover, the FD-based scheme outperforms the HD-based scheme in scenarios where the self-interference is small or moderate and/or the size of FL model updates is large.
Deep Learning Architecture Based Approach For 2D-Simulation of Microwave Plasma Interaction
Jun 02, 2022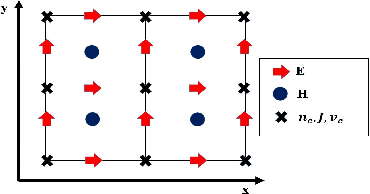
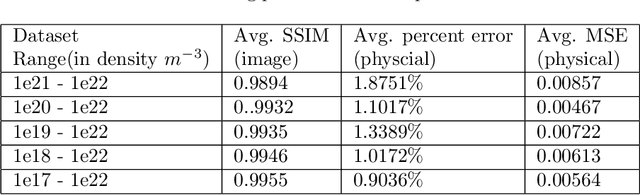
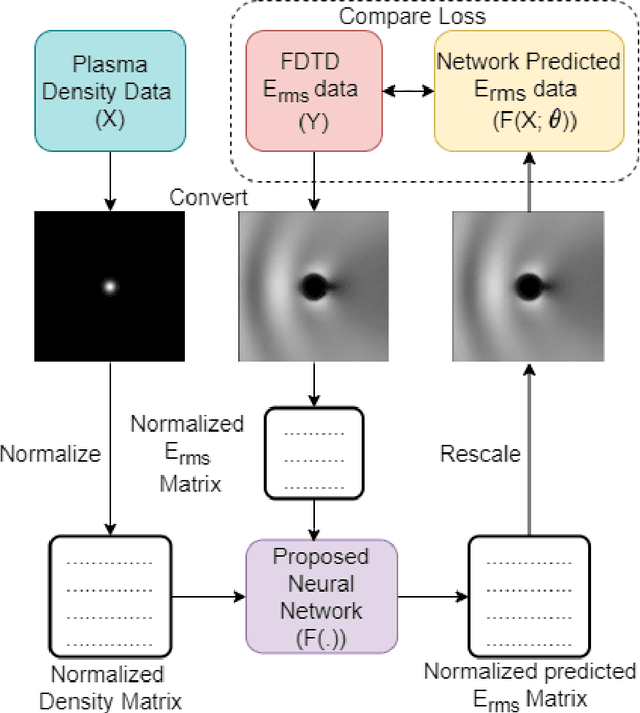
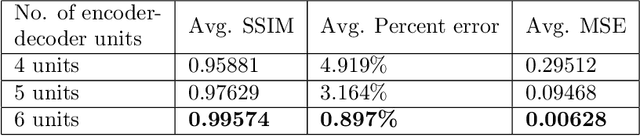
This paper presents a convolutional neural network (CNN)-based deep learning model, inspired from UNet with series of encoder and decoder units with skip connections, for the simulation of microwave-plasma interaction. The microwave propagation characteristics in complex plasma medium pertaining to transmission, absorption and reflection primarily depends on the ratio of electromagnetic (EM) wave frequency and electron plasma frequency, and the plasma density profile. The scattering of a plane EM wave with fixed frequency (1 GHz) and amplitude incident on a plasma medium with different gaussian density profiles (in the range of $1\times 10^{17}-1\times 10^{22}{m^{-3}}$) have been considered. The training data associated with microwave-plasma interaction has been generated using 2D-FDTD (Finite Difference Time Domain) based simulations. The trained deep learning model is then used to reproduce the scattered electric field values for the 1GHz incident microwave on different plasma profiles with error margin of less than 2\%. We propose a complete deep learning (DL) based pipeline to train, validate and evaluate the model. We compare the results of the network, using various metrics like SSIM index, average percent error and mean square error, with the physical data obtained from well-established FDTD based EM solvers. To the best of our knowledge, this is the first effort towards exploring a DL based approach for the simulation of complex microwave plasma interaction. The deep learning technique proposed in this work is significantly fast as compared to the existing computational techniques, and can be used as a new, prospective and alternative computational approach for investigating microwave-plasma interaction in a real time scenario.
Where to Begin? Exploring the Impact of Pre-Training and Initialization in Federated Learning
Jun 30, 2022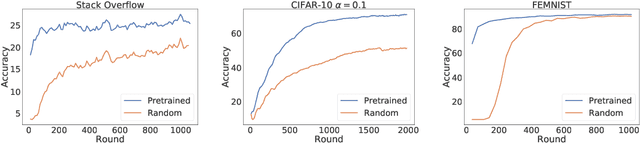



An oft-cited challenge of federated learning is the presence of data heterogeneity -- the data at different clients may follow very different distributions. Several federated optimization methods have been proposed to address these challenges. In the literature, empirical evaluations usually start federated training from a random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task which can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four common federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables training more accurate models (by up to 40\%) than is possible than when starting from a random initialization. Surprisingly, we also find that the effect of data heterogeneity is much less significant when starting federated training from a pre-trained initialization. Rather, when starting from a pre-trained model, using an adaptive optimizer at the server, such as \textsc{FedAdam}, consistently leads to the best accuracy. We recommend that future work proposing and evaluating federated optimization methods consider the performance when starting both random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
Coherent FDA Radar Systems: Joint Design of Transmitting and Receiving Array Weighters
Apr 14, 2022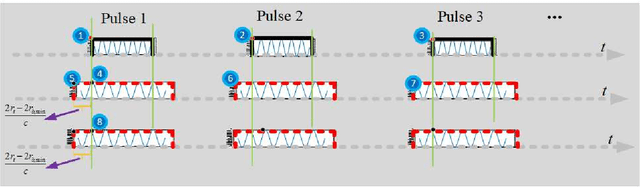

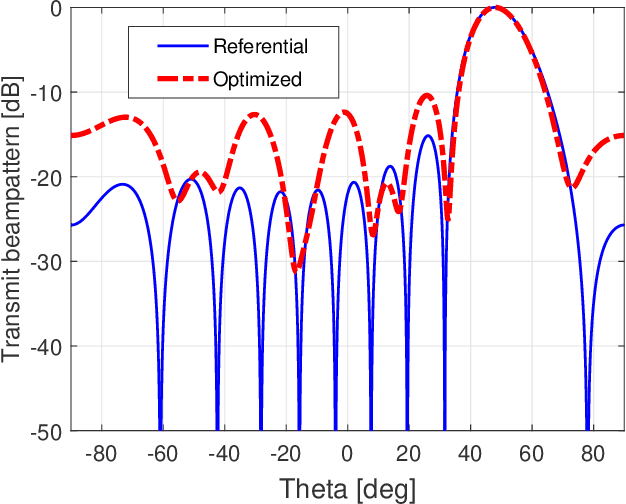
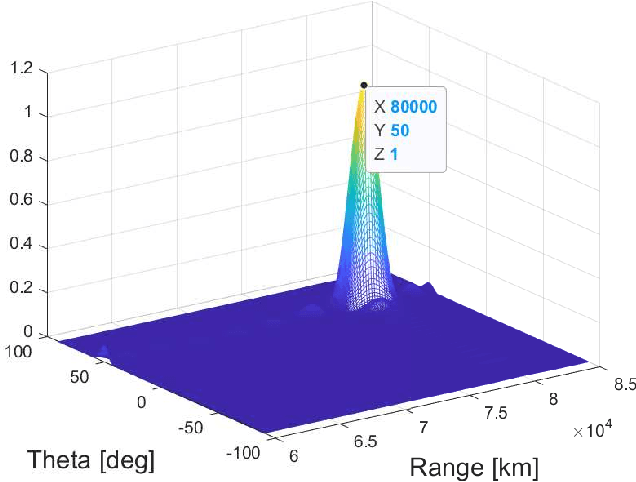
Due to the frequency offset across its array elements, frequency diverse array (FDA) will generate angle-range-dependent and time-variant transmit beampattern. Since existing investigations usually focus on FDA transmitter and only instantaneous beampattern is considered, which cannot fully exploit the time-range characteristics of FDA radar for enhanced performance, in this paper we formulate a multi-carrier mixing receiver for coherent pulsed-Doppler FDA radar to effectively retain the range information of FDA radar returned signals in subsequent receiver processing. Accordingly, the joint transmitter and receiver is systematically modeled with time-range relationship consideration. More importantly, we optimally design the joint transmitting and receiving weighters by maximizing the radiated energy within the desired range-angle sections for given total energy. All proposed methods are verified by simulation results.
Centralized and Decentralized Control in Modular Robots and Their Effect on Morphology
Jun 27, 2022
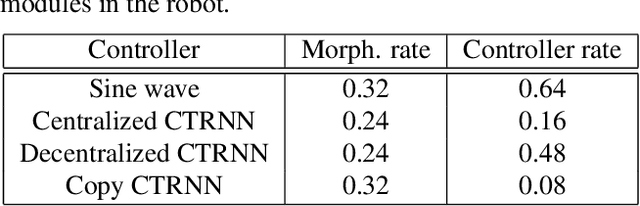

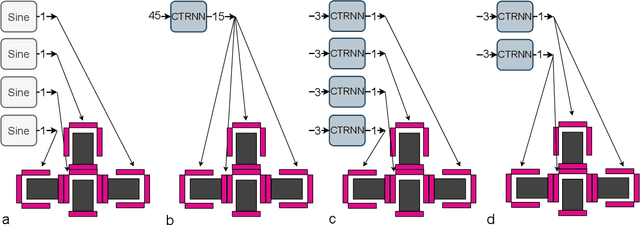
In Evolutionary Robotics, evolutionary algorithms are used to co-optimize morphology and control. However, co-optimizing leads to different challenges: How do you optimize a controller for a body that often changes its number of inputs and outputs? Researchers must then make some choice between centralized or decentralized control. In this article, we study the effects of centralized and decentralized controllers on modular robot performance and morphologies. This is done by implementing one centralized and two decentralized continuous time recurrent neural network controllers, as well as a sine wave controller for a baseline. We found that a decentralized approach that was more independent of morphology size performed significantly better than the other approaches. It also worked well in a larger variety of morphology sizes. In addition, we highlighted the difficulties of implementing centralized control for a changing morphology, and saw that our centralized controller struggled more with early convergence than the other approaches. Our findings indicate that duplicated decentralized networks are beneficial when evolving both the morphology and control of modular robots. Overall, if these findings translate to other robot systems, our results and issues encountered can help future researchers make a choice of control method when co-optimizing morphology and control.
Performance Comparison of Simple Transformer and Res-CNN-BiLSTM for Cyberbullying Classification
Jun 05, 2022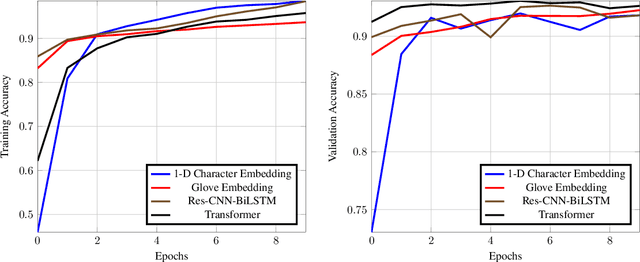
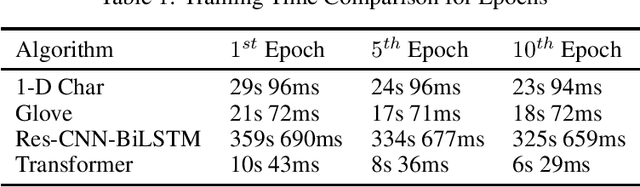
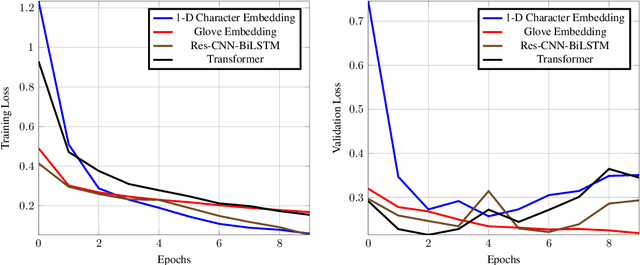
The task of text classification using Bidirectional based LSTM architectures is computationally expensive and time consuming to train. For this, transformers were discovered which effectively give good performance as compared to the traditional deep learning architectures. In this paper we present a performance based comparison between simple transformer based network and Res-CNN-BiLSTM based network for cyberbullying text classification problem. The results obtained show that transformer we trained with 0.65 million parameters has significantly being able to beat the performance of Res-CNN-BiLSTM with 48.82 million parameters for faster training speeds and more generalized metrics. The paper also compares the 1-dimensional character level embedding network and 100-dimensional glove embedding network with transformer.
Posterior Coreset Construction with Kernelized Stein Discrepancy for Model-Based Reinforcement Learning
Jun 02, 2022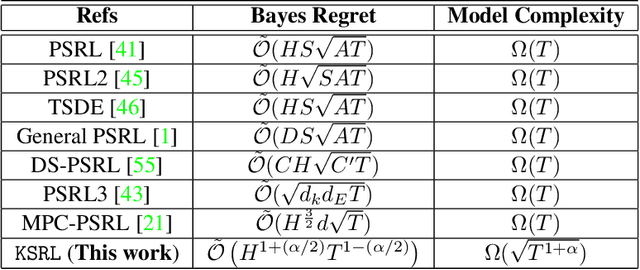
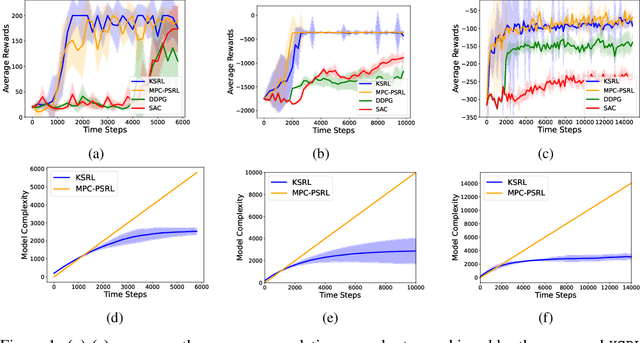
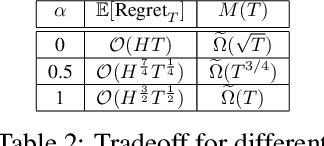
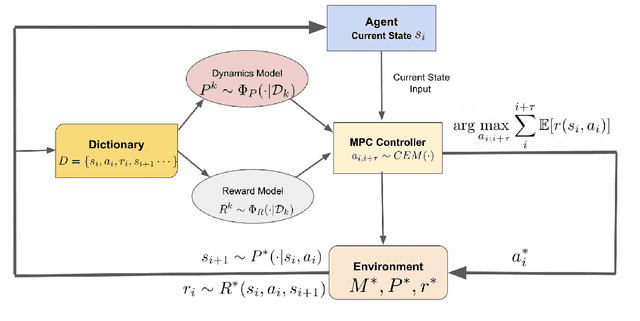
In this work, we propose a novel ${\bf K}$ernelized ${\bf S}$tein Discrepancy-based Posterior Sampling for ${\bf RL}$ algorithm (named $\texttt{KSRL}$) which extends model-based RL based upon posterior sampling (PSRL) in several ways: we (i) relax the need for any smoothness or Gaussian assumptions, allowing for complex mixture models; (ii) ensure it is applicable to large-scale training by incorporating a compression step such that the posterior consists of a \emph{Bayesian coreset} of only statistically significant past state-action pairs; and (iii) develop a novel regret analysis of PSRL based upon integral probability metrics, which, under a smoothness condition on the constructed posterior, can be evaluated in closed form as the kernelized Stein discrepancy (KSD). Consequently, we are able to improve the $\mathcal{O}(H^{3/2}d\sqrt{T})$ {regret} of PSRL to $\mathcal{O}(H^{3/2}\sqrt{T})$, where $d$ is the input dimension, $H$ is the episode length, and $T$ is the total number of episodes experienced, alleviating a linear dependence on $d$ . Moreover, we theoretically establish a trade-off between regret rate with posterior representational complexity via introducing a compression budget parameter $\epsilon$ based on KSD, and establish a lower bound on the required complexity for consistency of the model. Experimentally, we observe that this approach is competitive with several state of the art RL methodologies, with substantive improvements in computation time. Experimentally, we observe that this approach is competitive with several state of the art RL methodologies, and can achieve up-to $50\%$ reduction in wall clock time in some continuous control environments.
Deep Video Prediction for Time Series Forecasting
Feb 24, 2021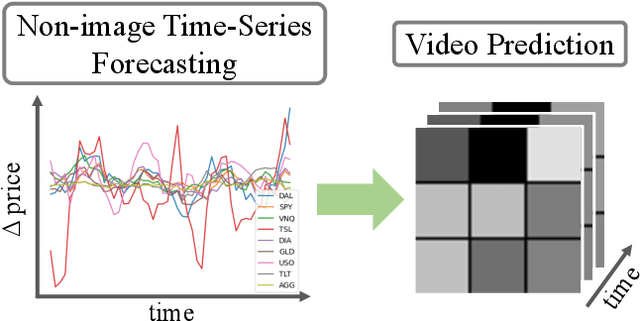


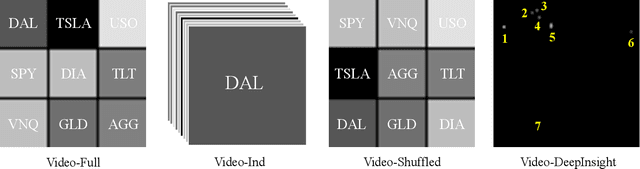
Time series forecasting is essential for decision making in many domains. In this work, we address the challenge of predicting prices evolution among multiple potentially interacting financial assets. A solution to this problem has obvious importance for governments, banks, and investors. Statistical methods such as Auto Regressive Integrated Moving Average (ARIMA) are widely applied to these problems. In this paper, we propose to approach economic time series forecasting of multiple financial assets in a novel way via video prediction. Given past prices of multiple potentially interacting financial assets, we aim to predict the prices evolution in the future. Instead of treating the snapshot of prices at each time point as a vector, we spatially layout these prices in 2D as an image, such that we can harness the power of CNNs in learning a latent representation for these financial assets. Thus, the history of these prices becomes a sequence of images, and our goal becomes predicting future images. We build on a state-of-the-art video prediction method for forecasting future images. Our experiments involve the prediction task of the price evolution of nine financial assets traded in U.S. stock markets. The proposed method outperforms baselines including ARIMA, Prophet, and variations of the proposed method, demonstrating the benefits of harnessing the power of CNNs in the problem of economic time series forecasting.
Accurate and fast identification of minimally prepared bacteria phenotypes using Raman spectroscopy assisted by machine learning
Jun 27, 2022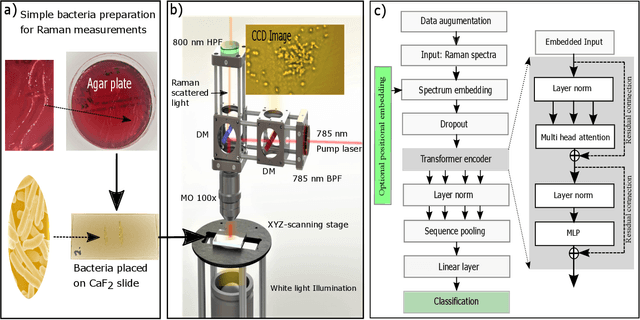
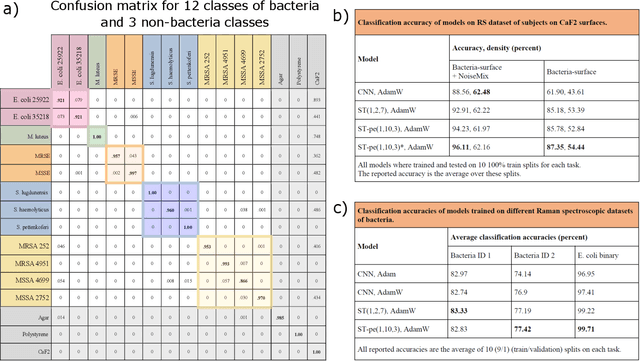
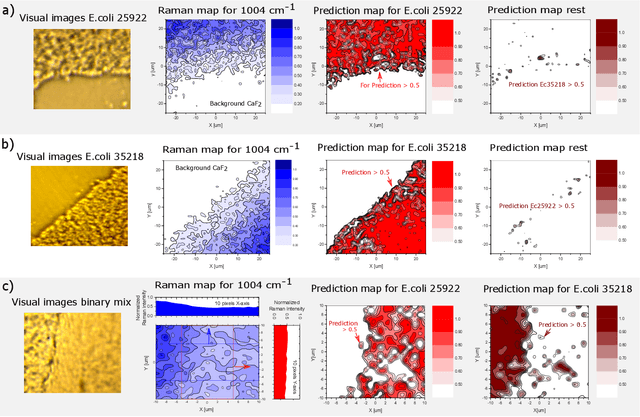
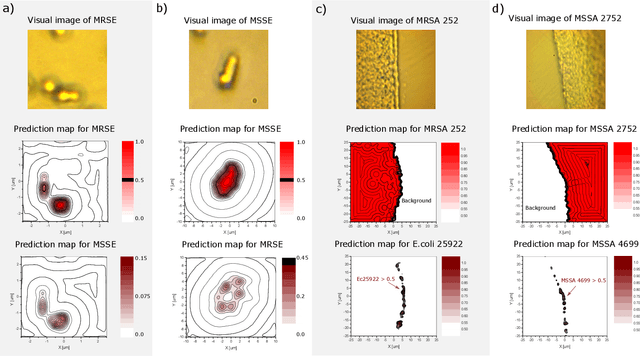
The worldwide increase of antimicrobial resistance (AMR) is a serious threat to human health. To avert the spread of AMR, fast reliable diagnostics tools that facilitate optimal antibiotic stewardship are an unmet need. In this regard, Raman spectroscopy promises rapid label- and culture-free identification and antimicrobial susceptibility testing (AST) in a single step. However, even though many Raman-based bacteria-identification and AST studies have demonstrated impressive results, some shortcomings must be addressed. To bridge the gap between proof-of-concept studies and clinical application, we have developed machine learning techniques in combination with a novel data-augmentation algorithm, for fast identification of minimally prepared bacteria phenotypes and the distinctions of methicillin-resistant (MR) from methicillin-susceptible (MS) bacteria. For this we have implemented a spectral transformer model for hyper-spectral Raman images of bacteria. We show that our model outperforms the standard convolutional neural network models on a multitude of classification problems, both in terms of accuracy and in terms of training time. We attain more than 96$\%$ classification accuracy on a dataset consisting of 15 different classes and 95.6$\%$ classification accuracy for six MR-MS bacteria species. More importantly, our results are obtained using only fast and easy-to-produce training and test data