 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Maximum Linear Arrangement Problem for trees under projectivity and planarity
Jun 16, 2022
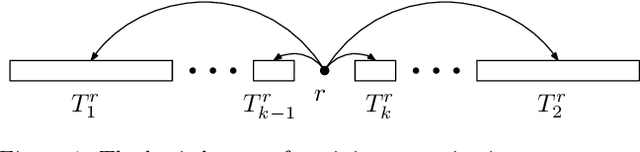
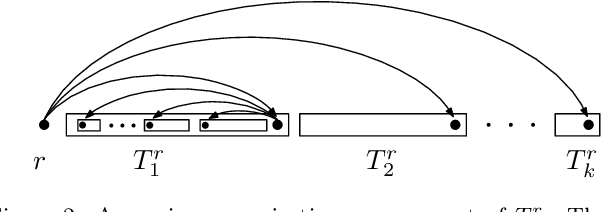
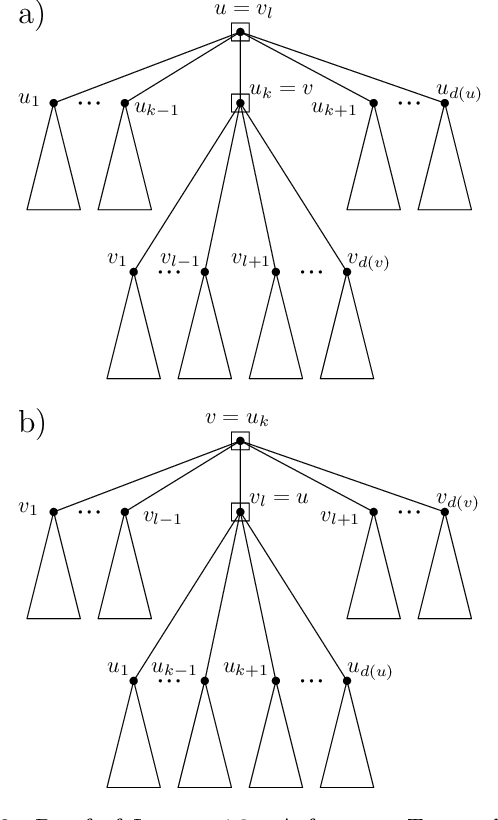
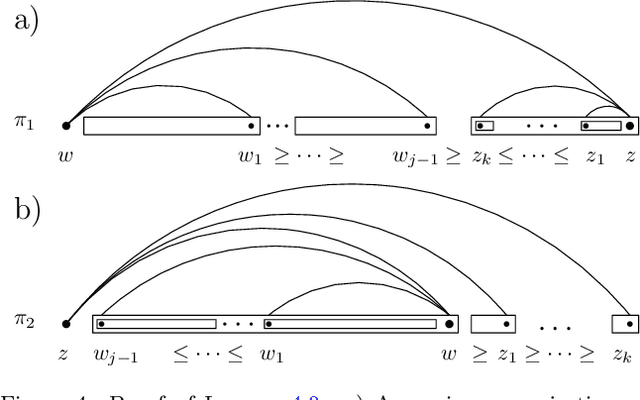
The Maximum Linear Arrangement problem (MaxLA) consists of finding a mapping $\pi$ from the $n$ vertices of a graph $G$ to distinct consecutive integers that maximizes $D_{\pi}(G)=\sum_{uv\in E(G)}|\pi(u) - \pi(v)|$. In this setting, vertices are considered to lie on a horizontal line and edges are drawn as semicircles above the line. There exist variants of MaxLA in which the arrangements are constrained. In the planar variant edge crossings are forbidden. In the projective variant for rooted trees arrangements are planar and the root cannot be covered by any edge. Here we present $O(n)$-time and $O(n)$-space algorithms that solve Planar and Projective MaxLA for trees. We also prove several properties of maximum projective and planar arrangements.
Adapting to Online Label Shift with Provable Guarantees
Jul 05, 2022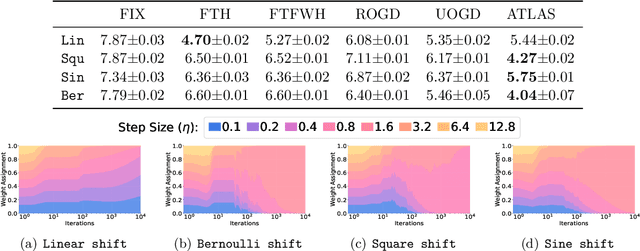
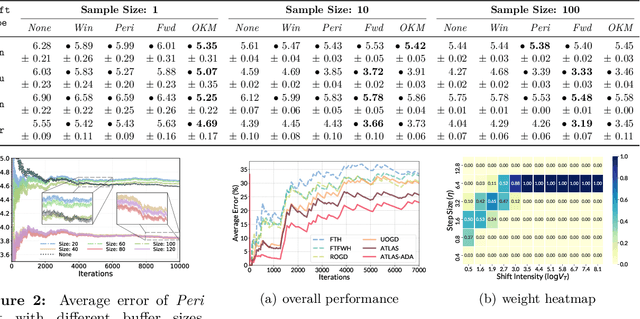
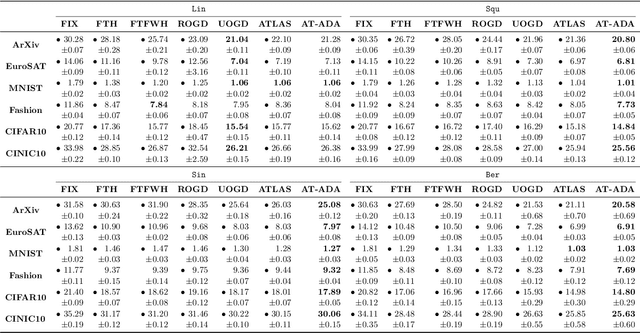
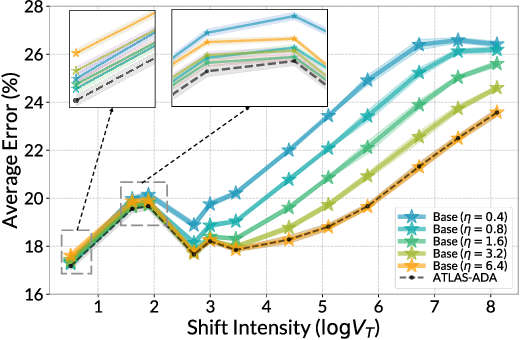
The standard supervised learning paradigm works effectively when training data shares the same distribution as the upcoming testing samples. However, this assumption is often violated in real-world applications, especially when testing data appear in an online fashion. In this paper, we formulate and investigate the problem of online label shift (OLaS): the learner trains an initial model from the labeled offline data and then deploys it to an unlabeled online environment where the underlying label distribution changes over time but the label-conditional density does not. The non-stationarity nature and the lack of supervision make the problem challenging to be tackled. To address the difficulty, we construct a new unbiased risk estimator that utilizes the unlabeled data, which exhibits many benign properties albeit with potential non-convexity. Building upon that, we propose novel online ensemble algorithms to deal with the non-stationarity of the environments. Our approach enjoys optimal dynamic regret, indicating that the performance is competitive with a clairvoyant who knows the online environments in hindsight and then chooses the best decision for each round. The obtained dynamic regret bound scales with the intensity and pattern of label distribution shift, hence exhibiting the adaptivity in the OLaS problem. Extensive experiments are conducted to validate the effectiveness and support our theoretical findings.
Precise Change Point Detection using Spectral Drift Detection
May 13, 2022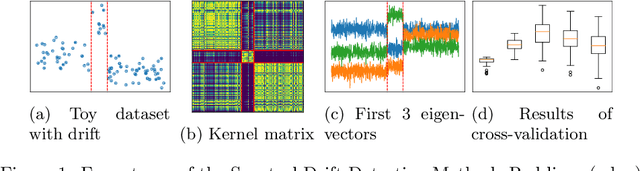
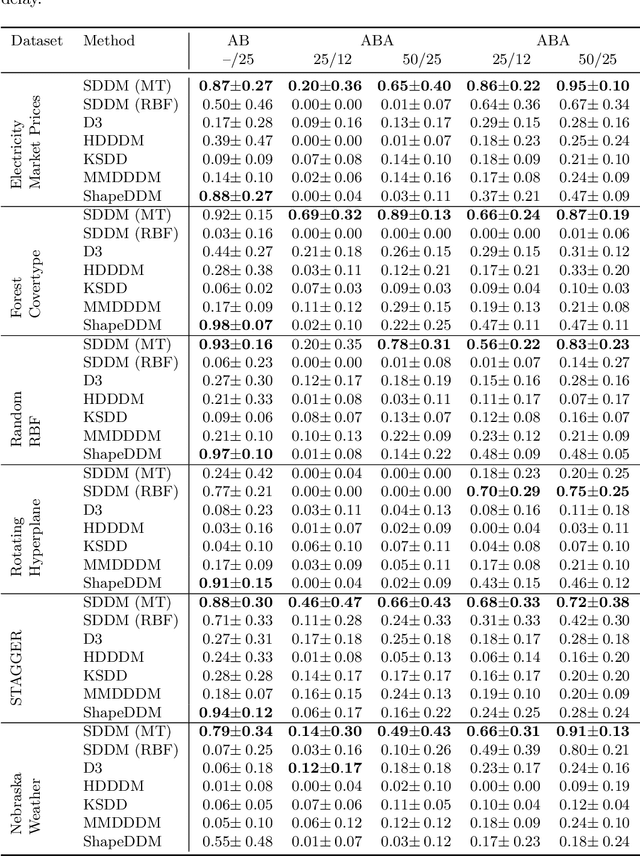
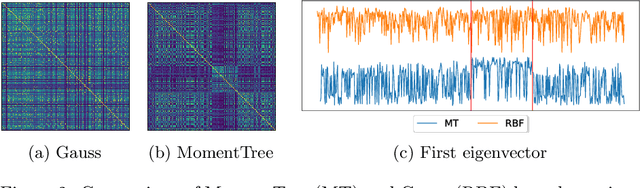
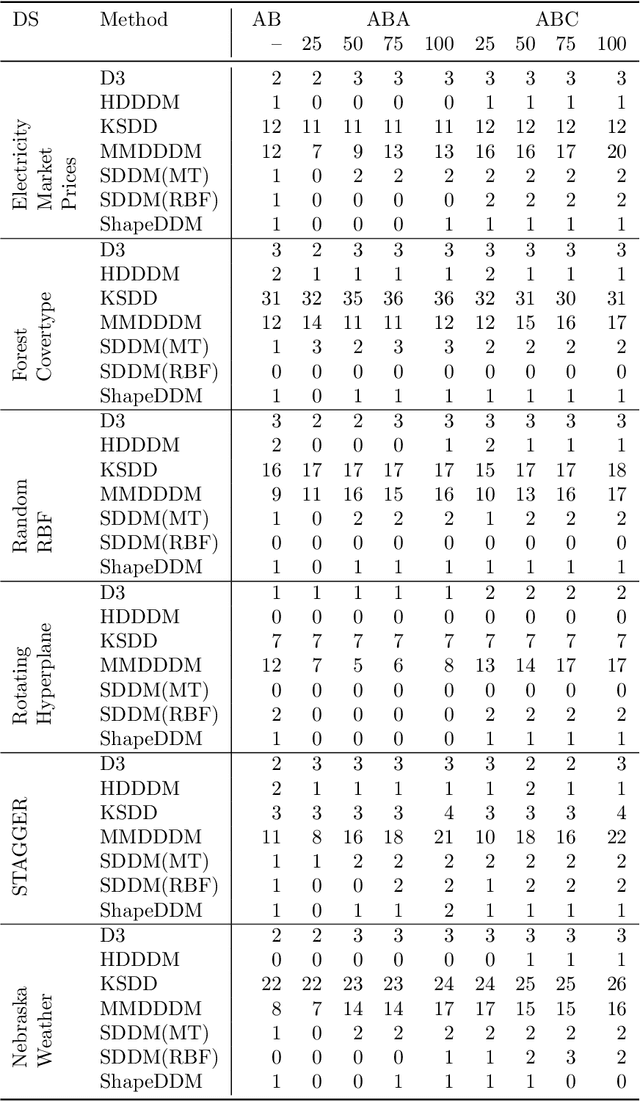
The notion of concept drift refers to the phenomenon that the data generating distribution changes over time; as a consequence machine learning models may become inaccurate and need adjustment. In this paper we consider the problem of detecting those change points in unsupervised learning. Many unsupervised approaches rely on the discrepancy between the sample distributions of two time windows. This procedure is noisy for small windows, hence prone to induce false positives and not able to deal with more than one drift event in a window. In this paper we rely on structural properties of drift induced signals, which use spectral properties of kernel embedding of distributions. Based thereon we derive a new unsupervised drift detection algorithm, investigate its mathematical properties, and demonstrate its usefulness in several experiments.
Long-Tail Prediction Uncertainty Aware Trajectory Planning for Self-driving Vehicles
Jul 02, 2022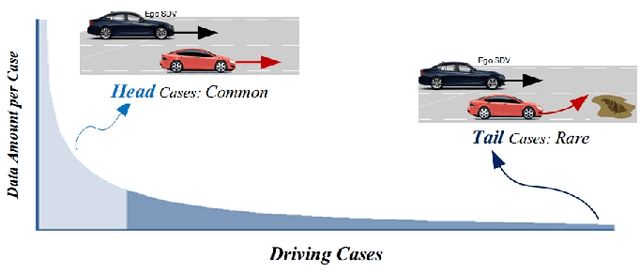
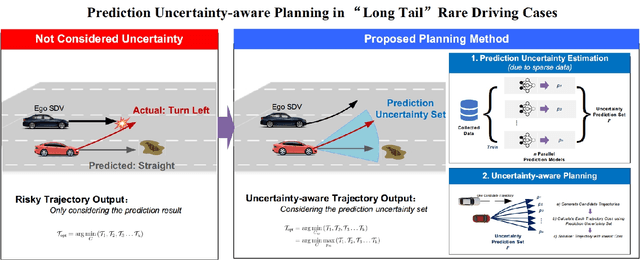
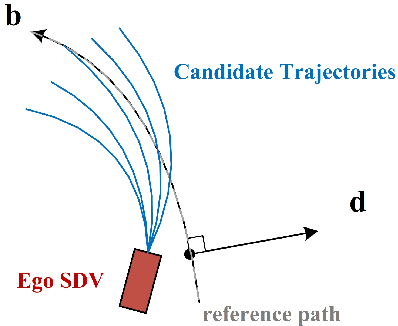
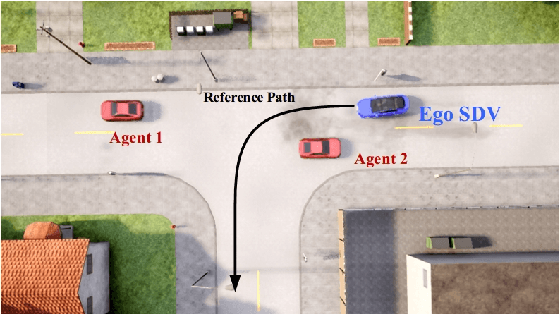
A typical trajectory planner of autonomous driving usually relies on predicting the future behavior of surrounding obstacles. In recent years, prediction models based on deep learning have been widely used due to their impressive performance. However, recent studies have shown that deep learning models trained on a dataset following a long-tailed driving scenario distribution will suffer from large prediction errors in the "tails," which might lead to failures of the planner. To this end, this work defines a notion of prediction model uncertainty to quantify high errors due to sparse data. Moreover, this work proposes a trajectory planner to consider such prediction uncertainty for safer performance. Firstly, the prediction model's uncertainty due to insufficient training data is estimated by an ensemble network structure. Then a trajectory planner is designed to consider the worst-case arising from prediction uncertainty. The results show that the proposed method can improve the safety of trajectory planning under the prediction uncertainty caused by insufficient data. At the same time, with sufficient data, the framework will not lead to overly conservative results. This technology helps to improve the safety and reliability of autonomous vehicles under the long-tail data distribution of the real world.
CASHformer: Cognition Aware SHape Transformer for Longitudinal Analysis
Jul 05, 2022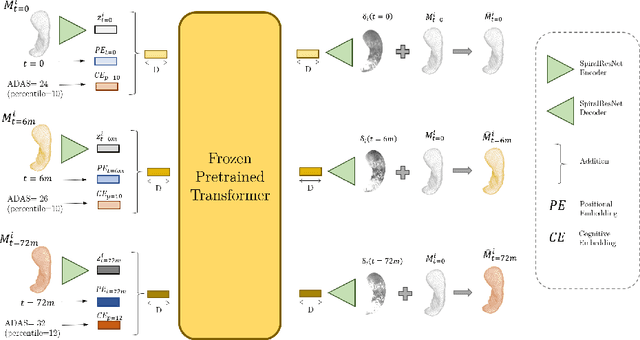
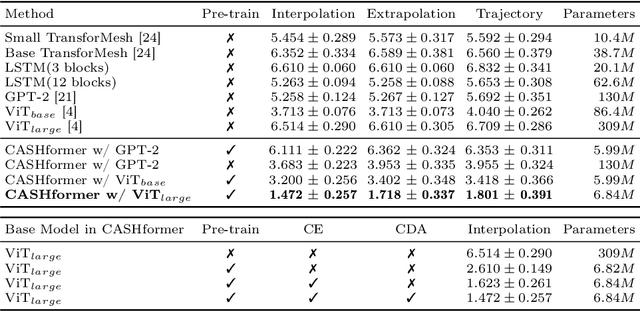
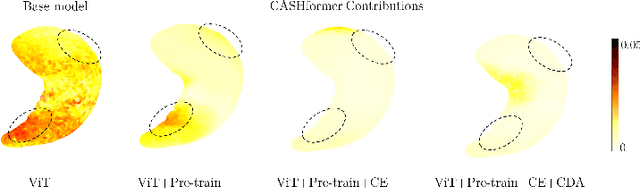
Modeling temporal changes in subcortical structures is crucial for a better understanding of the progression of Alzheimer's disease (AD). Given their flexibility to adapt to heterogeneous sequence lengths, mesh-based transformer architectures have been proposed in the past for predicting hippocampus deformations across time. However, one of the main limitations of transformers is the large amount of trainable parameters, which makes the application on small datasets very challenging. In addition, current methods do not include relevant non-image information that can help to identify AD-related patterns in the progression. To this end, we introduce CASHformer, a transformer-based framework to model longitudinal shape trajectories in AD. CASHformer incorporates the idea of pre-trained transformers as universal compute engines that generalize across a wide range of tasks by freezing most layers during fine-tuning. This reduces the number of parameters by over 90% with respect to the original model and therefore enables the application of large models on small datasets without overfitting. In addition, CASHformer models cognitive decline to reveal AD atrophy patterns in the temporal sequence. Our results show that CASHformer reduces the reconstruction error by 73% compared to previously proposed methods. Moreover, the accuracy of detecting patients progressing to AD increases by 3% with imputing missing longitudinal shape data.
Learning Cross-Scale Visual Representations for Real-Time Image Geo-Localization
Sep 09, 2021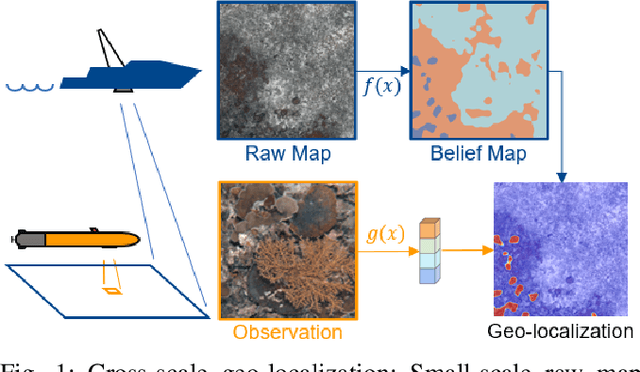
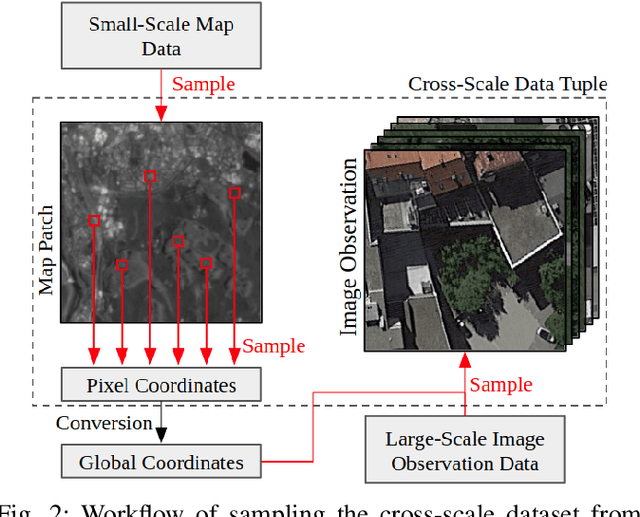
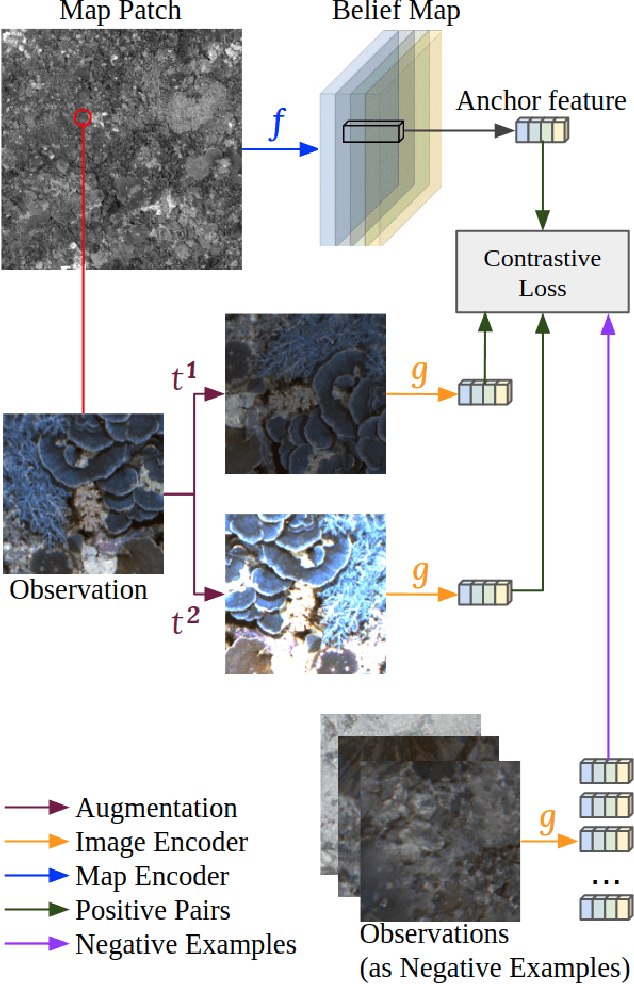

Robot localization remains a challenging task in GPS denied environments. State estimation approaches based on local sensors, e.g. cameras or IMUs, are drifting-prone for long-range missions as error accumulates. In this study, we aim to address this problem by localizing image observations in a 2D multi-modal geospatial map. We introduce the cross-scale dataset and a methodology to produce additional data from cross-modality sources. We propose a framework that learns cross-scale visual representations without supervision. Experiments are conducted on data from two different domains, underwater and aerial. In contrast to existing studies in cross-view image geo-localization, our approach a) performs better on smaller-scale multi-modal maps; b) is more computationally efficient for real-time applications; c) can serve directly in concert with state estimation pipelines.
Parallel Synthesis for Autoregressive Speech Generation
Apr 25, 2022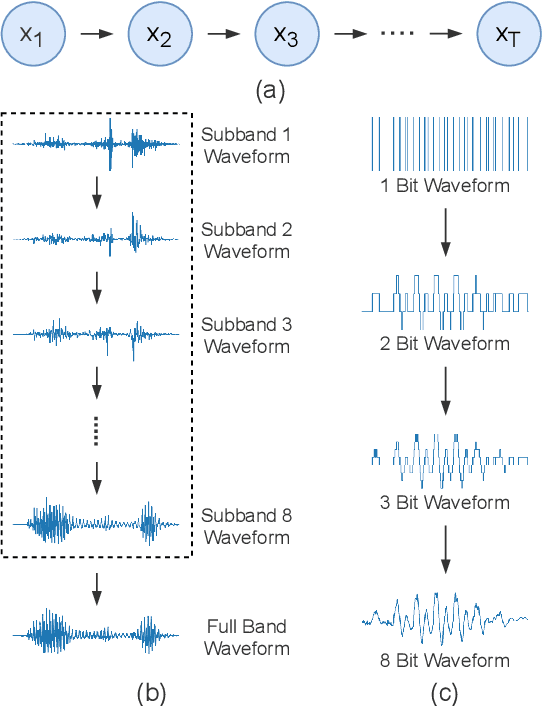
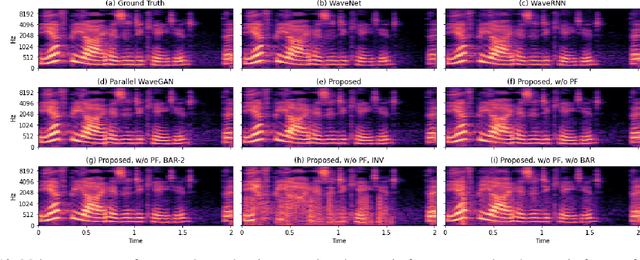
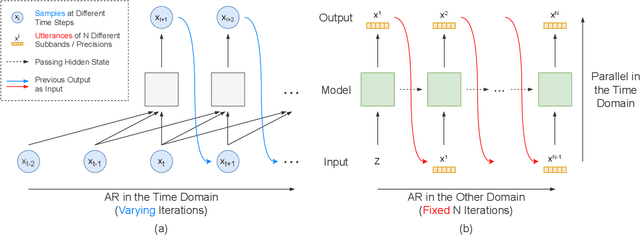
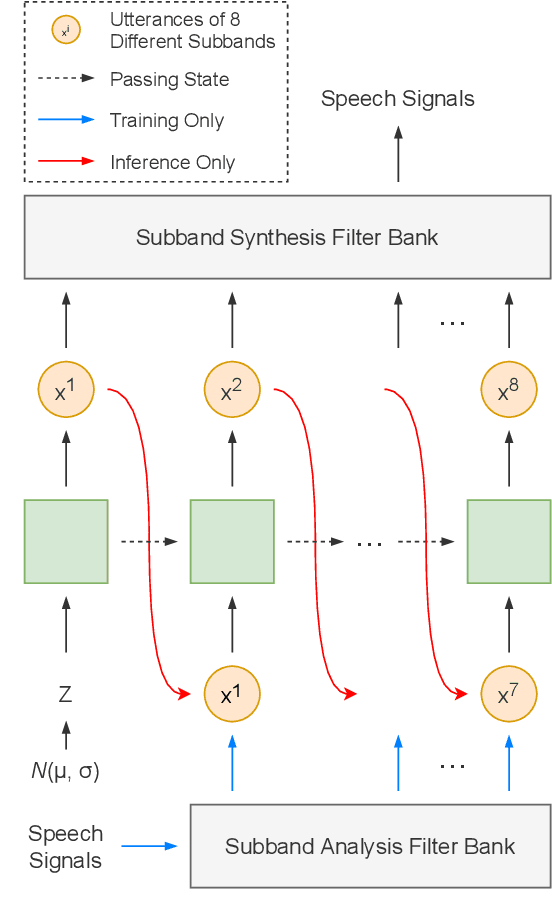
Autoregressive models have achieved outstanding performance in neural speech synthesis tasks. Though they can generate highly natural human speech, the iterative generation inevitably makes the synthesis time proportional to the utterance's length, leading to low efficiency. Many works were dedicated to generating the whole speech time sequence in parallel and then proposed GAN-based, flow-based, and score-based models. This paper proposed a new thought for the autoregressive generation. Instead of iteratively predicting samples in a time sequence, the proposed model performs frequency-wise autoregressive generation (FAR) and bit-wise autoregressive generation (BAR) to synthesize speech. In FAR, a speech utterance is first split into different frequency subbands. The proposed model generates a subband conditioned on the previously generated one. A full band speech can then be reconstructed by using these generated subbands and a synthesis filter bank. Similarly, in BAR, an 8-bit quantized signal is generated iteratively from the first bit. By redesigning the autoregressive method to compute in domains other than the time domain, the number of iterations in the proposed model is no longer proportional to the utterance's length but the number of subbands/bits. The inference efficiency is hence significantly increased. Besides, a post-filter is employed to sample audio signals from output posteriors, and its training objective is designed based on the characteristics of the proposed autoregressive methods. The experimental results show that the proposed model is able to synthesize speech faster than real-time without GPU acceleration. Compared with the baseline autoregressive and non-autoregressive models, the proposed model achieves better MOS and shows its good generalization ability while synthesizing 44 kHz speech or utterances from unseen speakers.
Disentangling private classes through regularization
Jul 05, 2022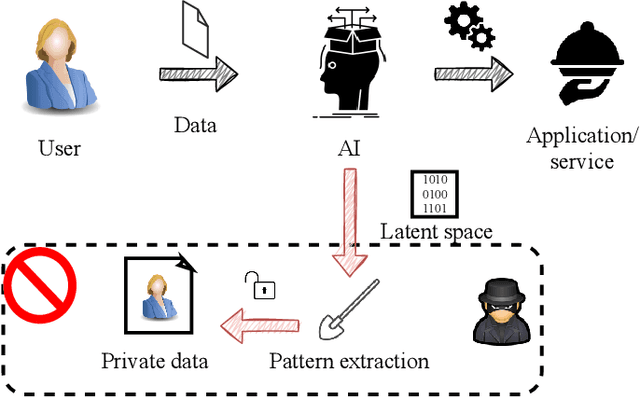
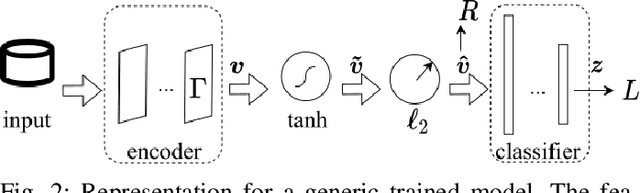
Deep learning models are nowadays broadly deployed to solve an incredibly large variety of tasks. However, little attention has been devoted to connected legal aspects. In 2016, the European Union approved the General Data Protection Regulation which entered into force in 2018. Its main rationale was to protect the privacy and data protection of its citizens by the way of operating of the so-called "Data Economy". As data is the fuel of modern Artificial Intelligence, it is argued that the GDPR can be partly applicable to a series of algorithmic decision making tasks before a more structured AI Regulation enters into force. In the meantime, AI should not allow undesired information leakage deviating from the purpose for which is created. In this work we propose DisP, an approach for deep learning models disentangling the information related to some classes we desire to keep private, from the data processed by AI. In particular, DisP is a regularization strategy de-correlating the features belonging to the same private class at training time, hiding the information of private classes membership. Our experiments on state-of-the-art deep learning models show the effectiveness of DisP, minimizing the risk of extraction for the classes we desire to keep private.
Learning in games from a stochastic approximation viewpoint
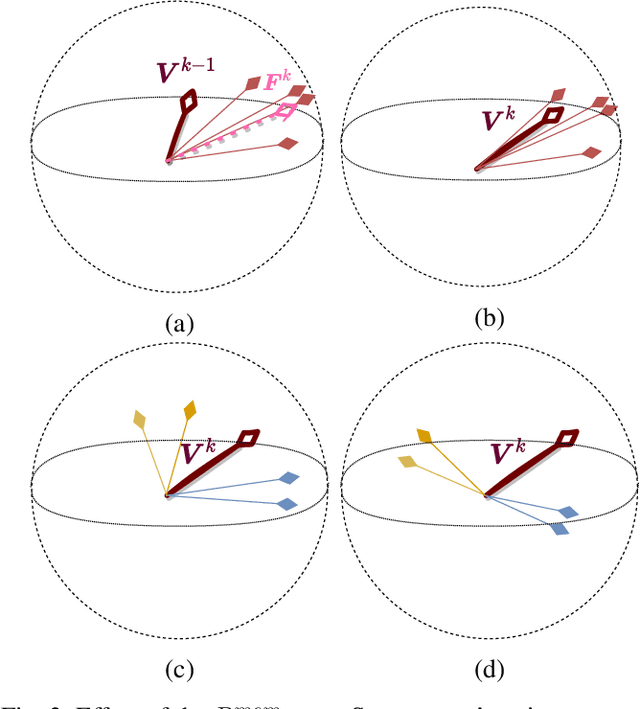
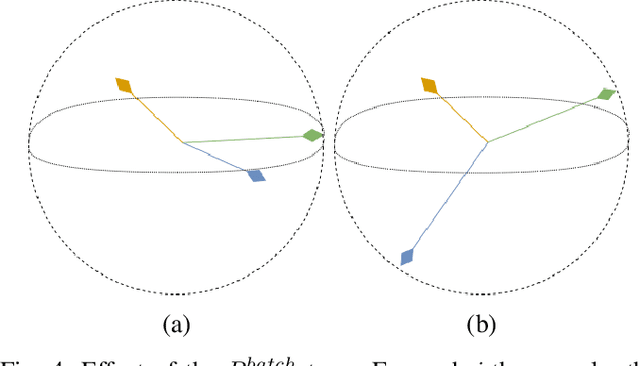
Jun 08, 2022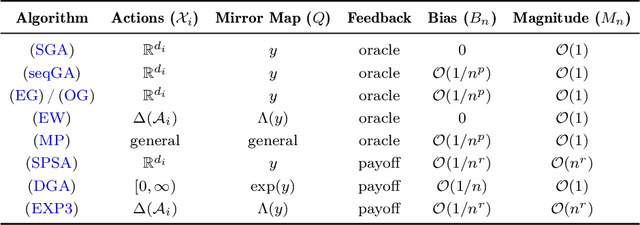
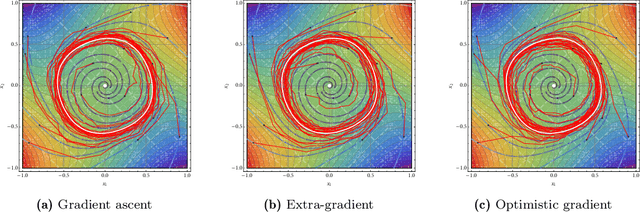
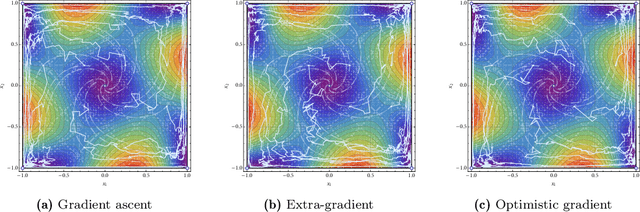
We develop a unified stochastic approximation framework for analyzing the long-run behavior of multi-agent online learning in games. Our framework is based on a "primal-dual", mirrored Robbins-Monro (MRM) template which encompasses a wide array of popular game-theoretic learning algorithms (gradient methods, their optimistic variants, the EXP3 algorithm for learning with payoff-based feedback in finite games, etc.). In addition to providing an integrated view of these algorithms, the proposed MRM blueprint allows us to obtain a broad range of new convergence results, both asymptotic and in finite time, in both continuous and finite games.
Outlier Detection as Instance Selection Method for Feature Selection in Time Series Classification
Nov 16, 2021
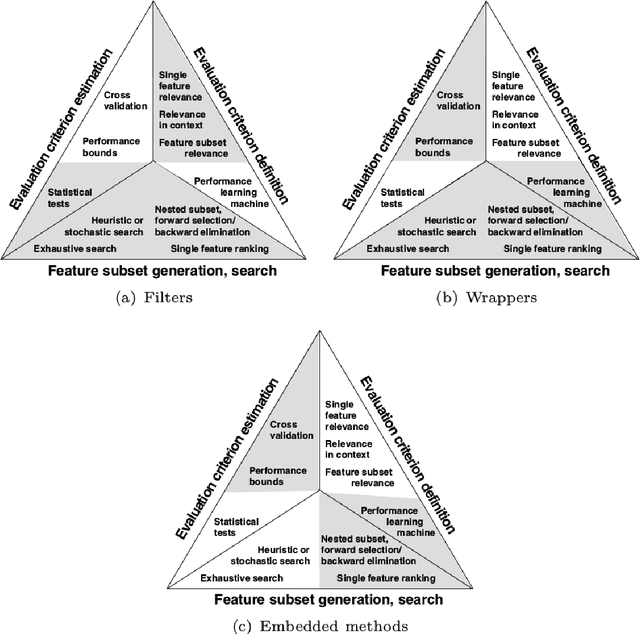
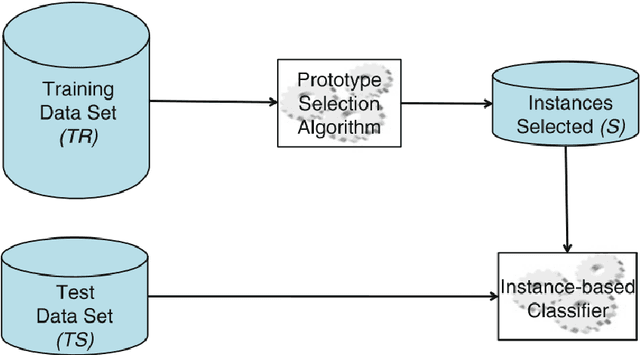
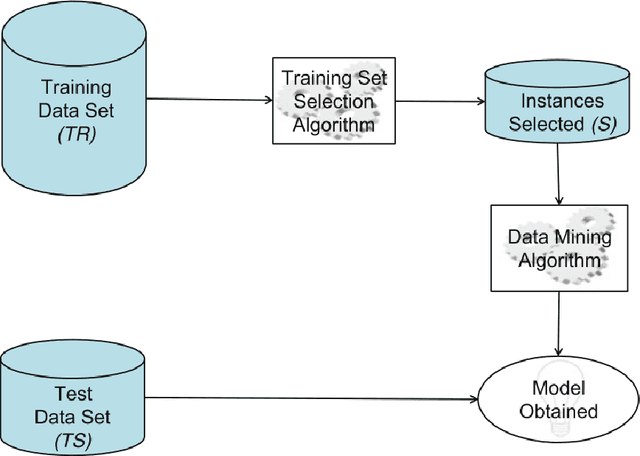
In order to allow machine learning algorithms to extract knowledge from raw data, these data must first be cleaned, transformed, and put into machine-appropriate form. These often very time-consuming phase is referred to as preprocessing. An important step in the preprocessing phase is feature selection, which aims at better performance of prediction models by reducing the amount of features of a data set. Within these datasets, instances of different events are often imbalanced, which means that certain normal events are over-represented while other rare events are very limited. Typically, these rare events are of special interest since they have more discriminative power than normal events. The aim of this work was to filter instances provided to feature selection methods for these rare instances, and thus positively influence the feature selection process. In the course of this work, we were able to show that this filtering has a positive effect on the performance of classification models and that outlier detection methods are suitable for this filtering. For some data sets, the resulting increase in performance was only a few percent, but for other datasets, we were able to achieve increases in performance of up to 16 percent. This work should lead to the improvement of the predictive models and the better interpretability of feature selection in the course of the preprocessing phase. In the spirit of open science and to increase transparency within our research field, we have made all our source code and the results of our experiments available in a publicly available repository.