 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FELARE: Fair Scheduling of Machine Learning Applications on Heterogeneous Edge Systems
May 31, 2022
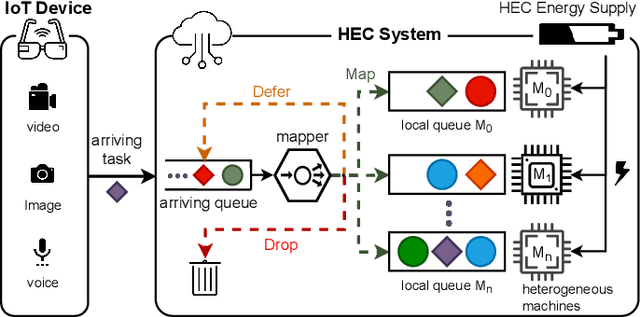
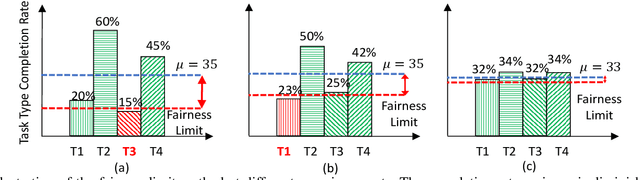
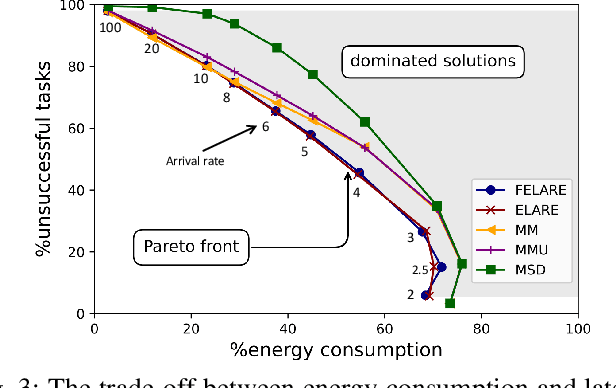
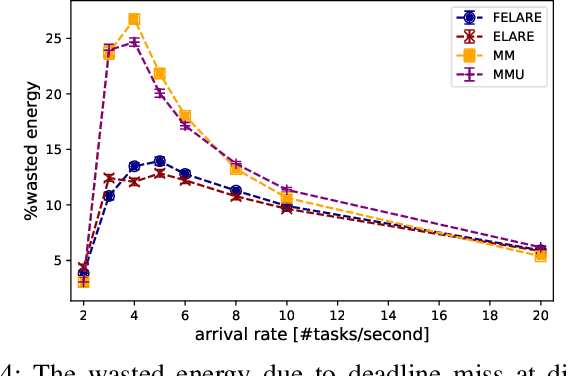
Edge computing enables smart IoT-based systems via concurrent and continuous execution of latency-sensitive machine learning (ML) applications. These edge-based machine learning systems are often battery-powered (i.e., energy-limited). They use heterogeneous resources with diverse computing performance (e.g., CPU, GPU, and/or FPGAs) to fulfill the latency constraints of ML applications. The challenge is to allocate user requests for different ML applications on the Heterogeneous Edge Computing Systems (HEC) with respect to both the energy and latency constraints of these systems. To this end, we study and analyze resource allocation solutions that can increase the on-time task completion rate while considering the energy constraint. Importantly, we investigate edge-friendly (lightweight) multi-objective mapping heuristics that do not become biased toward a particular application type to achieve the objectives; instead, the heuristics consider "fairness" across the concurrent ML applications in their mapping decisions. Performance evaluations demonstrate that the proposed heuristic outperforms widely-used heuristics in heterogeneous systems in terms of the latency and energy objectives, particularly, at low to moderate request arrival rates. We observed 8.9% improvement in on-time task completion rate and 12.6% in energy-saving without imposing any significant overhead on the edge system.
Enhancing Adversarial Robustness via Test-time Transformation Ensembling
Jul 29, 2021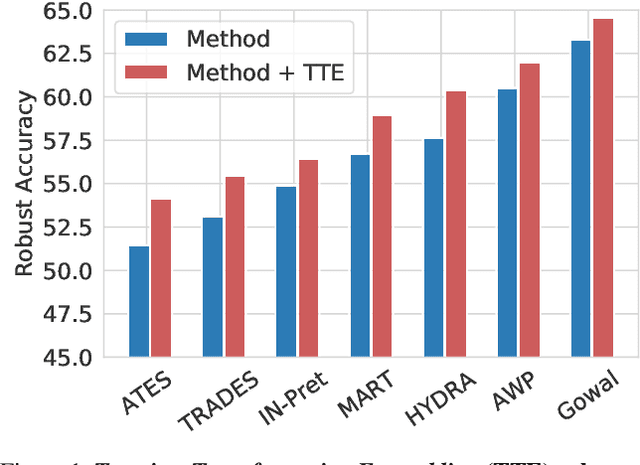
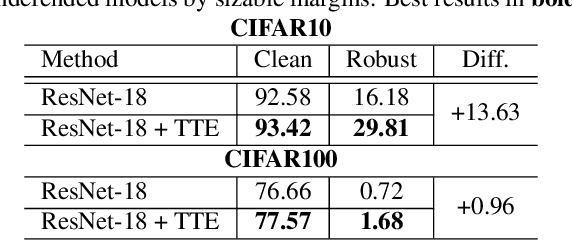
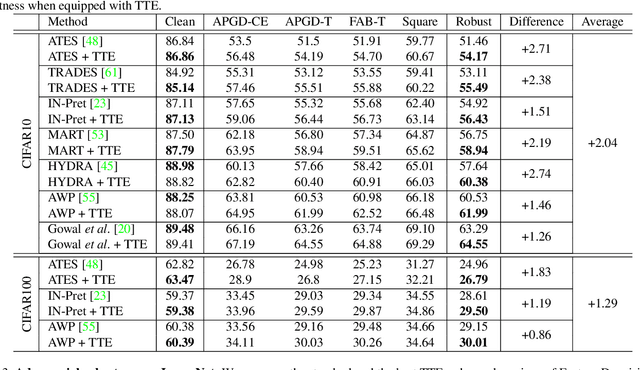
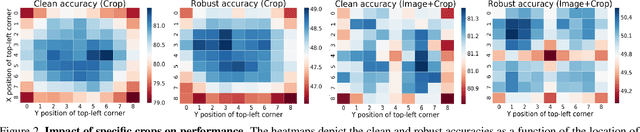
Deep learning models are prone to being fooled by imperceptible perturbations known as adversarial attacks. In this work, we study how equipping models with Test-time Transformation Ensembling (TTE) can work as a reliable defense against such attacks. While transforming the input data, both at train and test times, is known to enhance model performance, its effects on adversarial robustness have not been studied. Here, we present a comprehensive empirical study of the impact of TTE, in the form of widely-used image transforms, on adversarial robustness. We show that TTE consistently improves model robustness against a variety of powerful attacks without any need for re-training, and that this improvement comes at virtually no trade-off with accuracy on clean samples. Finally, we show that the benefits of TTE transfer even to the certified robustness domain, in which TTE provides sizable and consistent improvements.
Guardian Angel: A Novel Walking Aid for the Visually Impaired
Jun 20, 2022
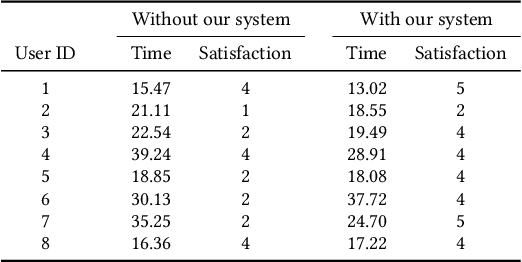
This work introduces Guardian Angel, an Android App that assists visually impaired people to avoid danger in complex traffic environment. The system, consisting of object detection by pretrained YOLO model, distance estimation and moving direction estimation, provides information about surrounding vehicles and alarms users of potential danger without expensive special purpose device. With an experiment of 8 subjects, we corroborate that in terms of satisfaction score in pedestrian-crossing experiment with the assistance of our App using a smartphone is better than when without under 99% confidence level. The time needed to cross a road is shorter on average with the assistance of our system, however, not reaching significant difference by our experiment. The App has been released in Google Play Store, open to the public for free.
Prosody Cloning in Zero-Shot Multispeaker Text-to-Speech
Jun 24, 2022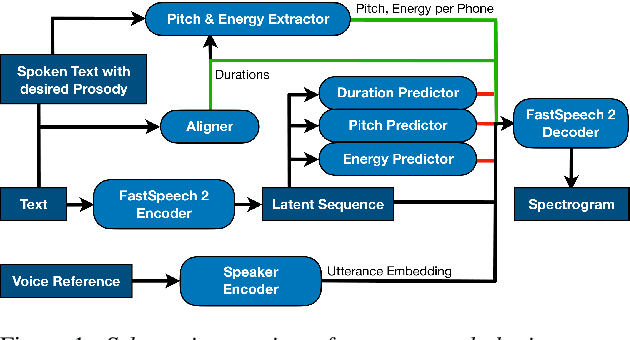
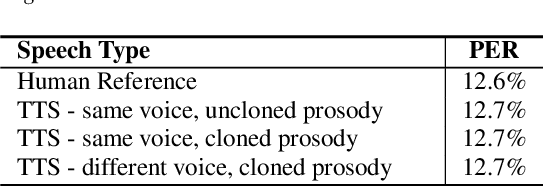

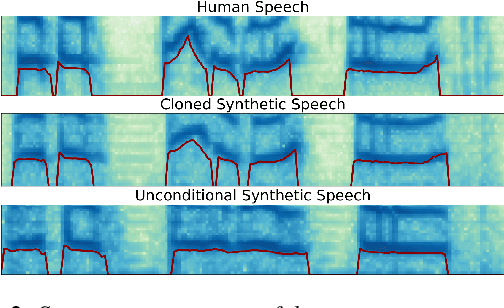
The cloning of a speaker's voice using an untranscribed reference sample is one of the great advances of modern neural text-to-speech (TTS) methods. Approaches for mimicking the prosody of a transcribed reference audio have also been proposed recently. In this work, we bring these two tasks together for the first time through utterance level normalization in conjunction with an utterance level speaker embedding. We further introduce a lightweight aligner for extracting fine-grained prosodic features, that can be finetuned on individual samples within seconds. We show that it is possible to clone the voice of a speaker as well as the prosody of a spoken reference independently without any degradation in quality and high similarity to both original voice and prosody, as our objective evaluation and human study show. All of our code and trained models are available, alongside static and interactive demos.
Semi-Supervised Cross-Silo Advertising with Partial Knowledge Transfer
May 31, 2022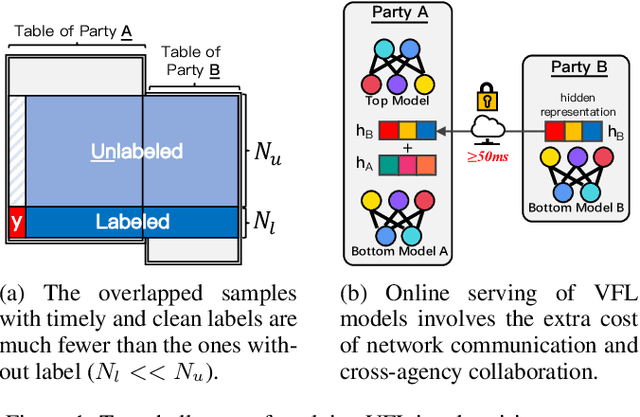
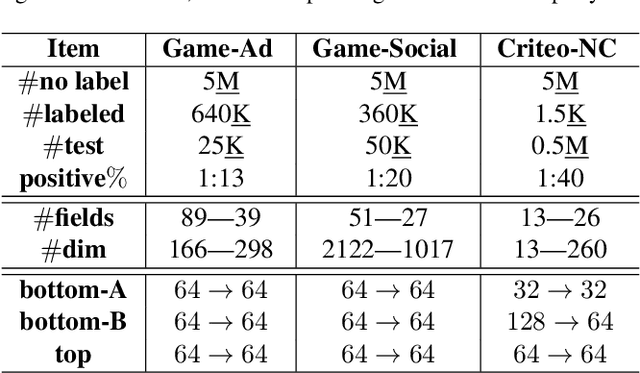
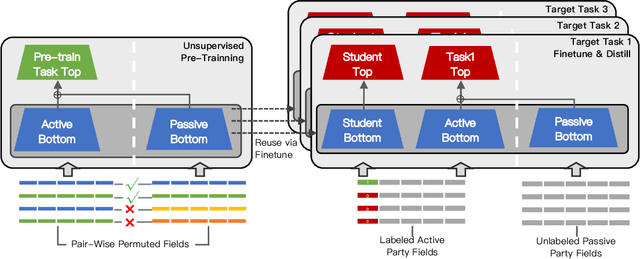
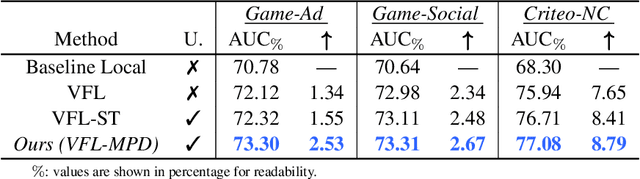
As an emerging secure learning paradigm in leveraging cross-agency private data, vertical federated learning (VFL) is expected to improve advertising models by enabling the joint learning of complementary user attributes privately owned by the advertiser and the publisher. However, there are two key challenges in applying it to advertising systems: a) the limited scale of labeled overlapping samples, and b) the high cost of real-time cross-agency serving. In this paper, we propose a semi-supervised split distillation framework VFed-SSD to alleviate the two limitations. We identify that: i) there are massive unlabeled overlapped data available in advertising systems, and ii) we can keep a balance between model performance and inference cost by decomposing the federated model. Specifically, we develop a self-supervised task Matched Pair Detection (MPD) to exploit the vertically partitioned unlabeled data and propose the Split Knowledge Distillation (SplitKD) schema to avoid cross-agency serving. Empirical studies on three industrial datasets exhibit the effectiveness of our methods, with the median AUC over all datasets improved by 0.86% and 2.6% in the local deployment mode and the federated deployment mode respectively. Overall, our framework provides an efficient federation-enhanced solution for real-time display advertising with minimal deploying cost and significant performance lift.
A prediction perspective on the Wiener-Hopf equations for discrete time series
Jul 11, 2021The Wiener-Hopf equations are a Toeplitz system of linear equations that have several applications in time series. These include the update and prediction step of the stationary Kalman filter equations and the prediction of bivariate time series. The Wiener-Hopf technique is the classical tool for solving the equations, and is based on a comparison of coefficients in a Fourier series expansion. The purpose of this note is to revisit the (discrete) Wiener-Hopf equations and obtain an alternative expression for the solution that is more in the spirit of time series analysis. Specifically, we propose a solution to the Wiener-Hopf equations that combines linear prediction with deconvolution. The solution of the Wiener-Hopf equations requires one to obtain the spectral factorization of the underlying spectral density function. For general spectral density functions this is infeasible. Therefore, it is usually assumed that the spectral density is rational, which allows one to obtain a computationally tractable solution. This leads to an approximation error when the underlying spectral density is not a rational function. We use the proposed solution together with Baxter's inequality to derive an error bound for the rational spectral density approximation.
Analog Compressed Sensing for Sparse Frequency Shift Keying Modulation Schemes
May 31, 2022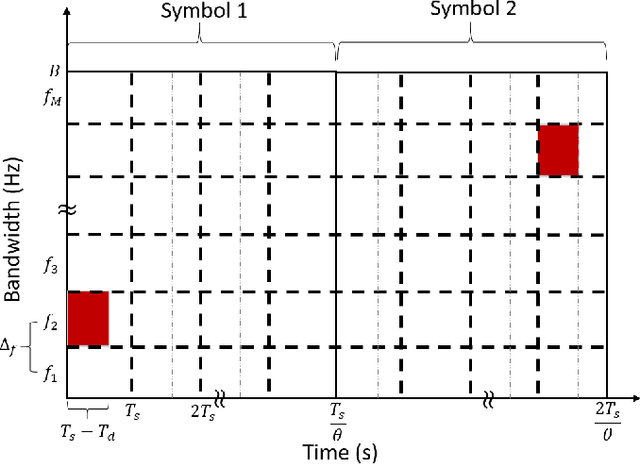
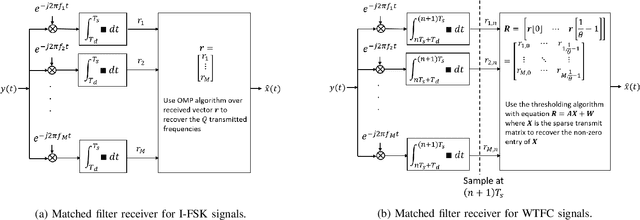
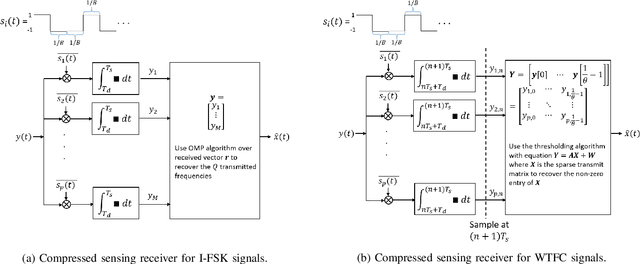
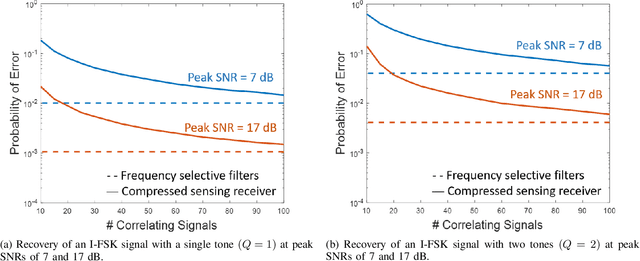
There is a growing interest in signaling schemes that operate in the wideband regime due to the crowded frequency spectrum. However, a downside of the wideband regime is that obtaining channel state information is costly, and the capacity of previously used modulation schemes such as code division multiple access and orthogonal frequency division multiplexing begins to diverge from the capacity bound without channel state information. Impulsive frequency shift keying and wideband time frequency coding have been shown to perform well in the wideband regime without channel state information, thus avoiding the costs and challenges associated with obtaining channel state information. However, the maximum likelihood receiver is a bank of frequency-selective filters, which is very costly to implement due to the large number of filters. In this work, we aim to simplify the receiver by using an analog compressed sensing receiver with chipping sequences as correlating signals to detect the sparse signals. Our results show that using a compressed sensing receiver allows for the simplification of the analog receiver with the trade off of a slight degradation in recovery performance. For a fixed frequency separation, symbol time, and peak SNR, the performance loss remains the same for a fixed ratio of number of correlating signals to the number of frequencies.
Real-time Detection of Practical Universal Adversarial Perturbations
May 22, 2021

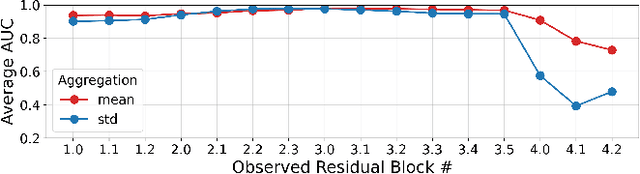
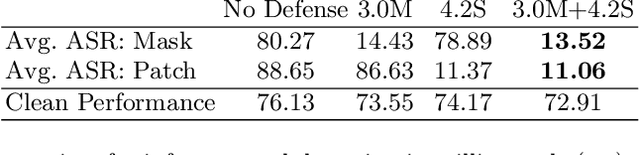
Universal Adversarial Perturbations (UAPs) are a prominent class of adversarial examples that exploit the systemic vulnerabilities and enable physically realizable and robust attacks against Deep Neural Networks (DNNs). UAPs generalize across many different inputs; this leads to realistic and effective attacks that can be applied at scale. In this paper we propose HyperNeuron, an efficient and scalable algorithm that allows for the real-time detection of UAPs by identifying suspicious neuron hyper-activations. Our results show the effectiveness of HyperNeuron on multiple tasks (image classification, object detection), against a wide variety of universal attacks, and in realistic scenarios, like perceptual ad-blocking and adversarial patches. HyperNeuron is able to simultaneously detect both adversarial mask and patch UAPs with comparable or better performance than existing UAP defenses whilst introducing a significantly reduced latency of only 0.86 milliseconds per image. This suggests that many realistic and practical universal attacks can be reliably mitigated in real-time, which shows promise for the robust deployment of machine learning systems.
SphereVLAD++: Attention-based and Signal-enhanced Viewpoint Invariant Descriptor
Jul 06, 2022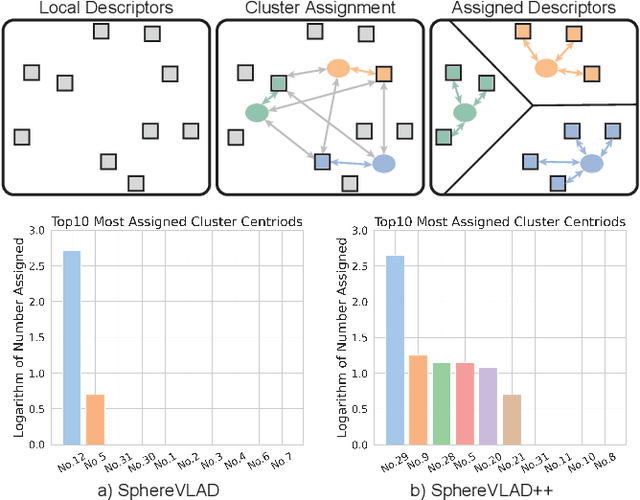
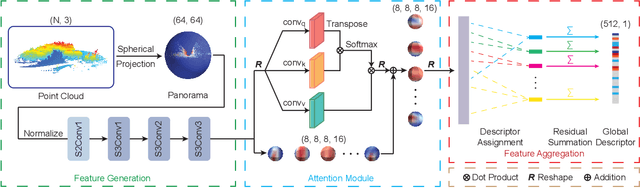
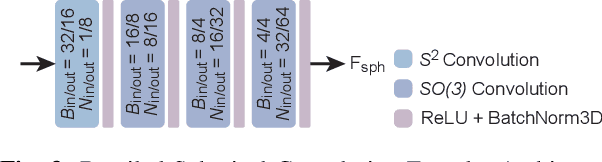
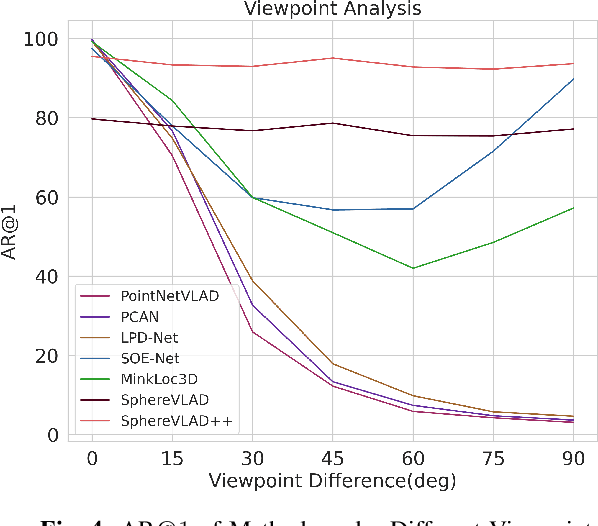
LiDAR-based localization approach is a fundamental module for large-scale navigation tasks, such as last-mile delivery and autonomous driving, and localization robustness highly relies on viewpoints and 3D feature extraction. Our previous work provides a viewpoint-invariant descriptor to deal with viewpoint differences; however, the global descriptor suffers from a low signal-noise ratio in unsupervised clustering, reducing the distinguishable feature extraction ability. We develop SphereVLAD++, an attention-enhanced viewpoint invariant place recognition method in this work. SphereVLAD++ projects the point cloud on the spherical perspective for each unique area and captures the contextual connections between local features and their dependencies with global 3D geometry distribution. In return, clustered elements within the global descriptor are conditioned on local and global geometries and support the original viewpoint-invariant property of SphereVLAD. In the experiments, we evaluated the localization performance of SphereVLAD++ on both public KITTI360 datasets and self-generated datasets from the city of Pittsburgh. The experiment results show that SphereVLAD++ outperforms all relative state-of-the-art 3D place recognition methods under small or even totally reversed viewpoint differences and shows 0.69% and 15.81% successful retrieval rates with better than the second best. Low computation requirements and high time efficiency also help its application for low-cost robots.
NP-Match: When Neural Processes meet Semi-Supervised Learning
Jul 03, 2022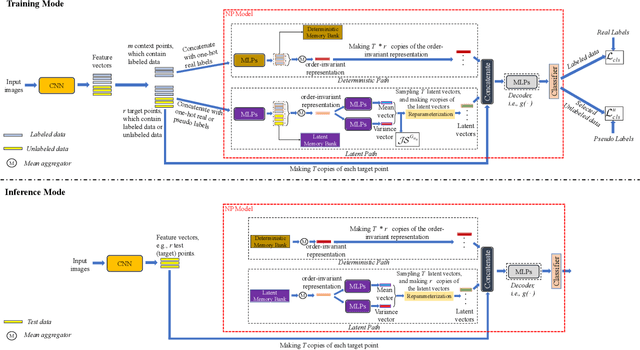
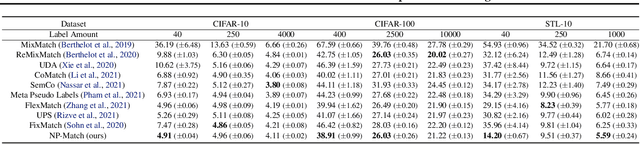
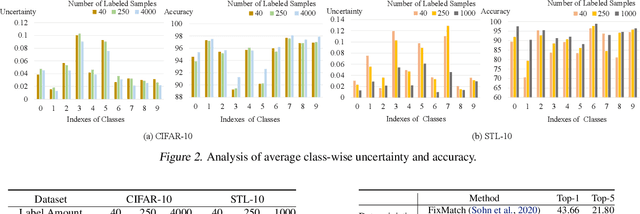
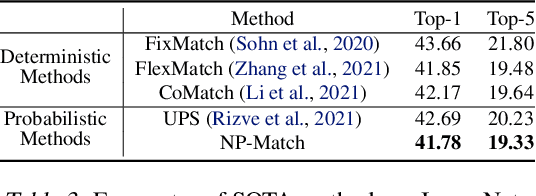
Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on four public datasets, and NP-Match outperforms state-of-the-art (SOTA) results or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL.