 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Elastic Similarity Measures for Multivariate Time Series Classification
Feb 20, 2021
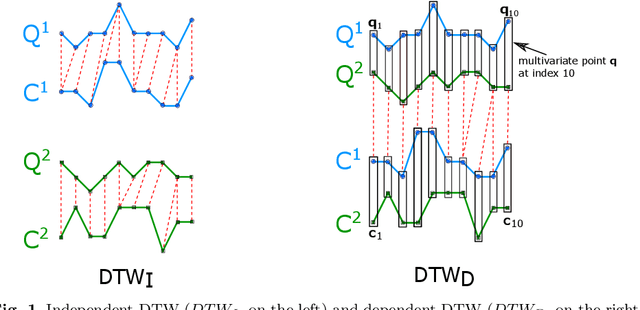
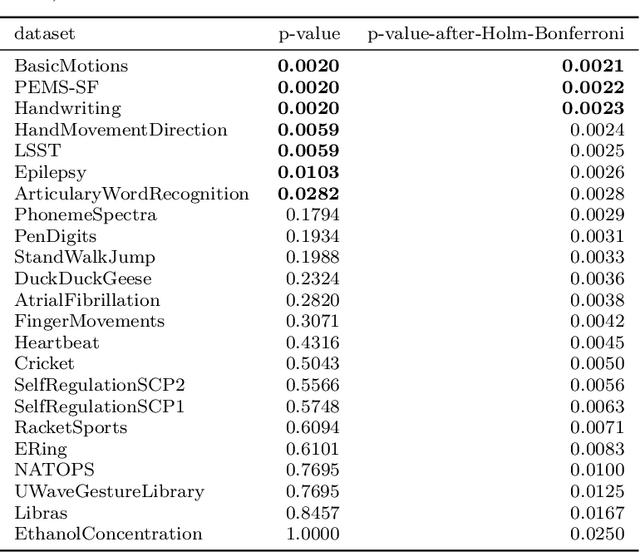

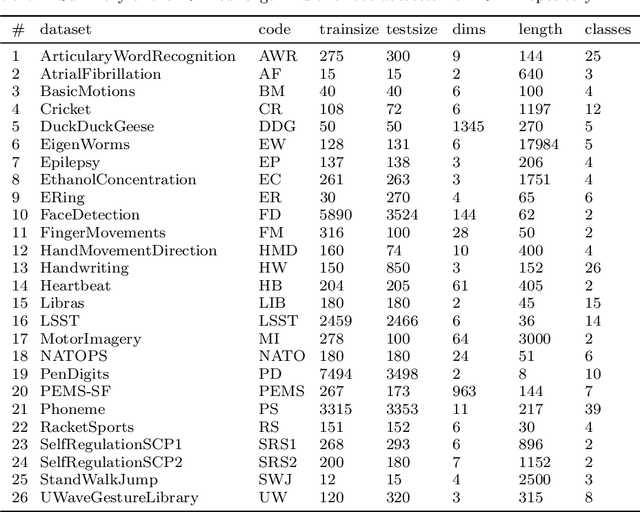
Elastic similarity measures are a class of similarity measures specifically designed to work with time series data. When scoring the similarity between two time series, they allow points that do not correspond in timestamps to be aligned. This can compensate for misalignments in the time axis of time series data, and for similar processes that proceed at variable and differing paces. Elastic similarity measures are widely used in machine learning tasks such as classification, clustering and outlier detection when using time series data. There is a multitude of research on various univariate elastic similarity measures. However, except for multivariate versions of the well known Dynamic Time Warping (DTW) there is a lack of work to generalise other similarity measures for multivariate cases. This paper adapts two existing strategies used in multivariate DTW, namely, Independent and Dependent DTW, to several commonly used elastic similarity measures. Using 23 datasets from the University of East Anglia (UEA) multivariate archive, for nearest neighbour classification, we demonstrate that each measure outperforms all others on at least one dataset and that there are datasets for which either the dependent versions of all measures are more accurate than their independent counterparts or vice versa. This latter finding suggests that these differences arise from a fundamental property of the data. We also show that an ensemble of such nearest neighbour classifiers is highly competitive with other state-of-the-art multivariate time series classifiers.
StarEnhancer: Learning Real-Time and Style-Aware Image Enhancement
Aug 02, 2021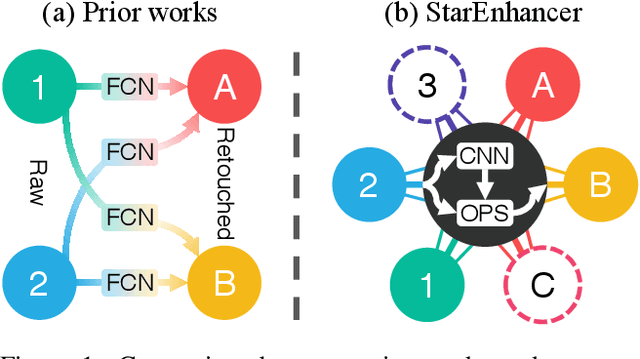
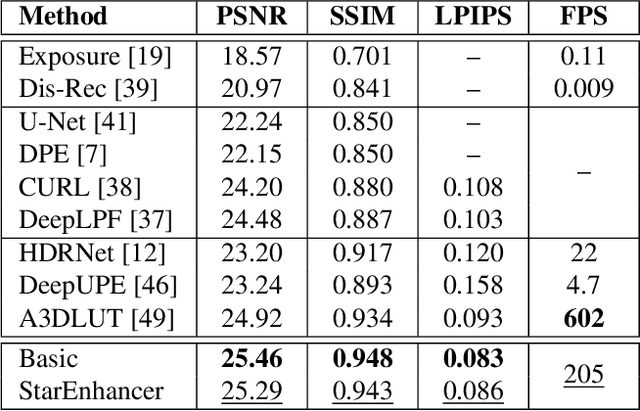
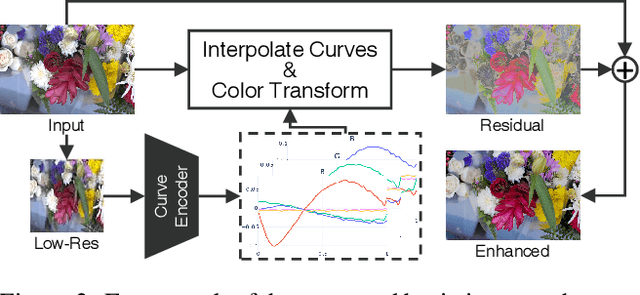
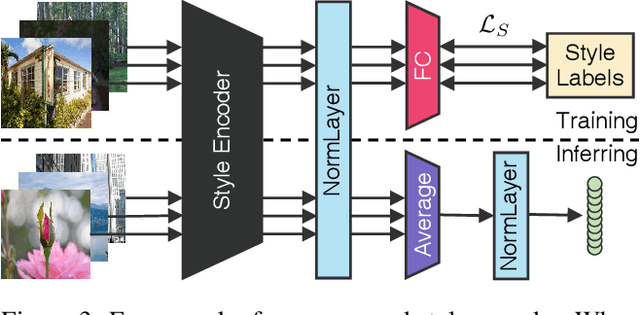
Image enhancement is a subjective process whose targets vary with user preferences. In this paper, we propose a deep learning-based image enhancement method covering multiple tonal styles using only a single model dubbed StarEnhancer. It can transform an image from one tonal style to another, even if that style is unseen. With a simple one-time setting, users can customize the model to make the enhanced images more in line with their aesthetics. To make the method more practical, we propose a well-designed enhancer that can process a 4K-resolution image over 200 FPS but surpasses the contemporaneous single style image enhancement methods in terms of PSNR, SSIM, and LPIPS. Finally, our proposed enhancement method has good interactability, which allows the user to fine-tune the enhanced image using intuitive options.
CASS: Cross Architectural Self-Supervision for Medical Image Analysis
Jun 23, 2022
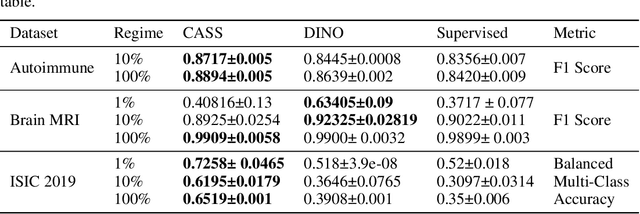


Recent advances in Deep Learning and Computer Vision have alleviated many of the bottlenecks, allowing algorithms to be label-free with better performance. Specifically, Transformers provide a global perspective of the image, which Convolutional Neural Networks (CNN) lack by design. Here we present Cross Architectural Self-Supervision, a novel self-supervised learning approach which leverages transformers and CNN simultaneously, while also being computationally accessible to general practitioners via easily available cloud services. Compared to existing state-of-the-art self-supervised learning approaches, we empirically show CASS trained CNNs, and Transformers gained an average of 8.5% with 100% labelled data, 7.3% with 10% labelled data, and 11.5% with 1% labelled data, across three diverse datasets. Notably, one of the employed datasets included histopathology slides of an autoimmune disease, a topic underrepresented in Medical Imaging and has minimal data. In addition, our findings reveal that CASS is twice as efficient as other state-of-the-art methods in terms of training time. The code is open source and is available on GitHub.
Object Localization Assistive System Based on CV and Vibrotactile Encoding
Jun 19, 2022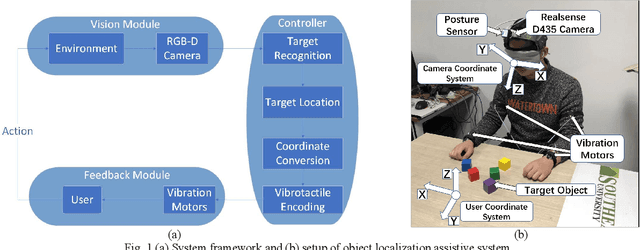
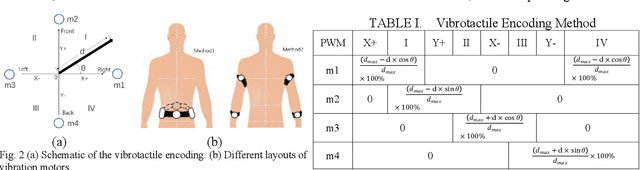
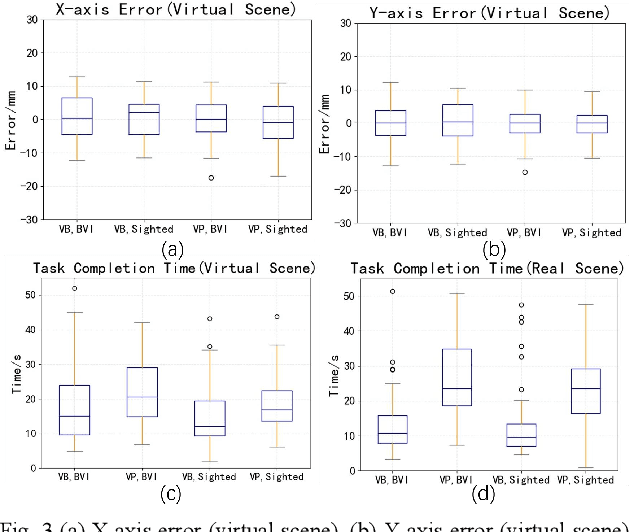
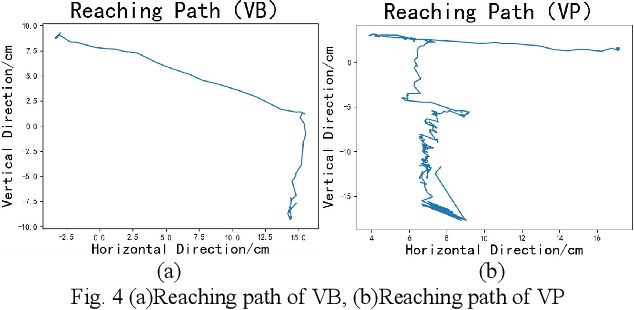
Intelligent assistive systems can navigate blind people, but most of them could only give non-intuitive cues or inefficient guidance. Based on computer vision and vibrotactile encoding, this paper presents an interactive system that provides blind people with intuitive spatial cognition. Different from the traditional auditory feedback strategy based on speech cues, this paper firstly introduces a vibration-encoded feedback method that leverages the haptic neural pathway and enables the users to interact with objects other than manipulating an assistance device. Based on this strategy, a wearable visual module based on an RGB-D camera is adopted for 3D spatial object localization, which contributes to accurate perception and quick object localization in the real environment. The experimental results on target blind individuals indicate that vibrotactile feedback reduces the task completion time by over 25% compared with the mainstream voice prompt feedback scheme. The proposed object localization system provides a more intuitive spatial navigation and comfortable wearability for blindness assistance.
Improving Policy Optimization with Generalist-Specialist Learning
Jun 26, 2022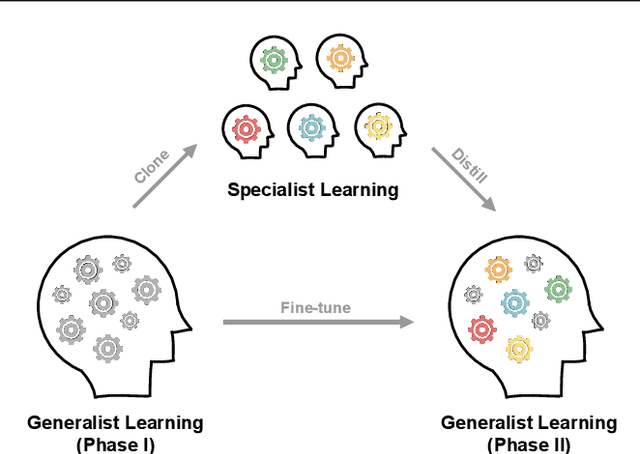

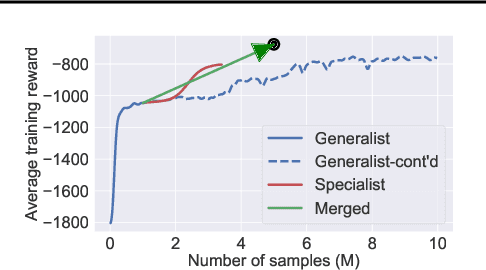

Generalization in deep reinforcement learning over unseen environment variations usually requires policy learning over a large set of diverse training variations. We empirically observe that an agent trained on many variations (a generalist) tends to learn faster at the beginning, yet its performance plateaus at a less optimal level for a long time. In contrast, an agent trained only on a few variations (a specialist) can often achieve high returns under a limited computational budget. To have the best of both worlds, we propose a novel generalist-specialist training framework. Specifically, we first train a generalist on all environment variations; when it fails to improve, we launch a large population of specialists with weights cloned from the generalist, each trained to master a selected small subset of variations. We finally resume the training of the generalist with auxiliary rewards induced by demonstrations of all specialists. In particular, we investigate the timing to start specialist training and compare strategies to learn generalists with assistance from specialists. We show that this framework pushes the envelope of policy learning on several challenging and popular benchmarks including Procgen, Meta-World and ManiSkill.
Learning a Restricted Boltzmann Machine using biased Monte Carlo sampling
Jun 02, 2022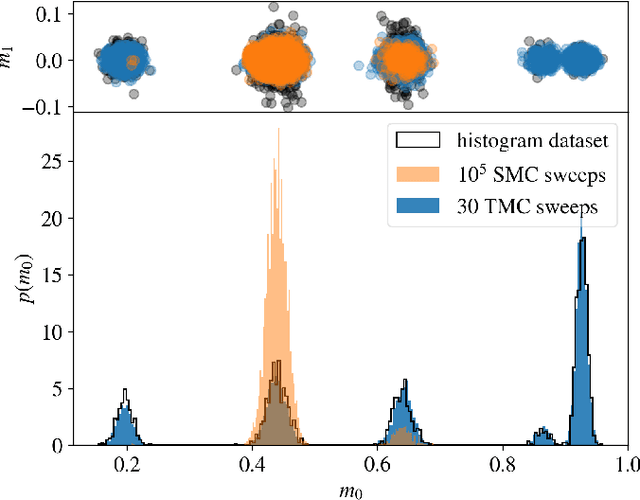
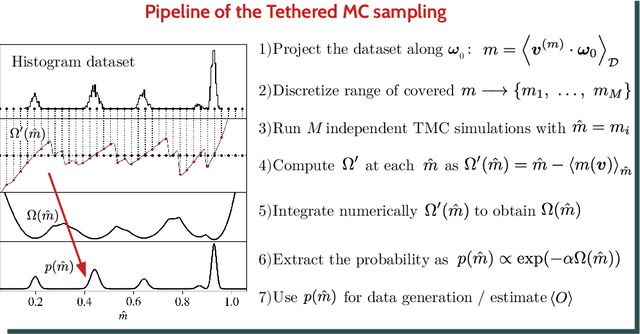
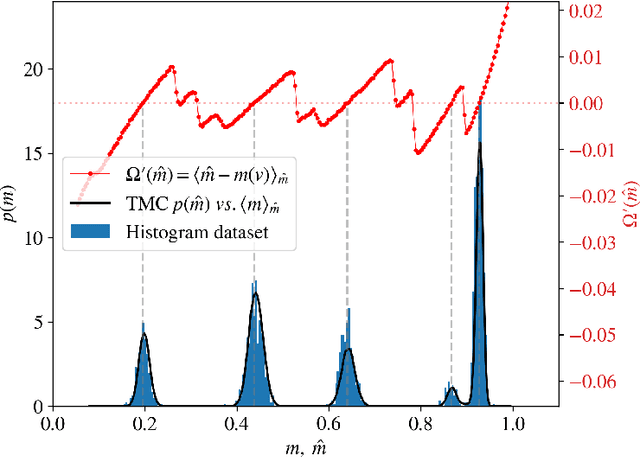
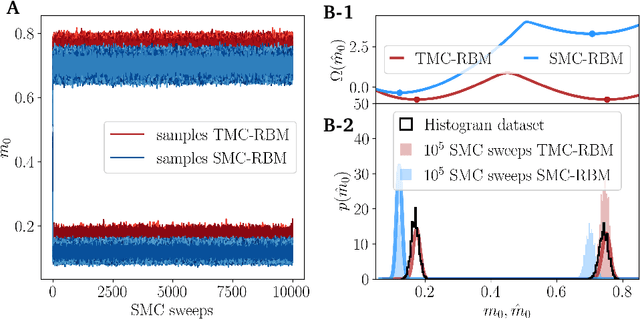
Restricted Boltzmann Machines are simple and powerful generative models capable of encoding any complex dataset. Despite all their advantages, in practice, trainings are often unstable, and it is hard to assess their quality because dynamics are hampered by extremely slow time-dependencies. This situation becomes critical when dealing with low-dimensional clustered datasets, where the time needed to sample ergodically the trained models becomes computationally prohibitive. In this work, we show that this divergence of Monte Carlo mixing times is related to a phase coexistence phenomenon, similar to that encountered in Physics in the vicinity of a first order phase transition. We show that sampling the equilibrium distribution via Markov Chain Monte Carlo can be dramatically accelerated using biased sampling techniques, in particular, the Tethered Monte Carlo method (TMC). This sampling technique solves efficiently the problem of evaluating the quality of a given trained model and the generation of new samples in reasonable times. In addition, we show that this sampling technique can be exploited to improve the computation of the log-likelihood gradient during the training too, which produces dramatic improvements when training RBMs with artificial clustered datasets. When dealing with real low-dimensional datasets, this new training procedure fits RBM models with significantly faster relaxational dynamics than those obtained with standard PCD recipes. We also show that TMC sampling can be used to recover free-energy profile of the RBM, which turns out to be extremely useful to compute the probability distribution of a given model and to improve the generation of new decorrelated samples on slow PCD trained models.
Lossless Compression of Point Cloud Sequences Using Sequence Optimized CNN Models
Jun 02, 2022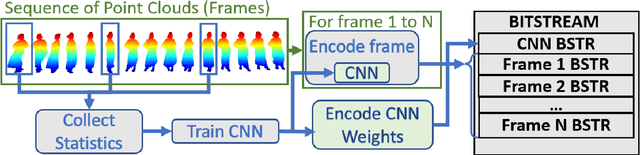
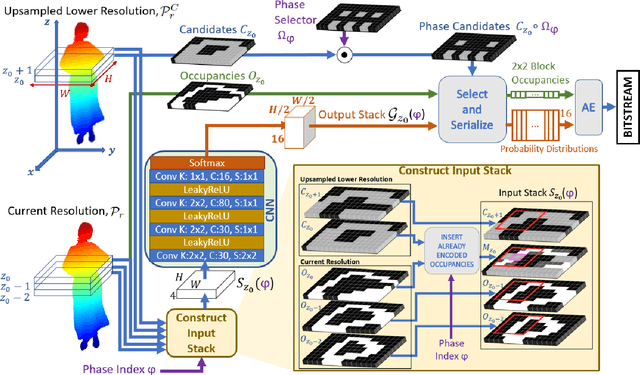
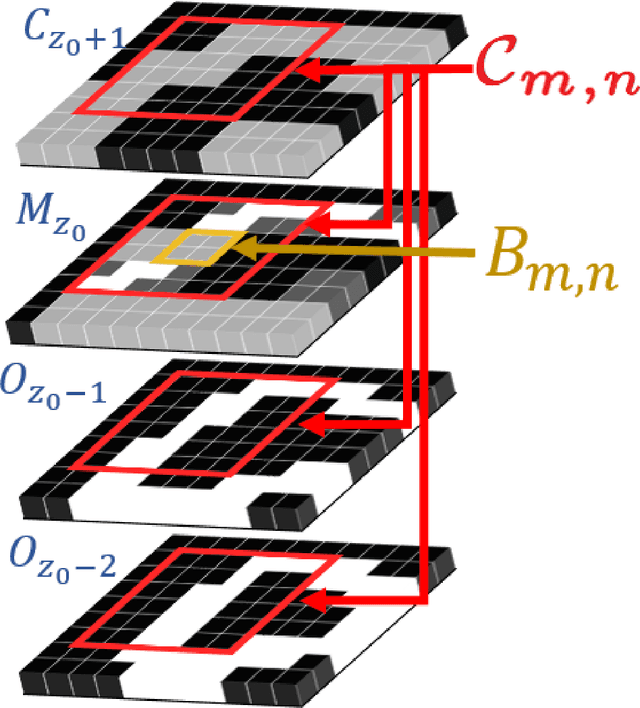
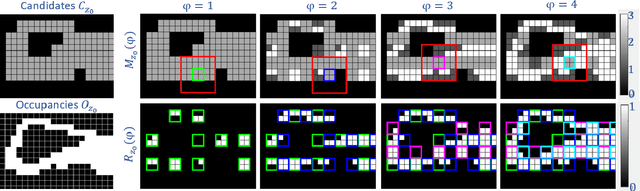
We propose a new paradigm for encoding the geometry of point cloud sequences, where the convolutional neural network (CNN) which estimates the encoding distributions is optimized on several frames of the sequence to be compressed. We adopt lightweight CNN structures, we perform training as part of the encoding process, and the CNN parameters are transmitted as part of the bitstream. The newly proposed encoding scheme operates on the octree representation for each point cloud, encoding consecutively each octree resolution layer. At every octree resolution layer, the voxel grid is traversed section-by-section (each section being perpendicular to a selected coordinate axis) and in each section the occupancies of groups of two-by-two voxels are encoded at once, in a single arithmetic coding operation. A context for the conditional encoding distribution is defined for each two-by-two group of voxels, based on the information available about the occupancy of neighbor voxels in the current and lower resolution layers of the octree. The CNN estimates the probability distributions of occupancy patterns of all voxel groups from one section in four phases. In each new phase the contexts are updated with the occupancies encoded in the previous phase, and each phase estimates the probabilities in parallel, providing a reasonable trade-off between the parallelism of processing and the informativeness of the contexts. The CNN training time is comparable to the time spent in the remaining encoding steps, leading to competitive overall encoding times. Bitrates and encoding-decoding times compare favorably with those of recently published compression schemes.
Restoring speech intelligibility for hearing aid users with deep learning
Jun 23, 2022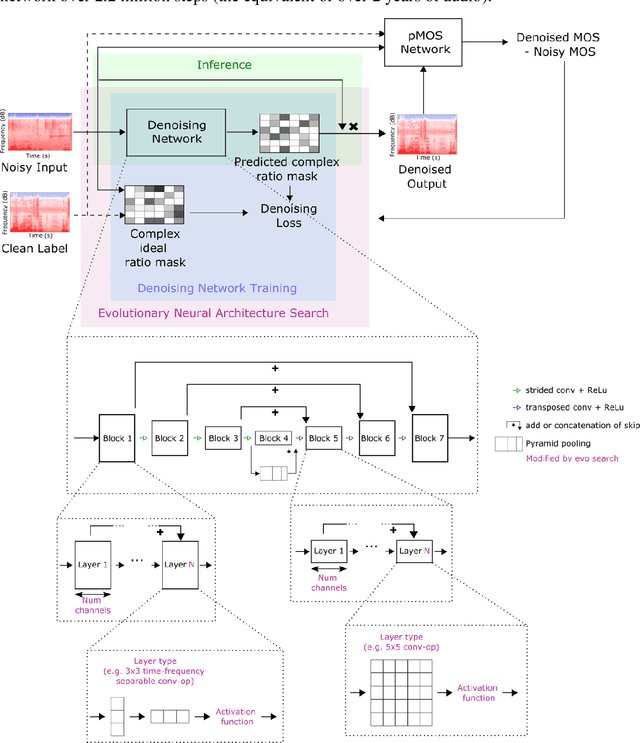
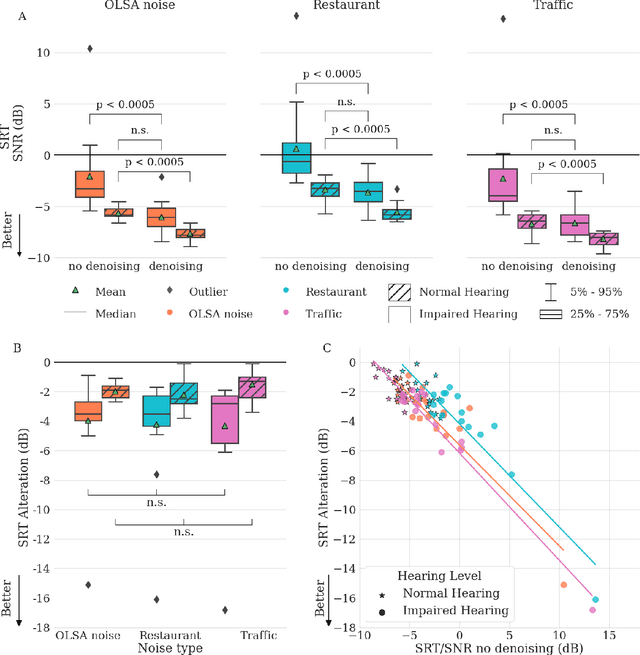
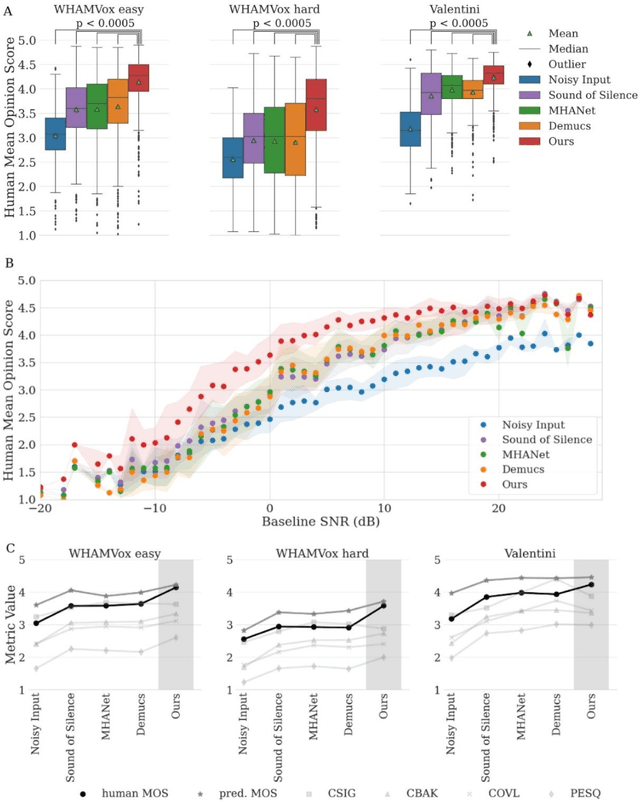
Almost half a billion people world-wide suffer from disabling hearing loss. While hearing aids can partially compensate for this, a large proportion of users struggle to understand speech in situations with background noise. Here, we present a deep learning-based algorithm that selectively suppresses noise while maintaining speech signals. The algorithm restores speech intelligibility for hearing aid users to the level of control subjects with normal hearing. It consists of a deep network that is trained on a large custom database of noisy speech signals and is further optimized by a neural architecture search, using a novel deep learning-based metric for speech intelligibility. The network achieves state-of-the-art denoising on a range of human-graded assessments, generalizes across different noise categories and - in contrast to classic beamforming approaches - operates on a single microphone. The system runs in real time on a laptop, suggesting that large-scale deployment on hearing aid chips could be achieved within a few years. Deep learning-based denoising therefore holds the potential to improve the quality of life of millions of hearing impaired people soon.
Improving Ads-Profitability Using Traffic-Fingerprints
May 31, 2022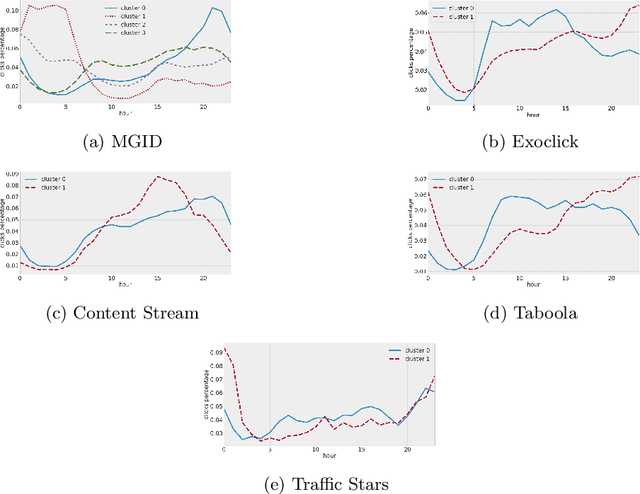
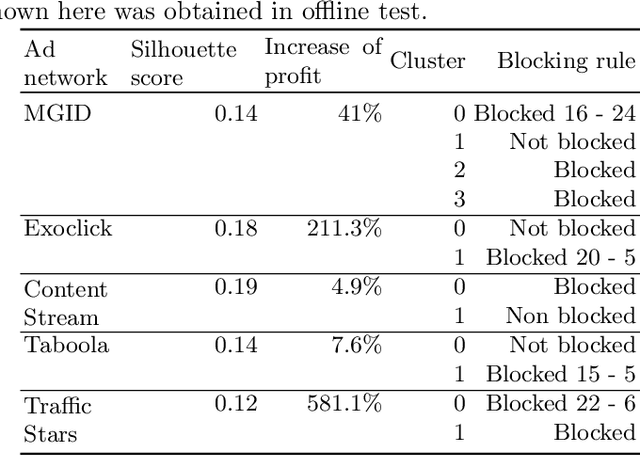
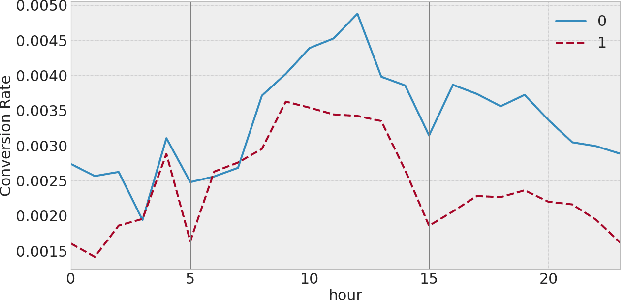
This paper introduces the concept of traffic-fingerprints, i.e., normalized 24-dimensional vectors representing a distribution of daily traffic on a web page. Using k-means clustering we show that similarity of traffic-fingerprints is related to the similarity of profitability time patterns for ads shown on these pages. In other words, these fingerprints are correlated with the conversions rates, thus allowing us to argue about conversion rates on pages with negligible traffic. By blocking or unblocking whole clusters of pages we were able to increase the revenue of online campaigns by more than 50%.
Falconn++: A Locality-sensitive Filtering Approach for Approximate Nearest Neighbor Search
Jun 03, 2022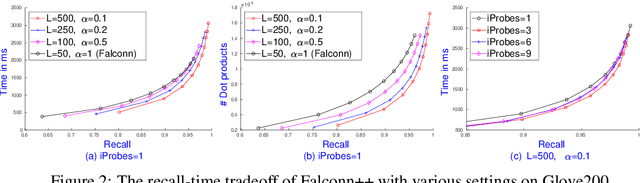

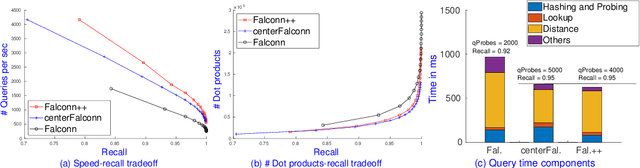
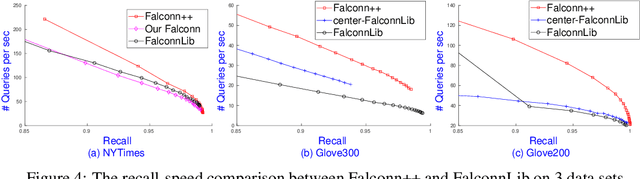
We present Falconn++, a novel locality-sensitive filtering (LSF) approach for approximate nearest neighbor search on angular distance. Falconn++ can filter out potential far away points in any hash bucket before querying, which results in higher quality candidates compared to other hashing-based solutions. Theoretically, Falconn++ asymptotically achieves lower query time complexity than Falconn, an optimal locality-sensitive hashing scheme on angular distance. Empirically, Falconn++ achieves a higher recall-speed tradeoff than Falconn on many real-world data sets. Falconn++ is also competitive against HNSW, an efficient representative of graph-based solutions on high search recall regimes.