 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benign, Tempered, or Catastrophic: A Taxonomy of Overfitting
Jul 14, 2022
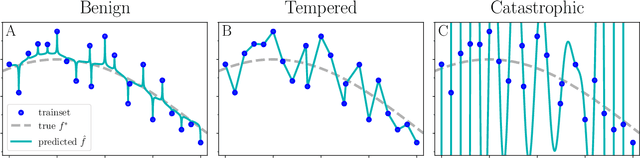

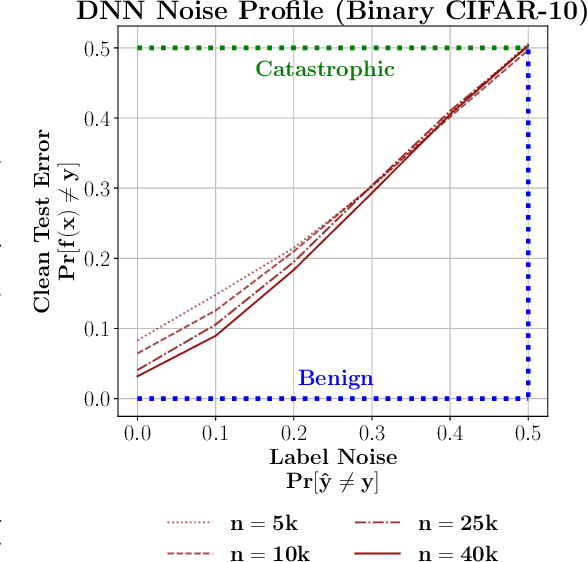

The practical success of overparameterized neural networks has motivated the recent scientific study of interpolating methods, which perfectly fit their training data. Certain interpolating methods, including neural networks, can fit noisy training data without catastrophically bad test performance, in defiance of standard intuitions from statistical learning theory. Aiming to explain this, a body of recent work has studied $\textit{benign overfitting}$, a phenomenon where some interpolating methods approach Bayes optimality, even in the presence of noise. In this work we argue that while benign overfitting has been instructive and fruitful to study, many real interpolating methods like neural networks $\textit{do not fit benignly}$: modest noise in the training set causes nonzero (but non-infinite) excess risk at test time, implying these models are neither benign nor catastrophic but rather fall in an intermediate regime. We call this intermediate regime $\textit{tempered overfitting}$, and we initiate its systematic study. We first explore this phenomenon in the context of kernel (ridge) regression (KR) by obtaining conditions on the ridge parameter and kernel eigenspectrum under which KR exhibits each of the three behaviors. We find that kernels with powerlaw spectra, including Laplace kernels and ReLU neural tangent kernels, exhibit tempered overfitting. We then empirically study deep neural networks through the lens of our taxonomy, and find that those trained to interpolation are tempered, while those stopped early are benign. We hope our work leads to a more refined understanding of overfitting in modern learning.
TabText: a Systematic Approach to Aggregate Knowledge Across Tabular Data Structures
Jun 21, 2022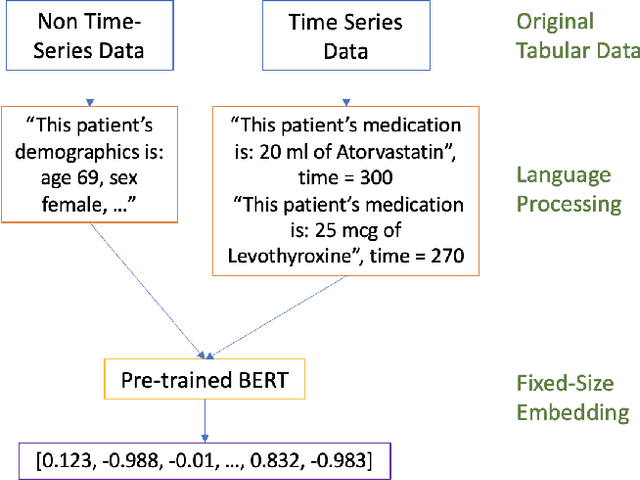
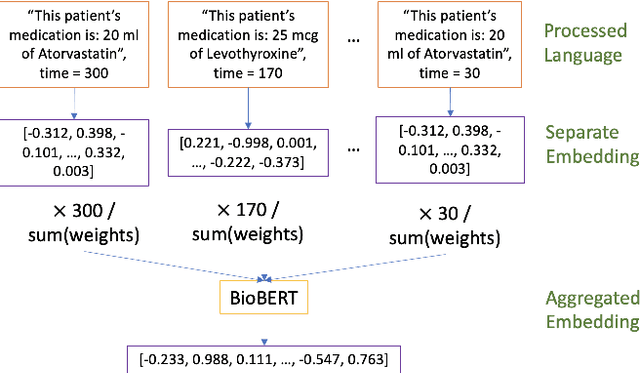
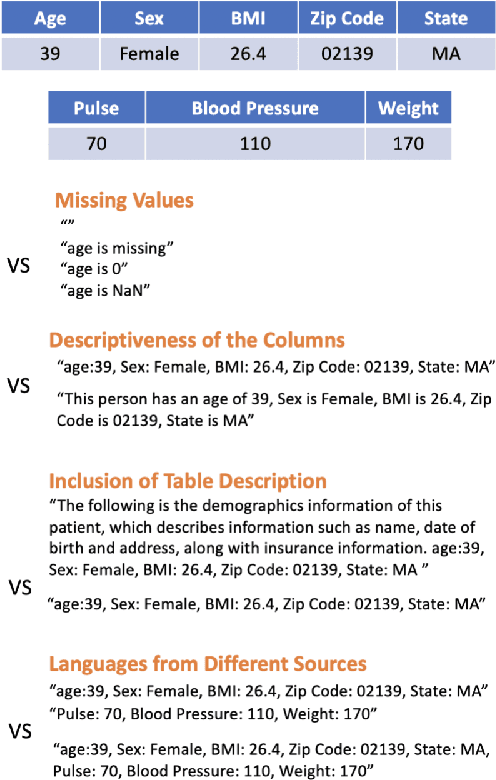
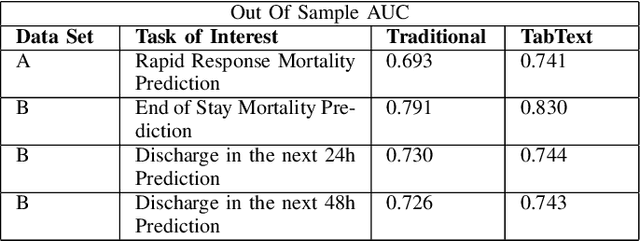
Processing and analyzing tabular data in a productive and efficient way is essential for building successful applications of machine learning in fields such as healthcare. However, the lack of a unified framework for representing and standardizing tabular information poses a significant challenge to researchers and professionals alike. In this work, we present TabText, a methodology that leverages the unstructured data format of language to encode tabular data from different table structures and time periods efficiently and accurately. We show using two healthcare datasets and four prediction tasks that features extracted via TabText outperform those extracted with traditional processing methods by 2-5%. Furthermore, we analyze the sensitivity of our framework against different choices for sentence representations of missing values, meta information and language descriptiveness, and provide insights into winning strategies that improve performance.
Consistency of Implicit and Explicit Features Matters for Monocular 3D Object Detection
Jul 16, 2022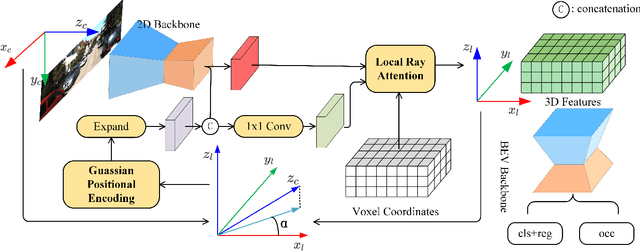
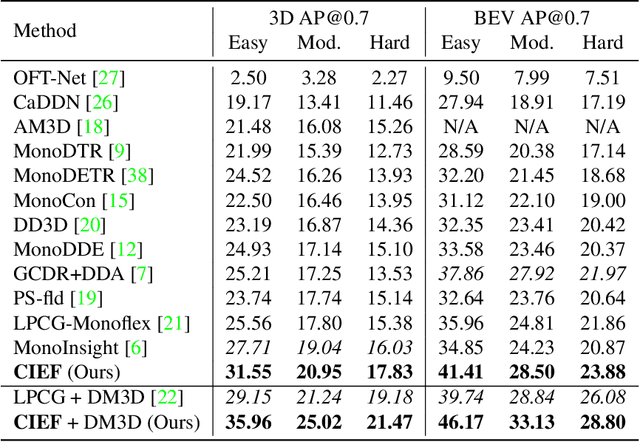
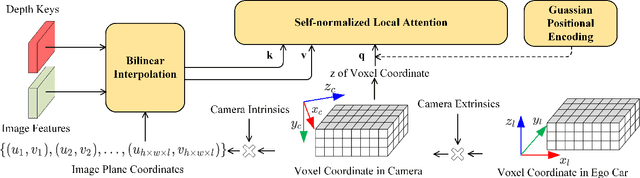
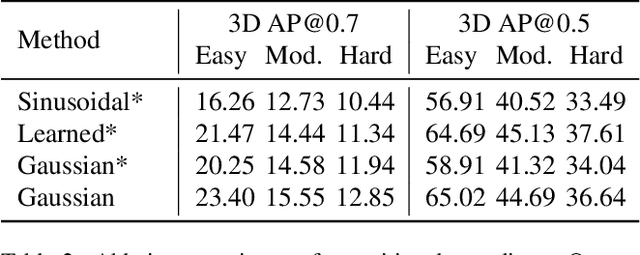
Monocular 3D object detection is a common solution for low-cost autonomous agents to perceive their surrounding environment. Monocular detection has progressed into two categories: (1)Direct methods that infer 3D bounding boxes directly from a frontal-view image; (2)3D intermedia representation methods that map image features to 3D space for subsequent 3D detection. The second category is standing out not only because 3D detection forges ahead at the mercy of more meaningful and representative features, but because of emerging SOTA end-to-end prediction and planning paradigms that require a bird's-eye-view feature map from a perception pipeline. However, in transforming to 3D representation, these methods do not guarantee that objects' implicit orientations and locations in latent space are consistent with those explicitly observed in Euclidean space, which will hurt model performance. Hence, we argue that the consistency of implicit and explicit features matters and present a novel monocular detection method, named CIEF, with the first orientation-aware image backbone to eliminate the disparity of implicit and explicit features in subsequent 3D representation. As a second contribution, we introduce a ray attention mechanism. In contrast to previous methods that repeat features along the projection ray or rely on another intermedia frustum point cloud, we directly transform image features to voxel representations with well-localized features. We also propose a handcrafted gaussian positional encoding function that outperforms the sinusoidal encoding function but maintains the benefit of being continuous. CIEF ranked 1st among all reported methods on both 3D and BEV detection benchmark of KITTI at submission time.
opPINN: Physics-Informed Neural Network with operator learning to approximate solutions to the Fokker-Planck-Landau equation
Jul 05, 2022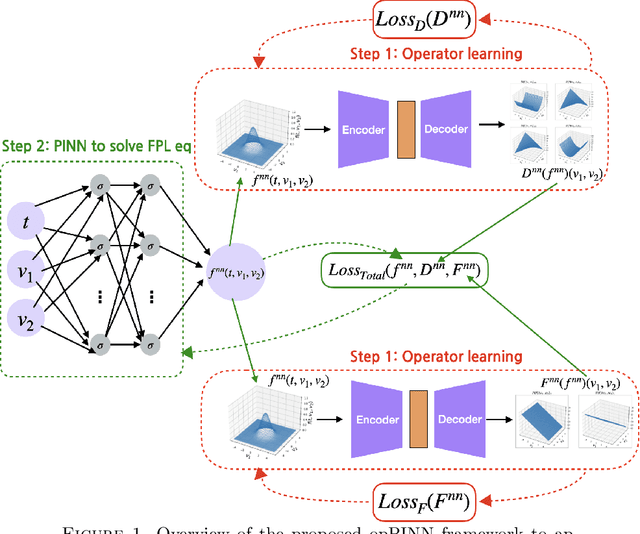
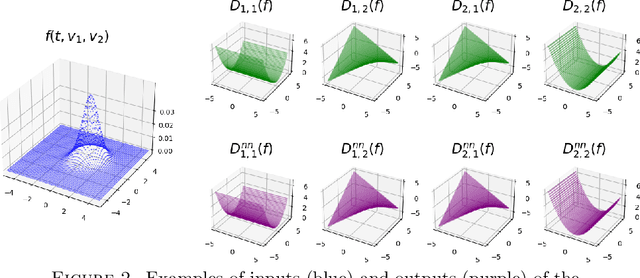
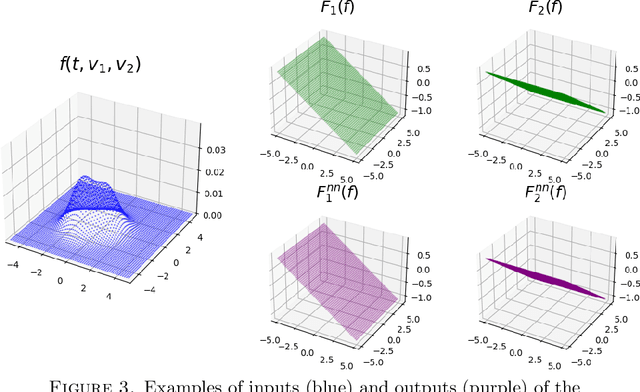
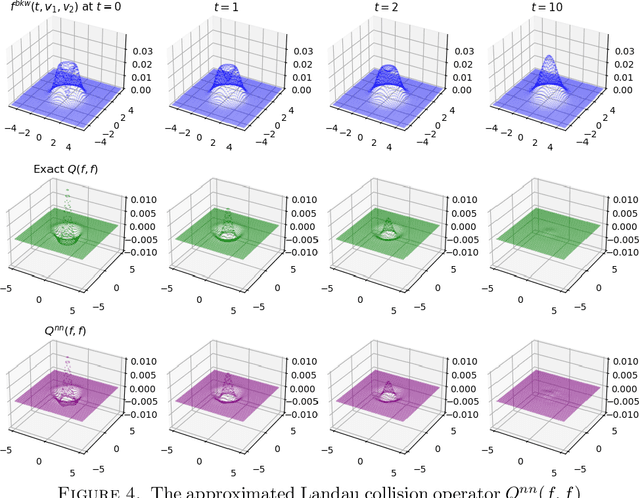
We propose a hybrid framework opPINN: physics-informed neural network (PINN) with operator learning for approximating the solution to the Fokker-Planck-Landau (FPL) equation. The opPINN framework is divided into two steps: Step 1 and Step 2. After the operator surrogate models are trained during Step 1, PINN can effectively approximate the solution to the FPL equation during Step 2 by using the pre-trained surrogate models. The operator surrogate models greatly reduce the computational cost and boost PINN by approximating the complex Landau collision integral in the FPL equation. The operator surrogate models can also be combined with the traditional numerical schemes. It provides a high efficiency in computational time when the number of velocity modes becomes larger. Using the opPINN framework, we provide the neural network solutions for the FPL equation under the various types of initial conditions, and interaction models in two and three dimensions. Furthermore, based on the theoretical properties of the FPL equation, we show that the approximated neural network solution converges to the a priori classical solution of the FPL equation as the pre-defined loss function is reduced.
Fitting Sparse Markov Models to Categorical Time Series Using Regularization
Feb 11, 2022The major problem of fitting a higher order Markov model is the exponentially growing number of parameters. The most popular approach is to use a Variable Length Markov Chain (VLMC), which determines relevant contexts (recent pasts) of variable orders and form a context tree. A more general approach is called Sparse Markov Model (SMM), where all possible histories of order $m$ form a partition so that the transition probability vectors are identical for the histories belonging to a particular group. We develop an elegant method of fitting SMM using convex clustering, which involves regularization. The regularization parameter is selected using BIC criterion. Theoretical results demonstrate the model selection consistency of our method for large sample size. Extensive simulation studies under different set-up have been presented to measure the performance of our method. We apply this method to classify genome sequences, obtained from individuals affected by different viruses.
Cluster-based Characterization and Modeling for UAV Air-to-Ground Time-Varying Channels
Aug 26, 2021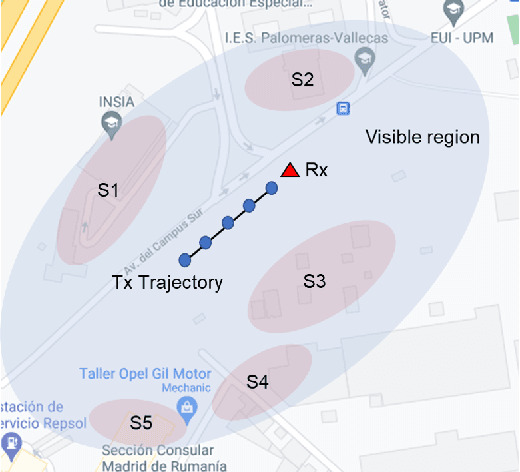
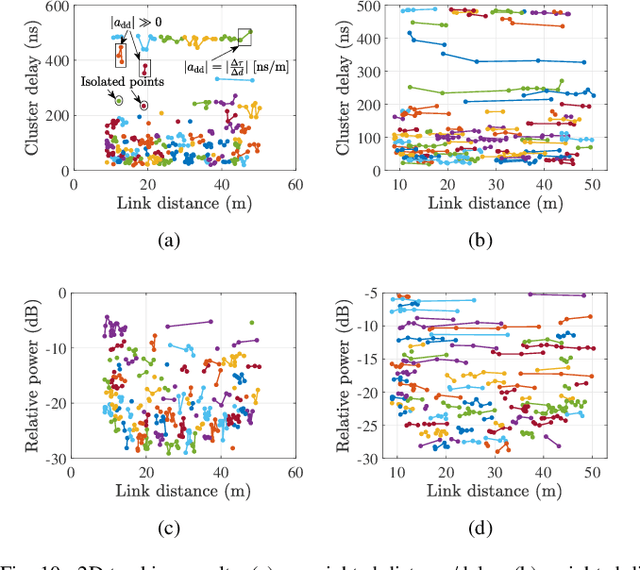
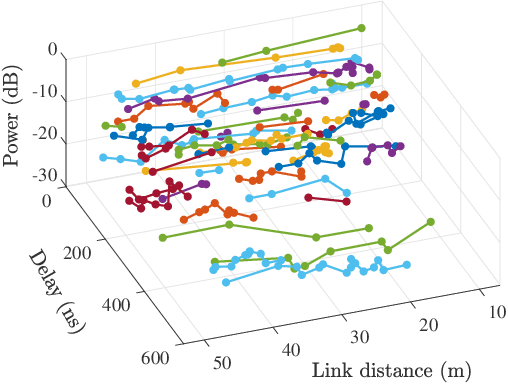
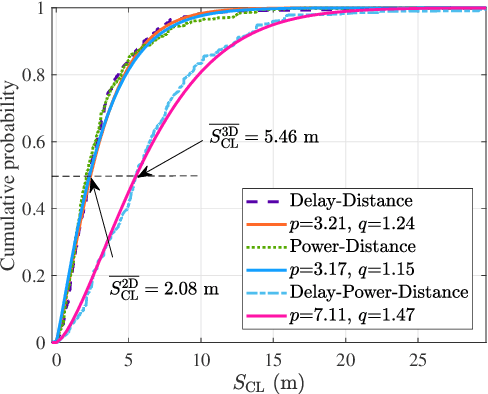
With the deep integration between the unmanned aerial vehicle (UAV) and wireless communication, UAV-based air-to-ground (AG) propagation channels need more detailed descriptions and accurate models. In this paper, we aim to perform cluster-based characterization and modeling for AG channels. To our best knowledge, this is the first study that concentrates on the clustering and tracking of multipath components (MPCs) for time-varying AG channels. Based on measurement data at 6.5 GHz with 500 MHz of bandwidth, we first estimate potential MPCs utilizing the space-alternating generalized expectation-maximization (SAGE) algorithm. Then, we cluster the extracted MPCs considering their static and dynamic characteristics by employing K-Power-Means (KPM) algorithm under multipath component distance (MCD) measure. For characterizing time-variant clusters, we exploit a clustering-based tracking (CBT) method, which efficiently quantifies the survival lengths of clusters. Ultimately, we establish a cluster-based channel model, and validations illustrate the accuracy of the proposed model. This work not only promotes a better understanding of AG propagation channels but also provides a general cluster-based AG channel model with certain extensibility.
Real-World Single Image Super-Resolution Under Rainy Condition
Jun 16, 2022
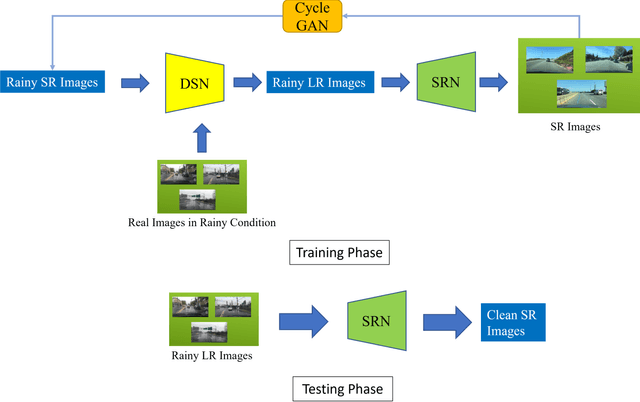


Image super-resolution is an important research area in computer vision that has a wide variety of applications including surveillance, medical imaging etc. Real-world signal image super-resolution has become very popular now-a-days due to its real-time application. There are still a lot of scopes to improve real-world single image super-resolution specially during challenging weather scenarios. In this paper, we have proposed a new algorithm to perform real-world single image super-resolution during rainy condition. Our proposed method can mitigate the influence of rainy conditions during image super-resolution. Our experiment results show that our proposed algorithm can perform image super-resolution decreasing the negative effects of the rain.
On Merging Feature Engineering and Deep Learning for Diagnosis, Risk-Prediction and Age Estimation Based on the 12-Lead ECG
Jul 16, 2022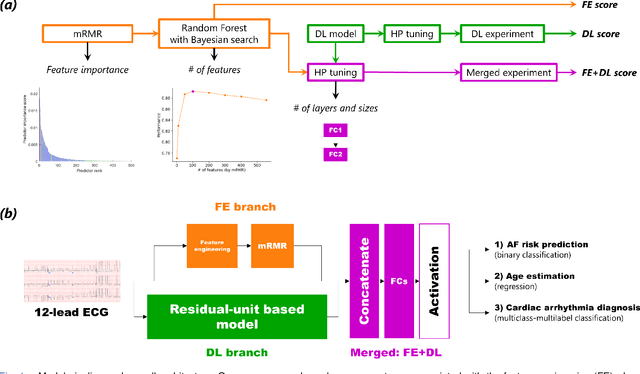
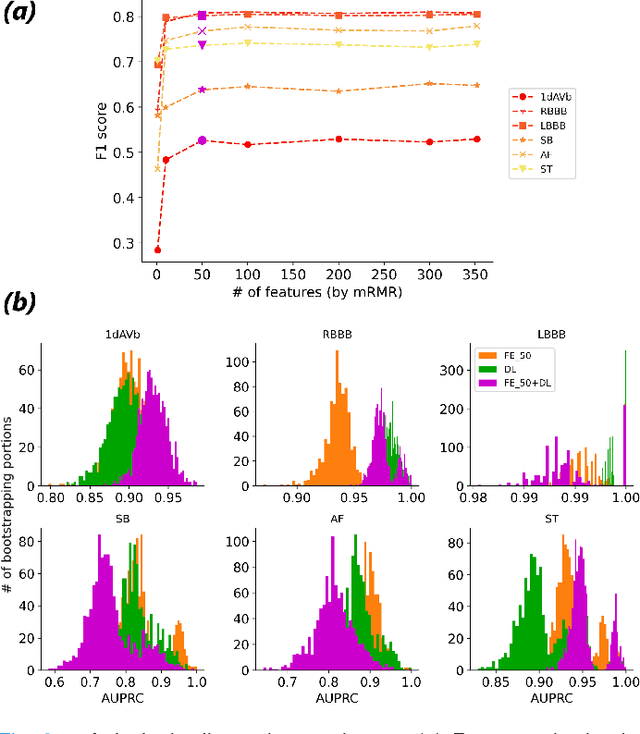
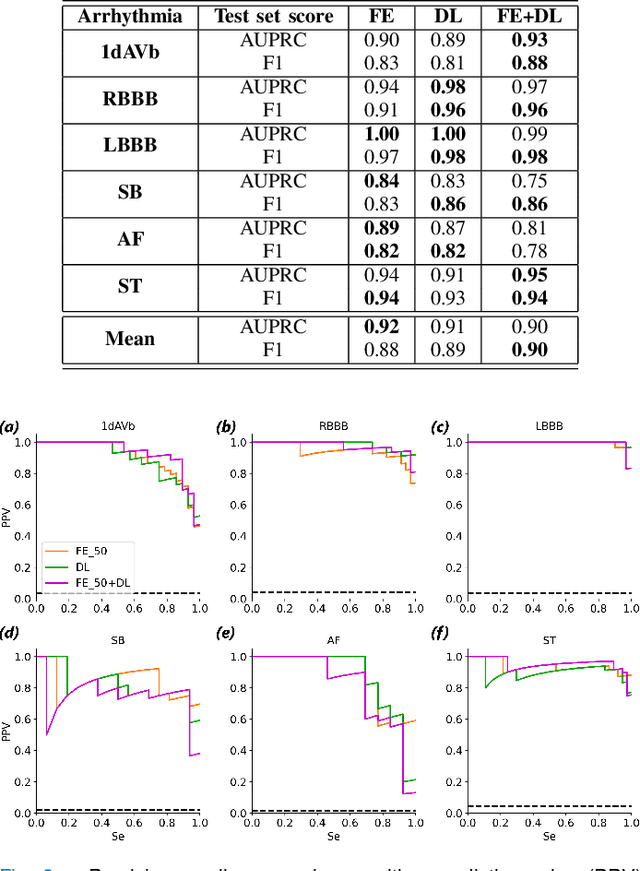
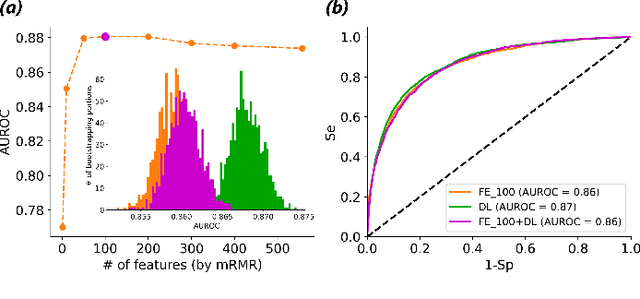
Objective: Machine learning techniques have been used extensively for 12-lead electrocardiogram (ECG) analysis. For physiological time series, deep learning (DL) superiority to feature engineering (FE) approaches based on domain knowledge is still an open question. Moreover, it remains unclear whether combining DL with FE may improve performance. Methods: We considered three tasks intending to address these research gaps: cardiac arrhythmia diagnosis (multiclass-multilabel classification), atrial fibrillation risk prediction (binary classification), and age estimation (regression). We used an overall dataset of 2.3M 12-lead ECG recordings to train the following models for each task: i) a random forest taking the FE as input was trained as a classical machine learning approach; ii) an end-to-end DL model; and iii) a merged model of FE+DL. Results: FE yielded comparable results to DL while necessitating significantly less data for the two classification tasks and it was outperformed by DL for the regression task. For all tasks, merging FE with DL did not improve performance over DL alone. Conclusion: We found that for traditional 12-lead ECG based diagnosis tasks DL did not yield a meaningful improvement over FE, while it improved significantly the nontraditional regression task. We also found that combining FE with DL did not improve over DL alone which suggests that the FE were redundant with the features learned by DL. Significance: Our findings provides important recommendations on what machine learning strategy and data regime to chose with respect to the task at hand for the development of new machine learning models based on the 12-lead ECG.
A Modified Dynamic Time Warping (MDTW) Approach and Innovative Average Non-Self Match Distance (ANSD) Method for Anomaly Detection in ECG Recordings
Nov 01, 2021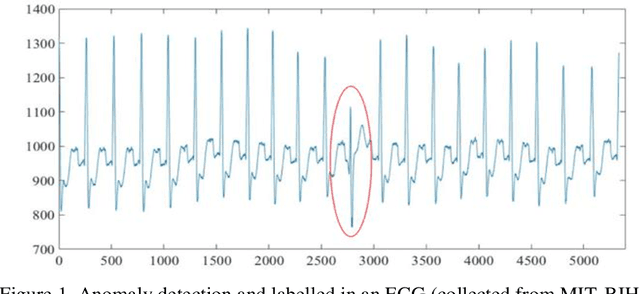
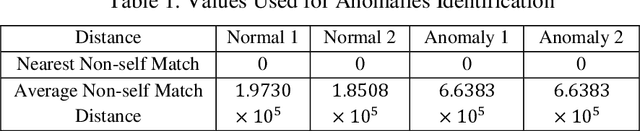
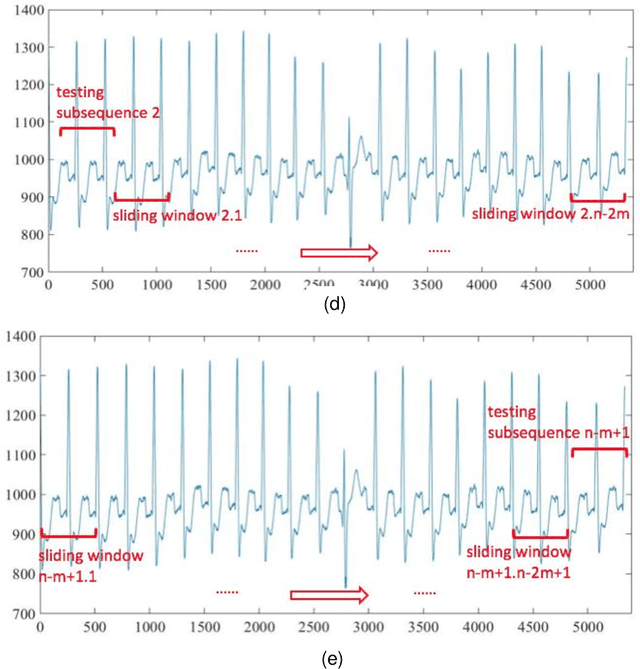
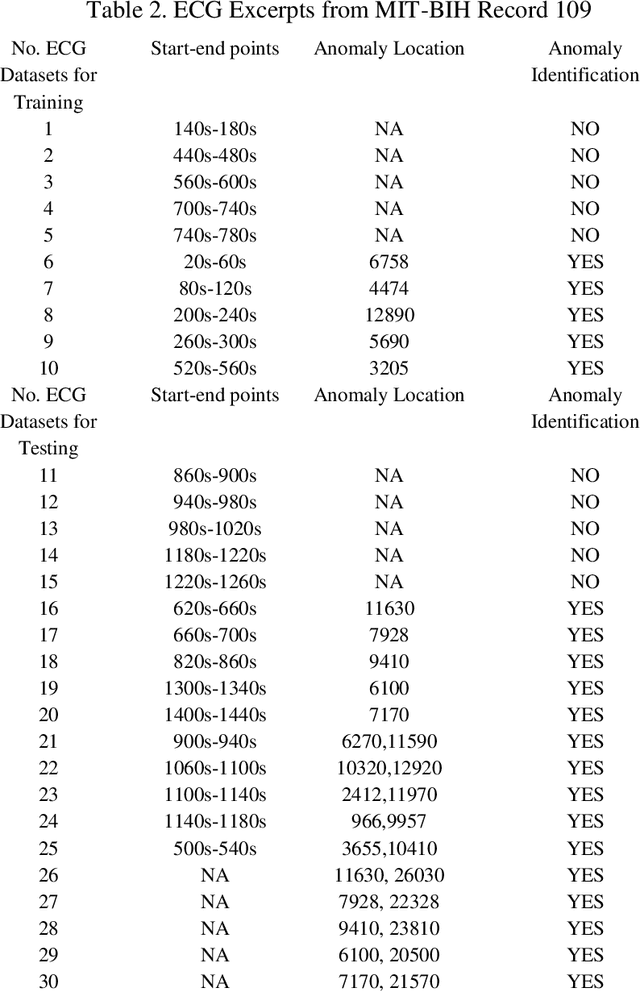
ECGs objectively reflects the working conditions of the hearts as these signals contain vast physiological and pathological information. In this work, in order to improve the efficiency and accuracy of "best so far" time series analysis-based ECG anomaly detection methods, a novel method, comprising a modified dynamic time warping (MDTW) and an innovative average non-self match distance (ANSD) measure, is proposed for ECG anomaly detection. To evaluate the performance of the proposed method, the proposed method is applied to real ECG data selected from the MIT-BIH heartbeat database. To provide a reference for comparison, two existing anomaly detection methods, namely, brute force discord discovery (BFDD) and adaptive window discord discovery (AWDD), are also applied to the same data. The experimental results show that our proposed method outperforms BFDD and AWD.
Scale Dependencies and Self-Similarity Through Wavelet Scattering Covariance
Apr 19, 2022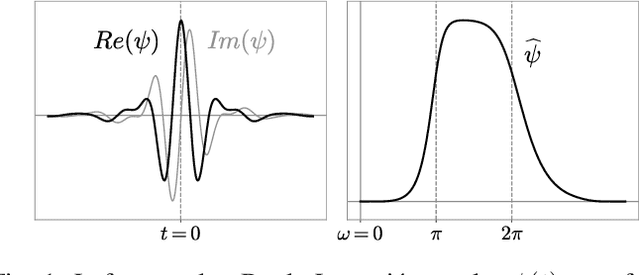
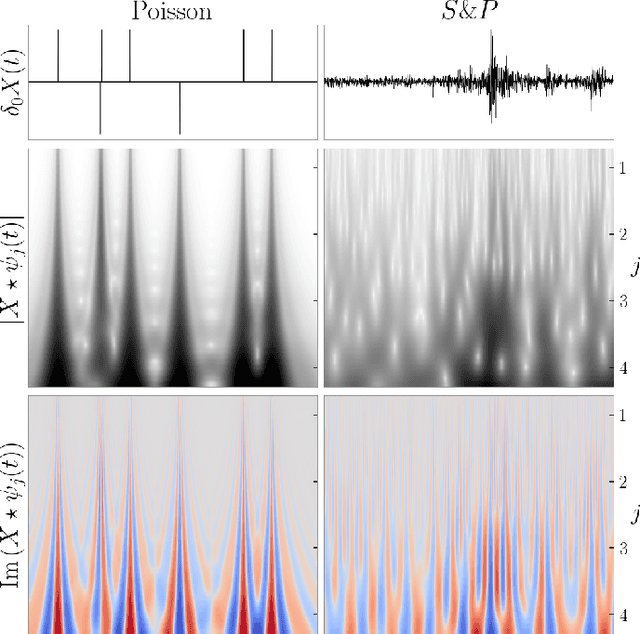
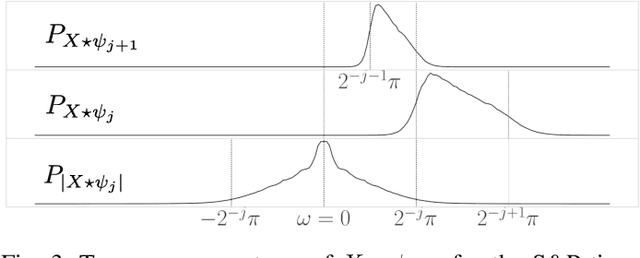
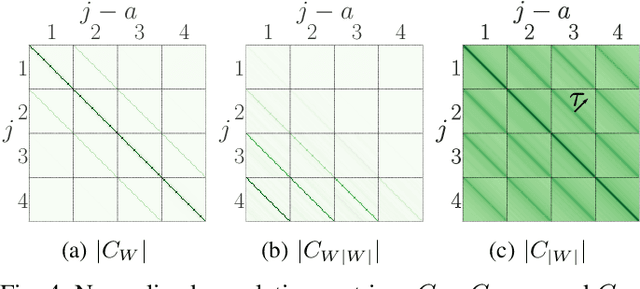
We introduce a scattering covariance matrix which provides non-Gaussian models of time-series having stationary increments. A complex wavelet transform computes signal variations at each scale. Dependencies across scales are captured by the joint covariance across time and scales of complex wavelet coefficients and their modulus. This covariance is nearly diagonalized by a second wavelet transform, which defines the scattering covariance. We show that this set of moments characterizes a wide range of non-Gaussian properties of multi-scale processes. This is analyzed for a variety of processes, including fractional Brownian motions, Poisson, multifractal random walks and Hawkes processes. We prove that self-similar processes have a scattering covariance matrix which is scale invariant. This property can be estimated numerically and defines a class of wide-sense self-similar processes. We build maximum entropy models conditioned by scattering covariance coefficients, and generate new time-series with a microcanonical sampling algorithm. Applications are shown for highly non-Gaussian financial and turbulence time-series.