 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Varying Channel Prediction for RIS-Assisted MU-MISO Networks via Deep Learning
Nov 09, 2021
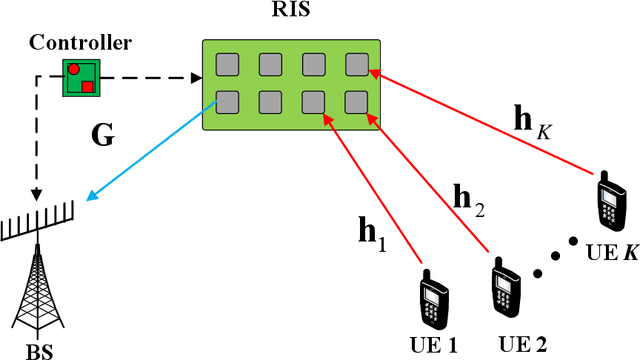
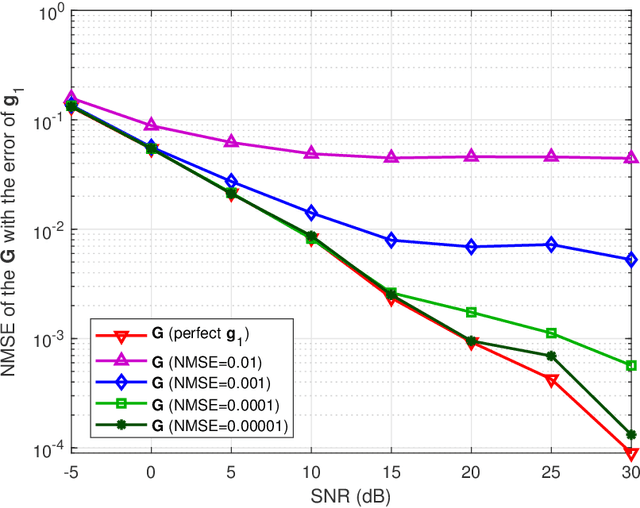
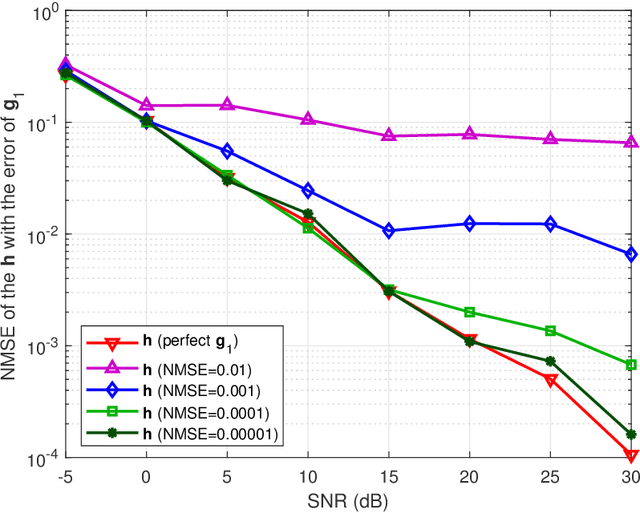
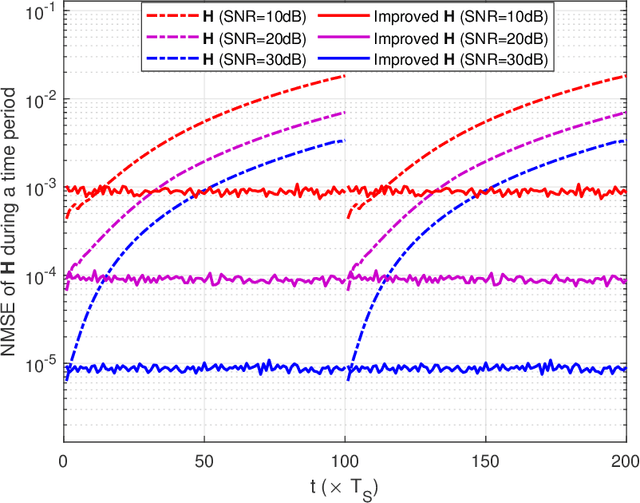
To mitigate the effects of shadow fading and obstacle blocking, reconfigurable intelligent surface (RIS) has become a promising technology to improve the signal transmission quality of wireless communications by controlling the reconfigurable passive elements with less hardware cost and lower power consumption. However, accurate, low-latency and low-pilot-overhead channel state information (CSI) acquisition remains a considerable challenge in RIS-assisted systems due to the large number of RIS passive elements. In this paper, we propose a three-stage joint channel decomposition and prediction framework to require CSI. The proposed framework exploits the two-timescale property that the base station (BS)-RIS channel is quasi-static and the RIS-user equipment (UE) channel is fast time-varying. Specifically, in the first stage, we use the full-duplex technique to estimate the channel between a BS's specific antenna and the RIS, addressing the critical scaling ambiguity problem in the channel decomposition. We then design a novel deep neural network, namely, the sparse-connected long short-term memory (SCLSTM), and propose a SCLSTM-based algorithm in the second and third stages, respectively. The algorithm can simultaneously decompose the BS-RIS channel and RIS-UE channel from the cascaded channel and capture the temporal relationship of the RIS-UE channel for prediction. Simulation results show that our proposed framework has lower pilot overhead than the traditional channel estimation algorithms, and the proposed SCLSTM-based algorithm can also achieve more accurate CSI acquisition robustly and effectively.
Aug-NeRF: Training Stronger Neural Radiance Fields with Triple-Level Physically-Grounded Augmentations
Jul 04, 2022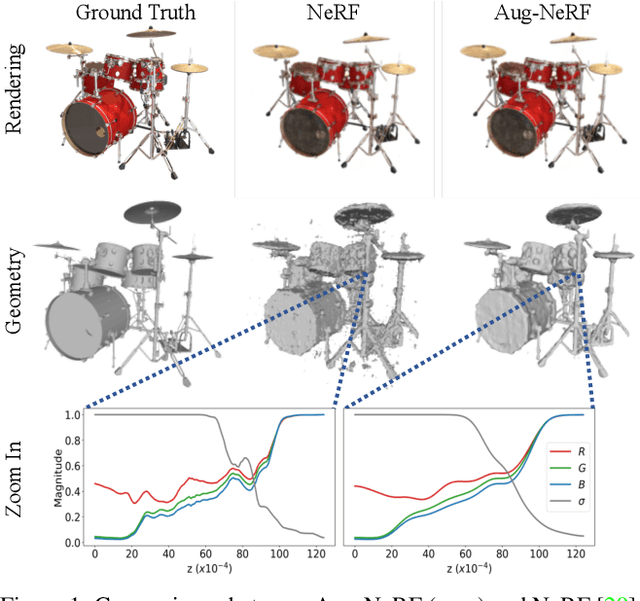
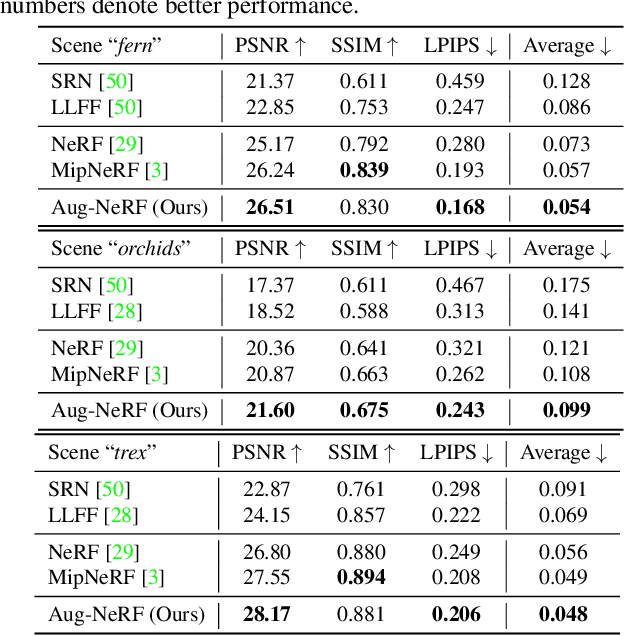
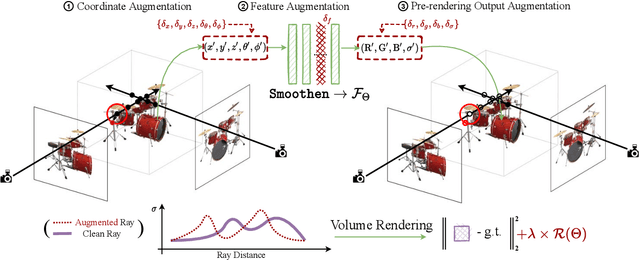
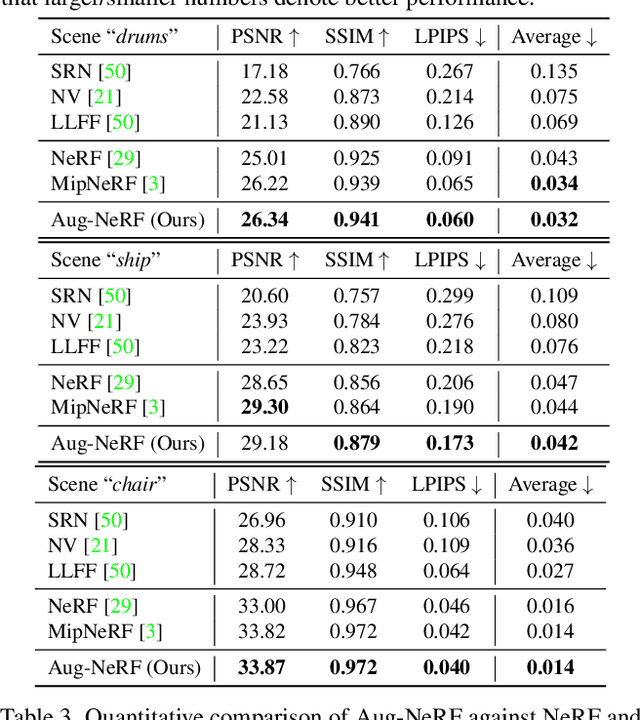
Neural Radiance Field (NeRF) regresses a neural parameterized scene by differentially rendering multi-view images with ground-truth supervision. However, when interpolating novel views, NeRF often yields inconsistent and visually non-smooth geometric results, which we consider as a generalization gap between seen and unseen views. Recent advances in convolutional neural networks have demonstrated the promise of advanced robust data augmentations, either random or learned, in enhancing both in-distribution and out-of-distribution generalization. Inspired by that, we propose Augmented NeRF (Aug-NeRF), which for the first time brings the power of robust data augmentations into regularizing the NeRF training. Particularly, our proposal learns to seamlessly blend worst-case perturbations into three distinct levels of the NeRF pipeline with physical grounds, including (1) the input coordinates, to simulate imprecise camera parameters at image capture; (2) intermediate features, to smoothen the intrinsic feature manifold; and (3) pre-rendering output, to account for the potential degradation factors in the multi-view image supervision. Extensive results demonstrate that Aug-NeRF effectively boosts NeRF performance in both novel view synthesis (up to 1.5dB PSNR gain) and underlying geometry reconstruction. Furthermore, thanks to the implicit smooth prior injected by the triple-level augmentations, Aug-NeRF can even recover scenes from heavily corrupted images, a highly challenging setting untackled before. Our codes are available in https://github.com/VITA-Group/Aug-NeRF.
WOLONet: Wave Outlooker for Efficient and High Fidelity Speech Synthesis
Jun 20, 2022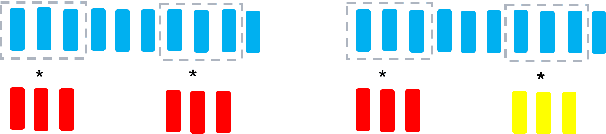
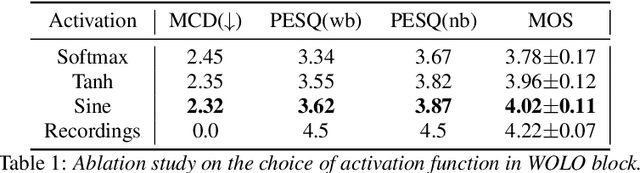
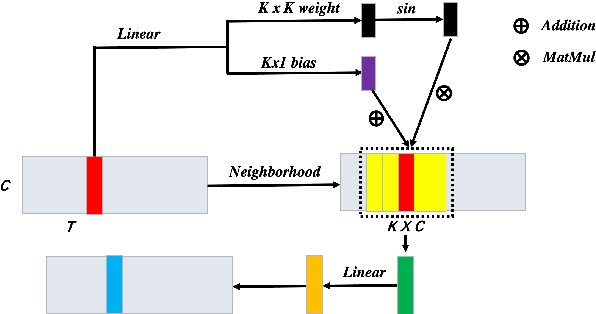
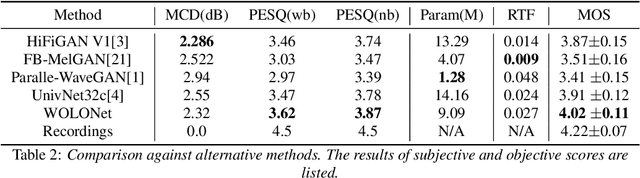
Recently, GAN-based neural vocoders such as Parallel WaveGAN, MelGAN, HiFiGAN, and UnivNet have become popular due to their lightweight and parallel structure, resulting in a real-time synthesized waveform with high fidelity, even on a CPU. HiFiGAN and UnivNet are two SOTA vocoders. Despite their high quality, there is still room for improvement. In this paper, motivated by the structure of Vision Outlooker from computer vision, we adopt a similar idea and propose an effective and lightweight neural vocoder called WOLONet. In this network, we develop a novel lightweight block that uses a location-variable, channel-independent, and depthwise dynamic convolutional kernel with sinusoidally activated dynamic kernel weights. To demonstrate the effectiveness and generalizability of our method, we perform an ablation study to verify our novel design and make a subjective and objective comparison with typical GAN-based vocoders. The results show that our WOLONet achieves the best generation quality while requiring fewer parameters than the two neural SOTA vocoders, HiFiGAN and UnivNet.
Parallel Bayesian Optimization of Agent-based Transportation Simulation
Jul 11, 2022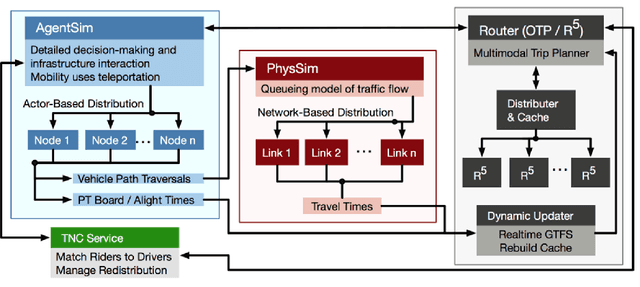
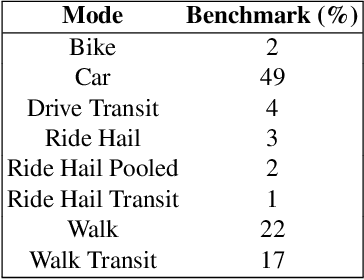
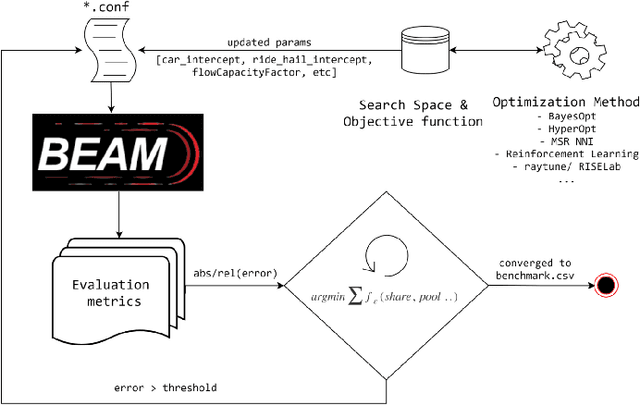
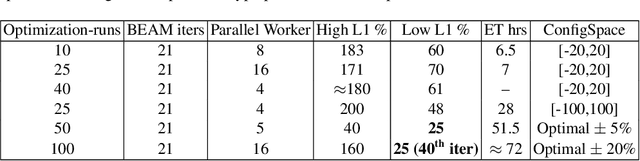
MATSim (Multi-Agent Transport Simulation Toolkit) is an open source large-scale agent-based transportation planning project applied to various areas like road transport, public transport, freight transport, regional evacuation, etc. BEAM (Behavior, Energy, Autonomy, and Mobility) framework extends MATSim to enable powerful and scalable analysis of urban transportation systems. The agents from the BEAM simulation exhibit 'mode choice' behavior based on multinomial logit model. In our study, we consider eight mode choices viz. bike, car, walk, ride hail, driving to transit, walking to transit, ride hail to transit, and ride hail pooling. The 'alternative specific constants' for each mode choice are critical hyperparameters in a configuration file related to a particular scenario under experimentation. We use the 'Urbansim-10k' BEAM scenario (with 10,000 population size) for all our experiments. Since these hyperparameters affect the simulation in complex ways, manual calibration methods are time consuming. We present a parallel Bayesian optimization method with early stopping rule to achieve fast convergence for the given multi-in-multi-out problem to its optimal configurations. Our model is based on an open source HpBandSter package. This approach combines hierarchy of several 1D Kernel Density Estimators (KDE) with a cheap evaluator (Hyperband, a single multidimensional KDE). Our model has also incorporated extrapolation based early stopping rule. With our model, we could achieve a 25% L1 norm for a large-scale BEAM simulation in fully autonomous manner. To the best of our knowledge, our work is the first of its kind applied to large-scale multi-agent transportation simulations. This work can be useful for surrogate modeling of scenarios with very large populations.
Optimizing Coordinative Schedules for Tanker Terminals: An Intelligent Large Spatial-Temporal Data-Driven Approach -- Part 2
Apr 08, 2022
In this study, a novel coordinative scheduling optimization approach is proposed to enhance port efficiency by reducing weighted average turnaround time. The proposed approach is developed as a heuristic algorithm applied and investigated through different observation windows with weekly rolling horizon paradigm method. The experimental results show that the proposed approach is effective and promising on mitigating the turnaround time of vessels. The results demonstrate that largest potential savings of turnaround time (weighted average) are around 17 hours (28%) reduction on baseline of 1-week observation, 45 hours (37%) reduction on baseline of 2-week observation and 70 hours (40%) reduction on baseline of 3-week observation. Even though the experimental results are based on historical datasets, the results potentially present significant benefits if real-time applications were applied under a quadratic computational complexity.
Pre-RTL DNN Hardware Evaluator With Fused Layer Support
May 02, 2022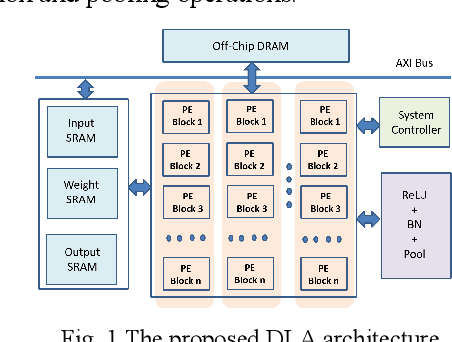
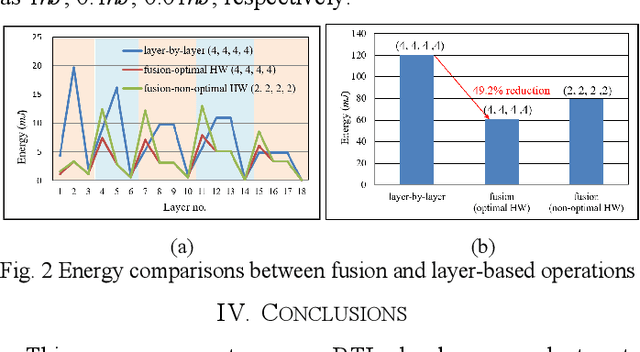
With the popularity of the deep neural network (DNN), hardware accelerators are demanded for real time execution. However, lengthy design process and fast evolving DNN models make hardware evaluation hard to meet the time to market need. This paper proposes a pre-RTL DNN hardware evaluator that supports conventional layer-by-layer processing as well as the fused layer processing for low external bandwidth requirement. The evaluator supports two state-of-the-art accelerator architectures and finds the best hardware and layer fusion group The experimental results show the layer fusion scheme can achieve 55.6% memory bandwidth reduction, 36.7% latency improvement and 49.2% energy reduction compared with layer-by-layer operation.
From Known to Unknown: Knowledge-guided Transformer for Time-Series Sales Forecasting in Alibaba
Sep 22, 2021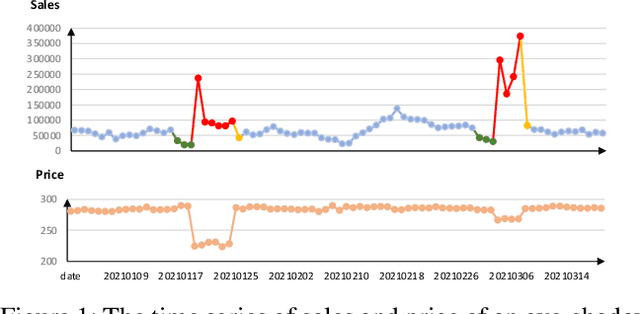
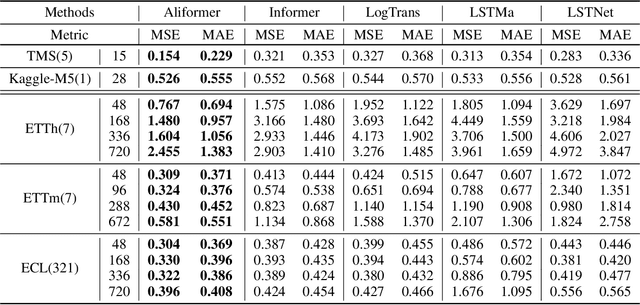
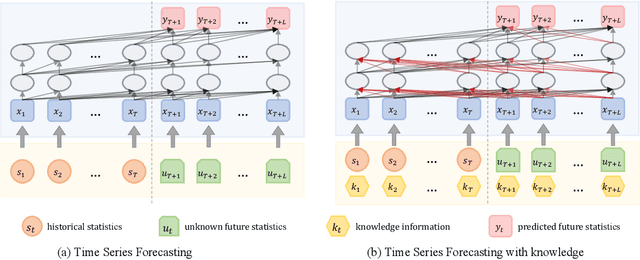
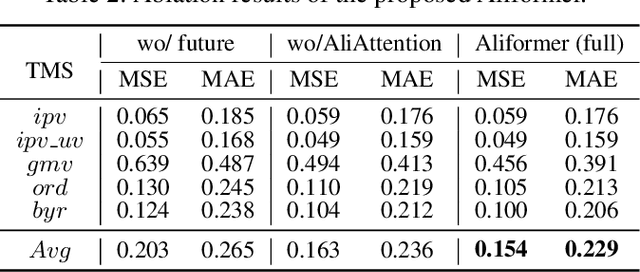
Time series forecasting (TSF) is fundamentally required in many real-world applications, such as electricity consumption planning and sales forecasting. In e-commerce, accurate time-series sales forecasting (TSSF) can significantly increase economic benefits. TSSF in e-commerce aims to predict future sales of millions of products. The trend and seasonality of products vary a lot, and the promotion activity heavily influences sales. Besides the above difficulties, we can know some future knowledge in advance except for the historical statistics. Such future knowledge may reflect the influence of the future promotion activity on current sales and help achieve better accuracy. However, most existing TSF methods only predict the future based on historical information. In this work, we make up for the omissions of future knowledge. Except for introducing future knowledge for prediction, we propose Aliformer based on the bidirectional Transformer, which can utilize the historical information, current factor, and future knowledge to predict future sales. Specifically, we design a knowledge-guided self-attention layer that uses known knowledge's consistency to guide the transmission of timing information. And the future-emphasized training strategy is proposed to make the model focus more on the utilization of future knowledge. Extensive experiments on four public benchmark datasets and one proposed large-scale industrial dataset from Tmall demonstrate that Aliformer can perform much better than state-of-the-art TSF methods. Aliformer has been deployed for goods selection on Tmall Industry Tablework, and the dataset will be released upon approval.
Markedness in Visual Semantic AI
May 23, 2022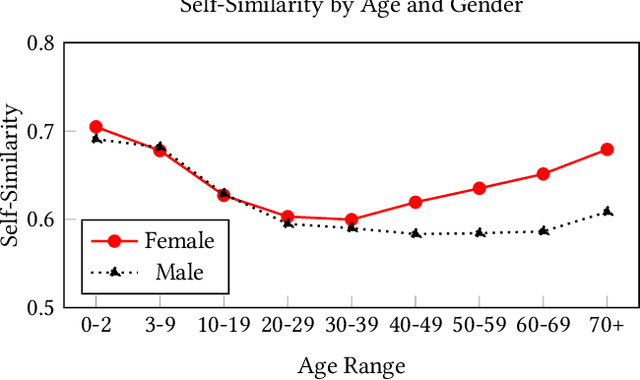
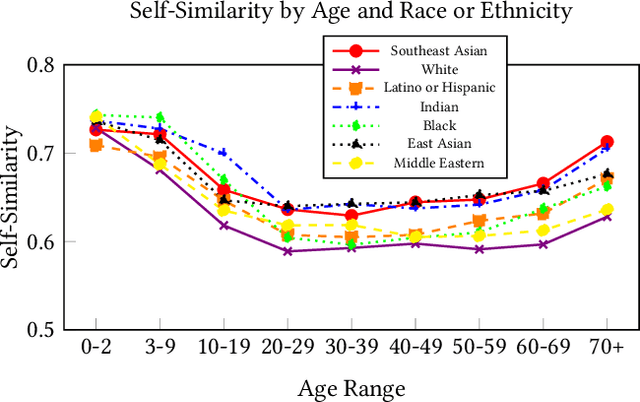

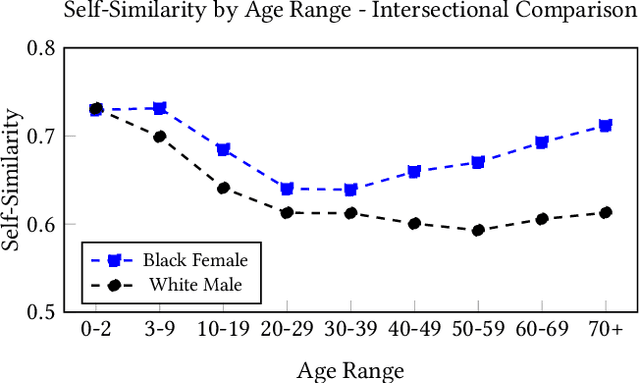
We evaluate the state-of-the-art multimodal "visual semantic" model CLIP ("Contrastive Language Image Pretraining") for biases related to the marking of age, gender, and race or ethnicity. Given the option to label an image as "a photo of a person" or to select a label denoting race or ethnicity, CLIP chooses the "person" label 47.9% of the time for White individuals, compared with 5.0% or less for individuals who are Black, East Asian, Southeast Asian, Indian, or Latino or Hispanic. The model is more likely to rank the unmarked "person" label higher than labels denoting gender for Male individuals (26.7% of the time) vs. Female individuals (15.2% of the time). Age affects whether an individual is marked by the model: Female individuals under the age of 20 are more likely than Male individuals to be marked with a gender label, but less likely to be marked with an age label, while Female individuals over the age of 40 are more likely to be marked based on age than Male individuals. We also examine the self-similarity (mean pairwise cosine similarity) for each social group, where higher self-similarity denotes greater attention directed by CLIP to the shared characteristics (age, race, or gender) of the social group. As age increases, the self-similarity of representations of Female individuals increases at a higher rate than for Male individuals, with the disparity most pronounced at the "more than 70" age range. All ten of the most self-similar social groups are individuals under the age of 10 or over the age of 70, and six of the ten are Female individuals. Existing biases of self-similarity and markedness between Male and Female gender groups are further exacerbated when the groups compared are individuals who are White and Male and individuals who are Black and Female. Results indicate that CLIP reflects the biases of the language and society which produced its training data.
C^3Net: End-to-End deep learning for efficient real-time visual active camera control
Jul 28, 2021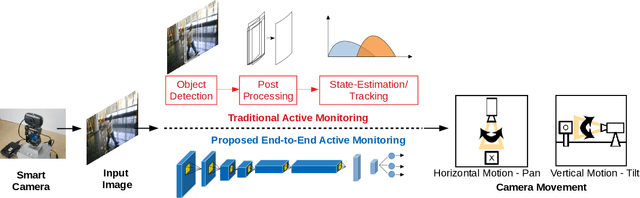
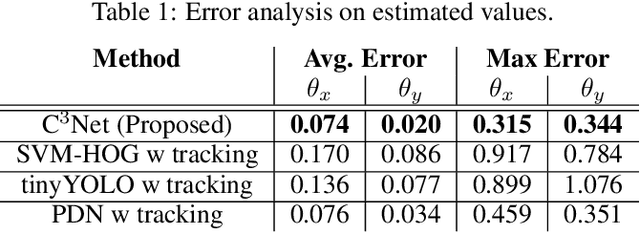
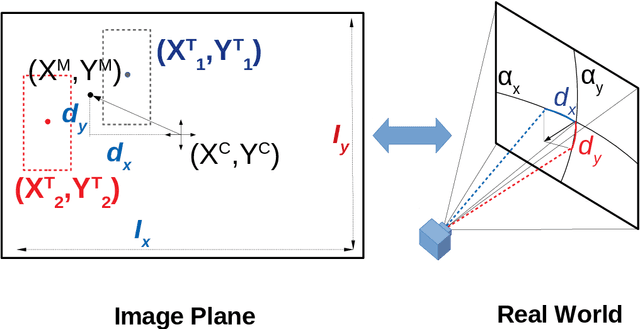
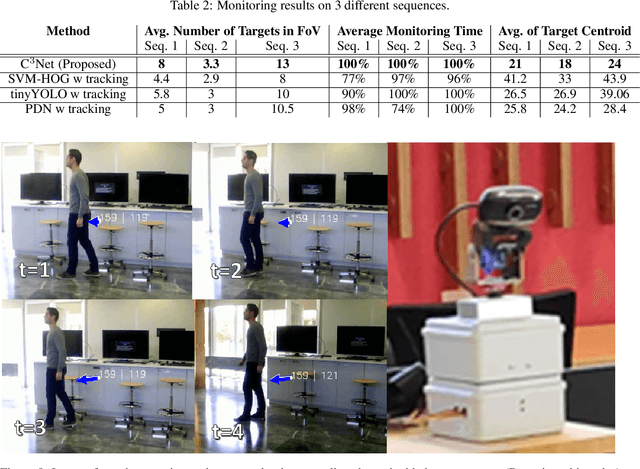
The need for automated real-time visual systems in applications such as smart camera surveillance, smart environments, and drones necessitates the improvement of methods for visual active monitoring and control. Traditionally, the active monitoring task has been handled through a pipeline of modules such as detection, filtering, and control. However, such methods are difficult to jointly optimize and tune their various parameters for real-time processing in resource constraint systems. In this paper a deep Convolutional Camera Controller Neural Network is proposed to go directly from visual information to camera movement to provide an efficient solution to the active vision problem. It is trained end-to-end without bounding box annotations to control a camera and follow multiple targets from raw pixel values. Evaluation through both a simulation framework and real experimental setup, indicate that the proposed solution is robust to varying conditions and able to achieve better monitoring performance than traditional approaches both in terms of number of targets monitored as well as in effective monitoring time. The advantage of the proposed approach is that it is computationally less demanding and can run at over 10 FPS (~4x speedup) on an embedded smart camera providing a practical and affordable solution to real-time active monitoring.
Towards a Query-Optimal and Time-Efficient Algorithm for Clustering with a Faulty Oracle
Jun 18, 2021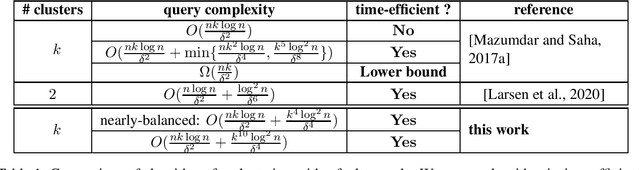
Motivated by applications in crowdsourced entity resolution in database, signed edge prediction in social networks and correlation clustering, Mazumdar and Saha [NIPS 2017] proposed an elegant theoretical model for studying clustering with a faulty oracle. In this model, given a set of $n$ items which belong to $k$ unknown groups (or clusters), our goal is to recover the clusters by asking pairwise queries to an oracle. This oracle can answer the query that ``do items $u$ and $v$ belong to the same cluster?''. However, the answer to each pairwise query errs with probability $\varepsilon$, for some $\varepsilon\in(0,\frac12)$. Mazumdar and Saha provided two algorithms under this model: one algorithm is query-optimal while time-inefficient (i.e., running in quasi-polynomial time), the other is time efficient (i.e., in polynomial time) while query-suboptimal. Larsen, Mitzenmacher and Tsourakakis [WWW 2020] then gave a new time-efficient algorithm for the special case of $2$ clusters, which is query-optimal if the bias $\delta:=1-2\varepsilon$ of the model is large. It was left as an open question whether one can obtain a query-optimal, time-efficient algorithm for the general case of $k$ clusters and other regimes of $\delta$. In this paper, we make progress on the above question and provide a time-efficient algorithm with nearly-optimal query complexity (up to a factor of $O(\log^2 n)$) for all constant $k$ and any $\delta$ in the regime when information-theoretic recovery is possible. Our algorithm is built on a connection to the stochastic block model.