 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quantile-based fuzzy clustering of multivariate time series in the frequency domain
Sep 08, 2021
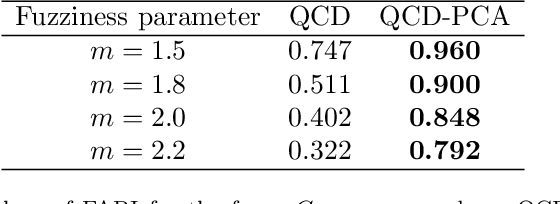
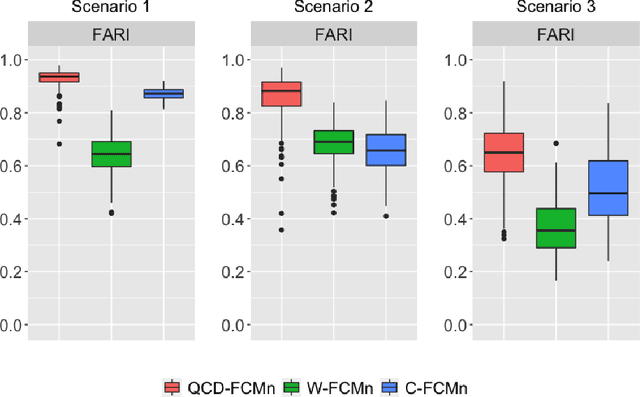
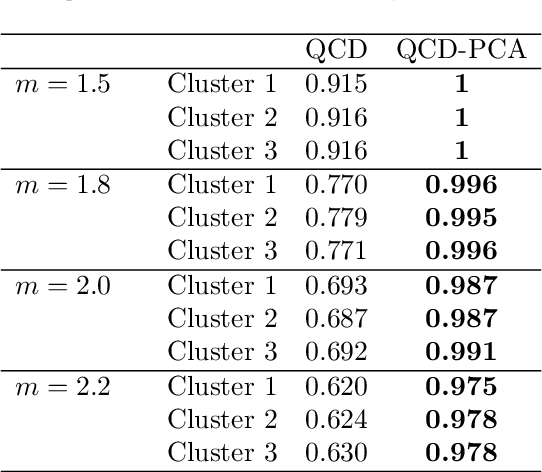
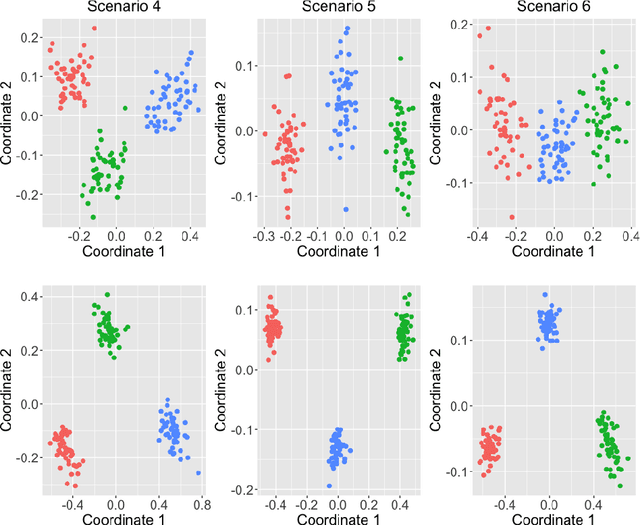
A novel procedure to perform fuzzy clustering of multivariate time series generated from different dependence models is proposed. Different amounts of dissimilarity between the generating models or changes on the dynamic behaviours over time are some arguments justifying a fuzzy approach, where each series is associated to all the clusters with specific membership levels. Our procedure considers quantile-based cross-spectral features and consists of three stages: (i) each element is characterized by a vector of proper estimates of the quantile cross-spectral densities, (ii) principal component analysis is carried out to capture the main differences reducing the effects of the noise, and (iii) the squared Euclidean distance between the first retained principal components is used to perform clustering through the standard fuzzy C-means and fuzzy C-medoids algorithms. The performance of the proposed approach is evaluated in a broad simulation study where several types of generating processes are considered, including linear, nonlinear and dynamic conditional correlation models. Assessment is done in two different ways: by directly measuring the quality of the resulting fuzzy partition and by taking into account the ability of the technique to determine the overlapping nature of series located equidistant from well-defined clusters. The procedure is compared with the few alternatives suggested in the literature, substantially outperforming all of them whatever the underlying process and the evaluation scheme. Two specific applications involving air quality and financial databases illustrate the usefulness of our approach.
Fully Sparse 3D Object Detection
Jul 20, 2022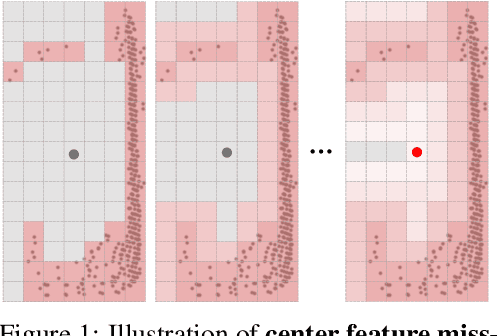
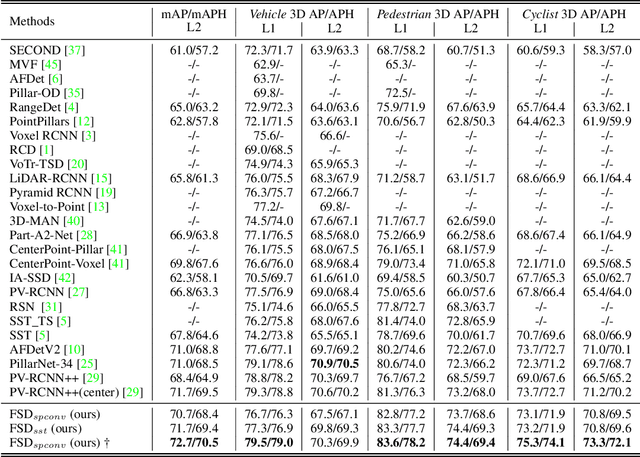
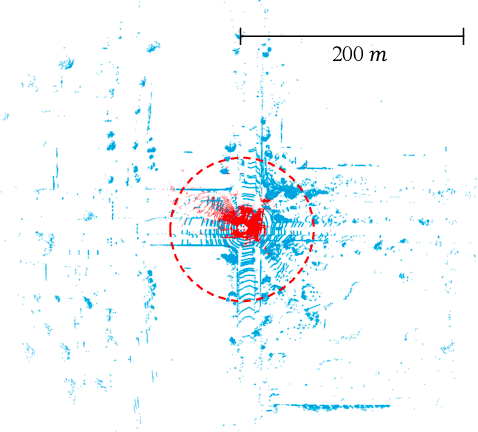
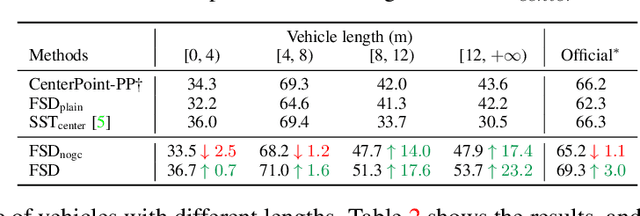
As the perception range of LiDAR increases, LiDAR-based 3D object detection becomes a dominant task in the long-range perception task of autonomous driving. The mainstream 3D object detectors usually build dense feature maps in the network backbone and prediction head. However, the computational and spatial costs on the dense feature map are quadratic to the perception range, which makes them hardly scale up to the long-range setting. To enable efficient long-range LiDAR-based object detection, we build a fully sparse 3D object detector (FSD). The computational and spatial cost of FSD is roughly linear to the number of points and independent of the perception range. FSD is built upon the general sparse voxel encoder and a novel sparse instance recognition (SIR) module. SIR first groups the points into instances and then applies instance-wise feature extraction and prediction. In this way, SIR resolves the issue of center feature missing, which hinders the design of the fully sparse architecture for all center-based or anchor-based detectors. Moreover, SIR avoids the time-consuming neighbor queries in previous point-based methods by grouping points into instances. We conduct extensive experiments on the large-scale Waymo Open Dataset to reveal the working mechanism of FSD, and state-of-the-art performance is reported. To demonstrate the superiority of FSD in long-range detection, we also conduct experiments on Argoverse 2 Dataset, which has a much larger perception range ($200m$) than Waymo Open Dataset ($75m$). On such a large perception range, FSD achieves state-of-the-art performance and is 2.4$\times$ faster than the dense counterpart.Codes will be released at https://github.com/TuSimple/SST.
Adaptive Machine Learning for Time-Varying Systems: Low Dimensional Latent Space Tuning
Jul 13, 2021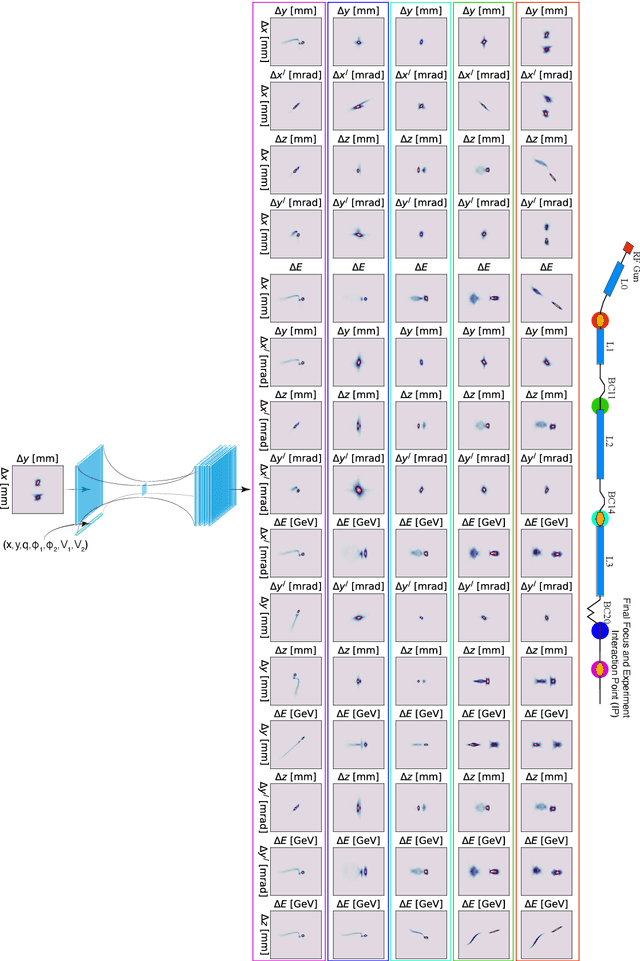
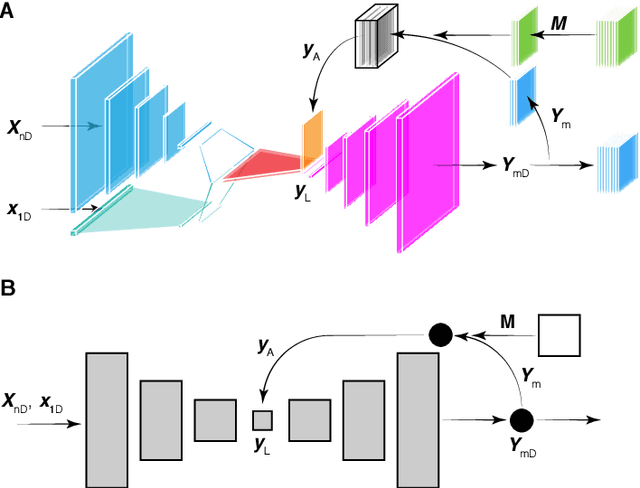
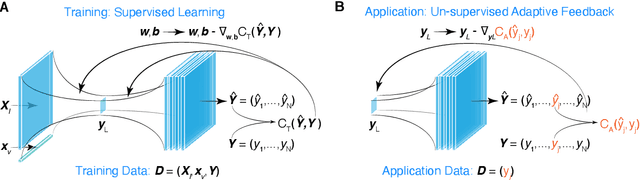
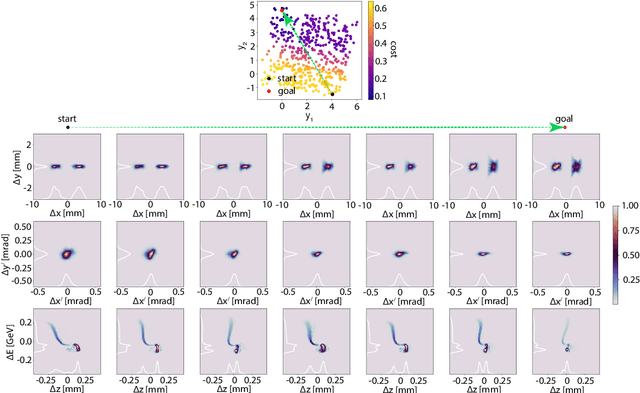
Machine learning (ML) tools such as encoder-decoder convolutional neural networks (CNN) can represent incredibly complex nonlinear functions which map between combinations of images and scalars. For example, CNNs can be used to map combinations of accelerator parameters and images which are 2D projections of the 6D phase space distributions of charged particle beams as they are transported between various particle accelerator locations. Despite their strengths, applying ML to time-varying systems, or systems with shifting distributions, is an open problem, especially for large systems for which collecting new data for re-training is impractical or interrupts operations. Particle accelerators are one example of large time-varying systems for which collecting detailed training data requires lengthy dedicated beam measurements which may no longer be available during regular operations. We present a recently developed method of adaptive ML for time-varying systems. Our approach is to map very high (N>100k) dimensional inputs (a combination of scalar parameters and images) into the low dimensional (N~2) latent space at the output of the encoder section of an encoder-decoder CNN. We then actively tune the low dimensional latent space-based representation of complex system dynamics by the addition of an adaptively tuned feedback vector directly before the decoder sections builds back up to our image-based high-dimensional phase space density representations. This method allows us to learn correlations within and to quickly tune the characteristics of incredibly high parameter systems and to track their evolution in real time based on feedback without massive new data sets for re-training.
AutoInit: Automatic Initialization via Jacobian Tuning
Jun 27, 2022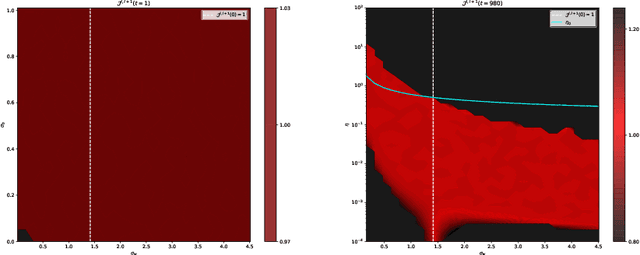
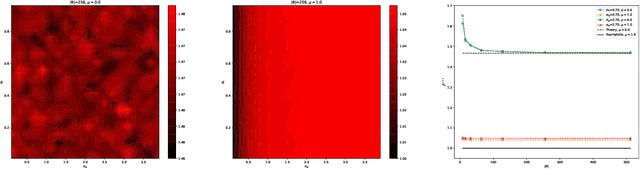
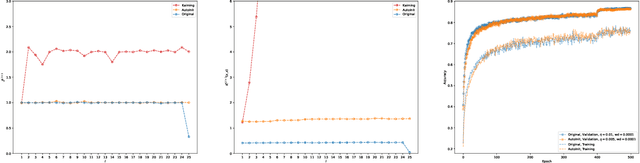
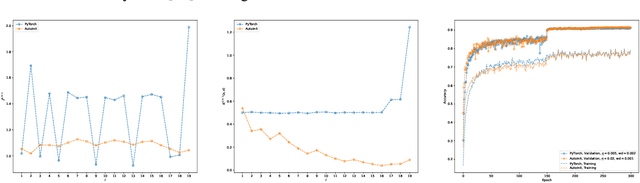
Good initialization is essential for training Deep Neural Networks (DNNs). Oftentimes such initialization is found through a trial and error approach, which has to be applied anew every time an architecture is substantially modified, or inherited from smaller size networks leading to sub-optimal initialization. In this work we introduce a new and cheap algorithm, that allows one to find a good initialization automatically, for general feed-forward DNNs. The algorithm utilizes the Jacobian between adjacent network blocks to tune the network hyperparameters to criticality. We solve the dynamics of the algorithm for fully connected networks with ReLU and derive conditions for its convergence. We then extend the discussion to more general architectures with BatchNorm and residual connections. Finally, we apply our method to ResMLP and VGG architectures, where the automatic one-shot initialization found by our method shows good performance on vision tasks.
Correctly Modeling TX and RX Chain in (Distributed) Massive MIMO -- New Fundamental Insights on Coherency
Jun 29, 2022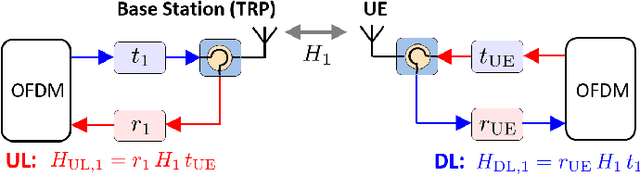
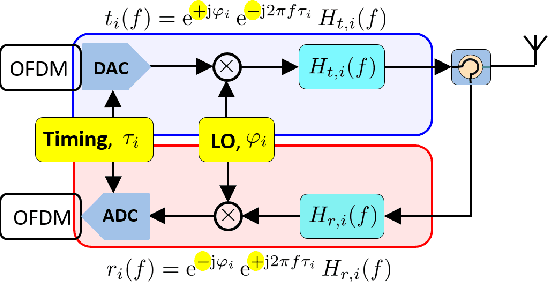
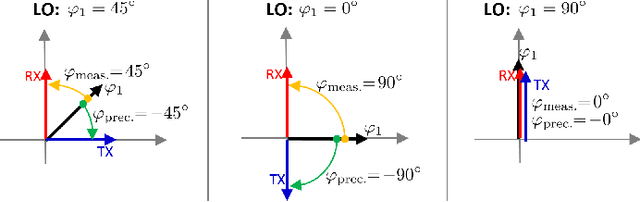
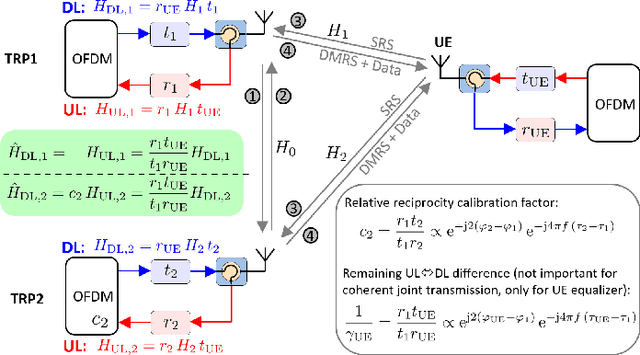
This paper shows that the TX and RX models commonly used in literature for downlink (distributed) massive MIMO are inaccurate, leading also to inaccurate conclusions. In particular, the Local Oscillator (LO) effect should be modeled as $+\phi$ in the transmitter chain and $-\phi$ in the receiver chain, i.e., different signs. A common misconception in literature is to use the same sign for both chains. By correctly modeling TX and RX chain, one realizes that the LO phases are included in the reciprocity calibration and whenever the LO phases drift apart, a new reciprocity calibration becomes necessary (the same applies to time drifts). Thus, free-running LOs and the commonly made assumption of perfect reciprocity calibration (to enable blind DL channel estimation) are both not that useful, as they would require too much calibration overhead. Instead, the LOs at the base stations should be locked and relative reciprocity calibration in combination with downlink demodulation reference symbols should be employed.
Real-time Nonrigid Mosaicking of Laparoscopy Images
Mar 12, 2021
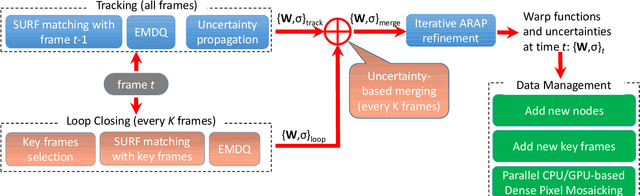
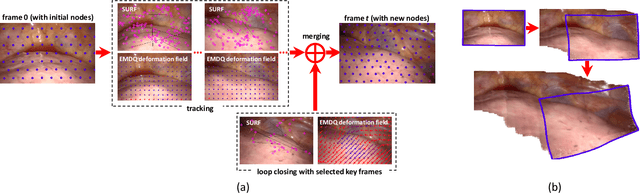
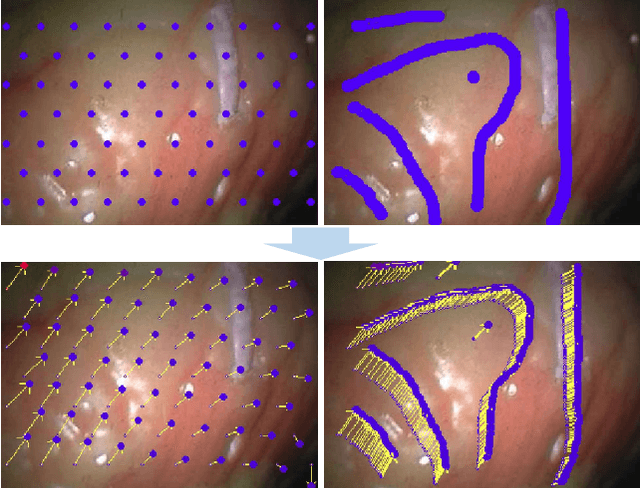
The ability to extend the field of view of laparoscopy images can help the surgeons to obtain a better understanding of the anatomical context. However, due to tissue deformation, complex camera motion and significant three-dimensional (3D) anatomical surface, image pixels may have non-rigid deformation and traditional mosaicking methods cannot work robustly for laparoscopy images in real-time. To solve this problem, a novel two-dimensional (2D) non-rigid simultaneous localization and mapping (SLAM) system is proposed in this paper, which is able to compensate for the deformation of pixels and perform image mosaicking in real-time. The key algorithm of this 2D non-rigid SLAM system is the expectation maximization and dual quaternion (EMDQ) algorithm, which can generate smooth and dense deformation field from sparse and noisy image feature matches in real-time. An uncertainty-based loop closing method has been proposed to reduce the accumulative errors. To achieve real-time performance, both CPU and GPU parallel computation technologies are used for dense mosaicking of all pixels. Experimental results on \textit{in vivo} and synthetic data demonstrate the feasibility and accuracy of our non-rigid mosaicking method.
Audio Similarity is Unreliable as a Proxy for Audio Quality
Jun 27, 2022
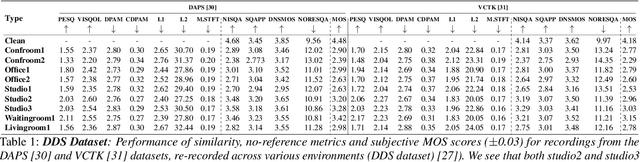

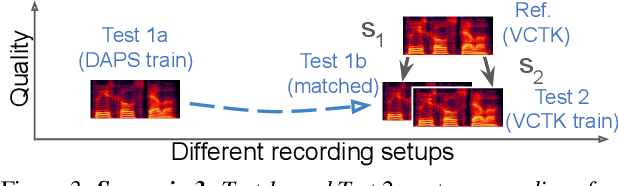
Many audio processing tasks require perceptual assessment. However, the time and expense of obtaining ``gold standard'' human judgments limit the availability of such data. Most applications incorporate full reference or other similarity-based metrics (e.g. PESQ) that depend on a clean reference. Researchers have relied on such metrics to evaluate and compare various proposed methods, often concluding that small, measured differences imply one is more effective than another. This paper demonstrates several practical scenarios where similarity metrics fail to agree with human perception, because they: (1) vary with clean references; (2) rely on attributes that humans factor out when considering quality, and (3) are sensitive to imperceptible signal level differences. In those scenarios, we show that no-reference metrics do not suffer from such shortcomings and correlate better with human perception. We conclude therefore that similarity serves as an unreliable proxy for audio quality.
GPU-Accelerated Machine Learning in Non-Orthogonal Multiple Access
Jun 13, 2022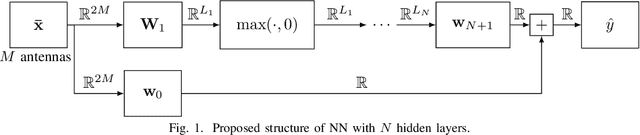

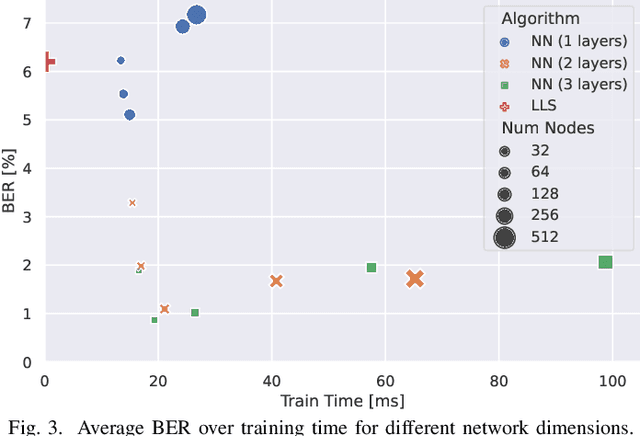
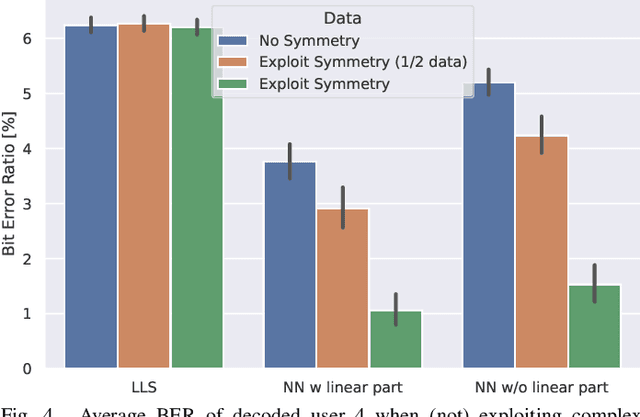
Non-orthogonal multiple access (NOMA) is an interesting technology that enables massive connectivity as required in future 5G and 6G networks. While purely linear processing already achieves good performance in NOMA systems, in certain scenarios, non-linear processing is mandatory to ensure acceptable performance. In this paper, we propose a neural network architecture that combines the advantages of both linear and non-linear processing. Its real-time detection performance is demonstrated by a highly efficient implementation on a graphics processing unit (GPU). Using real measurements in a laboratory environment, we show the superiority of our approach over conventional methods.
Physics-Embedded Neural Networks: $\boldsymbol{\mathrm{E}(n)}$-Equivariant Graph Neural PDE Solvers
May 24, 2022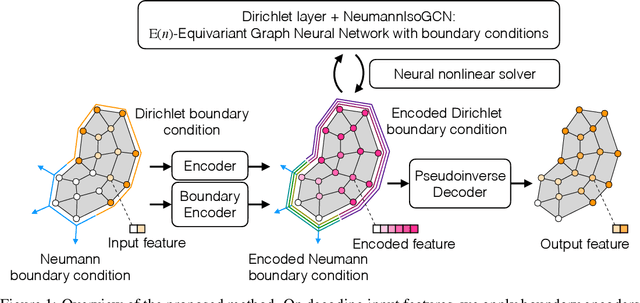
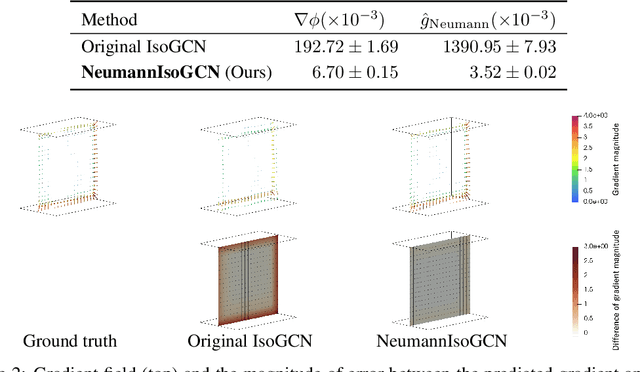

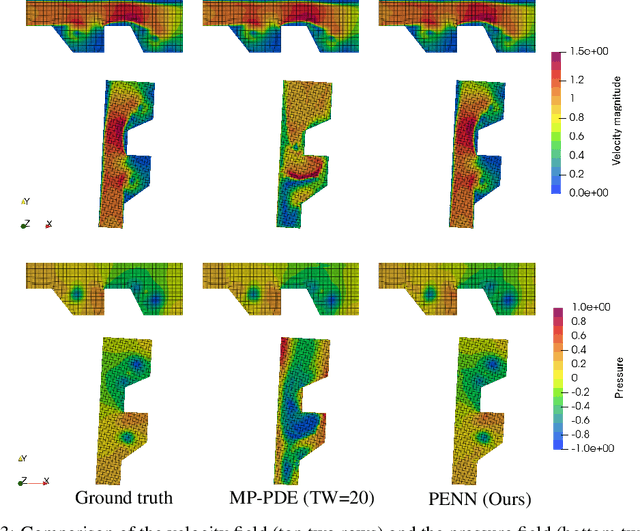
Graph neural network (GNN) is a promising approach to learning and predicting physical phenomena described in boundary value problems, such as partial differential equations (PDEs) with boundary conditions. However, existing models inadequately treat boundary conditions essential for the reliable prediction of such problems. In addition, because of the locally connected nature of GNNs, it is difficult to accurately predict the state after a long time, where interaction between vertices tends to be global. We present our approach termed physics-embedded neural networks that considers boundary conditions and predicts the state after a long time using an implicit method. It is built based on an $\mathrm{E}(n)$-equivariant GNN, resulting in high generalization performance on various shapes. We demonstrate that our model learns flow phenomena in complex shapes and outperforms a well-optimized classical solver and a state-of-the-art machine learning model in speed-accuracy trade-off. Therefore, our model can be a useful standard for realizing reliable, fast, and accurate GNN-based PDE solvers.
A Proof of the Tree of Shapes in n-D
Jun 10, 2022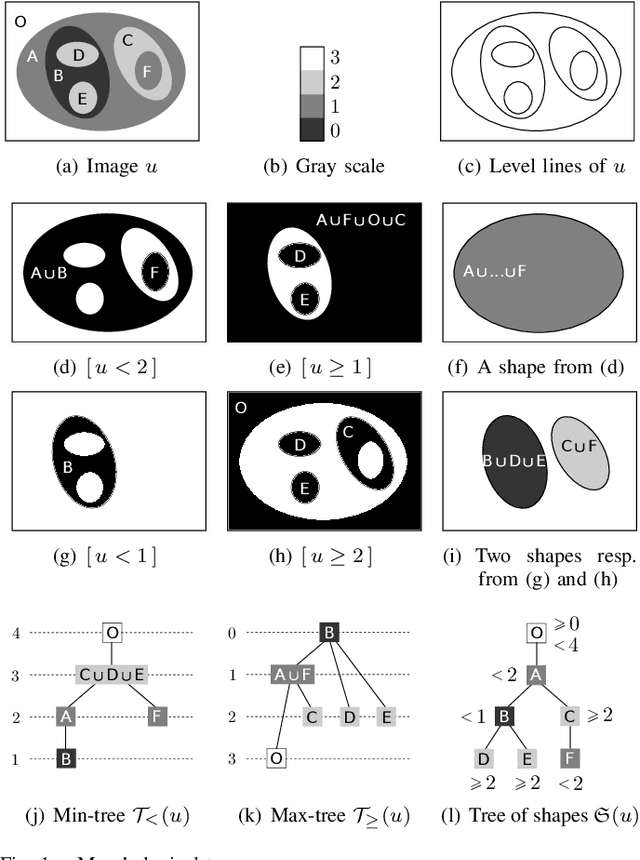
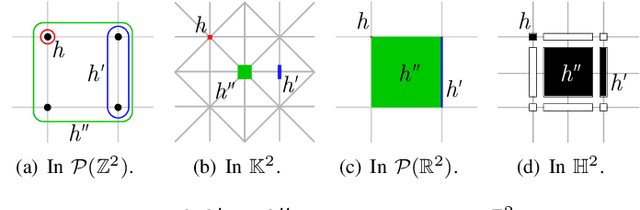
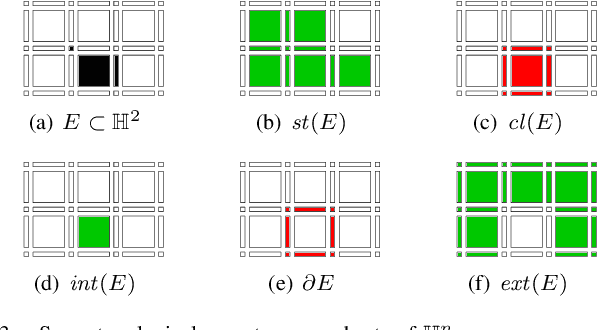
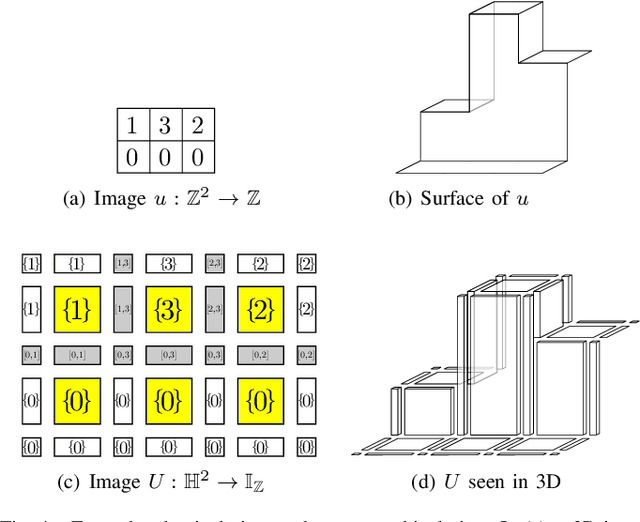
In this paper, we prove that the self-dual morphological hierarchical structure computed on a n-D gray-level wellcomposed image u by the algorithm of G{\'e}raud et al. [1] is exactly the mathematical structure defined to be the tree of shape of u in Najman et al [2]. We recall that this algorithm is in quasi-linear time and thus considered to be optimal. The tree of shapes leads to many applications in mathematical morphology and in image processing like grain filtering, shapings, image segmentation, and so on.