 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Formalizing the Problem of Side Effect Regularization
Jun 24, 2022
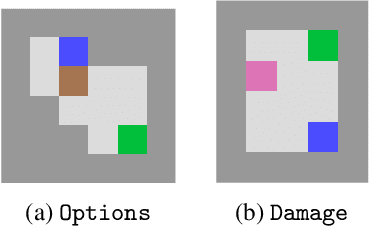
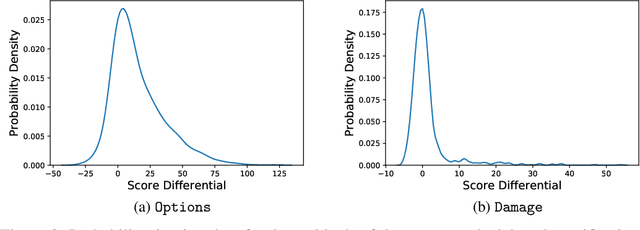
AI objectives are often hard to specify properly. Some approaches tackle this problem by regularizing the AI's side effects: Agents must weigh off "how much of a mess they make" with an imperfectly specified proxy objective. We propose a formal criterion for side effect regularization via the assistance game framework. In these games, the agent solves a partially observable Markov decision process (POMDP) representing its uncertainty about the objective function it should optimize. We consider the setting where the true objective is revealed to the agent at a later time step. We show that this POMDP is solved by trading off the proxy reward with the agent's ability to achieve a range of future tasks. We empirically demonstrate the reasonableness of our problem formalization via ground-truth evaluation in two gridworld environments.
Learning Large-scale Universal User Representation with Sparse Mixture of Experts
Jul 11, 2022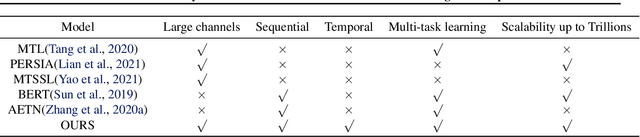
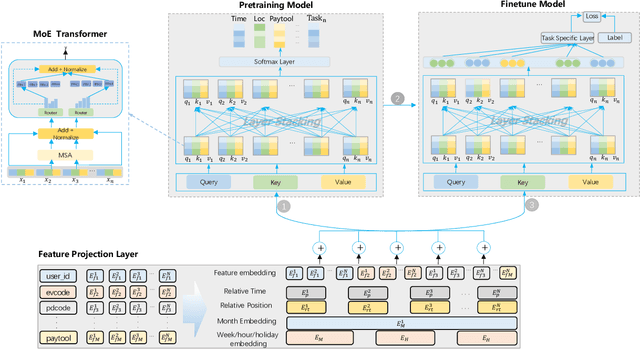
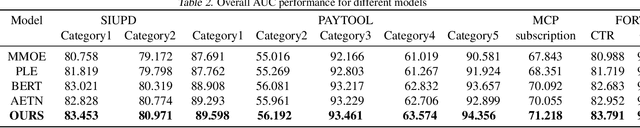
Learning user sequence behaviour embedding is very sophisticated and challenging due to the complicated feature interactions over time and high dimensions of user features. Recent emerging foundation models, e.g., BERT and its variants, encourage a large body of researchers to investigate in this field. However, unlike natural language processing (NLP) tasks, the parameters of user behaviour model come mostly from user embedding layer, which makes most existing works fail in training a universal user embedding of large scale. Furthermore, user representations are learned from multiple downstream tasks, and the past research work do not address the seesaw phenomenon. In this paper, we propose SUPERMOE, a generic framework to obtain high quality user representation from multiple tasks. Specifically, the user behaviour sequences are encoded by MoE transformer, and we can thus increase the model capacity to billions of parameters, or even to trillions of parameters. In order to deal with seesaw phenomenon when learning across multiple tasks, we design a new loss function with task indicators. We perform extensive offline experiments on public datasets and online experiments on private real-world business scenarios. Our approach achieves the best performance over state-of-the-art models, and the results demonstrate the effectiveness of our framework.
* Accepted by ICML 2022 Pre-training Workshop
Measuring Forgetting of Memorized Training Examples
Jun 30, 2022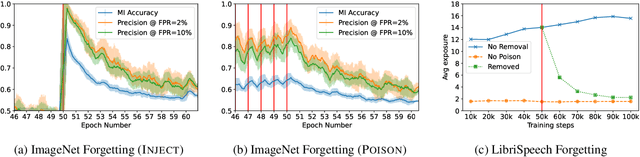
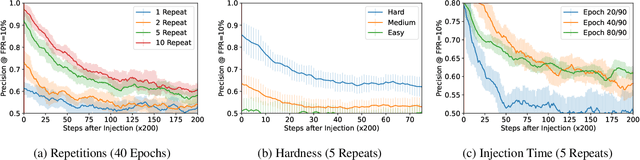
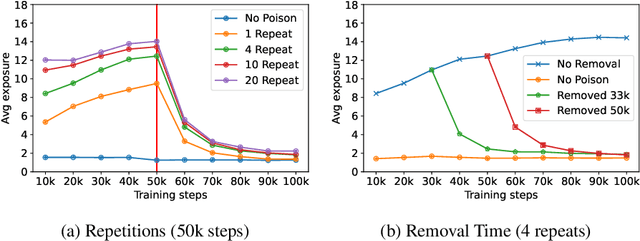
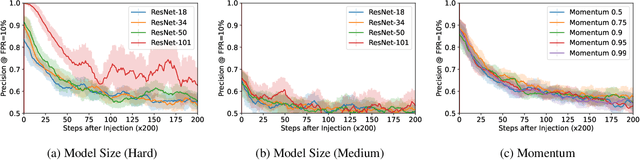
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models ``forget'' the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets -- for instance those examples used to pre-train a model -- may observe privacy benefits at the expense of examples seen later.
A Universal Error Measure for Input Predictions Applied to Online Graph Problems
May 25, 2022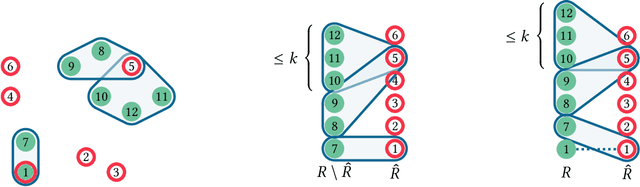
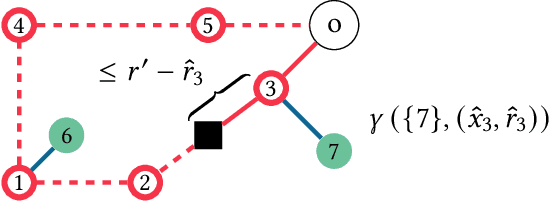
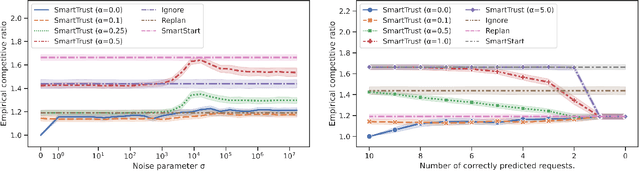
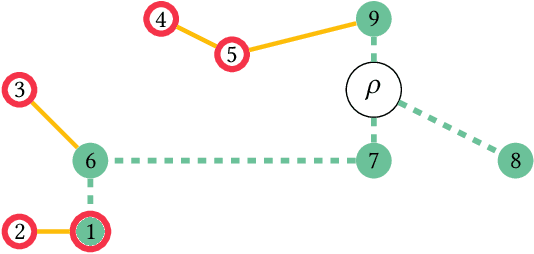
We introduce a novel measure for quantifying the error in input predictions. The error is based on a minimum-cost hyperedge cover in a suitably defined hypergraph and provides a general template which we apply to online graph problems. The measure captures errors due to absent predicted requests as well as unpredicted actual requests; hence, predicted and actual inputs can be of arbitrary size. We achieve refined performance guarantees for previously studied network design problems in the online-list model, such as Steiner tree and facility location. Further, we initiate the study of learning-augmented algorithms for online routing problems, such as the traveling salesperson problem and dial-a-ride problem, where (transportation) requests arrive over time (online-time model). We provide a general algorithmic framework and we give error-dependent performance bounds that improve upon known worst-case barriers, when given accurate predictions, at the cost of slightly increased worst-case bounds when given predictions of arbitrary quality.
Study of the performance and scalability of federated learning for medical imaging with intermittent clients
Jul 19, 2022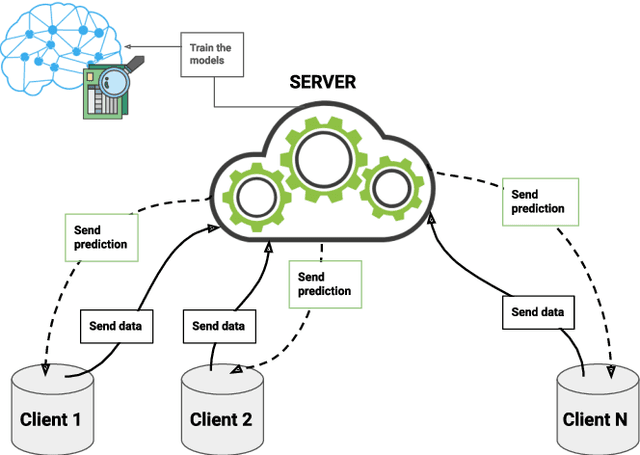
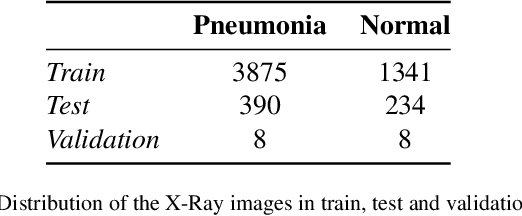
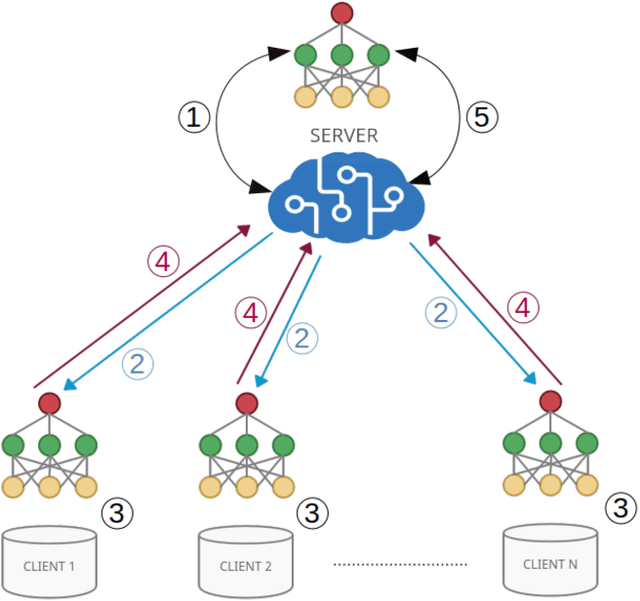
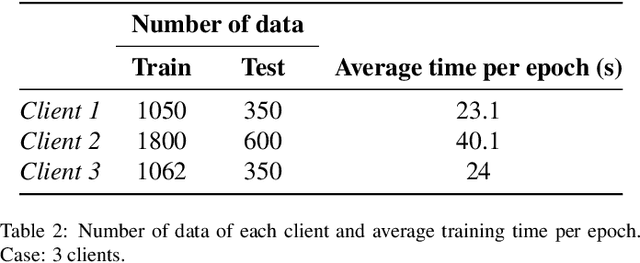
Federated learning is a data decentralization privacy-preserving technique used to perform machine or deep learning in a secure way. In this paper we present theoretical aspects about federated learning, such as the presentation of an aggregation operator, different types of federated learning, and issues to be taken into account in relation to the distribution of data from the clients, together with the exhaustive analysis of a use case where the number of clients varies. Specifically, a use case of medical image analysis is proposed, using chest X-ray images obtained from an open data repository. In addition to the advantages related to privacy, improvements in predictions (in terms of accuracy and area under the curve) and reduction of execution times will be studied with respect to the classical case (the centralized approach). Different clients will be simulated from the training data, selected in an unbalanced manner, i.e., they do not all have the same number of data. The results of considering three or ten clients are exposed and compared between them and against the centralized case. Two approaches to follow will be analyzed in the case of intermittent clients, as in a real scenario some clients may leave the training, and some new ones may enter the training. The evolution of the results for the test set in terms of accuracy, area under the curve and execution time is shown as the number of clients into which the original data is divided increases. Finally, improvements and future work in the field are proposed.
Hessian-Free Second-Order Adversarial Examples for Adversarial Learning
Jul 04, 2022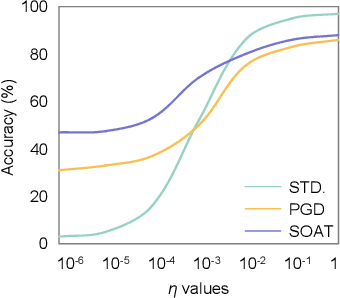
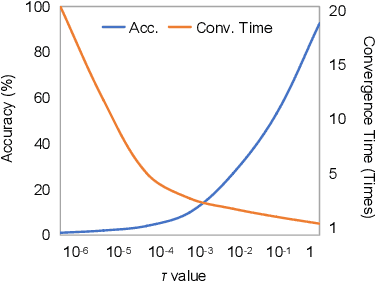
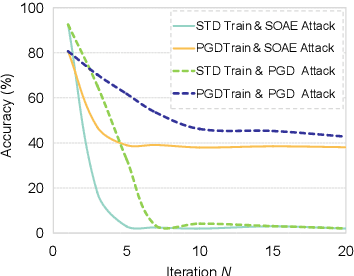
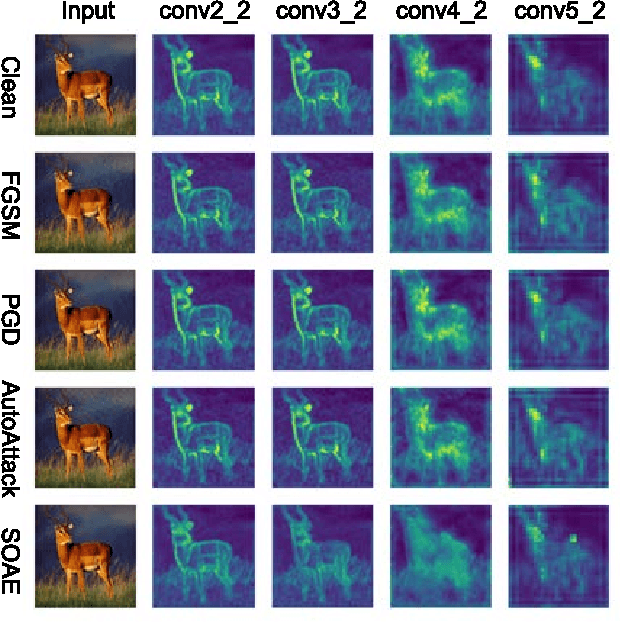
Recent studies show deep neural networks (DNNs) are extremely vulnerable to the elaborately designed adversarial examples. Adversarial learning with those adversarial examples has been proved as one of the most effective methods to defend against such an attack. At present, most existing adversarial examples generation methods are based on first-order gradients, which can hardly further improve models' robustness, especially when facing second-order adversarial attacks. Compared with first-order gradients, second-order gradients provide a more accurate approximation of the loss landscape with respect to natural examples. Inspired by this, our work crafts second-order adversarial examples and uses them to train DNNs. Nevertheless, second-order optimization involves time-consuming calculation for Hessian-inverse. We propose an approximation method through transforming the problem into an optimization in the Krylov subspace, which remarkably reduce the computational complexity to speed up the training procedure. Extensive experiments conducted on the MINIST and CIFAR-10 datasets show that our adversarial learning with second-order adversarial examples outperforms other fisrt-order methods, which can improve the model robustness against a wide range of attacks.
Stochastic Event-triggered Variational Bayesian Filtering
Jun 14, 2022
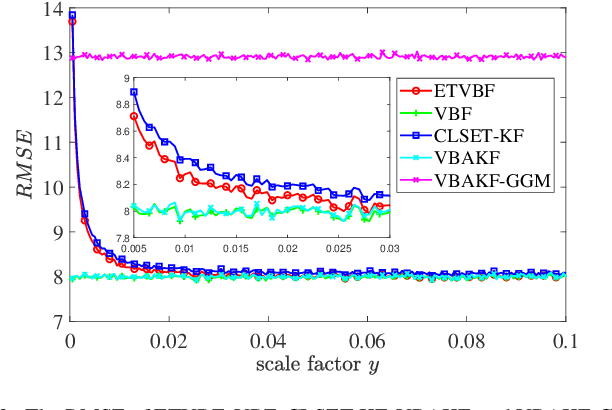
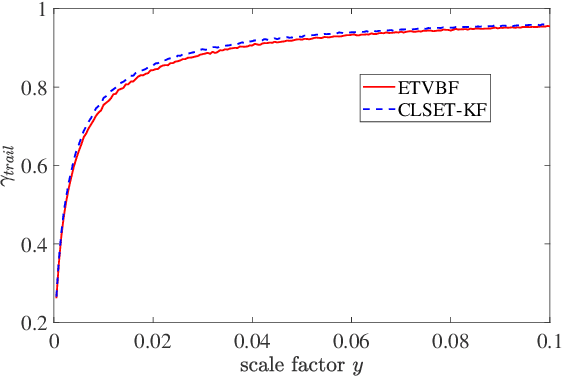
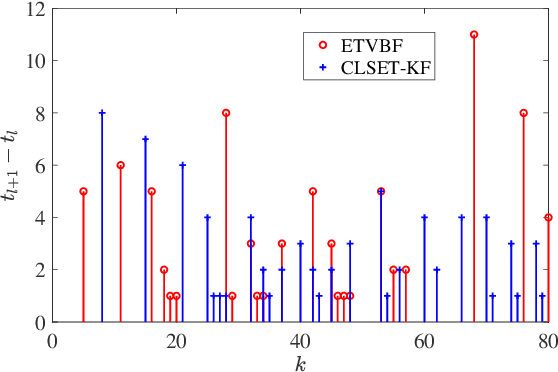
This paper proposes an event-triggered variational Bayesian filter for remote state estimation with unknown and time-varying noise covariances. After presetting multiple nominal process noise covariances and an initial measurement noise covariance, a variational Bayesian method and a fixed-point iteration method are utilized to jointly estimate the posterior state vector and the unknown noise covariances under a stochastic event-triggered mechanism. The proposed algorithm ensures low communication loads and excellent estimation performances for a wide range of unknown noise covariances. Finally, the performance of the proposed algorithm is demonstrated by tracking simulations of a vehicle.
A multi-level interpretable sleep stage scoring system by infusing experts' knowledge into a deep network architecture
Jul 11, 2022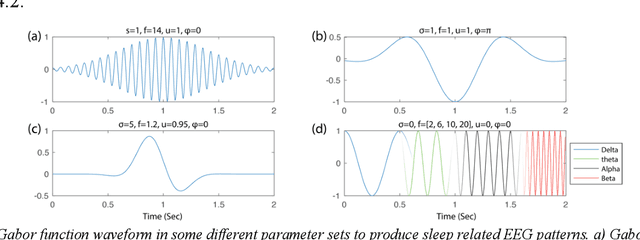
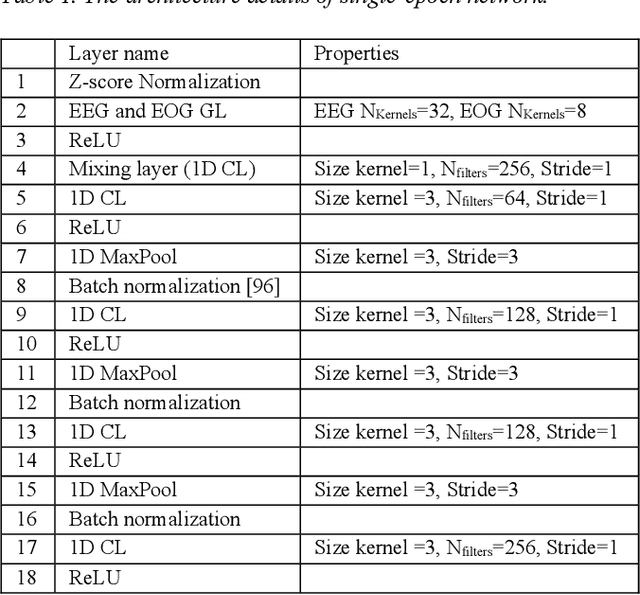
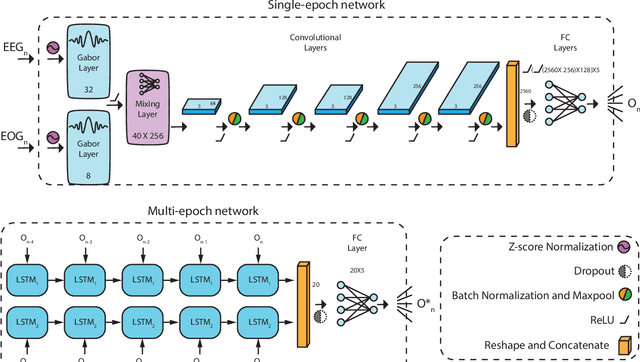
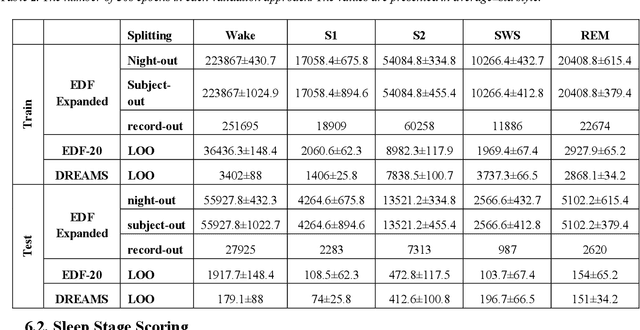
In recent years, deep learning has shown potential and efficiency in a wide area including computer vision, image and signal processing. Yet, translational challenges remain for user applications due to a lack of interpretability of algorithmic decisions and results. This black box problem is particularly problematic for high-risk applications such as medical-related decision-making. The current study goal was to design an interpretable deep learning system for time series classification of electroencephalogram (EEG) for sleep stage scoring as a step toward designing a transparent system. We have developed an interpretable deep neural network that includes a kernel-based layer based on a set of principles used for sleep scoring by human experts in the visual analysis of polysomnographic records. A kernel-based convolutional layer was defined and used as the first layer of the system and made available for user interpretation. The trained system and its results were interpreted in four levels from the microstructure of EEG signals, such as trained kernels and the effect of each kernel on the detected stages, to macrostructures, such as the transition between stages. The proposed system demonstrated greater performance than prior studies and the results of interpretation showed that the system learned information which was consistent with expert knowledge.
LIFE: Learning Individual Features for Multivariate Time Series Prediction with Missing Values
Oct 09, 2021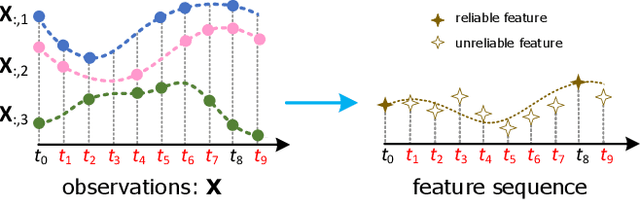
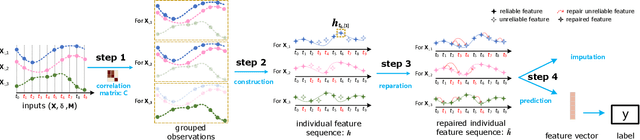
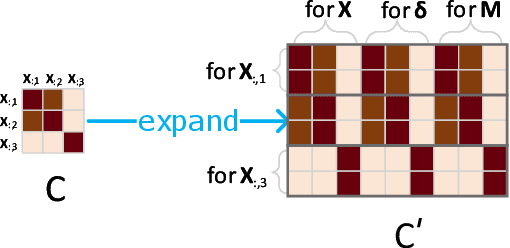
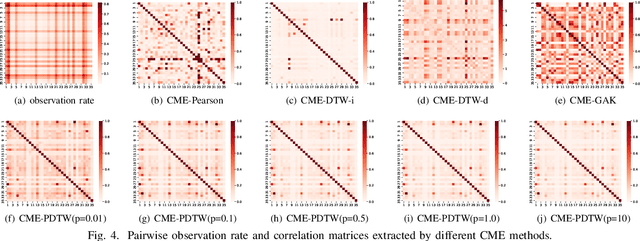
Multivariate time series (MTS) prediction is ubiquitous in real-world fields, but MTS data often contains missing values. In recent years, there has been an increasing interest in using end-to-end models to handle MTS with missing values. To generate features for prediction, existing methods either merge all input dimensions of MTS or tackle each input dimension independently. However, both approaches are hard to perform well because the former usually produce many unreliable features and the latter lacks correlated information. In this paper, we propose a Learning Individual Features (LIFE) framework, which provides a new paradigm for MTS prediction with missing values. LIFE generates reliable features for prediction by using the correlated dimensions as auxiliary information and suppressing the interference from uncorrelated dimensions with missing values. Experiments on three real-world data sets verify the superiority of LIFE to existing state-of-the-art models.
Personalized QoE Enhancement for Adaptive Video Streaming: A Digital Twin-Assisted Scheme
May 09, 2022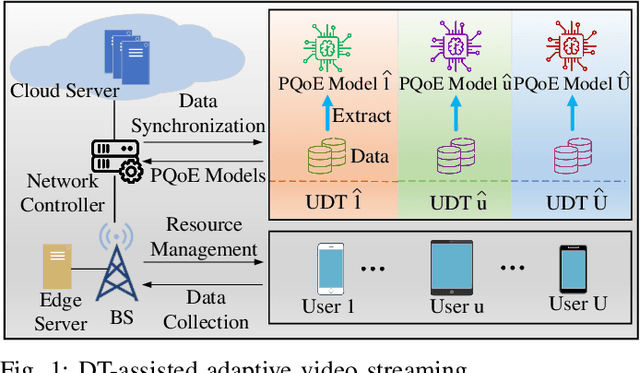
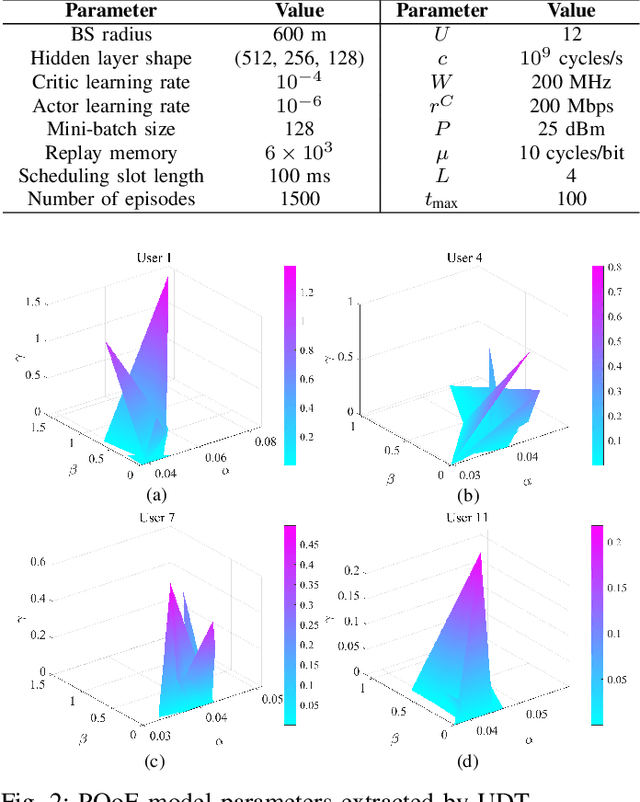
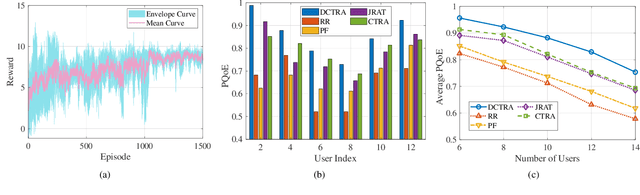
In this paper, we present a digital twin (DT)-assisted adaptive video streaming scheme to enhance personalized quality-of-experience (PQoE). Since PQoE models are user-specific and time-varying, existing schemes based on universal and time-invariant PQoE models may suffer from performance degradation. To address this issue, we first propose a DT-assisted PQoE model construction method to obtain accurate user-specific PQoE models. Specifically, user DTs (UDTs) are respectively constructed for individual users, which can acquire and utilize users' data to accurately tune PQoE model parameters in real time. Next, given the obtained PQoE models, we formulate a resource management problem to maximize the overall long-term PQoE by taking the dynamics of user' locations, video content requests, and buffer statuses into account. To solve this problem, a deep reinforcement learning algorithm is developed to jointly determine segment version selection, and communication and computing resource allocation. Simulation results on the real-world dataset demonstrate that the proposed scheme can effectively enhance PQoE compared with benchmark schemes.