 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Learning Algorithms for Keyword Extraction in an Undergraduate Thesis
Jun 23, 2022

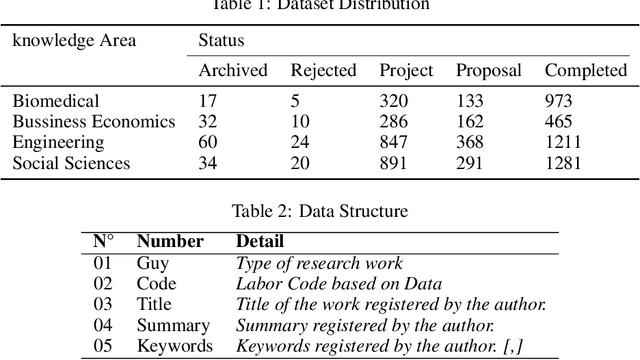
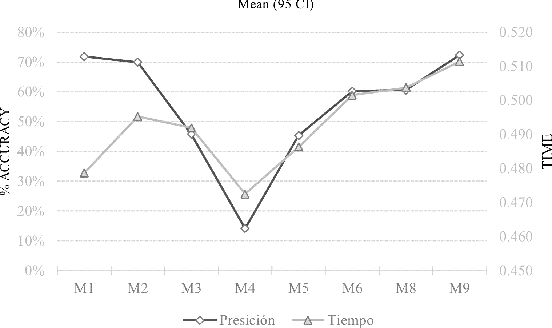
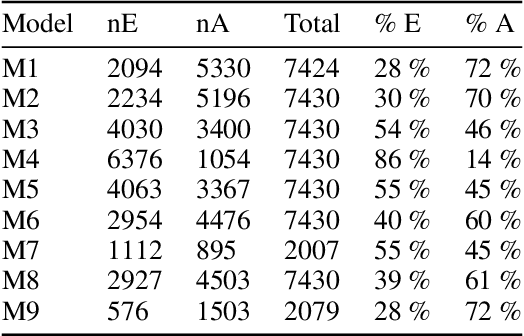
The amount of data managed in many academic institutions has increased in recent years, particularly in all the research work done by undergraduate students, who simply use empirical techniques for keyword selection, forgetting existing technical methods to assist their students in this process. Information and communication technologies, such as the platform for integrated research and academic work with responsibility (PILAR), which records information about research projects, such as titles, summaries, and keywords in their various modalities, have gained relevance and importance in the management of these. We proved algorithms with these records of research projects that have been analysed in this study, and predictions were made for each of the nine (09) models of unsupervised machine learning algorithms that were implemented for each of the 7430 records from the dataset. The most efficient way of extracting keywords for this dataset was the TF-IDF method, obtaining 72% accuracy and [0.4786, SD 0.0501] in average extraction time for each thesis file processed by this model.
Transferability-Guided Cross-Domain Cross-Task Transfer Learning
Jul 12, 2022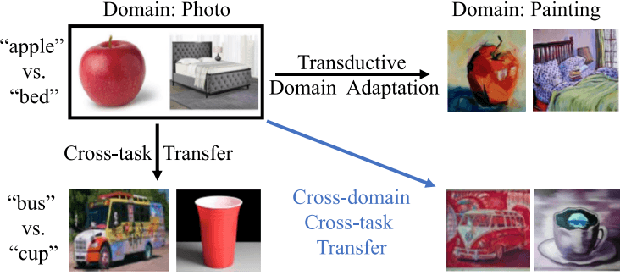
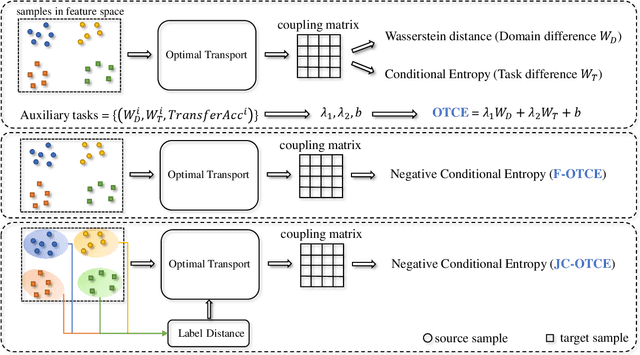
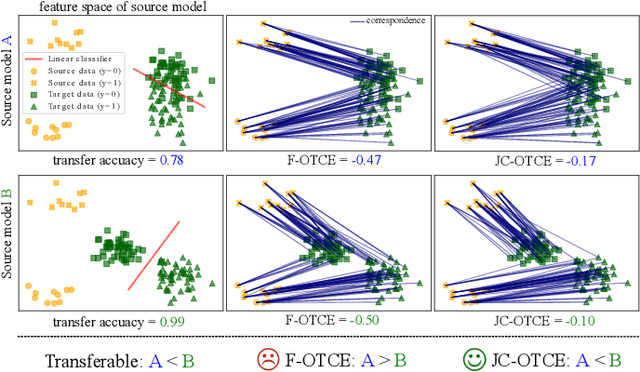
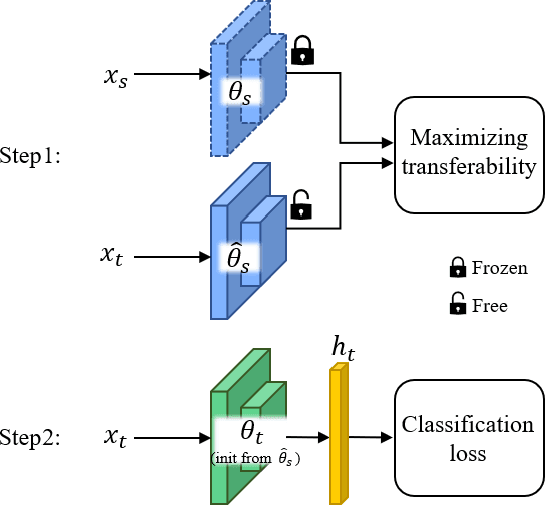
We propose two novel transferability metrics F-OTCE (Fast Optimal Transport based Conditional Entropy) and JC-OTCE (Joint Correspondence OTCE) to evaluate how much the source model (task) can benefit the learning of the target task and to learn more transferable representations for cross-domain cross-task transfer learning. Unlike the existing metric that requires evaluating the empirical transferability on auxiliary tasks, our metrics are auxiliary-free such that they can be computed much more efficiently. Specifically, F-OTCE estimates transferability by first solving an Optimal Transport (OT) problem between source and target distributions, and then uses the optimal coupling to compute the Negative Conditional Entropy between source and target labels. It can also serve as a loss function to maximize the transferability of the source model before finetuning on the target task. Meanwhile, JC-OTCE improves the transferability robustness of F-OTCE by including label distances in the OT problem, though it may incur additional computation cost. Extensive experiments demonstrate that F-OTCE and JC-OTCE outperform state-of-the-art auxiliary-free metrics by 18.85% and 28.88%, respectively in correlation coefficient with the ground-truth transfer accuracy. By eliminating the training cost of auxiliary tasks, the two metrics reduces the total computation time of the previous method from 43 minutes to 9.32s and 10.78s, respectively, for a pair of tasks. When used as a loss function, F-OTCE shows consistent improvements on the transfer accuracy of the source model in few-shot classification experiments, with up to 4.41% accuracy gain.
Recurrent segmentation meets block models in temporal networks
May 19, 2022
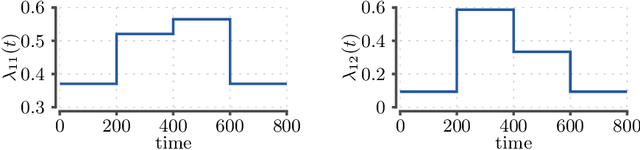


A popular approach to model interactions is to represent them as a network with nodes being the agents and the interactions being the edges. Interactions are often timestamped, which leads to having timestamped edges. Many real-world temporal networks have a recurrent or possibly cyclic behaviour. For example, social network activity may be heightened during certain hours of day. In this paper, our main interest is to model recurrent activity in such temporal networks. As a starting point we use stochastic block model, a popular choice for modelling static networks, where nodes are split into $R$ groups. We extend this model to temporal networks by modelling the edges with a Poisson process. We make the parameters of the process dependent on time by segmenting the time line into $K$ segments. To enforce the recurring activity we require that only $H < K$ different set of parameters can be used, that is, several, not necessarily consecutive, segments must share their parameters. We prove that the searching for optimal blocks and segmentation is an NP-hard problem. Consequently, we split the problem into 3 subproblems where we optimize blocks, model parameters, and segmentation in turn while keeping the remaining structures fixed. We propose an iterative algorithm that requires $O(KHm + Rn + R^2H)$ time per iteration, where $n$ and $m$ are the number of nodes and edges in the network. We demonstrate experimentally that the number of required iterations is typically low, the algorithm is able to discover the ground truth from synthetic datasets, and show that certain real-world networks exhibit recurrent behaviour as the likelihood does not deteriorate when $H$ is lowered.
PyDaddy: A Python package for discovering stochastic dynamical equations from timeseries data
May 05, 2022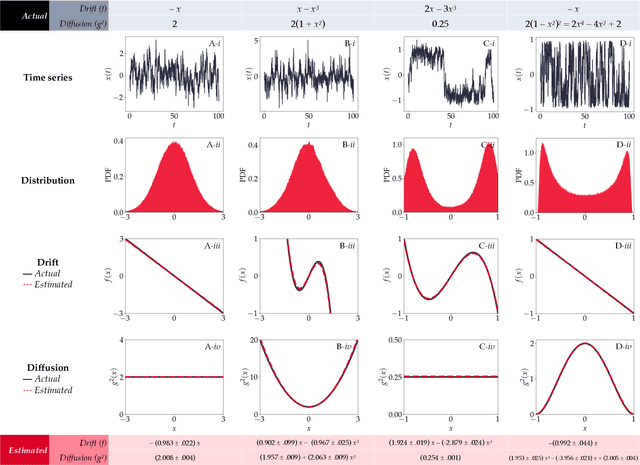
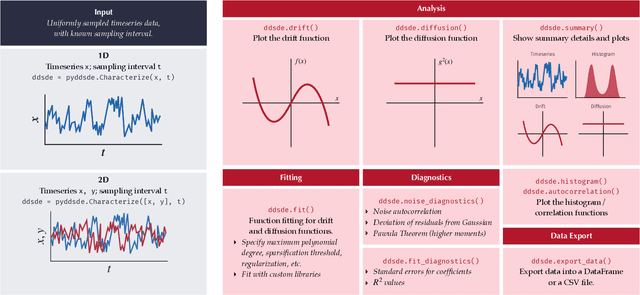
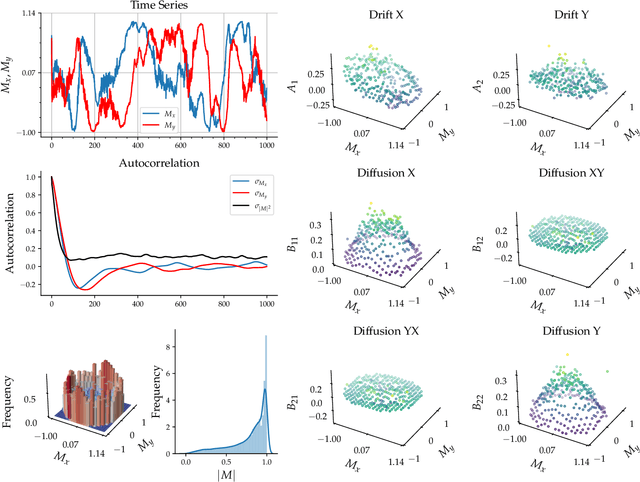
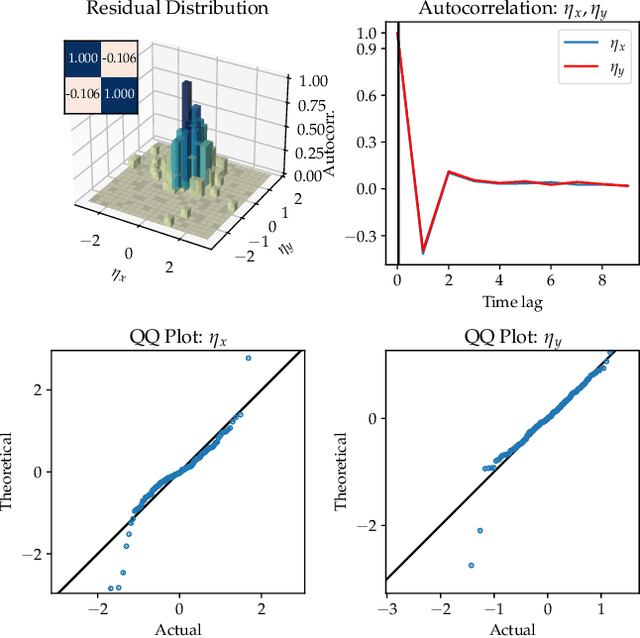
Most real-world ecological dynamics, ranging from ecosystem dynamics to collective animal movement, are inherently stochastic in nature. Stochastic differential equations (SDEs) are a popular modelling framework to model dynamics with intrinsic randomness. Here, we focus on the inverse question: If one has empirically measured time-series data from some system of interest, is it possible to discover the SDE model that best describes the data. Here, we present PyDaddy (PYthon library for DAta Driven DYnamics), a toolbox to construct and analyze interpretable SDE models based on time-series data. We combine traditional approaches for data-driven SDE reconstruction with an equation learning approach, to derive symbolic equations governing the stochastic dynamics. The toolkit is presented as an open-source Python library, and consists of tools to construct and analyze SDEs. Functionality is included for visual examination of the stochastic structure of the data, guided extraction of the functional form of the SDE, and diagnosis and debugging of the underlying assumptions and the extracted model. Using simulated time-series datasets, exhibiting a wide range of dynamics, we show that PyDaddy is able to correctly identify underlying SDE models. We demonstrate the applicability of the toolkit to real-world data using a previously published movement data of a fish school. Starting from the time-series of the observed polarization of the school, pyDaddy readily discovers the SDE model governing the dynamics of group polarization. The model recovered by PyDaddy is consistent with the previous study. In summary, stochastic and noise-induced effects are central to the dynamics of many biological systems. In this context, we present an easy-to-use package to reconstruct SDEs from timeseries data.
Learn Fast, Segment Well: Fast Object Segmentation Learning on the iCub Robot
Jun 27, 2022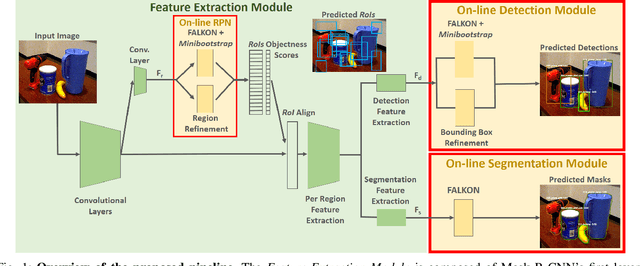

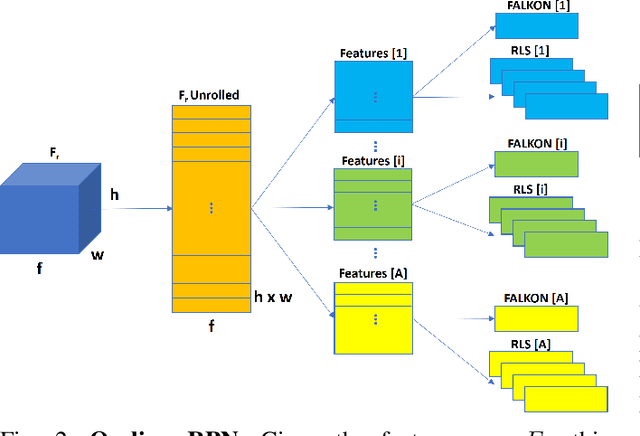

The visual system of a robot has different requirements depending on the application: it may require high accuracy or reliability, be constrained by limited resources or need fast adaptation to dynamically changing environments. In this work, we focus on the instance segmentation task and provide a comprehensive study of different techniques that allow adapting an object segmentation model in presence of novel objects or different domains. We propose a pipeline for fast instance segmentation learning designed for robotic applications where data come in stream. It is based on an hybrid method leveraging on a pre-trained CNN for feature extraction and fast-to-train Kernel-based classifiers. We also propose a training protocol that allows to shorten the training time by performing feature extraction during the data acquisition. We benchmark the proposed pipeline on two robotics datasets and we deploy it on a real robot, i.e. the iCub humanoid. To this aim, we adapt our method to an incremental setting in which novel objects are learned on-line by the robot. The code to reproduce the experiments is publicly available on GitHub.
OPerA: Object-Centric Performance Analysis
Apr 22, 2022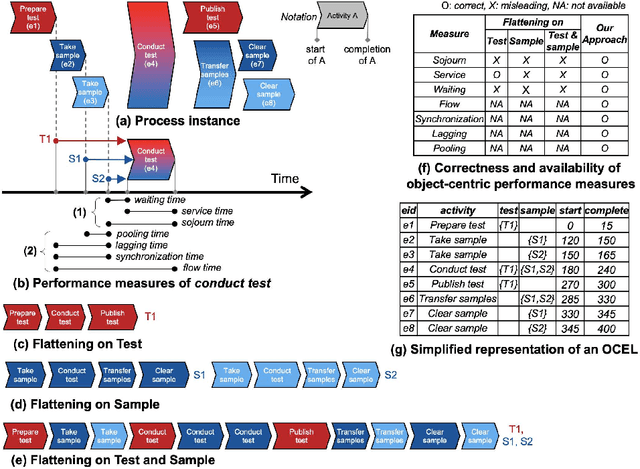
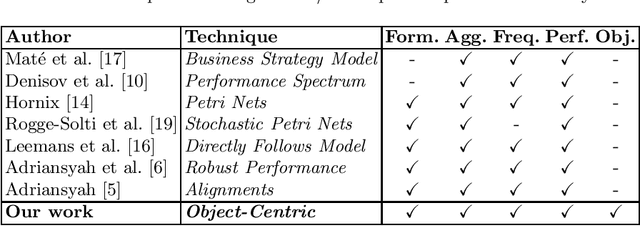
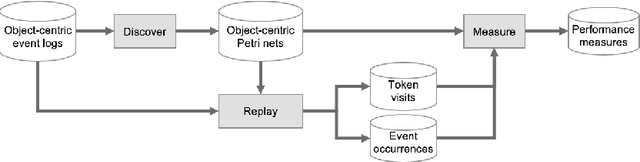
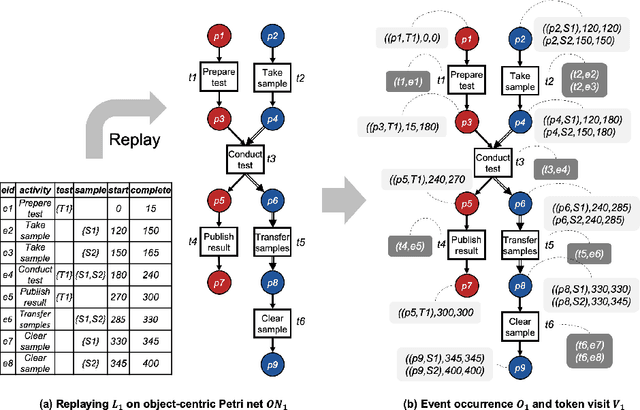
Performance analysis in process mining aims to provide insights on the performance of a business process by using a process model as a formal representation of the process. Such insights are reliably interpreted by process analysts in the context of a model with formal semantics. Existing techniques for performance analysis assume that a single case notion exists in a business process (e.g., a patient in healthcare process). However, in reality, different objects might interact (e.g., order, item, delivery, and invoice in an O2C process). In such a setting, traditional techniques may yield misleading or even incorrect insights on performance metrics such as waiting time. More importantly, by considering the interaction between objects, we can define object-centric performance metrics such as synchronization time, pooling time, and lagging time. In this work, we propose a novel approach to performance analysis considering multiple case notions by using object-centric Petri nets as formal representations of business processes. The proposed approach correctly computes existing performance metrics, while supporting the derivation of newly-introduced object-centric performance metrics. We have implemented the approach as a web application and conducted a case study based on a real-life loan application process.
A novel conservative chaos driven dynamic DNA coding for image encryption
Jul 12, 2022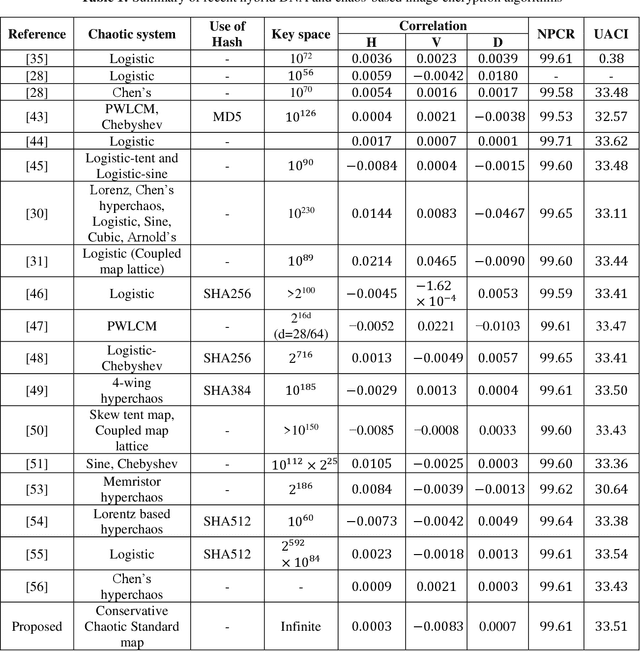
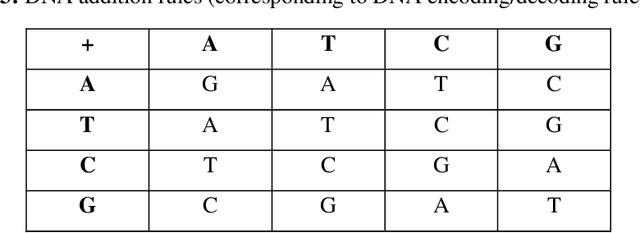
In this paper, we propose a novel conservative chaotic standard map-driven dynamic DNA coding (encoding, addition, subtraction and decoding) for the image encryption. The proposed image encryption algorithm is a dynamic DNA coding algorithm i.e., for the encryption of each pixel different rules for encoding, addition/subtraction, decoding etc. are randomly selected based on the pseudorandom sequences generated with the help of the conservative chaotic standard map. We propose a novel way to generate pseudo-random sequences through the conservative chaotic standard map and also test them rigorously through the most stringent test suite of pseudo-randomness, the NIST test suite, before using them in the proposed image encryption algorithm. Our image encryption algorithm incorporates a unique feed-forward and feedback mechanisms to generate and modify the dynamic one-time pixels that are further used for the encryption of each pixel of the plain image, therefore, bringing in the desired sensitivity on plaintext as well as ciphertext. All the controlling pseudorandom sequences used in the algorithm are generated for a different value of the parameter (part of the secret key) with inter-dependency through the iterates of the chaotic map (in the generation process) and therefore possess extreme key sensitivity too. The performance and security analysis has been executed extensively through histogram analysis, correlation analysis, information entropy analysis, DNA sequence-based analysis, perceptual quality analysis, key sensitivity analysis, plaintext sensitivity analysis, etc., The results are promising and prove the robustness of the algorithm against various common cryptanalytic attacks.
Interpretable Acoustic Representation Learning on Breathing and Speech Signals for COVID-19 Detection
Jun 27, 2022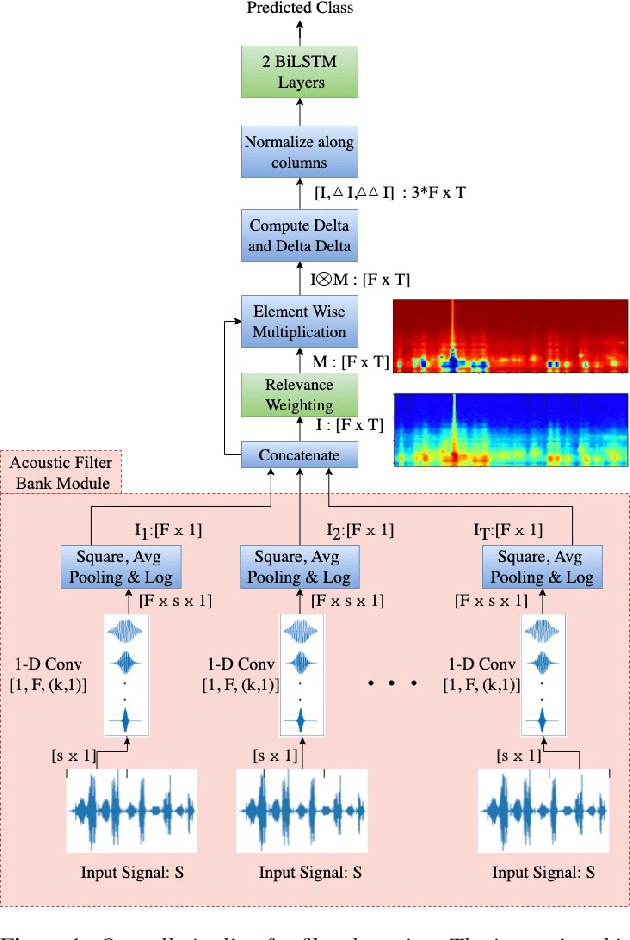
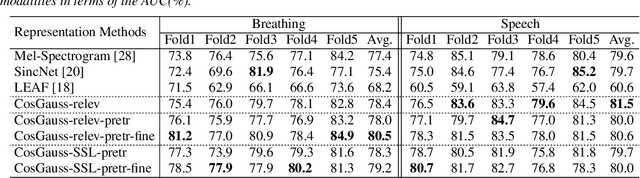
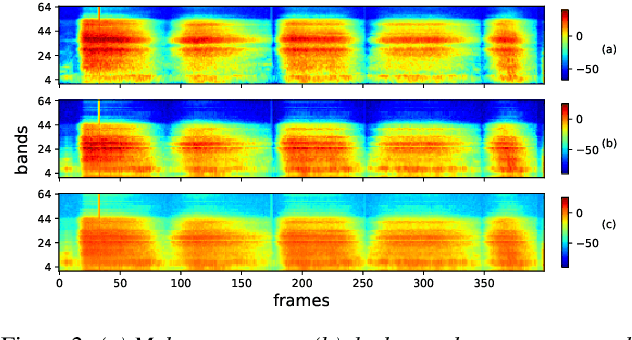
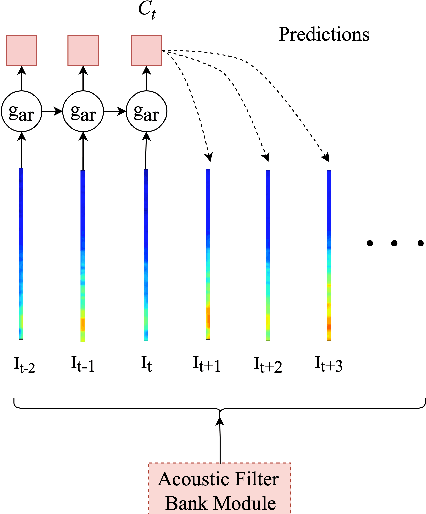
In this paper, we describe an approach for representation learning of audio signals for the task of COVID-19 detection. The raw audio samples are processed with a bank of 1-D convolutional filters that are parameterized as cosine modulated Gaussian functions. The choice of these kernels allows the interpretation of the filterbanks as smooth band-pass filters. The filtered outputs are pooled, log-compressed and used in a self-attention based relevance weighting mechanism. The relevance weighting emphasizes the key regions of the time-frequency decomposition that are important for the downstream task. The subsequent layers of the model consist of a recurrent architecture and the models are trained for a COVID-19 detection task. In our experiments on the Coswara data set, we show that the proposed model achieves significant performance improvements over the baseline system as well as other representation learning approaches. Further, the approach proposed is shown to be uniformly applicable for speech and breathing signals and for transfer learning from a larger data set.
Factorized Structured Regression for Large-Scale Varying Coefficient Models
May 25, 2022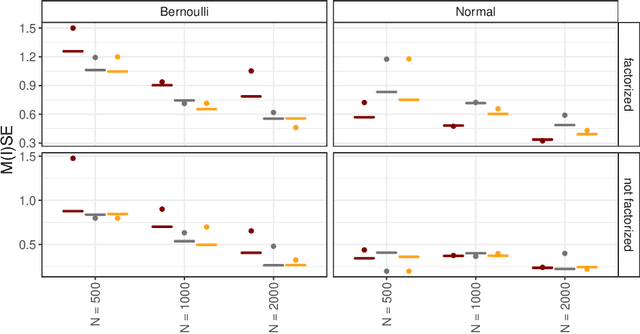
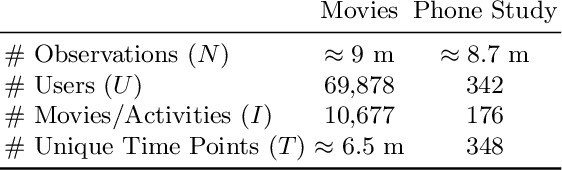
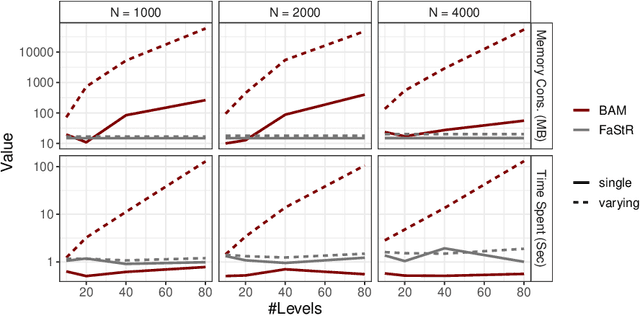
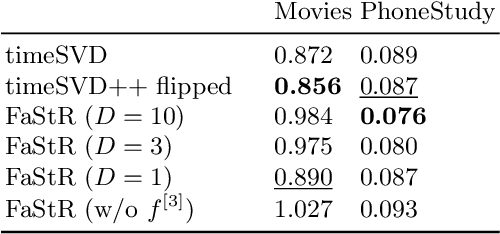
Recommender Systems (RS) pervade many aspects of our everyday digital life. Proposed to work at scale, state-of-the-art RS allow the modeling of thousands of interactions and facilitate highly individualized recommendations. Conceptually, many RS can be viewed as instances of statistical regression models that incorporate complex feature effects and potentially non-Gaussian outcomes. Such structured regression models, including time-aware varying coefficients models, are, however, limited in their applicability to categorical effects and inclusion of a large number of interactions. Here, we propose Factorized Structured Regression (FaStR) for scalable varying coefficient models. FaStR overcomes limitations of general regression models for large-scale data by combining structured additive regression and factorization approaches in a neural network-based model implementation. This fusion provides a scalable framework for the estimation of statistical models in previously infeasible data settings. Empirical results confirm that the estimation of varying coefficients of our approach is on par with state-of-the-art regression techniques, while scaling notably better and also being competitive with other time-aware RS in terms of prediction performance. We illustrate FaStR's performance and interpretability on a large-scale behavioral study with smartphone user data.
Exploring Map-based Features for Efficient Attention-based Vehicle Motion Prediction
May 25, 2022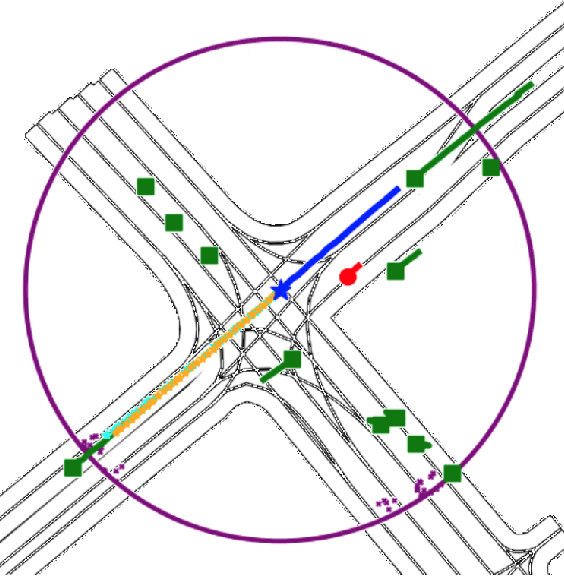
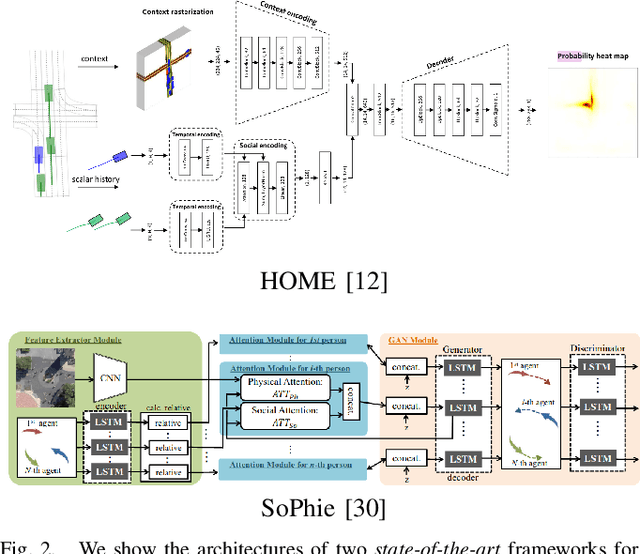
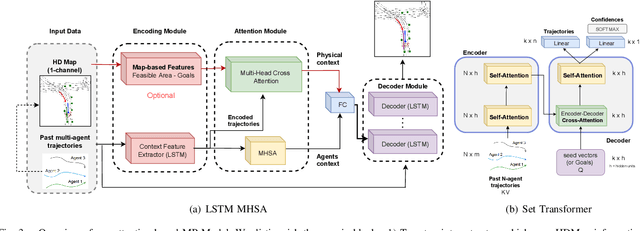
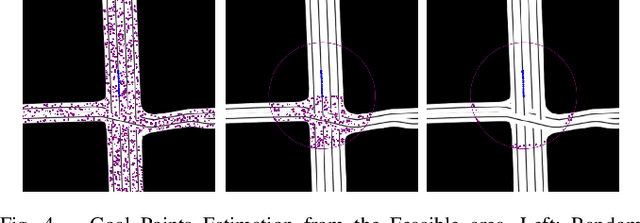
Motion prediction (MP) of multiple agents is a crucial task in arbitrarily complex environments, from social robots to self-driving cars. Current approaches tackle this problem using end-to-end networks, where the input data is usually a rendered top-view of the scene and the past trajectories of all the agents; leveraging this information is a must to obtain optimal performance. In that sense, a reliable Autonomous Driving (AD) system must produce reasonable predictions on time, however, despite many of these approaches use simple ConvNets and LSTMs, models might not be efficient enough for real-time applications when using both sources of information (map and trajectory history). Moreover, the performance of these models highly depends on the amount of training data, which can be expensive (particularly the annotated HD maps). In this work, we explore how to achieve competitive performance on the Argoverse 1.0 Benchmark using efficient attention-based models, which take as input the past trajectories and map-based features from minimal map information to ensure efficient and reliable MP. These features represent interpretable information as the driveable area and plausible goal points, in opposition to black-box CNN-based methods for map processing.